* Add instructions on how to install alongside pyenv (#393) Like probably many others, I have a lot of different virtualenvs, one for each project. Most of them are handled by `pyenv`. After installing according to these instructions I had issues with ´pyenv`and `miniconda` fighting over the $PATH of my system. But then I stumbled upon this nice solution on SO: https://stackoverflow.com/a/73139031 , upon which I have based my suggested changes. It runs perfectly on my M1 setup, with the anaconda setup as a virtual environment handled by pyenv. Feel free to incorporate these instructions as you see fit. Thanks a million for all your hard work. * Disabled debug output (#436) Co-authored-by: Henry van Megen <hvanmegen@gmail.com> * Add New Logo Co-authored-by: Håvard Gulldahl <havard@lurtgjort.no> Co-authored-by: Henry van Megen <h.vanmegen@gmail.com> Co-authored-by: Henry van Megen <hvanmegen@gmail.com> Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
35 KiB
Stable Diffusion Dream Script
![]()
This is a fork of CompVis/stable-diffusion, the wonderful open source text-to-image generator. This fork supports:
-
An interactive command-line interface that accepts the same prompt and switches as the Discord bot.
-
A basic Web interface that allows you to run a local web server for generating images in your browser.
-
Support for img2img in which you provide a seed image to guide the image creation. (inpainting & masking coming soon)
-
Preliminary inpainting support.
-
A notebook for running the code on Google Colab.
-
Upscaling and face fixing using the optional ESRGAN and GFPGAN packages.
-
Weighted subprompts for prompt tuning.
-
Image variations which allow you to systematically generate variations of an image you like and combine two or more images together to combine the best features of both.
-
Textual inversion for customization of the prompt language and images.
-
...and more!
This fork is rapidly evolving, so use the Issues panel to report bugs and make feature requests, and check back periodically for improvements and bug fixes.
Table of Contents
Features
Interactive command-line interface similar to the Discord bot
The dream.py script, located in scripts/dream.py, provides an interactive interface to image generation similar to the "dream mothership" bot that Stable AI provided on its Discord server. Unlike the txt2img.py and img2img.py scripts provided in the original CompViz/stable-diffusion source code repository, the time-consuming initialization of the AI model initialization only happens once. After that image generation from the command-line interface is very fast.
The script uses the readline library to allow for in-line editing, command history (up and down arrows), autocompletion, and more. To help keep track of which prompts generated which images, the script writes a log file of image names and prompts to the selected output directory. In addition, as of version 1.02, it also writes the prompt into the PNG file's metadata where it can be retrieved using scripts/images2prompt.py
The script is confirmed to work on Linux, Windows and Mac systems. Note that this script runs from the command-line or can be used as a Web application. The Web GUI is currently rudimentary, but a much better replacement is on its way.
(ldm) ~/stable-diffusion$ python3 ./scripts/dream.py
* Initializing, be patient...
Loading model from models/ldm/text2img-large/model.ckpt
(...more initialization messages...)
* Initialization done! Awaiting your command...
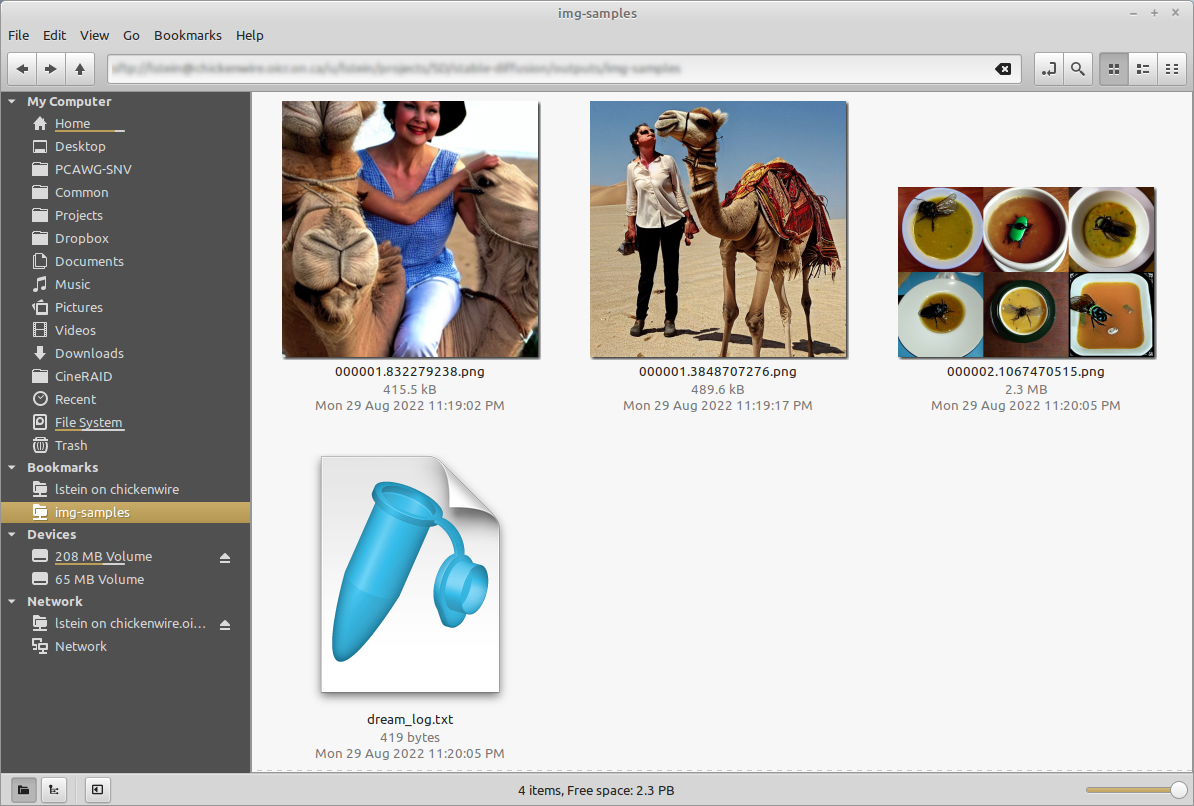
dream> ashley judd riding a camel -n2 -s150
Outputs:
outputs/img-samples/00009.png: "ashley judd riding a camel" -n2 -s150 -S 416354203
