23 KiB
Stable Diffusion Dream Script
This is a fork of CompVis/stable-diffusion, the wonderful open source text-to-image generator.
The original has been modified in several ways:
Interactive command-line interface similar to the Discord bot
The dream.py script, located in scripts/dream.py, provides an interactive interface to image generation similar to the "dream mothership" bot that Stable AI provided on its Discord server. Unlike the txt2img.py and img2img.py scripts provided in the original CompViz/stable-diffusion source code repository, the time-consuming initialization of the AI model initialization only happens once. After that image generation from the command-line interface is very fast.
The script uses the readline library to allow for in-line editing, command history (up and down arrows), autocompletion, and more.
The script is confirmed to work on Linux and Windows systems. It should work on MacOSX as well, but this is not confirmed. Note that this script runs from the command-line (CMD or Terminal window), and does not have a GUI.
(ldm) ~/stable-diffusion$ python3 ./scripts/dream.py
* Initializing, be patient...
Loading model from models/ldm/text2img-large/model.ckpt
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 872.30 M params.
making attention of type 'vanilla' with 512 in_channels
Working with z of shape (1, 4, 32, 32) = 4096 dimensions.
making attention of type 'vanilla' with 512 in_channels
Loading Bert tokenizer from "models/bert"
setting sampler to plms
* Initialization done! Awaiting your command...
dream> ashley judd riding a camel -n2 -s150
Outputs:
outputs/txt2img-samples/00009.png: "ashley judd riding a camel" -n2 -s150 -S 416354203
outputs/txt2img-samples/00010.png: "ashley judd riding a camel" -n2 -s150-S 1362479620
dream> "there's a fly in my soup" -n6 -g
outputs/txt2img-samples/00041.png: "there's a fly in my soup" -n6 -g -S 2685670268
seeds for individual rows: [2685670268, 1216708065, 2335773498, 822223658, 714542046, 3395302430]
The dream> prompt's arguments are pretty much identical to those used in the Discord bot, except you don't need to type "!dream" (it doesn't hurt if you do). A significant change is that creation of individual images is now the default unless --grid (-g) is given. For backward compatibility, the -i switch is recognized. For command-line help type -h (or --help) at the dream> prompt.
The script itself also recognizes a series of command-line switches that will change important global defaults, such as the directory for image outputs and the location of the model weight files.
Image-to-Image
This script also provides an img2img feature that lets you seed your creations with a drawing or photo. This is a really cool feature that tells stable diffusion to build the prompt on top of the image you provide, preserving the original's basic shape and layout. To use it, provide the --init_img option as shown here:
dream> "waterfall and rainbow" --init_img=./init-images/crude_drawing.png --strength=0.5 -s100 -n4
The --init_img (-I) option gives the path to the seed picture. --strength (-f) controls how much the original will be modified, ranging from 0.0 (keep the original intact), to 1.0 (ignore the original completely). The default is 0.75, and ranges from 0.25-0.75 give interesting results.
Changes
- v1.01 (21 August 2022)
- added k_lms sampling. Please run "conda env update -f environment.yaml" to load the k_lms dependencies!!
- use half precision arithmetic by default, resulting in faster execution and lower memory requirements Pass argument --full_precision to dream.py to get slower but more accurate image generation
Installation
Linux/Mac
- You will need to install the following prerequisites if they are not already available. Use your operating system's preferred installer
- Python (version 3.8.5 recommended; higher may work)
- git
- Install the Python Anaconda environment manager using pip3.
~$ pip3 install anaconda
After installing anaconda, you should log out of your system and log back in. If the installation worked, your command prompt will be prefixed by the name of the current anaconda environment, "(base)".
- Copy the stable-diffusion source code from GitHub:
(base) ~$ git clone https://github.com/lstein/stable-diffusion.git
This will create stable-diffusion folder where you will follow the rest of the steps.
- Enter the newly-created stable-diffusion folder. From this step forward make sure that you are working in the stable-diffusion directory!
(base) ~$ cd stable-diffusion
(base) ~/stable-diffusion$
- Use anaconda to copy necessary python packages, create a new python environment named "ldm", and activate the environment.
(base) ~/stable-diffusion$ conda env create -f environment.yaml
(base) ~/stable-diffusion$ conda activate ldm
(ldm) ~/stable-diffusion$
After these steps, your command prompt will be prefixed by "(ldm)" as shown above.
