---
title: Home
---
[](https://github.com/invoke-ai/InvokeAI)
[![discord badge]][discord link]
[![latest release badge]][latest release link]
[![github stars badge]][github stars link]
[![github forks badge]][github forks link]
[![CI checks on main badge]][ci checks on main link]
[![CI checks on dev badge]][ci checks on dev link]
[![latest commit to dev badge]][latest commit to dev link]
[![github open issues badge]][github open issues link]
[![github open prs badge]][github open prs link]
[ci checks on dev badge]:
https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/development?label=CI%20status%20on%20dev&cache=900&icon=github
[ci checks on dev link]:
https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Adevelopment
[ci checks on main badge]:
https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/main?label=CI%20status%20on%20main&cache=900&icon=github
[ci checks on main link]:
https://github.com/invoke-ai/InvokeAI/actions/workflows/test-invoke-conda.yml
[discord badge]: https://flat.badgen.net/discord/members/ZmtBAhwWhy?icon=discord
[discord link]: https://discord.gg/ZmtBAhwWhy
[github forks badge]:
https://flat.badgen.net/github/forks/invoke-ai/InvokeAI?icon=github
[github forks link]:
https://useful-forks.github.io/?repo=lstein%2Fstable-diffusion
[github open issues badge]:
https://flat.badgen.net/github/open-issues/invoke-ai/InvokeAI?icon=github
[github open issues link]:
https://github.com/invoke-ai/InvokeAI/issues?q=is%3Aissue+is%3Aopen
[github open prs badge]:
https://flat.badgen.net/github/open-prs/invoke-ai/InvokeAI?icon=github
[github open prs link]:
https://github.com/invoke-ai/InvokeAI/pulls?q=is%3Apr+is%3Aopen
[github stars badge]:
https://flat.badgen.net/github/stars/invoke-ai/InvokeAI?icon=github
[github stars link]: https://github.com/invoke-ai/InvokeAI/stargazers
[latest commit to dev badge]:
