In some cases the command-line was getting parsed before the logger was
initialized, causing the logger not to pick up custom logging
instructions from `--log_handlers`. This PR fixes the issue.
[fix(ui): blur tab on
click](93f3658a4a)
Fixes issue where after clicking a tab, using the arrow keys changes tab
instead of changing selected image
[fix(ui): fix canvas not filling screen on first
load](68be95acbb)
[feat(ui): remove clear temp folder canvas
button](813f79f0f9)
This button is nonfunctional.
Soon we will introduce a different way to handle clearing out
intermediate images (likely automated).
There was an issue where for graphs w/ iterations, your images were output all at once, at the very end of processing. So if you canceled halfway through an execution of 10 nodes, you wouldn't get any images - even though you'd completed 5 images' worth of inference.
## Cause
Because graphs executed breadth-first (i.e. depth-by-depth), leaf nodes were necessarily processed last. For image generation graphs, your `LatentsToImage` will be leaf nodes, and be the last depth to be executed.
For example, a `TextToLatents` graph w/ 3 iterations would execute all 3 `TextToLatents` nodes fully before moving to the next depth, where the `LatentsToImage` nodes produce output images, resulting in a node execution order like this:
1. TextToLatents
2. TextToLatents
3. TextToLatents
4. LatentsToImage
5. LatentsToImage
6. LatentsToImage
## Solution
This PR makes a two changes to graph execution to execute as deeply as it can along each branch of the graph.
### Eager node preparation
We now prepare as many nodes as possible, instead of just a single node at a time.
We also need to change the conditions in which nodes are prepared. Previously, nodes were prepared only when all of their direct ancestors were executed.
The updated logic prepares nodes that:
- are *not* `Iterate` nodes whose inputs have *not* been executed
- do *not* have any unexecuted `Iterate` ancestor nodes
This results in graphs always being maximally prepared.
### Always execute the deepest prepared node
We now choose the next node to execute by traversing from the bottom of the graph instead of the top, choosing the first node whose inputs are all executed.
This means we always execute the deepest node possible.
## Result
Graphs now execute depth-first, so instead of an execution order like this:
1. TextToLatents
2. TextToLatents
3. TextToLatents
4. LatentsToImage
5. LatentsToImage
6. LatentsToImage
... we get an execution order like this:
1. TextToLatents
2. LatentsToImage
3. TextToLatents
4. LatentsToImage
5. TextToLatents
6. LatentsToImage
Immediately after inference, the image is decoded and sent to the gallery.
fixes#3400
This PR creates the databases directory at app startup time. It also
removes a couple of debugging statements that were inadvertently left in
the model manager.
# Make InvokeAI package installable by mere mortals
This commit makes InvokeAI 3.0 to be installable via PyPi.org and/or the
installer script. The install process is now pretty much identical to
the 2.3 process, including creating launcher scripts `invoke.sh` and
`invoke.bat`.
Main changes:
1. Moved static web pages into `invokeai/frontend/web` and modified the
API to look for them there. This allows pip to copy the files into the
distribution directory so that user no longer has to be in repo root to
launch, and enables PyPi installations with `pip install invokeai`
2. Update invoke.sh and invoke.bat to launch the new web application
properly. This also changes the wording for launching the CLI from
"generate images" to "explore the InvokeAI node system," since I would
not recommend using the CLI to generate images routinely.
3. Fix a bug in the checkpoint converter script that was identified
during testing.
4. Better error reporting when checkpoint converter fails.
5. Rebuild front end.
# Major improvements to the model installer.
1. The text user interface for `invokeai-model-install` has been
expanded to allow the user to install controlnet, LoRA, textual
inversion, diffusers and checkpoint models. The user can install
interactively (without leaving the TUI), or in batch mode after exiting
the application.
