mirror of
https://github.com/invoke-ai/InvokeAI
synced 2024-08-30 20:32:17 +00:00
Compare commits
93 Commits
fix/revert
...
feat/restr
| Author | SHA1 | Date | |
|---|---|---|---|
| 09609cd553 | |||
| 0aedd6d9f0 | |||
| 70a1202deb | |||
| 9a1aea9caf | |||
| 388d36b839 | |||
| bedb35af8c | |||
| dc232438fb | |||
| d7edf5aaad | |||
| 3ad1226d1e | |||
| 86ca9f122d | |||
| 2c6772f92f | |||
| e6c1e03b8b | |||
| c9d95e5758 | |||
| 10755718b8 | |||
| 459c7b3b74 | |||
| 353719f81d | |||
| bd4b260c23 | |||
| 3e389d3f60 | |||
| ffb01f1345 | |||
| faa0a8236c | |||
| e4d73d3659 | |||
| 6994783c17 | |||
| 3f9708f166 | |||
| bcf0d8a590 | |||
| 2060ee22f2 | |||
| 3fd79b837f | |||
| 1c099e0abb | |||
| 95cca9493c | |||
| 779c902402 | |||
| 99e6bb48ba | |||
| c3d6ff5b11 | |||
| bba962b82f | |||
| 78b8cfede3 | |||
| e9879b9e1f | |||
| e21f3af5ab | |||
| 2ab7c5f783 | |||
| 8bbd938be9 | |||
| b4cee46936 | |||
| 48626c40fd | |||
| a1001b6d10 | |||
| 50df641e1b | |||
| 22dd64dfa4 | |||
| 0a929ca3de | |||
| 8c61cda4b8 | |||
| 75663ec81e | |||
| 40a568c060 | |||
| 8e7aa74a16 | |||
| fcba4382b2 | |||
| 15cabc4968 | |||
| 21d5969942 | |||
| 334dcf71c4 | |||
| 52274087f3 | |||
| 5b2ed4ffb4 | |||
| a49b8febed | |||
| e543db5a5d | |||
| 670f3aa165 | |||
| c0534d6519 | |||
| 7bc6c23dfa | |||
| 851ce36250 | |||
| d631088566 | |||
| f0bf733309 | |||
| 65af7dd8f8 | |||
| 74c666aaa2 | |||
| 45f9aca7e5 | |||
| 9fb624f390 | |||
| 962e51320b | |||
| 44932923eb | |||
| ffcf6dfde6 | |||
| be52eb153c | |||
| bd97c6b708 | |||
| 9940cbfa87 | |||
| 77aeb9a421 | |||
| 2bad8b9f29 | |||
| 8e943b2ce1 | |||
| 5d3ab4f333 | |||
| 1047d08835 | |||
| 516cc258f9 | |||
| 7c2aa1dc20 | |||
| 035f1e12e1 | |||
| 4c93202ee4 | |||
| 227046bdb0 | |||
| 83b123f1f6 | |||
| 320ef15ee9 | |||
| 6905c61912 | |||
| 494bde785e | |||
| 732ab38ca6 | |||
| ba38aa56a5 | |||
| 0a48c5a712 | |||
| 133ab91c8d | |||
| 7a672bd2b2 | |||
| 7dee6f51a3 | |||
| 3c029eee29 | |||
| 1a8f9d1ecb |
2
.github/workflows/pypi-release.yml
vendored
2
.github/workflows/pypi-release.yml
vendored
@ -28,7 +28,7 @@ jobs:
|
||||
run: twine check dist/*
|
||||
|
||||
- name: check PyPI versions
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3' || github.ref == 'refs/heads/v3.3.0post1'
|
||||
if: github.ref == 'refs/heads/main' || startsWith(github.ref, 'refs/heads/release/')
|
||||
run: |
|
||||
pip install --upgrade requests
|
||||
python -c "\
|
||||
|
||||
@ -8,28 +8,42 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
--------------------------------
|
||||
- Community Nodes
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
+ [Grid to Gif](#grid-to-gif)
|
||||
+ [Halftone](#halftone)
|
||||
+ [Ideal Size](#ideal-size)
|
||||
+ [Image and Mask Composition Pack](#image-and-mask-composition-pack)
|
||||
+ [Image to Character Art Image Nodes](#image-to-character-art-image-nodes)
|
||||
+ [Image Picker](#image-picker)
|
||||
+ [Load Video Frame](#load-video-frame)
|
||||
+ [Make 3D](#make-3d)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Retroize](#retroize)
|
||||
+ [Size Stepper Nodes](#size-stepper-nodes)
|
||||
+ [Text font to Image](#text-font-to-image)
|
||||
+ [Thresholding](#thresholding)
|
||||
+ [XY Image to Grid and Images to Grids nodes](#xy-image-to-grid-and-images-to-grids-nodes)
|
||||
- [Example Node Template](#example-node-template)
|
||||
- [Disclaimer](#disclaimer)
|
||||
- [Help](#help)
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
### Depth Map from Wavefront OBJ
|
||||
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Output Examples**
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
@ -39,68 +53,19 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
**Node Link:** https://github.com/JPPhoto/film-grain-node
|
||||
|
||||
--------------------------------
|
||||
### Image Picker
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" style="width: 30%" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" style="width: 30%" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" style="width: 30%" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
{: style="height:512px;width:512px"}
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||

|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/generative-grammar-prompt-nodes/main/lookuptables_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### GPT2RandomPromptMaker
|
||||
@ -113,76 +78,49 @@ CMYK Halftone Output:
|
||||
|
||||
Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
|
||||
|
||||

|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/8496ba09-bcdd-4ff7-8076-ff213b6a1e4c" width="200" />
|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
**Description:** One node that turns a grid image into an image collection, one node that turns an image collection into a gif.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
**Output Examples**
|
||||
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
### Oobabooga
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
**Example:**
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/fd5efb9f-4355-4409-a1c2-c1ca99e0cab4" width="300" />
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
Halftone Output:
|
||||
|
||||
*can return*
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/7e606f29-e68f-4d46-b3d5-97f799a4ec2f" width="300" />
|
||||
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
CMYK Halftone Output:
|
||||
|
||||

|
||||
|
||||
**Requirement**
|
||||
|
||||
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independantly of the LLM's output.
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c59c578f-db8e-4d66-8c66-2851752d75ea" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Depth Map from Wavefront OBJ
|
||||
### Ideal Size
|
||||
|
||||
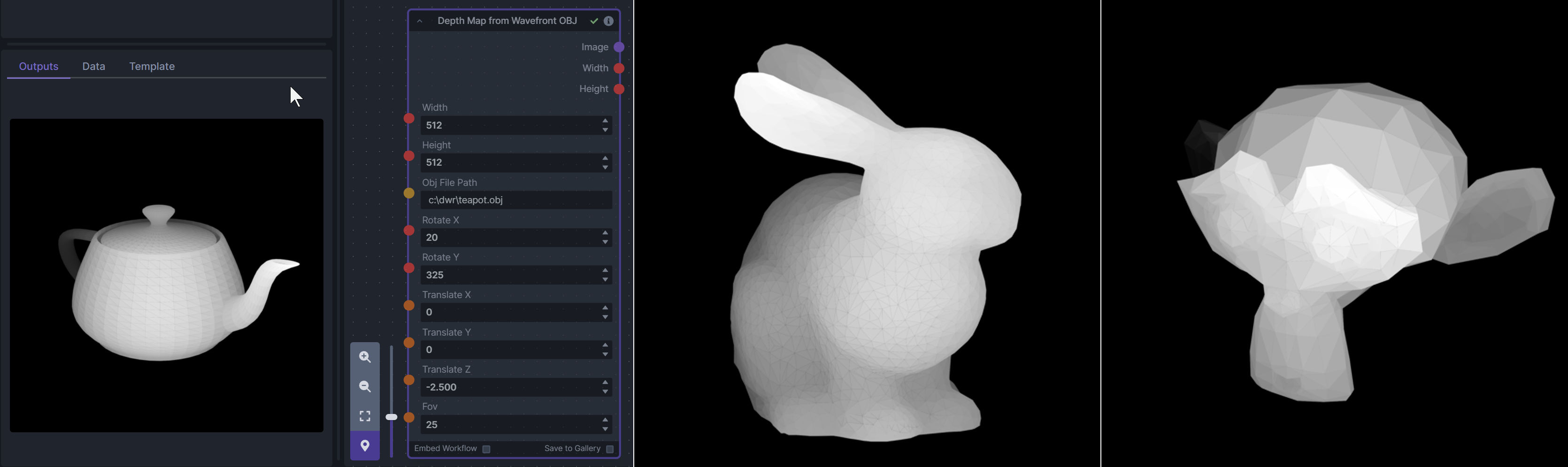
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
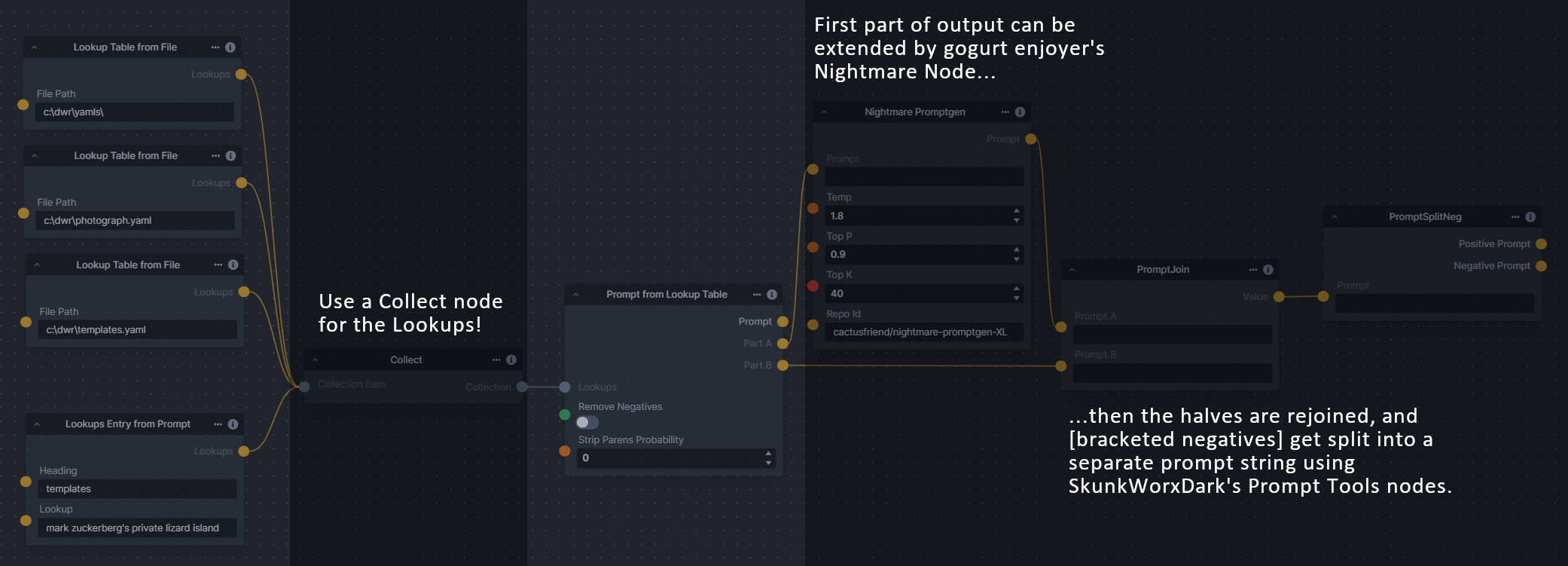
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no more nonterminal terms remain in the string.
|
||||
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
|
||||
--------------------------------
|
||||
### Image and Mask Composition Pack
|
||||
@ -209,44 +147,87 @@ This includes 15 Nodes:
|
||||
|
||||
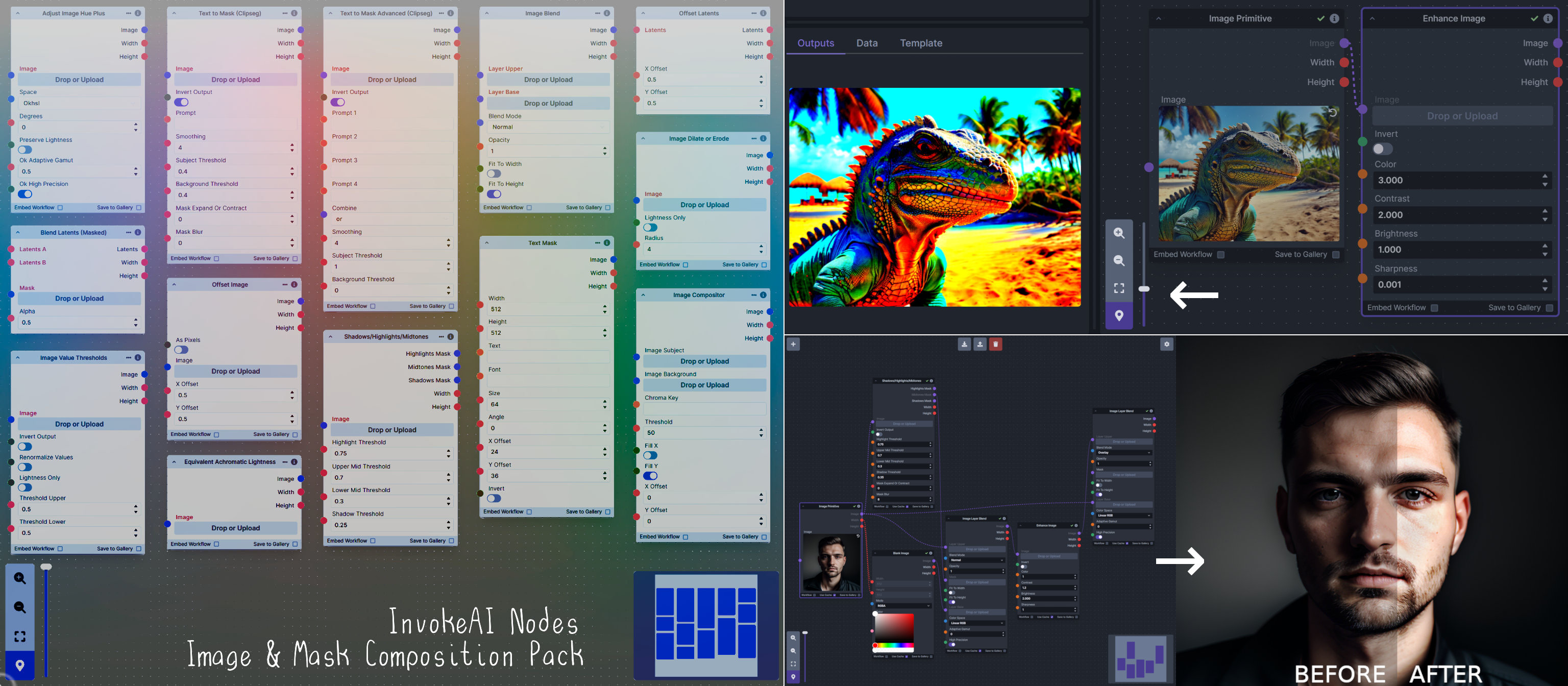
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Nodes and Output Examples:**
|
||||
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/composition-nodes/main/composition_pack_overview.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
### Image to Character Art Image Nodes
|
||||
|
||||
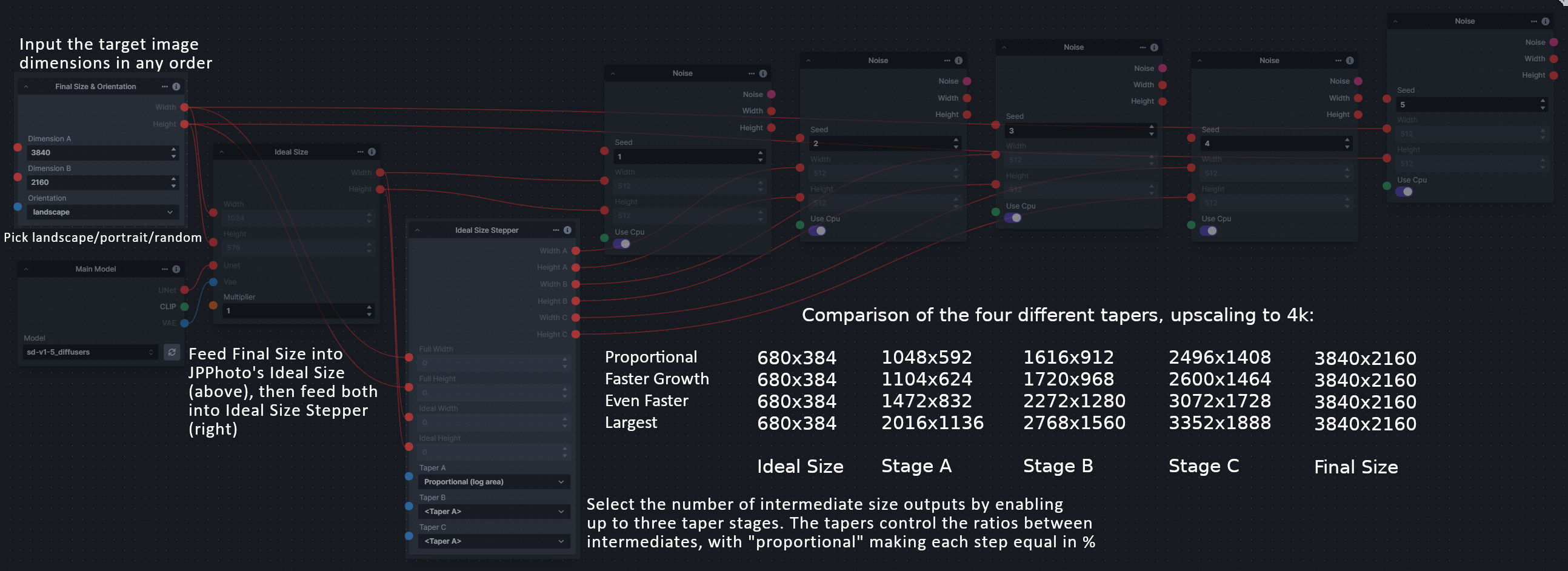
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||

|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||

|
||||

|
||||

|
||||
<img src="https://user-images.githubusercontent.com/115216705/271817646-8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056.png" width="300" /><img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image Picker
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
|
||||
<img src="https://github.com/helix4u/load_video_frame/blob/main/testmp4_embed_converted.gif" width="500" />
|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-1.png" width="300" />
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-2.png" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
|
||||
**Example:**
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
|
||||
*can return*
|
||||
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
|
||||
<img src="https://github.com/sammyf/oobabooga-node/assets/42468608/cecdd820-93dd-4c35-abbf-607e001fb2ed" width="300" />
|
||||
|
||||
**Requirement**
|
||||
|
||||
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independently of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These were written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
@ -263,51 +244,83 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||
<img src="https://github.com/Ar7ific1al/InvokeAI_nodes_retroize/assets/2306586/de8b4fa6-324c-4c2d-b36c-297600c73974" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/size-stepper-nodes/main/size_nodes_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/c21b0af3-d9c6-4c16-9152-846a23effd36" width="300" />
|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/915f1a53-968e-43eb-aa61-07cd8f1a733a" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/821ef89e-8a60-44f5-b94e-471a9d8690cc" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/2befcb6d-49f4-4bfd-b5fc-1fee19274f89" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c88ada13-fb3d-484c-a4fe-947b44712632" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then multiple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporting nodes. See example node setups for more details.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image to Character Art Image Node's
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/115216705/8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image colletion, one node that turns an image collection into a gif
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
@ -318,7 +331,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
{: style="height:115px;width:240px"}
|
||||
</br><img src="https://invoke-ai.github.io/InvokeAI/assets/invoke_ai_banner.png" width="500" />
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
@ -42,7 +42,7 @@ async def upload_image(
|
||||
crop_visible: Optional[bool] = Query(default=False, description="Whether to crop the image"),
|
||||
) -> ImageDTO:
|
||||
"""Uploads an image"""
|
||||
if not file.content_type.startswith("image"):
|
||||
if not file.content_type or not file.content_type.startswith("image"):
|
||||
raise HTTPException(status_code=415, detail="Not an image")
|
||||
|
||||
contents = await file.read()
|
||||
|
||||
@ -2,11 +2,11 @@
|
||||
|
||||
|
||||
import pathlib
|
||||
from typing import List, Literal, Optional, Union
|
||||
from typing import Annotated, List, Literal, Optional, Union
|
||||
|
||||
from fastapi import Body, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, parse_obj_as
|
||||
from pydantic import BaseModel, ConfigDict, Field, TypeAdapter
|
||||
from starlette.exceptions import HTTPException
|
||||
|
||||
from invokeai.backend import BaseModelType, ModelType
|
||||
@ -23,8 +23,14 @@ from ..dependencies import ApiDependencies
|
||||
models_router = APIRouter(prefix="/v1/models", tags=["models"])
|
||||
|
||||
UpdateModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
update_models_response_adapter = TypeAdapter(UpdateModelResponse)
|
||||
|
||||
ImportModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
import_models_response_adapter = TypeAdapter(ImportModelResponse)
|
||||
|
||||
ConvertModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
convert_models_response_adapter = TypeAdapter(ConvertModelResponse)
|
||||
|
||||
MergeModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
ImportModelAttributes = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
|
||||
@ -32,6 +38,11 @@ ImportModelAttributes = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
class ModelsList(BaseModel):
|
||||
models: list[Union[tuple(OPENAPI_MODEL_CONFIGS)]]
|
||||
|
||||
model_config = ConfigDict(use_enum_values=True)
|
||||
|
||||
|
||||
models_list_adapter = TypeAdapter(ModelsList)
|
||||
|
||||
|
||||
@models_router.get(
|
||||
"/",
|
||||
@ -49,7 +60,7 @@ async def list_models(
|
||||
models_raw.extend(ApiDependencies.invoker.services.model_manager.list_models(base_model, model_type))
|
||||
else:
|
||||
models_raw = ApiDependencies.invoker.services.model_manager.list_models(None, model_type)
|
||||
models = parse_obj_as(ModelsList, {"models": models_raw})
|
||||
models = models_list_adapter.validate_python({"models": models_raw})
|
||||
return models
|
||||
|
||||
|
||||
@ -105,11 +116,14 @@ async def update_model(
|
||||
info.path = new_info.get("path")
|
||||
|
||||
# replace empty string values with None/null to avoid phenomenon of vae: ''
|
||||
info_dict = info.dict()
|
||||
info_dict = info.model_dump()
|
||||
info_dict = {x: info_dict[x] if info_dict[x] else None for x in info_dict.keys()}
|
||||
|
||||
ApiDependencies.invoker.services.model_manager.update_model(
|
||||
model_name=model_name, base_model=base_model, model_type=model_type, model_attributes=info_dict
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
model_attributes=info_dict,
|
||||
)
|
||||
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
@ -117,7 +131,7 @@ async def update_model(
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
model_response = parse_obj_as(UpdateModelResponse, model_raw)
|
||||
model_response = update_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
@ -152,13 +166,15 @@ async def import_model(
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
location = location.strip("\"' ")
|
||||
items_to_import = {location}
|
||||
prediction_types = {x.value: x for x in SchedulerPredictionType}
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
|
||||
try:
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.heuristic_import(
|
||||
items_to_import=items_to_import, prediction_type_helper=lambda x: prediction_types.get(prediction_type)
|
||||
items_to_import=items_to_import,
|
||||
prediction_type_helper=lambda x: prediction_types.get(prediction_type),
|
||||
)
|
||||
info = installed_models.get(location)
|
||||
|
||||
@ -170,7 +186,7 @@ async def import_model(
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.name, base_model=info.base_model, model_type=info.model_type
|
||||
)
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
return import_models_response_adapter.validate_python(model_raw)
|
||||
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
@ -204,13 +220,18 @@ async def add_model(
|
||||
|
||||
try:
|
||||
ApiDependencies.invoker.services.model_manager.add_model(
|
||||
info.model_name, info.base_model, info.model_type, model_attributes=info.dict()
|
||||
info.model_name,
|
||||
info.base_model,
|
||||
info.model_type,
|
||||
model_attributes=info.model_dump(),
|
||||
)
|
||||
logger.info(f"Successfully added {info.model_name}")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.model_name, base_model=info.base_model, model_type=info.model_type
|
||||
model_name=info.model_name,
|
||||
base_model=info.base_model,
|
||||
model_type=info.model_type,
|
||||
)
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
return import_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
@ -222,7 +243,10 @@ async def add_model(
|
||||
@models_router.delete(
|
||||
"/{base_model}/{model_type}/{model_name}",
|
||||
operation_id="del_model",
|
||||
responses={204: {"description": "Model deleted successfully"}, 404: {"description": "Model not found"}},
|
||||
responses={
|
||||
204: {"description": "Model deleted successfully"},
|
||||
404: {"description": "Model not found"},
|
||||
},
|
||||
status_code=204,
|
||||
response_model=None,
|
||||
)
|
||||
@ -278,7 +302,7 @@ async def convert_model(
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name, base_model=base_model, model_type=model_type
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
response = convert_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=f"Model '{model_name}' not found: {str(e)}")
|
||||
except ValueError as e:
|
||||
@ -301,7 +325,8 @@ async def search_for_models(
|
||||
) -> List[pathlib.Path]:
|
||||
if not search_path.is_dir():
|
||||
raise HTTPException(
|
||||
status_code=404, detail=f"The search path '{search_path}' does not exist or is not directory"
|
||||
status_code=404,
|
||||
detail=f"The search path '{search_path}' does not exist or is not directory",
|
||||
)
|
||||
return ApiDependencies.invoker.services.model_manager.search_for_models(search_path)
|
||||
|
||||
@ -336,6 +361,26 @@ async def sync_to_config() -> bool:
|
||||
return True
|
||||
|
||||
|
||||
# There's some weird pydantic-fastapi behaviour that requires this to be a separate class
|
||||
# TODO: After a few updates, see if it works inside the route operation handler?
|
||||
class MergeModelsBody(BaseModel):
|
||||
model_names: List[str] = Field(description="model name", min_length=2, max_length=3)
|
||||
merged_model_name: Optional[str] = Field(description="Name of destination model")
|
||||
alpha: Optional[float] = Field(description="Alpha weighting strength to apply to 2d and 3d models", default=0.5)
|
||||
interp: Optional[MergeInterpolationMethod] = Field(description="Interpolation method")
|
||||
force: Optional[bool] = Field(
|
||||
description="Force merging of models created with different versions of diffusers",
|
||||
default=False,
|
||||
)
|
||||
|
||||
merge_dest_directory: Optional[str] = Field(
|
||||
description="Save the merged model to the designated directory (with 'merged_model_name' appended)",
|
||||
default=None,
|
||||
)
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@models_router.put(
|
||||
"/merge/{base_model}",
|
||||
operation_id="merge_models",
|
||||
@ -348,31 +393,23 @@ async def sync_to_config() -> bool:
|
||||
response_model=MergeModelResponse,
|
||||
)
|
||||
async def merge_models(
|
||||
body: Annotated[MergeModelsBody, Body(description="Model configuration", embed=True)],
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_names: List[str] = Body(description="model name", min_items=2, max_items=3),
|
||||
merged_model_name: Optional[str] = Body(description="Name of destination model"),
|
||||
alpha: Optional[float] = Body(description="Alpha weighting strength to apply to 2d and 3d models", default=0.5),
|
||||
interp: Optional[MergeInterpolationMethod] = Body(description="Interpolation method"),
|
||||
force: Optional[bool] = Body(
|
||||
description="Force merging of models created with different versions of diffusers", default=False
|
||||
),
|
||||
merge_dest_directory: Optional[str] = Body(
|
||||
description="Save the merged model to the designated directory (with 'merged_model_name' appended)",
|
||||
default=None,
|
||||
),
|
||||
) -> MergeModelResponse:
|
||||
"""Convert a checkpoint model into a diffusers model"""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
try:
|
||||
logger.info(f"Merging models: {model_names} into {merge_dest_directory or '<MODELS>'}/{merged_model_name}")
|
||||
dest = pathlib.Path(merge_dest_directory) if merge_dest_directory else None
|
||||
logger.info(
|
||||
f"Merging models: {body.model_names} into {body.merge_dest_directory or '<MODELS>'}/{body.merged_model_name}"
|
||||
)
|
||||
dest = pathlib.Path(body.merge_dest_directory) if body.merge_dest_directory else None
|
||||
result = ApiDependencies.invoker.services.model_manager.merge_models(
|
||||
model_names,
|
||||
base_model,
|
||||
merged_model_name=merged_model_name or "+".join(model_names),
|
||||
alpha=alpha,
|
||||
interp=interp,
|
||||
force=force,
|
||||
model_names=body.model_names,
|
||||
base_model=base_model,
|
||||
merged_model_name=body.merged_model_name or "+".join(body.model_names),
|
||||
alpha=body.alpha,
|
||||
interp=body.interp,
|
||||
force=body.force,
|
||||
merge_dest_directory=dest,
|
||||
)
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
@ -380,9 +417,12 @@ async def merge_models(
|
||||
base_model=base_model,
|
||||
model_type=ModelType.Main,
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
response = convert_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException:
|
||||
raise HTTPException(status_code=404, detail=f"One or more of the models '{model_names}' not found")
|
||||
raise HTTPException(
|
||||
status_code=404,
|
||||
detail=f"One or more of the models '{body.model_names}' not found",
|
||||
)
|
||||
except ValueError as e:
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
return response
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
from typing import Optional
|
||||
from typing import Optional, Union
|
||||
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
from fastapi import Body
|
||||
@ -27,6 +27,7 @@ async def parse_dynamicprompts(
|
||||
combinatorial: bool = Body(default=True, description="Whether to use the combinatorial generator"),
|
||||
) -> DynamicPromptsResponse:
|
||||
"""Creates a batch process"""
|
||||
generator: Union[RandomPromptGenerator, CombinatorialPromptGenerator]
|
||||
try:
|
||||
error: Optional[str] = None
|
||||
if combinatorial:
|
||||
|
||||
@ -30,8 +30,8 @@ class SocketIO:
|
||||
|
||||
async def _handle_sub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
async def _handle_unsub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
@ -22,7 +22,7 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from pydantic.schema import schema
|
||||
from pydantic.json_schema import models_json_schema
|
||||
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
@ -31,7 +31,7 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
|
||||
from ..backend.util.logging import InvokeAILogger
|
||||
from .api.dependencies import ApiDependencies
|
||||
from .api.routers import app_info, board_images, boards, images, models, session_queue, sessions, utilities
|
||||
from .api.routers import app_info, board_images, boards, images, models, session_queue, utilities
|
||||
from .api.sockets import SocketIO
|
||||
from .invocations.baseinvocation import BaseInvocation, UIConfigBase, _InputField, _OutputField
|
||||
|
||||
@ -51,7 +51,7 @@ mimetypes.add_type("text/css", ".css")
