- Discord member @marcus.llewellyn reported that some civitai
2.1-derived checkpoints were not converting properly (probably
dreambooth-generated):
https://discord.com/channels/1020123559063990373/1078386197589655582/1078387806122025070
- @blessedcoolant tracked this down to a missing key that was used to
derive vector length of the CLIP model used by fetching the second
dimension of the tensor at "cond_stage_model.model.text_projection".
- On inspection, I found that the same second dimension can be recovered
from key 'cond_stage_model.model.ln_final.bias', and use that instead. I
hope this is correct; tested on multiple v1, v2 and inpainting models
and they converted correctly.
- While debugging this, I found and fixed several other issues:
- model download script was not pre-downloading the OpenCLIP
text_encoder or text_tokenizer. This is fixed.
- got rid of legacy code in `ckpt_to_diffuser.py` and replaced with
calls into `model_manager`
- more consistent status reporting in the CLI.
- Discord member @marcus.llewellyn reported that some civitai 2.1-derived checkpoints were
not converting properly (probably dreambooth-generated):
https://discord.com/channels/1020123559063990373/1078386197589655582/1078387806122025070
- @blessedcoolant tracked this down to a missing key that was used to
derive vector length of the CLIP model used by fetching the second
dimension of the tensor at "cond_stage_model.model.text_projection".
His proposed solution was to hardcode a value of 1024.
- On inspection, I found that the same second dimension can be
recovered from key 'cond_stage_model.model.ln_final.bias', and use
that instead. I hope this is correct; tested on multiple v1, v2 and
inpainting models and they converted correctly.
- While debugging this, I found and fixed several other issues:
- model download script was not pre-downloading the OpenCLIP
text_encoder or text_tokenizer. This is fixed.
- got rid of legacy code in `ckpt_to_diffuser.py` and replaced
with calls into `model_manager`
- more consistent status reporting in the CLI.
Root directory finding algorithm is:
2) use --root argument
2) use INVOKEAI_ROOT environment variable
3) use VIRTUAL_ENV environment variable
4) use ~/invokeai
Since developers are liable to put virtual environments in their
favorite places, not necessarily in the invokeai root directory, this PR
adds a sanity check that looks for the existence of
`VIRTUAL_ENV/invokeai.init`, and moves on to (4) if not found.
# This will constitute v2.3.1+rc2
## Windows installer enhancements
1. resize installer window to give more room for configure and download
forms
2. replace '\' with '/' in directory names to allow user to
drag-and-drop
folders into the dialogue boxes that accept directories.
3. similar change in CLI for the !import_model and !convert_model
commands
4. better error reporting when a model download fails due to network
errors
5. put the launcher scripts into a loop so that menu reappears after
invokeai, merge script, etc exits. User can quit with "Q".
6. do not try to download fp16 of sd-ft-mse-vae, since it doesn't exist.
7. cleaned up status reporting when installing models
8. Detect when install failed for some reason and print helpful error
message rather than stack trace.
9. Detect window size and resize to minimum acceptable values to provide
better display of configure and install forms.
10. Fix a bug in the CLI which prevented diffusers imported by their
repo_ids
from being correctly registered in the current session (though they
install
correctly)
11. Capitalize the "i" in Imported in the autogenerated descriptions.
Root directory finding algorithm is:
2) use --root argument
2) use INVOKEAI_ROOT environment variable
3) use VIRTUAL_ENV environment variable
4) use ~/invokeai
Since developer's are liable to put virtual environments in their
favorite places, not necessarily in the invokeai root directory, this
PR adds a sanity check that looks for the existence of
VIRTUAL_ENV/invokeai.init, and moves to (4) if not found.
- Fix a bug in the CLI which prevented diffusers imported by their repo_ids
from being correctly registered in the current session (though they install
correctly)
- Capitalize the "i" in Imported in the autogenerated descriptions.
1. resize installer window to give more room for configure and download forms
2. replace '\' with '/' in directory names to allow user to drag-and-drop
folders into the dialogue boxes that accept directories.
