17 KiB
Gravity Sync
Advanced Configuration
The purpose of this guide is to break out the manual install instructions, and any advanced configuration flags, into a seperate document to limit confusion from the primary README. It is expected that users have read and are familiar with the process and concepts outlined in the primary README.
Prerequisites
- If you're installing Gravity Sync on a system running Fedora or CentOS, make sure that you are not just using the built in root account and have a dedicated user in the Administrator group. You'll also need SELinux disabled to install Pi-hole.
Installation
If you don't trust git to install your software, or just like doing things by hand, that's fine.
Keep in mind that installing via this method means you won't be able to use Gravity Sync's built-in update mechanism.
Download the latest release from GitHub and extract the files to your secondary Pi-hole server.
cd ~
wget https://github.com/vmstan/gravity-sync/archive/v2.1.6.zip
unzip v2.1.6.zip -d gravity-sync
cd gravity-sync
Please note the script must be run from a folder in your user home directory (ex: /home/USER/gravity-sync) -- I wouldn't suggest deviating from the gravity-sync folder name. If you do you'll need to also change the configuration settings defined in the gravity-sync.sh script, which can be a little tedious to do everytime you upgrade the script.
Configuration
After you install Gravity Sync to your server there will be a file called gravity-sync.conf.example that you can use as the basis for your own gravity-sync.conf file. Make a copy of the example file and modify it with your site specific settings.
cp gravity-sync.conf.example gravity-sync.conf
vi gravity-sync.conf
Note: If you don't like VI or don't have VIM on your system, use NANO, or if you don't like any of those subsitute for your text editor of choice. I'm not here to start a war.
Make sure you've set the REMOTE_HOST and REMOTE_USER variables with the IP (or DNS name) and user account to authenticate to the primary Pi. This account will need to have sudo permissions on the remote system.
REMOTE_HOST='192.168.1.10'
REMOTE_USER='pi'
Do not set the REMOTE_PASS variable until you've read the next section on SSH.
SSH Configuration
Gravity Sync uses SSH to run commands on the primary Pi-hole, and sync the two systems by performing file copies. There are two methods available for authenticating with SSH.
Key-Pair Authentication
This is the preferred option, as it's more reliable and less dependant on third party plugins.
You'll need to generate an SSH key for your secondary Pi-hole user and copy it to your primary Pi-hole. This will allow you to connect to and copy the necessary files without needing a password each time. When generating the SSH key, accept all the defaults and do not put a passphrase on your key file.
Note: If you already have this setup on your systems for other purposes, you can skip this step.
ssh-keygen -t rsa
ssh-copy-id -i ~/.ssh/id_rsa.pub REMOTE_USER@REMOTE_HOST
Subsitute REMOTE_USER for the account on the primary Pi-hole with sudo permissions, and REMOTE_HOST for the IP or DNS name of the Pi-hole you have designated as the primary.
Make sure to leave the REMOTE_PASS variable set to nothing in gravity-sync.conf if you want to use key-pair authentication.
Password Authentication
This is the non-preferred option, as it depends on an non-standard utility called sshpass which must be installed on your secondary Pi-hole. Install it using your package manager of choice. The example below is for Raspberry Pi OS (previously Raspbian) or Ubuntu.
sudo apt install sshpass
Then enter your password in the gravity-sync.conf file you configured above.
REMOTE_PASS='password'
Gravity Sync will validate that the sshpass utility is installed on your system and failback to attempting key-pair authentication if it's not detected.
Save. Keep calm, carry on.
The Pull Function
The Gravity Sync Pull, prior to version 2.0, was the standard method of sync operation, and will not prompt for user input after execution.
./gravity-sync.sh pull
If the execution completes, you will now have overwritten your running gravity.db and custom.list on the secondary Pi-hole after creating a copy of the running files (with .backup appended) in the backup subfolder located with your script. Gravity Sync will also keep a copy of the last sync'd files from the primary (in the backup folder appended with .pull) for future use.
The Push Function
Gravity Sync includes the ability to push from the secondary Pi-hole back to the primary. This would be useful in a situation where your primary Pi-hole is down for an extended period of time, and you have made list changes on the secondary Pi-hole that you want to force back to the primary, when it comes online.
