* Fixes inpainting + code cleanup
* Disable stage info in Inpainting Tab
* Mask Brush Preview now always at 0.5 opacity
The new mask is only visible properly at max opacity but at max opacity the brush preview becomes fully opaque blocking the view. So the mask brush preview no remains at 0.5 no matter what the Brush opacity is.
* Remove save button from Canvas Controls (cleanup)
* Implements invert mask
* Changes "Invert Mask" to "Preserve Masked Areas"
* Fixes (?) spacebar issues
* Patches redux-persist and redux-deep-persist with debounced persists
Our app changes redux state very, very often. As our undo/redo history grows, the calls to persist state start to take in the 100ms range, due to a the deep cloning of the history. This causes very noticeable performance lag.
The deep cloning is required because we need to blacklist certain items in redux from being persisted (e.g. the app's connection status).
Debouncing the whole process of persistence is a simple and effective solution. Unfortunately, `redux-persist` dropped `debounce` between v4 and v5, replacing it with `throttle`. `throttle`, instead of delaying the expensive action until a period of X ms of inactivity, simply ensures the action is executed at least every X ms. Of course, this does not fix our performance issue.
The patch is very simple. It adds a `debounce` argument - a number of milliseconds - and debounces `redux-persist`'s `update()` method (provided by `createPersistoid`) by that many ms.
Before this, I also tried writing a custom storage adapter for `redux-persist` to debounce the calls to `localStorage.setItem()`. While this worked and was far less invasive, it doesn't actually address the issue. It turns out `setItem()` is a very fast part of the process.
We use `redux-deep-persist` to simplify the `redux-persist` configuration, which can get complicated when you need to blacklist or whitelist deeply nested state. There is also a patch here for that library because it uses the same types as `redux-persist`.
Unfortunately, the last release of `redux-persist` used a package `flat-stream` which was malicious and has been removed from npm. The latest commits to `redux-persist` (about 1 year ago) do not build; we cannot use the master branch. And between the last release and last commit, the changes have all been breaking.
Patching this last release (about 3 years old at this point) directly is far simpler than attempting to fix the upstream library's master branch or figuring out an alternative to the malicious and now non-existent dependency.
* Adds debouncing
* Fixes AttributeError: 'dict' object has no attribute 'invert_mask'
* Updates package.json to use redux-persist patches
* Attempts to fix redux-persist debounce patch
* Fixes undo/redo
* Fixes invert mask
* Debounce > 300ms
* Limits history to 256 for each of undo and redo
* Canvas styling
* Hotkeys improvement
* Add Metadata To Viewer
* Increases CFG Scale max to 200
* Fix gallery width size for Outpainting
Also fixes the canvas resizing failing n fast pushes
* Fixes disappearing canvas grid lines
* Adds staging area
* Fixes "use all" not setting variationAmount
Now sets to 0 when the image had variations.
* Builds fresh bundle
* Outpainting tab loads to empty canvas instead of upload
* Fixes wonky canvas layer ordering & compositing
* Fixes error on inpainting paste back
`TypeError: 'float' object cannot be interpreted as an integer`
* Hides staging area outline on mouseover prev/next
* Fixes inpainting not doing img2img when no mask
* Fixes bbox not resizing in outpainting if partially off screen
* Fixes crashes during iterative outpaint. Still doesn't work correctly though.
* Fix iterative outpainting by restoring original images
* Moves image uploading to HTTP
- It all seems to work fine
- A lot of cleanup is still needed
- Logging needs to be added
- May need types to be reviewed
* Fixes: outpainting temp images show in gallery
* WIP refactor to unified canvas
* Removes console.log from redux-persist patch
* Initial unification of canvas
* Removes all references to split inpainting/outpainting canvas
* Add patchmatch and infill_method parameter to prompt2image (options are 'patchmatch' or 'tile').
* Fixes app after removing in/out-painting refs
* Rebases on dev, updates new env files w/ patchmatch
* Organises features/canvas
* Fixes bounding box ending up offscreen
* Organises features/canvas
* Stops unnecessary canvas rescales on gallery state change
* Fixes 2px layout shift on toggle canvas lock
* Clips lines drawn while canvas locked
When drawing with the locked canvas, if a brush stroke gets too close to the edge of the canvas and its stroke would extend past the edge of the canvas, the edge of that stroke will be seen after unlocking the canvas.
This could cause a problem if you unlock the canvas and now have a bunch of strokes just outside the init image area, which are far back in undo history and you cannot easily erase.
With this change, lines drawn while the canvas is locked get clipped to the initial image bbox, fixing this issue.
Additionally, the merge and save to gallery functions have been updated to respect the initial image bbox so they function how you'd expect.
* Fixes reset canvas view when locked
* Fixes send to buttons
* Fixes bounding box not being rounded to 64
* Abandons "inpainting" canvas lock
* Fixes save to gallery including empty area, adds download and copy image
* Fix Current Image display background going over image bounds
* Sets status immediately when clicking Invoke
* Adds hotkeys and refactors sharing of konva instances
Adds hotkeys to canvas. As part of this change, the access to konva instance objects was refactored:
Previously closure'd refs were used to indirectly get access to the konva instances outside of react components.
Now, a getter and setter function are used to provide access directly to the konva objects.
* Updates hotkeys
* Fixes canvas showing spinner on first load
Also adds good default canvas scale and positioning when no image is on it
* Fixes possible hang on MaskCompositer
* Improves behaviour when setting init canvas image/reset view
* Resets bounding box coords/dims when no image present
* Disables canvas actions which cannot be done during processing
* Adds useToastWatcher hook
- Dispatch an `addToast` action with standard Chakra toast options object to add a toast to the toastQueue
- The hook is called in App.tsx and just useEffect's w/ toastQueue as dependency to create the toasts
- So now you can add toasts anywhere you have access to `dispatch`, which includes middleware and thunks
- Adds first usage of this for the save image buttons in canvas
* Update Hotkey Info
Add missing tooltip hotkeys and update the hotkeys modal to reflect the new hotkeys for the Unified Canvas.
* Fix theme changer not displaying current theme on page refresh
* Fix tab count in hotkeys panel
* Unify Brush and Eraser Sizes
* Fix staging area display toggle not working
* Staging Area delete button is now red
So it doesnt feel blended into to the rest of them.
* Revert "Fix theme changer not displaying current theme on page refresh"
This reverts commit 903edfb803e743500242589ff093a8a8a0912726.
