### WebUI Model Conversion
**Model Search Updates**
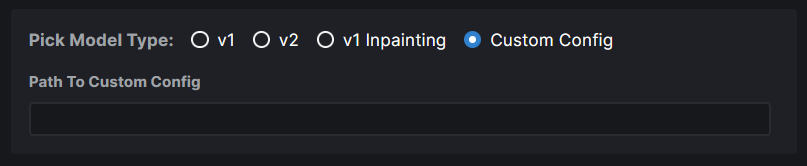
- Model Search now has a radio group that allows users to pick the type
of model they are importing. If they know their model has a custom
config file, they can assign it right here. Based on their pick, the
model config data is automatically populated. And this same information
is used when converting the model to `diffusers`.
- Files named `model.safetensors` and
`diffusion_pytorch_model.safetensors` are excluded from the search
because these are naming conventions used by diffusers models and they
will end up showing on the list because our conversion saves safetensors
and not bin files.
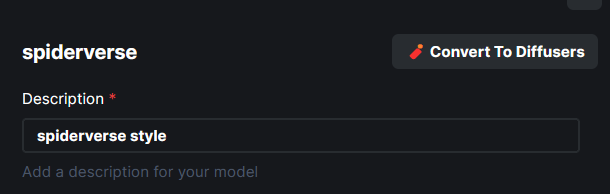
**Model Conversion UI**
- The **Convert To Diffusers** button can be found on the Edit page of
any **Checkpoint Model**.
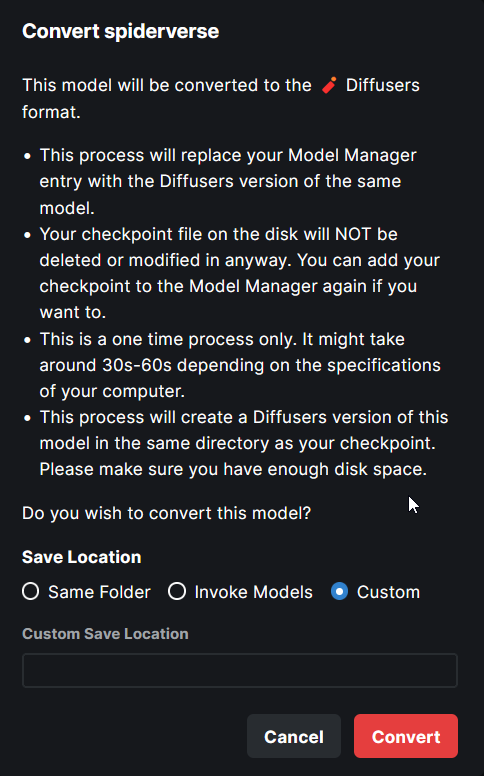
- When converting the model, the entire process is handled
automatically. The corresponding config while at the time of the Ckpt
addition is used in the process.
- Users are presented with the choice on where to save the diffusers
converted model - same location as the ckpt, InvokeAI models root folder
or a completely custom location.
- When the model is converted, the checkpoint entry is replaced with the
diffusers model entry. A user can readd the ckpt if they wish to.
---
More or less done. Might make some minor UX improvements as I refine
things.
Tensors with diffusers no longer have to be multiples of 8. This broke Perlin noise generation. We now generate noise for the next largest multiple of 8 and return a cropped result. Fixes#2674.
`generator` now asks `InvokeAIDiffuserComponent` to do postprocessing work on latents after every step. Thresholding - now implemented as replacing latents outside of the threshold with random noise - is called at this point. This postprocessing step is also where we can hook up symmetry and other image latent manipulations in the future.
Note: code at this layer doesn't need to worry about MPS as relevant torch functions are wrapped and made MPS-safe by `generator.py`.
I have added the arabic locale files. There need to be some
modifications to the code in order to detect the language direction and
add it to the current document body properties.
