## What type of PR is this? (check all applicable)
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X] No - this should go into release notes.
## Description
During installation, the installer will now ask the user whether they
wish to perform a manual or automatic configuration of invokeai. If they
choose automatic (the default), then the install is performed without
running the TUI of the `invokeai-configure` script. Otherwise the
console-based interface is activated as usual.
This script also bumps up the default model RAM cache size to 7.5, which
improves performance on SDXL models.
* Add 'Random Float' node <3
does what it says on the tin :)
* Add random float + random seeded float nodes
altered my random float node as requested by Millu, kept the seeded version as an alternate variant for those that would like to control the randomization seed :)
* Update math.py
* Update math.py
* feat(nodes): standardize fields to match other nodes
---------
Co-authored-by: Millun Atluri <Millu@users.noreply.github.com>
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
* fix(nodes): do not disable invocation cache delete methods
When the runtime disabled flag is on, do not skip the delete methods. This could lead to a hit on a missing resource.
Do skip them when the cache size is 0, because the user cannot change this (must restart app to change it).
* fix(nodes): do not use double-underscores in cache service
* Thread lock for cache
* Making cache LRU
* Bug fixes
* bugfix
* Switching to one Lock and OrderedDict cache
* Removing unused imports
* Move lock cache instance
* Addressing PR comments
---------
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
Co-authored-by: Martin Kristiansen <martin@modyfi.io>
* add skeleton loading state for queue lit
* hide use cache checkbox if cache is disabled
* undo accidental add
* feat(ui): hide node footer entirely if nothing to show there
---------
Co-authored-by: Mary Hipp <maryhipp@Marys-MacBook-Air.local>
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
Skeletons are for when we know the number of specific content items that are loading. When the queue is loading, we don't know how many items there are, or how many will load, so the whole list should be replaced with loading state.
The previous behaviour rendered a static number of skeletons. That number would rarely be the right number - the app shouldn't say "I'm loading 7 queue items", then load none, or load 50.
A future enhancement could use the queue item skeleton component and go by the total number of queue items, as reported by the queue status. I tried this but had some layout jankiness, not worth the effort right now.
The queue item skeleton component's styling was updated to support this future enhancement, making it exactly the same size as a queue item (it was a bit smaller before).
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Description
I left a dangling debug statement in a recent merged PR (#4674 ). This
removes it.
Updates my Image & Mask Composition Pack from 4 to 14 nodes, and moves
the Enhance Image node into it.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [X] Documentation Update
- [X] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because:
This is an update of my existing community nodes entries.
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
Adds 9 more nodes to my Image & Mask Composition pack including Clipseg,
Image Layer Blend, Masked Latent/Noise Blend, Image Dilate/Erode,
Shadows/Highlights/Midtones masks from image, and more.
## Related Tickets & Documents
n/a
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [X] No : out of scope, tested the nodes, will integrate tests with my
own repo in time as is helpful
Adds 9 more of my nodes to the Image & Mask Composition Pack in the community nodes page, and integrates the Enhance Image node into that pack as well (formerly it was its own entry).
Add some instructions about installing the frontend toolchain when doing
a git-based install.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [x] Documentation Update
- [ ] Community Node Submission
## Description
[Update
020_INSTALL_MANUAL.md](73ca8ccdb3)
Add some instructions about installing the frontend toolchain when doing
a git-based install.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
This is actually a platform-specific issue. `madge` is complaining about
a circular dependency on a single file -
`invokeai/frontend/web/src/features/queue/store/nanoStores.ts`. In that
file, we import from the `nanostores` package. Very similar name to the
file itself.
The error only appears on Windows and macOS, I imagine because those
systems both resolve `nanostores` to itself before resolving to the
package.
The solution is simple - rename `nanoStores.ts`. It's now
`queueNanoStore.ts`.
## Related Tickets & Documents
https://discord.com/channels/1020123559063990373/1155434451979993140
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
## What type of PR is this? (check all applicable)
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
This PR adds support for selecting and installing IP-Adapters at
configure time. The user is offered the four existing InvokeAI IP
Adapters in the UI as shown below. The matching image encoders are
selected and installed behind the scenes. That is, if the user selects
one of the three sd15 adapters, then the SD encoder will be installed.
If they select the sdxl adapter, then the SDXL encoder will be
installed.