|
||||
|
||||
# Create the app
|
||||
# TODO: create this all in a method so configuration/etc. can be passed in?
|
||||
app = FastAPI(title="Invoke AI", docs_url=None, redoc_url=None)
|
||||
app = FastAPI(title="Invoke AI", docs_url=None, redoc_url=None, separate_input_output_schemas=False)
|
||||
|
||||
# Add event handler
|
||||
event_handler_id: int = id(app)
|
||||
@ -63,18 +63,18 @@ app.add_middleware(
|
||||
|
||||
socket_io = SocketIO(app)
|
||||
|
||||
app.add_middleware(
|
||||
CORSMiddleware,
|
||||
allow_origins=app_config.allow_origins,
|
||||
allow_credentials=app_config.allow_credentials,
|
||||
allow_methods=app_config.allow_methods,
|
||||
allow_headers=app_config.allow_headers,
|
||||
)
|
||||
|
||||
|
||||
# Add startup event to load dependencies
|
||||
@app.on_event("startup")
|
||||
async def startup_event():
|
||||
app.add_middleware(
|
||||
CORSMiddleware,
|
||||
allow_origins=app_config.allow_origins,
|
||||
allow_credentials=app_config.allow_credentials,
|
||||
allow_methods=app_config.allow_methods,
|
||||
allow_headers=app_config.allow_headers,
|
||||
)
|
||||
|
||||
ApiDependencies.initialize(config=app_config, event_handler_id=event_handler_id, logger=logger)
|
||||
|
||||
|
||||
@ -85,12 +85,7 @@ async def shutdown_event():
|
||||
|
||||
|
||||
# Include all routers
|
||||
# TODO: REMOVE
|
||||
# app.include_router(
|
||||
# invocation.invocation_router,
|
||||
# prefix = '/api')
|
||||
|
||||
app.include_router(sessions.session_router, prefix="/api")
|
||||
# app.include_router(sessions.session_router, prefix="/api")
|
||||
|
||||
app.include_router(utilities.utilities_router, prefix="/api")
|
||||
|
||||
@ -117,6 +112,7 @@ def custom_openapi():
|
||||
description="An API for invoking AI image operations",
|
||||
version="1.0.0",
|
||||
routes=app.routes,
|
||||
separate_input_output_schemas=False, # https://fastapi.tiangolo.com/how-to/separate-openapi-schemas/
|
||||
)
|
||||
|
||||
# Add all outputs
|
||||
@ -127,29 +123,32 @@ def custom_openapi():
|
||||
output_type = signature(invoker.invoke).return_annotation
|
||||
output_types.add(output_type)
|
||||
|
||||
output_schemas = schema(output_types, ref_prefix="#/components/schemas/")
|
||||
for schema_key, output_schema in output_schemas["definitions"].items():
|
||||
output_schema["class"] = "output"
|
||||
openapi_schema["components"]["schemas"][schema_key] = output_schema
|
||||
|
||||
output_schemas = models_json_schema(
|
||||
models=[(o, "serialization") for o in output_types], ref_template="#/components/schemas/{model}"
|
||||
)
|
||||
for schema_key, output_schema in output_schemas[1]["$defs"].items():
|
||||
# TODO: note that we assume the schema_key here is the TYPE.__name__
|
||||
# This could break in some cases, figure out a better way to do it
|
||||
output_type_titles[schema_key] = output_schema["title"]
|
||||
|
||||
# Add Node Editor UI helper schemas
|
||||
ui_config_schemas = schema([UIConfigBase, _InputField, _OutputField], ref_prefix="#/components/schemas/")
|
||||
for schema_key, ui_config_schema in ui_config_schemas["definitions"].items():
|
||||
ui_config_schemas = models_json_schema(
|
||||
[(UIConfigBase, "serialization"), (_InputField, "serialization"), (_OutputField, "serialization")],
|
||||
ref_template="#/components/schemas/{model}",
|
||||
)
|
||||
for schema_key, ui_config_schema in ui_config_schemas[1]["$defs"].items():
|
||||
openapi_schema["components"]["schemas"][schema_key] = ui_config_schema
|
||||
|
||||
# Add a reference to the output type to additionalProperties of the invoker schema
|
||||
for invoker in all_invocations:
|
||||
invoker_name = invoker.__name__
|
||||
output_type = signature(invoker.invoke).return_annotation
|
||||
output_type = signature(obj=invoker.invoke).return_annotation
|
||||
output_type_title = output_type_titles[output_type.__name__]
|
||||
invoker_schema = openapi_schema["components"]["schemas"][invoker_name]
|
||||
invoker_schema = openapi_schema["components"]["schemas"][f"{invoker_name}"]
|
||||
outputs_ref = {"$ref": f"#/components/schemas/{output_type_title}"}
|
||||
invoker_schema["output"] = outputs_ref
|
||||
invoker_schema["class"] = "invocation"
|
||||
openapi_schema["components"]["schemas"][f"{output_type_title}"]["class"] = "output"
|
||||
|
||||
from invokeai.backend.model_management.models import get_model_config_enums
|
||||
|
||||
@ -172,7 +171,7 @@ def custom_openapi():
|
||||
return app.openapi_schema
|
||||
|
||||
|
||||
app.openapi = custom_openapi
|
||||
app.openapi = custom_openapi # type: ignore [method-assign] # this is a valid assignment
|
||||
|
||||
# Override API doc favicons
|
||||
app.mount("/static", StaticFiles(directory=Path(web_dir.__path__[0], "static/dream_web")), name="static")
|
||||
|
||||
@ -24,8 +24,8 @@ def add_field_argument(command_parser, name: str, field, default_override=None):
|
||||
if field.default_factory is None
|
||||
else field.default_factory()
|
||||
)
|
||||
if get_origin(field.type_) == Literal:
|
||||
allowed_values = get_args(field.type_)
|
||||
if get_origin(field.annotation) == Literal:
|
||||
allowed_values = get_args(field.annotation)
|
||||
allowed_types = set()
|
||||
for val in allowed_values:
|
||||
allowed_types.add(type(val))
|
||||
@ -38,15 +38,15 @@ def add_field_argument(command_parser, name: str, field, default_override=None):
|
||||
type=field_type,
|
||||
default=default,
|
||||
choices=allowed_values,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
else:
|
||||
command_parser.add_argument(
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
|
||||
@ -142,7 +142,6 @@ class BaseCommand(ABC, BaseModel):
|
||||
"""A CLI command"""
|
||||
|
||||
# All commands must include a type name like this:
|
||||
# type: Literal['your_command_name'] = 'your_command_name'
|
||||
|
||||
@classmethod
|
||||
def get_all_subclasses(cls):
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -2,7 +2,7 @@
|
||||
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
from pydantic import ValidationInfo, field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import IntegerCollectionOutput
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
@ -20,9 +20,9 @@ class RangeInvocation(BaseInvocation):
|
||||
stop: int = InputField(default=10, description="The stop of the range")
|
||||
step: int = InputField(default=1, description="The step of the range")
|
||||
|
||||
@validator("stop")
|
||||
def stop_gt_start(cls, v, values):
|
||||
if "start" in values and v <= values["start"]:
|
||||
@field_validator("stop")
|
||||
def stop_gt_start(cls, v: int, info: ValidationInfo):
|
||||
if "start" in info.data and v <= info.data["start"]:
|
||||
raise ValueError("stop must be greater than start")
|
||||
return v
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Union
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import torch
|
||||
from compel import Compel, ReturnedEmbeddingsType
|
||||
@ -43,7 +43,13 @@ class ConditioningFieldData:
|
||||
# PerpNeg = "perp_neg"
|
||||
|
||||
|
||||
@invocation("compel", title="Prompt", tags=["prompt", "compel"], category="conditioning", version="1.0.0")
|
||||
@invocation(
|
||||
"compel",
|
||||
title="Prompt",
|
||||
tags=["prompt", "compel"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class CompelInvocation(BaseInvocation):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
@ -60,23 +66,21 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
context=context,
|
||||
tokenizer_info = context.get_model(
|
||||
**self.clip.tokenizer.model_dump(),
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
context=context,
|
||||
text_encoder_info = context.get_model(
|
||||
**self.clip.text_encoder.model_dump(),
|
||||
)
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.clip.loras:
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.get_model(**lora.model_dump(exclude={"weight"}))
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
# loras = [(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
# loras = [(context.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
|
||||
ti_list = []
|
||||
for trigger in re.findall(r"<[a-zA-Z0-9., _-]+>", self.prompt):
|
||||
@ -85,11 +89,10 @@ class CompelInvocation(BaseInvocation):
|
||||
ti_list.append(
|
||||
(
|
||||
name,
|
||||
context.services.model_manager.get_model(
|
||||
context.get_model(
|
||||
model_name=name,
|
||||
base_model=self.clip.text_encoder.base_model,
|
||||
model_type=ModelType.TextualInversion,
|
||||
context=context,
|
||||
).context.model,
|
||||
)
|
||||
)
|
||||
@ -118,7 +121,7 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
conjunction = Compel.parse_prompt_string(self.prompt)
|
||||
|
||||
if context.services.configuration.log_tokenization:
|
||||
if context.config.log_tokenization:
|
||||
log_tokenization_for_conjunction(conjunction, tokenizer)
|
||||
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
@ -139,8 +142,7 @@ class CompelInvocation(BaseInvocation):
|
||||
]
|
||||
)
|
||||
|
||||
conditioning_name = f"{context.graph_execution_state_id}_{self.id}_conditioning"
|
||||
context.services.latents.save(conditioning_name, conditioning_data)
|
||||
conditioning_name = context.save_conditioning(conditioning_data)
|
||||
|
||||
return ConditioningOutput(
|
||||
conditioning=ConditioningField(
|
||||
@ -160,11 +162,11 @@ class SDXLPromptInvocationBase:
|
||||
zero_on_empty: bool,
|
||||
):
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**clip_field.tokenizer.dict(),
|
||||
**clip_field.tokenizer.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**clip_field.text_encoder.dict(),
|
||||
**clip_field.text_encoder.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -172,7 +174,11 @@ class SDXLPromptInvocationBase:
|
||||
if prompt == "" and zero_on_empty:
|
||||
cpu_text_encoder = text_encoder_info.context.model
|
||||
c = torch.zeros(
|
||||
(1, cpu_text_encoder.config.max_position_embeddings, cpu_text_encoder.config.hidden_size),
|
||||
(
|
||||
1,
|
||||
cpu_text_encoder.config.max_position_embeddings,
|
||||
cpu_text_encoder.config.hidden_size,
|
||||
),
|
||||
dtype=text_encoder_info.context.cache.precision,
|
||||
)
|
||||
if get_pooled:
|
||||
@ -186,7 +192,9 @@ class SDXLPromptInvocationBase:
|
||||
|
||||
def _lora_loader():
|
||||
for lora in clip_field.loras:
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.model_dump(exclude={"weight"}), context=context
|
||||
)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
@ -273,8 +281,16 @@ class SDXLPromptInvocationBase:
|
||||
class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
prompt: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
style: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
prompt: str = InputField(
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
style: str = InputField(
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
original_width: int = InputField(default=1024, description="")
|
||||
original_height: int = InputField(default=1024, description="")
|
||||
crop_top: int = InputField(default=0, description="")
|
||||
@ -310,7 +326,9 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
[
|
||||
c1,
|
||||
torch.zeros(
|
||||
(c1.shape[0], c2.shape[1] - c1.shape[1], c1.shape[2]), device=c1.device, dtype=c1.dtype
|
||||
(c1.shape[0], c2.shape[1] - c1.shape[1], c1.shape[2]),
|
||||
device=c1.device,
|
||||
dtype=c1.dtype,
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
@ -321,7 +339,9 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
[
|
||||
c2,
|
||||
torch.zeros(
|
||||
(c2.shape[0], c1.shape[1] - c2.shape[1], c2.shape[2]), device=c2.device, dtype=c2.dtype
|
||||
(c2.shape[0], c1.shape[1] - c2.shape[1], c2.shape[2]),
|
||||
device=c2.device,
|
||||
dtype=c2.dtype,
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
@ -359,7 +379,9 @@ class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
style: str = InputField(
|
||||
default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
) # TODO: ?
|
||||
original_width: int = InputField(default=1024, description="")
|
||||
original_height: int = InputField(default=1024, description="")
|
||||
@ -403,10 +425,16 @@ class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase
|
||||
class ClipSkipInvocationOutput(BaseInvocationOutput):
|
||||
"""Clip skip node output"""
|
||||
|
||||
clip: ClipField = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
|
||||
|
||||
@invocation("clip_skip", title="CLIP Skip", tags=["clipskip", "clip", "skip"], category="conditioning", version="1.0.0")
|
||||
@invocation(
|
||||
"clip_skip",
|
||||
title="CLIP Skip",
|
||||
tags=["clipskip", "clip", "skip"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ClipSkipInvocation(BaseInvocation):
|
||||
"""Skip layers in clip text_encoder model."""
|
||||
|
||||
@ -421,7 +449,9 @@ class ClipSkipInvocation(BaseInvocation):
|
||||
|
||||
|
||||
def get_max_token_count(
|
||||
tokenizer, prompt: Union[FlattenedPrompt, Blend, Conjunction], truncate_if_too_long=False
|
||||
tokenizer,
|
||||
prompt: Union[FlattenedPrompt, Blend, Conjunction],
|
||||
truncate_if_too_long=False,
|
||||
) -> int:
|
||||
if type(prompt) is Blend:
|
||||
blend: Blend = prompt
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
# initial implementation by Gregg Helt, 2023
|
||||
# heavily leverages controlnet_aux package: https://github.com/patrickvonplaten/controlnet_aux
|
||||
from builtins import bool, float
|
||||
from typing import Dict, List, Literal, Optional, Union
|
||||
from typing import Dict, List, Literal, Union
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
@ -24,7 +24,7 @@ from controlnet_aux import (
|
||||
)
|
||||
from controlnet_aux.util import HWC3, ade_palette
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field, validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
@ -57,6 +57,8 @@ class ControlNetModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the ControlNet model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class ControlField(BaseModel):
|
||||
image: ImageField = Field(description="The control image")
|
||||
@ -71,7 +73,7 @@ class ControlField(BaseModel):
|
||||
control_mode: CONTROLNET_MODE_VALUES = Field(default="balanced", description="The control mode to use")
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
@validator("control_weight")
|
||||
@field_validator("control_weight")
|
||||
def validate_control_weight(cls, v):
|
||||
"""Validate that all control weights in the valid range"""
|
||||
if isinstance(v, list):
|
||||
@ -124,9 +126,7 @@ class ControlNetInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"image_processor", title="Base Image Processor", tags=["controlnet"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
# This invocation exists for other invocations to subclass it - do not register with @invocation!
|
||||
class ImageProcessorInvocation(BaseInvocation):
|
||||
"""Base class for invocations that preprocess images for ControlNet"""
|
||||
|
||||
@ -393,9 +393,9 @@ class ContentShuffleImageProcessorInvocation(ImageProcessorInvocation):
|
||||
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
h: Optional[int] = InputField(default=512, ge=0, description="Content shuffle `h` parameter")
|
||||
w: Optional[int] = InputField(default=512, ge=0, description="Content shuffle `w` parameter")
|
||||
f: Optional[int] = InputField(default=256, ge=0, description="Content shuffle `f` parameter")
|
||||
h: int = InputField(default=512, ge=0, description="Content shuffle `h` parameter")
|
||||
w: int = InputField(default=512, ge=0, description="Content shuffle `w` parameter")
|
||||
f: int = InputField(default=256, ge=0, description="Content shuffle `f` parameter")
|
||||
|
||||
def run_processor(self, image):
|
||||
content_shuffle_processor = ContentShuffleDetector()
|
||||
@ -575,14 +575,14 @@ class ColorMapImageProcessorInvocation(ImageProcessorInvocation):
|
||||
|
||||
def run_processor(self, image: Image.Image):
|
||||
image = image.convert("RGB")
|
||||
image = np.array(image, dtype=np.uint8)
|
||||
height, width = image.shape[:2]
|
||||
np_image = np.array(image, dtype=np.uint8)
|
||||
height, width = np_image.shape[:2]
|
||||
|
||||
width_tile_size = min(self.color_map_tile_size, width)
|
||||
height_tile_size = min(self.color_map_tile_size, height)
|
||||
|
||||
color_map = cv2.resize(
|
||||
image,
|
||||
np_image,
|
||||
(width // width_tile_size, height // height_tile_size),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
|
||||
@ -8,7 +8,7 @@ import numpy as np
|
||||
from mediapipe.python.solutions.face_mesh import FaceMesh # type: ignore[import]
|
||||
from PIL import Image, ImageDraw, ImageFilter, ImageFont, ImageOps
|
||||
from PIL.Image import Image as ImageType
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
import invokeai.assets.fonts as font_assets
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
@ -46,6 +46,8 @@ class FaceResultData(TypedDict):
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
chunk_x_offset: int
|
||||
chunk_y_offset: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
@ -78,6 +80,48 @@ FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def coalesce_faces(face1: FaceResultData, face2: FaceResultData) -> FaceResultData:
|
||||
face1_x_offset = face1["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face2_x_offset = face2["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face1_y_offset = face1["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
face2_y_offset = face2["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
|
||||
new_im_width = (
|
||||
max(face1["image"].width, face2["image"].width)
|
||||
+ max(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
- min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
)
|
||||
new_im_height = (
|
||||
max(face1["image"].height, face2["image"].height)
|
||||
+ max(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
- min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
)
|
||||
pil_image = Image.new(mode=face1["image"].mode, size=(new_im_width, new_im_height))
|
||||
pil_image.paste(face1["image"], (face1_x_offset, face1_y_offset))
|
||||
pil_image.paste(face2["image"], (face2_x_offset, face2_y_offset))
|
||||
|
||||
# Mask images are always from the origin
|
||||
new_mask_im_width = max(face1["mask"].width, face2["mask"].width)
|
||||
new_mask_im_height = max(face1["mask"].height, face2["mask"].height)
|
||||
mask_pil = create_white_image(new_mask_im_width, new_mask_im_height)
|
||||
black_image = create_black_image(face1["mask"].width, face1["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face1["mask"]))
|
||||
black_image = create_black_image(face2["mask"].width, face2["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face2["mask"]))
|
||||
|
||||
new_face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil,
|
||||
x_center=max(face1["x_center"], face2["x_center"]),
|
||||
y_center=max(face1["y_center"], face2["y_center"]),
|
||||
mesh_width=max(face1["mesh_width"], face2["mesh_width"]),
|
||||
mesh_height=max(face1["mesh_height"], face2["mesh_height"]),
|
||||
chunk_x_offset=max(face1["chunk_x_offset"], face2["chunk_x_offset"]),
|
||||
chunk_y_offset=max(face2["chunk_y_offset"], face2["chunk_y_offset"]),
|
||||
)
|
||||
return new_face
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
@ -91,7 +135,7 @@ def prepare_faces_list(
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for face in deduped_faces:
|
||||
for idx, face in enumerate(deduped_faces):
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
@ -105,6 +149,7 @@ def prepare_faces_list(
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
deduped_faces[idx] = coalesce_faces(face, candidate)
|
||||
should_add = False
|
||||
break
|
||||
|
||||
@ -138,7 +183,6 @@ def generate_face_box_mask(
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
check_bounds: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
@ -211,33 +255,20 @@ def generate_face_box_mask(
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
left_side = x_center - mesh_width
|
||||
right_side = x_center + mesh_width
|
||||
top_side = y_center - mesh_height
|
||||
bottom_side = y_center + mesh_height
|
||||
im_width, im_height = pil_image.size
|
||||
over_w = im_width * 0.1
|
||||
over_h = im_height * 0.1
|
||||
if not check_bounds or (
|
||||
(left_side >= -over_w)
|
||||
and (right_side < im_width + over_w)
|
||||
and (top_side >= -over_h)
|
||||
and (bottom_side < im_height + over_h)
|
||||
):
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
)
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
chunk_x_offset=chunk_x_offset,
|
||||
chunk_y_offset=chunk_y_offset,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
else:
|
||||
context.services.logger.info("FaceTools --> Face out of bounds, ignoring.")
|
||||
result.append(face)
|
||||
|
||||
return result
|
||||
|
||||
@ -346,7 +377,6 @@ def get_faces_list(
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
check_bounds=False,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
@ -360,24 +390,26 @@ def get_faces_list(
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height)
|
||||
steps = int(width * 2 / height) + 1
|
||||
increment = (width - height) / (steps - 1)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height - 1, height - 1)))
|
||||
image_chunks.append(image.crop((x, 0, x + height, height)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += (width - height) / steps
|
||||
fx += increment
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width)
|
||||
steps = int(height * 2 / width) + 1
|
||||
increment = (height - width) / (steps - 1)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width - 1, y + width - 1)))
|
||||
image_chunks.append(image.crop((0, y, width, y + width)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += (height - width) / steps
|
||||
fy += increment
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
@ -404,7 +436,7 @@ def get_faces_list(
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.1")
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.2")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
@ -498,7 +530,7 @@ class FaceOffInvocation(BaseInvocation):
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.1")
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.2")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
@ -518,7 +550,7 @@ class FaceMaskInvocation(BaseInvocation):
|
||||
)
|
||||
invert_mask: bool = InputField(default=False, description="Toggle to invert the mask")
|
||||
|
||||
@validator("face_ids")
|
||||
@field_validator("face_ids")
|
||||
def validate_comma_separated_ints(cls, v) -> str:
|
||||
comma_separated_ints_regex = re.compile(r"^\d*(,\d+)*$")
|
||||
if comma_separated_ints_regex.match(v) is None:
|
||||
@ -616,7 +648,7 @@ class FaceMaskInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.1"
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.2"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
@ -36,7 +36,13 @@ class ShowImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("blank_image", title="Blank Image", tags=["image"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"blank_image",
|
||||
title="Blank Image",
|
||||
tags=["image"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class BlankImageInvocation(BaseInvocation):
|
||||
"""Creates a blank image and forwards it to the pipeline"""
|
||||
|
||||
@ -65,7 +71,13 @@ class BlankImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_crop", title="Crop Image", tags=["image", "crop"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_crop",
|
||||
title="Crop Image",
|
||||
tags=["image", "crop"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageCropInvocation(BaseInvocation):
|
||||
"""Crops an image to a specified box. The box can be outside of the image."""
|
||||
|
||||
@ -98,7 +110,13 @@ class ImageCropInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_paste", title="Paste Image", tags=["image", "paste"], category="image", version="1.0.1")
|
||||
@invocation(
|
||||
"img_paste",
|
||||
title="Paste Image",
|
||||
tags=["image", "paste"],
|
||||
category="image",
|
||||
version="1.0.1",
|
||||
)
|
||||
class ImagePasteInvocation(BaseInvocation):
|
||||
"""Pastes an image into another image."""
|
||||
|
||||
@ -151,7 +169,13 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("tomask", title="Mask from Alpha", tags=["image", "mask"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"tomask",
|
||||
title="Mask from Alpha",
|
||||
tags=["image", "mask"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskFromAlphaInvocation(BaseInvocation):
|
||||
"""Extracts the alpha channel of an image as a mask."""
|
||||
|
||||
@ -182,7 +206,13 @@ class MaskFromAlphaInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_mul", title="Multiply Images", tags=["image", "multiply"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_mul",
|
||||
title="Multiply Images",
|
||||
tags=["image", "multiply"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageMultiplyInvocation(BaseInvocation):
|
||||
"""Multiplies two images together using `PIL.ImageChops.multiply()`."""
|
||||
|
||||
@ -215,7 +245,13 @@ class ImageMultiplyInvocation(BaseInvocation):
|
||||
IMAGE_CHANNELS = Literal["A", "R", "G", "B"]
|
||||
|
||||
|
||||
@invocation("img_chan", title="Extract Image Channel", tags=["image", "channel"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_chan",
|
||||
title="Extract Image Channel",
|
||||
tags=["image", "channel"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageChannelInvocation(BaseInvocation):
|
||||
"""Gets a channel from an image."""
|
||||
|
||||
@ -247,7 +283,13 @@ class ImageChannelInvocation(BaseInvocation):
|
||||
IMAGE_MODES = Literal["L", "RGB", "RGBA", "CMYK", "YCbCr", "LAB", "HSV", "I", "F"]
|
||||
|
||||
|
||||
@invocation("img_conv", title="Convert Image Mode", tags=["image", "convert"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_conv",
|
||||
title="Convert Image Mode",
|
||||
tags=["image", "convert"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageConvertInvocation(BaseInvocation):
|
||||
"""Converts an image to a different mode."""
|
||||
|
||||
@ -276,7 +318,13 @@ class ImageConvertInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_blur", title="Blur Image", tags=["image", "blur"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_blur",
|
||||
title="Blur Image",
|
||||
tags=["image", "blur"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageBlurInvocation(BaseInvocation):
|
||||
"""Blurs an image"""
|
||||
|
||||
@ -330,7 +378,13 @@ PIL_RESAMPLING_MAP = {
|
||||
}
|
||||
|
||||
|
||||
@invocation("img_resize", title="Resize Image", tags=["image", "resize"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_resize",
|
||||
title="Resize Image",
|
||||
tags=["image", "resize"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageResizeInvocation(BaseInvocation):
|
||||
"""Resizes an image to specific dimensions"""
|
||||
|
||||
@ -343,7 +397,7 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
image = context.get_image(self.image.image_name)
|
||||
|
||||
resample_mode = PIL_RESAMPLING_MAP[self.resample_mode]
|
||||
|
||||
@ -352,25 +406,22 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
resample=resample_mode,
|
||||
)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=resize_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
image_name = context.save_image(image=resize_image)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
image=ImageField(image_name=image_name),
|
||||
width=resize_image.width,
|
||||
height=resize_image.height,
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_scale", title="Scale Image", tags=["image", "scale"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_scale",
|
||||
title="Scale Image",
|
||||
tags=["image", "scale"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageScaleInvocation(BaseInvocation):
|
||||
"""Scales an image by a factor"""
|
||||
|
||||
@ -411,7 +462,13 @@ class ImageScaleInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_lerp", title="Lerp Image", tags=["image", "lerp"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_lerp",
|
||||
title="Lerp Image",
|
||||
tags=["image", "lerp"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageLerpInvocation(BaseInvocation):
|
||||
"""Linear interpolation of all pixels of an image"""
|
||||
|
||||
@ -444,7 +501,13 @@ class ImageLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_ilerp", title="Inverse Lerp Image", tags=["image", "ilerp"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_ilerp",
|
||||
title="Inverse Lerp Image",
|
||||
tags=["image", "ilerp"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageInverseLerpInvocation(BaseInvocation):
|
||||
"""Inverse linear interpolation of all pixels of an image"""
|
||||
|
||||
@ -456,7 +519,7 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
image_arr = numpy.asarray(image, dtype=numpy.float32)
|
||||
image_arr = numpy.minimum(numpy.maximum(image_arr - self.min, 0) / float(self.max - self.min), 1) * 255
|
||||
image_arr = numpy.minimum(numpy.maximum(image_arr - self.min, 0) / float(self.max - self.min), 1) * 255 # type: ignore [assignment]
|
||||
|
||||
ilerp_image = Image.fromarray(numpy.uint8(image_arr))
|
||||
|
||||
@ -477,7 +540,13 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_nsfw", title="Blur NSFW Image", tags=["image", "nsfw"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_nsfw",
|
||||
title="Blur NSFW Image",
|
||||
tags=["image", "nsfw"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
"""Add blur to NSFW-flagged images"""
|
||||
|
||||
@ -505,7 +574,7 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -515,7 +584,7 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
def _get_caution_img(self) -> Image:
|
||||
def _get_caution_img(self) -> Image.Image:
|
||||
import invokeai.app.assets.images as image_assets
|
||||
|
||||
caution = Image.open(Path(image_assets.__path__[0]) / "caution.png")
|
||||
@ -523,7 +592,11 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"img_watermark", title="Add Invisible Watermark", tags=["image", "watermark"], category="image", version="1.0.0"
|
||||
"img_watermark",
|
||||
title="Add Invisible Watermark",
|
||||
tags=["image", "watermark"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageWatermarkInvocation(BaseInvocation):
|
||||
"""Add an invisible watermark to an image"""
|
||||
@ -544,7 +617,7 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -555,7 +628,13 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("mask_edge", title="Mask Edge", tags=["image", "mask", "inpaint"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"mask_edge",
|
||||
title="Mask Edge",
|
||||
tags=["image", "mask", "inpaint"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskEdgeInvocation(BaseInvocation):
|
||||
"""Applies an edge mask to an image"""
|
||||
|
||||
@ -601,7 +680,11 @@ class MaskEdgeInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"mask_combine", title="Combine Masks", tags=["image", "mask", "multiply"], category="image", version="1.0.0"
|
||||
"mask_combine",
|
||||
title="Combine Masks",
|
||||
tags=["image", "mask", "multiply"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskCombineInvocation(BaseInvocation):
|
||||
"""Combine two masks together by multiplying them using `PIL.ImageChops.multiply()`."""
|
||||
@ -632,7 +715,13 @@ class MaskCombineInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("color_correct", title="Color Correct", tags=["image", "color"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"color_correct",
|
||||
title="Color Correct",
|
||||
tags=["image", "color"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorCorrectInvocation(BaseInvocation):
|
||||
"""
|
||||
Shifts the colors of a target image to match the reference image, optionally
|
||||
@ -742,7 +831,13 @@ class ColorCorrectInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_hue_adjust", title="Adjust Image Hue", tags=["image", "hue"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_hue_adjust",
|
||||
title="Adjust Image Hue",
|
||||
tags=["image", "hue"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageHueAdjustmentInvocation(BaseInvocation):
|
||||
"""Adjusts the Hue of an image."""
|
||||
|
||||
@ -980,7 +1075,7 @@ class SaveImageInvocation(BaseInvocation):
|
||||
|
||||
image: ImageField = InputField(description=FieldDescriptions.image)
|
||||
board: Optional[BoardField] = InputField(default=None, description=FieldDescriptions.board, input=Input.Direct)
|
||||
metadata: CoreMetadata = InputField(
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
ui_hidden=True,
|
||||
@ -997,7 +1092,7 @@ class SaveImageInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@ import os
|
||||
from builtins import float
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
@ -25,11 +25,15 @@ class IPAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the IP-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class CLIPVisionModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the CLIP Vision image encoder model")
|
||||
base_model: BaseModelType = Field(description="Base model (usually 'Any')")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
|
||||
@ -19,7 +19,7 @@ from diffusers.models.attention_processor import (
|
||||
)
|
||||
from diffusers.schedulers import DPMSolverSDEScheduler
|
||||
from diffusers.schedulers import SchedulerMixin as Scheduler
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
@ -84,12 +84,20 @@ class SchedulerOutput(BaseInvocationOutput):
|
||||
scheduler: SAMPLER_NAME_VALUES = OutputField(description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler)
|
||||
|
||||
|
||||
@invocation("scheduler", title="Scheduler", tags=["scheduler"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"scheduler",
|
||||
title="Scheduler",
|
||||
tags=["scheduler"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SchedulerInvocation(BaseInvocation):
|
||||
"""Selects a scheduler."""
|
||||
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler
|
||||
default="euler",
|
||||
description=FieldDescriptions.scheduler,
|
||||
ui_type=UIType.Scheduler,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SchedulerOutput:
|
||||
@ -97,7 +105,11 @@ class SchedulerInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"create_denoise_mask", title="Create Denoise Mask", tags=["mask", "denoise"], category="latents", version="1.0.0"
|
||||
"create_denoise_mask",
|
||||
title="Create Denoise Mask",
|
||||
tags=["mask", "denoise"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
"""Creates mask for denoising model run."""