./gravity-sync.sh push
Before executing, this will make a copy of the remote database under backup/gravity.db.push and backup/custom.list.push then sync the local configuration to the primary Pi-hole.
This function purposefuly asks for user interaction to avoid being accidentally automated.
- If your script prompts for a password on the remote system, make sure that your remote user account is setup not to require passwords in the sudoers file.
The Restore Function
Gravity Sync can also restore the database on the secondary Pi-hole in the event you've overwritten it accidentally. This might happen in the above scenario where you've had your primary Pi-hole down for an extended period, made changes to the secondary, but perhaps didn't get a chance to perform a push of the changes back to the primary, before your automated sync ran.
./gravity-sync.sh restore
This will copy your last gravity.db.backup and custom.list.backup to the running copy on the secondary Pi-hole.
This function purposefuly asks for user interaction to avoid being accidentally automated.
Hidden Figures
There are a series of advanced configuration options that you may need to change to better adapt Gravity Sync to your environment. They are referenced at the end of the gravity-sync.conf file. It is suggested that you make any necessary variable changes to this file, as they will superceed the ones located in the core script. If you want to revert back to the Gravity Sync default for any of these settings, just apply a # to the beginning of the line to comment it out.
SSH_PORT=''
Gravity Sync is configured by default to use the standard SSH port (22) but if you need to change this, such as if you're traversing a NAT/firewall for a multi-site deployment, to use a non-standard port.
Default setting in Gravity Sync is 22.
SSH_PKIF=''
Gravity Sync is configured by default to use the .ssh/id_rsa keyfile that is generated using the ssh-keygen command. If you have an existing keyfile stored somewhere else that you'd like to use, you can configure that here. The keyfile will still need to be in the users $HOME directory.
At this time Gravity Sync does not support passphrases in RSA keyfiles. If you have a passphrase applied to your standard .ssh/id_rsa either remove it, or generate a new file and specify that key for use only by Gravity Sync.
Default setting in Gravity Sync is .ssh/id_rsa
LOG_PATH=''
Gravity Sync will place logs in the same folder as the script (identified as .cron and .log) but if you'd like to place these in a another location, you can do that by identifying the full path to the directory. (ex: /full/path/to/logs)
Default setting in Gravity Sync is $HOME/${LOCAL_FOLDR}
SYNCING_LOG=''
Gravity Sync will write a timestamp for any completed sync, pull, push or restore job to this file. If you want to change the name of this file, you will also need to adjust the LOG_PATH variable above, otherwise your file will be remove during an update operations.
Default setting in Gravity Sync is gravity-sync.log
CRONJOB_LOG=''
Gravity Sync will log the execution history of the previous automation task via Cron to this file. If you want to change the name of this file, you will also need to adjust the LOG_PATH variable above, otherwise your file will be remove during an update operations.
This will have an impact to both the ./gravity-sync.sh automate function and the ./gravity-sync.sh cron functions. If you need to change this after running the automate function, either modify your crontab manually or delete the entry and re-run the automate function.
Default setting in Gravity Sync is gravity-sync.cron
HISTORY_MD5=''
Gravity Sync will log the file hashes of the previous smart task to this file. If you want to change the name of this file, you will also need to adjust the LOG_PATH variable above, otherwise your file will be removed during an update operations.
Default setting in Gravity Sync is gravity-sync.md5
VERIFY_PASS=''
Gravity Sync will prompt to verify user interactivity during push, restore, or config operations (that overwrite an existing configuration) with the intention that it prevents someone from accidentally automating in the wrong direction or overwriting data intentionally. If you'd like to automate a push function, or just don't like to be asked twice to do something distructive, then you can opt-out.
Default setting in Gravity Sync is 0, change to 1 to bypass this check.
SKIP_CUSTOM=''
Starting in v1.7.0, Gravity Sync manages the custom.list file that contains the "Local DNS Records" function within the Pi-hole interface. If you do not want to sync this setting, perhaps if you're doing a mutli-site deployment with differing local DNS settings, then you can opt-out of this sync.
Default setting in Gravity Sync is 0, change to 1 to exempt custom.list from replication.
DATE_OUTPUT=''
This feature has not been fully implemented, but the intent is to provide the ability to add timestamped output to each status indicator in the script output (ex: [2020-05-28 19:46:54] [EXEC] $MESSAGE).
Default setting in Gravity Sync is 0, change to 1 to print timestamped output.