* Add arguments to use SSL to webserver
* Integrates #1487 - touch events
Need to add:
- Pinch zoom
- Touch-specific handling (some things aren't quite right)
* Refactors upload-related async thunks
- Now standard thunks instead of RTK createAsyncThunk()
- Adds toasts for all canvas upload-related actions
* Reorganises app file structure
* Fixes Canvas Auto Save to Gallery
* Fixes staging area outline
* Adds staging area hotkeys, disables gallery left/right when staging
* Fixes Use All Parameters
* Fix metadata viewer image url length when viewing intermediate
* Fixes intermediate images being tiny in txt2img/img2img
* Removes stale code
* Improves canvas status text and adds option to toggle debug info
* Fixes paste image to upload
* Adds model drop-down to site header
* Adds theme changer popover
* Fix missing key on ThemeChanger map
* Fixes stage position changing on zoom
* Hotkey Cleanup
- Viewer is now Z
- Canvas Move tool is V - sync with PS
- Removed some unused hotkeys
* Fix canvas resizing when both options and gallery are unpinned
* Implements thumbnails for gallery
- Thumbnails are saved whenever an image is saved, and when gallery requests images from server
- Thumbnails saved at original image aspect ratio with width of 128px as WEBP
- If the thumbnail property of an image is unavailable for whatever reason, the image's full size URL is used instead
* Saves thumbnails to separate thumbnails directory
* Thumbnail size = 256px
* Fix Lightbox Issues
* Disables canvas image saving functions when processing
* Fix index error on going past last image in Gallery
* WIP - Lightbox Fixes
Still need to fix the images not being centered on load when the image res changes
* Fixes another similar index error, simplifies logic
* Reworks canvas toolbar
* Fixes canvas toolbar upload button
* Cleans up IAICanvasStatusText
* Improves metadata handling, fixes#1450
- Removes model list from metadata
- Adds generation's specific model to metadata
- Displays full metadata in JSON viewer
* Gracefully handles corrupted images; fixes#1486
- App does not crash if corrupted image loaded
- Error is displayed in the UI console and CLI output if an image cannot be loaded
* Adds hotkey to reset canvas interaction state
If the canvas' interaction state (e.g. isMovingBoundingBox, isDrawing, etc) get stuck somehow, user can press Escape to reset the state.
* Removes stray console.log()
* Fixes bug causing gallery to close on context menu open
* Minor bugfixes
- When doing long-running canvas image exporting actions, display indeterminate progress bar
- Fix staging area image outline not displaying after committing/discarding results
* Removes unused imports
* Fixes repo root .gitignore ignoring frontend things
* Builds fresh bundle
* Styling updates
* Removes reasonsWhyNotReady
The popover doesn't play well with the button being disabled, and I don't think adds any value.
* Image gallery resize/style tweaks
* Styles buttons for clearing canvas history and mask
* First pass on Canvas options panel
* Fixes bug where discarding staged images results in loss of history
* Adds Save to Gallery button to staging toolbar
* Rearrange some canvas toolbar icons
Put brush stuff together and canvas movement stuff together
* Fix gallery maxwidth on unified canvas
* Update Layer hotkey display to UI
* Adds option to crop to bounding box on save
* Masking option tweaks
* Crop to Bounding Box > Save Box Region Only
* Adds clear temp folder
* Updates mask options popover behavior
* Builds fresh bundle
* Fix styling on alert modals
* Fix input checkbox styling being incorrect on light theme
* Styling fixes
* Improves gallery resize behaviour
* Cap gallery size on canvas tab so it doesnt overflow
* Fixes bug when postprocessing image with no metadata
* Adds IAIAlertDialog component
* Moves Loopback to app settings
* Fixes metadata viewer not showing metadata after refresh
Also adds Dream-style prompt to metadata
* Adds outpainting specific options
* Linting
* Fixes gallery width on lightbox, fixes gallery button expansion
* Builds fresh bundle
* Fix Lightbox images of different res not centering
* Update feature tooltip text
* Highlight mask icon when on mask layer
* Fix gallery not resizing correctly on open and close
* Add loopback to just img2img. Remove from settings.
* Fix to gallery resizing
* Removes Advanced checkbox, cleans up options panel for unified canvas
* Minor styling fixes to new options panel layout
* Styling Updates
* Adds infill method
* Tab Styling Fixes
* memoize outpainting options
* Fix unnecessary gallery re-renders
* Isolate Cursor Pos debug text on canvas to prevent rerenders
* Fixes missing postprocessed image metadata before refresh
* Builds fresh bundle
* Fix rerenders on model select
* Floating panel re-render fix
* Simplify fullscreen hotkey selector
* Add Training WIP Tab
* Adds Training icon
* Move full screen hotkey to floating to prevent tab rerenders
* Adds single-column gallery layout
* Fixes crash on cancel with intermediates enabled, fixes#1416
* Updates npm dependencies
* Fixes img2img attempting inpaint when init image has transparency
* Fixes missing threshold and perlin parameters in metadata viewer
* Renames "Threshold" > "Noise Threshold"
* Fixes postprocessing not being disabled when clicking use all
* Builds fresh bundle
* Adds color picker
* Lints & builds fresh bundle
* Fixes iterations being disabled when seed random & variations are off
* Un-floors cursor position
* Changes color picker preview to circles
* Fixes variation params not set correctly when recalled
* Fixes invoke hotkey not working in input fields
* Simplifies Accordion
Prep for adding reset buttons for each section
* Fixes mask brush preview color
* Committing color picker color changes tool to brush
* Color picker does not overwrite user-selected alpha
* Adds brush color alpha hotkey
* Lints
* Removes force_outpaint param
* Add inpaint size options to inpaint at a larger size than the actual inpaint image, then scale back down for recombination
* Bug fix for inpaint size
* Adds inpaint size (as scale bounding box) to UI
* Adds auto-scaling for inpaint size
* Improves scaled bbox display logic
* Fixes bug with clear mask and history
* Fixes shouldShowStagingImage not resetting to true on commit
* Builds fresh bundle
* Fixes canvas failing to scale on first run
* Builds fresh bundle
* Fixes unnecessary canvas scaling
* Adds gallery drag and drop to img2img/canvas
* Builds fresh bundle
* Fix desktop mode being broken with new versions of flaskwebgui
* Fixes canvas dimensions not setting on first load
* Builds fresh bundle
* stop crash on !import_models call on model inside rootdir
- addresses bug report #1546
* prevent "!switch state gets confused if model switching fails"
- If !switch were to fail on a particular model, then generate got
confused and wouldn't try again until you switch to a different working
model and back again.
- This commit fixes and closes#1547
* Revert "make the docstring more readable and improve the list_models logic"
This reverts commit 248068fe5d.
* fix model cache path
* also set fail-fast to it's default (true)
in this way the whole action fails if one job fails
this should unblock the runners!!!
* fix output path for Archive results
* disable checks for python 3.9
* Update-requirements and test-invoke-pip workflow (#1574)
* update requirements files
* update test-invoke-pip workflow
* move requirements-mkdocs.txt to docs folder (#1575)
* move requirements-mkdocs.txt to docs folder
* update copyright
* Fixes outpainting with resized inpaint size
* Interactive configuration (#1517)
* Update scripts/configure_invokeai.py
prevent crash if output exists
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
* implement changes requested by reviews
* default to correct root and output directory on Windows systems
- Previously the script was relying on the readline buffer editing
feature to set up the correct default. But this feature doesn't
exist on windows.
- This commit detects when user typed return with an empty directory
value and replaces with the default directory.
* improved readability of directory choices
* Update scripts/configure_invokeai.py
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
* better error reporting at startup
- If user tries to run the script outside of the repo or runtime directory,
a more informative message will appear explaining the problem.
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
* Embedding merging (#1526)
* add whole <style token> to vocab for concept library embeddings
* add ability to load multiple concept .bin files
* make --log_tokenization respect custom tokens
* start working on concept downloading system
* preliminary support for dynamic loading and merging of multiple embedded models
- The embedding_manager is now enhanced with ldm.invoke.concepts_lib,
which handles dynamic downloading and caching of embedded models from
the Hugging Face concepts library (https://huggingface.co/sd-concepts-library)
- Downloading of a embedded model is triggered by the presence of one or more
<concept> tags in the prompt.
- Once the embedded model is downloaded, its trigger phrase will be loaded
into the embedding manager and the prompt's <concept> tag will be replaced
with the <trigger_phrase>
- The downloaded model stays on disk for fast loading later.