For example we can use this:
import { appWithTranslation, useTranslation } from "next-i18next";
import React, { useEffect } from "react";
const { t, i18n } = useTranslation();
const direction = i18n.dir();
useEffect(() => {
document.body.dir = direction;
}, [direction]);
This should be added to the app file. It uses next-i18next to
automatically get the current language and sets the body text direction
(ltr or rtl) depending on the selected language.
## Provide informative error messages when TI and Merge scripts have
insufficient space for console UI
- The invokeai-ti and invokeai-merge scripts will crash if there is not
enough space in the console to fit the user interface (even after
responsive formatting).
- This PR intercepts the errors and prints a useful error message
advising user to make window larger.
- The invokeai-ti and invokeai-merge scripts will crash if there is not enough space
in the console to fit the user interface (even after responsive formatting).
- This PR intercepts the errors and prints a useful error message advising user to
make window larger.
- fix unused variables and f-strings found by pyflakes
- use global_converted_ckpts_dir() to find location of diffusers
- fixed bug in model_manager that was causing the description of converted
models to read "Optimized version of {model_name}'
Strategize slicing based on free [V]RAM when not using xformers. Free [V]RAM is evaluated at every generation. When there's enough memory, the entire generation occurs without slicing. If there is not enough free memory, we use diffusers' sliced attention.
Some of the core features of this PR include:
- optional push image to dockerhub (will be skipped in repos which
didn't set it up)
- stop using the root user at runtime
- trigger builds also for update/docker/* and update/ci/docker/*
- always cache image from current branch and main branch
- separate caches for container flavors
- updated comments with instructions in build.sh and run.sh
Users can now pick the folder to save their diffusers converted model. It can either be the same folder as the ckpt, or the invoke root models folder or a totally custom location.
Fixed a couple of bugs:
1. The original config file for the ckpt file is derived from the entry in
`models.yaml` rather than relying on the user to select. The implication
of this is that V2 ckpt models need to be assigned `v2-inference-v.yaml`
when they are first imported. Otherwise they won't convert right. Note
that currently V2 ckpts are imported with `v1-inference.yaml`, which
isn't right either.
2. Fixed a backslash in the output diffusers path, which was causing
load failures on Linux.
Remaining issues:
1. The radio buttons for selecting the model type are
nonfunctional. It feels to me like these should be moved into the
dialogue for importing ckpt/safetensors files, because this is
where the algorithm needs help from the user.
2. The output diffusers model is written into the same directory as
the input ckpt file. The CLI does it differently and stores the
diffusers model in `ROOTDIR/models/converted-ckpts`. We should
settle on one way or the other.
Converted the picker options to a Radio Group and also updated the backend to use the appropriate config if it is a v2 model that needs to be converted.
## What was the problem/requirement? (What/Why)
* Windows location for the Python environment activate location is
currently incorrect
* Due to this, this command will fail for Windows-based users
* The contributing link within the `Developer Install` sections leads to
a [404](https://invoke-ai.github.io/index.md#Contributing)
* `Developer Install`'s numbered list currently lists 1, 1, 2, . . .
## What was the solution? (How)
* Changed the location of Windows script based on actual location -
[reference](https://docs.python.org/3/library/venv.html)
* Moved the link to point to one directory higher -- the main index.md
* Minor format adjustments to allow for the numbered list to appear as
expected
## How were these changes tested?
* `mkdocs serve` => Verified on local server that the changes reflected
as expected
## Notes
Contributing mentions to set the upstream towards the `development`
branch, but that branch has been untouched for several months, so I've
pointed to the `main` branch. Let me know if we need to switch to a
different one.
…odels
- If CLI asked to convert the currently loaded model, the model would
crash on the first rendering. CLI will now refuse to convert a model
loaded in memory (probably a good idea in any case).
- CLI will offer the `v1-inpainting-inference.yaml` as the configuration
file when importing an inpainting a .ckpt or .safetensors file that has
"inpainting" in the name. Otherwise it offers `v1-inference.yaml` as the
default.
rather than bypassing any path with diffusers in it, im specifically bypassing model.safetensors and diffusion_pytorch_model.safetensors both of which should be diffusers files in most cases.
{kind=link}
{kind=link}
{kind=link}