3. similar change in CLI for the !import_model and !convert_model commands
4. better error reporting when a model download fails due to network errors
5. put the launcher scripts into a loop so that menu reappears after
invokeai, merge script, etc exits. User can quit with "Q".
6. do not try to download fp16 of sd-ft-mse-vae, since it doesn't exist.
7. cleaned up status reporting when installing models
- Detect when install failed for some reason and print helpful error
message rather than stack trace.
- Detect window size and resize to minimum acceptable values to provide
better display of configure and install forms.
Currently translated at 81.4% (382 of 469 strings)
translationBot(ui): update translation (Russian)
Currently translated at 81.6% (382 of 468 strings)
Co-authored-by: Sergey Krashevich <svk@svk.su>
Translate-URL: https://hosted.weblate.org/projects/invokeai/web-ui/ru/
Translation: InvokeAI/Web UI
Currently translated at 100.0% (469 of 469 strings)
translationBot(ui): update translation (Italian)
Currently translated at 100.0% (468 of 468 strings)
Co-authored-by: Riccardo Giovanetti <riccardo.giovanetti@gmail.com>
Translate-URL: https://hosted.weblate.org/projects/invokeai/web-ui/it/
Translation: InvokeAI/Web UI
## Major Changes
The invokeai-configure script has now been refactored. The work of
selecting and downloading initial models at install time is now done by
a script named `invokeai-model-install` (module name is
`ldm.invoke.config.model_install`)
Screen 1 - adjust startup options:

Screen 2 - select SD models:
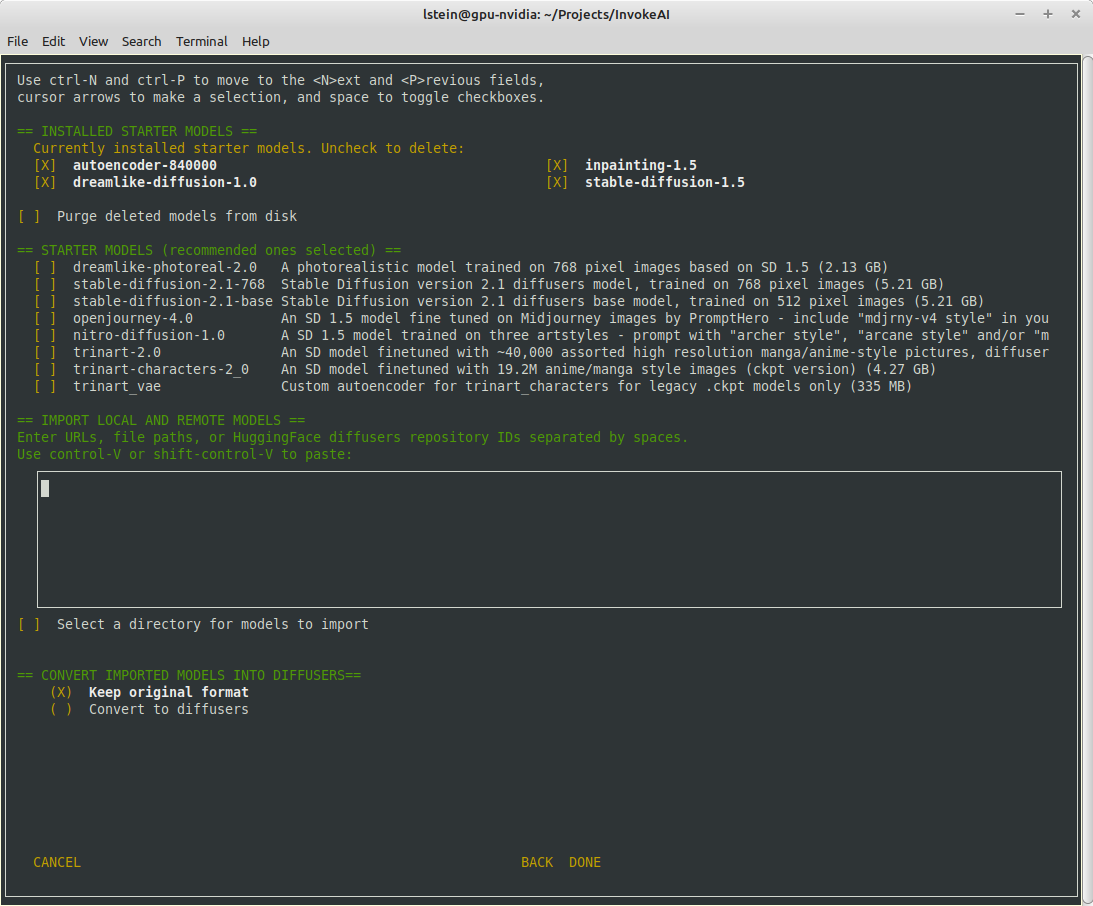
The calling arguments for `invokeai-configure` have not changed, so
nothing should break. After initializing the root directory, the script
calls `invokeai-model-install` to let the user select the starting
models to install.