https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/development?icon=github&color=yellow&label=last%20dev%20commit&cache=900
[latest commit to dev link]:
https://github.com/invoke-ai/InvokeAI/commits/development
[latest release badge]:
https://flat.badgen.net/github/release/invoke-ai/InvokeAI/development?icon=github
[latest release link]: https://github.com/invoke-ai/InvokeAI/releases
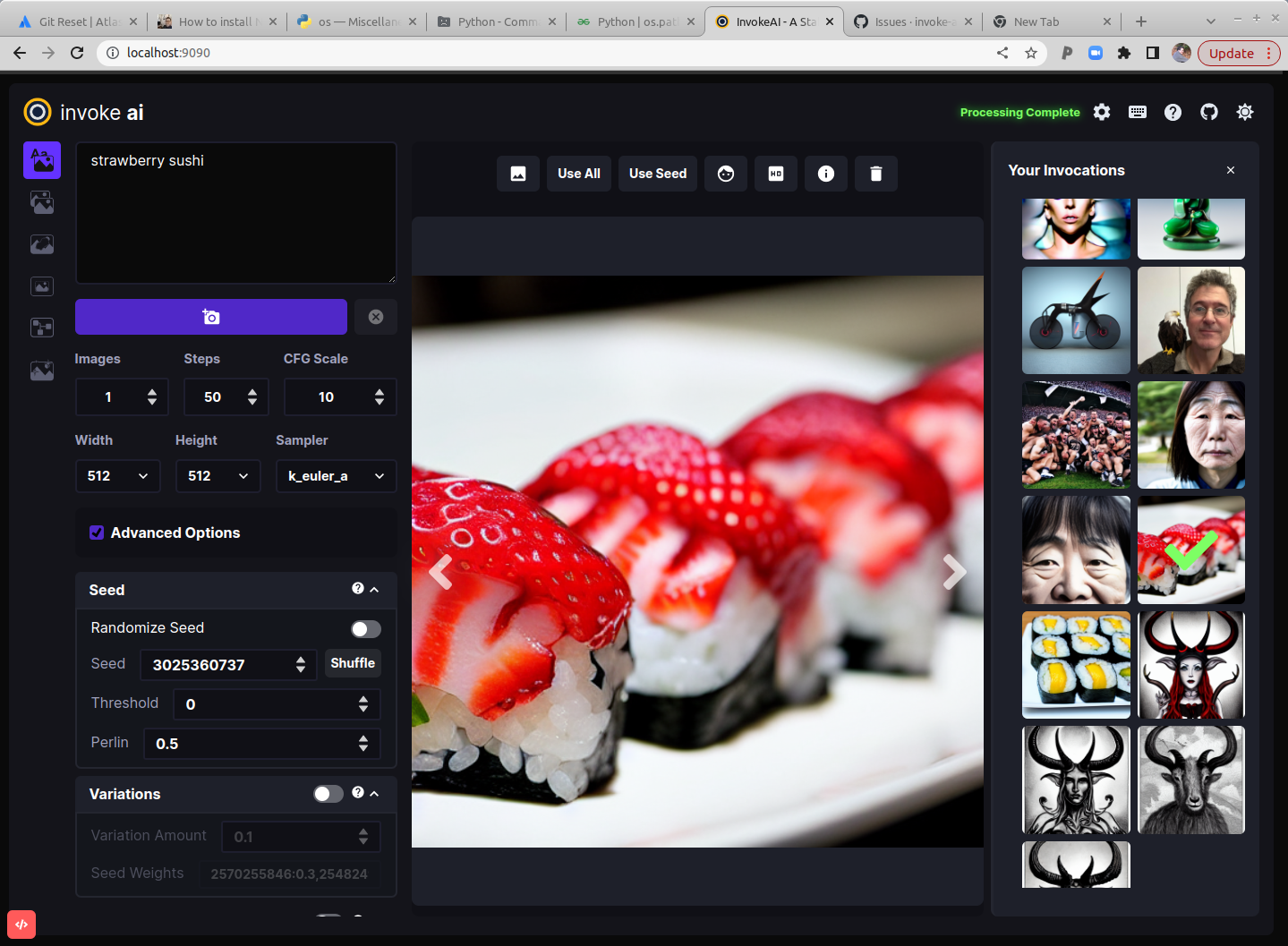
InvokeAI is an
implementation of Stable Diffusion, the open source text-to-image and
image-to-image generator. It provides a streamlined process with various new
features and options to aid the image generation process. It runs on Windows,
Mac and Linux machines, and runs on GPU cards with as little as 4 GB of RAM.
**Quick links**: [Discord Server]
[Code and Downloads] [Bug Reports] [Discussion, Ideas &
Q&A]
!!! note
This fork is rapidly evolving. Please use the [Issues tab](https://github.com/invoke-ai/InvokeAI/issues) to report bugs and make feature requests. Be sure to use the provided templates. They will help aid diagnose issues faster.
## :fontawesome-solid-computer: Hardware Requirements
### :octicons-cpu-24: System
You wil need one of the following:
- :simple-nvidia: An NVIDIA-based graphics card with 4 GB or more VRAM memory.
- :simple-amd: An AMD-based graphics card with 4 GB or more VRAM memory (Linux
only)
- :fontawesome-brands-apple: An Apple computer with an M1 chip.
We do **not recommend** the following video cards due to issues with their
running in half-precision mode and having insufficient VRAM to render 512x512
images in full-precision mode:
- NVIDIA 10xx series cards such as the 1080ti
- GTX 1650 series cards
- GTX 1660 series cards
### :fontawesome-solid-memory: Memory and Disk
- At least 12 GB Main Memory RAM.
- At least 18 GB of free disk space for the machine learning model, Python, and
all its dependencies.