outputs/img-samples/00010.png: "ashley judd riding a camel" -n2 -s150 -S 1362479620
dream> "there's a fly in my soup" -n6 -g
outputs/img-samples/00011.png: "there's a fly in my soup" -n6 -g -S 2685670268
seeds for individual rows: [2685670268, 1216708065, 2335773498, 822223658, 714542046, 3395302430]
dream> q
# this shows how to retrieve the prompt stored in the saved image's metadata
(ldm) ~/stable-diffusion$ python ./scripts/images2prompt.py outputs/img_samples/*.png
00009.png: "ashley judd riding a camel" -s150 -S 416354203
00010.png: "ashley judd riding a camel" -s150 -S 1362479620
00011.png: "there's a fly in my soup" -n6 -g -S 2685670268
The dream> prompt's arguments are pretty much identical to those used in the Discord bot, except you don't need to type "!dream" (it doesn't hurt if you do). A significant change is that creation of individual images is now the default unless --grid (-g) is given. For backward compatibility, the -i switch is recognized. For command-line help type -h (or --help) at the dream> prompt.
The script itself also recognizes a series of command-line switches that will change important global defaults, such as the directory for image outputs and the location of the model weight files.
Hardware Requirements
You will need one of:
-
An NVIDIA-based graphics card with 8 GB or more of VRAM memory*.
-
An Apple computer with an M1 chip.**
-
At least 12 GB of main memory RAM.
-
At least 6 GB of free disk space for the machine learning model, python, and all its dependencies.
- If you are have a Nvidia 10xx series card (e.g. the 1080ti), please run the dream script in full-precision mode as shown below.
** Similarly, specify full-precision mode on Apple M1 hardware.
To run in full-precision mode, start dream.py with the --full_precision flag:
(ldm) ~/stable-diffusion$ python scripts/dream.py --full_precision
Image-to-Image
This script also provides an img2img feature that lets you seed your creations with an initial drawing or photo. This is a really cool feature that tells stable diffusion to build the prompt on top of the image you provide, preserving the original's basic shape and layout. To use it, provide the --init_img option as shown here:
dream> "waterfall and rainbow" --init_img=./init-images/crude_drawing.png --strength=0.5 -s100 -n4
The --init_img (-I) option gives the path to the seed picture. --strength (-f) controls how much the original will be modified, ranging from 0.0 (keep the original intact), to 1.0 (ignore the original completely). The default is 0.75, and ranges from 0.25-0.75 give interesting results.
You may also pass a -v option to generate count variants on the original image. This is done by passing the first generated image back into img2img the requested number of times. It generates interesting variants.
If the initial image contains transparent regions, then Stable Diffusion will only draw within the transparent regions, a process called "inpainting". However, for this to work correctly, the color information underneath the transparent needs to be preserved, not erased. See Creating Transparent Images for Inpainting for details.
Seamless Tiling
The seamless tiling mode causes generated images to seamlessly tile with itself. To use it, add the --seamless option when starting the script which will result in all generated images to tile, or for each dream> prompt as shown here:
dream> "pond garden with lotus by claude monet" --seamless -s100 -n4
GFPGAN and Real-ESRGAN Support
The script also provides the ability to do face restoration and upscaling with the help of GFPGAN and Real-ESRGAN respectively.