|
||||
@ -106,7 +118,11 @@ class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
image: Optional[ImageField] = InputField(default=None, description="Image which will be masked", ui_order=1)
|
||||
mask: ImageField = InputField(description="The mask to use when pasting", ui_order=2)
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled, ui_order=3)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32, ui_order=4)
|
||||
fp32: bool = InputField(
|
||||
default=DEFAULT_PRECISION == "float32",
|
||||
description=FieldDescriptions.fp32,
|
||||
ui_order=4,
|
||||
)
|
||||
|
||||
def prep_mask_tensor(self, mask_image):
|
||||
if mask_image.mode != "L":
|
||||
@ -134,7 +150,7 @@ class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
|
||||
if image is not None:
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -166,9 +182,8 @@ def get_scheduler(
|
||||
seed: int,
|
||||
) -> Scheduler:
|
||||
scheduler_class, scheduler_extra_config = SCHEDULER_MAP.get(scheduler_name, SCHEDULER_MAP["ddim"])
|
||||
orig_scheduler_info = context.services.model_manager.get_model(
|
||||
**scheduler_info.dict(),
|
||||
context=context,
|
||||
orig_scheduler_info = context.get_model(
|
||||
**scheduler_info.model_dump(),
|
||||
)
|
||||
with orig_scheduler_info as orig_scheduler:
|
||||
scheduler_config = orig_scheduler.config
|
||||
@ -209,34 +224,64 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
negative_conditioning: ConditioningField = InputField(
|
||||
description=FieldDescriptions.negative_cond, input=Input.Connection, ui_order=1
|
||||
)
|
||||
noise: Optional[LatentsField] = InputField(description=FieldDescriptions.noise, input=Input.Connection, ui_order=3)
|
||||
noise: Optional[LatentsField] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.noise,
|
||||
input=Input.Connection,
|
||||
ui_order=3,
|
||||
)
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
cfg_scale: Union[float, List[float]] = InputField(
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, title="CFG Scale"
|
||||
)
|
||||
denoising_start: float = InputField(default=0.0, ge=0, le=1, description=FieldDescriptions.denoising_start)
|
||||
denoising_start: float = InputField(
|
||||
default=0.0,
|
||||
ge=0,
|
||||
le=1,
|
||||
description=FieldDescriptions.denoising_start,
|
||||
)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler
|
||||
default="euler",
|
||||
description=FieldDescriptions.scheduler,
|
||||
ui_type=UIType.Scheduler,
|
||||
)
|
||||
unet: UNetField = InputField(description=FieldDescriptions.unet, input=Input.Connection, title="UNet", ui_order=2)
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
unet: UNetField = InputField(
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
ui_order=2,
|
||||
)
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
description=FieldDescriptions.ip_adapter,
|
||||
title="IP-Adapter",
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=6,
|
||||
)
|
||||
t2i_adapter: Union[T2IAdapterField, list[T2IAdapterField]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter, title="T2I-Adapter", default=None, input=Input.Connection, ui_order=7
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter,
|
||||
title="T2I-Adapter",
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=7,
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(
|
||||
default=None, description=FieldDescriptions.latents, input=Input.Connection
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=8
|
||||
default=None,
|
||||
description=FieldDescriptions.mask,
|
||||
input=Input.Connection,
|
||||
ui_order=8,
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@field_validator("cfg_scale")
|
||||
def ge_one(cls, v):
|
||||
"""validate that all cfg_scale values are >= 1"""
|
||||
if isinstance(v, list):
|
||||
@ -252,15 +297,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def dispatch_progress(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
source_node_id: str,
|
||||
intermediate_state: PipelineIntermediateState,
|
||||
base_model: BaseModelType,
|
||||
) -> None:
|
||||
stable_diffusion_step_callback(
|
||||
context=context,
|
||||
intermediate_state=intermediate_state,
|
||||
node=self.dict(),
|
||||
source_node_id=source_node_id,
|
||||
base_model=base_model,
|
||||
)
|
||||
|
||||
@ -271,11 +313,11 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
unet,
|
||||
seed,
|
||||
) -> ConditioningData:
|
||||
positive_cond_data = context.services.latents.get(self.positive_conditioning.conditioning_name)
|
||||
positive_cond_data = context.get_conditioning(self.positive_conditioning.conditioning_name)
|
||||
c = positive_cond_data.conditionings[0].to(device=unet.device, dtype=unet.dtype)
|
||||
extra_conditioning_info = c.extra_conditioning
|
||||
|
||||
negative_cond_data = context.services.latents.get(self.negative_conditioning.conditioning_name)
|
||||
negative_cond_data = context.get_conditioning(self.negative_conditioning.conditioning_name)
|
||||
uc = negative_cond_data.conditionings[0].to(device=unet.device, dtype=unet.dtype)
|
||||
|
||||
conditioning_data = ConditioningData(
|
||||
@ -362,17 +404,16 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
controlnet_data = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
context.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
# control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
input_image = context.get_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
@ -430,30 +471,29 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
conditioning_data.ip_adapter_conditioning = []
|
||||
for single_ip_adapter in ip_adapter:
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
context.get_model(
|
||||
model_name=single_ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=single_ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
image_encoder_model_info = context.get_model(
|
||||
model_name=single_ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=single_ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(single_ip_adapter.image.image_name)
|
||||
input_image = context.get_image(single_ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
(
|
||||
image_prompt_embeds,
|
||||
uncond_image_prompt_embeds,
|
||||
) = ip_adapter_model.get_image_embeds(input_image, image_encoder_model)
|
||||
conditioning_data.ip_adapter_conditioning.append(
|
||||
IPAdapterConditioningInfo(image_prompt_embeds, uncond_image_prompt_embeds)
|
||||
)
|
||||
@ -488,13 +528,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
t2i_adapter_data = []
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_info = context.services.model_manager.get_model(
|
||||
t2i_adapter_model_info = context.get_model(
|
||||
model_name=t2i_adapter_field.t2i_adapter_model.model_name,
|
||||
model_type=ModelType.T2IAdapter,
|
||||
base_model=t2i_adapter_field.t2i_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
image = context.services.images.get_pil_image(t2i_adapter_field.image.image_name)
|
||||
image = context.get_image(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusion1:
|
||||
@ -604,11 +643,11 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
seed = None
|
||||
noise = None
|
||||
if self.noise is not None:
|
||||
noise = context.services.latents.get(self.noise.latents_name)
|
||||
noise = context.get_latents(self.noise.latents_name)
|
||||
seed = self.noise.seed
|
||||
|
||||
if self.latents is not None:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
latents = context.get_latents(self.latents.latents_name)
|
||||
if seed is None:
|
||||
seed = self.latents.seed
|
||||
|
||||
@ -628,29 +667,26 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
# TODO(ryand): I have hard-coded `do_classifier_free_guidance=True` to mirror the behaviour of ControlNets,
|
||||
# below. Investigate whether this is appropriate.
|
||||
t2i_adapter_data = self.run_t2i_adapters(
|
||||
context, self.t2i_adapter, latents.shape, do_classifier_free_guidance=True
|
||||
context,
|
||||
self.t2i_adapter,
|
||||
latents.shape,
|
||||
do_classifier_free_guidance=True,
|
||||
)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[self.id]
|
||||
|
||||
def step_callback(state: PipelineIntermediateState):
|
||||
self.dispatch_progress(context, source_node_id, state, self.unet.unet.base_model)
|
||||
self.dispatch_progress(context, state, self.unet.unet.base_model)
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.unet.loras:
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.dict(exclude={"weight"}),
|
||||
context=context,
|
||||
lora_info = context.get_model(
|
||||
**lora.model_dump(exclude={"weight"}),
|
||||
)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
unet_info = context.services.model_manager.get_model(
|
||||
**self.unet.unet.dict(),
|
||||
context=context,
|
||||
unet_info = context.get_model(
|
||||
**self.unet.unet.model_dump(),
|
||||
)
|
||||
with (
|
||||
ExitStack() as exit_stack,
|
||||
@ -700,7 +736,10 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
denoising_end=self.denoising_end,
|
||||
)
|
||||
|
||||
result_latents, result_attention_map_saver = pipeline.latents_from_embeddings(
|
||||
(
|
||||
result_latents,
|
||||
result_attention_map_saver,
|
||||
) = pipeline.latents_from_embeddings(
|
||||
latents=latents,
|
||||
timesteps=timesteps,
|
||||
init_timestep=init_timestep,
|
||||
@ -722,13 +761,16 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
context.services.latents.save(name, result_latents)
|
||||
return build_latents_output(latents_name=name, latents=result_latents, seed=seed)
|
||||
latents_name = context.save_latents(result_latents)
|
||||
return build_latents_output(latents_name=latents_name, latents=result_latents, seed=seed)
|
||||
|
||||
|
||||
@invocation(
|
||||
"l2i", title="Latents to Image", tags=["latents", "image", "vae", "l2i"], category="latents", version="1.0.0"
|
||||
"l2i",
|
||||
title="Latents to Image",
|
||||
tags=["latents", "image", "vae", "l2i"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LatentsToImageInvocation(BaseInvocation):
|
||||
"""Generates an image from latents."""
|
||||
@ -743,7 +785,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
)
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32)
|
||||
metadata: CoreMetadata = InputField(
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
ui_hidden=True,
|
||||
@ -751,11 +793,10 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
latents = context.get_latents(self.latents.latents_name)
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
vae_info = context.get_model(
|
||||
**self.vae.vae.model_dump(),
|
||||
)
|
||||
|
||||
with set_seamless(vae_info.context.model, self.vae.seamless_axes), vae_info as vae:
|
||||
@ -785,7 +826,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
vae.to(dtype=torch.float16)
|
||||
latents = latents.half()
|
||||
|
||||
if self.tiled or context.services.configuration.tiled_decode:
|
||||
if self.tiled or context.config.tiled_decode:
|
||||
vae.enable_tiling()
|
||||
else:
|
||||
vae.disable_tiling()
|
||||
@ -809,28 +850,25 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
image_name = context.save_image(image, category=context.categories.GENERAL)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
image=ImageField(image_name=image_name),
|
||||
width=image.width,
|
||||
height=image.height,
|
||||
)
|
||||
|
||||
|
||||
LATENTS_INTERPOLATION_MODE = Literal["nearest", "linear", "bilinear", "bicubic", "trilinear", "area", "nearest-exact"]
|
||||
|
||||
|
||||
@invocation("lresize", title="Resize Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lresize",
|
||||
title="Resize Latents",
|
||||
tags=["latents", "resize"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ResizeLatentsInvocation(BaseInvocation):
|
||||
"""Resizes latents to explicit width/height (in pixels). Provided dimensions are floor-divided by 8."""
|
||||
|
||||
@ -876,7 +914,13 @@ class ResizeLatentsInvocation(BaseInvocation):
|
||||
return build_latents_output(latents_name=name, latents=resized_latents, seed=self.latents.seed)
|
||||
|
||||
|
||||
@invocation("lscale", title="Scale Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lscale",
|
||||
title="Scale Latents",
|
||||
tags=["latents", "resize"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ScaleLatentsInvocation(BaseInvocation):
|
||||
"""Scales latents by a given factor."""
|
||||
|
||||
@ -915,7 +959,11 @@ class ScaleLatentsInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"i2l", title="Image to Latents", tags=["latents", "image", "vae", "i2l"], category="latents", version="1.0.0"
|
||||
"i2l",
|
||||
title="Image to Latents",
|
||||
tags=["latents", "image", "vae", "i2l"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageToLatentsInvocation(BaseInvocation):
|
||||
"""Encodes an image into latents."""
|
||||
@ -979,7 +1027,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -1007,7 +1055,13 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
return vae.encode(image_tensor).latents
|
||||
|
||||
|
||||
@invocation("lblend", title="Blend Latents", tags=["latents", "blend"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lblend",
|
||||
title="Blend Latents",
|
||||
tags=["latents", "blend"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class BlendLatentsInvocation(BaseInvocation):
|
||||
"""Blend two latents using a given alpha. Latents must have same size."""
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import FloatOutput, IntegerOutput
|
||||
|
||||
@ -72,7 +72,14 @@ class RandomIntInvocation(BaseInvocation):
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation("rand_float", title="Random Float", tags=["math", "float", "random"], category="math", version="1.0.0")
|
||||
@invocation(
|
||||
"rand_float",
|
||||
title="Random Float",
|
||||
tags=["math", "float", "random"],
|
||||
category="math",
|
||||
version="1.0.1",
|
||||
use_cache=False,
|
||||
)
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
@ -178,7 +185,7 @@ class IntegerMathInvocation(BaseInvocation):
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
@field_validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
@ -252,7 +259,7 @@ class FloatMathInvocation(BaseInvocation):
|
||||
a: float = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: float = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
@field_validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
|
||||
@ -44,28 +44,31 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
app_version: str = Field(default=__version__, description="The version of InvokeAI used to generate this image")
|
||||
generation_mode: str = Field(
|
||||
generation_mode: Optional[str] = Field(
|
||||
default=None,
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
created_by: Optional[str] = Field(description="The name of the creator of the image")
|
||||
positive_prompt: str = Field(description="The positive prompt parameter")
|
||||
negative_prompt: str = Field(description="The negative prompt parameter")
|
||||
width: int = Field(description="The width parameter")
|
||||
height: int = Field(description="The height parameter")
|
||||
seed: int = Field(description="The seed used for noise generation")
|
||||
rand_device: str = Field(description="The device used for random number generation")
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
positive_prompt: Optional[str] = Field(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = Field(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = Field(default=None, description="The width parameter")
|
||||
height: Optional[int] = Field(default=None, description="The height parameter")
|
||||
seed: Optional[int] = Field(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = Field(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = Field(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = Field(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = Field(default=None, description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = Field(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
model: Optional[MainModelField] = Field(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = Field(default=None, description="The ControlNets used for inference")
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = Field(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = Field(default=None, description="The IP Adapters used for inference")
|
||||
loras: Optional[list[LoRAMetadataField]] = Field(default=None, description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
@ -122,27 +125,34 @@ class MetadataAccumulatorOutput(BaseInvocationOutput):
|
||||
class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
"""Outputs a Core Metadata Object"""
|
||||
|
||||
generation_mode: str = InputField(
|
||||
generation_mode: Optional[str] = InputField(
|
||||
default=None,
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
positive_prompt: str = InputField(description="The positive prompt parameter")
|
||||
negative_prompt: str = InputField(description="The negative prompt parameter")
|
||||
width: int = InputField(description="The width parameter")
|
||||
height: int = InputField(description="The height parameter")
|
||||
seed: int = InputField(description="The seed used for noise generation")
|
||||
rand_device: str = InputField(description="The device used for random number generation")
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
positive_prompt: Optional[str] = InputField(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = InputField(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = InputField(default=None, description="The width parameter")
|
||||
height: Optional[int] = InputField(default=None, description="The height parameter")
|
||||
seed: Optional[int] = InputField(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = InputField(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = InputField(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = InputField(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = InputField(default=None, description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
ipAdapters: list[IPAdapterMetadataField] = InputField(description="The IP Adapters used for inference")
|
||||
t2iAdapters: list[T2IAdapterField] = Field(description="The IP Adapters used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
model: Optional[MainModelField] = InputField(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = InputField(
|
||||
default=None, description="The ControlNets used for inference"
|
||||
)
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
loras: Optional[list[LoRAMetadataField]] = InputField(default=None, description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The strength used for latents-to-latents",
|
||||
@ -156,6 +166,20 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
)
|
||||
|
||||
# High resolution fix metadata.
|
||||
hrf_width: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_height: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix img2img strength used in the upscale pass.",
|
||||
)
|
||||
|
||||
# SDXL
|
||||
positive_style_prompt: Optional[str] = InputField(
|
||||
default=None,
|
||||
@ -199,4 +223,4 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> MetadataAccumulatorOutput:
|
||||
"""Collects and outputs a CoreMetadata object"""
|
||||
|
||||
return MetadataAccumulatorOutput(metadata=CoreMetadata(**self.dict()))
|
||||
return MetadataAccumulatorOutput(metadata=CoreMetadata(**self.model_dump()))
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
import copy
|
||||
from typing import List, Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from ...backend.model_management import BaseModelType, ModelType, SubModelType
|
||||
from .baseinvocation import (
|
||||
@ -24,6 +24,8 @@ class ModelInfo(BaseModel):
|
||||
model_type: ModelType = Field(description="Info to load submodel")
|
||||
submodel: Optional[SubModelType] = Field(default=None, description="Info to load submodel")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class LoraInfo(ModelInfo):
|
||||
weight: float = Field(description="Lora's weight which to use when apply to model")
|
||||
@ -65,6 +67,8 @@ class MainModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class LoRAModelField(BaseModel):
|
||||
"""LoRA model field"""
|
||||
@ -72,8 +76,16 @@ class LoRAModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the LoRA model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
@invocation("main_model_loader", title="Main Model", tags=["model"], category="model", version="1.0.0")
|
||||
|
||||
@invocation(
|
||||
"main_model_loader",
|
||||
title="Main Model",
|
||||
tags=["model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MainModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a main model, outputting its submodels."""
|
||||
|
||||
@ -86,7 +98,7 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
model_type = ModelType.Main
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_manager.model_exists(
|
||||
if not context.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@ -180,10 +192,16 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
clip: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> LoraLoaderOutput:
|
||||
@ -244,20 +262,35 @@ class SDXLLoraLoaderOutput(BaseInvocationOutput):
|
||||
clip2: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP 2")
|
||||
|
||||
|
||||
@invocation("sdxl_lora_loader", title="SDXL LoRA", tags=["lora", "model"], category="model", version="1.0.0")
|
||||
@invocation(
|
||||
"sdxl_lora_loader",
|
||||
title="SDXL LoRA",
|
||||
tags=["lora", "model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
clip: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 1"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP 1",
|
||||
)
|
||||
clip2: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 2"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP 2",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SDXLLoraLoaderOutput:
|
||||
@ -330,6 +363,8 @@ class VAEModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@invocation_output("vae_loader_output")
|
||||
class VaeLoaderOutput(BaseInvocationOutput):
|
||||
@ -343,7 +378,10 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput"""
|
||||
|
||||
vae_model: VAEModelField = InputField(
|
||||
description=FieldDescriptions.vae_model, input=Input.Direct, ui_type=UIType.VaeModel, title="VAE"
|
||||
description=FieldDescriptions.vae_model,
|
||||
input=Input.Direct,
|
||||
ui_type=UIType.VaeModel,
|
||||
title="VAE",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> VaeLoaderOutput:
|
||||
@ -372,19 +410,31 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
class SeamlessModeOutput(BaseInvocationOutput):
|
||||
"""Modified Seamless Model output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(default=None, description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@invocation("seamless", title="Seamless", tags=["seamless", "model"], category="model", version="1.0.0")
|
||||
@invocation(
|
||||
"seamless",
|
||||
title="Seamless",
|
||||
tags=["seamless", "model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SeamlessModeInvocation(BaseInvocation):
|
||||
"""Applies the seamless transformation to the Model UNet and VAE."""
|
||||
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
vae: Optional[VaeField] = InputField(
|
||||
default=None, description=FieldDescriptions.vae_model, input=Input.Connection, title="VAE"
|
||||
default=None,
|
||||
description=FieldDescriptions.vae_model,
|
||||
input=Input.Connection,
|
||||
title="VAE",
|
||||
)
|
||||
seamless_y: bool = InputField(default=True, input=Input.Any, description="Specify whether Y axis is seamless")
|
||||
seamless_x: bool = InputField(default=True, input=Input.Any, description="Specify whether X axis is seamless")
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
|
||||
import torch
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.latent import LatentsField
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
@ -65,7 +65,7 @@ Nodes
|
||||
class NoiseOutput(BaseInvocationOutput):
|
||||
"""Invocation noise output"""
|
||||
|
||||
noise: LatentsField = OutputField(default=None, description=FieldDescriptions.noise)
|
||||
noise: LatentsField = OutputField(description=FieldDescriptions.noise)
|
||||
width: int = OutputField(description=FieldDescriptions.width)
|
||||
height: int = OutputField(description=FieldDescriptions.height)
|
||||
|
||||
@ -78,7 +78,13 @@ def build_noise_output(latents_name: str, latents: torch.Tensor, seed: int):
|
||||
)
|
||||
|
||||
|
||||
@invocation("noise", title="Noise", tags=["latents", "noise"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"noise",
|
||||
title="Noise",
|
||||
tags=["latents", "noise"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class NoiseInvocation(BaseInvocation):
|
||||
"""Generates latent noise."""
|
||||
|
||||
@ -105,7 +111,7 @@ class NoiseInvocation(BaseInvocation):
|
||||
description="Use CPU for noise generation (for reproducible results across platforms)",
|
||||
)
|
||||
|
||||
@validator("seed", pre=True)
|
||||
@field_validator("seed", mode="before")
|
||||
def modulo_seed(cls, v):
|
||||
"""Returns the seed modulo (SEED_MAX + 1) to ensure it is within the valid range."""
|
||||
return v % (SEED_MAX + 1)
|
||||
@ -118,6 +124,5 @@ class NoiseInvocation(BaseInvocation):
|
||||
seed=self.seed,
|
||||
use_cpu=self.use_cpu,
|
||||
)
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
context.services.latents.save(name, noise)
|
||||
return build_noise_output(latents_name=name, latents=noise, seed=self.seed)
|
||||
latents_name = context.save_latents(noise)
|
||||
return build_noise_output(latents_name=latents_name, latents=noise, seed=self.seed)
|
||||
|
||||
@ -9,7 +9,7 @@ from typing import List, Literal, Optional, Union
|
||||
import numpy as np
|
||||
import torch
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from pydantic import BaseModel, Field, validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, field_validator
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
@ -63,14 +63,17 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
**self.clip.tokenizer.model_dump(),
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
**self.clip.text_encoder.model_dump(),
|
||||
)
|
||||
with tokenizer_info as orig_tokenizer, text_encoder_info as text_encoder: # , ExitStack() as stack:
|
||||
loras = [
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(
|
||||
context.services.model_manager.get_model(**lora.model_dump(exclude={"weight"})).context.model,
|
||||
lora.weight,
|
||||
)
|
||||
for lora in self.clip.loras
|
||||
]
|
||||
|
||||
@ -175,14 +178,14 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
)
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
)
|
||||
# seamless: bool = InputField(default=False, description="Whether or not to generate an image that can tile without seams", )
|
||||
# seamless_axes: str = InputField(default="", description="The axes to tile the image on, 'x' and/or 'y'")
|
||||
|
||||
@validator("cfg_scale")
|
||||
@field_validator("cfg_scale")
|
||||
def ge_one(cls, v):
|
||||
"""validate that all cfg_scale values are >= 1"""
|
||||
if isinstance(v, list):
|
||||
@ -241,7 +244,7 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
stable_diffusion_step_callback(
|
||||
context=context,
|
||||
intermediate_state=intermediate_state,
|
||||
node=self.dict(),
|
||||
node=self.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
|
||||
@ -254,12 +257,15 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
eta=0.0,
|
||||
)
|
||||
|
||||
unet_info = context.services.model_manager.get_model(**self.unet.unet.dict())
|
||||
unet_info = context.services.model_manager.get_model(**self.unet.unet.model_dump())
|
||||
|
||||
with unet_info as unet: # , ExitStack() as stack:
|
||||
# loras = [(stack.enter_context(context.services.model_manager.get_model(**lora.dict(exclude={"weight"}))), lora.weight) for lora in self.unet.loras]
|
||||
loras = [
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(
|
||||
context.services.model_manager.get_model(**lora.model_dump(exclude={"weight"})).context.model,
|
||||
lora.weight,
|
||||
)
|
||||
for lora in self.unet.loras
|
||||
]
|
||||
|
||||
@ -346,7 +352,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
raise Exception(f"Expected vae_decoder, found: {self.vae.vae.model_type}")
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
)
|
||||
|
||||
# clear memory as vae decode can request a lot
|
||||
@ -375,7 +381,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -403,6 +409,8 @@ class OnnxModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@invocation("onnx_model_loader", title="ONNX Main Model", tags=["onnx", "model"], category="model", version="1.0.0")
|
||||
class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
@ -44,13 +44,22 @@ from invokeai.app.invocations.primitives import FloatCollectionOutput
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("float_range", title="Float Range", tags=["math", "range"], category="math", version="1.0.0")
|
||||
@invocation(
|
||||
"float_range",
|
||||
title="Float Range",
|
||||
tags=["math", "range"],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FloatLinearRangeInvocation(BaseInvocation):
|
||||
"""Creates a range"""
|
||||
|
||||
start: float = InputField(default=5, description="The first value of the range")
|
||||
stop: float = InputField(default=10, description="The last value of the range")
|
||||
steps: int = InputField(default=30, description="number of values to interpolate over (including start and stop)")
|
||||
steps: int = InputField(
|
||||
default=30,
|
||||
description="number of values to interpolate over (including start and stop)",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatCollectionOutput:
|
||||
param_list = list(np.linspace(self.start, self.stop, self.steps))
|
||||
@ -95,7 +104,13 @@ EASING_FUNCTION_KEYS = Literal[tuple(list(EASING_FUNCTIONS_MAP.keys()))]
|
||||
|
||||
|
||||
# actually I think for now could just use CollectionOutput (which is list[Any]
|
||||
@invocation("step_param_easing", title="Step Param Easing", tags=["step", "easing"], category="step", version="1.0.0")
|
||||
@invocation(
|
||||
"step_param_easing",
|
||||
title="Step Param Easing",
|
||||
tags=["step", "easing"],
|
||||
category="step",
|
||||
version="1.0.0",
|
||||
)
|
||||
class StepParamEasingInvocation(BaseInvocation):
|
||||
"""Experimental per-step parameter easing for denoising steps"""
|
||||
|
||||
@ -159,7 +174,9 @@ class StepParamEasingInvocation(BaseInvocation):
|
||||
context.services.logger.debug("base easing duration: " + str(base_easing_duration))
|
||||
even_num_steps = num_easing_steps % 2 == 0 # even number of steps
|
||||
easing_function = easing_class(
|
||||
start=self.start_value, end=self.end_value, duration=base_easing_duration - 1
|
||||
start=self.start_value,
|
||||
end=self.end_value,
|
||||
duration=base_easing_duration - 1,
|
||||
)
|
||||
base_easing_vals = list()
|
||||
for step_index in range(base_easing_duration):
|
||||
@ -199,7 +216,11 @@ class StepParamEasingInvocation(BaseInvocation):
|
||||
#
|
||||
|
||||
else: # no mirroring (default)
|
||||
easing_function = easing_class(start=self.start_value, end=self.end_value, duration=num_easing_steps - 1)
|
||||
easing_function = easing_class(
|
||||
start=self.start_value,
|
||||
end=self.end_value,
|
||||
duration=num_easing_steps - 1,
|
||||
)
|
||||
for step_index in range(num_easing_steps):
|
||||
step_val = easing_function.ease(step_index)
|
||||
easing_list.append(step_val)
|
||||
|
||||
@ -3,7 +3,7 @@ from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import StringCollectionOutput
|
||||
|
||||
@ -21,7 +21,10 @@ from .baseinvocation import BaseInvocation, InputField, InvocationContext, UICom
|
||||
class DynamicPromptInvocation(BaseInvocation):
|
||||
"""Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator"""
|
||||
|
||||
prompt: str = InputField(description="The prompt to parse with dynamicprompts", ui_component=UIComponent.Textarea)
|
||||
prompt: str = InputField(
|
||||
description="The prompt to parse with dynamicprompts",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
max_prompts: int = InputField(default=1, description="The number of prompts to generate")
|
||||
combinatorial: bool = InputField(default=False, description="Whether to use the combinatorial generator")
|
||||
|
||||
@ -36,21 +39,31 @@ class DynamicPromptInvocation(BaseInvocation):
|
||||
return StringCollectionOutput(collection=prompts)
|
||||
|
||||
|
||||
@invocation("prompt_from_file", title="Prompts from File", tags=["prompt", "file"], category="prompt", version="1.0.0")
|
||||
@invocation(
|
||||
"prompt_from_file",
|
||||
title="Prompts from File",
|
||||
tags=["prompt", "file"],
|
||||
category="prompt",
|
||||
version="1.0.0",
|
||||
)
|
||||
class PromptsFromFileInvocation(BaseInvocation):
|
||||
"""Loads prompts from a text file"""
|
||||
|
||||
file_path: str = InputField(description="Path to prompt text file")
|
||||
pre_prompt: Optional[str] = InputField(
|
||||
default=None, description="String to prepend to each prompt", ui_component=UIComponent.Textarea
|
||||
default=None,
|
||||
description="String to prepend to each prompt",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
post_prompt: Optional[str] = InputField(
|
||||
default=None, description="String to append to each prompt", ui_component=UIComponent.Textarea
|
||||
default=None,
|
||||
description="String to append to each prompt",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
start_line: int = InputField(default=1, ge=1, description="Line in the file to start start from")
|
||||
max_prompts: int = InputField(default=1, ge=0, description="Max lines to read from file (0=all)")
|
||||
|
||||
@validator("file_path")
|
||||
@field_validator("file_path")
|
||||
def file_path_exists(cls, v):
|
||||
if not exists(v):
|
||||
raise ValueError(FileNotFoundError)
|
||||
@ -79,6 +92,10 @@ class PromptsFromFileInvocation(BaseInvocation):
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringCollectionOutput:
|
||||
prompts = self.promptsFromFile(
|
||||
self.file_path, self.pre_prompt, self.post_prompt, self.start_line, self.max_prompts
|
||||
self.file_path,
|
||||
self.pre_prompt,
|
||||
self.post_prompt,
|
||||
self.start_line,
|
||||
self.max_prompts,
|
||||
)
|
||||
return StringCollectionOutput(collection=prompts)
|
||||
|
||||
0
invokeai/app/invocations/shared.py
Normal file
0
invokeai/app/invocations/shared.py
Normal file
@ -1,6 +1,6 @@
|
||||
from typing import Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
@ -23,6 +23,8 @@ class T2IAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the T2I-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The T2I-Adapter image prompt.")
|
||||
|
||||
@ -7,6 +7,7 @@ import numpy as np
|
||||
import torch
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from pydantic import ConfigDict
|
||||
from realesrgan import RealESRGANer
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
@ -38,6 +39,8 @@ class ESRGANInvocation(BaseInvocation):
|
||||
default=400, ge=0, description="Tile size for tiled ESRGAN upscaling (0=tiling disabled)"
|
||||
)
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
models_path = context.services.configuration.models_path
|
||||
|
||||
@ -12,7 +12,7 @@ from .board_image_records_base import BoardImageRecordStorageBase
|
||||
class SqliteBoardImageRecordStorage(BoardImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
from datetime import datetime
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import BaseModel, Extra, Field
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
@ -18,9 +18,9 @@ class BoardRecord(BaseModelExcludeNull):
|
||||
"""The created timestamp of the image."""
|
||||
updated_at: Union[datetime, str] = Field(description="The updated timestamp of the board.")
|
||||
"""The updated timestamp of the image."""
|
||||
deleted_at: Union[datetime, str, None] = Field(description="The deleted timestamp of the board.")
|
||||
deleted_at: Optional[Union[datetime, str]] = Field(default=None, description="The deleted timestamp of the board.")
|
||||
"""The updated timestamp of the image."""
|
||||
cover_image_name: Optional[str] = Field(description="The name of the cover image of the board.")
|
||||
cover_image_name: Optional[str] = Field(default=None, description="The name of the cover image of the board.")
|
||||
"""The name of the cover image of the board."""
|
||||
|
||||
|
||||
@ -46,9 +46,9 @@ def deserialize_board_record(board_dict: dict) -> BoardRecord:
|
||||
)
|
||||
|
||||
|
||||
class BoardChanges(BaseModel, extra=Extra.forbid):
|
||||
board_name: Optional[str] = Field(description="The board's new name.")
|
||||
cover_image_name: Optional[str] = Field(description="The name of the board's new cover image.")
|
||||
class BoardChanges(BaseModel, extra="forbid"):
|
||||
board_name: Optional[str] = Field(default=None, description="The board's new name.")
|
||||
cover_image_name: Optional[str] = Field(default=None, description="The name of the board's new cover image.")