## :octicons-package-dependencies-24: Installation
This fork is supported across Linux, Windows and Macintosh. Linux users can use
either an Nvidia-based card (with CUDA support) or an AMD card (using the ROCm
driver).
### [Installation Getting Started Guide](installation)
#### [Automated Installer](installation/010_INSTALL_AUTOMATED.md)
This method is recommended for 1st time users
#### [Manual Installation](installation/020_INSTALL_MANUAL.md)
This method is recommended for experienced users and developers
#### [Docker Installation](installation/040_INSTALL_DOCKER.md)
This method is recommended for those familiar with running Docker containers
### Other Installation Guides
- [PyPatchMatch](installation/060_INSTALL_PATCHMATCH.md)
- [XFormers](installation/070_INSTALL_XFORMERS.md)
- [CUDA and ROCm Drivers](installation/030_INSTALL_CUDA_AND_ROCM.md)
- [Installing New Models](installation/050_INSTALLING_MODELS.md)
## :octicons-gift-24: InvokeAI Features
### The InvokeAI Web Interface
- [WebUI overview](features/WEB.md)
- [WebUI hotkey reference guide](features/WEBUIHOTKEYS.md)
- [WebUI Unified Canvas for Img2Img, inpainting and outpainting](features/UNIFIED_CANVAS.md)
### The InvokeAI Command Line Interface
- [Command Line Interace Reference Guide](features/CLI.md)
### Image Management
- [Image2Image](features/IMG2IMG.md)
- [Inpainting](features/INPAINTING.md)
- [Outpainting](features/OUTPAINTING.md)
- [Adding custom styles and subjects](features/CONCEPTS.md)
- [Upscaling and Face Reconstruction](features/POSTPROCESS.md)
- [Embiggen upscaling](features/EMBIGGEN.md)
- [Other Features](features/OTHER.md)
### Model Management
- [Installing](installation/050_INSTALLING_MODELS.md)
- [Model Merging](features/MODEL_MERGING.md)
- [Style/Subject Concepts and Embeddings](features/CONCEPTS.md)
- [Textual Inversion](features/TEXTUAL_INVERSION.md)
- [Not Safe for Work (NSFW) Checker](features/NSFW.md)
### Prompt Engineering
- [Prompt Syntax](features/PROMPTS.md)
- [Generating Variations](features/VARIATIONS.md)
## :octicons-log-16: Latest Changes
### v2.3.0 (9 February 2023)
#### Migration to Stable Diffusion `diffusers` models
Previous versions of InvokeAI supported the original model file format introduced with Stable Diffusion 1.4. In the original format, known variously as "checkpoint", or "legacy" format, there is a single large weights file ending with `.ckpt` or `.safetensors`. Though this format has served the community well, it has a number of disadvantages, including file size, slow loading times, and a variety of non-standard variants that require special-case code to handle. In addition, because checkpoint files are actually a bundle of multiple machine learning sub-models, it is hard to swap different sub-models in and out, or to share common sub-models. A new format, introduced by the StabilityAI company in collaboration with HuggingFace, is called `diffusers` and consists of a directory of individual models. The most immediate benefit of `diffusers` is that they load from disk very quickly. A longer term benefit is that in the near future `diffusers` models will be able to share common sub-models, dramatically reducing disk space when you have multiple fine-tune models derived from the same base.
When you perform a new install of version 2.3.0, you will be offered the option to install the `diffusers` versions of a number of popular SD models, including Stable Diffusion versions 1.5 and 2.1 (including the 768x768 pixel version of 2.1). These will act and work just like the checkpoint versions. Do not be concerned if you already have a lot of ".ckpt" or ".safetensors" models on disk! InvokeAI 2.3.0 can still load these and generate images from them without any extra intervention on your part.
To take advantage of the optimized loading times of `diffusers` models, InvokeAI offers options to convert legacy checkpoint models into optimized `diffusers` models. If you use the `invokeai` command line interface, the relevant commands are:
* `!convert_model` -- Take the path to a local checkpoint file or a URL that is pointing to one, convert it into a `diffusers` model, and import it into InvokeAI's models registry file.