To use the ability, clone the GFPGAN
repository and follow their
installation instructions. By default, we expect GFPGAN to be
installed in a 'GFPGAN' sibling directory. Be sure that the "ldm"
conda environment is active as you install GFPGAN.
You can use the --gfpgan_dir argument with dream.py to set a
custom path to your GFPGAN directory. There are other GFPGAN related
boot arguments if you wish to customize further.
You can install Real-ESRGAN by typing the following command.
pip install realesrgan
Note: Internet connection needed:
Users whose GPU machines are isolated from the Internet (e.g. on a
University cluster) should be aware that the first time you run
dream.py with GFPGAN and Real-ESRGAN turned on, it will try to
download model files from the Internet. To rectify this, you may run
python3 scripts/preload_models.py after you have installed GFPGAN
and all its dependencies.
Usage
You will now have access to two new prompt arguments.
Upscaling
-U : <upscaling_factor> <upscaling_strength>
The upscaling prompt argument takes two values. The first value is a
scaling factor and should be set to either 2 or 4 only. This will
either scale the image 2x or 4x respectively using different models.
You can set the scaling stength between 0 and 1.0 to control
intensity of the of the scaling. This is handy because AI upscalers
generally tend to smooth out texture details. If you wish to retain
some of those for natural looking results, we recommend using values
between 0.5 to 0.8.
If you do not explicitly specify an upscaling_strength, it will default to 0.75.
Face Restoration
-G : <gfpgan_strength>
This prompt argument controls the strength of the face restoration
that is being applied. Similar to upscaling, values between 0.5 to 0.8 are recommended.
You can use either one or both without any conflicts. In cases where you use both, the image will be first upscaled and then the face restoration process will be executed to ensure you get the highest quality facial features.