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
|
||||
@ -20,7 +20,7 @@ from .board_records_common import (
|
||||
class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
|
||||
@ -17,7 +17,7 @@ class BoardDTO(BoardRecord):
|
||||
def board_record_to_dto(board_record: BoardRecord, cover_image_name: Optional[str], image_count: int) -> BoardDTO:
|
||||
"""Converts a board record to a board DTO."""
|
||||
return BoardDTO(
|
||||
**board_record.dict(exclude={"cover_image_name"}),
|
||||
**board_record.model_dump(exclude={"cover_image_name"}),
|
||||
cover_image_name=cover_image_name,
|
||||
image_count=image_count,
|
||||
)
|
||||
|
||||
@ -18,7 +18,7 @@ from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_args, get_origin, get_type_hints
|
||||
|
||||
from omegaconf import DictConfig, ListConfig, OmegaConf
|
||||
from pydantic import BaseSettings
|
||||
from pydantic_settings import BaseSettings, SettingsConfigDict
|
||||
|
||||
from invokeai.app.services.config.config_common import PagingArgumentParser, int_or_float_or_str
|
||||
|
||||
@ -32,12 +32,14 @@ class InvokeAISettings(BaseSettings):
|
||||
initconf: ClassVar[Optional[DictConfig]] = None
|
||||
argparse_groups: ClassVar[Dict] = {}
|
||||
|
||||
model_config = SettingsConfigDict(env_file_encoding="utf-8", arbitrary_types_allowed=True, case_sensitive=True)
|
||||
|
||||
def parse_args(self, argv: Optional[list] = sys.argv[1:]):
|
||||
parser = self.get_parser()
|
||||
opt, unknown_opts = parser.parse_known_args(argv)
|
||||
if len(unknown_opts) > 0:
|
||||
print("Unknown args:", unknown_opts)
|
||||
for name in self.__fields__:
|
||||
for name in self.model_fields:
|
||||
if name not in self._excluded():
|
||||
value = getattr(opt, name)
|
||||
if isinstance(value, ListConfig):
|
||||
@ -54,10 +56,12 @@ class InvokeAISettings(BaseSettings):
|
||||
cls = self.__class__
|
||||
type = get_args(get_type_hints(cls)["type"])[0]
|
||||
field_dict = dict({type: dict()})
|
||||
for name, field in self.__fields__.items():
|
||||
for name, field in self.model_fields.items():
|
||||
if name in cls._excluded_from_yaml():
|
||||
continue
|
||||
category = field.field_info.extra.get("category") or "Uncategorized"
|
||||
category = (
|
||||
field.json_schema_extra.get("category", "Uncategorized") if field.json_schema_extra else "Uncategorized"
|
||||
)
|
||||
value = getattr(self, name)
|
||||
if category not in field_dict[type]:
|
||||
field_dict[type][category] = dict()
|
||||
@ -73,7 +77,7 @@ class InvokeAISettings(BaseSettings):
|
||||
else:
|
||||
settings_stanza = "Uncategorized"
|
||||
|
||||
env_prefix = getattr(cls.Config, "env_prefix", None)
|
||||
env_prefix = getattr(cls.model_config, "env_prefix", None)
|
||||
env_prefix = env_prefix if env_prefix is not None else settings_stanza.upper()
|
||||
|
||||
initconf = (
|
||||
@ -89,14 +93,18 @@ class InvokeAISettings(BaseSettings):
|
||||
for key, value in os.environ.items():
|
||||
upcase_environ[key.upper()] = value
|
||||
|
||||
fields = cls.__fields__
|
||||
fields = cls.model_fields
|
||||
cls.argparse_groups = {}
|
||||
|
||||
for name, field in fields.items():
|
||||
if name not in cls._excluded():
|
||||
current_default = field.default
|
||||
|
||||
category = field.field_info.extra.get("category", "Uncategorized")
|
||||
category = (
|
||||
field.json_schema_extra.get("category", "Uncategorized")
|
||||
if field.json_schema_extra
|
||||
else "Uncategorized"
|
||||
)
|
||||
env_name = env_prefix + "_" + name
|
||||
if category in initconf and name in initconf.get(category):
|
||||
field.default = initconf.get(category).get(name)
|
||||
@ -146,11 +154,6 @@ class InvokeAISettings(BaseSettings):
|
||||
"tiled_decode",
|
||||
]
|
||||
|
||||
class Config:
|
||||
env_file_encoding = "utf-8"
|
||||
arbitrary_types_allowed = True
|
||||
case_sensitive = True
|
||||
|
||||
@classmethod
|
||||
def add_field_argument(cls, command_parser, name: str, field, default_override=None):
|
||||
field_type = get_type_hints(cls).get(name)
|
||||
@ -161,7 +164,7 @@ class InvokeAISettings(BaseSettings):
|
||||
if field.default_factory is None
|
||||
else field.default_factory()
|
||||
)
|
||||
if category := field.field_info.extra.get("category"):
|
||||
if category := (field.json_schema_extra.get("category", None) if field.json_schema_extra else None):
|
||||
if category not in cls.argparse_groups:
|
||||
cls.argparse_groups[category] = command_parser.add_argument_group(category)
|
||||
argparse_group = cls.argparse_groups[category]
|
||||
@ -169,7 +172,7 @@ class InvokeAISettings(BaseSettings):
|
||||
argparse_group = command_parser
|
||||
|
||||
if get_origin(field_type) == Literal:
|
||||
allowed_values = get_args(field.type_)
|
||||
allowed_values = get_args(field.annotation)
|
||||
allowed_types = set()
|
||||
for val in allowed_values:
|
||||
allowed_types.add(type(val))
|
||||
@ -182,7 +185,7 @@ class InvokeAISettings(BaseSettings):
|
||||
type=field_type,
|
||||
default=default,
|
||||
choices=allowed_values,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
elif get_origin(field_type) == Union:
|
||||
@ -191,7 +194,7 @@ class InvokeAISettings(BaseSettings):
|
||||
dest=name,
|
||||
type=int_or_float_or_str,
|
||||
default=default,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
elif get_origin(field_type) == list:
|
||||
@ -199,17 +202,17 @@ class InvokeAISettings(BaseSettings):
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
nargs="*",
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
action=argparse.BooleanOptionalAction if field.type_ == bool else "store",
|
||||
help=field.field_info.description,
|
||||
action=argparse.BooleanOptionalAction if field.annotation == bool else "store",
|
||||
help=field.description,
|
||||
)
|
||||
else:
|
||||
argparse_group.add_argument(
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
action=argparse.BooleanOptionalAction if field.type_ == bool else "store",
|
||||
help=field.field_info.description,
|
||||
action=argparse.BooleanOptionalAction if field.annotation == bool else "store",
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
@ -144,8 +144,8 @@ which is set to the desired top-level name. For example, to create a
|
||||
|
||||
class InvokeBatch(InvokeAISettings):
|
||||
type: Literal["InvokeBatch"] = "InvokeBatch"
|
||||
node_count : int = Field(default=1, description="Number of nodes to run on", category='Resources')
|
||||
cpu_count : int = Field(default=8, description="Number of GPUs to run on per node", category='Resources')
|
||||
node_count : int = Field(default=1, description="Number of nodes to run on", json_schema_extra=dict(category='Resources'))
|
||||
cpu_count : int = Field(default=8, description="Number of GPUs to run on per node", json_schema_extra=dict(category='Resources'))
|
||||
|
||||
This will now read and write from the "InvokeBatch" section of the
|
||||
config file, look for environment variables named INVOKEBATCH_*, and
|
||||
@ -175,7 +175,8 @@ from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_type_hints
|
||||
|
||||
from omegaconf import DictConfig, OmegaConf
|
||||
from pydantic import Field, parse_obj_as
|
||||
from pydantic import Field, TypeAdapter
|
||||
from pydantic_settings import SettingsConfigDict
|
||||
|
||||
from .config_base import InvokeAISettings
|
||||
|
||||
@ -185,6 +186,21 @@ LEGACY_INIT_FILE = Path("invokeai.init")
|
||||
DEFAULT_MAX_VRAM = 0.5
|
||||
|
||||
|
||||
class Categories(object):
|
||||
WebServer = dict(category="Web Server")
|
||||
Features = dict(category="Features")
|
||||
Paths = dict(category="Paths")
|
||||
Logging = dict(category="Logging")
|
||||
Development = dict(category="Development")
|
||||
Other = dict(category="Other")
|
||||
ModelCache = dict(category="Model Cache")
|
||||
Device = dict(category="Device")
|
||||
Generation = dict(category="Generation")
|
||||
Queue = dict(category="Queue")
|
||||
Nodes = dict(category="Nodes")
|
||||
MemoryPerformance = dict(category="Memory/Performance")
|
||||
|
||||
|
||||
class InvokeAIAppConfig(InvokeAISettings):
|
||||
"""
|
||||
Generate images using Stable Diffusion. Use "invokeai" to launch
|
||||
@ -201,86 +217,88 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
type: Literal["InvokeAI"] = "InvokeAI"
|
||||
|
||||
# WEB
|
||||
host : str = Field(default="127.0.0.1", description="IP address to bind to", category='Web Server')
|
||||
port : int = Field(default=9090, description="Port to bind to", category='Web Server')
|
||||
allow_origins : List[str] = Field(default=[], description="Allowed CORS origins", category='Web Server')
|
||||
allow_credentials : bool = Field(default=True, description="Allow CORS credentials", category='Web Server')
|
||||
allow_methods : List[str] = Field(default=["*"], description="Methods allowed for CORS", category='Web Server')
|
||||
allow_headers : List[str] = Field(default=["*"], description="Headers allowed for CORS", category='Web Server')
|
||||
host : str = Field(default="127.0.0.1", description="IP address to bind to", json_schema_extra=Categories.WebServer)
|
||||
port : int = Field(default=9090, description="Port to bind to", json_schema_extra=Categories.WebServer)
|
||||
allow_origins : List[str] = Field(default=[], description="Allowed CORS origins", json_schema_extra=Categories.WebServer)
|
||||
allow_credentials : bool = Field(default=True, description="Allow CORS credentials", json_schema_extra=Categories.WebServer)
|
||||
allow_methods : List[str] = Field(default=["*"], description="Methods allowed for CORS", json_schema_extra=Categories.WebServer)
|
||||
allow_headers : List[str] = Field(default=["*"], description="Headers allowed for CORS", json_schema_extra=Categories.WebServer)
|
||||
|
||||
# FEATURES
|
||||
esrgan : bool = Field(default=True, description="Enable/disable upscaling code", category='Features')
|
||||
internet_available : bool = Field(default=True, description="If true, attempt to download models on the fly; otherwise only use local models", category='Features')
|
||||
log_tokenization : bool = Field(default=False, description="Enable logging of parsed prompt tokens.", category='Features')
|
||||
patchmatch : bool = Field(default=True, description="Enable/disable patchmatch inpaint code", category='Features')
|
||||
ignore_missing_core_models : bool = Field(default=False, description='Ignore missing models in models/core/convert', category='Features')
|
||||
esrgan : bool = Field(default=True, description="Enable/disable upscaling code", json_schema_extra=Categories.Features)
|
||||
internet_available : bool = Field(default=True, description="If true, attempt to download models on the fly; otherwise only use local models", json_schema_extra=Categories.Features)
|
||||
log_tokenization : bool = Field(default=False, description="Enable logging of parsed prompt tokens.", json_schema_extra=Categories.Features)
|
||||
patchmatch : bool = Field(default=True, description="Enable/disable patchmatch inpaint code", json_schema_extra=Categories.Features)
|
||||
ignore_missing_core_models : bool = Field(default=False, description='Ignore missing models in models/core/convert', json_schema_extra=Categories.Features)
|
||||
|
||||
# PATHS
|
||||
root : Path = Field(default=None, description='InvokeAI runtime root directory', category='Paths')
|
||||
autoimport_dir : Path = Field(default='autoimport', description='Path to a directory of models files to be imported on startup.', category='Paths')
|
||||
lora_dir : Path = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', category='Paths')
|
||||
embedding_dir : Path = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', category='Paths')
|
||||
controlnet_dir : Path = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', category='Paths')
|
||||
conf_path : Path = Field(default='configs/models.yaml', description='Path to models definition file', category='Paths')
|
||||
models_dir : Path = Field(default='models', description='Path to the models directory', category='Paths')
|
||||
legacy_conf_dir : Path = Field(default='configs/stable-diffusion', description='Path to directory of legacy checkpoint config files', category='Paths')
|
||||
db_dir : Path = Field(default='databases', description='Path to InvokeAI databases directory', category='Paths')
|
||||
outdir : Path = Field(default='outputs', description='Default folder for output images', category='Paths')
|
||||
use_memory_db : bool = Field(default=False, description='Use in-memory database for storing image metadata', category='Paths')
|
||||
from_file : Path = Field(default=None, description='Take command input from the indicated file (command-line client only)', category='Paths')
|
||||
root : Optional[Path] = Field(default=None, description='InvokeAI runtime root directory', json_schema_extra=Categories.Paths)
|
||||
autoimport_dir : Optional[Path] = Field(default=Path('autoimport'), description='Path to a directory of models files to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
lora_dir : Optional[Path] = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
embedding_dir : Optional[Path] = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
controlnet_dir : Optional[Path] = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
conf_path : Optional[Path] = Field(default=Path('configs/models.yaml'), description='Path to models definition file', json_schema_extra=Categories.Paths)
|
||||
models_dir : Optional[Path] = Field(default=Path('models'), description='Path to the models directory', json_schema_extra=Categories.Paths)
|
||||
legacy_conf_dir : Optional[Path] = Field(default=Path('configs/stable-diffusion'), description='Path to directory of legacy checkpoint config files', json_schema_extra=Categories.Paths)
|
||||
db_dir : Optional[Path] = Field(default=Path('databases'), description='Path to InvokeAI databases directory', json_schema_extra=Categories.Paths)
|
||||
outdir : Optional[Path] = Field(default=Path('outputs'), description='Default folder for output images', json_schema_extra=Categories.Paths)
|
||||
use_memory_db : bool = Field(default=False, description='Use in-memory database for storing image metadata', json_schema_extra=Categories.Paths)
|
||||
from_file : Optional[Path] = Field(default=None, description='Take command input from the indicated file (command-line client only)', json_schema_extra=Categories.Paths)
|
||||
|
||||
# LOGGING
|
||||
log_handlers : List[str] = Field(default=["console"], description='Log handler. Valid options are "console", "file=<path>", "syslog=path|address:host:port", "http=<url>"', category="Logging")
|
||||
log_handlers : List[str] = Field(default=["console"], description='Log handler. Valid options are "console", "file=<path>", "syslog=path|address:host:port", "http=<url>"', json_schema_extra=Categories.Logging)
|
||||
# note - would be better to read the log_format values from logging.py, but this creates circular dependencies issues
|
||||
log_format : Literal['plain', 'color', 'syslog', 'legacy'] = Field(default="color", description='Log format. Use "plain" for text-only, "color" for colorized output, "legacy" for 2.3-style logging and "syslog" for syslog-style', category="Logging")
|
||||
log_level : Literal["debug", "info", "warning", "error", "critical"] = Field(default="info", description="Emit logging messages at this level or higher", category="Logging")
|
||||
log_sql : bool = Field(default=False, description="Log SQL queries", category="Logging")
|
||||
log_format : Literal['plain', 'color', 'syslog', 'legacy'] = Field(default="color", description='Log format. Use "plain" for text-only, "color" for colorized output, "legacy" for 2.3-style logging and "syslog" for syslog-style', json_schema_extra=Categories.Logging)
|
||||
log_level : Literal["debug", "info", "warning", "error", "critical"] = Field(default="info", description="Emit logging messages at this level or higher", json_schema_extra=Categories.Logging)
|
||||
log_sql : bool = Field(default=False, description="Log SQL queries", json_schema_extra=Categories.Logging)
|
||||
|
||||
dev_reload : bool = Field(default=False, description="Automatically reload when Python sources are changed.", category="Development")
|
||||
dev_reload : bool = Field(default=False, description="Automatically reload when Python sources are changed.", json_schema_extra=Categories.Development)
|
||||
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", json_schema_extra=Categories.Other)
|
||||
|
||||
# CACHE
|
||||
ram : float = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number, GB)", category="Model Cache", )
|
||||
vram : float = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number, GB)", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
ram : float = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number, GB)", json_schema_extra=Categories.ModelCache, )
|
||||
vram : float = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number, GB)", json_schema_extra=Categories.ModelCache, )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", json_schema_extra=Categories.ModelCache, )
|
||||
|
||||
# DEVICE
|
||||
device : Literal["auto", "cpu", "cuda", "cuda:1", "mps"] = Field(default="auto", description="Generation device", category="Device", )
|
||||
precision : Literal["auto", "float16", "float32", "autocast"] = Field(default="auto", description="Floating point precision", category="Device", )
|
||||
device : Literal["auto", "cpu", "cuda", "cuda:1", "mps"] = Field(default="auto", description="Generation device", json_schema_extra=Categories.Device)
|
||||
precision : Literal["auto", "float16", "float32", "autocast"] = Field(default="auto", description="Floating point precision", json_schema_extra=Categories.Device)
|
||||
|
||||
# GENERATION
|
||||
sequential_guidance : bool = Field(default=False, description="Whether to calculate guidance in serial instead of in parallel, lowering memory requirements", category="Generation", )
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", category="Generation", )
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", category="Generation", )
|
||||
sequential_guidance : bool = Field(default=False, description="Whether to calculate guidance in serial instead of in parallel, lowering memory requirements", json_schema_extra=Categories.Generation)
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", json_schema_extra=Categories.Generation)
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', json_schema_extra=Categories.Generation)
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", json_schema_extra=Categories.Generation)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", json_schema_extra=Categories.Generation)
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", json_schema_extra=Categories.Queue)
|
||||
|
||||
# NODES
|
||||
allow_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.", category="Nodes")
|
||||
deny_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to deny. Omit to deny none.", category="Nodes")
|
||||
node_cache_size : int = Field(default=512, description="How many cached nodes to keep in memory", category="Nodes", )
|
||||
allow_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.", json_schema_extra=Categories.Nodes)
|
||||
deny_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to deny. Omit to deny none.", json_schema_extra=Categories.Nodes)
|
||||
node_cache_size : int = Field(default=512, description="How many cached nodes to keep in memory", json_schema_extra=Categories.Nodes)
|
||||
|
||||
# DEPRECATED FIELDS - STILL HERE IN ORDER TO OBTAN VALUES FROM PRE-3.1 CONFIG FILES
|
||||
always_use_cpu : bool = Field(default=False, description="If true, use the CPU for rendering even if a GPU is available.", category='Memory/Performance')
|
||||
free_gpu_mem : Optional[bool] = Field(default=None, description="If true, purge model from GPU after each generation.", category='Memory/Performance')
|
||||
max_cache_size : Optional[float] = Field(default=None, gt=0, description="Maximum memory amount used by model cache for rapid switching", category='Memory/Performance')
|
||||
max_vram_cache_size : Optional[float] = Field(default=None, ge=0, description="Amount of VRAM reserved for model storage", category='Memory/Performance')
|
||||
xformers_enabled : bool = Field(default=True, description="Enable/disable memory-efficient attention", category='Memory/Performance')
|
||||
tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category='Memory/Performance')
|
||||
always_use_cpu : bool = Field(default=False, description="If true, use the CPU for rendering even if a GPU is available.", json_schema_extra=Categories.MemoryPerformance)
|
||||
free_gpu_mem : Optional[bool] = Field(default=None, description="If true, purge model from GPU after each generation.", json_schema_extra=Categories.MemoryPerformance)
|
||||
max_cache_size : Optional[float] = Field(default=None, gt=0, description="Maximum memory amount used by model cache for rapid switching", json_schema_extra=Categories.MemoryPerformance)
|
||||
max_vram_cache_size : Optional[float] = Field(default=None, ge=0, description="Amount of VRAM reserved for model storage", json_schema_extra=Categories.MemoryPerformance)
|
||||
xformers_enabled : bool = Field(default=True, description="Enable/disable memory-efficient attention", json_schema_extra=Categories.MemoryPerformance)
|
||||
tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", json_schema_extra=Categories.MemoryPerformance)
|
||||
|
||||
# See InvokeAIAppConfig subclass below for CACHE and DEVICE categories
|
||||
# fmt: on
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
model_config = SettingsConfigDict(validate_assignment=True, env_prefix="INVOKEAI")
|
||||
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
def parse_args(
|
||||
self,
|
||||
argv: Optional[list[str]] = None,
|
||||
conf: Optional[DictConfig] = None,
|
||||
clobber=False,
|
||||
):
|
||||
"""
|
||||
Update settings with contents of init file, environment, and
|
||||
command-line settings.
|
||||
@ -308,7 +326,11 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
if self.singleton_init and not clobber:
|
||||
hints = get_type_hints(self.__class__)
|
||||
for k in self.singleton_init:
|
||||
setattr(self, k, parse_obj_as(hints[k], self.singleton_init[k]))
|
||||
setattr(
|
||||
self,
|
||||
k,
|
||||
TypeAdapter(hints[k]).validate_python(self.singleton_init[k]),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_config(cls, **kwargs) -> InvokeAIAppConfig:
|
||||
|
||||
@ -2,7 +2,6 @@
|
||||
|
||||
from typing import Any, Optional
|
||||
|
||||
from invokeai.app.invocations.model import ModelInfo
|
||||
from invokeai.app.services.invocation_processor.invocation_processor_common import ProgressImage
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
BatchStatus,
|
||||
@ -11,6 +10,7 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
from invokeai.backend.model_management.model_manager import ModelInfo
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
@ -55,7 +55,7 @@ class EventServiceBase:
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node.get("id"),
|
||||
source_node_id=source_node_id,
|
||||
progress_image=progress_image.dict() if progress_image is not None else None,
|
||||
progress_image=progress_image.model_dump() if progress_image is not None else None,
|
||||
step=step,
|
||||
order=order,
|
||||
total_steps=total_steps,
|
||||
@ -291,8 +291,8 @@ class EventServiceBase:
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
batch_status=batch_status.dict(),
|
||||
queue_status=queue_status.dict(),
|
||||
batch_status=batch_status.model_dump(),
|
||||
queue_status=queue_status.model_dump(),
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
@ -13,7 +14,7 @@ class ImageFileStorageBase(ABC):
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> Path:
|
||||
"""Gets the internal path to an image or thumbnail."""
|
||||
pass
|
||||
|
||||
|
||||
@ -34,8 +34,8 @@ class ImageRecordStorageBase(ABC):
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: Optional[int] = None,
|
||||
limit: Optional[int] = None,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
@ -69,11 +69,11 @@ class ImageRecordStorageBase(ABC):
|
||||
image_category: ImageCategory,
|
||||
width: int,
|
||||
height: int,
|
||||
session_id: Optional[str],
|
||||
node_id: Optional[str],
|
||||
metadata: Optional[dict],
|
||||
is_intermediate: bool = False,
|
||||
starred: bool = False,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
starred: Optional[bool] = False,
|
||||
session_id: Optional[str] = None,
|
||||
node_id: Optional[str] = None,
|
||||
metadata: Optional[dict] = None,
|
||||
) -> datetime:
|
||||
"""Saves an image record."""
|
||||
pass
|
||||
|
||||
@ -3,7 +3,7 @@ import datetime
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import Extra, Field, StrictBool, StrictStr
|
||||
from pydantic import Field, StrictBool, StrictStr
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
@ -129,7 +129,9 @@ class ImageRecord(BaseModelExcludeNull):
|
||||
"""The created timestamp of the image."""
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="The updated timestamp of the image.")
|
||||
"""The updated timestamp of the image."""
|
||||
deleted_at: Union[datetime.datetime, str, None] = Field(description="The deleted timestamp of the image.")
|
||||
deleted_at: Optional[Union[datetime.datetime, str]] = Field(
|
||||
default=None, description="The deleted timestamp of the image."
|
||||
)
|
||||
"""The deleted timestamp of the image."""
|
||||
is_intermediate: bool = Field(description="Whether this is an intermediate image.")
|
||||
"""Whether this is an intermediate image."""
|
||||
@ -147,7 +149,7 @@ class ImageRecord(BaseModelExcludeNull):
|
||||
"""Whether this image is starred."""
|
||||
|
||||
|
||||
class ImageRecordChanges(BaseModelExcludeNull, extra=Extra.forbid):
|
||||
class ImageRecordChanges(BaseModelExcludeNull, extra="allow"):
|
||||
"""A set of changes to apply to an image record.
|
||||
|
||||
Only limited changes are valid:
|
||||
|
||||
@ -2,7 +2,7 @@ import json
|
||||
import sqlite3
|
||||
import threading
|
||||
from datetime import datetime
|
||||
from typing import Optional, cast
|
||||
from typing import Optional, Union, cast
|
||||
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite import SqliteDatabase
|
||||
@ -24,7 +24,7 @@ from .image_records_common import (
|
||||
class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
@ -117,7 +117,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
"""
|
||||
)
|
||||
|
||||
def get(self, image_name: str) -> Optional[ImageRecord]:
|
||||
def get(self, image_name: str) -> ImageRecord:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
|
||||
@ -223,8 +223,8 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
offset: Optional[int] = None,
|
||||
limit: Optional[int] = None,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
@ -249,7 +249,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
"""
|
||||
|
||||
query_conditions = ""
|
||||
query_params = []
|
||||
query_params: list[Union[int, str, bool]] = []
|
||||
|
||||
if image_origin is not None:
|
||||
query_conditions += """--sql
|
||||
@ -387,13 +387,13 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
image_name: str,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
session_id: Optional[str],
|
||||
width: int,
|
||||
height: int,
|
||||
node_id: Optional[str],
|
||||
metadata: Optional[dict],
|
||||
is_intermediate: bool = False,
|
||||
starred: bool = False,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
starred: Optional[bool] = False,
|
||||
session_id: Optional[str] = None,
|
||||
node_id: Optional[str] = None,
|
||||
metadata: Optional[dict] = None,
|
||||
) -> datetime:
|
||||
try:
|
||||
metadata_json = None if metadata is None else json.dumps(metadata)
|
||||
|
||||
@ -49,7 +49,7 @@ class ImageServiceABC(ABC):
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
|
||||
@ -20,7 +20,9 @@ class ImageUrlsDTO(BaseModelExcludeNull):
|
||||
class ImageDTO(ImageRecord, ImageUrlsDTO):
|
||||
"""Deserialized image record, enriched for the frontend."""
|
||||
|
||||
board_id: Optional[str] = Field(description="The id of the board the image belongs to, if one exists.")
|
||||
board_id: Optional[str] = Field(
|
||||
default=None, description="The id of the board the image belongs to, if one exists."
|
||||
)
|
||||
"""The id of the board the image belongs to, if one exists."""
|
||||
|
||||
pass
|
||||
@ -34,7 +36,7 @@ def image_record_to_dto(
|
||||
) -> ImageDTO:
|
||||
"""Converts an image record to an image DTO."""
|
||||
return ImageDTO(
|
||||
**image_record.dict(),
|
||||
**image_record.model_dump(),
|
||||
image_url=image_url,
|
||||
thumbnail_url=thumbnail_url,
|
||||
board_id=board_id,
|
||||
|
||||
@ -41,7 +41,7 @@ class ImageService(ImageServiceABC):
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
@ -146,7 +146,7 @@ class ImageService(ImageServiceABC):
|
||||
self.__invoker.services.logger.error("Problem getting image DTO")
|
||||
raise e
|
||||
|
||||
def get_metadata(self, image_name: str) -> Optional[ImageMetadata]:
|
||||
def get_metadata(self, image_name: str) -> ImageMetadata:
|
||||
try:
|
||||
image_record = self.__invoker.services.image_records.get(image_name)
|
||||
metadata = self.__invoker.services.image_records.get_metadata(image_name)
|
||||
@ -174,7 +174,7 @@ class ImageService(ImageServiceABC):
|
||||
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
try:
|
||||
return self.__invoker.services.image_files.get_path(image_name, thumbnail)
|
||||
return str(self.__invoker.services.image_files.get_path(image_name, thumbnail))
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image path")
|
||||
raise e
|
||||
|
||||
@ -58,7 +58,12 @@ class MemoryInvocationCache(InvocationCacheBase):
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(invocation_output, invocation_output.json())
|
||||
self._cache[key] = CachedItem(
|
||||
invocation_output,
|
||||
invocation_output.model_dump_json(
|
||||
warnings=False, exclude_defaults=True, exclude_unset=True, include={"type"}
|
||||
),
|
||||
)
|
||||
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
@ -85,7 +90,7 @@ class MemoryInvocationCache(InvocationCacheBase):
|
||||
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
return hash(invocation.model_dump_json(exclude={"id"}, warnings=False))
|
||||
|
||||
def disable(self) -> None:
|
||||
with self._lock:
|
||||
|
||||
@ -4,7 +4,7 @@ from threading import BoundedSemaphore, Event, Thread
|
||||
from typing import Optional
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.invocations.baseinvocation import InvocationContext
|
||||
from invokeai.app.invocations.baseinvocation import AppInvocationContext
|
||||
from invokeai.app.services.invocation_queue.invocation_queue_common import InvocationQueueItem
|
||||
|
||||
from ..invoker import Invoker
|
||||
@ -89,25 +89,28 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
|
||||
# Invoke
|
||||
try:
|
||||
graph_id = graph_execution_state.id
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[invocation.id]
|
||||
|
||||
with self.__invoker.services.performance_statistics.collect_stats(invocation, graph_id):
|
||||
# use the internal invoke_internal(), which wraps the node's invoke() method,
|
||||
# which handles a few things:
|
||||
# - nodes that require a value, but get it only from a connection
|
||||
# - referencing the invocation cache instead of executing the node
|
||||
outputs = invocation.invoke_internal(
|
||||
InvocationContext(
|
||||
AppInvocationContext(
|
||||
services=self.__invoker.services,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
)
|
||||
|
||||
@ -127,9 +130,9 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
result=outputs.dict(),
|
||||
result=outputs.model_dump(),
|
||||
)
|
||||
self.__invoker.services.performance_statistics.log_stats()
|
||||
|
||||
@ -157,7 +160,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
error_type=e.__class__.__name__,
|
||||
error=error,
|
||||
@ -187,7 +190,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
error_type=e.__class__.__name__,
|
||||
error=traceback.format_exc(),
|
||||
|
||||
@ -72,7 +72,7 @@ class InvocationStatsService(InvocationStatsServiceBase):
|
||||
)
|
||||
self.collector.update_invocation_stats(
|
||||
graph_id=self.graph_id,
|
||||
invocation_type=self.invocation.type, # type: ignore - `type` is not on the `BaseInvocation` model, but *is* on all invocations
|
||||
invocation_type=self.invocation.type, # type: ignore # `type` is not on the `BaseInvocation` model, but *is* on all invocations
|
||||
time_used=time.time() - self.start_time,
|
||||
vram_used=torch.cuda.max_memory_allocated() / GIG if torch.cuda.is_available() else 0.0,
|
||||
)
|
||||
|
||||
@ -2,7 +2,7 @@ import sqlite3
|
||||
import threading
|
||||
from typing import Generic, Optional, TypeVar, get_args
|
||||
|
||||
from pydantic import BaseModel, parse_raw_as
|
||||
from pydantic import BaseModel, TypeAdapter
|
||||
|
||||
from invokeai.app.services.shared.pagination import PaginatedResults
|
||||
from invokeai.app.services.shared.sqlite import SqliteDatabase
|
||||
@ -17,7 +17,8 @@ class SqliteItemStorage(ItemStorageABC, Generic[T]):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_id_field: str
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
_adapter: Optional[TypeAdapter[T]]
|
||||
|
||||
def __init__(self, db: SqliteDatabase, table_name: str, id_field: str = "id"):
|
||||
super().__init__()
|
||||
@ -27,6 +28,7 @@ class SqliteItemStorage(ItemStorageABC, Generic[T]):
|
||||
self._table_name = table_name
|
||||
self._id_field = id_field # TODO: validate that T has this field
|
||||
self._cursor = self._conn.cursor()
|
||||
self._adapter: Optional[TypeAdapter[T]] = None
|
||||
|
||||
self._create_table()
|
||||
|
||||
@ -45,16 +47,21 @@ class SqliteItemStorage(ItemStorageABC, Generic[T]):
|
||||
self._lock.release()
|
||||
|
||||
def _parse_item(self, item: str) -> T:
|
||||
# __orig_class__ is technically an implementation detail of the typing module, not a supported API
|
||||
item_type = get_args(self.__orig_class__)[0] # type: ignore
|
||||
return parse_raw_as(item_type, item)
|
||||
if self._adapter is None:
|
||||
"""
|
||||
We don't get access to `__orig_class__` in `__init__()`, and we need this before start(), so
|
||||
we can create it when it is first needed instead.
