Our app changes redux state very, very often. As our undo/redo history grows, the calls to persist state start to take in the 100ms range, due to a the deep cloning of the history. This causes very noticeable performance lag. The deep cloning is required because we need to blacklist certain items in redux from being persisted (e.g. the app's connection status). Debouncing the whole process of persistence is a simple and effective solution. Unfortunately, `redux-persist` dropped `debounce` between v4 and v5, replacing it with `throttle`. `throttle`, instead of delaying the expensive action until a period of X ms of inactivity, simply ensures the action is executed at least every X ms. Of course, this does not fix our performance issue. The patch is very simple. It adds a `debounce` argument - a number of milliseconds - and debounces `redux-persist`'s `update()` method (provided by `createPersistoid`) by that many ms. Before this, I also tried writing a custom storage adapter for `redux-persist` to debounce the calls to `localStorage.setItem()`. While this worked and was far less invasive, it doesn't actually address the issue. It turns out `setItem()` is a very fast part of the process. We use `redux-deep-persist` to simplify the `redux-persist` configuration, which can get complicated when you need to blacklist or whitelist deeply nested state. There is also a patch here for that library because it uses the same types as `redux-persist`. Unfortunately, the last release of `redux-persist` used a package `flat-stream` which was malicious and has been removed from npm. The latest commits to `redux-persist` (about 1 year ago) do not build; we cannot use the master branch. And between the last release and last commit, the changes have all been breaking. Patching this last release (about 3 years old at this point) directly is far simpler than attempting to fix the upstream library's master branch or figuring out an alternative to the malicious and now non-existent dependency.
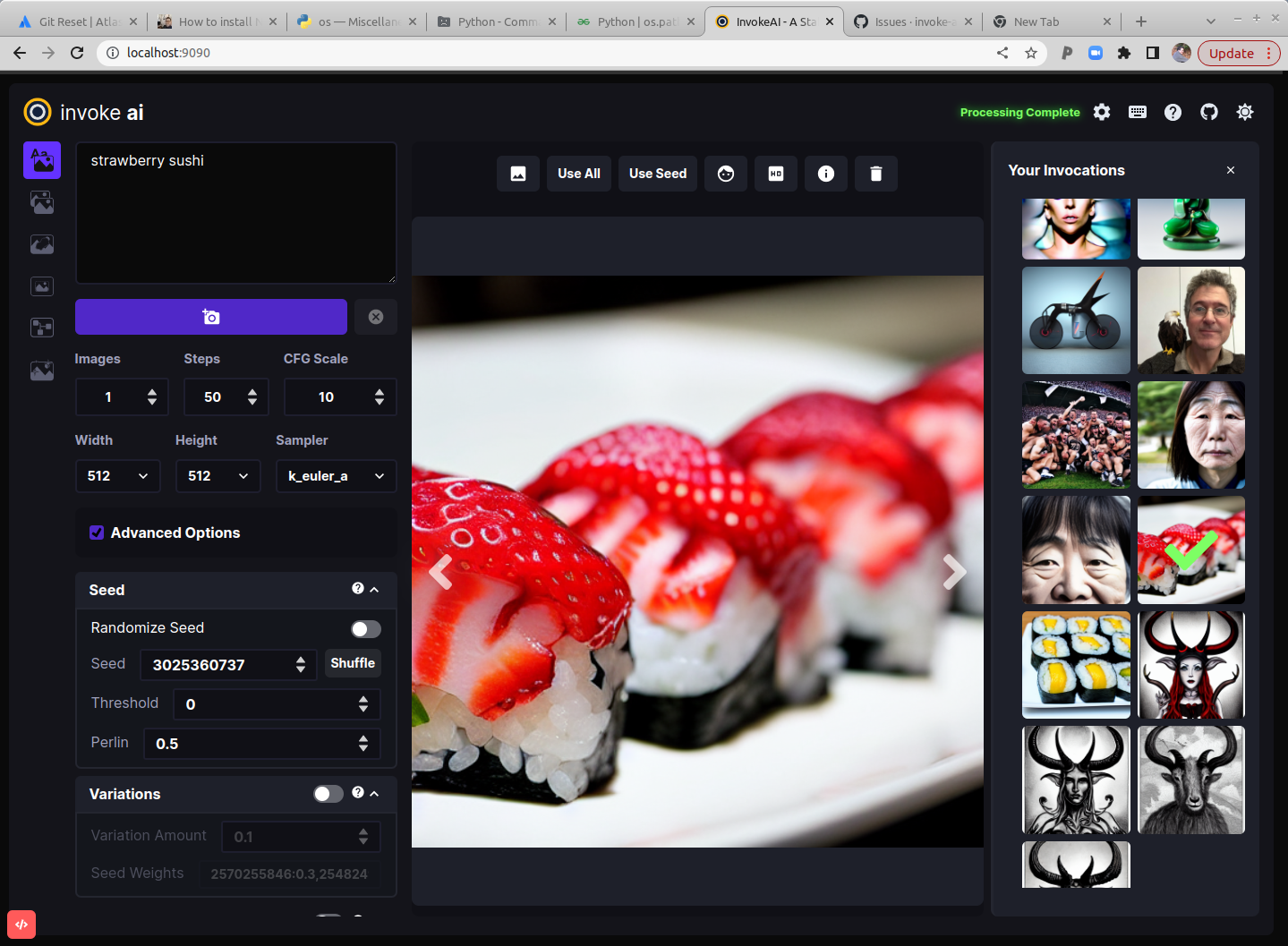
This is a fork of CompVis/stable-diffusion, the open source text-to-image generator. It provides a streamlined process with various new features and options to aid the image generation process. It runs on Windows, Mac and Linux machines, with GPU cards with as little as 4 GB of RAM. It provides both a polished Web interface (see below), and an easy-to-use command-line interface.