BASH_PATH=''
If you need to adjust the path to bash that is identified for automated execution via Crontab, you can do that here. This will only have an impact if changed before generating the crontab via the ./gravity-sync.sh automate function. If you need to change this after the fact, either modify your crontab manually or delete the entry and re-run the automate function.
PING_AVOID=''
The ./gravity-sync.sh config function will attempt to ping the remote host to validate it has a valid network connection. If there is a firewall between your hosts preventing ping replies, or you otherwise wish to skip this step, it can by bypassed here.
Default setting in Gravity Sync is 0, change to 1 to skip this network test.
BACKUP_RETAIN=''
The ./gravity-sync.sh backup function will retain a defined number of days worth of gravity.db and custom.list backups.
Default setting in Gravity Sync is 7, adjust as resired.
Execution
If you are just straight up unable to run the gravity-sync.sh file, make sure it's marked as an executable by Linux.
chmod +x gravity-sync.sh
Updates
If you manually installed Gravity Sync via .zip or .tar.gz you will need to download and overwrite the gravity-sync.sh file with a newer version. If you've chosen this path, I won't lay out exactly what you'll need to do every time, but you should at least review the contents of the script bundle (specifically the example configuration file) to make sure there are no new additional files or required settings.
At the very least, I would reccomend backing up your existing gravity-sync folder and then deploying a fresh copy each time you update, and then either creating a new .conf file or copying your old file over to the new folder.
Development Builds
Starting in v1.7.2, you can easily flag if you want to receive the development branch of Gravity Sync when running the built in ./gravity-sync.sh update function. Beginning in v1.7.4 ./gravity-sync.sh dev will now toggle the dev flag on/off. No touch required, although it still works that way under the covers.
To manually adjust the flag, create an empty file in the gravity-sync folder called dev and afterwards the standard ./gravity-sync.sh update function will apply the correct updates.
cd gravity-sync
touch dev
./gravity-sync.sh update
Delete the dev file and update again to revert back to the stable/master branch.
This method for implementation is decidedly different than the configuration flags in the .conf file, as explained above, to make it easier to identify development systems.
Updater Troubleshooting
If the built in updater doesn't function as expected, you can manually run the git commands that operate under the covers.
git fetch --all
git reset --hard origin/master
Use origin/development to pull that branch instead.
If your code is still not updating after this, reinstallation is suggested rather than spending all your time troubleshooting git commands.
Automation
There are many automation methods available to run scripts on a regular basis of a Linux system. The one built into all of them is cron, but if you'd like to utilize something different then the principles are still the same.
If you prefer to still use cron but modify your settings by hand, using the entry below will cause the entry to run at the top and bottom of every hour (1:00 PM, 1:30 PM, 2:00 PM, etc) but you are free to dial this back or be more agressive if you feel the need.
crontab -e
*/30 * * * * /bin/bash /home/USER/gravity-sync/gravity-sync.sh > /home/USER/gravity-sync/gravity-sync.cron
Reference Architectures
The designation of primary and secondary is purely at your discretion. The doesn't matter if you're using an HA process like keepalived to present a single DNS IP address to clients, or handing out two DNS resolvers via DHCP. Generally it is expected that the two (or more) Pi-hole(s) will be at the same phyiscal location, or at least on the same internal networks. It should also be possible to to replicate to a secondary Pi-hole across networks, either over a VPN or open-Internet, with the approprate firewall/NAT configuration.
There are three reference architectures that I'll outline. All of them require an external DHCP server (such as a router, or dedicated DHCP server) handing out the DNS address(es) for your Pi-holes. Use of the integrated DHCP function in Pi-hole when using Gravity Sync is discouraged, although I'm sure there are ways to make it work. Gravity Sync does not manage any DHCP settings.