--save_orig
When you use either -U or -G, the final result you get is upscaled
or face modified. If you want to save the original Stable Diffusion
generation, you can use the -save_orig prompt argument to save the
original unaffected version too.
Example Usage
dream > superman dancing with a panda bear -U 2 0.6 -G 0.4
This also works with img2img:
dream> a man wearing a pineapple hat -I path/to/your/file.png -U 2 0.5 -G 0.6
Note
GFPGAN and Real-ESRGAN are both memory intensive. In order to avoid crashes and memory overloads during the Stable Diffusion process, these effects are applied after Stable Diffusion has completed its work.
In single image generations, you will see the output right away but when you are using multiple iterations, the images will first be generated and then upscaled and face restored after that process is complete. While the image generation is taking place, you will still be able to preview the base images.
If you wish to stop during the image generation but want to upscale or
face restore a particular generated image, pass it again with the same
prompt and generated seed along with the -U and -G prompt
arguments to perform those actions.
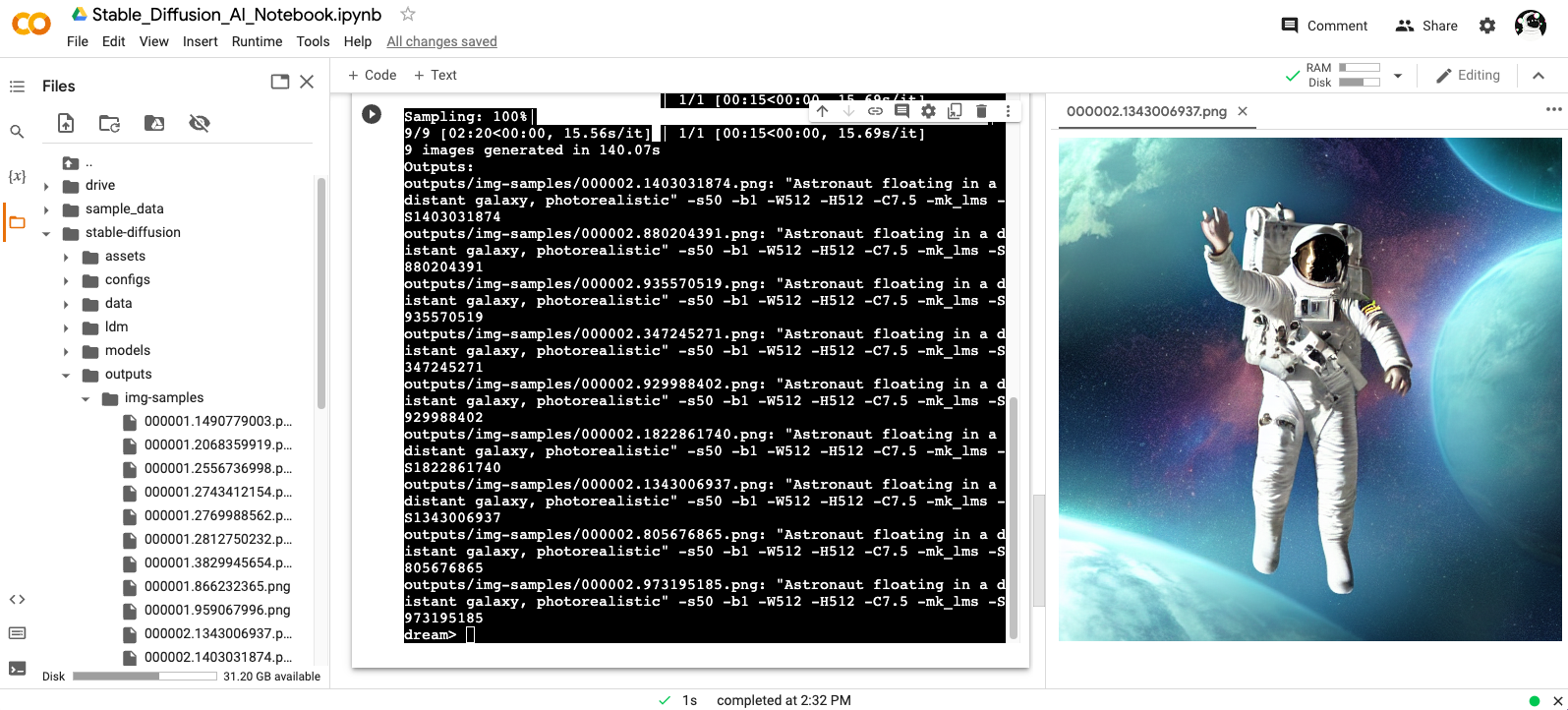
Google Colab
Stable Diffusion AI Notebook: ![]()
Open and follow instructions to use an isolated environment running Dream.
Output example:
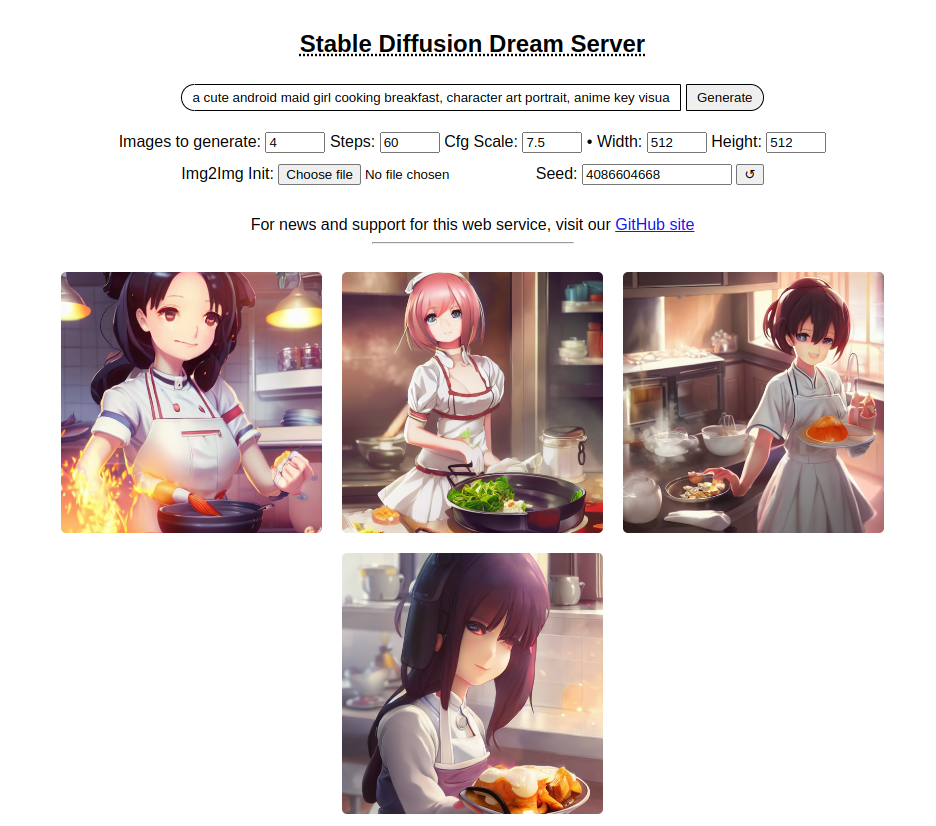
Barebones Web Server
As of version 1.10, this distribution comes with a bare bones web server (see screenshot). To use it, run the dream.py script by adding the --web option.
(ldm) ~/stable-diffusion$ python3 scripts/dream.py --web
You can then connect to the server by pointing your web browser at http://localhost:9090, or to the network name or IP address of the server.
Kudos to Tesseract Cat for contributing this code, and to dagf2101 for refining it.