|
||||
__orig_class__ is technically an implementation detail of the typing module, not a supported API
|
||||
"""
|
||||
self._adapter = TypeAdapter(get_args(self.__orig_class__)[0]) # type: ignore [attr-defined]
|
||||
return self._adapter.validate_json(item)
|
||||
|
||||
def set(self, item: T):
|
||||
try:
|
||||
self._lock.acquire()
|
||||
self._cursor.execute(
|
||||
f"""INSERT OR REPLACE INTO {self._table_name} (item) VALUES (?);""",
|
||||
(item.json(),),
|
||||
(item.model_dump_json(warnings=False, exclude_none=True),),
|
||||
)
|
||||
self._conn.commit()
|
||||
finally:
|
||||
|
||||
@ -48,9 +48,12 @@ class ModelManagerServiceBase(ABC):
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
node: Optional[BaseInvocation] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""Retrieve the indicated model with name and type.
|
||||
submodel can be used to get a part (such as the vae)
|
||||
@ -231,7 +234,7 @@ class ModelManagerServiceBase(ABC):
|
||||
def merge_models(
|
||||
self,
|
||||
model_names: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model names to merge"
|
||||
default=None, min_length=2, max_length=3, description="List of model names to merge"
|
||||
),
|
||||
base_model: Union[BaseModelType, str] = Field(
|
||||
default=None, description="Base model shared by all models to be merged"
|
||||
|
||||
@ -11,6 +11,7 @@ from pydantic import Field
|
||||
|
||||
from invokeai.app.services.config.config_default import InvokeAIAppConfig
|
||||
from invokeai.app.services.invocation_processor.invocation_processor_common import CanceledException
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.backend.model_management import (
|
||||
AddModelResult,
|
||||
BaseModelType,
|
||||
@ -86,28 +87,35 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
)
|
||||
logger.info("Model manager service initialized")
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self._invoker = invoker
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
context: Optional[InvocationContext] = None,
|
||||
) -> ModelInfo:
|
||||
"""
|
||||
Retrieve the indicated model. submodel can be used to get a
|
||||
part (such as the vae) of a diffusers mode.
|
||||
"""
|
||||
|
||||
# we can emit model loading events if we are executing with access to the invocation context
|
||||
if context:
|
||||
self._emit_load_event(
|
||||
context=context,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
)
|
||||
self._emit_load_event(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
)
|
||||
|
||||
model_info = self.mgr.get_model(
|
||||
model_name,
|
||||
@ -116,15 +124,17 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
submodel,
|
||||
)
|
||||
|
||||
if context:
|
||||
self._emit_load_event(
|
||||
context=context,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
model_info=model_info,
|
||||
)
|
||||
self._emit_load_event(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
submodel=submodel,
|
||||
model_info=model_info,
|
||||
)
|
||||
|
||||
return model_info
|
||||
|
||||
@ -263,22 +273,25 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
|
||||
def _emit_load_event(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
model_type: ModelType,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
submodel: Optional[SubModelType] = None,
|
||||
model_info: Optional[ModelInfo] = None,
|
||||
):
|
||||
if context.services.queue.is_canceled(context.graph_execution_state_id):
|
||||
if self._invoker.services.queue.is_canceled(graph_execution_state_id):
|
||||
raise CanceledException()
|
||||
|
||||
if model_info:
|
||||
context.services.events.emit_model_load_completed(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
self._invoker.services.events.emit_model_load_completed(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@ -286,11 +299,11 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
model_info=model_info,
|
||||
)
|
||||
else:
|
||||
context.services.events.emit_model_load_started(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
self._invoker.services.events.emit_model_load_started(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@ -327,7 +340,7 @@ class ModelManagerService(ModelManagerServiceBase):
|
||||
def merge_models(
|
||||
self,
|
||||
model_names: List[str] = Field(
|
||||
default=None, min_items=2, max_items=3, description="List of model names to merge"
|
||||
default=None, min_length=2, max_length=3, description="List of model names to merge"
|
||||
),
|
||||
base_model: Union[BaseModelType, str] = Field(
|
||||
default=None, description="Base model shared by all models to be merged"
|
||||
|
||||
@ -3,8 +3,8 @@ import json
|
||||
from itertools import chain, product
|
||||
from typing import Generator, Iterable, Literal, NamedTuple, Optional, TypeAlias, Union, cast
|
||||
|
||||
from pydantic import BaseModel, Field, StrictStr, parse_raw_as, root_validator, validator
|
||||
from pydantic.json import pydantic_encoder
|
||||
from pydantic import BaseModel, ConfigDict, Field, StrictStr, TypeAdapter, field_validator, model_validator
|
||||
from pydantic_core import to_jsonable_python
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation
|
||||
from invokeai.app.services.shared.graph import Graph, GraphExecutionState, NodeNotFoundError
|
||||
@ -17,7 +17,7 @@ class BatchZippedLengthError(ValueError):
|
||||
"""Raise when a batch has items of different lengths."""
|
||||
|
||||
|
||||
class BatchItemsTypeError(TypeError):
|
||||
class BatchItemsTypeError(ValueError): # this cannot be a TypeError in pydantic v2
|
||||
"""Raise when a batch has items of different types."""
|
||||
|
||||
|
||||
@ -70,7 +70,7 @@ class Batch(BaseModel):
|
||||
default=1, ge=1, description="Int stating how many times to iterate through all possible batch indices"
|
||||
)
|
||||
|
||||
@validator("data")
|
||||
@field_validator("data")
|
||||
def validate_lengths(cls, v: Optional[BatchDataCollection]):
|
||||
if v is None:
|
||||
return v
|
||||
@ -81,7 +81,7 @@ class Batch(BaseModel):
|
||||
raise BatchZippedLengthError("Zipped batch items must all have the same length")
|
||||
return v
|
||||
|
||||
@validator("data")
|
||||
@field_validator("data")
|
||||
def validate_types(cls, v: Optional[BatchDataCollection]):
|
||||
if v is None:
|
||||
return v
|
||||
@ -94,7 +94,7 @@ class Batch(BaseModel):
|
||||
raise BatchItemsTypeError("All items in a batch must have the same type")
|
||||
return v
|
||||
|
||||
@validator("data")
|
||||
@field_validator("data")
|
||||
def validate_unique_field_mappings(cls, v: Optional[BatchDataCollection]):
|
||||
if v is None:
|
||||
return v
|
||||
@ -107,34 +107,35 @@ class Batch(BaseModel):
|
||||
paths.add(pair)
|
||||
return v
|
||||
|
||||
@root_validator(skip_on_failure=True)
|
||||
@model_validator(mode="after")
|
||||
def validate_batch_nodes_and_edges(cls, values):
|
||||
batch_data_collection = cast(Optional[BatchDataCollection], values["data"])
|
||||
batch_data_collection = cast(Optional[BatchDataCollection], values.data)
|
||||
if batch_data_collection is None:
|
||||
return values
|
||||
graph = cast(Graph, values["graph"])
|
||||
graph = cast(Graph, values.graph)
|
||||
for batch_data_list in batch_data_collection:
|
||||
for batch_data in batch_data_list:
|
||||
try:
|
||||
node = cast(BaseInvocation, graph.get_node(batch_data.node_path))
|
||||
except NodeNotFoundError:
|
||||
raise NodeNotFoundError(f"Node {batch_data.node_path} not found in graph")
|
||||
if batch_data.field_name not in node.__fields__:
|
||||
if batch_data.field_name not in node.model_fields:
|
||||
raise NodeNotFoundError(f"Field {batch_data.field_name} not found in node {batch_data.node_path}")
|
||||
return values
|
||||
|
||||
@validator("graph")
|
||||
@field_validator("graph")
|
||||
def validate_graph(cls, v: Graph):
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
model_config = ConfigDict(
|
||||
json_schema_extra=dict(
|
||||
required=[
|
||||
"graph",
|
||||
"runs",
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
# endregion Batch
|
||||
@ -146,15 +147,21 @@ DEFAULT_QUEUE_ID = "default"
|
||||
|
||||
QUEUE_ITEM_STATUS = Literal["pending", "in_progress", "completed", "failed", "canceled"]
|
||||
|
||||
adapter_NodeFieldValue = TypeAdapter(list[NodeFieldValue])
|
||||
|
||||
|
||||
def get_field_values(queue_item_dict: dict) -> Optional[list[NodeFieldValue]]:
|
||||
field_values_raw = queue_item_dict.get("field_values", None)
|
||||
return parse_raw_as(list[NodeFieldValue], field_values_raw) if field_values_raw is not None else None
|
||||
return adapter_NodeFieldValue.validate_json(field_values_raw) if field_values_raw is not None else None
|
||||
|
||||
|
||||
adapter_GraphExecutionState = TypeAdapter(GraphExecutionState)
|
||||
|
||||
|
||||
def get_session(queue_item_dict: dict) -> GraphExecutionState:
|
||||
session_raw = queue_item_dict.get("session", "{}")
|
||||
return parse_raw_as(GraphExecutionState, session_raw)
|
||||
session = adapter_GraphExecutionState.validate_json(session_raw, strict=False)
|
||||
return session
|
||||
|
||||
|
||||
class SessionQueueItemWithoutGraph(BaseModel):
|
||||
@ -178,14 +185,14 @@ class SessionQueueItemWithoutGraph(BaseModel):
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, queue_item_dict: dict) -> "SessionQueueItemDTO":
|
||||
def queue_item_dto_from_dict(cls, queue_item_dict: dict) -> "SessionQueueItemDTO":
|
||||
# must parse these manually
|
||||
queue_item_dict["field_values"] = get_field_values(queue_item_dict)
|
||||
return SessionQueueItemDTO(**queue_item_dict)
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
model_config = ConfigDict(
|
||||
json_schema_extra=dict(
|
||||
required=[
|
||||
"item_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
@ -196,7 +203,8 @@ class SessionQueueItemWithoutGraph(BaseModel):
|
||||
"created_at",
|
||||
"updated_at",
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class SessionQueueItemDTO(SessionQueueItemWithoutGraph):
|
||||
@ -207,15 +215,15 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
session: GraphExecutionState = Field(description="The fully-populated session to be executed")
|
||||
|
||||
@classmethod
|
||||
def from_dict(cls, queue_item_dict: dict) -> "SessionQueueItem":
|
||||
def queue_item_from_dict(cls, queue_item_dict: dict) -> "SessionQueueItem":
|
||||
# must parse these manually
|
||||
queue_item_dict["field_values"] = get_field_values(queue_item_dict)
|
||||
queue_item_dict["session"] = get_session(queue_item_dict)
|
||||
return SessionQueueItem(**queue_item_dict)
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
model_config = ConfigDict(
|
||||
json_schema_extra=dict(
|
||||
required=[
|
||||
"item_id",
|
||||
"status",
|
||||
"batch_id",
|
||||
@ -227,7 +235,8 @@ class SessionQueueItem(SessionQueueItemWithoutGraph):
|
||||
"created_at",
|
||||
"updated_at",
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
# endregion Queue Items
|
||||
@ -321,7 +330,7 @@ def populate_graph(graph: Graph, node_field_values: Iterable[NodeFieldValue]) ->
|
||||
"""
|
||||
Populates the given graph with the given batch data items.
|
||||
"""
|
||||
graph_clone = graph.copy(deep=True)
|
||||
graph_clone = graph.model_copy(deep=True)
|
||||
for item in node_field_values:
|
||||
node = graph_clone.get_node(item.node_path)
|
||||
if node is None:
|
||||
@ -354,7 +363,7 @@ def create_session_nfv_tuples(
|
||||
for item in batch_datum.items
|
||||
]
|
||||
node_field_values_to_zip.append(node_field_values)
|
||||
data.append(list(zip(*node_field_values_to_zip)))
|
||||
data.append(list(zip(*node_field_values_to_zip))) # type: ignore [arg-type]
|
||||
|
||||
# create generator to yield session,nfv tuples
|
||||
count = 0
|
||||
@ -409,11 +418,11 @@ def prepare_values_to_insert(queue_id: str, batch: Batch, priority: int, max_new
|
||||
values_to_insert.append(
|
||||
SessionQueueValueToInsert(
|
||||
queue_id, # queue_id
|
||||
session.json(), # session (json)
|
||||
session.model_dump_json(warnings=False, exclude_none=True), # session (json)
|
||||
session.id, # session_id
|
||||
batch.batch_id, # batch_id
|
||||
# must use pydantic_encoder bc field_values is a list of models
|
||||
json.dumps(field_values, default=pydantic_encoder) if field_values else None, # field_values (json)
|
||||
json.dumps(field_values, default=to_jsonable_python) if field_values else None, # field_values (json)
|
||||
priority, # priority
|
||||
)
|
||||
)
|
||||
@ -421,3 +430,6 @@ def prepare_values_to_insert(queue_id: str, batch: Batch, priority: int, max_new
|
||||
|
||||
|
||||
# endregion Util
|
||||
|
||||
Batch.model_rebuild(force=True)
|
||||
SessionQueueItem.model_rebuild(force=True)
|
||||
|
||||
@ -37,7 +37,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
__invoker: Invoker
|
||||
__conn: sqlite3.Connection
|
||||
__cursor: sqlite3.Cursor
|
||||
__lock: threading.Lock
|
||||
__lock: threading.RLock
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
@ -277,8 +277,8 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
if result is None:
|
||||
raise SessionQueueItemNotFoundError(f"No queue item with batch id {enqueue_result.batch.batch_id}")
|
||||
return EnqueueGraphResult(
|
||||
**enqueue_result.dict(),
|
||||
queue_item=SessionQueueItemDTO.from_dict(dict(result)),
|
||||
**enqueue_result.model_dump(),
|
||||
queue_item=SessionQueueItemDTO.queue_item_dto_from_dict(dict(result)),
|
||||
)
|
||||
|
||||
def enqueue_batch(self, queue_id: str, batch: Batch, prepend: bool) -> EnqueueBatchResult:
|
||||
@ -351,7 +351,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
if result is None:
|
||||
return None
|
||||
queue_item = SessionQueueItem.from_dict(dict(result))
|
||||
queue_item = SessionQueueItem.queue_item_from_dict(dict(result))
|
||||
queue_item = self._set_queue_item_status(item_id=queue_item.item_id, status="in_progress")
|
||||
return queue_item
|
||||
|
||||
@ -380,7 +380,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
if result is None:
|
||||
return None
|
||||
return SessionQueueItem.from_dict(dict(result))
|
||||
return SessionQueueItem.queue_item_from_dict(dict(result))
|
||||
|
||||
def get_current(self, queue_id: str) -> Optional[SessionQueueItem]:
|
||||
try:
|
||||
@ -404,7 +404,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
if result is None:
|
||||
return None
|
||||
return SessionQueueItem.from_dict(dict(result))
|
||||
return SessionQueueItem.queue_item_from_dict(dict(result))
|
||||
|
||||
def _set_queue_item_status(
|
||||
self, item_id: int, status: QUEUE_ITEM_STATUS, error: Optional[str] = None
|
||||
@ -564,7 +564,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
queue_item = self.get_queue_item(item_id)
|
||||
if queue_item.status not in ["canceled", "failed", "completed"]:
|
||||
status = "failed" if error is not None else "canceled"
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status=status, error=error)
|
||||
queue_item = self._set_queue_item_status(item_id=item_id, status=status, error=error) # type: ignore [arg-type] # mypy seems to not narrow the Literals here
|
||||
self.__invoker.services.queue.cancel(queue_item.session_id)
|
||||
self.__invoker.services.events.emit_session_canceled(
|
||||
queue_item_id=queue_item.item_id,
|
||||
@ -699,7 +699,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
self.__lock.release()
|
||||
if result is None:
|
||||
raise SessionQueueItemNotFoundError(f"No queue item with id {item_id}")
|
||||
return SessionQueueItem.from_dict(dict(result))
|
||||
return SessionQueueItem.queue_item_from_dict(dict(result))
|
||||
|
||||
def list_queue_items(
|
||||
self,
|
||||
@ -751,7 +751,7 @@ class SqliteSessionQueue(SessionQueueBase):
|
||||
params.append(limit + 1)
|
||||
self.__cursor.execute(query, params)
|
||||
results = cast(list[sqlite3.Row], self.__cursor.fetchall())
|
||||
items = [SessionQueueItemDTO.from_dict(dict(result)) for result in results]
|
||||
items = [SessionQueueItemDTO.queue_item_dto_from_dict(dict(result)) for result in results]
|
||||
has_more = False
|
||||
if len(items) > limit:
|
||||
# remove the extra item
|
||||
|
||||
@ -80,10 +80,10 @@ def create_system_graphs(graph_library: ItemStorageABC[LibraryGraph]) -> list[Li
|
||||
# TODO: Uncomment this when we are ready to fix this up to prevent breaking changes
|
||||
graphs: list[LibraryGraph] = list()
|
||||
|
||||
# text_to_image = graph_library.get(default_text_to_image_graph_id)
|
||||
text_to_image = graph_library.get(default_text_to_image_graph_id)
|
||||
|
||||
# # TODO: Check if the graph is the same as the default one, and if not, update it
|
||||
# #if text_to_image is None:
|
||||
# TODO: Check if the graph is the same as the default one, and if not, update it
|
||||
# if text_to_image is None:
|
||||
text_to_image = create_text_to_image()
|
||||
graph_library.set(text_to_image)
|
||||
|
||||
|
||||
@ -5,7 +5,7 @@ import itertools
|
||||
from typing import Annotated, Any, Optional, Union, get_args, get_origin, get_type_hints
|
||||
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, root_validator, validator
|
||||
from pydantic import BaseModel, ConfigDict, field_validator, model_validator
|
||||
from pydantic.fields import Field
|
||||
|
||||
# Importing * is bad karma but needed here for node detection
|
||||
@ -235,7 +235,8 @@ class CollectInvocationOutput(BaseInvocationOutput):
|
||||
class CollectInvocation(BaseInvocation):
|
||||
"""Collects values into a collection"""
|
||||
|
||||
item: Any = InputField(
|
||||
item: Optional[Any] = InputField(
|
||||
default=None,
|
||||
description="The item to collect (all inputs must be of the same type)",
|
||||
ui_type=UIType.CollectionItem,
|
||||
title="Collection Item",
|
||||
@ -250,8 +251,8 @@ class CollectInvocation(BaseInvocation):
|
||||
return CollectInvocationOutput(collection=copy.copy(self.collection))
|
||||
|
||||
|
||||
InvocationsUnion = Union[BaseInvocation.get_invocations()] # type: ignore
|
||||
InvocationOutputsUnion = Union[BaseInvocationOutput.get_all_subclasses_tuple()] # type: ignore
|
||||
InvocationsUnion: Any = BaseInvocation.get_invocations_union()
|
||||
InvocationOutputsUnion: Any = BaseInvocationOutput.get_outputs_union()
|
||||
|
||||
|
||||
class Graph(BaseModel):
|
||||
@ -378,13 +379,13 @@ class Graph(BaseModel):
|
||||
raise NodeNotFoundError(f"Edge destination node {edge.destination.node_id} does not exist in the graph")
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
if edge.source.field not in source_node.get_output_type().model_fields:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
if edge.destination.field not in destination_node.model_fields:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
@ -395,24 +396,24 @@ class Graph(BaseModel):
|
||||
raise CyclicalGraphError("Graph contains cycles")
|
||||
|
||||
# Validate all edge connections are valid
|
||||
for e in self.edges:
|
||||
for edge in self.edges:
|
||||
if not are_connections_compatible(
|
||||
self.get_node(e.source.node_id),
|
||||
e.source.field,
|
||||
self.get_node(e.destination.node_id),
|
||||
e.destination.field,
|
||||
self.get_node(edge.source.node_id),
|
||||
edge.source.field,
|
||||
self.get_node(edge.destination.node_id),
|
||||
edge.destination.field,
|
||||
):
|
||||
raise InvalidEdgeError(
|
||||
f"Invalid edge from {e.source.node_id}.{e.source.field} to {e.destination.node_id}.{e.destination.field}"
|
||||
f"Invalid edge from {edge.source.node_id}.{edge.source.field} to {edge.destination.node_id}.{edge.destination.field}"
|
||||
)
|
||||
|
||||
# Validate all iterators & collectors
|
||||
# TODO: may need to validate all iterators & collectors in subgraphs so edge connections in parent graphs will be available
|
||||
for n in self.nodes.values():
|
||||
if isinstance(n, IterateInvocation) and not self._is_iterator_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid iterator node {n.id}")
|
||||
if isinstance(n, CollectInvocation) and not self._is_collector_connection_valid(n.id):
|
||||
raise InvalidEdgeError(f"Invalid collector node {n.id}")
|
||||
for node in self.nodes.values():
|
||||
if isinstance(node, IterateInvocation) and not self._is_iterator_connection_valid(node.id):
|
||||
raise InvalidEdgeError(f"Invalid iterator node {node.id}")
|
||||
if isinstance(node, CollectInvocation) and not self._is_collector_connection_valid(node.id):
|
||||
raise InvalidEdgeError(f"Invalid collector node {node.id}")
|
||||
|
||||
return None
|
||||
|
||||
@ -594,7 +595,7 @@ class Graph(BaseModel):
|
||||
|
||||
def _get_input_edges_and_graphs(
|
||||
self, node_path: str, prefix: Optional[str] = None
|
||||
) -> list[tuple["Graph", str, Edge]]:
|
||||
) -> list[tuple["Graph", Union[str, None], Edge]]:
|
||||
"""Gets all input edges for a node along with the graph they are in and the graph's path"""
|
||||
edges = list()
|
||||
|
||||
@ -636,7 +637,7 @@ class Graph(BaseModel):
|
||||
|
||||
def _get_output_edges_and_graphs(
|
||||
self, node_path: str, prefix: Optional[str] = None
|
||||
) -> list[tuple["Graph", str, Edge]]:
|
||||
) -> list[tuple["Graph", Union[str, None], Edge]]:
|
||||
"""Gets all output edges for a node along with the graph they are in and the graph's path"""
|
||||
edges = list()
|
||||
|
||||
@ -817,15 +818,15 @@ class GraphExecutionState(BaseModel):
|
||||
default_factory=dict,
|
||||
)
|
||||
|
||||
@validator("graph")
|
||||
@field_validator("graph")
|
||||
def graph_is_valid(cls, v: Graph):
|
||||
"""Validates that the graph is valid"""
|
||||
v.validate_self()
|
||||
return v
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
model_config = ConfigDict(
|
||||
json_schema_extra=dict(
|
||||
required=[
|
||||
"id",
|
||||
"graph",
|
||||
"execution_graph",
|
||||
@ -836,7 +837,8 @@ class GraphExecutionState(BaseModel):
|
||||
"prepared_source_mapping",
|
||||
"source_prepared_mapping",
|
||||
]
|
||||
}
|
||||
)
|
||||
)
|
||||
|
||||
def next(self) -> Optional[BaseInvocation]:
|
||||
"""Gets the next node ready to execute."""
|
||||
@ -910,7 +912,7 @@ class GraphExecutionState(BaseModel):
|
||||
input_collection = getattr(input_collection_prepared_node_output, input_collection_edge.source.field)
|
||||
self_iteration_count = len(input_collection)
|
||||
|
||||
new_nodes = list()
|
||||
new_nodes: list[str] = list()
|
||||
if self_iteration_count == 0:
|
||||
# TODO: should this raise a warning? It might just happen if an empty collection is input, and should be valid.
|
||||
return new_nodes
|
||||
@ -920,7 +922,7 @@ class GraphExecutionState(BaseModel):
|
||||
|
||||
# Create new edges for this iteration
|
||||
# For collect nodes, this may contain multiple inputs to the same field
|
||||
new_edges = list()
|
||||
new_edges: list[Edge] = list()
|
||||
for edge in input_edges:
|
||||
for input_node_id in (n[1] for n in iteration_node_map if n[0] == edge.source.node_id):
|
||||
new_edge = Edge(
|
||||
@ -1179,18 +1181,18 @@ class LibraryGraph(BaseModel):
|
||||
description="The outputs exposed by this graph", default_factory=list
|
||||
)
|
||||
|
||||
@validator("exposed_inputs", "exposed_outputs")
|
||||
def validate_exposed_aliases(cls, v):
|
||||
@field_validator("exposed_inputs", "exposed_outputs")
|
||||
def validate_exposed_aliases(cls, v: list[Union[ExposedNodeInput, ExposedNodeOutput]]):
|
||||
if len(v) != len(set(i.alias for i in v)):
|
||||
raise ValueError("Duplicate exposed alias")
|
||||
return v
|
||||
|
||||
@root_validator
|
||||
@model_validator(mode="after")
|
||||
def validate_exposed_nodes(cls, values):
|
||||
graph = values["graph"]
|
||||
graph = values.graph
|
||||
|
||||
# Validate exposed inputs
|
||||
for exposed_input in values["exposed_inputs"]:
|
||||
for exposed_input in values.exposed_inputs:
|
||||
if not graph.has_node(exposed_input.node_path):
|
||||
raise ValueError(f"Exposed input node {exposed_input.node_path} does not exist")
|
||||
node = graph.get_node(exposed_input.node_path)
|
||||
@ -1200,7 +1202,7 @@ class LibraryGraph(BaseModel):
|
||||
)
|
||||
|
||||
# Validate exposed outputs
|
||||
for exposed_output in values["exposed_outputs"]:
|
||||
for exposed_output in values.exposed_outputs:
|
||||
if not graph.has_node(exposed_output.node_path):
|
||||
raise ValueError(f"Exposed output node {exposed_output.node_path} does not exist")
|
||||
node = graph.get_node(exposed_output.node_path)
|
||||
@ -1212,4 +1214,6 @@ class LibraryGraph(BaseModel):
|
||||
return values
|
||||
|
||||
|
||||
GraphInvocation.update_forward_refs()
|
||||
GraphInvocation.model_rebuild(force=True)
|
||||
Graph.model_rebuild(force=True)
|
||||
GraphExecutionState.model_rebuild(force=True)
|
||||
|
||||
@ -1,12 +1,11 @@
|
||||
from typing import Generic, TypeVar
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic.generics import GenericModel
|
||||
|
||||
GenericBaseModel = TypeVar("GenericBaseModel", bound=BaseModel)
|
||||
|
||||
|
||||
class CursorPaginatedResults(GenericModel, Generic[GenericBaseModel]):
|
||||
class CursorPaginatedResults(BaseModel, Generic[GenericBaseModel]):
|
||||
"""
|
||||
Cursor-paginated results
|
||||
Generic must be a Pydantic model
|
||||
@ -17,7 +16,7 @@ class CursorPaginatedResults(GenericModel, Generic[GenericBaseModel]):
|
||||
items: list[GenericBaseModel] = Field(..., description="Items")
|
||||
|
||||
|
||||
class OffsetPaginatedResults(GenericModel, Generic[GenericBaseModel]):
|
||||
class OffsetPaginatedResults(BaseModel, Generic[GenericBaseModel]):
|
||||
"""
|
||||
Offset-paginated results
|
||||
Generic must be a Pydantic model
|
||||
@ -29,7 +28,7 @@ class OffsetPaginatedResults(GenericModel, Generic[GenericBaseModel]):
|
||||
items: list[GenericBaseModel] = Field(description="Items")
|
||||
|
||||
|
||||
class PaginatedResults(GenericModel, Generic[GenericBaseModel]):
|
||||
class PaginatedResults(BaseModel, Generic[GenericBaseModel]):
|
||||
"""
|
||||
Paginated results
|
||||
Generic must be a Pydantic model
|
||||
|
||||
@ -9,7 +9,7 @@ sqlite_memory = ":memory:"
|
||||
|
||||
class SqliteDatabase:
|
||||
conn: sqlite3.Connection
|
||||
lock: threading.Lock
|
||||
lock: threading.RLock
|
||||
_logger: Logger
|
||||
_config: InvokeAIAppConfig
|
||||
|
||||
@ -27,7 +27,7 @@ class SqliteDatabase:
|
||||
self._logger.info(f"Using database at {location}")
|
||||
|
||||
self.conn = sqlite3.connect(location, check_same_thread=False)
|
||||
self.lock = threading.Lock()
|
||||
self.lock = threading.RLock()
|
||||
self.conn.row_factory = sqlite3.Row
|
||||
|
||||
if self._config.log_sql:
|
||||
|
||||
@ -265,7 +265,7 @@ def np_img_resize(np_img: np.ndarray, resize_mode: str, h: int, w: int, device:
|
||||
|
||||
|
||||
def prepare_control_image(
|
||||
image: Image,
|
||||
image: Image.Image,
|
||||
width: int,
|
||||
height: int,
|
||||
num_channels: int = 3,
|
||||
|
||||
@ -1,4 +1,5 @@
|
||||
import datetime
|
||||
import typing
|
||||
import uuid
|
||||
|
||||
import numpy as np
|
||||
@ -27,3 +28,8 @@ def get_random_seed():
|
||||
def uuid_string():
|
||||
res = uuid.uuid4()
|
||||
return str(res)
|
||||
|
||||
|
||||
def is_optional(value: typing.Any):
|
||||
"""Checks if a value is typed as Optional. Note that Optional is sugar for Union[x, None]."""