Quick links: [Discord Server] [Documentation and Tutorials] [Code and Downloads] [Bug Reports] [Discussion, Ideas & Q&A]
Note: This fork is rapidly evolving. Please use the Issues tab to report bugs and make feature requests. Be sure to use the provided templates. They will help aid diagnose issues faster.
Table of Contents
- Installation
- Hardware Requirements
- Features
- Latest Changes
- Troubleshooting
- Contributing
- Contributors
- Support
- Further Reading
Installation
This fork is supported across Linux, Windows and Macintosh. Linux users can use either an Nvidia-based card (with CUDA support) or an AMD card (using the ROCm driver). For full installation and upgrade instructions, please see: InvokeAI Installation Overview
Hardware Requirements
System
You wil need one of the following:
- An NVIDIA-based graphics card with 4 GB or more VRAM memory.
- An Apple computer with an M1 chip.
Memory
- At least 12 GB Main Memory RAM.
Disk
- At least 12 GB of free disk space for the machine learning model, Python, and all its dependencies.
Note
If you have a Nvidia 10xx series card (e.g. the 1080ti), please run the dream script in full-precision mode as shown below.
Similarly, specify full-precision mode on Apple M1 hardware.
Precision is auto configured based on the device. If however you encounter
errors like 'expected type Float but found Half' or 'not implemented for Half'
you can try starting invoke.py with the --precision=float32 flag:
(invokeai) ~/InvokeAI$ python scripts/invoke.py --precision=float32
Features
Major Features
- Web Server
- Interactive Command Line Interface
- Image To Image
- Inpainting Support
- Outpainting Support
- Upscaling, face-restoration and outpainting
- Reading Prompts From File
- Prompt Blending
- Thresholding and Perlin Noise Initialization Options
- Negative/Unconditioned Prompts
- Variations
- Personalizing Text-to-Image Generation
- Simplified API for text to image generation
Other Features
Latest Changes
-
v2.0.1 (13 October 2022)
- fix noisy images at high step count when using k* samplers
- dream.py script now calls invoke.py module directly rather than via a new python process (which could break the environment)
-
v2.0.0 (9 October 2022)
dream.pyscript renamedinvoke.py. Adream.pyscript wrapper remains for backward compatibility.- Completely new WebGUI - launch with
python3 scripts/invoke.py --web - Support for inpainting and outpainting
- img2img runs on all k* samplers
- Support for negative prompts
- Support for CodeFormer face reconstruction
- Support for Textual Inversion on Macintoshes
- Support in both WebGUI and CLI for post-processing of previously-generated images
using facial reconstruction, ESRGAN upscaling, outcropping (similar to DALL-E infinite canvas),
and "embiggen" upscaling. See the
!fixcommand. - New
--hiresoption oninvoke>line allows larger images to be created without duplicating elements, at the cost of some performance. - New
--perlinand--thresholdoptions allow you to add and control variation during image generation (see Thresholding and Perlin Noise Initialization - Extensive metadata now written into PNG files, allowing reliable regeneration of images and tweaking of previous settings.
- Command-line completion in
invoke.pynow works on Windows, Linux and Mac platforms. - Improved command-line completion behavior.
New commands added:
- List command-line history with
!history - Search command-line history with
!search - Clear history with
!clear
- List command-line history with
- Deprecated
--full_precision/-F. Simply omit it andinvoke.pywill auto configure. To switch away from auto use the new flag like--precision=float32.
For older changelogs, please visit the CHANGELOG.
Troubleshooting
Please check out our Q&A to get solutions for common installation problems and other issues.
Contributing
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code cleanup, testing, or code reviews, is very much encouraged to do so. If you are unfamiliar with how to contribute to GitHub projects, here is a Getting Started Guide.
A full set of contribution guidelines, along with templates, are in progress, but for now the most important thing is to make your pull request against the "development" branch, and not against "main". This will help keep public breakage to a minimum and will allow you to propose more radical changes.
Contributors
This fork is a combined effort of various people from across the world. Check out the list of all these amazing people. We thank them for their time, hard work and effort.
Support
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an email if you use and like the script.
Original portions of the software are Copyright (c) 2020 Lincoln D. Stein
Further Reading
Please see the original README for more information on this software and underlying algorithm, located in the file README-CompViz.md.