* `!optimize_model` -- If you already have a checkpoint model in your InvokeAI models file, this command will accept its short name and convert it into a like-named `diffusers` model, optionally deleting the original checkpoint file.
* `!import_model` -- Take the local path of either a checkpoint file or a `diffusers` model directory and import it into InvokeAI's registry file. You may also provide the ID of any diffusers model that has been published on the [HuggingFace models repository](https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads) and it will be downloaded and installed automatically.
The WebGUI offers similar functionality for model management.
For advanced users, new command-line options provide additional functionality. Launching `invokeai` with the argument `--autoconvert ` takes the path to a directory of checkpoint files, automatically converts them into `diffusers` models and imports them. Each time the script is launched, the directory will be scanned for new checkpoint files to be loaded. Alternatively, the `--ckpt_convert` argument will cause any checkpoint or safetensors model that is already registered with InvokeAI to be converted into a `diffusers` model on the fly, allowing you to take advantage of future diffusers-only features without explicitly converting the model and saving it to disk.
Please see [INSTALLING MODELS](https://invoke-ai.github.io/InvokeAI/installation/050_INSTALLING_MODELS/) for more information on model management in both the command-line and Web interfaces.
#### Support for the `XFormers` Memory-Efficient Crossattention Package
On CUDA (Nvidia) systems, version 2.3.0 supports the `XFormers` library. Once installed, the`xformers` package dramatically reduces the memory footprint of loaded Stable Diffusion models files and modestly increases image generation speed. `xformers` will be installed and activated automatically if you specify a CUDA system at install time.
The caveat with using `xformers` is that it introduces slightly non-deterministic behavior, and images generated using the same seed and other settings will be subtly different between invocations. Generally the changes are unnoticeable unless you rapidly shift back and forth between images, but to disable `xformers` and restore fully deterministic behavior, you may launch InvokeAI using the `--no-xformers` option. This is most conveniently done by opening the file `invokeai/invokeai.init` with a text editor, and adding the line `--no-xformers` at the bottom.
#### A Negative Prompt Box in the WebUI
There is now a separate text input box for negative prompts in the WebUI. This is convenient for stashing frequently-used negative prompts ("mangled limbs, bad anatomy"). The `[negative prompt]` syntax continues to work in the main prompt box as well.
To see exactly how your prompts are being parsed, launch `invokeai` with the `--log_tokenization` option. The console window will then display the tokenization process for both positive and negative prompts.
#### Model Merging
Version 2.3.0 offers an intuitive user interface for merging up to three Stable Diffusion models using an intuitive user interface. Model merging allows you to mix the behavior of models to achieve very interesting effects. To use this, each of the models must already be imported into InvokeAI and saved in `diffusers` format, then launch the merger using a new menu item in the InvokeAI launcher script (`invoke.sh`, `invoke.bat`) or directly from the command line with `invokeai-merge --gui`. You will be prompted to select the models to merge, the proportions in which to mix them, and the mixing algorithm. The script will create a new merged `diffusers` model and import it into InvokeAI for your use.
See [MODEL MERGING](https://invoke-ai.github.io/InvokeAI/features/MODEL_MERGING/) for more details.
#### Textual Inversion Training
Textual Inversion (TI) is a technique for training a Stable Diffusion model to emit a particular subject or style when triggered by a keyword phrase. You can perform TI training by placing a small number of images of the subject or style in a directory, and choosing a distinctive trigger phrase, such as "pointillist-style". After successful training, The subject or style will be activated by including `` in your prompt.
Previous versions of InvokeAI were able to perform TI, but it required using a command-line script with dozens of obscure command-line arguments. Version 2.3.0 features an intuitive TI frontend that will build a TI model on top of any `diffusers` model. To access training you can launch from a new item in the launcher script or from the command line using `invokeai-ti --gui`.