|
||||
return typing.get_origin(value) is typing.Union and type(None) in typing.get_args(value)
|
||||
|
||||
@ -13,11 +13,11 @@ From https://github.com/tiangolo/fastapi/discussions/8882#discussioncomment-5154
|
||||
|
||||
|
||||
class BaseModelExcludeNull(BaseModel):
|
||||
def dict(self, *args, **kwargs) -> dict[str, Any]:
|
||||
def model_dump(self, *args, **kwargs) -> dict[str, Any]:
|
||||
"""
|
||||
Override the default dict method to exclude None values in the response
|
||||
"""
|
||||
kwargs.pop("exclude_none", None)
|
||||
return super().dict(*args, exclude_none=True, **kwargs)
|
||||
return super().model_dump(*args, exclude_none=True, **kwargs)
|
||||
|
||||
pass
|
||||
|
||||
@ -27,11 +27,9 @@ def sample_to_lowres_estimated_image(samples, latent_rgb_factors, smooth_matrix=
|
||||
def stable_diffusion_step_callback(
|
||||
context: InvocationContext,
|
||||
intermediate_state: PipelineIntermediateState,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
base_model: BaseModelType,
|
||||
):
|
||||
if context.services.queue.is_canceled(context.graph_execution_state_id):
|
||||
if context.is_canceled():
|
||||
raise CanceledException
|
||||
|
||||
# Some schedulers report not only the noisy latents at the current timestep,
|
||||
@ -108,13 +106,7 @@ def stable_diffusion_step_callback(
|
||||
|
||||
dataURL = image_to_dataURL(image, image_format="JPEG")
|
||||
|
||||
context.services.events.emit_generator_progress(
|
||||
queue_id=context.queue_id,
|
||||
queue_item_id=context.queue_item_id,
|
||||
queue_batch_id=context.queue_batch_id,
|
||||
graph_execution_state_id=context.graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
context.emit_denoising_progress(
|
||||
progress_image=ProgressImage(width=width, height=height, dataURL=dataURL),
|
||||
step=intermediate_state.step,
|
||||
order=intermediate_state.order,
|
||||
|
||||
0
invokeai/assets/__init__.py
Normal file
0
invokeai/assets/__init__.py
Normal file
@ -41,18 +41,18 @@ config = InvokeAIAppConfig.get_config()
|
||||
|
||||
|
||||
class SegmentedGrayscale(object):
|
||||
def __init__(self, image: Image, heatmap: torch.Tensor):
|
||||
def __init__(self, image: Image.Image, heatmap: torch.Tensor):
|
||||
self.heatmap = heatmap
|
||||
self.image = image
|
||||
|
||||
def to_grayscale(self, invert: bool = False) -> Image:
|
||||
def to_grayscale(self, invert: bool = False) -> Image.Image:
|
||||
return self._rescale(Image.fromarray(np.uint8(255 - self.heatmap * 255 if invert else self.heatmap * 255)))
|
||||
|
||||
def to_mask(self, threshold: float = 0.5) -> Image:
|
||||
def to_mask(self, threshold: float = 0.5) -> Image.Image:
|
||||
discrete_heatmap = self.heatmap.lt(threshold).int()
|
||||
return self._rescale(Image.fromarray(np.uint8(discrete_heatmap * 255), mode="L"))
|
||||
|
||||
def to_transparent(self, invert: bool = False) -> Image:
|
||||
def to_transparent(self, invert: bool = False) -> Image.Image:
|
||||
transparent_image = self.image.copy()
|
||||
# For img2img, we want the selected regions to be transparent,
|
||||
# but to_grayscale() returns the opposite. Thus invert.
|
||||
@ -61,7 +61,7 @@ class SegmentedGrayscale(object):
|
||||
return transparent_image
|
||||
|
||||
# unscales and uncrops the 352x352 heatmap so that it matches the image again
|
||||
def _rescale(self, heatmap: Image) -> Image:
|
||||
def _rescale(self, heatmap: Image.Image) -> Image.Image:
|
||||
size = self.image.width if (self.image.width > self.image.height) else self.image.height
|
||||
resized_image = heatmap.resize((size, size), resample=Image.Resampling.LANCZOS)
|
||||
return resized_image.crop((0, 0, self.image.width, self.image.height))
|
||||
@ -82,7 +82,7 @@ class Txt2Mask(object):
|
||||
self.model = CLIPSegForImageSegmentation.from_pretrained(CLIPSEG_MODEL, cache_dir=config.cache_dir)
|
||||
|
||||
@torch.no_grad()
|
||||
def segment(self, image, prompt: str) -> SegmentedGrayscale:
|
||||
def segment(self, image: Image.Image, prompt: str) -> SegmentedGrayscale:
|
||||
"""
|
||||
Given a prompt string such as "a bagel", tries to identify the object in the
|
||||
provided image and returns a SegmentedGrayscale object in which the brighter
|
||||
@ -99,7 +99,7 @@ class Txt2Mask(object):
|
||||
heatmap = torch.sigmoid(outputs.logits)
|
||||
return SegmentedGrayscale(image, heatmap)
|
||||
|
||||
def _scale_and_crop(self, image: Image) -> Image:
|
||||
def _scale_and_crop(self, image: Image.Image) -> Image.Image:
|
||||
scaled_image = Image.new("RGB", (CLIPSEG_SIZE, CLIPSEG_SIZE))
|
||||
if image.width > image.height: # width is constraint
|
||||
scale = CLIPSEG_SIZE / image.width
|
||||
|
||||
@ -9,7 +9,7 @@ class InitImageResizer:
|
||||
def __init__(self, Image):
|
||||
self.image = Image
|
||||
|
||||
def resize(self, width=None, height=None) -> Image:
|
||||
def resize(self, width=None, height=None) -> Image.Image:
|
||||
"""
|
||||
Return a copy of the image resized to fit within
|
||||
a box width x height. The aspect ratio is
|
||||
|
||||
@ -793,7 +793,11 @@ def migrate_init_file(legacy_format: Path):
|
||||
old = legacy_parser.parse_args([f"@{str(legacy_format)}"])
|
||||
new = InvokeAIAppConfig.get_config()
|
||||
|
||||
fields = [x for x, y in InvokeAIAppConfig.__fields__.items() if y.field_info.extra.get("category") != "DEPRECATED"]
|
||||
fields = [
|
||||
x
|
||||
for x, y in InvokeAIAppConfig.model_fields.items()
|
||||
if (y.json_schema_extra.get("category", None) if y.json_schema_extra else None) != "DEPRECATED"
|
||||
]
|
||||
for attr in fields:
|
||||
if hasattr(old, attr):
|
||||
try:
|
||||
|
||||
@ -236,9 +236,16 @@ class ModelInstall(object):
|
||||
if not models_installed:
|
||||
models_installed = dict()
|
||||
|
||||
model_path_id_or_url = str(model_path_id_or_url).strip("\"' ")
|
||||
|
||||
# A little hack to allow nested routines to retrieve info on the requested ID
|
||||
self.current_id = model_path_id_or_url
|
||||
path = Path(model_path_id_or_url)
|
||||
|
||||
# fix relative paths
|
||||
if path.exists() and not path.is_absolute():
|
||||
path = path.absolute() # make relative to current WD
|
||||
|
||||
# checkpoint file, or similar
|
||||
if path.is_file():
|
||||
models_installed.update({str(path): self._install_path(path)})
|
||||
|
||||
@ -55,8 +55,10 @@ class MemorySnapshot:
|
||||
|
||||
try:
|
||||
malloc_info = LibcUtil().mallinfo2()
|
||||
except OSError:
|
||||
# This is expected in environments that do not have the 'libc.so.6' shared library.
|
||||
except (OSError, AttributeError):
|
||||
# OSError: This is expected in environments that do not have the 'libc.so.6' shared library.
|
||||
# AttributeError: This is expected in environments that have `libc.so.6` but do not have the `mallinfo2` (e.g. glibc < 2.33)
|
||||
# TODO: Does `mallinfo` work?
|
||||
malloc_info = None
|
||||
|
||||
return cls(process_ram, vram, malloc_info)
|
||||
|
||||
@ -236,13 +236,13 @@ import types
|
||||
from dataclasses import dataclass
|
||||
from pathlib import Path
|
||||
from shutil import move, rmtree
|
||||
from typing import Callable, Dict, List, Literal, Optional, Set, Tuple, Union
|
||||
from typing import Callable, Dict, List, Literal, Optional, Set, Tuple, Union, cast
|
||||
|
||||
import torch
|
||||
import yaml
|
||||
from omegaconf import OmegaConf
|
||||
from omegaconf.dictconfig import DictConfig
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
@ -294,6 +294,8 @@ class AddModelResult(BaseModel):
|
||||
base_model: BaseModelType = Field(description="The base model")
|
||||
config: ModelConfigBase = Field(description="The configuration of the model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
MAX_CACHE_SIZE = 6.0 # GB
|
||||
|
||||
@ -576,7 +578,7 @@ class ModelManager(object):
|
||||
"""
|
||||
model_key = self.create_key(model_name, base_model, model_type)
|
||||
if model_key in self.models:
|
||||
return self.models[model_key].dict(exclude_defaults=True)
|
||||
return self.models[model_key].model_dump(exclude_defaults=True)
|
||||
else:
|
||||
return None # TODO: None or empty dict on not found
|
||||
|
||||
@ -632,7 +634,7 @@ class ModelManager(object):
|
||||
continue
|
||||
|
||||
model_dict = dict(
|
||||
**model_config.dict(exclude_defaults=True),
|
||||
**model_config.model_dump(exclude_defaults=True),
|
||||
# OpenAPIModelInfoBase
|
||||
model_name=cur_model_name,
|
||||
base_model=cur_base_model,
|
||||
@ -900,14 +902,16 @@ class ModelManager(object):
|
||||
Write current configuration out to the indicated file.
|
||||
"""
|
||||
data_to_save = dict()
|
||||
data_to_save["__metadata__"] = self.config_meta.dict()
|
||||
data_to_save["__metadata__"] = self.config_meta.model_dump()
|
||||
|
||||
for model_key, model_config in self.models.items():
|
||||
model_name, base_model, model_type = self.parse_key(model_key)
|
||||
model_class = self._get_implementation(base_model, model_type)
|
||||
if model_class.save_to_config:
|
||||
# TODO: or exclude_unset better fits here?
|
||||
data_to_save[model_key] = model_config.dict(exclude_defaults=True, exclude={"error"})
|
||||
data_to_save[model_key] = cast(BaseModel, model_config).model_dump(
|
||||
exclude_defaults=True, exclude={"error"}, mode="json"
|
||||
)
|
||||
# alias for config file
|
||||
data_to_save[model_key]["format"] = data_to_save[model_key].pop("model_format")
|
||||
|
||||
@ -986,6 +990,8 @@ class ModelManager(object):
|
||||
|
||||
for model_path in models_dir.iterdir():
|
||||
if model_path not in loaded_files: # TODO: check
|
||||
if model_path.name.startswith("."):
|
||||
continue
|
||||
model_name = model_path.name if model_path.is_dir() else model_path.stem
|
||||
model_key = self.create_key(model_name, cur_base_model, cur_model_type)
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@ import inspect
|
||||
from enum import Enum
|
||||
from typing import Literal, get_origin
|
||||
|
||||
from pydantic import BaseModel
|
||||
from pydantic import BaseModel, ConfigDict, create_model
|
||||
|
||||
from .base import ( # noqa: F401
|
||||
BaseModelType,
|
||||
@ -106,6 +106,8 @@ class OpenAPIModelInfoBase(BaseModel):
|
||||
base_model: BaseModelType
|
||||
model_type: ModelType
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
for base_model, models in MODEL_CLASSES.items():
|
||||
for model_type, model_class in models.items():
|
||||
@ -121,17 +123,11 @@ for base_model, models in MODEL_CLASSES.items():
|
||||
if openapi_cfg_name in vars():
|
||||
continue
|
||||
|
||||
api_wrapper = type(
|
||||
api_wrapper = create_model(
|
||||
openapi_cfg_name,
|
||||
(cfg, OpenAPIModelInfoBase),
|
||||
dict(
|
||||
__annotations__=dict(
|
||||
model_type=Literal[model_type.value],
|
||||
),
|
||||
),
|
||||
__base__=(cfg, OpenAPIModelInfoBase),
|
||||
model_type=(Literal[model_type], model_type), # type: ignore
|
||||
)
|
||||
|
||||
# globals()[openapi_cfg_name] = api_wrapper
|
||||
vars()[openapi_cfg_name] = api_wrapper
|
||||
OPENAPI_MODEL_CONFIGS.append(api_wrapper)
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ from diffusers import logging as diffusers_logging
|
||||
from onnx import numpy_helper
|
||||
from onnxruntime import InferenceSession, SessionOptions, get_available_providers
|
||||
from picklescan.scanner import scan_file_path
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
from transformers import logging as transformers_logging
|
||||
|
||||
|
||||
@ -86,14 +86,21 @@ class ModelError(str, Enum):
|
||||
NotFound = "not_found"
|
||||
|
||||
|
||||
def model_config_json_schema_extra(schema: dict[str, Any]) -> None:
|
||||
if "required" not in schema:
|
||||
schema["required"] = []
|
||||
schema["required"].append("model_type")
|
||||
|
||||
|
||||
class ModelConfigBase(BaseModel):
|
||||
path: str # or Path
|
||||
description: Optional[str] = Field(None)
|
||||
model_format: Optional[str] = Field(None)
|
||||
error: Optional[ModelError] = Field(None)
|
||||
|
||||
class Config:
|
||||
use_enum_values = True
|
||||
model_config = ConfigDict(
|
||||
use_enum_values=True, protected_namespaces=(), json_schema_extra=model_config_json_schema_extra
|
||||
)
|
||||
|
||||
|
||||
class EmptyConfigLoader(ConfigMixin):
|
||||
|
||||
@ -58,14 +58,16 @@ class IPAdapterModel(ModelBase):
|
||||
|
||||
def get_model(
|
||||
self,
|
||||
torch_dtype: Optional[torch.dtype],
|
||||
torch_dtype: torch.dtype,
|
||||
child_type: Optional[SubModelType] = None,
|
||||
) -> typing.Union[IPAdapter, IPAdapterPlus]:
|
||||
if child_type is not None:
|
||||
raise ValueError("There are no child models in an IP-Adapter model.")
|
||||
|
||||
model = build_ip_adapter(
|
||||
ip_adapter_ckpt_path=os.path.join(self.model_path, "ip_adapter.bin"), device="cpu", dtype=torch_dtype
|
||||
ip_adapter_ckpt_path=os.path.join(self.model_path, "ip_adapter.bin"),
|
||||
device=torch.device("cpu"),
|
||||
dtype=torch_dtype,
|
||||
)
|
||||
|
||||
self.model_size = model.calc_size()
|
||||
|
||||
@ -96,7 +96,7 @@ def set_seamless(model: Union[UNet2DConditionModel, AutoencoderKL], seamless_axe
|
||||
finally:
|
||||
for module, orig_conv_forward in to_restore:
|
||||
module._conv_forward = orig_conv_forward
|
||||
if hasattr(m, "asymmetric_padding_mode"):
|
||||
del m.asymmetric_padding_mode
|
||||
if hasattr(m, "asymmetric_padding"):
|
||||
del m.asymmetric_padding
|
||||
if hasattr(module, "asymmetric_padding_mode"):
|
||||
del module.asymmetric_padding_mode
|
||||
if hasattr(module, "asymmetric_padding"):
|
||||
del module.asymmetric_padding
|
||||
|
||||
@ -1,7 +1,8 @@
|
||||
import math
|
||||
from typing import Optional
|
||||
|
||||
import PIL
|
||||
import torch
|
||||
from PIL import Image
|
||||
from torchvision.transforms.functional import InterpolationMode
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
@ -11,7 +12,7 @@ class AttentionMapSaver:
|
||||
self.token_ids = token_ids
|
||||
self.latents_shape = latents_shape
|
||||
# self.collated_maps = #torch.zeros([len(token_ids), latents_shape[0], latents_shape[1]])
|
||||
self.collated_maps = {}
|
||||
self.collated_maps: dict[str, torch.Tensor] = {}
|
||||
|
||||
def clear_maps(self):
|
||||
self.collated_maps = {}
|
||||
@ -38,9 +39,10 @@ class AttentionMapSaver:
|
||||
|
||||
def write_maps_to_disk(self, path: str):
|
||||
pil_image = self.get_stacked_maps_image()
|
||||
pil_image.save(path, "PNG")
|
||||
if pil_image is not None:
|
||||
pil_image.save(path, "PNG")
|
||||
|
||||
def get_stacked_maps_image(self) -> PIL.Image:
|
||||
def get_stacked_maps_image(self) -> Optional[Image.Image]:
|
||||
"""
|
||||
Scale all collected attention maps to the same size, blend them together and return as an image.
|
||||
:return: An image containing a vertical stack of blended attention maps, one for each requested token.
|
||||
@ -95,4 +97,4 @@ class AttentionMapSaver:
|
||||
return None
|
||||
|
||||
merged_bytes = merged.mul(0xFF).byte()
|
||||
return PIL.Image.fromarray(merged_bytes.numpy(), mode="L")
|
||||
return Image.fromarray(merged_bytes.numpy(), mode="L")
|
||||
|
||||
@ -54,42 +54,42 @@
|
||||
]
|
||||
},
|
||||
"dependencies": {
|
||||
"@chakra-ui/anatomy": "^2.2.0",
|
||||
"@chakra-ui/icons": "^2.1.0",
|
||||
"@chakra-ui/react": "^2.8.0",
|
||||
"@chakra-ui/anatomy": "^2.2.1",
|
||||
"@chakra-ui/icons": "^2.1.1",
|
||||
"@chakra-ui/react": "^2.8.1",
|
||||
"@chakra-ui/styled-system": "^2.9.1",
|
||||
"@chakra-ui/theme-tools": "^2.1.0",
|
||||
"@chakra-ui/theme-tools": "^2.1.1",
|
||||
"@dagrejs/graphlib": "^2.1.13",
|
||||
"@dnd-kit/core": "^6.0.8",
|
||||
"@dnd-kit/modifiers": "^6.0.1",
|
||||
"@dnd-kit/utilities": "^3.2.1",
|
||||
"@emotion/react": "^11.11.1",
|
||||
"@emotion/styled": "^11.11.0",
|
||||
"@floating-ui/react-dom": "^2.0.1",
|
||||
"@fontsource-variable/inter": "^5.0.8",
|
||||
"@fontsource/inter": "^5.0.8",
|
||||
"@floating-ui/react-dom": "^2.0.2",
|
||||
"@fontsource-variable/inter": "^5.0.13",
|
||||
"@fontsource/inter": "^5.0.13",
|
||||
"@mantine/core": "^6.0.19",
|
||||
"@mantine/form": "^6.0.19",
|
||||
"@mantine/hooks": "^6.0.19",
|
||||
"@nanostores/react": "^0.7.1",
|
||||
"@reduxjs/toolkit": "^1.9.5",
|
||||
"@roarr/browser-log-writer": "^1.1.5",
|
||||
"@reduxjs/toolkit": "^1.9.7",
|
||||
"@roarr/browser-log-writer": "^1.3.0",
|
||||
"@stevebel/png": "^1.5.1",
|
||||
"compare-versions": "^6.1.0",
|
||||
"dateformat": "^5.0.3",
|
||||
"formik": "^2.4.3",
|
||||
"framer-motion": "^10.16.1",
|
||||
"formik": "^2.4.5",
|
||||
"framer-motion": "^10.16.4",
|
||||
"fuse.js": "^6.6.2",
|
||||
"i18next": "^23.4.4",
|
||||
"i18next": "^23.5.1",
|
||||
"i18next-browser-languagedetector": "^7.0.2",
|
||||
"i18next-http-backend": "^2.2.1",
|
||||
"konva": "^9.2.0",
|
||||
"i18next-http-backend": "^2.2.2",
|
||||
"konva": "^9.2.2",
|
||||
"lodash-es": "^4.17.21",
|
||||
"nanostores": "^0.9.2",
|
||||
"new-github-issue-url": "^1.0.0",
|
||||
"openapi-fetch": "^0.7.4",
|
||||
"overlayscrollbars": "^2.2.0",
|
||||
"overlayscrollbars-react": "^0.5.0",
|
||||
"openapi-fetch": "^0.7.10",
|
||||
"overlayscrollbars": "^2.3.2",
|
||||
"overlayscrollbars-react": "^0.5.2",
|
||||
"patch-package": "^8.0.0",
|
||||
"query-string": "^8.1.0",
|
||||
"react": "^18.2.0",
|
||||
@ -98,25 +98,25 @@
|
||||
"react-dropzone": "^14.2.3",
|
||||
"react-error-boundary": "^4.0.11",
|
||||
"react-hotkeys-hook": "4.4.1",
|
||||
"react-i18next": "^13.1.2",
|
||||
"react-icons": "^4.10.1",
|
||||
"react-i18next": "^13.3.0",
|
||||
"react-icons": "^4.11.0",
|
||||
"react-konva": "^18.2.10",
|
||||
"react-redux": "^8.1.2",
|
||||
"react-redux": "^8.1.3",
|
||||
"react-resizable-panels": "^0.0.55",
|
||||
"react-use": "^17.4.0",
|
||||
"react-virtuoso": "^4.5.0",
|
||||
"react-zoom-pan-pinch": "^3.0.8",
|
||||
"reactflow": "^11.8.3",
|
||||
"react-virtuoso": "^4.6.1",
|
||||
"react-zoom-pan-pinch": "^3.2.0",
|
||||
"reactflow": "^11.9.3",
|
||||
"redux-dynamic-middlewares": "^2.2.0",
|
||||
"redux-remember": "^4.0.1",
|
||||
"redux-remember": "^4.0.4",
|
||||
"roarr": "^7.15.1",
|
||||
"serialize-error": "^11.0.1",
|
||||
"serialize-error": "^11.0.2",
|
||||
"socket.io-client": "^4.7.2",
|
||||
"type-fest": "^4.2.0",
|
||||
"type-fest": "^4.4.0",
|
||||
"use-debounce": "^9.0.4",
|
||||
"use-image": "^1.1.1",
|
||||
"uuid": "^9.0.0",
|
||||
"zod": "^3.22.2",
|
||||
"uuid": "^9.0.1",
|
||||
"zod": "^3.22.4",
|
||||
"zod-validation-error": "^1.5.0"
|
||||
},
|
||||
"peerDependencies": {
|
||||
@ -129,40 +129,40 @@
|
||||
"devDependencies": {
|
||||
"@chakra-ui/cli": "^2.4.1",
|
||||
"@types/dateformat": "^5.0.0",
|
||||
"@types/lodash-es": "^4.14.194",
|
||||
"@types/node": "^20.5.1",
|
||||
"@types/react": "^18.2.20",
|
||||
"@types/react-dom": "^18.2.6",
|
||||
"@types/react-redux": "^7.1.25",
|
||||
"@types/react-transition-group": "^4.4.6",
|
||||
"@types/uuid": "^9.0.2",
|
||||
"@typescript-eslint/eslint-plugin": "^6.4.1",
|
||||
"@typescript-eslint/parser": "^6.4.1",
|
||||
"@vitejs/plugin-react-swc": "^3.3.2",
|
||||
"axios": "^1.4.0",
|
||||
"@types/lodash-es": "^4.17.9",
|
||||
"@types/node": "^20.8.6",
|
||||
"@types/react": "^18.2.28",
|
||||
"@types/react-dom": "^18.2.13",
|
||||
"@types/react-redux": "^7.1.27",
|
||||
"@types/react-transition-group": "^4.4.7",
|
||||
"@types/uuid": "^9.0.5",
|
||||
"@typescript-eslint/eslint-plugin": "^6.7.5",
|
||||
"@typescript-eslint/parser": "^6.7.5",
|
||||
"@vitejs/plugin-react-swc": "^3.4.0",
|
||||
"axios": "^1.5.1",
|
||||
"babel-plugin-transform-imports": "^2.0.0",
|
||||
"concurrently": "^8.2.0",
|
||||
"eslint": "^8.47.0",
|
||||
"concurrently": "^8.2.1",
|
||||
"eslint": "^8.51.0",
|
||||
"eslint-config-prettier": "^9.0.0",
|
||||
"eslint-plugin-prettier": "^5.0.0",
|
||||
"eslint-plugin-prettier": "^5.0.1",
|
||||
"eslint-plugin-react": "^7.33.2",
|
||||
"eslint-plugin-react-hooks": "^4.6.0",
|
||||
"form-data": "^4.0.0",
|
||||
"husky": "^8.0.3",
|
||||
"lint-staged": "^14.0.1",
|
||||
"lint-staged": "^15.0.1",
|
||||
"madge": "^6.1.0",
|
||||
"openapi-types": "^12.1.3",
|
||||
"openapi-typescript": "^6.5.2",
|
||||
"openapi-typescript": "^6.7.0",
|
||||
"postinstall-postinstall": "^2.1.0",
|
||||
"prettier": "^3.0.2",
|
||||
"prettier": "^3.0.3",
|
||||
"rollup-plugin-visualizer": "^5.9.2",
|
||||
"ts-toolbelt": "^9.6.0",
|
||||
"typescript": "^5.2.2",
|
||||
"vite": "^4.4.9",
|
||||
"vite": "^4.4.11",
|
||||
"vite-plugin-css-injected-by-js": "^3.3.0",
|
||||
"vite-plugin-dts": "^3.5.2",
|
||||
"vite-plugin-dts": "^3.6.0",
|
||||
"vite-plugin-eslint": "^1.8.1",
|
||||
"vite-tsconfig-paths": "^4.2.0",
|
||||
"vite-tsconfig-paths": "^4.2.1",
|
||||
"yarn": "^1.22.19"
|
||||
}
|
||||
}
|
||||
|
||||
@ -137,9 +137,9 @@
|
||||
"controlnet": {
|
||||
"controlAdapter_one": "Control Adapter",
|
||||
"controlAdapter_other": "Control Adapters",
|
||||
"controlnet": "$t(controlnet.controlAdapter) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.t2iAdapter))",
|
||||
"controlnet": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.controlNet))",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.ipAdapter))",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter_one) #{{number}} ($t(common.t2iAdapter))",
|
||||
"addControlNet": "Add $t(common.controlNet)",
|
||||
"addIPAdapter": "Add $t(common.ipAdapter)",
|
||||
"addT2IAdapter": "Add $t(common.t2iAdapter)",
|
||||
@ -559,8 +559,10 @@
|
||||
"negativePrompt": "Negative Prompt",
|
||||
"noImageDetails": "No image details found",
|
||||
"noMetaData": "No metadata found",
|
||||
"noRecallParameters": "No parameters to recall found",
|
||||
"perlin": "Perlin Noise",
|
||||
"positivePrompt": "Positive Prompt",
|
||||
"recallParameters": "Recall Parameters",
|
||||
"scheduler": "Scheduler",
|
||||
"seamless": "Seamless",
|
||||
"seed": "Seed",
|
||||
@ -1113,6 +1115,7 @@
|
||||
"showProgressInViewer": "Show Progress Images in Viewer",
|
||||
"ui": "User Interface",
|
||||
"useSlidersForAll": "Use Sliders For All Options",
|
||||
"clearIntermediatesDisabled": "Queue must be empty to clear intermediates",
|
||||
"clearIntermediatesDesc1": "Clearing intermediates will reset your Canvas and ControlNet state.",
|
||||
"clearIntermediatesDesc2": "Intermediate images are byproducts of generation, different from the result images in the gallery. Clearing intermediates will free disk space.",
|
||||
"clearIntermediatesDesc3": "Your gallery images will not be deleted.",
|
||||
|
||||
@ -87,7 +87,9 @@
|
||||
"learnMore": "Per saperne di più",
|
||||
"ipAdapter": "Adattatore IP",
|
||||
"t2iAdapter": "Adattatore T2I",
|
||||
"controlAdapter": "Adattatore di Controllo"
|
||||
"controlAdapter": "Adattatore di Controllo",
|
||||
"controlNet": "ControlNet",
|
||||
"auto": "Automatico"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Generazioni",
|
||||
@ -115,7 +117,10 @@
|
||||
"currentlyInUse": "Questa immagine è attualmente utilizzata nelle seguenti funzionalità:",
|
||||
"copy": "Copia",
|
||||
"download": "Scarica",
|
||||
"setCurrentImage": "Imposta come immagine corrente"
|
||||
"setCurrentImage": "Imposta come immagine corrente",
|
||||
"preparingDownload": "Preparazione del download",
|
||||
"preparingDownloadFailed": "Problema durante la preparazione del download",
|
||||
"downloadSelection": "Scarica gli elementi selezionati"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Tasti rapidi",
|
||||
@ -468,7 +473,8 @@
|
||||
"useCustomConfig": "Utilizza configurazione personalizzata",
|
||||
"closeAdvanced": "Chiudi Avanzate",
|
||||
"modelType": "Tipo di modello",
|
||||
"customConfigFileLocation": "Posizione del file di configurazione personalizzato"
|
||||
"customConfigFileLocation": "Posizione del file di configurazione personalizzato",
|
||||
"vaePrecision": "Precisione VAE"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Immagini",
|
||||
@ -570,9 +576,12 @@
|
||||
"systemBusy": "Sistema occupato",
|
||||
"unableToInvoke": "Impossibile invocare",
|
||||
"systemDisconnected": "Sistema disconnesso",
|
||||
"noControlImageForControlAdapter": "L'adattatore di controllo {{number}} non ha un'immagine di controllo",
|
||||
"noModelForControlAdapter": "Nessun modello selezionato per l'adattatore di controllo {{number}}.",
|
||||
"incompatibleBaseModelForControlAdapter": "Il modello dell'adattatore di controllo {{number}} non è compatibile con il modello principale."