Reading Prompts from a File
You can automate dream.py by providing a text file with the prompts you want to run, one line per prompt. The text file must be composed with a text editor (e.g. Notepad) and not a word processor. Each line should look like what you would type at the dream> prompt:
a beautiful sunny day in the park, children playing -n4 -C10
stormy weather on a mountain top, goats grazing -s100
innovative packaging for a squid's dinner -S137038382
Then pass this file's name to dream.py when you invoke it:
(ldm) ~/stable-diffusion$ python3 scripts/dream.py --from_file "path/to/prompts.txt"
You may read a series of prompts from standard input by providing a filename of "-":
(ldm) ~/stable-diffusion$ echo "a beautiful day" | python3 scripts/dream.py --from_file -
Shortcut for reusing seeds from the previous command
Since it is so common to reuse seeds while refining a prompt, there is now a shortcut as of version 1.11. Provide a -S (or --seed) switch of -1 to use the seed of the most recent image generated. If you produced multiple images with the -n switch, then you can go back further using -2, -3, etc. up to the first image generated by the previous command. Sorry, but you can't go back further than one command.
Here's an example of using this to do a quick refinement. It also illustrates using the new -G switch to turn on upscaling and face enhancement (see previous section):
dream> a cute child playing hopscotch -G0.5
[...]
outputs/img-samples/000039.3498014304.png: "a cute child playing hopscotch" -s50 -W512 -H512 -C7.5 -mk_lms -S3498014304
# I wonder what it will look like if I bump up the steps and set facial enhancement to full strength?
dream> a cute child playing hopscotch -G1.0 -s100 -S -1
reusing previous seed 3498014304
[...]
outputs/img-samples/000040.3498014304.png: "a cute child playing hopscotch" -G1.0 -s100 -W512 -H512 -C7.5 -mk_lms -S3498014304
Weighted Prompts
You may weight different sections of the prompt to tell the sampler to attach different levels of priority to them, by adding :(number) to the end of the section you wish to up- or downweight. For example consider this prompt:
tabby cat:0.25 white duck:0.75 hybrid
This will tell the sampler to invest 25% of its effort on the tabby cat aspect of the image and 75% on the white duck aspect (surprisingly, this example actually works). The prompt weights can use any combination of integers and floating point numbers, and they do not need to add up to 1.
Personalizing Text-to-Image Generation
You may personalize the generated images to provide your own styles or objects by training a new LDM checkpoint and introducing a new vocabulary to the fixed model.
To train, prepare a folder that contains images sized at 512x512 and execute the following:
WINDOWS: As the default backend is not available on Windows, if you're using that platform, set the environment variable PL_TORCH_DISTRIBUTED_BACKEND=gloo
(ldm) ~/stable-diffusion$ python3 ./main.py --base ./configs/stable-diffusion/v1-finetune.yaml \
-t \
--actual_resume ./models/ldm/stable-diffusion-v1/model.ckpt \
-n my_cat \
--gpus 0, \
--data_root D:/textual-inversion/my_cat \
--init_word 'cat'
During the training process, files will be created in /logs/[project][time][project]/ where you can see the process.
conditioning* contains the training prompts inputs, reconstruction the input images for the training epoch samples, samples scaled for a sample of the prompt and one with the init word provided
On a RTX3090, the process for SD will take ~1h @1.6 iterations/sec.
Note: According to the associated paper, the optimal number of images is 3-5. Your model may not converge if you use more images than that.
Training will run indefinately, but you may wish to stop it before the heat death of the universe, when you find a low loss epoch or around ~5000 iterations.
Once the model is trained, specify the trained .pt file when starting dream using
(ldm) ~/stable-diffusion$ python3 ./scripts/dream.py --embedding_path /path/to/embedding.pt --full_precision
Then, to utilize your subject at the dream prompt
dream> "a photo of *"
this also works with image2image
dream> "waterfall and rainbow in the style of *" --init_img=./init-images/crude_drawing.png --strength=0.5 -s100 -n4
It's also possible to train multiple tokens (modify the placeholder string in configs/stable-diffusion/v1-finetune.yaml) and combine LDM checkpoints using:
(ldm) ~/stable-diffusion$ python3 ./scripts/merge_embeddings.py \
--manager_ckpts /path/to/first/embedding.pt /path/to/second/embedding.pt [...] \
--output_path /path/to/output/embedding.pt
Credit goes to @rinongal and the repository located at https://github.com/rinongal/textual_inversion Please see the repository and associated paper for details and limitations.