- The CLI autocomplete will complete partial <concept> tags for you. Type a
'<' and hit tab to get all ~700 concepts.
BUGS AND LIMITATIONS:
- MODEL NAME VS TRIGGER PHRASE
You must use the name of the concept embed model from the SD
library, and not the trigger phrase itself. Usually these are the
same, but not always. For example, the model named "hoi4-leaders"
corresponds to the trigger "<HOI4-Leader>"
One reason for this design choice is that there is no apparent
constraint on the uniqueness of the trigger phrases and one trigger
phrase may map onto multiple models. So we use the model name
instead.
The second reason is that there is no way I know of to search
Hugging Face for models with certain trigger phrases. So we'd have
to download all 700 models to index the phrases.
The problem this presents is that this may confuse users, who will
want to reuse prompts from distributions that use the trigger phrase
directly. Usually this will work, but not always.
- WON'T WORK ON A FIREWALLED SYSTEM
If the host running IAI has no internet connection, it can't
download the concept libraries. I will add a script that allows
users to preload a list of concept models.
- BUG IN PROMPT REPLACEMENT WHEN MODEL NOT FOUND
There's a small bug that occurs when the user provides an invalid
model name. The <concept> gets replaced with <None> in the prompt.
* fix loading .pt embeddings; allow multi-vector embeddings; warn on dupes
* simplify replacement logic and remove cuda assumption
* download list of concepts from hugging face
* remove misleading customization of '*' placeholder
the existing code as-is did not do anything; unclear what it was supposed to do.
the obvious alternative -- setting using 'placeholder_strings' instead of
'placeholder_tokens' to match model.params.personalization_config.params.placeholder_strings --
caused a crash. i think this is because the passed string also needed to be handed over
on init of the PersonalizedBase as the 'placeholder_token' argument.
this is weird config dict magic and i don't want to touch it. put a
breakpoint in personalzied.py line 116 (top of PersonalizedBase.__init__) if
you want to have a crack at it yourself.
* address all the issues raised by damian0815 in review of PR #1526
* actually resize the token_embeddings
* multiple improvements to the concept loader based on code reviews
1. Activated the --embedding_directory option (alias --embedding_path)
to load a single embedding or an entire directory of embeddings at
startup time.
2. Can turn off automatic loading of embeddings using --no-embeddings.
3. Embedding checkpoints are scanned with the pickle scanner.
4. More informative error messages when a concept can't be loaded due
either to a 404 not found error or a network error.
* autocomplete terms end with ">" now
* fix startup error and network unreachable
1. If the .invokeai file does not contain the --root and --outdir options,
invoke.py will now fix it.
2. Catch and handle network problems when downloading hugging face textual
inversion concepts.
* fix misformatted error string
Co-authored-by: Damian Stewart <d@damianstewart.com>
* model_cache.py: fix list_models
Signed-off-by: devops117 <55235206+devops117@users.noreply.github.com>
* add statement of values (#1584)
* this adds the Statement of Values
Google doc source = https://docs.google.com/document/d/1-PrUKDJcxy8OyNGc8CyiHhv2VgLvjt7LRGlEpbg1nmQ/edit?usp=sharing
* Fix heading
* Update InvokeAI_Statement_of_Values.md
* Update InvokeAI_Statement_of_Values.md
* Update InvokeAI_Statement_of_Values.md
* Update InvokeAI_Statement_of_Values.md
* Update InvokeAI_Statement_of_Values.md
* add keturn and mauwii to the team member list
* Fix punctuation
* this adds the Statement of Values
Google doc source = https://docs.google.com/document/d/1-PrUKDJcxy8OyNGc8CyiHhv2VgLvjt7LRGlEpbg1nmQ/edit?usp=sharing
* add keturn and mauwii to the team member list
* fix formating
- make sub bullets use * (decide to all use - or *)
- indent sub bullets
Sorry, first only looked at the code version and found this only after
looking at the markdown rendered version
* use multiparagraph numbered sections
* Break up Statement Of Values as per comments on #1584
* remove duplicated word, reduce vagueness
it's important not to overstate how many artists we are consulting.
* fix typo (sorry blessedcoolant)
Co-authored-by: mauwii <Mauwii@outlook.de>
Co-authored-by: damian <git@damianstewart.com>
* update dockerfile (#1551)
* update dockerfile
* remove not existing file from .dockerignore
* remove bloat and unecesary step
also use --no-cache-dir for pip install
image is now close to 2GB
* make Dockerfile a variable
* set base image to `ubuntu:22.10`
* add build-essential
* link outputs folder for persistence
* update tag variable
* update docs
* fix not customizeable build args, add reqs output
* !model_import autocompletes in ROOTDIR
* Adds psychedelicious to statement of values signature (#1602)
* add a --no-patchmatch option to disable patchmatch loading (#1598)
This feature was added to prevent the CI Macintosh tests from erroring
out when patchmatch is unable to retrieve its shared library from
github assets.
* Fix#1599 by relaxing the `match_trigger` regex (#1601)
* Fix#1599 by relaxing the `match_trigger` regex
Also simplify logic and reduce duplication.
* restrict trigger regex again (but not so far)
* make concepts library work with Web UI
This PR makes it possible to include a Hugging Face concepts library
<style-or-subject-trigger> in the WebUI prompt. The metadata seems
to be correctly handled.
* documentation enhancements (#1603)
- Add documentation for the Hugging Face concepts library and TI embedding.
- Fixup index.md to point to each of the feature documentation files,
including ones that are pending.
* tweak setup and environment files for linux & pypatchmatch (#1580)
* tweak setup and environment files for linux & pypatchmatch
- Downgrade python requirements to 3.9 because 3.10 is not supported
on Ubuntu 20.04 LTS (widely-used distro)
- Use our github pypatchmatch 0.1.3 in order to install Makefile
where it needs to be.
- Restored "-e ." as the last install step on pip installs. Hopefully
this will not trigger the high-CPU hang we've previously experienced.
* keep windows on basicsr 1.4.1
* keep windows on basicsr 1.4.1
* bump pypatchmatch requirement to 0.1.4
- This brings in a version of pypatchmatch that will gracefully
handle internet connection not available at startup time.
- Also refactors and simplifies the handling of gfpgan's basicsr requirement
across various platforms.
* revert to older version of list_models() (#1611)
This restores the correct behavior of list_models() and quenches
the bug of list_models() returning a single model entry named "name".
I have not investigated what was wrong with the new version, but I
think it may have to do with changes to the behavior in dict.update()
* Fixes for #1604 (#1605)
* Converts ESRGAN image input to RGB
- Also adds typing for image input.
- Partially resolves#1604
* ensure there are unmasked pixels before color matching
Co-authored-by: Kyle Schouviller <kyle0654@hotmail.com>
* update index.md (#1609)
- comment out non existing link
- fix indention
- add seperator between feature categories
* Debloat-docker (#1612)
* debloat Dockerfile
- less options more but more userfriendly
- better Entrypoint to simulate CLI usage
- without command the container still starts the web-host
* debloat build.sh
* better syntax in run.sh
* update Docker docs
- fix description of VOLUMENAME
- update run script example to reflect new entrypoint
* Test installer (#1618)
* test linux install
* try removing http from parsed requirements
* pip install confirmed working on linux
* ready for linux testing
- rebuilt py3.10-linux-x86_64-cuda-reqs.txt to include pypatchmatch
dependency.
