Currently translated at 81.4% (382 of 469 strings)
translationBot(ui): update translation (Russian)
Currently translated at 81.6% (382 of 468 strings)
Co-authored-by: Sergey Krashevich <svk@svk.su>
Translate-URL: https://hosted.weblate.org/projects/invokeai/web-ui/ru/
Translation: InvokeAI/Web UI
Currently translated at 100.0% (469 of 469 strings)
translationBot(ui): update translation (Italian)
Currently translated at 100.0% (468 of 468 strings)
Co-authored-by: Riccardo Giovanetti <riccardo.giovanetti@gmail.com>
Translate-URL: https://hosted.weblate.org/projects/invokeai/web-ui/it/
Translation: InvokeAI/Web UI
## Major Changes
The invokeai-configure script has now been refactored. The work of
selecting and downloading initial models at install time is now done by
a script named `invokeai-model-install` (module name is
`ldm.invoke.config.model_install`)
Screen 1 - adjust startup options:

Screen 2 - select SD models:
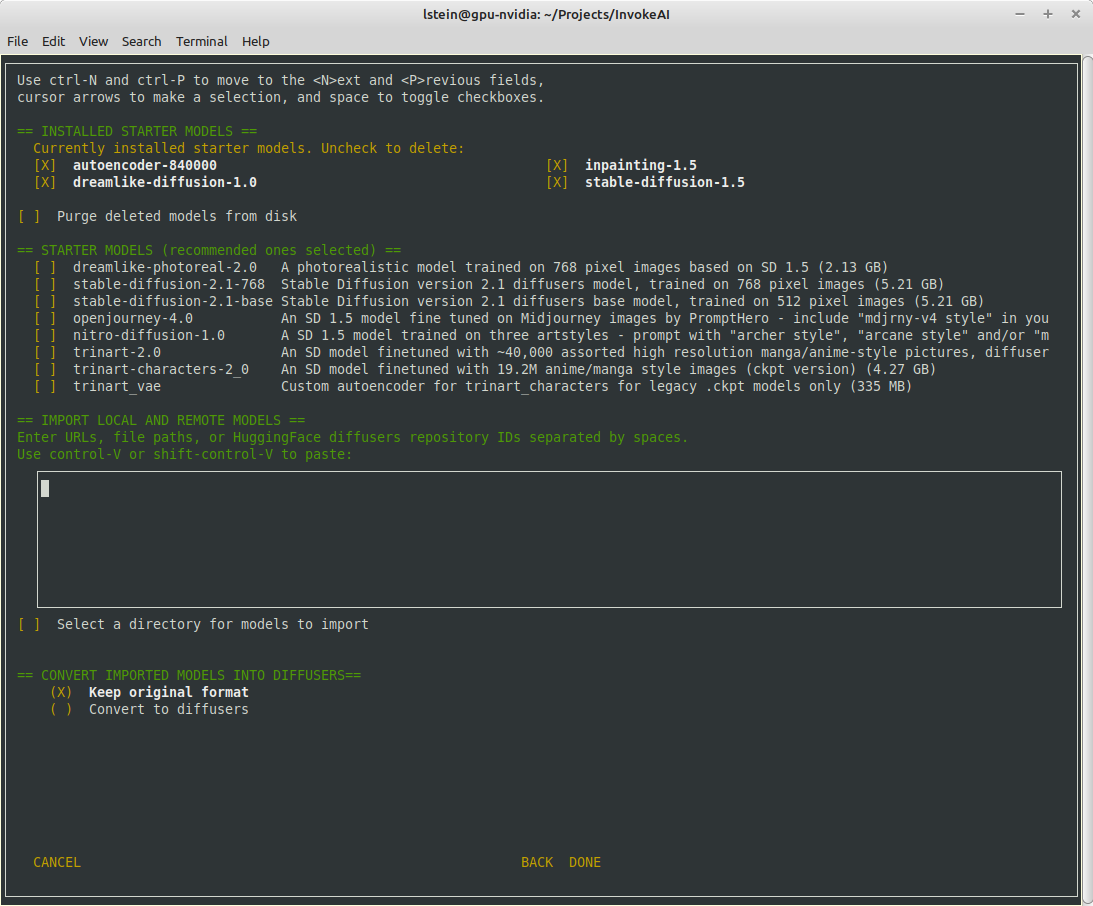
The calling arguments for `invokeai-configure` have not changed, so
nothing should break. After initializing the root directory, the script
calls `invokeai-model-install` to let the user select the starting
models to install.
`invokeai-model-install puts up a console GUI with checkboxes to
indicate which models to install. It respects the `--default_only` and
`--yes` arguments so that CI will continue to work. Here are the various
effects you can achieve:
`invokeai-configure`
This will use console-based UI to initialize invokeai.init,
download support models, and choose and download SD models
`invokeai-configure --yes`
Without activating the GUI, populate invokeai.init with default values,
download support models and download the "recommended" SD models
`invokeai-configure --default_only`
Activate the GUI for changing init options, but don't show the SD
download
form, and automatically download the default SD model (currently SD-1.5)
`invokeai-model-install`
Select and install models. This can be used to download arbitrary
models from the Internet, install HuggingFace models using their
repo_id,
or watch a directory for models to load at startup time
`invokeai-model-install --yes`
Import the recommended SD models without a GUI
`invokeai-model-install --default_only`
As above, but only import the default model
## Flexible Model Imports
The console GUI allows the user to import arbitrary models into InvokeAI
using:
1. A HuggingFace Repo_id
2. A URL (http/https/ftp) that points to a checkpoint or safetensors
file
3. A local path on disk pointing to a checkpoint/safetensors file or
diffusers directory
4. A directory to be scanned for all checkpoint/safetensors files to be
imported
The UI allows the user to specify multiple models to bulk import. The
user can specify whether to import the ckpt/safetensors as-is, or
convert to `diffusers`. The user can also designate a directory to be
scanned at startup time for checkpoint/safetensors files.