Easy Peasy
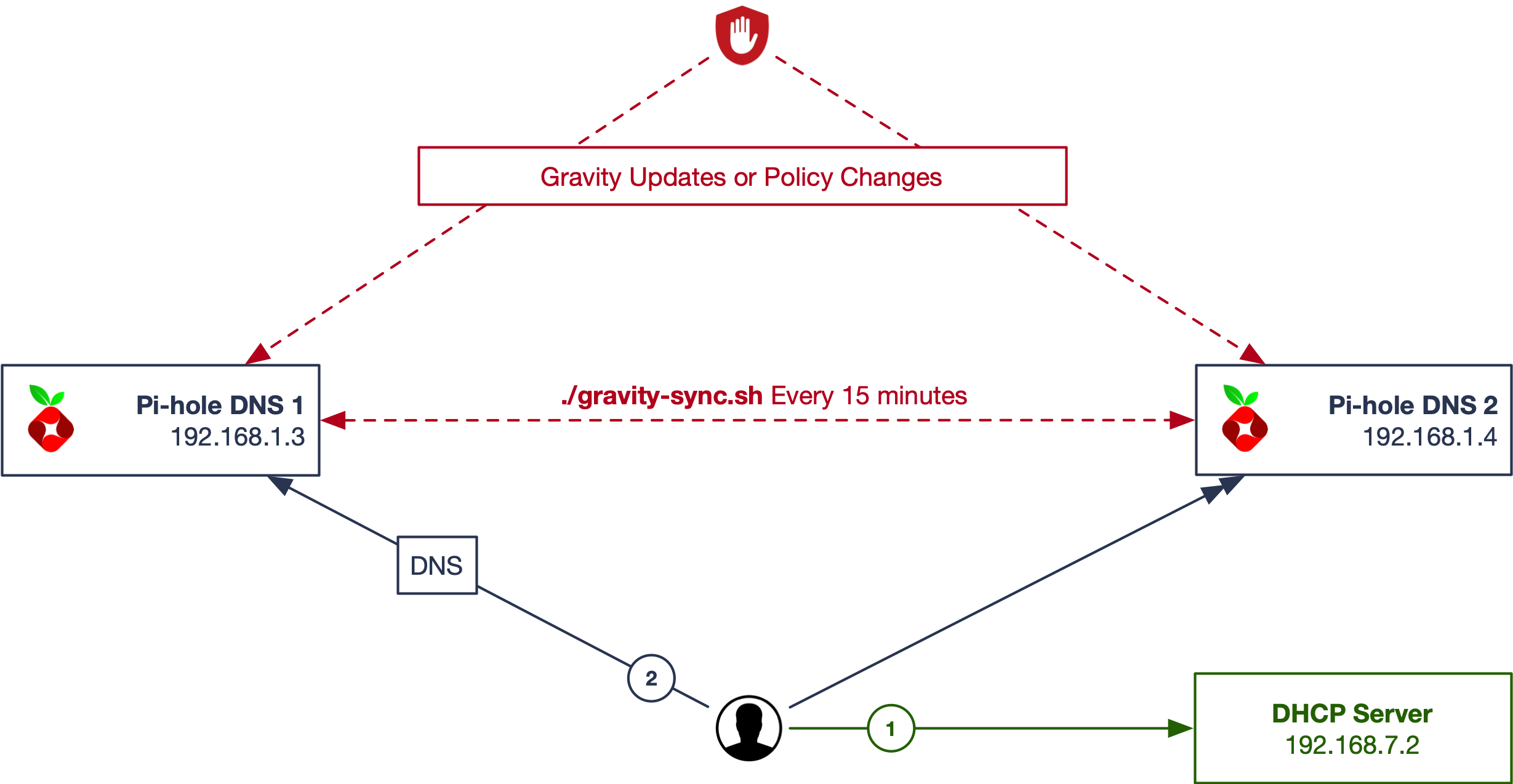
This design requires the least amount of overhead, or additional software/network configuration beyond Pi-hole and Gravity Sync.
- Client requests an IP address from a DHCP server on the network and receives it along with DNS and gateway information back. Two DNS servers (Pi-hole) are returned to the client.
- Client queries one of the two DNS servers, and Pi-hole does it's thing.
You can make changes to your blocklist, exceptions, etc, on either Pi-hole and they will be sync'd to the other within the timeframe you establish (here, 15 minutes.) The downside in the above design is you have two places where your clients are logging lookup requests to. Gravity Sync will let you change filter settings in either location, but if you're doing it often things may get overwritten.