- point install.sh and install.bat to test-installer branch.
* Updates MPS reqs
* detect broken readline history files
* fix download.pytorch.org URL
* Test installer (Win 11) (#1620)
Co-authored-by: Cyrus Chan <cyruswkc@hku.hk>
* Test installer (MacOS 13.0.1 w/ torch==1.12.0) (#1621)
* Test installer (Win 11)
* Test installer (MacOS 13.0.1 w/ torch==1.12.0)
Co-authored-by: Cyrus Chan <cyruswkc@hku.hk>
* change sourceball to development for testing
* Test installer (MacOS 13.0.1 w/ torch==1.12.1 & torchvision==1.13.1) (#1622)
* Test installer (Win 11)
* Test installer (MacOS 13.0.1 w/ torch==1.12.0)
* Test installer (MacOS 13.0.1 w/ torch==1.12.1 & torchvision==1.13.1)
Co-authored-by: Cyrus Chan <cyruswkc@hku.hk>
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
Co-authored-by: Cyrus Chan <82143712+cyruschan360@users.noreply.github.com>
Co-authored-by: Cyrus Chan <cyruswkc@hku.hk>
* 2.2 Doc Updates (#1589)
* Unified Canvas Docs & Assets
Unified Canvas draft
Advanced Tools Updates
Doc Updates (lstein feedback)
* copy edits to Unified Canvas docs
- consistent capitalisation and feature naming
- more intimate address (replace "the user" with "you") for improved User
Engagement(tm)
- grammatical massaging and *poesie*
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
Co-authored-by: damian <git@damianstewart.com>
* include a step after config to `cat ~/.invokeai` (#1629)
* disable patchmatch in CI actions (#1626)
* disable patchmatch in CI actions
* fix indention
* replace tab with spaces
Co-authored-by: Matthias Wild <40327258+mauwii@users.noreply.github.com>
Co-authored-by: mauwii <Mauwii@outlook.de>
* Fix installer script for macOS. (#1630)
* refer to the platform as 'osx' instead of 'mac', otherwise the
composed URL to micromamba is wrong.
* move the `-O` option to `tar` to be grouped with the other tar flags
to avoid the `-O` being interpreted as something to unarchive.
* Removes symlinked environment.yaml (#1631)
Was unintentionally added in #1621
* Fix inpainting with iterations (#1635)
* fix error when inpainting using runwayml inpainting model (#1634)
- error was "Omnibus object has no attribute pil_image"
- closes#1596
* add k_dpmpp_2_a and k_dpmpp_2 solvers options (#1389)
* add k_dpmpp_2_a and k_dpmpp_2 solvers options
* update frontend
Co-authored-by: Victor <victorca25@users.noreply.github.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* add .editorconfig (#1636)
* Web UI 2.2 bugfixes (#1572)
* Fixes bug preventing multiple images from being generated
* Fixes valid seam strength value range
* Update Delete Alert Text
Indicates to the user that images are not permanently deleted.
* Fixes left/right arrows not working on gallery
* Fixes initial image on load erroneously set to a user uploaded image
Should be a result gallery image.
* Lightbox Fixes
- Lightbox is now a button in the current image buttons
- Lightbox is also now available in the gallery context menu
- Lightbox zoom issues fixed
- Lightbox has a fade in animation.
* Fix image display wrapper in current preview not overflow bounds
* Revert "Fix image display wrapper in current preview not overflow bounds"
This reverts commit 5511c82714dbf1d1999d64e8bc357bafa34ddf37.
* Change Staging Area discard icon from Bin to X
* Expose Snap Threshold and Move Snap Settings to BBox Panel
* Changes img2img strength default to 0.75
* Fixes drawing triggering when mouse enters canvas w/ button down
When we only supported inpainting and no zoom, this was useful. It allowed the cursor to leave the canvas (which was easy to do given the limited canvas dimensions) and without losing the "I am drawing" state.
With a zoomable canvas this is no longer as useful.
Additionally, we have more popovers and tools (like the color pickers) which result in unexpected brush strokes. This fixes that issue.
* Revert "Expose Snap Threshold and Move Snap Settings to BBox Panel"
We will handle this a bit differently - by allowing the grid origin to be moved. I will dig in at some point.
This reverts commit 33c92ecf4da724c2f17d9d91c7ea31a43a2f6deb.
* Adds Limit Strokes to Box
* Adds fill bounding box button
* Adds erase bounding box button
* Changes Staging area discard icon to match others
* Fixes right click breaking move tool
* Fixes brush preview visibility issue with "darken outside box"
* Fixes history bugs with addFillRect, addEraseRect, and other actions
* Adds missing `key`
* Fixes postprocessing being applied to canvas generations
* Fixes bbox not getting scaled in various situations
* Fixes staging area show image toggle not resetting on accept/discard
* Locks down canvas while generating/staging
* Fixes move tool breaking when canvas loses focus during move/transform
* Hides cursor when restrict strokes is on and mouse outside bbox
* Lints
* Builds fresh bundle
* Fix overlapping hotkey for Fill Bounding Box
* Build Fresh Bundle
* Fixes bug with mask and bbox overlay
* Builds fresh bundle
Co-authored-by: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
* disable NSFW checker loading during the CI tests (#1641)
* disable NSFW checker loading during the CI tests
The NSFW filter apparently causes invoke.py to crash during CI testing,
possibly due to out of memory errors. This workaround disables NSFW
model loading.
* doc change
* fix formatting errors in yml files
* Configure the NSFW checker at install time with default on (#1624)
* configure the NSFW checker at install time with default on
1. Changes the --safety_checker argument to --nsfw_checker and
--no-nsfw_checker. The original argument is recognized for backward
compatibility.
2. The configure script asks users whether to enable the checker
(default yes). Also offers users ability to select default sampler and
number of generation steps.
3.Enables the pasting of the caution icon on blurred images when
InvokeAI is installed into the package directory.
4. Adds documentation for the NSFW checker, including caveats about
accuracy, memory requirements, and intermediate image dispaly.