|
||||
"noControlImageForControlAdapter": "L'adattatore di controllo #{{number}} non ha un'immagine di controllo",
|
||||
"noModelForControlAdapter": "Nessun modello selezionato per l'adattatore di controllo #{{number}}.",
|
||||
"incompatibleBaseModelForControlAdapter": "Il modello dell'adattatore di controllo #{{number}} non è compatibile con il modello principale.",
|
||||
"missingNodeTemplate": "Modello di nodo mancante",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} ingresso mancante",
|
||||
"missingFieldTemplate": "Modello di campo mancante"
|
||||
},
|
||||
"enableNoiseSettings": "Abilita le impostazioni del rumore",
|
||||
"cpuNoise": "Rumore CPU",
|
||||
@ -583,7 +592,7 @@
|
||||
"iterations": "Iterazioni",
|
||||
"iterationsWithCount_one": "{{count}} Iterazione",
|
||||
"iterationsWithCount_many": "{{count}} Iterazioni",
|
||||
"iterationsWithCount_other": "",
|
||||
"iterationsWithCount_other": "{{count}} Iterazioni",
|
||||
"seamlessX&Y": "Senza cuciture X & Y",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "L'immagine è troppo grande per l'ampliamento con il modello x4, utilizza il modello x2",
|
||||
@ -591,7 +600,8 @@
|
||||
},
|
||||
"seamlessX": "Senza cuciture X",
|
||||
"seamlessY": "Senza cuciture Y",
|
||||
"imageActions": "Azioni Immagine"
|
||||
"imageActions": "Azioni Immagine",
|
||||
"aspectRatioFree": "Libere"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modelli",
|
||||
@ -620,7 +630,19 @@
|
||||
"beta": "Beta",
|
||||
"enableNodesEditor": "Abilita l'editor dei nodi",
|
||||
"experimental": "Sperimentale",
|
||||
"autoChangeDimensions": "Aggiorna L/A alle impostazioni predefinite del modello in caso di modifica"
|
||||
"autoChangeDimensions": "Aggiorna L/A alle impostazioni predefinite del modello in caso di modifica",
|
||||
"clearIntermediates": "Cancella le immagini intermedie",
|
||||
"clearIntermediatesDesc3": "Le immagini della galleria non verranno eliminate.",
|
||||
"clearIntermediatesDesc2": "Le immagini intermedie sono sottoprodotti della generazione, diversi dalle immagini risultanti nella galleria. La cancellazione degli intermedi libererà spazio su disco.",
|
||||
"intermediatesCleared_one": "Cancellata {{count}} immagine intermedia",
|
||||
"intermediatesCleared_many": "Cancellate {{count}} immagini intermedie",
|
||||
"intermediatesCleared_other": "Cancellate {{count}} immagini intermedie",
|
||||
"clearIntermediatesDesc1": "La cancellazione delle immagini intermedie ripristinerà lo stato di Tela Unificata e ControlNet.",
|
||||
"intermediatesClearedFailed": "Problema con la cancellazione delle immagini intermedie",
|
||||
"clearIntermediatesWithCount_one": "Cancella {{count}} immagine intermedia",
|
||||
"clearIntermediatesWithCount_many": "Cancella {{count}} immagini intermedie",
|
||||
"clearIntermediatesWithCount_other": "Cancella {{count}} immagini intermedie",
|
||||
"clearIntermediatesDisabled": "La coda deve essere vuota per cancellare le immagini intermedie"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Cartella temporanea svuotata",
|
||||
@ -670,9 +692,9 @@
|
||||
"nodesUnrecognizedTypes": "Impossibile caricare. Il grafico ha tipi di dati non riconosciuti",
|
||||
"nodesNotValidJSON": "JSON non valido",
|
||||
"nodesBrokenConnections": "Impossibile caricare. Alcune connessioni sono interrotte.",
|
||||
"baseModelChangedCleared_one": "Il modello base è stato modificato, cancellato o disabilitato {{number}} sotto-modello incompatibile",
|
||||
"baseModelChangedCleared_many": "",
|
||||
"baseModelChangedCleared_other": "",
|
||||
"baseModelChangedCleared_one": "Il modello base è stato modificato, cancellato o disabilitato {{count}} sotto-modello incompatibile",
|
||||
"baseModelChangedCleared_many": "Il modello base è stato modificato, cancellato o disabilitato {{count}} sotto-modelli incompatibili",
|
||||
"baseModelChangedCleared_other": "Il modello base è stato modificato, cancellato o disabilitato {{count}} sotto-modelli incompatibili",
|
||||
"imageSavingFailed": "Salvataggio dell'immagine non riuscito",
|
||||
"canvasSentControlnetAssets": "Tela inviata a ControlNet & Risorse",
|
||||
"problemCopyingCanvasDesc": "Impossibile copiare la tela",
|
||||
@ -866,7 +888,144 @@
|
||||
"workflowValidation": "Errore di convalida del flusso di lavoro",
|
||||
"workflowAuthor": "Autore",
|
||||
"workflowName": "Nome",
|
||||
"workflowNotes": "Note"
|
||||
"workflowNotes": "Note",
|
||||
"unhandledInputProperty": "Proprietà di input non gestita",
|
||||
"versionUnknown": " Versione sconosciuta",
|
||||
"unableToValidateWorkflow": "Impossibile convalidare il flusso di lavoro",
|
||||
"updateApp": "Aggiorna App",
|
||||
"problemReadingWorkflow": "Problema durante la lettura del flusso di lavoro dall'immagine",
|
||||
"unableToLoadWorkflow": "Impossibile caricare il flusso di lavoro",
|
||||
"updateNode": "Aggiorna nodo",
|
||||
"version": "Versione",
|
||||
"notes": "Note",
|
||||
"problemSettingTitle": "Problema nell'impostazione del titolo",
|
||||
"unkownInvocation": "Tipo di invocazione sconosciuta",
|
||||
"unknownTemplate": "Modello sconosciuto",
|
||||
"nodeType": "Tipo di nodo",
|
||||
"vaeField": "VAE",
|
||||
"unhandledOutputProperty": "Proprietà di output non gestita",
|
||||
"notesDescription": "Aggiunge note sul tuo flusso di lavoro",
|
||||
"unknownField": "Campo sconosciuto",
|
||||
"unknownNode": "Nodo sconosciuto",
|
||||
"vaeFieldDescription": "Sotto modello VAE.",
|
||||
"booleanPolymorphicDescription": "Una raccolta di booleani.",
|
||||
"missingTemplate": "Modello mancante",
|
||||
"outputSchemaNotFound": "Schema di output non trovato",
|
||||
"colorFieldDescription": "Un colore RGBA.",
|
||||
"maybeIncompatible": "Potrebbe essere incompatibile con quello installato",
|
||||
"noNodeSelected": "Nessun nodo selezionato",
|
||||
"colorPolymorphic": "Colore polimorfico",
|
||||
"booleanCollectionDescription": "Una raccolta di booleani.",
|
||||
"colorField": "Colore",
|
||||
"nodeTemplate": "Modello di nodo",
|
||||
"nodeOpacity": "Opacità del nodo",
|
||||
"pickOne": "Sceglierne uno",
|
||||
"outputField": "Campo di output",
|
||||
"nodeSearch": "Cerca nodi",
|
||||
"nodeOutputs": "Uscite del nodo",
|
||||
"collectionItem": "Oggetto della raccolta",
|
||||
"noConnectionInProgress": "Nessuna connessione in corso",
|
||||
"noConnectionData": "Nessun dato di connessione",
|
||||
"outputFields": "Campi di output",
|
||||
"cannotDuplicateConnection": "Impossibile creare connessioni duplicate",
|
||||
"booleanPolymorphic": "Polimorfico booleano",
|
||||
"colorPolymorphicDescription": "Una collezione di colori polimorfici.",
|
||||
"missingCanvaInitImage": "Immagine iniziale della tela mancante",
|
||||
"clipFieldDescription": "Sottomodelli di tokenizzatore e codificatore di testo.",
|
||||
"noImageFoundState": "Nessuna immagine iniziale trovata nello stato",
|
||||
"clipField": "CLIP",
|
||||
"noMatchingNodes": "Nessun nodo corrispondente",
|
||||
"noFieldType": "Nessun tipo di campo",
|
||||
"colorCollection": "Una collezione di colori.",
|
||||
"noOutputSchemaName": "Nessun nome dello schema di output trovato nell'oggetto di riferimento",
|
||||
"boolean": "Booleani",
|
||||
"missingCanvaInitMaskImages": "Immagini di inizializzazione e maschera della tela mancanti",
|
||||
"oNNXModelField": "Modello ONNX",
|
||||
"node": "Nodo",
|
||||
"booleanDescription": "I booleani sono veri o falsi.",
|
||||
"collection": "Raccolta",
|
||||
"cannotConnectInputToInput": "Impossibile collegare Input a Input",
|
||||
"cannotConnectOutputToOutput": "Impossibile collegare Output ad Output",
|
||||
"booleanCollection": "Raccolta booleana",
|
||||
"cannotConnectToSelf": "Impossibile connettersi a se stesso",
|
||||
"mismatchedVersion": "Ha una versione non corrispondente",
|
||||
"outputNode": "Nodo di Output",
|
||||
"loadingNodes": "Caricamento nodi...",
|
||||
"oNNXModelFieldDescription": "Campo del modello ONNX.",
|
||||
"denoiseMaskFieldDescription": "La maschera di riduzione del rumore può essere passata tra i nodi",
|
||||
"floatCollectionDescription": "Una raccolta di numeri virgola mobile.",
|
||||
"enum": "Enumeratore",
|
||||
"float": "In virgola mobile",
|
||||
"doesNotExist": "non esiste",
|
||||
"currentImageDescription": "Visualizza l'immagine corrente nell'editor dei nodi",
|
||||
"fieldTypesMustMatch": "I tipi di campo devono corrispondere",
|
||||
"edge": "Bordo",
|
||||
"enumDescription": "Gli enumeratori sono valori che possono essere una delle diverse opzioni.",
|
||||
"denoiseMaskField": "Maschera riduzione rumore",
|
||||
"currentImage": "Immagine corrente",
|
||||
"floatCollection": "Raccolta in virgola mobile",
|
||||
"inputField": "Campo di Input",
|
||||
"controlFieldDescription": "Informazioni di controllo passate tra i nodi.",
|
||||
"skippingUnknownOutputType": "Tipo di campo di output sconosciuto saltato",
|
||||
"latentsFieldDescription": "Le immagini latenti possono essere passate tra i nodi.",
|
||||
"ipAdapterPolymorphicDescription": "Una raccolta di adattatori IP.",
|
||||
"latentsPolymorphicDescription": "Le immagini latenti possono essere passate tra i nodi.",
|
||||
"ipAdapterCollection": "Raccolta Adattatori IP",
|
||||
"conditioningCollection": "Raccolta condizionamenti",
|
||||
"ipAdapterPolymorphic": "Adattatore IP Polimorfico",
|
||||
"integerPolymorphicDescription": "Una raccolta di numeri interi.",
|
||||
"conditioningCollectionDescription": "Il condizionamento può essere passato tra i nodi.",
|
||||
"skippingReservedFieldType": "Tipo di campo riservato saltato",
|
||||
"conditioningPolymorphic": "Condizionamento Polimorfico",
|
||||
"integer": "Numero Intero",
|
||||
"latentsCollection": "Raccolta Latenti",
|
||||
"sourceNode": "Nodo di origine",
|
||||
"integerDescription": "Gli interi sono numeri senza punto decimale.",
|
||||
"stringPolymorphic": "Stringa polimorfica",
|
||||
"conditioningPolymorphicDescription": "Il condizionamento può essere passato tra i nodi.",
|
||||
"skipped": "Saltato",
|
||||
"imagePolymorphic": "Immagine Polimorfica",
|
||||
"imagePolymorphicDescription": "Una raccolta di immagini.",
|
||||
"floatPolymorphic": "Numeri in virgola mobile Polimorfici",
|
||||
"ipAdapterCollectionDescription": "Una raccolta di adattatori IP.",
|
||||
"stringCollectionDescription": "Una raccolta di stringhe.",
|
||||
"unableToParseNode": "Impossibile analizzare il nodo",
|
||||
"controlCollection": "Raccolta di Controllo",
|
||||
"stringCollection": "Raccolta di stringhe",
|
||||
"inputMayOnlyHaveOneConnection": "L'ingresso può avere solo una connessione",
|
||||
"ipAdapter": "Adattatore IP",
|
||||
"integerCollection": "Raccolta di numeri interi",
|
||||
"controlCollectionDescription": "Informazioni di controllo passate tra i nodi.",
|
||||
"skippedReservedInput": "Campo di input riservato saltato",
|
||||
"inputNode": "Nodo di Input",
|
||||
"imageField": "Immagine",
|
||||
"skippedReservedOutput": "Campo di output riservato saltato",
|
||||
"integerCollectionDescription": "Una raccolta di numeri interi.",
|
||||
"conditioningFieldDescription": "Il condizionamento può essere passato tra i nodi.",
|
||||
"stringDescription": "Le stringhe sono testo.",
|
||||
"integerPolymorphic": "Numero intero Polimorfico",
|
||||
"ipAdapterModel": "Modello Adattatore IP",
|
||||
"latentsPolymorphic": "Latenti polimorfici",
|
||||
"skippingInputNoTemplate": "Campo di input senza modello saltato",
|
||||
"ipAdapterDescription": "Un adattatore di prompt di immagini (Adattatore IP).",
|
||||
"stringPolymorphicDescription": "Una raccolta di stringhe.",
|
||||
"skippingUnknownInputType": "Tipo di campo di input sconosciuto saltato",
|
||||
"controlField": "Controllo",
|
||||
"ipAdapterModelDescription": "Campo Modello adattatore IP",
|
||||
"invalidOutputSchema": "Schema di output non valido",
|
||||
"floatDescription": "I numeri in virgola mobile sono numeri con un punto decimale.",
|
||||
"floatPolymorphicDescription": "Una raccolta di numeri in virgola mobile.",
|
||||
"conditioningField": "Condizionamento",
|
||||
"string": "Stringa",
|
||||
"latentsField": "Latenti",
|
||||
"connectionWouldCreateCycle": "La connessione creerebbe un ciclo",
|
||||
"inputFields": "Campi di Input",
|
||||
"uNetFieldDescription": "Sub-modello UNet.",
|
||||
"imageCollectionDescription": "Una raccolta di immagini.",
|
||||
"imageFieldDescription": "Le immagini possono essere passate tra i nodi.",
|
||||
"unableToParseEdge": "Impossibile analizzare il bordo",
|
||||
"latentsCollectionDescription": "Le immagini latenti possono essere passate tra i nodi.",
|
||||
"imageCollection": "Raccolta Immagini"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Aggiungi automaticamente bacheca",
|
||||
@ -883,7 +1042,8 @@
|
||||
"searchBoard": "Cerca bacheche ...",
|
||||
"noMatching": "Nessuna bacheca corrispondente",
|
||||
"selectBoard": "Seleziona una Bacheca",
|
||||
"uncategorized": "Non categorizzato"
|
||||
"uncategorized": "Non categorizzato",
|
||||
"downloadBoard": "Scarica la bacheca"
|
||||
},
|
||||
"controlnet": {
|
||||
"contentShuffleDescription": "Rimescola il contenuto di un'immagine",
|
||||
@ -951,8 +1111,12 @@
|
||||
"addControlNet": "Aggiungi $t(common.controlNet)",
|
||||
"controlNetT2IMutexDesc": "$t(common.controlNet) e $t(common.t2iAdapter) contemporaneamente non sono attualmente supportati.",
|
||||
"addIPAdapter": "Aggiungi $t(common.ipAdapter)",
|
||||
"controlAdapter": "Adattatore di Controllo",
|
||||
"megaControl": "Mega ControlNet"
|
||||
"controlAdapter_one": "Adattatore di Controllo",
|
||||
"controlAdapter_many": "Adattatori di Controllo",
|
||||
"controlAdapter_other": "Adattatori di Controllo",
|
||||
"megaControl": "Mega ControlNet",
|
||||
"minConfidence": "Confidenza minima",
|
||||
"scribble": "Scribble"
|
||||
},
|
||||
"queue": {
|
||||
"queueFront": "Aggiungi all'inizio della coda",
|
||||
@ -979,7 +1143,9 @@
|
||||
"pause": "Sospendi",
|
||||
"pruneTooltip": "Rimuovi {{item_count}} elementi completati",
|
||||
"cancelSucceeded": "Elemento annullato",
|
||||
"batchQueuedDesc": "Aggiunte {{item_count}} sessioni a {{direction}} della coda",
|
||||
"batchQueuedDesc_one": "Aggiunta {{count}} sessione a {{direction}} della coda",
|
||||
"batchQueuedDesc_many": "Aggiunte {{count}} sessioni a {{direction}} della coda",
|
||||
"batchQueuedDesc_other": "Aggiunte {{count}} sessioni a {{direction}} della coda",
|
||||
"graphQueued": "Grafico in coda",
|
||||
"batch": "Lotto",
|
||||
"clearQueueAlertDialog": "Lo svuotamento della coda annulla immediatamente tutti gli elementi in elaborazione e cancella completamente la coda.",
|
||||
@ -1056,7 +1222,7 @@
|
||||
"maxPrompts": "Numero massimo di prompt",
|
||||
"promptsWithCount_one": "{{count}} Prompt",
|
||||
"promptsWithCount_many": "{{count}} Prompt",
|
||||
"promptsWithCount_other": "",
|
||||
"promptsWithCount_other": "{{count}} Prompt",
|
||||
"dynamicPrompts": "Prompt dinamici"
|
||||
},
|
||||
"popovers": {
|
||||
@ -1268,7 +1434,8 @@
|
||||
"controlNet": {
|
||||
"paragraphs": [
|
||||
"ControlNet fornisce una guida al processo di generazione, aiutando a creare immagini con composizione, struttura o stile controllati, a seconda del modello selezionato."
|
||||
]
|
||||
],
|
||||
"heading": "ControlNet"
|
||||
}
|
||||
},
|
||||
"sdxl": {
|
||||
@ -1313,6 +1480,8 @@
|
||||
"createdBy": "Creato da",
|
||||
"workflow": "Flusso di lavoro",
|
||||
"steps": "Passi",
|
||||
"scheduler": "Campionatore"
|
||||
"scheduler": "Campionatore",
|
||||
"recallParameters": "Richiama i parametri",
|
||||
"noRecallParameters": "Nessun parametro da richiamare trovato"
|
||||
}
|
||||
}
|
||||
|
||||
@ -79,7 +79,18 @@
|
||||
"modelManager": "Modelbeheer",
|
||||
"darkMode": "Donkere modus",
|
||||
"lightMode": "Lichte modus",
|
||||
"communityLabel": "Gemeenschap"
|
||||
"communityLabel": "Gemeenschap",
|
||||
"t2iAdapter": "T2I-adapter",
|
||||
"on": "Aan",
|
||||
"nodeEditor": "Knooppunteditor",
|
||||
"ipAdapter": "IP-adapter",
|
||||
"controlAdapter": "Control-adapter",
|
||||
"auto": "Autom.",
|
||||
"controlNet": "ControlNet",
|
||||
"statusProcessing": "Bezig met verwerken",
|
||||
"imageFailedToLoad": "Kan afbeelding niet laden",
|
||||
"learnMore": "Meer informatie",
|
||||
"advanced": "Uitgebreid"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "Gegenereerde afbeeldingen",
|
||||
@ -100,7 +111,17 @@
|
||||
"deleteImagePermanent": "Gewiste afbeeldingen kunnen niet worden hersteld.",
|
||||
"assets": "Eigen onderdelen",
|
||||
"images": "Afbeeldingen",
|
||||
"autoAssignBoardOnClick": "Ken automatisch bord toe bij klikken"
|
||||
"autoAssignBoardOnClick": "Ken automatisch bord toe bij klikken",
|
||||
"featuresWillReset": "Als je deze afbeelding verwijdert, dan worden deze functies onmiddellijk teruggezet.",
|
||||
"loading": "Bezig met laden",
|
||||
"unableToLoad": "Kan galerij niet laden",
|
||||
"preparingDownload": "Bezig met voorbereiden van download",
|
||||
"preparingDownloadFailed": "Fout bij voorbereiden van download",
|
||||
"downloadSelection": "Download selectie",
|
||||
"currentlyInUse": "Deze afbeelding is momenteel in gebruik door de volgende functies:",
|
||||
"copy": "Kopieer",
|
||||
"download": "Download",
|
||||
"setCurrentImage": "Stel in als huidige afbeelding"
|
||||
},
|
||||
"hotkeys": {
|
||||
"keyboardShortcuts": "Sneltoetsen",
|
||||
@ -332,7 +353,7 @@
|
||||
"config": "Configuratie",
|
||||
"configValidationMsg": "Pad naar het configuratiebestand van je model.",
|
||||
"modelLocation": "Locatie model",
|
||||
"modelLocationValidationMsg": "Pad naar waar je model zich bevindt.",
|
||||
"modelLocationValidationMsg": "Geef het pad naar een lokale map waar je Diffusers-model wordt bewaard",
|
||||
"vaeLocation": "Locatie VAE",
|
||||
"vaeLocationValidationMsg": "Pad naar waar je VAE zich bevindt.",
|
||||
"width": "Breedte",
|
||||
@ -444,7 +465,17 @@
|
||||
"syncModelsDesc": "Als je modellen niet meer synchroon zijn met de backend, kan je ze met deze optie verversen. Dit wordt typisch gebruikt in het geval je het models.yaml bestand met de hand bewerkt of als je modellen aan de InvokeAI root map toevoegt nadat de applicatie gestart werd.",
|
||||
"loraModels": "LoRA's",
|
||||
"onnxModels": "Onnx",
|
||||
"oliveModels": "Olives"
|
||||
"oliveModels": "Olives",
|
||||
"noModels": "Geen modellen gevonden",
|
||||
"predictionType": "Soort voorspelling (voor Stable Diffusion 2.x-modellen en incidentele Stable Diffusion 1.x-modellen)",
|
||||
"quickAdd": "Voeg snel toe",
|
||||
"simpleModelDesc": "Geef een pad naar een lokaal Diffusers-model, lokale-checkpoint- / safetensors-model, een HuggingFace-repo-ID of een url naar een checkpoint- / Diffusers-model.",
|
||||
"advanced": "Uitgebreid",
|
||||
"useCustomConfig": "Gebruik eigen configuratie",
|
||||
"closeAdvanced": "Sluit uitgebreid",
|
||||
"modelType": "Soort model",
|
||||
"customConfigFileLocation": "Locatie eigen configuratiebestand",
|
||||
"vaePrecision": "Nauwkeurigheid VAE"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "Afbeeldingen",
|
||||
@ -465,7 +496,7 @@
|
||||
"type": "Soort",
|
||||
"strength": "Sterkte",
|
||||
"upscaling": "Opschalen",
|
||||
"upscale": "Schaal op",
|
||||
"upscale": "Vergroot (Shift + U)",
|
||||
"upscaleImage": "Schaal afbeelding op",
|
||||
"scale": "Schaal",
|
||||
"otherOptions": "Andere opties",
|
||||
@ -496,7 +527,7 @@
|
||||
"useInitImg": "Gebruik initiële afbeelding",
|
||||
"info": "Info",
|
||||
"initialImage": "Initiële afbeelding",
|
||||
"showOptionsPanel": "Toon deelscherm Opties",
|
||||
"showOptionsPanel": "Toon deelscherm Opties (O of T)",
|
||||
"symmetry": "Symmetrie",
|
||||
"hSymmetryStep": "Stap horiz. symmetrie",
|
||||
"vSymmetryStep": "Stap vert. symmetrie",
|
||||
@ -504,7 +535,8 @@
|
||||
"immediate": "Annuleer direct",
|
||||
"isScheduled": "Annuleren",
|
||||
"setType": "Stel annuleervorm in",
|
||||
"schedule": "Annuleer na huidige iteratie"
|
||||
"schedule": "Annuleer na huidige iteratie",
|
||||
"cancel": "Annuleer"
|
||||
},
|
||||
"general": "Algemeen",
|
||||
"copyImage": "Kopieer afbeelding",
|
||||
@ -520,7 +552,7 @@
|
||||
"boundingBoxWidth": "Tekenvak breedte",
|
||||
"boundingBoxHeight": "Tekenvak hoogte",
|
||||
"clipSkip": "Overslaan CLIP",
|
||||
"aspectRatio": "Verhouding",
|
||||
"aspectRatio": "Beeldverhouding",
|
||||
"negativePromptPlaceholder": "Negatieve prompt",
|
||||
"controlNetControlMode": "Aansturingsmodus",
|
||||
"positivePromptPlaceholder": "Positieve prompt",
|
||||
@ -532,7 +564,46 @@
|
||||
"coherenceSteps": "Stappen",
|
||||
"coherenceStrength": "Sterkte",
|
||||
"seamHighThreshold": "Hoog",
|
||||
"seamLowThreshold": "Laag"
|
||||
"seamLowThreshold": "Laag",
|
||||
"invoke": {
|
||||
"noNodesInGraph": "Geen knooppunten in graaf",
|
||||
"noModelSelected": "Geen model ingesteld",
|
||||
"invoke": "Start",
|
||||
"noPrompts": "Geen prompts gegenereerd",
|
||||
"systemBusy": "Systeem is bezig",
|
||||
"noInitialImageSelected": "Geen initiële afbeelding gekozen",
|
||||
"missingInputForField": "{{nodeLabel}} -> {{fieldLabel}} invoer ontbreekt",
|
||||
"noControlImageForControlAdapter": "Controle-adapter #{{number}} heeft geen controle-afbeelding",
|
||||
"noModelForControlAdapter": "Control-adapter #{{number}} heeft geen model ingesteld staan.",
|
||||
"unableToInvoke": "Kan niet starten",
|
||||
"incompatibleBaseModelForControlAdapter": "Model van controle-adapter #{{number}} is ongeldig in combinatie met het hoofdmodel.",
|
||||
"systemDisconnected": "Systeem is niet verbonden",
|
||||
"missingNodeTemplate": "Knooppuntsjabloon ontbreekt",
|
||||
"readyToInvoke": "Klaar om te starten",
|
||||
"missingFieldTemplate": "Veldsjabloon ontbreekt",
|
||||
"addingImagesTo": "Bezig met toevoegen van afbeeldingen aan"
|
||||
},
|
||||
"seamlessX&Y": "Naadloos X en Y",
|
||||
"isAllowedToUpscale": {
|
||||
"useX2Model": "Afbeelding is te groot om te vergroten met het x4-model. Gebruik hiervoor het x2-model",
|
||||
"tooLarge": "Afbeelding is te groot om te vergoten. Kies een kleinere afbeelding"
|
||||
},
|
||||
"aspectRatioFree": "Vrij",
|
||||
"cpuNoise": "CPU-ruis",
|
||||
"patchmatchDownScaleSize": "Verklein",
|
||||
"gpuNoise": "GPU-ruis",
|
||||
"seamlessX": "Naadloos X",
|
||||
"useCpuNoise": "Gebruik CPU-ruis",
|
||||
"clipSkipWithLayerCount": "Overslaan CLIP {{layerCount}}",
|
||||
"seamlessY": "Naadloos Y",
|
||||
"manualSeed": "Handmatige seedwaarde",
|
||||
"imageActions": "Afbeeldingshandeling",
|
||||
"randomSeed": "Willekeurige seedwaarde",
|
||||
"iterations": "Iteraties",
|
||||
"iterationsWithCount_one": "{{count}} iteratie",
|
||||
"iterationsWithCount_other": "{{count}} iteraties",
|
||||
"enableNoiseSettings": "Schakel ruisinstellingen in",
|
||||
"coherenceMode": "Modus"
|
||||
},
|
||||
"settings": {
|
||||
"models": "Modellen",
|
||||
@ -561,7 +632,16 @@
|
||||
"experimental": "Experimenteel",
|
||||
"alternateCanvasLayout": "Omwisselen Canvas Layout",
|
||||
"enableNodesEditor": "Knopen Editor Inschakelen",
|
||||
"autoChangeDimensions": "Werk bij wijziging afmetingen bij naar modelstandaard"
|
||||
"autoChangeDimensions": "Werk bij wijziging afmetingen bij naar modelstandaard",
|
||||
"clearIntermediates": "Wis tussentijdse afbeeldingen",
|
||||
"clearIntermediatesDesc3": "Je galerijafbeeldingen zullen niet worden verwijderd.",
|
||||
"clearIntermediatesWithCount_one": "Wis {{count}} tussentijdse afbeelding",
|
||||
"clearIntermediatesWithCount_other": "Wis {{count}} tussentijdse afbeeldingen",
|
||||
"clearIntermediatesDesc2": "Tussentijdse afbeeldingen zijn nevenproducten bij een generatie, die afwijken van de uitvoerafbeeldingen in de galerij. Het wissen van tussentijdse afbeeldingen zal schijfruimte vrijmaken.",
|
||||
"intermediatesCleared_one": "{{count}} tussentijdse afbeelding gewist",
|
||||
"intermediatesCleared_other": "{{count}} tussentijdse afbeeldingen gewist",
|
||||
"clearIntermediatesDesc1": "Het wissen van tussentijdse onderdelen zet de staat van je canvas en ControlNet terug.",
|
||||
"intermediatesClearedFailed": "Fout bij wissen van tussentijdse afbeeldingen"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "Tijdelijke map geleegd",
|
||||
@ -610,7 +690,42 @@
|
||||
"nodesCorruptedGraph": "Kan niet laden. Graph lijkt corrupt.",
|
||||
"nodesUnrecognizedTypes": "Laden mislukt. Graph heeft onherkenbare types",
|
||||
"nodesBrokenConnections": "Laden mislukt. Sommige verbindingen zijn verbroken.",
|
||||
"nodesNotValidGraph": "Geen geldige knooppunten graph"
|
||||
"nodesNotValidGraph": "Geen geldige knooppunten graph",
|
||||
"baseModelChangedCleared_one": "Basismodel is gewijzigd: {{count}} niet-compatibel submodel weggehaald of uitgeschakeld",
|
||||
"baseModelChangedCleared_other": "Basismodel is gewijzigd: {{count}} niet-compatibele submodellen weggehaald of uitgeschakeld",
|
||||
"imageSavingFailed": "Fout bij bewaren afbeelding",
|
||||
"canvasSentControlnetAssets": "Canvas gestuurd naar ControlNet en Assets",
|
||||
"problemCopyingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"loadedWithWarnings": "Werkstroom geladen met waarschuwingen",
|
||||
"setInitialImage": "Ingesteld als initiële afbeelding",
|
||||
"canvasCopiedClipboard": "Canvas gekopieerd naar klembord",
|
||||
"setControlImage": "Ingesteld als controle-afbeelding",
|
||||
"setNodeField": "Ingesteld als knooppuntveld",
|
||||
"problemSavingMask": "Fout bij bewaren masker",
|
||||
"problemSavingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"maskSavedAssets": "Masker bewaard in Assets",
|
||||
"modelAddFailed": "Fout bij toevoegen model",
|
||||
"problemDownloadingCanvas": "Fout bij downloaden van canvas",
|
||||
"problemMergingCanvas": "Fout bij samenvoegen canvas",
|
||||
"setCanvasInitialImage": "Ingesteld als initiële canvasafbeelding",
|
||||
"imageUploaded": "Afbeelding geüpload",
|
||||
"addedToBoard": "Toegevoegd aan bord",