`invokeai-model-install puts up a console GUI with checkboxes to
indicate which models to install. It respects the `--default_only` and
`--yes` arguments so that CI will continue to work. Here are the various
effects you can achieve:
`invokeai-configure`
This will use console-based UI to initialize invokeai.init,
download support models, and choose and download SD models
`invokeai-configure --yes`
Without activating the GUI, populate invokeai.init with default values,
download support models and download the "recommended" SD models
`invokeai-configure --default_only`
Activate the GUI for changing init options, but don't show the SD
download
form, and automatically download the default SD model (currently SD-1.5)
`invokeai-model-install`
Select and install models. This can be used to download arbitrary
models from the Internet, install HuggingFace models using their
repo_id,
or watch a directory for models to load at startup time
`invokeai-model-install --yes`
Import the recommended SD models without a GUI
`invokeai-model-install --default_only`
As above, but only import the default model
## Flexible Model Imports
The console GUI allows the user to import arbitrary models into InvokeAI
using:
1. A HuggingFace Repo_id
2. A URL (http/https/ftp) that points to a checkpoint or safetensors
file
3. A local path on disk pointing to a checkpoint/safetensors file or
diffusers directory
4. A directory to be scanned for all checkpoint/safetensors files to be
imported
The UI allows the user to specify multiple models to bulk import. The
user can specify whether to import the ckpt/safetensors as-is, or
convert to `diffusers`. The user can also designate a directory to be
scanned at startup time for checkpoint/safetensors files.
## Backend Changes
To support the model selection GUI PR introduces a new method in
`ldm.invoke.model_manager` called `heuristic_import(). This accepts a
string-like object which can be a repo_id, URL, local path or directory.
It will figure out what the object is and import it. It interrogates the
contents of checkpoint and safetensors files to determine what type of
SD model they are -- v1.x, v2.x or v1.x inpainting.
## Installer
I am attaching a zip file of the installer if you would like to try the
process from end to end.
[InvokeAI-installer-v2.3.0.zip](https://github.com/invoke-ai/InvokeAI/files/10785474/InvokeAI-installer-v2.3.0.zip)
motivation: i want to be doing future prompting development work in the
`compel` lib (https://github.com/damian0815/compel) - which is currently
pip installable with `pip install compel`.
-At some point pathlib was added to the list of imported modules and
this broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
-At some point pathlib was added to the list of imported modules and this
broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
- Disable responsive resizing below starting dimensions (you can make
form larger, but not smaller than what it was at startup)
- Fix bug that caused multiple --ckpt_convert entries (and similar) to
be written to init file.
This bug is related to the format in which we stored prompts for some time: an array of weighted subprompts.
This caused some strife when recalling a prompt if the prompt had colons in it, due to our recently introduced handling of negative prompts.
Currently there is no need to store a prompt as anything other than a string, so we revert to doing that.
Compatibility with structured prompts is maintained via helper hook.
Lots of earlier embeds use a common trigger token such as * or the
hebrew letter shan. Previously, the textual inversion manager would
refuse to load the second and subsequent embeddings that used a
previously-claimed trigger. Now, when this case is encountered, the
trigger token is replaced by <filename> and the user is informed of the
fact.
{kind=link}
{kind=link}