* use better fitting icon
* NSFW defaults false for testing
* set default back to nsfw active
Co-authored-by: Matthias Wild <40327258+mauwii@users.noreply.github.com>
Co-authored-by: mauwii <Mauwii@outlook.de>
Signed-off-by: devops117 <55235206+devops117@users.noreply.github.com>
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
Co-authored-by: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Co-authored-by: Kyle Schouviller <kyle0654@hotmail.com>
Co-authored-by: javl <mail@jaspervanloenen.com>
Co-authored-by: Kent Keirsey <31807370+hipsterusername@users.noreply.github.com>
Co-authored-by: mauwii <Mauwii@outlook.de>
Co-authored-by: Matthias Wild <40327258+mauwii@users.noreply.github.com>
Co-authored-by: Damian Stewart <d@damianstewart.com>
Co-authored-by: DevOps117 <55235206+devops117@users.noreply.github.com>
Co-authored-by: damian <git@damianstewart.com>
Co-authored-by: Damian Stewart <null@damianstewart.com>
Co-authored-by: Cyrus Chan <82143712+cyruschan360@users.noreply.github.com>
Co-authored-by: Cyrus Chan <cyruswkc@hku.hk>
Co-authored-by: Andre LaBranche <dre@mac.com>
Co-authored-by: victorca25 <41912303+victorca25@users.noreply.github.com>
Co-authored-by: Victor <victorca25@users.noreply.github.com>
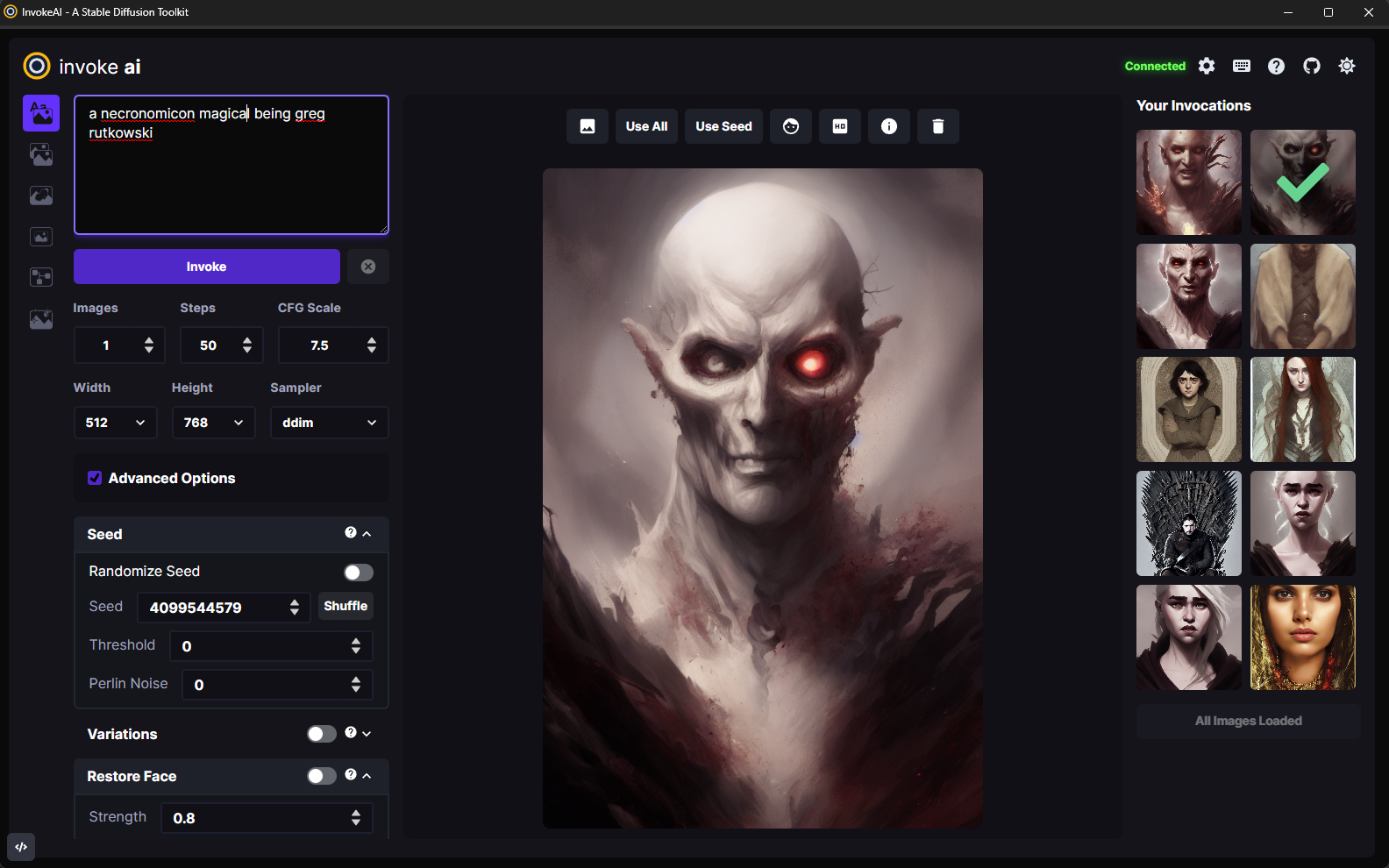
As of version 2.0.0, this distribution comes with a full-featured web server
(see screenshot). To use it, run the invoke.py script by adding the --web
option:
You can then connect to the server by pointing your web browser at
http://localhost:9090. To reach the server from a different machine on your LAN,
you may launch the web server with the --host argument and either the IP
address of the host you are running it on, or the wildcard 0.0.0.0. For
example:
While most of the WebGUI's features are intuitive, here is a guided walkthrough
through its various components.
{:width="640px"}
The screenshot above shows the Text to Image tab of the WebGUI. There are three
main sections:
A control panel on the left, which contains various settings for text to
image generation. The most important part is the text field (currently
showing strawberry sushi) for entering the text prompt, and the camera icon
directly underneath that will render the image. We'll call this the Invoke
button from now on.
The current image section in the middle, which shows a large format
version of the image you are currently working on. A series of buttons at the
top ("image to image", "Use All", "Use Seed", etc) lets you modify the image
in various ways.
A *gallery section on the left that contains a history of the images you
have generated. These images are read and written to the directory specified
at launch time in --outdir.
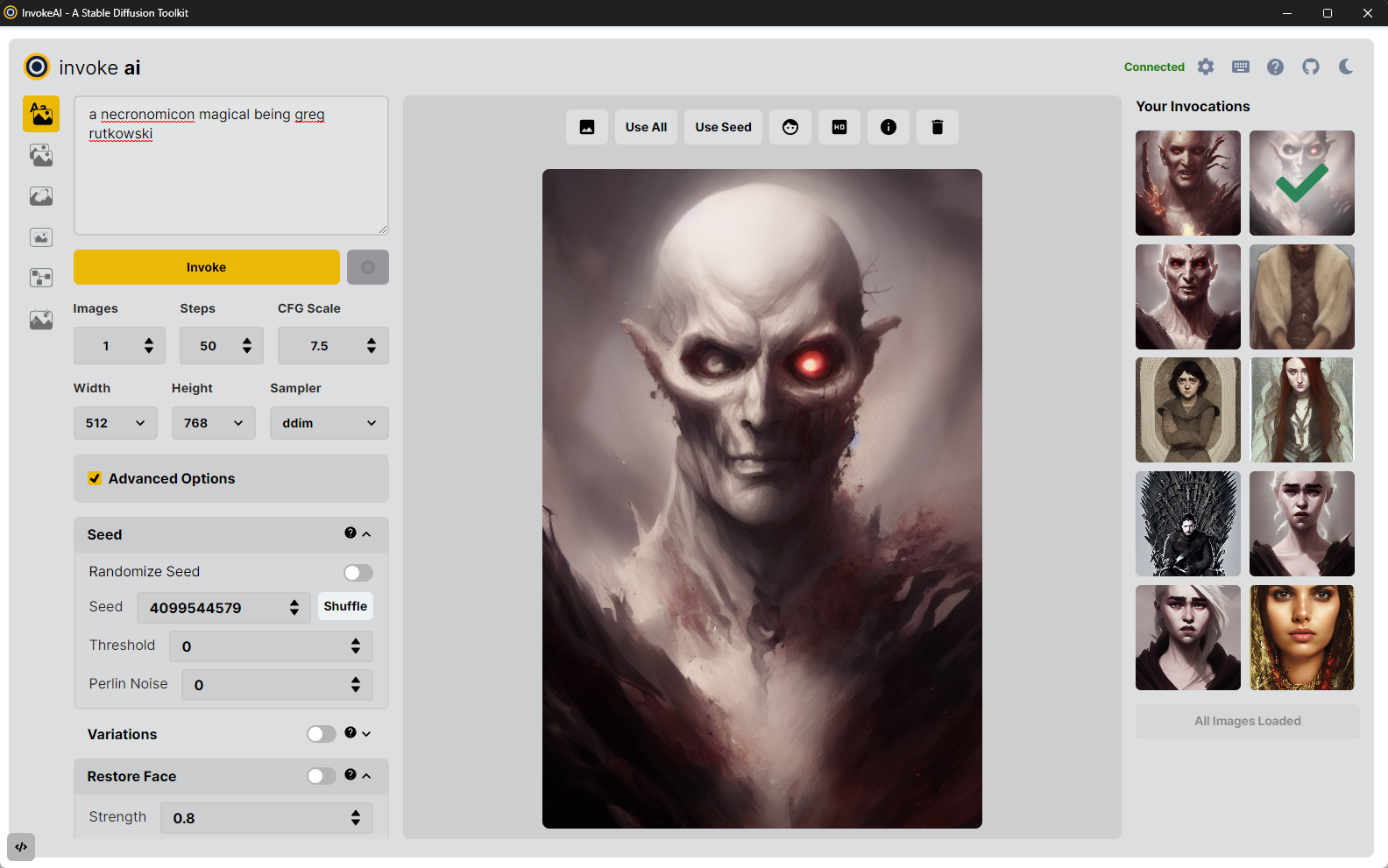
In addition to these three elements, there are a series of icons for changing
global settings, reporting bugs, and changing the theme on the upper right.