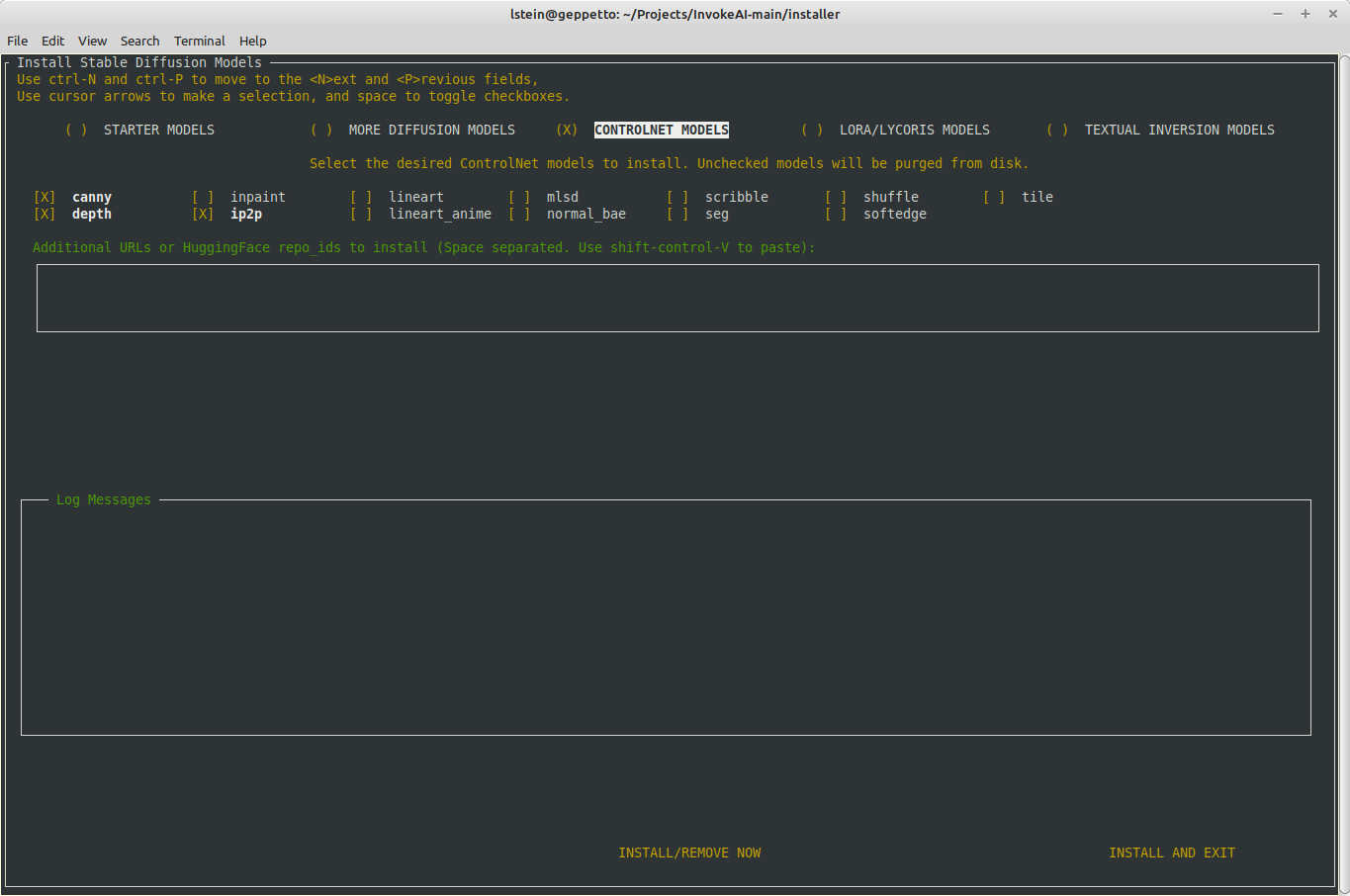
2. The `invokeai-model-install` command now lets you list, add and
delete models from the command line:
## Listing models
```
$ invokeai-model-install --list diffusers
Diffuser models:
analog-diffusion-1.0 not loaded diffusers An SD-1.5 model trained on diverse analog photographs (2.13 GB)
d&d-diffusion-1.0 not loaded diffusers Dungeons & Dragons characters (2.13 GB)
deliberate-1.0 not loaded diffusers Versatile model that produces detailed images up to 768px (4.27 GB)
DreamShaper not loaded diffusers Imported diffusers model DreamShaper
sd-inpainting-1.5 not loaded diffusers RunwayML SD 1.5 model optimized for inpainting, diffusers version (4.27 GB)
sd-inpainting-2.0 not loaded diffusers Stable Diffusion version 2.0 inpainting model (5.21 GB)
stable-diffusion-1.5 not loaded diffusers Stable Diffusion version 1.5 diffusers model (4.27 GB)
stable-diffusion-2.1 not loaded diffusers Stable Diffusion version 2.1 diffusers model, trained on 768 pixel images (5.21 GB)
```
```
$ invokeai-model-install --list tis
Loading Python libraries...