- Load a couple of small machine-learning models required by stable diffusion:
(ldm) ~/stable-diffusion$ python3 scripts/preload_models.py
- Now you need to install the weights for the stable diffusion model.
For testing prior to the release of the real weights, you can use an older weight file that produces low-quality images. Create a directory within stable-diffusion named "models/ldm/text2img-large", and use the wget URL downloader tool to copy the weight file into it:
(ldm) ~/stable-diffusion$ mkdir -p models/ldm/text2img-large
(ldm) ~/stable-diffusion$ wget -O models/ldm/text2img-large/model.ckpt https://ommer-lab.com/files/latent-diffusion/nitro/txt2img-f8-large/model.ckpt
For testing with the released weighs, you will do something similar, but with a directory named "models/ldm/stable-diffusion-v1"
(ldm) ~/stable-diffusion$ mkdir -p models/ldm/stable-diffusion-v1
(ldm) ~/stable-diffusion$ wget -O models/ldm/stable-diffusion-v1/model.ckpt <ENTER URL HERE>
These weight files are ~5 GB in size, so downloading may take a while.
- Start generating images!
# for the pre-release weights use the -l or --liaon400m switch
(ldm) ~/stable-diffusion$ python3 scripts/dream.py -l
# for the post-release weights do not use the switch
(ldm) ~/stable-diffusion$ python3 scripts/dream.py
# for additional configuration switches and arguments, use -h or --help
(ldm) ~/stable-diffusion$ python3 scripts/dream.py -h
- Subsequently, to relaunch the script, be sure to run "conda activate ldm" (step 5, second command), enter the "stable-diffusion" directory, and then launch the dream script (step 8). If you forget to activate the ldm environment, the script will fail with multiple ModuleNotFound errors.
Updating to newer versions of the script
This distribution is changing rapidly. If you used the "git clone" method (step 5) to download the stable-diffusion directory, then to update to the latest and greatest version, launch the Anaconda window, enter "stable-diffusion", and type:
(ldm) ~/stable-diffusion$ git pull
This will bring your local copy into sync with the remote one.
Windows
-
Install Python version 3.8.5 from here: https://www.python.org/downloads/windows/ (note that several users have reported that later versions do not work properly)
-
Install Anaconda3 (miniconda3 version) from here: https://docs.anaconda.com/anaconda/install/windows/
-
Install Git from here: https://git-scm.com/download/win
-
Launch Anaconda from the Windows Start menu. This will bring up a command window. Type all the remaining commands in this window.
-
Run the command:
git clone https://github.com/lstein/stable-diffusion.git
This will create stable-diffusion folder where you will follow the rest of the steps.
- Enter the newly-created stable-diffusion folder. From this step forward make sure that you are working in the stable-diffusion directory!
cd stable-diffusion
- Run the following two commands:
conda env create -f environment.yaml (step 7a)
conda activate ldm (step 7b)
This will install all python requirements and activate the "ldm" environment which sets PATH and other environment variables properly.
- Run the command:
python scripts\preload_models.py
This installs two machine learning models that stable diffusion requires.
- Now you need to install the weights for the big stable diffusion model.
For testing prior to the release of the real weights, create a directory within stable-diffusion named "models\ldm\text2img-large".
For testing with the released weights, create a directory within stable-diffusion named "models\ldm\stable-diffusion-v1".
Then use a web browser to copy model.ckpt into the appropriate directory. For the text2img-large (pre-release) model, the weights are at https://ommer-lab.com/files/latent-diffusion/nitro/txt2img-f8-large/model.ckpt. Check back here later for the release URL.
- Start generating images!
# for the pre-release weights
python scripts\dream.py -l
# for the post-release weights
python scripts\dream.py
- Subsequently, to relaunch the script, first activate the Anaconda command window (step 4), run "conda activate ldm" (step 7b), and then launch the dream script (step 10).
Updating to newer versions of the script
This distribution is changing rapidly. If you used the "git clone" method (step 5) to download the stable-diffusion directory, then to update to the latest and greatest version, launch the Anaconda window, enter "stable-diffusion", and type:
git pull
This will bring your local copy into sync with the remote one.