Latest Changes
-
v1.14 (In progress)
- Add "seamless mode" for circular tiling of image. Generates beautiful effects. (prixt)
-
v1.13 (3 September 2022
- Support image variations (see VARIATIONS (Kevin Gibbons and many contributors and reviewers)
- Supports a Google Colab notebook for a standalone server running on Google hardware Arturo Mendivil
- WebUI supports GFPGAN/ESRGAN facial reconstruction and upscaling Kevin Gibbons
- WebUI supports incremental display of in-progress images during generation Kevin Gibbons
- A new configuration file scheme that allows new models (including upcoming stable-diffusion-v1.5) to be added without altering the code. (David Wager)
- Can specify --grid on dream.py command line as the default.
- Miscellaneous internal bug and stability fixes.
- Works on M1 Apple hardware.
- Multiple bug fixes.
For older changelogs, please visit CHANGELOGS.
Installation
There are separate installation walkthroughs for Linux, Windows and Macintosh
Linux
- You will need to install the following prerequisites if they are not already available. Use your operating system's preferred installer
- Python (version 3.8.5 recommended; higher may work)
- git
- Install the Python Anaconda environment manager.
~$ wget https://repo.anaconda.com/archive/Anaconda3-2022.05-Linux-x86_64.sh
~$ chmod +x Anaconda3-2022.05-Linux-x86_64.sh
~$ ./Anaconda3-2022.05-Linux-x86_64.sh
After installing anaconda, you should log out of your system and log back in. If the installation worked, your command prompt will be prefixed by the name of the current anaconda environment, "(base)".
- Copy the stable-diffusion source code from GitHub:
(base) ~$ git clone https://github.com/lstein/stable-diffusion.git
This will create stable-diffusion folder where you will follow the rest of the steps.
- Enter the newly-created stable-diffusion folder. From this step forward make sure that you are working in the stable-diffusion directory!
(base) ~$ cd stable-diffusion
(base) ~/stable-diffusion$
- Use anaconda to copy necessary python packages, create a new python environment named "ldm", and activate the environment.
(base) ~/stable-diffusion$ conda env create -f environment.yaml
(base) ~/stable-diffusion$ conda activate ldm
(ldm) ~/stable-diffusion$
After these steps, your command prompt will be prefixed by "(ldm)" as shown above.
- Load a couple of small machine-learning models required by stable diffusion:
(ldm) ~/stable-diffusion$ python3 scripts/preload_models.py
Note that this step is necessary because I modified the original just-in-time model loading scheme to allow the script to work on GPU machines that are not internet connected. See Workaround for machines with limited internet connectivity
- Now you need to install the weights for the stable diffusion model.
For running with the released weights, you will first need to set up an acount with Hugging Face (https://huggingface.co). Use your credentials to log in, and then point your browser at https://huggingface.co/CompVis/stable-diffusion-v-1-4-original. You may be asked to sign a license agreement at this point.
Click on "Files and versions" near the top of the page, and then click on the file named "sd-v1-4.ckpt". You'll be taken to a page that prompts you to click the "download" link. Save the file somewhere safe on your local machine.
Now run the following commands from within the stable-diffusion directory. This will create a symbolic link from the stable-diffusion model.ckpt file, to the true location of the sd-v1-4.ckpt file.
(ldm) ~/stable-diffusion$ mkdir -p models/ldm/stable-diffusion-v1
(ldm) ~/stable-diffusion$ ln -sf /path/to/sd-v1-4.ckpt models/ldm/stable-diffusion-v1/model.ckpt
- Start generating images!
# for the pre-release weights use the -l or --liaon400m switch
(ldm) ~/stable-diffusion$ python3 scripts/dream.py -l
# for the post-release weights do not use the switch
(ldm) ~/stable-diffusion$ python3 scripts/dream.py
# for additional configuration switches and arguments, use -h or --help
(ldm) ~/stable-diffusion$ python3 scripts/dream.py -h
- Subsequently, to relaunch the script, be sure to run "conda activate ldm" (step 5, second command), enter the "stable-diffusion" directory, and then launch the dream script (step 8). If you forget to activate the ldm environment, the script will fail with multiple ModuleNotFound errors.
Updating to newer versions of the script
This distribution is changing rapidly. If you used the "git clone" method (step 5) to download the stable-diffusion directory, then to update to the latest and greatest version, launch the Anaconda window, enter "stable-diffusion", and type:
(ldm) ~/stable-diffusion$ git pull
This will bring your local copy into sync with the remote one.
Windows
Notebook install (semi-automated)
We have a Jupyter notebook with cell-by-cell installation steps. It will download the code in this repo as one of the steps, so instead of cloning this repo, simply download the notebook from the link above and load it up in VSCode (with the appropriate extensions installed)/Jupyter/JupyterLab and start running the cells one-by-one.
Note that you will need NVIDIA drivers, Python 3.10, and Git installed beforehand - simplified step-by-step instructions are available in the wiki (you'll only need steps 1, 2, & 3 ).