## Backend Changes
To support the model selection GUI PR introduces a new method in
`ldm.invoke.model_manager` called `heuristic_import(). This accepts a
string-like object which can be a repo_id, URL, local path or directory.
It will figure out what the object is and import it. It interrogates the
contents of checkpoint and safetensors files to determine what type of
SD model they are -- v1.x, v2.x or v1.x inpainting.
## Installer
I am attaching a zip file of the installer if you would like to try the
process from end to end.
[InvokeAI-installer-v2.3.0.zip](https://github.com/invoke-ai/InvokeAI/files/10785474/InvokeAI-installer-v2.3.0.zip)
motivation: i want to be doing future prompting development work in the
`compel` lib (https://github.com/damian0815/compel) - which is currently
pip installable with `pip install compel`.
-At some point pathlib was added to the list of imported modules and
this broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
-At some point pathlib was added to the list of imported modules and this
broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
- Disable responsive resizing below starting dimensions (you can make
form larger, but not smaller than what it was at startup)
- Fix bug that caused multiple --ckpt_convert entries (and similar) to
be written to init file.
This bug is related to the format in which we stored prompts for some time: an array of weighted subprompts.
This caused some strife when recalling a prompt if the prompt had colons in it, due to our recently introduced handling of negative prompts.
Currently there is no need to store a prompt as anything other than a string, so we revert to doing that.
Compatibility with structured prompts is maintained via helper hook.
Lots of earlier embeds use a common trigger token such as * or the
hebrew letter shan. Previously, the textual inversion manager would
refuse to load the second and subsequent embeddings that used a
previously-claimed trigger. Now, when this case is encountered, the
trigger token is replaced by <filename> and the user is informed of the
fact.
1. Fixed display crash when the number of installed models is less than
the number of desired columns to display them.
2. Added --ckpt_convert option to init file.
Enhancements:
1. Directory-based imports will not attempt to import components of diffusers models.
2. Diffuser directory imports now supported
3. Files that end with .ckpt that are not Stable Diffusion models (such as VAEs) are
skipped during import.
Bugs identified in Psychedelicious's review:
1. The invokeai-configure form now tracks the current contents of `invokeai.init` correctly.
2. The autoencoders are no longer treated like installable models, but instead are
mandatory support models. They will no longer appear in `models.yaml`
Bugs identified in Damian's review:
1. If invokeai-model-install is started before the root directory is initialized, it will
call invokeai-configure to fix the matter.
2. Fix bug that was causing empty `models.yaml` under certain conditions.
3. Made import textbox smaller
4. Hide the "convert to diffusers" options if nothing to import.
In theory, this reduces peak memory consumption by doing the conditioned
and un-conditioned predictions one after the other instead of in a
single mini-batch.
In practice, it doesn't reduce the reported "Max VRAM used for this
generation" for me, even without xformers. (But it does slow things down
by a good 18%.)
That suggests to me that the peak memory usage is during VAE decoding,
not the diffusion unet, but ymmv. It does [improve things for gogurt's
16 GB
M1](https://github.com/invoke-ai/InvokeAI/pull/2732#issuecomment-1436187407),
so it seems worthwhile.
To try it out, use the `--sequential_guidance` option:
2dded68267/ldm/invoke/args.py (L487-L492)
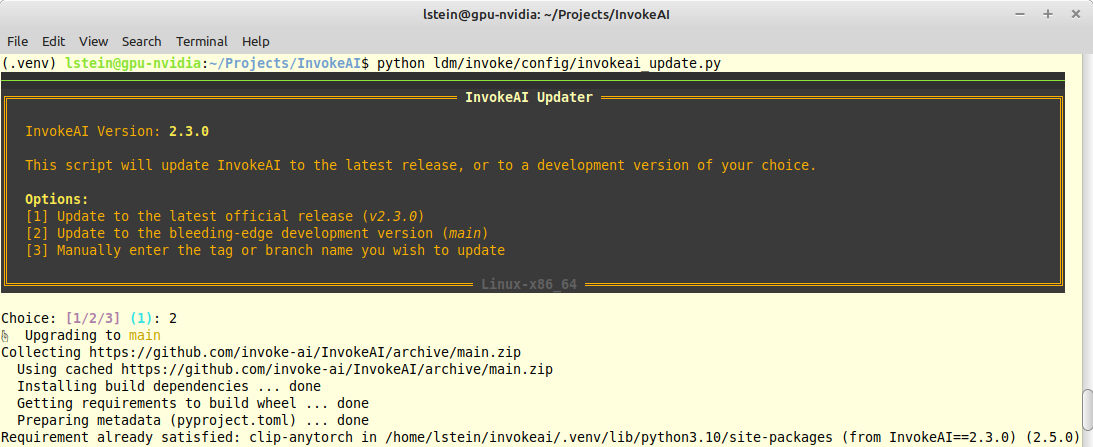
- Adds an update action to launcher script
- This action calls new python script `invokeai-update`, which prompts
user to update to latest release version, main development version, or
an arbitrary git tag or branch name.
- It then uses `pip` to update to whatever tag was specified.
The user interface (such as it is) looks like this:
{kind=link}
{kind=link}
{kind=link}