There are also a series of icons to the left of the control panel (see
highlighted area in the screenshot below) which select among a series of tabs
for performing different types of operations.
{:width="512px"}
From top to bottom, these are:
Text to Image - generate images from text
Image to Image - from an uploaded starting image (drawing or photograph)
generate a new one, modified by the text prompt
Inpainting (pending) - Interactively erase portions of a starting image and
have the AI fill in the erased region from a text prompt.
Outpainting (pending) - Interactively add blank space to the borders of a
starting image and fill in the background from a text prompt.
Postprocessing (pending) - Interactively postprocess generated images using a
variety of filters.
The inpainting, outpainting and postprocessing tabs are currently in
development. However, limited versions of their features can already be accessed
through the Text to Image and Image to Image tabs.
Walkthrough
The following walkthrough will exercise most (but not all) of the WebGUI's
feature set.
Text to Image
Launch the WebGUI using python scripts/invoke.py --web and connect to it
with your browser by accessing http://localhost:9090. If the browser and
server are running on different machines on your LAN, add the option
--host 0.0.0.0 to the launch command line and connect to the machine
hosting the web server using its IP address or domain name.
If all goes well, the WebGUI should come up and you'll see a green
connected message on the upper right.
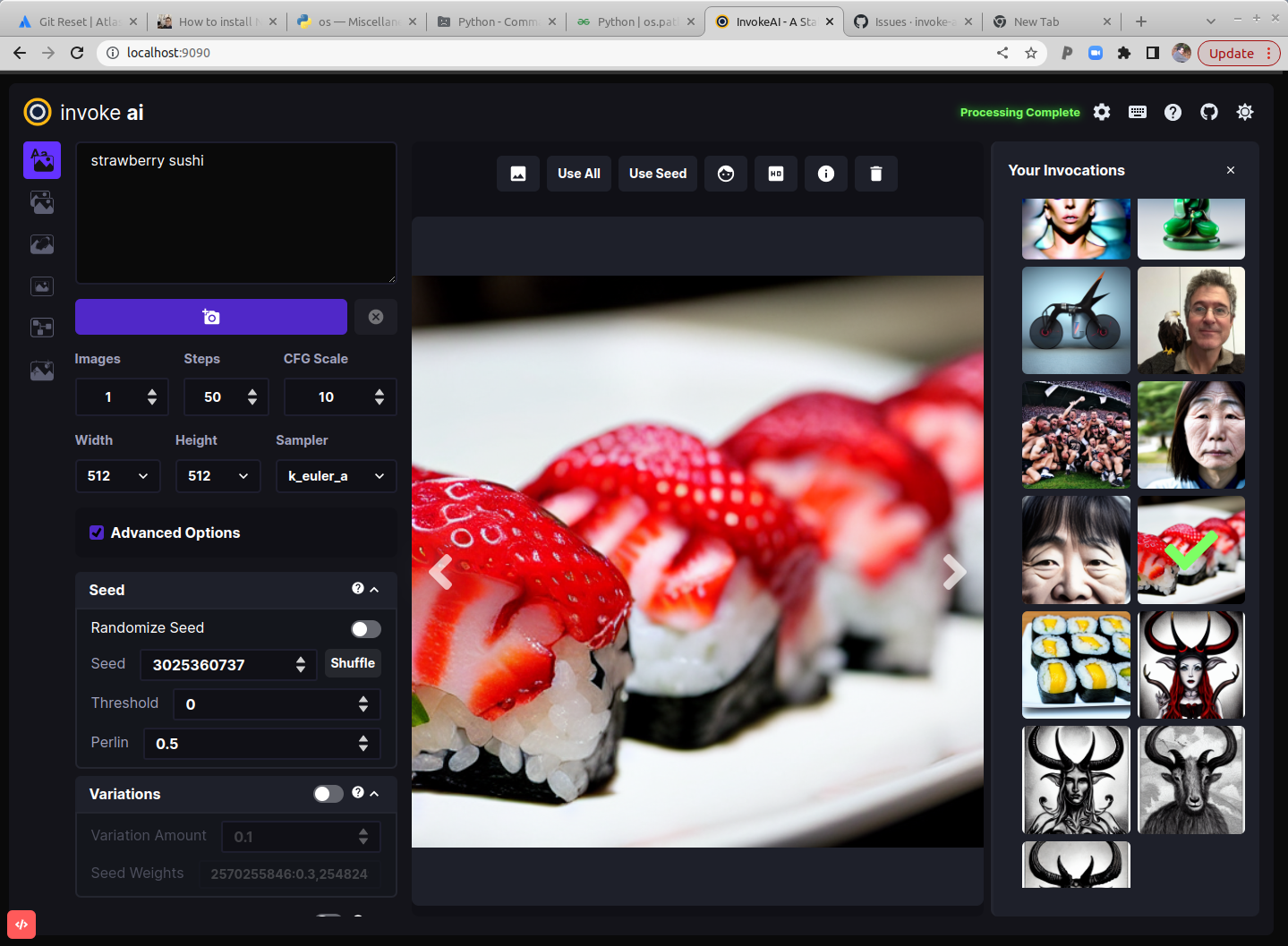
Basics
Generate an image by typing strawberry sushi into the large prompt field
on the upper left and then clicking on the Invoke button (the one with the
Camera icon). After a short wait, you'll see a large image of sushi in the
image panel, and a new thumbnail in the gallery on the right.
If you need more room on the screen, you can turn the gallery off by
clicking on the x to the right of "Your Invocations". You can turn it
back on later by clicking the image icon that appears in the gallery's
place.
The images are written into the directory indicated by the --outdir option
provided at script launch time. By default, this is outputs/img-samples
under the InvokeAI directory.
Generate a bunch of strawberry sushi images by increasing the number of
requested images by adjusting the Images counter just below the Camera
button. As each is generated, it will be added to the gallery. You can
switch the active image by clicking on the gallery thumbnails.