Simplified API for text to image generation
For programmers who wish to incorporate stable-diffusion into other products, this repository includes a simplified API for text to image generation, which lets you create images from a prompt in just three lines of code:
from ldm.simplet2i import T2I
model = T2I()
outputs = model.text2image("a unicorn in manhattan")
Outputs is a list of lists in the format [[filename1,seed1],[filename2,seed2]...] Please see ldm/simplet2i.py for more information.
Workaround for machines with limited internet connectivity
My development machine is a GPU node in a high-performance compute cluster which has no connection to the internet. During model initialization, stable-diffusion tries to download the Bert tokenizer and a file needed by the kornia library. This obviously didn't work for me.
To work around this, I have modified ldm/modules/encoders/modules.py to look for locally cached Bert files rather than attempting to download them. For this to work, you must run "scripts/preload_models.py" once from an internet-connected machine prior to running the code on an isolated one. This assumes that both machines share a common network-mounted filesystem with a common .cache directory.
(ldm) ~/stable-diffusion$ python3 ./scripts/preload_models.py
preloading bert tokenizer...
Downloading: 100%|██████████████████████████████████| 28.0/28.0 [00:00<00:00, 49.3kB/s]
Downloading: 100%|██████████████████████████████████| 226k/226k [00:00<00:00, 2.79MB/s]
Downloading: 100%|██████████████████████████████████| 455k/455k [00:00<00:00, 4.36MB/s]
Downloading: 100%|██████████████████████████████████| 570/570 [00:00<00:00, 477kB/s]
...success
preloading kornia requirements...
Downloading: "https://github.com/DagnyT/hardnet/raw/master/pretrained/train_liberty_with_aug/checkpoint_liberty_with_aug.pth" to /u/lstein/.cache/torch/hub/checkpoints/checkpoint_liberty_with_aug.pth
100%|███████████████████████████████████████████████| 5.10M/5.10M [00:00<00:00, 101MB/s]
...success
If you don't need this change and want to download the files just in time, copy over the file ldm/modules/encoders/modules.py from the CompVis/stable-diffusion repository. Or you can run preload_models.py on the target machine.
Support
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an email if you use and like the script.
Original Author: Lincoln D. Stein lincoln.stein@gmail.com
Contributions by: Peter Kowalczyk, Henry Harrison, xraxra, and bmaltais
Original README from CompViz/stable-diffusion
Stable Diffusion was made possible thanks to a collaboration with Stability AI and Runway and builds upon our previous work:
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach*,
Andreas Blattmann*,
Dominik Lorenz,
Patrick Esser,
Björn Ommer
CVPR '22 Oral
which is available on GitHub. PDF at arXiv. Please also visit our Project page.
 Stable Diffusion is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database.
Similar to Google's Imagen,
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See this section below and the model card.
Stable Diffusion is a latent text-to-image diffusion
model.
Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database.
Similar to Google's Imagen,
this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
See this section below and the model card.
Requirements
A suitable conda environment named ldm can be created
and activated with:
conda env create -f environment.yaml
conda activate ldm
You can also update an existing latent diffusion environment by running
conda install pytorch torchvision -c pytorch
pip install transformers==4.19.2
pip install -e .
Stable Diffusion v1
Stable Diffusion v1 refers to a specific configuration of the model architecture that uses a downsampling-factor 8 autoencoder with an 860M UNet and CLIP ViT-L/14 text encoder for the diffusion model. The model was pretrained on 256x256 images and then finetuned on 512x512 images.
Note: Stable Diffusion v1 is a general text-to-image diffusion model and therefore mirrors biases and (mis-)conceptions that are present in its training data. Details on the training procedure and data, as well as the intended use of the model can be found in the corresponding model card. Research into the safe deployment of general text-to-image models is an ongoing effort. To prevent misuse and harm, we currently provide access to the checkpoints only for academic research purposes upon request. This is an experiment in safe and community-driven publication of a capable and general text-to-image model. We are working on a public release with a more permissive license that also incorporates ethical considerations.