Stay Alive
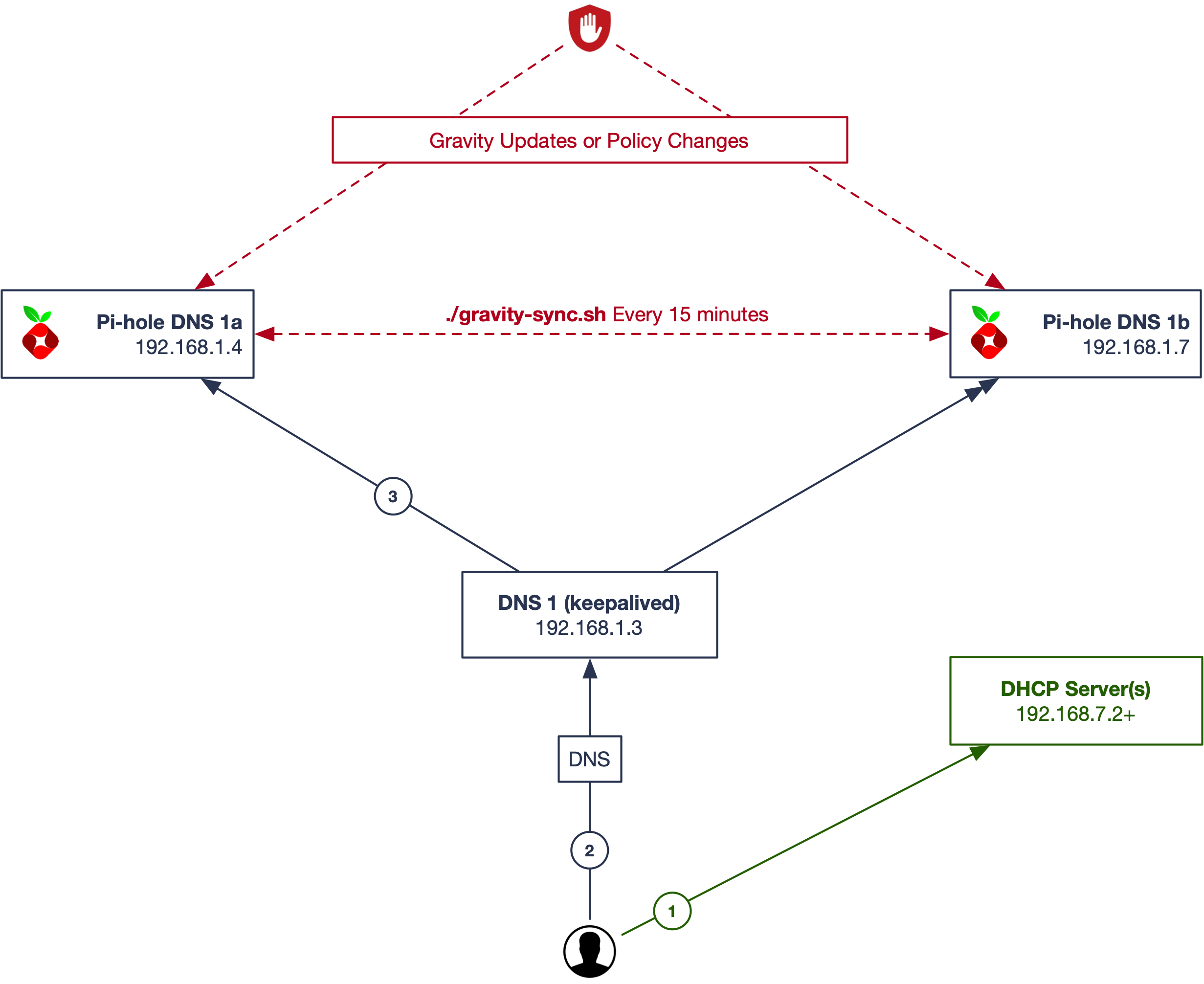
One way to get around having logging in two places is by using keepalived and present a single virtual IP address of the two Pi-hole, to clients in an active/passive mode. The two nodes will check their own status, and each other, and hand the VIP around if there are issues.
- Client requests an IP address from a DHCP server on the network and receives it along with DNS and gateway information back. One DNS server (VIP) is returned to the client.
- The VIP managed by the keepalived service will determine which Pi-hole responds. You make your configuration changes to the active VIP address.
- Client queries the single DNS servers, and Pi-hole does it's thing.
You make your configuration changes to the active VIP address and they will be sync'd to the other within the timeframe you establish (here, 15 minutes.)