Try playing with different settings, including image width and height, the
Sampler, the Steps and the CFG scale.
Image Width and Height do what you'd expect. However, be aware that
larger images consume more VRAM memory and take longer to generate.
The Sampler controls how the AI selects the image to display. Some
samplers are more "creative" than others and will produce a wider range of
variations (see next section). Some samplers run faster than others.
Steps controls how many noising/denoising/sampling steps the AI will take.
The higher this value, the more refined the image will be, but the longer
the image will take to generate. A typical strategy is to generate images
with a low number of steps in order to select one to work on further, and
then regenerate it using a higher number of steps.
The CFG Scale controls how hard the AI tries to match the generated image
to the input prompt. You can go as high or low as you like, but generally
values greater than 20 won't improve things much, and values lower than 5
will produce unexpected images. There are complex interactions between
Steps, CFG Scale and the Sampler, so experiment to find out what works
for you.
To regenerate a previously-generated image, select the image you want and
click Use All. This loads the text prompt and other original settings into
the control panel. If you then press Invoke it will regenerate the image
exactly. You can also selectively modify the prompt or other settings to
tweak the image.
Alternatively, you may click on Use Seed to load just the image's seed,
and leave other settings unchanged.
To regenerate a Stable Diffusion image that was generated by another SD
package, you need to know its text prompt and its Seed. Copy-paste the
prompt into the prompt box, unset the Randomize Seed control in the
control panel, and copy-paste the desired Seed into its text field. When
you Invoke, you will get something similar to the original image. It will
not be exact unless you also set the correct values for the original
sampler, CFG, steps and dimensions, but it will (usually) be close.
Variations on a theme
Let's try generating some variations. Select your favorite sushi image from
the gallery to load it. Then select "Use All" from the list of buttons
above. This will load up all the settings used to generate this image,
including its unique seed.
Go down to the Variations section of the Control Panel and set the button to
On. Set Variation Amount to 0.2 to generate a modest number of variations on
the image, and also set the Image counter to 4. Press the invoke button.
This will generate a series of related images. To obtain smaller variations,
just lower the Variation Amount. You may also experiment with changing the
Sampler. Some samplers generate more variability than others. k_euler_a is
particularly creative, while ddim is pretty conservative.
For even more variations, experiment with increasing the setting for
Perlin. This adds a bit of noise to the image generation process. Note
that values of Perlin noise greater than 0.15 produce poor images for
several of the samplers.
Facial reconstruction and upscaling
Stable Diffusion frequently produces mangled faces, particularly when there are
multiple figures in the same scene. Stable Diffusion has particular issues with
generating reallistic eyes. InvokeAI provides the ability to reconstruct faces
using either the GFPGAN or CodeFormer libraries. For more information see
POSTPROCESS.
Invoke a prompt that generates a mangled face. A prompt that often gives
this is "portrait of a lawyer, 3/4 shot" (this is not intended as a slur
against lawyers!) Once you have an image that needs some touching up, load
it into the Image panel, and press the button with the face icon
(highlighted in the first screenshot below). A dialog box will appear. Leave
Strength at 0.8 and press *Restore Faces". If all goes well, the eyes and
other aspects of the face will be improved (see the second screenshot)
The facial reconstruction Strength field adjusts how aggressively the face
library will try to alter the face. It can be as high as 1.0, but be aware
that this often softens the face airbrush style, losing some details. The
default 0.8 is usually sufficient.
"Upscaling" is the process of increasing the size of an image while
retaining the sharpness. InvokeAI uses an external library called "ESRGAN"
to do this. To invoke upscaling, simply select an image and press the HD
button above it. You can select between 2X and 4X upscaling, and adjust the
upscaling strength, which has much the same meaning as in facial
reconstruction. Try running this on one of your previously-generated images.
Finally, you can run facial reconstruction and/or upscaling automatically
after each Invocation. Go to the Advanced Options section of the Control
Panel and turn on Restore Face and/or Upscale.
Image to Image
InvokeAI lets you take an existing image and use it as the basis for a new
creation. You can use any sort of image, including a photograph, a scanned
sketch, or a digital drawing, as long as it is in PNG or JPEG format.
Click on the Image to Image tab icon, which is the second icon from the
top on the left-hand side of the screen:

This will bring you to a screen similar to the one shown here:
{:width="640px"}
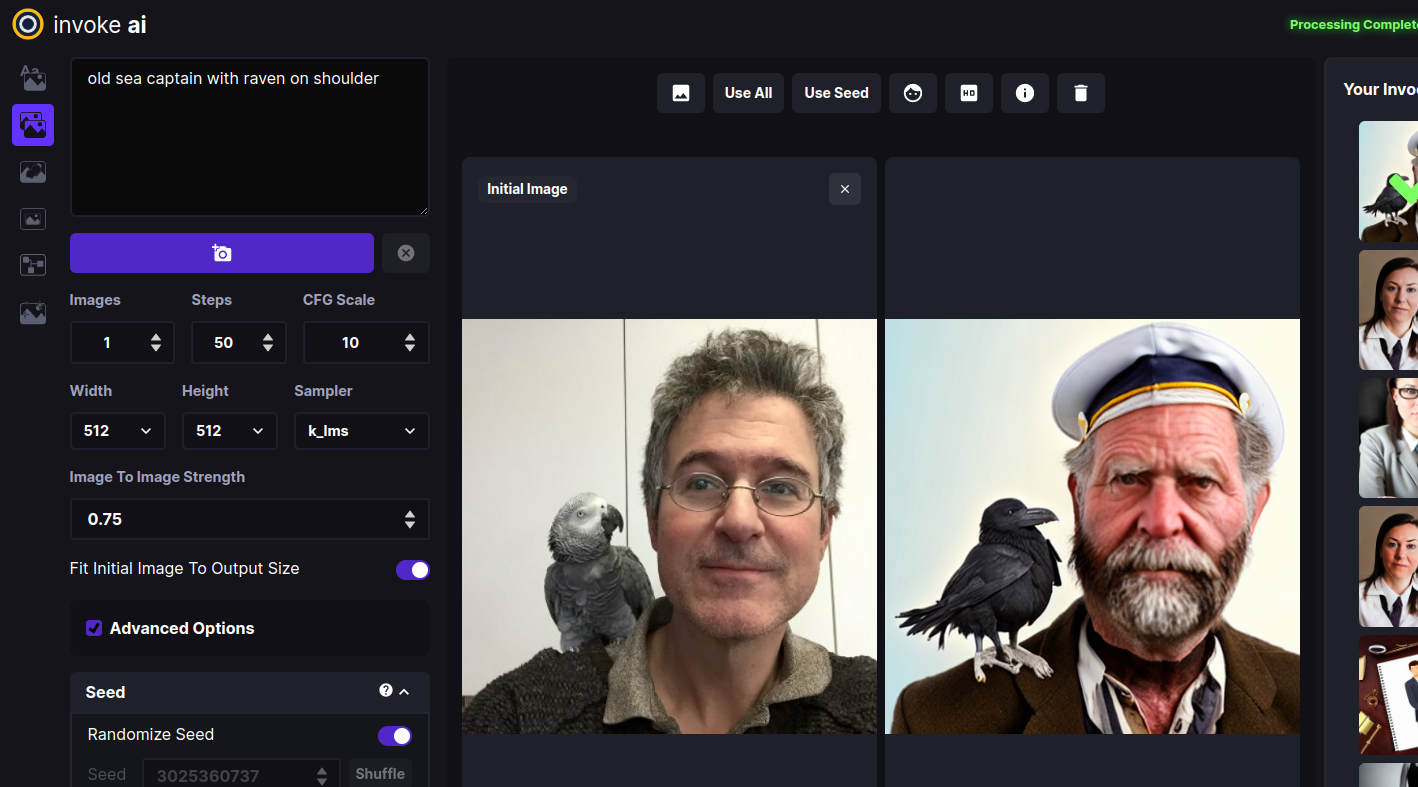
Drag-and-drop the Lincoln-and-Parrot image into the Image panel, or click
the blank area to get an upload dialog. The image will load into an area
marked Initial Image. (The WebGUI will also load the most
recently-generated image from the gallery into a section on the left, but
this image will be replaced in the next step.)