Request access to Stable Diffusion v1 checkpoints for academic research
Weights
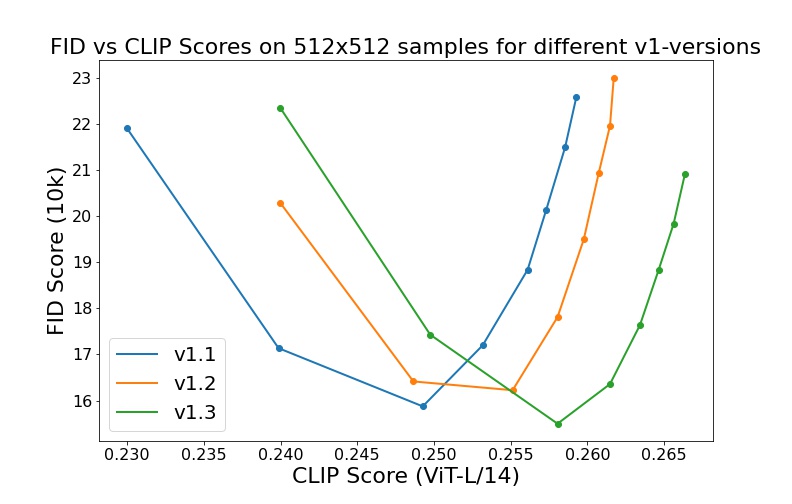
We currently provide three checkpoints, sd-v1-1.ckpt, sd-v1-2.ckpt and sd-v1-3.ckpt,
which were trained as follows,
sd-v1-1.ckpt: 237k steps at resolution256x256on laion2B-en. 194k steps at resolution512x512on laion-high-resolution (170M examples from LAION-5B with resolution>= 1024x1024).sd-v1-2.ckpt: Resumed fromsd-v1-1.ckpt. 515k steps at resolution512x512on "laion-improved-aesthetics" (a subset of laion2B-en, filtered to images with an original size>= 512x512, estimated aesthetics score> 5.0, and an estimated watermark probability< 0.5. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an improved aesthetics estimator).sd-v1-3.ckpt: Resumed fromsd-v1-2.ckpt. 195k steps at resolution512x512on "laion-improved-aesthetics" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:
Text-to-Image with Stable Diffusion


Stable Diffusion is a latent diffusion model conditioned on the (non-pooled) text embeddings of a CLIP ViT-L/14 text encoder.
Sampling Script
After obtaining the weights, link them
mkdir -p models/ldm/stable-diffusion-v1/
ln -s <path/to/model.ckpt> models/ldm/stable-diffusion-v1/model.ckpt
and sample with
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms
By default, this uses a guidance scale of --scale 7.5, Katherine Crowson's implementation of the PLMS sampler,
and renders images of size 512x512 (which it was trained on) in 50 steps. All supported arguments are listed below (type python scripts/txt2img.py --help).
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA] [--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS]
[--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT] [--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision
Note: The inference config for all v1 versions is designed to be used with EMA-only checkpoints.
For this reason use_ema=False is set in the configuration, otherwise the code will try to switch from
non-EMA to EMA weights. If you want to examine the effect of EMA vs no EMA, we provide "full" checkpoints
which contain both types of weights. For these, use_ema=False will load and use the non-EMA weights.
Diffusers Integration
Another way to download and sample Stable Diffusion is by using the diffusers library
# make sure you're logged in with `huggingface-cli login`
from torch import autocast
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-3-diffusers",
use_auth_token=True
)
prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt)["sample"][0]
image.save("astronaut_rides_horse.png")
Image Modification with Stable Diffusion
By using a diffusion-denoising mechanism as first proposed by SDEdit, the model can be used for different tasks such as text-guided image-to-image translation and upscaling. Similar to the txt2img sampling script, we provide a script to perform image modification with Stable Diffusion.
The following describes an example where a rough sketch made in Pinta is converted into a detailed artwork.
python scripts/img2img.py --prompt "A fantasy landscape, trending on artstation" --init-img <path-to-img.jpg> --strength 0.8
Here, strength is a value between 0.0 and 1.0, that controls the amount of noise that is added to the input image. Values that approach 1.0 allow for lots of variations but will also produce images that are not semantically consistent with the input. See the following example.
Input

Outputs


This procedure can, for example, also be used to upscale samples from the base model.
Comments
-
Our codebase for the diffusion models builds heavily on OpenAI's ADM codebase and https://github.com/lucidrains/denoising-diffusion-pytorch. Thanks for open-sourcing!
-
The implementation of the transformer encoder is from x-transformers by lucidrains.
BibTeX
@misc{rombach2021highresolution,
title={High-Resolution Image Synthesis with Latent Diffusion Models},
author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
year={2021},
eprint={2112.10752},
archivePrefix={arXiv},
primaryClass={cs.CV}
}