Manual installs
pip
See Easy-peasy Windows install in the wiki
Conda
-
Install Anaconda3 (miniconda3 version) from here: https://docs.anaconda.com/anaconda/install/windows/
-
Install Git from here: https://git-scm.com/download/win
-
Launch Anaconda from the Windows Start menu. This will bring up a command window. Type all the remaining commands in this window.
-
Run the command:
git clone https://github.com/lstein/stable-diffusion.git
This will create stable-diffusion folder where you will follow the rest of the steps.
- Enter the newly-created stable-diffusion folder. From this step forward make sure that you are working in the stable-diffusion directory!
cd stable-diffusion
- Run the following two commands:
conda env create -f environment.yaml (step 6a)
conda activate ldm (step 6b)
This will install all python requirements and activate the "ldm" environment which sets PATH and other environment variables properly.
- Run the command:
python scripts\preload_models.py
This installs several machine learning models that stable diffusion requires. (Note that this step is required. I created it because some people are using GPU systems that are behind a firewall and the models can't be downloaded just-in-time)
- Now you need to install the weights for the big stable diffusion model.
For running with the released weights, you will first need to set up an acount with Hugging Face (https://huggingface.co). Use your credentials to log in, and then point your browser at https://huggingface.co/CompVis/stable-diffusion-v-1-4-original. You may be asked to sign a license agreement at this point.
Click on "Files and versions" near the top of the page, and then click on the file named "sd-v1-4.ckpt". You'll be taken to a page that prompts you to click the "download" link. Now save the file somewhere safe on your local machine. The weight file is >4 GB in size, so downloading may take a while.
Now run the following commands from within the stable-diffusion directory to copy the weights file to the right place:
mkdir -p models\ldm\stable-diffusion-v1
copy C:\path\to\sd-v1-4.ckpt models\ldm\stable-diffusion-v1\model.ckpt
Please replace "C:\path\to\sd-v1.4.ckpt" with the correct path to wherever you stashed this file. If you prefer not to copy or move the .ckpt file, you may instead create a shortcut to it from within "models\ldm\stable-diffusion-v1".
- Start generating images!
# for the pre-release weights
python scripts\dream.py -l
# for the post-release weights
python scripts\dream.py
- Subsequently, to relaunch the script, first activate the Anaconda command window (step 3), enter the stable-diffusion directory (step 5, "cd \path\to\stable-diffusion"), run "conda activate ldm" (step 6b), and then launch the dream script (step 9).
Note: Tildebyte has written an alternative "Easy peasy Windows install" which uses the Windows Powershell and pew. If you are having trouble with Anaconda on Windows, give this a try (or try it first!)
Updating to newer versions of the script
This distribution is changing rapidly. If you used the "git clone" method (step 5) to download the stable-diffusion directory, then to update to the latest and greatest version, launch the Anaconda window, enter "stable-diffusion", and type:
git pull
This will bring your local copy into sync with the remote one.
Macintosh
See README-Mac-MPS for instructions.
Simplified API for text to image generation
For programmers who wish to incorporate stable-diffusion into other products, this repository includes a simplified API for text to image generation, which lets you create images from a prompt in just three lines of code:
from ldm.simplet2i import T2I
model = T2I()
outputs = model.txt2img("a unicorn in manhattan")
Outputs is a list of lists in the format [[filename1,seed1],[filename2,seed2]...] Please see ldm/simplet2i.py for more information. A set of example scripts is coming RSN.
Workaround for machines with limited internet connectivity
My development machine is a GPU node in a high-performance compute cluster which has no connection to the internet. During model initialization, stable-diffusion tries to download the Bert tokenizer and a file needed by the kornia library. This obviously didn't work for me.
To work around this, I have modified ldm/modules/encoders/modules.py to look for locally cached Bert files rather than attempting to download them. For this to work, you must run "scripts/preload_models.py" once from an internet-connected machine prior to running the code on an isolated one. This assumes that both machines share a common network-mounted filesystem with a common .cache directory.
(ldm) ~/stable-diffusion$ python3 ./scripts/preload_models.py
preloading bert tokenizer...
Downloading: 100%|██████████████████████████████████| 28.0/28.0 [00:00<00:00, 49.3kB/s]
Downloading: 100%|██████████████████████████████████| 226k/226k [00:00<00:00, 2.79MB/s]
Downloading: 100%|██████████████████████████████████| 455k/455k [00:00<00:00, 4.36MB/s]
Downloading: 100%|██████████████████████████████████| 570/570 [00:00<00:00, 477kB/s]
...success
preloading kornia requirements...
Downloading: "https://github.com/DagnyT/hardnet/raw/master/pretrained/train_liberty_with_aug/checkpoint_liberty_with_aug.pth" to /u/lstein/.cache/torch/hub/checkpoints/checkpoint_liberty_with_aug.pth
100%|███████████████████████████████████████████████| 5.10M/5.10M [00:00<00:00, 101MB/s]
...success
Troubleshooting
Here are a few common installation problems and their solutions. Often these are caused by incomplete installations or crashes during the install process.