Go to the prompt box and type old sea captain with raven on shoulder and
press Invoke. A derived image will appear to the right of the original one:
{:width="640px"}
Experiment with the different settings. The most influential one in Image to
Image is Image to Image Strength located about midway down the control
panel. By default it is set to 0.75, but can range from 0.0 to 0.99. The
higher the value, the more of the original image the AI will replace. A
value of 0 will leave the initial image completely unchanged, while 0.99
will replace it completely. However, the Sampler and CFG Scale also
influence the final result. You can also generate variations in the same way
as described in Text to Image.
What if we only want to change certain part(s) of the image and leave the
rest intact? This is called Inpainting, and a future version of the InvokeAI
web server will provide an interactive painting canvas on which you can
directly draw the areas you wish to Inpaint into. For now, you can achieve
this effect by using an external photoeditor tool to make one or more
regions of the image transparent as described in [INPAINTING.md] and
uploading that.
The file
Lincoln-and-Parrot-512-transparent.png
is a version of the earlier image in which the area around the parrot has
been replaced with transparency. Click on the "x" in the upper right of the
Initial Image and upload the transparent version. Using the same prompt "old
sea captain with raven on shoulder" try Invoking an image. This time, only
the parrot will be replaced, leaving the rest of the original image intact:
{:width="640px"}
Would you like to modify a previously-generated image using the Image to
Image facility? Easy! While in the Image to Image panel, hover over any of
the gallery images to see a little menu of icons pop up. Click the picture
icon to instantly send the selected image to Image to Image as the initial
image.
You can do the same from the Text to Image tab by clicking on the picture icon
above the central image panel. The screenshot below shows where the "use as
initial image" icons are located.
{:width="640px"}
Parting remarks
This concludes the walkthrough, but there are several more features that you can
explore. Please check out the Command Line Interface documentation for
further explanation of the advanced features that were not covered here.
The WebGUI is only rapid development. Check back regularly for updates!
Reference
Additional Options
parameter
effect
--web_develop
Starts the web server in development mode.
--web_verbose
Enables verbose logging
--cors [CORS ...]
Additional allowed origins, comma-separated
--host HOST
Web server: Host or IP to listen on. Set to 0.0.0.0 to accept traffic from other devices on your network.
--port PORT
Web server: Port to listen on
--certfile CERTFILE
Web server: Path to certificate file to use for SSL. Use together with --keyfile
--keyfile KEYFILE
Web server: Path to private key file to use for SSL. Use together with --certfile'
--gui
Start InvokeAI GUI - This is the "desktop mode" version of the web app. It uses Flask to create a desktop app experience of the webserver.
Web Specific Features
The web experience offers an incredibly easy-to-use experience for interacting
with the InvokeAI toolkit. For detailed guidance on individual features, see the
Feature-specific help documents available in this directory. Note that the
latest functionality available in the CLI may not always be available in the Web
interface.
Dark Mode & Light Mode
The InvokeAI interface is available in a nano-carbon black & purple Dark Mode,
and a "burn your eyes out Nosferatu" Light Mode. These can be toggled by
clicking the Sun/Moon icons at the top right of the interface.
Invocation Toolbar
The left side of the InvokeAI interface is available for customizing the prompt
and the settings used for invoking your new image. Typing your prompt into the
open text field and clicking the Invoke button will produce the image based on
the settings configured in the toolbar.
See below for additional documentation related to each feature:
The currently selected --outdir (or the default outputs folder) will display all
previously generated files on load. As new invocations are generated, these will
be dynamically added to the gallery, and can be previewed by selecting them.
Each image also has a simple set of actions (e.g., Delete, Use Seed, Use All
Parameters, etc.) that can be accessed by hovering over the image.
Image Workspace
When an image from the Invocation Gallery is selected, or is generated, the
image will be displayed within the center of the interface. A quickbar of common
image interactions are displayed along the top of the image, including:
 {:width="640px"}
{:width="640px"}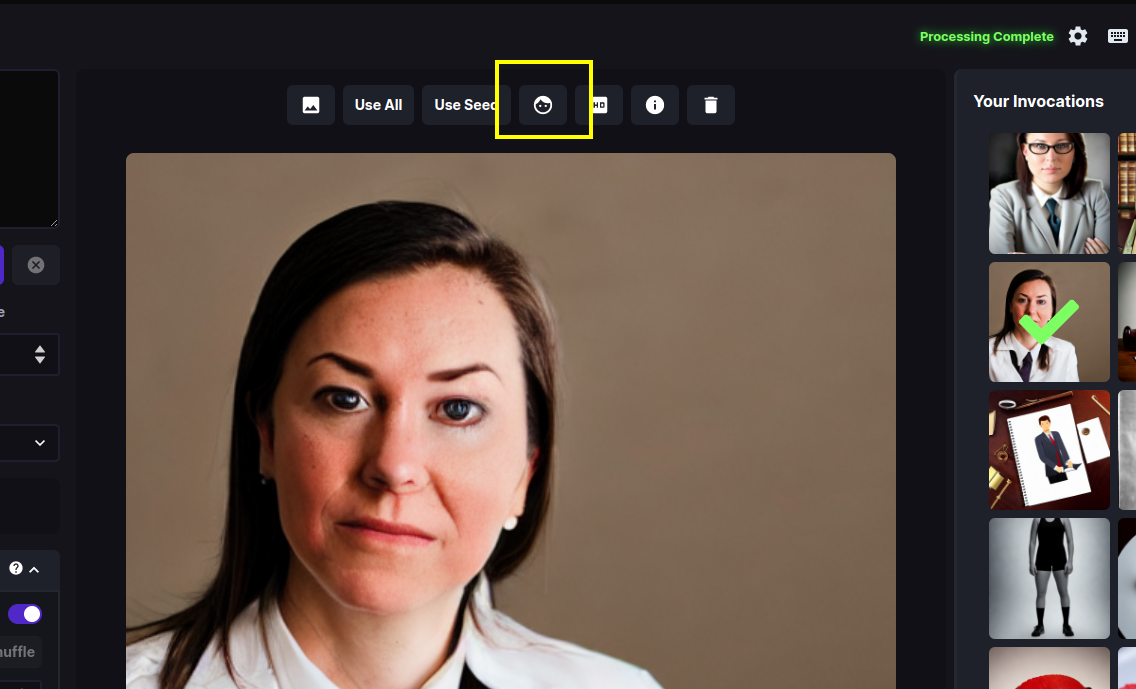
{kind=link}
{kind=link}
 {:width="640px"}
{:width="640px"} {:width="640px"}
{:width="640px"}