Crazy Town
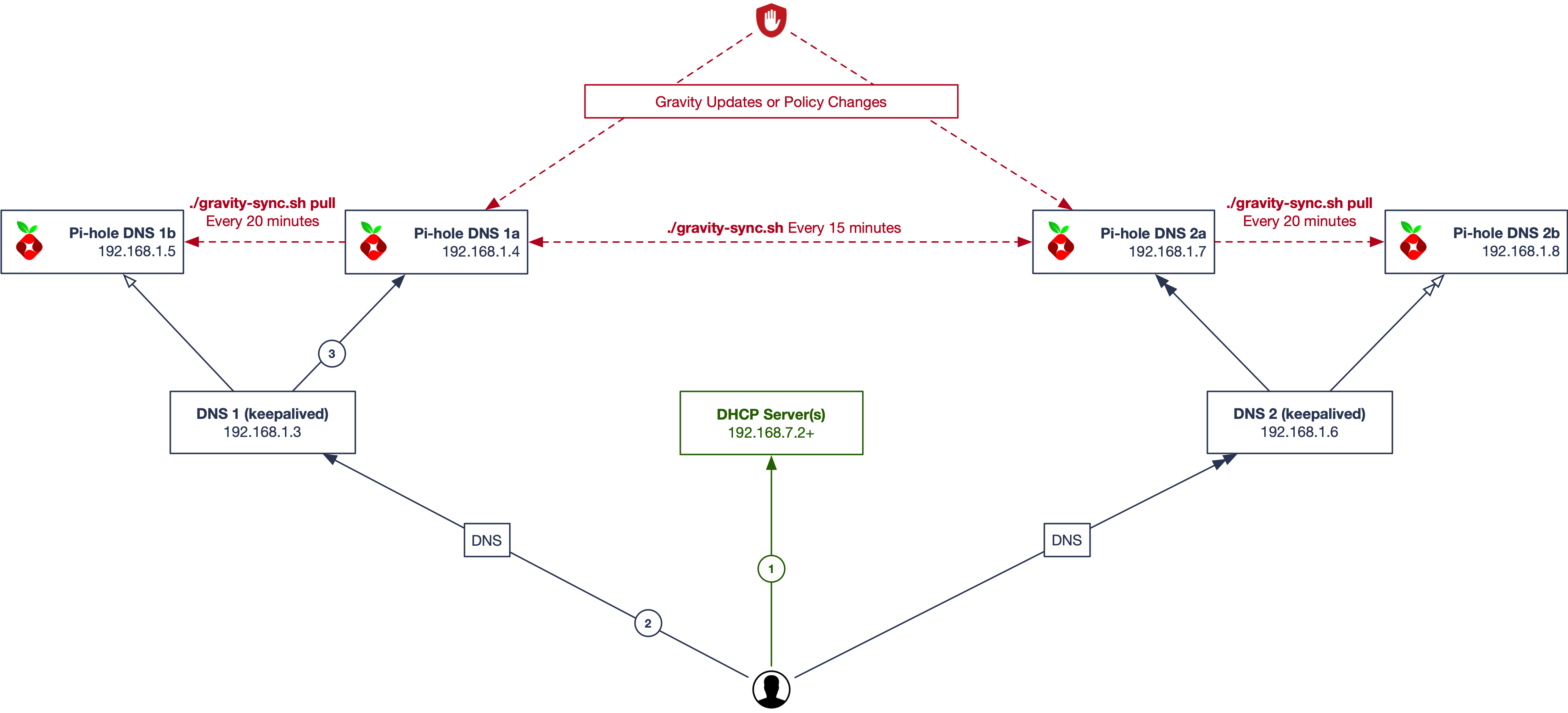
For those who really love Pi-hole and Gravity Sync. Combining the best of both worlds.
- Client requests an IP address from a DHCP server on the network and receives it along with DNS and gateway information back. Two DNS servers (VIPs) are returned to the client.
- The VIPs are managed by the keepalived service on each side and will determine which of two Pi-hole responds. You can make your configuration changes to the active VIP address on either side.
- Client queries one of the two VIP servers, and the responding Pi-hole does it's thing.
Here we use ./gravity-sync pull on the secondary Pi-hole at each side, and off-set the update intervals from the main sync.
(I call this crazy, but this is what I use at home.)