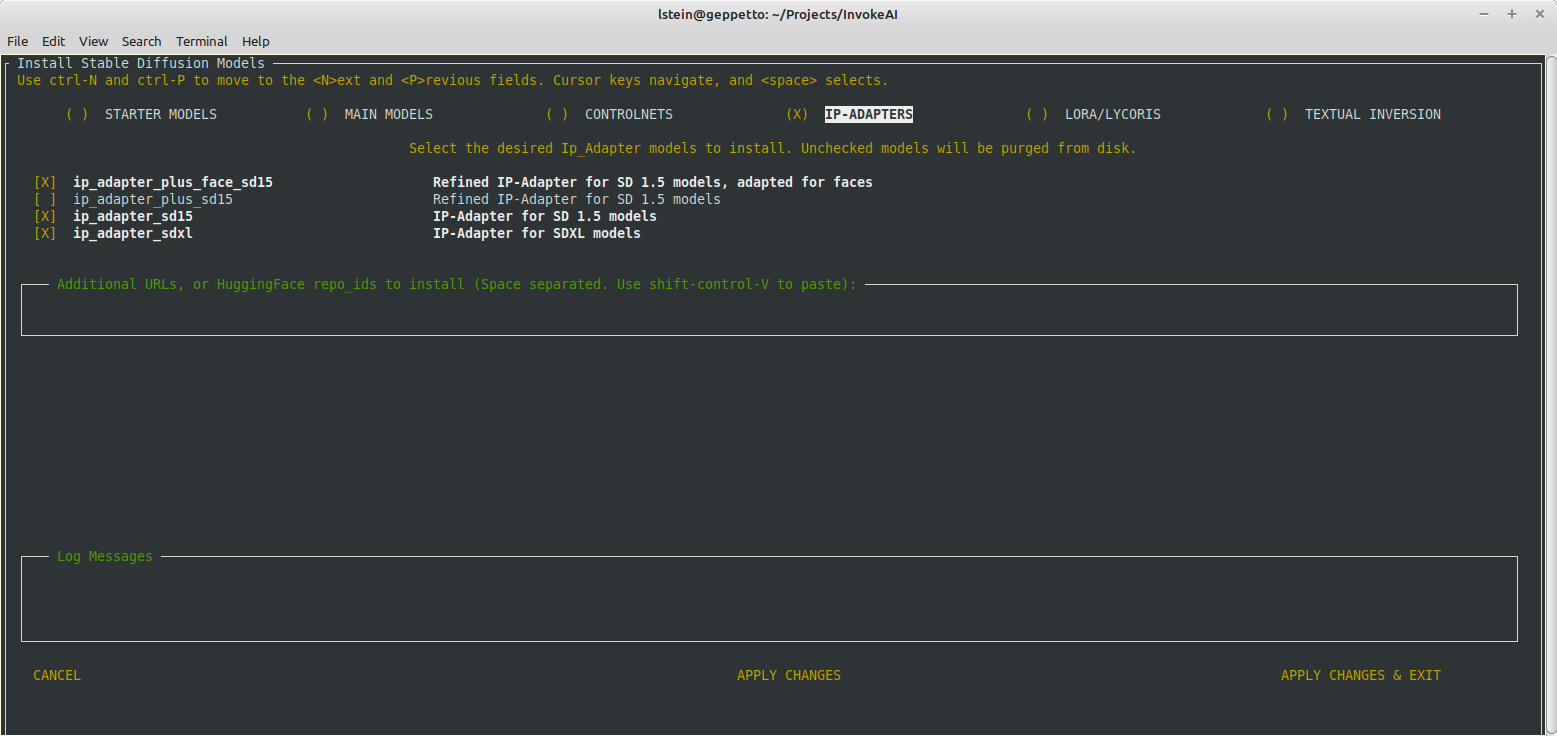
Note that the automatic selection of the encoder does not work when the
installer is run in headless mode. I may be able to fix that soon, but
I'm out of time today.
This is actually a platform-specific issue. `madge` is complaining about a circular dependency on a single file - `invokeai/frontend/web/src/features/queue/store/nanoStores.ts`. In that file, we import from the `nanostores` package. Very similar name to the file itself.
The error only appears on Windows and macOS, I imagine because those systems both resolve `nanostores` to itself before resolving to the package.
The solution is simple - rename `nanoStores.ts`. It's now `queueNanoStore.ts`.
## What type of PR is this? (check all applicable)
- [X] Bug Fix
- [ ] Optimizatio
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] Np
## Have you updated all relevant documentation?
- [ ] Yes
- [X] No
## Description
ip_adapter models live in a folder containing the file
`image_encoder.txt` and a safetensors file. The load-time probe for new
models was detecting the files contained within the folder rather than
the folder itself, and so models.yaml was not getting correctly updated.
This fixes the issue.
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
It turns out that there are a few SD-1 models that use the
`v_prediction` SchedulerPredictionType. Examples here:
https://huggingface.co/zatochu/EasyFluff/tree/main . Previously we only
allowed the user to set the prediction type for sd-2 models. This PR
does three things:
1. Add a new checkpoint configuration file `v1-inference-v.yaml`. This
will install automatically on new installs, but for existing installs
users will need to update and then run `invokeai-configure` to get it.
2. Change the prompt on the web model install page to indicate that some
SD-1 models use the "v_prediction" method
3. Provide backend support for sd-1 models that use the v_prediction
method.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes#4277
## QA Instructions, Screenshots, Recordings
Update, run `invoke-ai-configure --yes --skip-sd --skip-support`, and
then use the web interface to install
https://huggingface.co/zatochu/EasyFluff/resolve/main/EasyFluffV11.2.safetensors
with the prediction type set to "v_prediction." Check that the installed
model uses configuration `v1-inference-v.yaml`.
If "None" is selected from the install menu, check that SD-1 models
default to `v1-inference.yaml` and SD-2 default to
`v2-inference-v.yaml`.
Also try installing a checkpoint at a local path if a like-named config
.yaml file is located next to it in the same directory. This should
override everything else and use the local path .yaml.
## Added/updated tests?
- [ ] Yes
- [X] No
## What type of PR is this? (check all applicable)
- [X] Refactor
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because: trivial fix
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
It annoyed me that the class method to get the invokeai logger was
`InvokeAILogger.getLogger()`. We do not use camelCase anywhere else. So
this PR renames the method `get_logger()`.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
Pydantic handles the casting so this is always safe.
Also de-duplicate some validation logic code that was needlessly
duplicated.