Installed Textual Inversion Embeddings:
EasyNegative
ahx-beta-453407d
```
## Installing models
(this example shows correct handling of a server side error at Civitai)
```
$ invokeai-model-install --diffusers https://civitai.com/api/download/models/46259 Linaqruf/anything-v3.0
Loading Python libraries...
[2023-06-05 22:17:23,556]::[InvokeAI]::INFO --> INSTALLING EXTERNAL MODELS
[2023-06-05 22:17:23,557]::[InvokeAI]::INFO --> Probing https://civitai.com/api/download/models/46259 for import
[2023-06-05 22:17:23,557]::[InvokeAI]::INFO --> https://civitai.com/api/download/models/46259 appears to be a URL
[2023-06-05 22:17:23,763]::[InvokeAI]::ERROR --> An error occurred during downloading /home/lstein/invokeai-test/models/ldm/stable-diffusion-v1/46259: Internal Server Error
[2023-06-05 22:17:23,763]::[InvokeAI]::ERROR --> ERROR DOWNLOADING https://civitai.com/api/download/models/46259: {"error":"Invalid database operation","cause":{"clientVersion":"4.12.0"}}
[2023-06-05 22:17:23,764]::[InvokeAI]::INFO --> Probing Linaqruf/anything-v3.0 for import
[2023-06-05 22:17:23,764]::[InvokeAI]::DEBUG --> Linaqruf/anything-v3.0 appears to be a HuggingFace diffusers repo_id
[2023-06-05 22:17:23,768]::[InvokeAI]::INFO --> Loading diffusers model from Linaqruf/anything-v3.0
[2023-06-05 22:17:23,769]::[InvokeAI]::DEBUG --> Using faster float16 precision
[2023-06-05 22:17:23,883]::[InvokeAI]::ERROR --> An unexpected error occurred while downloading the model: 404 Client Error. (Request ID: Root=1-647e9733-1b0ee3af67d6ac3456b1ebfc)
Revision Not Found for url: https://huggingface.co/Linaqruf/anything-v3.0/resolve/fp16/model_index.json.
Invalid rev id: fp16)
Downloading (…)ain/model_index.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 511/511 [00:00<00:00, 2.57MB/s]
Downloading (…)cial_tokens_map.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 472/472 [00:00<00:00, 6.13MB/s]
Downloading (…)cheduler_config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 341/341 [00:00<00:00, 3.30MB/s]
Downloading (…)okenizer_config.json: 100%|██████████████████████████████████████████████████████████████████████████████████████████████| 807/807 [00:00<00:00, 11.3MB/s]
```
## Deleting models
```
invokeai-model-install --delete --diffusers anything-v3
Loading Python libraries...
[2023-06-05 22:19:45,927]::[InvokeAI]::INFO --> Processing requested deletions
[2023-06-05 22:19:45,927]::[InvokeAI]::INFO --> anything-v3...
[2023-06-05 22:19:45,927]::[InvokeAI]::INFO --> Deleting the cached model directory for Linaqruf/anything-v3.0
[2023-06-05 22:19:45,948]::[InvokeAI]::WARNING --> Deletion of this model is expected to free 4.3G
```
1. Contents of autoscan directory field are restored after doing an installation.
2. Activate dialogue to choose V2 parameterization when importing from a directory.
3. Remove autoscan directory from init file when its checkbox is unselected.
4. Add widget cycling behavior to install models form.
The processor is automatically selected when model is changed.
But if the user manually changes the processor, processor settings, or disables the new `Auto configure processor` switch, auto processing is disabled.
The user can enable auto configure by turning the switch back on.
When auto configure is enabled, a small dot is overlaid on the expand button to remind the user that the system is not auto configuring the processor for them.
If auto configure is enabled, the processor settings are reset to the default for the selected model.