-
PROBLEM: During "conda env create -f environment.yaml", conda hangs indefinitely.
-
SOLUTION: Enter the stable-diffusion directory and completely remove the "src" directory and all its contents. The safest way to do this is to enter the stable-diffusion directory and give the command "git clean -f". If this still doesn't fix the problem, try "conda clean -all" and then restart at the "conda env create" step.
-
PROBLEM: dream.py crashes with the complaint that it can't find ldm.simplet2i.py. Or it complains that function is being passed incorrect parameters.
-
SOLUTION: Reinstall the stable diffusion modules. Enter the stable-diffusion directory and give the command "pip install -e ."
-
PROBLEM: dream.py dies, complaining of various missing modules, none of which starts with "ldm".
-
SOLUTION: From within the stable-diffusion directory, run "conda env update -f environment.yaml" This is also frequently the solution to complaints about an unknown function in a module.
-
PROBLEM: There's a feature or bugfix in the Stable Diffusion GitHub that you want to try out.
-
SOLUTION: If the fix/feature is on the "main" branch, enter the stable-diffusion directory and do a "git pull". Usually this will be sufficient, but if you start to see errors about missing or incorrect modules, use the command "pip install -e ." and/or "conda env update -f environment.yaml" (These commands won't break anything.)
-
If the feature/fix is on a branch (e.g. "foo-bugfix"), the recipe is similar, but do a "git pull ".
-
If the feature/fix is in a pull request that has not yet been made part of the main branch or a feature/bugfix branch, then from the page for the desired pull request, look for the line at the top that reads "xxxx wants to merge xx commits into lstein:main from YYYYYY". Copy the URL in YYYY. It should have the format https://github.com//stable-diffusion/tree/
-
Then go to the directory above stable-diffusion, and rename the directory to "stable-diffusion.lstein", "stable-diffusion.old", or whatever. You can then git clone the branch that contains the pull request:
git clone https://github.com/<name of contributor>/stable-diffusion/tree/<name
of branch>
You will need to go through the install procedure again, but it should be fast because all the dependencies are already loaded.
Creating Transparent Regions for Inpainting
Inpainting is really cool. To do it, you start with an initial image and use a photoeditor to make one or more regions transparent (i.e. they have a "hole" in them). You then provide the path to this image at the dream> command line using the -I switch. Stable Diffusion will only paint within the transparent region.
There's a catch. In the current implementation, you have to prepare the initial image correctly so that the underlying colors are preserved under the transparent area. Many imaging editing applications will by default erase the color information under the transparent pixels and replace them with white or black, which will lead to suboptimal inpainting. You also must take care to export the PNG file in such a way that the color information is preserved.
If your photoeditor is erasing the underlying color information, dream.py will give you a big fat warning. If you can't find a way to coax your photoeditor to retain color values under transparent areas, then you can combine the -I and -M switches to provide both the original unedited image and the masked (partially transparent) image:
dream> man with cat on shoulder -I./images/man.png -M./images/man-transparent.png
We are hoping to get rid of the need for this workaround in an upcoming release.
Recipe for GIMP
GIMP is a popular Linux photoediting tool.
- Open image in GIMP.
- Layer->Transparency->Add Alpha Channel
- Use lasoo tool to select region to mask
- Choose Select -> Float to create a floating selection
- Open the Layers toolbar (^L) and select "Floating Selection"
- Set opacity to 0%
- Export as PNG
- In the export dialogue, Make sure the "Save colour values from transparent pixels" checkbox is selected.
Contributing
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code cleanup, testing, or code reviews, is very much encouraged to do so. If you are unfamiliar with how to contribute to GitHub projects, here is a Getting Started Guide.
A full set of contribution guidelines, along with templates, are in progress, but for now the most important thing is to make your pull request against the "development" branch, and not against "main". This will help keep public breakage to a minimum and will allow you to propose more radical changes.
Support
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an email if you use and like the script.
Original Author: Lincoln D. Stein lincoln.stein@gmail.com
Contributions by: Peter Kowalczyk, Henry Harrison, xraxra, bmaltais, Sean McLellan, nicolai256, Benjamin Warner, tildebyte,yunsaki, [James Reynolds][https://github.com/magnusviri], Tesseract Cat, and many more!
(If you have contributed and don't see your name on the list of contributors, please let lstein know about the omission, or make a pull request)
Original portions of the software are Copyright (c) 2020 Lincoln D. Stein (https://github.com/lstein)
Further Reading
Please see the original README for more information on this software and underlying algorithm, located in the file README-CompViz.md.