See [TEXTUAL INVERSION](https://invoke-ai.github.io/InvokeAI/features/TEXTUAL_INVERSION/) for further details.
#### A New Installer Experience
The InvokeAI installer has been upgraded in order to provide a smoother and hopefully more glitch-free experience. In addition, InvokeAI is now packaged as a PyPi project, allowing developers and power-users to install InvokeAI with the command `pip install InvokeAI --use-pep517`. Please see [Installation](#installation) for details.
Developers should be aware that the `pip` installation procedure has been simplified and that the `conda` method is no longer supported at all. Accordingly, the `environments_and_requirements` directory has been deleted from the repository.
#### Command-line name changes
All of InvokeAI's functionality, including the WebUI, command-line interface, textual inversion training and model merging, can all be accessed from the `invoke.sh` and `invoke.bat` launcher scripts. The menu of options has been expanded to add the new functionality. For the convenience of developers and power users, we have normalized the names of the InvokeAI command-line scripts:
* `invokeai` -- Command-line client
* `invokeai --web` -- Web GUI
* `invokeai-merge --gui` -- Model merging script with graphical front end
* `invokeai-ti --gui` -- Textual inversion script with graphical front end
* `invokeai-configure` -- Configuration tool for initializing the `invokeai` directory and selecting popular starter models.
For backward compatibility, the old command names are also recognized, including `invoke.py` and `configure-invokeai.py`. However, these are deprecated and will eventually be removed.
Developers should be aware that the locations of the script's source code has been moved. The new locations are:
* `invokeai` => `ldm/invoke/CLI.py`
* `invokeai-configure` => `ldm/invoke/config/configure_invokeai.py`
* `invokeai-ti`=> `ldm/invoke/training/textual_inversion.py`
* `invokeai-merge` => `ldm/invoke/merge_diffusers`
Developers are strongly encouraged to perform an "editable" install of InvokeAI using `pip install -e . --use-pep517` in the Git repository, and then to call the scripts using their 2.3.0 names, rather than executing the scripts directly. Developers should also be aware that the several important data files have been relocated into a new directory named `invokeai`. This includes the WebGUI's `frontend` and `backend` directories, and the `INITIAL_MODELS.yaml` files used by the installer to select starter models. Eventually all InvokeAI modules will be in subdirectories of `invokeai`.
Please see [2.3.0 Release Notes](https://github.com/invoke-ai/InvokeAI/releases/tag/v2.3.0) for further details.
For older changelogs, please visit the
**[CHANGELOG](CHANGELOG/#v223-2-december-2022)**.
## :material-target: Troubleshooting
Please check out our **[:material-frequently-asked-questions:
Troubleshooting
Guide](installation/010_INSTALL_AUTOMATED.md#troubleshooting)** to
get solutions for common installation problems and other issues.
## :octicons-repo-push-24: Contributing
Anyone who wishes to contribute to this project, whether documentation,
features, bug fixes, code cleanup, testing, or code reviews, is very much
encouraged to do so. If you are unfamiliar with how to contribute to GitHub
projects, here is a
[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github).
A full set of contribution guidelines, along with templates, are in progress,
but for now the most important thing is to **make your pull request against the
"development" branch**, and not against "main". This will help keep public
breakage to a minimum and will allow you to propose more radical changes.
## :octicons-person-24: Contributors
This fork is a combined effort of various people from across the world.
[Check out the list of all these amazing people](other/CONTRIBUTORS.md). We
thank them for their time, hard work and effort.
## :octicons-question-24: Support
For support, please use this repository's GitHub Issues tracking service. Feel
free to send me an email if you use and like the script.
Original portions of the software are Copyright (c) 2022-23
by [The InvokeAI Team](https://github.com/invoke-ai).
## :octicons-book-24: Further Reading
Please see the original README for more information on this software and
underlying algorithm, located in the file
[README-CompViz.md](other/README-CompViz.md).