|
||||
"workflowLoaded": "Werkstroom geladen",
|
||||
"modelAddedSimple": "Model toegevoegd",
|
||||
"problemImportingMaskDesc": "Kan masker niet exporteren",
|
||||
"problemCopyingCanvas": "Fout bij kopiëren canvas",
|
||||
"problemSavingCanvas": "Fout bij bewaren canvas",
|
||||
"canvasDownloaded": "Canvas gedownload",
|
||||
"setIPAdapterImage": "Ingesteld als IP-adapterafbeelding",
|
||||
"problemMergingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"problemDownloadingCanvasDesc": "Kan basislaag niet exporteren",
|
||||
"problemSavingMaskDesc": "Kan masker niet exporteren",
|
||||
"imageSaved": "Afbeelding bewaard",
|
||||
"maskSentControlnetAssets": "Masker gestuurd naar ControlNet en Assets",
|
||||
"canvasSavedGallery": "Canvas bewaard in galerij",
|
||||
"imageUploadFailed": "Fout bij uploaden afbeelding",
|
||||
"modelAdded": "Model toegevoegd: {{modelName}}",
|
||||
"problemImportingMask": "Fout bij importeren masker"
|
||||
},
|
||||
"tooltip": {
|
||||
"feature": {
|
||||
@ -685,7 +800,9 @@
|
||||
"betaDarkenOutside": "Verduister buiten tekenvak",
|
||||
"betaLimitToBox": "Beperk tot tekenvak",
|
||||
"betaPreserveMasked": "Behoud masker",
|
||||
"antialiasing": "Anti-aliasing"
|
||||
"antialiasing": "Anti-aliasing",
|
||||
"showResultsOn": "Toon resultaten (aan)",
|
||||
"showResultsOff": "Toon resultaten (uit)"
|
||||
},
|
||||
"accessibility": {
|
||||
"exitViewer": "Stop viewer",
|
||||
@ -707,7 +824,9 @@
|
||||
"toggleAutoscroll": "Autom. scrollen aan/uit",
|
||||
"toggleLogViewer": "Logboekviewer aan/uit",
|
||||
"showOptionsPanel": "Toon zijscherm",
|
||||
"menu": "Menu"
|
||||
"menu": "Menu",
|
||||
"showGalleryPanel": "Toon deelscherm Galerij",
|
||||
"loadMore": "Laad meer"
|
||||
},
|
||||
"ui": {
|
||||
"showProgressImages": "Toon voortgangsafbeeldingen",
|
||||
@ -730,6 +849,661 @@
|
||||
"resetWorkflow": "Herstel werkstroom",
|
||||
"resetWorkflowDesc": "Weet je zeker dat je deze werkstroom wilt herstellen?",
|
||||
"resetWorkflowDesc2": "Herstel van een werkstroom haalt alle knooppunten, randen en werkstroomdetails weg.",
|
||||
"downloadWorkflow": "Download JSON van werkstroom"
|
||||
"downloadWorkflow": "Download JSON van werkstroom",
|
||||
"booleanPolymorphicDescription": "Een verzameling Booleanse waarden.",
|
||||
"scheduler": "Planner",
|
||||
"inputField": "Invoerveld",
|
||||
"controlFieldDescription": "Controlegegevens doorgegeven tussen knooppunten.",
|
||||
"skippingUnknownOutputType": "Overslaan van onbekend soort uitvoerveld",
|
||||
"latentsFieldDescription": "Latents kunnen worden doorgegeven tussen knooppunten.",
|
||||
"denoiseMaskFieldDescription": "Ontruisingsmasker kan worden doorgegeven tussen knooppunten",
|
||||
"floatCollectionDescription": "Een verzameling zwevende-kommagetallen.",
|
||||
"missingTemplate": "Ontbrekende sjabloon",
|
||||
"outputSchemaNotFound": "Uitvoerschema niet gevonden",
|
||||
"ipAdapterPolymorphicDescription": "Een verzameling IP-adapters.",
|
||||
"workflowDescription": "Korte beschrijving",
|
||||
"latentsPolymorphicDescription": "Latents kunnen worden doorgegeven tussen knooppunten.",
|
||||
"colorFieldDescription": "Een RGBA-kleur.",
|
||||
"mainModelField": "Model",
|
||||
"unhandledInputProperty": "Onverwerkt invoerkenmerk",
|
||||
"versionUnknown": " Versie onbekend",
|
||||
"ipAdapterCollection": "Verzameling IP-adapters",
|
||||
"conditioningCollection": "Verzameling conditionering",
|
||||
"maybeIncompatible": "Is mogelijk niet compatibel met geïnstalleerde knooppunten",
|
||||
"ipAdapterPolymorphic": "Polymorfisme IP-adapter",
|
||||
"noNodeSelected": "Geen knooppunt gekozen",
|
||||
"addNode": "Voeg knooppunt toe",
|
||||
"unableToValidateWorkflow": "Kan werkstroom niet valideren",
|
||||
"enum": "Enumeratie",
|
||||
"integerPolymorphicDescription": "Een verzameling gehele getallen.",
|
||||
"noOutputRecorded": "Geen uitvoer opgenomen",
|
||||
"updateApp": "Werk app bij",
|
||||
"conditioningCollectionDescription": "Conditionering kan worden doorgegeven tussen knooppunten.",
|
||||
"colorPolymorphic": "Polymorfisme kleur",
|
||||
"colorCodeEdgesHelp": "Kleurgecodeerde randen op basis van hun verbonden velden",
|
||||
"collectionDescription": "Beschrijving",
|
||||
"float": "Zwevende-kommagetal",
|
||||
"workflowContact": "Contactpersoon",
|
||||
"skippingReservedFieldType": "Overslaan van gereserveerd veldsoort",
|
||||
"animatedEdges": "Geanimeerde randen",
|
||||
"booleanCollectionDescription": "Een verzameling van Booleanse waarden.",
|
||||
"sDXLMainModelFieldDescription": "SDXL-modelveld.",
|
||||
"conditioningPolymorphic": "Polymorfisme conditionering",
|
||||
"integer": "Geheel getal",
|
||||
"colorField": "Kleur",
|
||||
"boardField": "Bord",
|
||||
"nodeTemplate": "Sjabloon knooppunt",
|
||||
"latentsCollection": "Verzameling latents",
|
||||
"problemReadingWorkflow": "Fout bij lezen van werkstroom uit afbeelding",
|
||||
"sourceNode": "Bronknooppunt",
|
||||
"nodeOpacity": "Dekking knooppunt",
|
||||
"pickOne": "Kies er een",
|
||||
"collectionItemDescription": "Beschrijving",
|
||||
"integerDescription": "Gehele getallen zijn getallen zonder een decimaalteken.",
|
||||
"outputField": "Uitvoerveld",
|
||||
"unableToLoadWorkflow": "Kan werkstroom niet valideren",
|
||||
"snapToGrid": "Lijn uit op raster",
|
||||
"stringPolymorphic": "Polymorfisme tekenreeks",
|
||||
"conditioningPolymorphicDescription": "Conditionering kan worden doorgegeven tussen knooppunten.",
|
||||
"noFieldsLinearview": "Geen velden toegevoegd aan lineaire weergave",
|
||||
"skipped": "Overgeslagen",
|
||||
"imagePolymorphic": "Polymorfisme afbeelding",
|
||||
"nodeSearch": "Zoek naar knooppunten",
|
||||
"updateNode": "Werk knooppunt bij",
|
||||
"sDXLRefinerModelFieldDescription": "Beschrijving",
|
||||
"imagePolymorphicDescription": "Een verzameling afbeeldingen.",
|
||||
"floatPolymorphic": "Polymorfisme zwevende-kommagetal",
|
||||
"version": "Versie",
|
||||
"doesNotExist": "bestaat niet",
|
||||
"ipAdapterCollectionDescription": "Een verzameling van IP-adapters.",
|
||||
"stringCollectionDescription": "Een verzameling tekenreeksen.",
|
||||
"unableToParseNode": "Kan knooppunt niet inlezen",
|
||||
"controlCollection": "Controle-verzameling",
|
||||
"validateConnections": "Valideer verbindingen en graaf",
|
||||
"stringCollection": "Verzameling tekenreeksen",
|
||||
"inputMayOnlyHaveOneConnection": "Invoer mag slechts een enkele verbinding hebben",
|
||||
"notes": "Opmerkingen",
|
||||
"uNetField": "UNet",
|
||||
"nodeOutputs": "Uitvoer knooppunt",
|
||||
"currentImageDescription": "Toont de huidige afbeelding in de knooppunteditor",
|
||||
"validateConnectionsHelp": "Voorkom dat er ongeldige verbindingen worden gelegd en dat er ongeldige grafen worden aangeroepen",
|
||||
"problemSettingTitle": "Fout bij instellen titel",
|
||||
"ipAdapter": "IP-adapter",
|
||||
"integerCollection": "Verzameling gehele getallen",
|
||||
"collectionItem": "Verzamelingsonderdeel",
|
||||
"noConnectionInProgress": "Geen verbinding bezig te maken",
|
||||
"vaeModelField": "VAE",
|
||||
"controlCollectionDescription": "Controlegegevens doorgegeven tussen knooppunten.",
|
||||
"skippedReservedInput": "Overgeslagen gereserveerd invoerveld",
|
||||
"workflowVersion": "Versie",
|
||||
"noConnectionData": "Geen verbindingsgegevens",
|
||||
"outputFields": "Uitvoervelden",
|
||||
"fieldTypesMustMatch": "Veldsoorten moeten overeenkomen",
|
||||
"workflow": "Werkstroom",
|
||||
"edge": "Rand",
|
||||
"inputNode": "Invoerknooppunt",
|
||||
"enumDescription": "Enumeraties zijn waarden die uit een aantal opties moeten worden gekozen.",
|
||||
"unkownInvocation": "Onbekende aanroepsoort",
|
||||
"loRAModelFieldDescription": "Beschrijving",
|
||||
"imageField": "Afbeelding",
|
||||
"skippedReservedOutput": "Overgeslagen gereserveerd uitvoerveld",
|
||||
"animatedEdgesHelp": "Animeer gekozen randen en randen verbonden met de gekozen knooppunten",
|
||||
"cannotDuplicateConnection": "Kan geen dubbele verbindingen maken",
|
||||
"booleanPolymorphic": "Polymorfisme Booleaanse waarden",
|
||||
"unknownTemplate": "Onbekend sjabloon",
|
||||
"noWorkflow": "Geen werkstroom",
|
||||
"removeLinearView": "Verwijder uit lineaire weergave",
|
||||
"colorCollectionDescription": "Beschrijving",
|
||||
"integerCollectionDescription": "Een verzameling gehele getallen.",
|
||||
"colorPolymorphicDescription": "Een verzameling kleuren.",
|
||||
"sDXLMainModelField": "SDXL-model",
|
||||
"workflowTags": "Labels",
|
||||
"denoiseMaskField": "Ontruisingsmasker",
|
||||
"schedulerDescription": "Beschrijving",
|
||||
"missingCanvaInitImage": "Ontbrekende initialisatie-afbeelding voor canvas",
|
||||
"conditioningFieldDescription": "Conditionering kan worden doorgegeven tussen knooppunten.",
|
||||
"clipFieldDescription": "Submodellen voor tokenizer en text_encoder.",
|
||||
"fullyContainNodesHelp": "Knooppunten moeten zich volledig binnen het keuzevak bevinden om te worden gekozen",
|
||||
"noImageFoundState": "Geen initiële afbeelding gevonden in de staat",
|
||||
"workflowValidation": "Validatiefout werkstroom",
|
||||
"clipField": "Clip",
|
||||
"stringDescription": "Tekenreeksen zijn tekst.",
|
||||
"nodeType": "Soort knooppunt",
|
||||
"noMatchingNodes": "Geen overeenkomende knooppunten",
|
||||
"fullyContainNodes": "Omvat knooppunten volledig om ze te kiezen",
|
||||
"integerPolymorphic": "Polymorfisme geheel getal",
|
||||
"executionStateInProgress": "Bezig",
|
||||
"noFieldType": "Geen soort veld",
|
||||
"colorCollection": "Een verzameling kleuren.",
|
||||
"executionStateError": "Fout",
|
||||
"noOutputSchemaName": "Geen naam voor uitvoerschema gevonden in referentieobject",
|
||||
"ipAdapterModel": "Model IP-adapter",
|
||||
"latentsPolymorphic": "Polymorfisme latents",
|
||||
"vaeModelFieldDescription": "Beschrijving",
|
||||
"skippingInputNoTemplate": "Overslaan van invoerveld zonder sjabloon",
|
||||
"ipAdapterDescription": "Een Afbeeldingsprompt-adapter (IP-adapter).",
|
||||
"boolean": "Booleaanse waarden",
|
||||
"missingCanvaInitMaskImages": "Ontbrekende initialisatie- en maskerafbeeldingen voor canvas",
|
||||
"problemReadingMetadata": "Fout bij lezen van metagegevens uit afbeelding",
|
||||
"stringPolymorphicDescription": "Een verzameling tekenreeksen.",
|
||||
"oNNXModelField": "ONNX-model",
|
||||
"executionStateCompleted": "Voltooid",
|
||||
"node": "Knooppunt",
|
||||
"skippingUnknownInputType": "Overslaan van onbekend soort invoerveld",
|
||||
"workflowAuthor": "Auteur",
|
||||
"currentImage": "Huidige afbeelding",
|
||||
"controlField": "Controle",
|
||||
"workflowName": "Naam",
|
||||
"booleanDescription": "Booleanse waarden zijn waar en onwaar.",
|
||||
"collection": "Verzameling",
|
||||
"ipAdapterModelDescription": "Modelveld IP-adapter",
|
||||
"cannotConnectInputToInput": "Kan invoer niet aan invoer verbinden",
|
||||
"invalidOutputSchema": "Ongeldig uitvoerschema",
|
||||
"boardFieldDescription": "Een galerijbord",
|
||||
"floatDescription": "Zwevende-kommagetallen zijn getallen met een decimaalteken.",
|
||||
"floatPolymorphicDescription": "Een verzameling zwevende-kommagetallen.",
|
||||
"vaeField": "Vae",
|
||||
"conditioningField": "Conditionering",
|
||||
"unhandledOutputProperty": "Onverwerkt uitvoerkenmerk",
|
||||
"workflowNotes": "Opmerkingen",
|
||||
"string": "Tekenreeks",
|
||||
"floatCollection": "Verzameling zwevende-kommagetallen",
|
||||
"latentsField": "Latents",
|
||||
"cannotConnectOutputToOutput": "Kan uitvoer niet aan uitvoer verbinden",
|
||||
"booleanCollection": "Verzameling Booleaanse waarden",
|
||||
"connectionWouldCreateCycle": "Verbinding zou cyclisch worden",
|
||||
"cannotConnectToSelf": "Kan niet aan zichzelf verbinden",
|
||||
"notesDescription": "Voeg opmerkingen toe aan je werkstroom",
|
||||
"unknownField": "Onbekend veld",
|
||||
"inputFields": "Invoervelden",
|
||||
"colorCodeEdges": "Kleurgecodeerde randen",
|
||||
"uNetFieldDescription": "UNet-submodel.",
|
||||
"unknownNode": "Onbekend knooppunt",
|
||||
"imageCollectionDescription": "Een verzameling afbeeldingen.",
|
||||
"mismatchedVersion": "Heeft niet-overeenkomende versie",
|
||||
"vaeFieldDescription": "Vae-submodel.",
|
||||
"imageFieldDescription": "Afbeeldingen kunnen worden doorgegeven tussen knooppunten.",
|
||||
"outputNode": "Uitvoerknooppunt",
|
||||
"addNodeToolTip": "Voeg knooppunt toe (Shift+A, spatie)",
|
||||
"loadingNodes": "Bezig met laden van knooppunten...",
|
||||
"snapToGridHelp": "Lijn knooppunten uit op raster bij verplaatsing",
|
||||
"workflowSettings": "Instellingen werkstroomeditor",
|
||||
"mainModelFieldDescription": "Beschrijving",
|
||||
"sDXLRefinerModelField": "Verfijningsmodel",
|
||||
"loRAModelField": "LoRA",
|
||||
"unableToParseEdge": "Kan rand niet inlezen",
|
||||
"latentsCollectionDescription": "Latents kunnen worden doorgegeven tussen knooppunten.",
|
||||
"oNNXModelFieldDescription": "ONNX-modelveld.",
|
||||
"imageCollection": "Afbeeldingsverzameling"
|
||||
},
|
||||
"controlnet": {
|
||||
"amult": "a_mult",
|
||||
"resize": "Schaal",
|
||||
"showAdvanced": "Toon uitgebreid",
|
||||
"contentShuffleDescription": "Verschuift het materiaal in de afbeelding",
|
||||
"bgth": "bg_th",
|
||||
"addT2IAdapter": "Voeg $t(common.t2iAdapter) toe",
|
||||
"pidi": "PIDI",
|
||||
"importImageFromCanvas": "Importeer afbeelding uit canvas",
|
||||
"lineartDescription": "Zet afbeelding om naar lineart",
|
||||
"normalBae": "Normale BAE",
|
||||
"importMaskFromCanvas": "Importeer masker uit canvas",
|
||||
"hed": "HED",
|
||||
"hideAdvanced": "Verberg uitgebreid",
|
||||
"contentShuffle": "Verschuif materiaal",
|
||||
"controlNetEnabledT2IDisabled": "$t(common.controlNet) ingeschakeld, $t(common.t2iAdapter)s uitgeschakeld",
|
||||
"ipAdapterModel": "Adaptermodel",
|
||||
"resetControlImage": "Zet controle-afbeelding terug",
|
||||
"beginEndStepPercent": "Percentage begin-/eindstap",
|
||||
"mlsdDescription": "Minimalistische herkenning lijnsegmenten",
|
||||
"duplicate": "Maak kopie",
|
||||
"balanced": "Gebalanceerd",
|
||||
"f": "F",
|
||||
"h": "H",
|
||||
"prompt": "Prompt",
|
||||
"depthMidasDescription": "Generatie van diepteblad via Midas",
|
||||
"controlnet": "$t(controlnet.controlAdapter) #{{number}} ($t(common.controlNet))",
|
||||
"openPoseDescription": "Menselijke pose-benadering via Openpose",
|
||||
"control": "Controle",
|
||||
"resizeMode": "Modus schaling",
|
||||
"t2iEnabledControlNetDisabled": "$t(common.t2iAdapter) ingeschakeld, $t(common.controlNet)s uitgeschakeld",
|
||||
"coarse": "Grof",
|
||||
"weight": "Gewicht",
|
||||
"selectModel": "Kies een model",
|
||||
"crop": "Snij bij",
|
||||
"depthMidas": "Diepte (Midas)",
|
||||
"w": "B",
|
||||
"processor": "Verwerker",
|
||||
"addControlNet": "Voeg $t(common.controlNet) toe",
|
||||
"none": "Geen",
|
||||
"incompatibleBaseModel": "Niet-compatibel basismodel:",
|
||||
"enableControlnet": "Schakel ControlNet in",
|
||||
"detectResolution": "Herken resolutie",
|
||||
"controlNetT2IMutexDesc": "Gelijktijdig gebruik van $t(common.controlNet) en $t(common.t2iAdapter) wordt op dit moment niet ondersteund.",
|
||||
"ip_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.ipAdapter))",
|
||||
"pidiDescription": "PIDI-afbeeldingsverwerking",
|
||||
"mediapipeFace": "Mediapipe - Gezicht",
|
||||
"mlsd": "M-LSD",
|
||||
"controlMode": "Controlemodus",
|
||||
"fill": "Vul",
|
||||
"cannyDescription": "Herkenning Canny-rand",
|
||||
"addIPAdapter": "Voeg $t(common.ipAdapter) toe",
|
||||
"lineart": "Lineart",
|
||||
"colorMapDescription": "Genereert een kleurenblad van de afbeelding",
|
||||
"lineartAnimeDescription": "Lineartverwerking in anime-stijl",
|
||||
"t2i_adapter": "$t(controlnet.controlAdapter) #{{number}} ($t(common.t2iAdapter))",
|
||||
"minConfidence": "Min. vertrouwensniveau",
|
||||
"imageResolution": "Resolutie afbeelding",
|
||||
"megaControl": "Zeer veel controle",
|
||||
"depthZoe": "Diepte (Zoe)",
|
||||
"colorMap": "Kleur",
|
||||
"lowThreshold": "Lage drempelwaarde",
|
||||
"autoConfigure": "Configureer verwerker automatisch",
|
||||
"highThreshold": "Hoge drempelwaarde",
|
||||
"normalBaeDescription": "Normale BAE-verwerking",
|
||||
"noneDescription": "Geen verwerking toegepast",
|
||||
"saveControlImage": "Bewaar controle-afbeelding",
|
||||
"openPose": "Openpose",
|
||||
"toggleControlNet": "Zet deze ControlNet aan/uit",
|
||||
"delete": "Verwijder",
|
||||
"controlAdapter_one": "Control-adapter",
|
||||
"controlAdapter_other": "Control-adapters",
|
||||
"safe": "Veilig",
|
||||
"colorMapTileSize": "Grootte tegel",
|
||||
"lineartAnime": "Lineart-anime",
|
||||
"ipAdapterImageFallback": "Geen IP-adapterafbeelding gekozen",
|
||||
"mediapipeFaceDescription": "Gezichtsherkenning met Mediapipe",
|
||||
"canny": "Canny",
|
||||
"depthZoeDescription": "Generatie van diepteblad via Zoe",
|
||||
"hedDescription": "Herkenning van holistisch-geneste randen",
|
||||
"setControlImageDimensions": "Stel afmetingen controle-afbeelding in op B/H",
|
||||
"scribble": "Krabbel",
|
||||
"resetIPAdapterImage": "Zet IP-adapterafbeelding terug",
|
||||
"handAndFace": "Hand en gezicht",
|
||||
"enableIPAdapter": "Schakel IP-adapter in",
|
||||
"maxFaces": "Max. gezichten"
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"seedBehaviour": {
|
||||
"perPromptDesc": "Gebruik een verschillende seedwaarde per afbeelding",
|
||||
"perIterationLabel": "Seedwaarde per iteratie",
|
||||
"perIterationDesc": "Gebruik een verschillende seedwaarde per iteratie",
|
||||
"perPromptLabel": "Seedwaarde per afbeelding",
|
||||
"label": "Gedrag seedwaarde"
|
||||
},
|
||||
"enableDynamicPrompts": "Schakel dynamische prompts in",
|
||||
"combinatorial": "Combinatorische generatie",
|
||||
"maxPrompts": "Max. prompts",
|
||||
"promptsWithCount_one": "{{count}} prompt",
|
||||
"promptsWithCount_other": "{{count}} prompts",
|
||||
"dynamicPrompts": "Dynamische prompts"
|
||||
},
|
||||
"popovers": {
|
||||
"noiseUseCPU": {
|
||||
"paragraphs": [
|
||||
"Bestuurt of ruis wordt gegenereerd op de CPU of de GPU.",
|
||||
"Met CPU-ruis ingeschakeld zal een bepaalde seedwaarde dezelfde afbeelding opleveren op welke machine dan ook.",
|
||||
"Er is geen prestatieverschil bij het inschakelen van CPU-ruis."
|
||||
],
|
||||
"heading": "Gebruik CPU-ruis"
|
||||
},
|
||||
"paramScheduler": {
|
||||
"paragraphs": [
|
||||
"De planner bepaalt hoe per keer ruis wordt toegevoegd aan een afbeelding of hoe een monster wordt bijgewerkt op basis van de uitvoer van een model."
|
||||
],
|
||||
"heading": "Planner"
|
||||
},
|
||||
"scaleBeforeProcessing": {
|
||||
"paragraphs": [
|
||||
"Schaalt het gekozen gebied naar de grootte die het meest geschikt is voor het model, vooraf aan het proces van het afbeeldingen genereren."
|
||||
],
|
||||
"heading": "Schaal vooraf aan verwerking"
|
||||
},
|
||||
"compositingMaskAdjustments": {
|
||||
"heading": "Aanpassingen masker",
|
||||
"paragraphs": [
|
||||
"Pas het masker aan."
|
||||
]
|
||||
},
|
||||
"paramRatio": {
|
||||
"heading": "Beeldverhouding",
|
||||
"paragraphs": [
|
||||
"De beeldverhouding van de afmetingen van de afbeelding die wordt gegenereerd.",
|
||||
"Een afbeeldingsgrootte (in aantal pixels) equivalent aan 512x512 wordt aanbevolen voor SD1.5-modellen. Een grootte-equivalent van 1024x1024 wordt aanbevolen voor SDXL-modellen."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceSteps": {
|
||||
"heading": "Stappen",
|
||||
"paragraphs": [
|
||||
"Het aantal te gebruiken ontruisingsstappen in de coherentiefase.",
|
||||
"Gelijk aan de hoofdparameter Stappen."
|
||||
]
|
||||
},
|
||||
"dynamicPrompts": {
|
||||
"paragraphs": [
|
||||
"Dynamische prompts vormt een enkele prompt om in vele.",
|
||||
"De basissyntax is \"a {red|green|blue} ball\". Dit zal de volgende drie prompts geven: \"a red ball\", \"a green ball\" en \"a blue ball\".",
|
||||
"Gebruik de syntax zo vaak als je wilt in een enkele prompt, maar zorg ervoor dat het aantal gegenereerde prompts in lijn ligt met de instelling Max. prompts."
|
||||
],
|
||||
"heading": "Dynamische prompts"
|
||||
},
|
||||
"paramVAE": {
|
||||
"paragraphs": [
|
||||
"Het model gebruikt voor het vertalen van AI-uitvoer naar de uiteindelijke afbeelding."
|
||||
],
|
||||
"heading": "VAE"
|
||||
},
|
||||
"compositingBlur": {
|
||||
"heading": "Vervaging",
|
||||
"paragraphs": [
|
||||
"De vervagingsstraal van het masker."
|
||||
]
|
||||
},
|
||||
"paramIterations": {
|
||||
"paragraphs": [
|
||||
"Het aantal te genereren afbeeldingen.",
|
||||
"Als dynamische prompts is ingeschakeld, dan zal elke prompt dit aantal keer gegenereerd worden."
|
||||
],
|
||||
"heading": "Iteraties"
|
||||
},
|
||||
"paramVAEPrecision": {
|
||||
"heading": "Nauwkeurigheid VAE",
|
||||
"paragraphs": [
|
||||
"De nauwkeurigheid gebruikt tijdens de VAE-codering en -decodering. FP16/halve nauwkeurig is efficiënter, ten koste van kleine afbeeldingsvariaties."
|
||||
]
|
||||
},
|
||||
"compositingCoherenceMode": {
|
||||
"heading": "Modus",
|
||||
"paragraphs": [
|
||||
"De modus van de coherentiefase."
|
||||
]
|
||||
},
|
||||
"paramSeed": {
|
||||
"paragraphs": [
|
||||
"Bestuurt de startruis die gebruikt wordt bij het genereren.",
|
||||
"Schakel \"Willekeurige seedwaarde\" uit om identieke resultaten te krijgen met dezelfde generatie-instellingen."
|
||||
],
|
||||
"heading": "Seedwaarde"
|
||||
},
|
||||
"controlNetResizeMode": {
|
||||
"heading": "Schaalmodus",
|
||||
"paragraphs": [
|
||||
"Hoe de ControlNet-afbeelding zal worden geschaald aan de uitvoergrootte van de afbeelding."
|
||||
]
|
||||
},
|
||||
"controlNetBeginEnd": {
|
||||
"paragraphs": [
|
||||
"Op welke stappen van het ontruisingsproces ControlNet worden toegepast.",
|
||||
"ControlNets die worden toegepast aan het begin begeleiden het compositieproces. ControlNets die worden toegepast aan het eind zorgen voor details."
|
||||
],
|
||||
"heading": "Percentage begin- / eindstap"
|
||||
},
|
||||
"dynamicPromptsSeedBehaviour": {
|
||||
"paragraphs": [
|
||||
"Bestuurt hoe de seedwaarde wordt gebruikt bij het genereren van prompts.",
|
||||
"Per iteratie zal een unieke seedwaarde worden gebruikt voor elke iteratie. Gebruik dit om de promptvariaties binnen een enkele seedwaarde te verkennen.",
|
||||
"Bijvoorbeeld: als je vijf prompts heb, dan zal voor elke afbeelding dezelfde seedwaarde gebruikt worden.",
|
||||
"De optie Per afbeelding zal een unieke seedwaarde voor elke afbeelding gebruiken. Dit biedt meer variatie."
|
||||
],
|
||||
"heading": "Gedrag seedwaarde"
|
||||
},
|
||||
"clipSkip": {
|
||||
"paragraphs": [
|
||||
"Kies hoeveel CLIP-modellagen je wilt overslaan.",
|
||||
"Bepaalde modellen werken beter met bepaalde Overslaan CLIP-instellingen.",
|
||||
"Een hogere waarde geeft meestal een minder gedetailleerde afbeelding."
|
||||
],
|
||||
"heading": "Overslaan CLIP"
|
||||
},
|
||||
"paramModel": {
|
||||
"heading": "Model",
|
||||
"paragraphs": [
|
||||
"Model gebruikt voor de ontruisingsstappen.",
|
||||
"Verschillende modellen zijn meestal getraind zich te specialiseren in het maken van bepaalde esthetische resultaten en materiaal."
|
||||
]
|
||||
},
|
||||
"compositingCoherencePass": {
|
||||
"heading": "Coherentiefase",
|
||||
"paragraphs": [
|
||||
"Een tweede ronde ontruising helpt bij het samenstellen van de erin- of eruitgetekende afbeelding."
|
||||
]
|
||||
},
|
||||
"paramDenoisingStrength": {
|
||||
"paragraphs": [
|
||||
"Hoeveel ruis wordt toegevoegd aan de invoerafbeelding.",
|
||||
"0 geeft een identieke afbeelding, waarbij 1 een volledig nieuwe afbeelding geeft."
|
||||
],
|
||||
"heading": "Ontruisingssterkte"
|
||||
},
|
||||
"compositingStrength": {
|
||||
"heading": "Sterkte",
|
||||
"paragraphs": [
|
||||
"Ontruisingssterkte voor de coherentiefase.",
|
||||
"Gelijk aan de parameter Ontruisingssterkte Afbeelding naar afbeelding."
|
||||
]
|
||||
},
|
||||
"paramNegativeConditioning": {
|
||||
"paragraphs": [
|
||||
"Het generatieproces voorkomt de gegeven begrippen in de negatieve prompt. Gebruik dit om bepaalde zaken of voorwerpen uit te sluiten van de uitvoerafbeelding.",
|
||||
"Ondersteunt Compel-syntax en -embeddingen."
|
||||
],
|
||||
"heading": "Negatieve prompt"
|
||||
},
|
||||
"compositingBlurMethod": {
|
||||
"heading": "Vervagingsmethode",
|
||||
"paragraphs": [
|
||||
"De methode van de vervaging die wordt toegepast op het gemaskeerd gebied."
|
||||
]
|
||||
},
|
||||
"dynamicPromptsMaxPrompts": {
|
||||
"heading": "Max. prompts",
|
||||
"paragraphs": [
|
||||
"Beperkt het aantal prompts die kunnen worden gegenereerd door dynamische prompts."
|
||||
]
|
||||
},
|
||||
"infillMethod": {
|
||||
"paragraphs": [
|
||||
"Methode om een gekozen gebied in te vullen."
|
||||
],
|
||||
"heading": "Invulmethode"
|
||||
},
|
||||
"controlNetWeight": {
|
||||
"heading": "Gewicht",
|
||||
"paragraphs": [
|
||||
"Hoe sterk ControlNet effect heeft op de gegeneerde afbeelding."
|
||||
]
|
||||
},
|
||||
"controlNet": {
|
||||
"heading": "ControlNet",
|
||||
"paragraphs": [
|
||||
"ControlNets biedt begeleiding aan het generatieproces, waarbij hulp wordt geboden bij het maken van afbeelding met aangestuurde compositie, structuur of stijl, afhankelijk van het gekozen model."
|
||||
]
|
||||
},
|
||||
"paramCFGScale": {
|
||||
"heading": "CFG-schaal",
|
||||
"paragraphs": [
|
||||
"Bestuurt hoeveel je prompt invloed heeft op het generatieproces."
|
||||
]
|
||||
},
|
||||
"controlNetControlMode": {
|
||||
"paragraphs": [
|
||||
"Geeft meer gewicht aan ofwel de prompt danwel ControlNet."
|
||||
],
|
||||
"heading": "Controlemodus"
|
||||
},
|
||||
"paramSteps": {
|
||||
"heading": "Stappen",
|
||||
"paragraphs": [
|
||||
"Het aantal uit te voeren stappen tijdens elke generatie.",
|
||||
"Hogere stappenaantallen geven meestal betere afbeeldingen ten koste van een grotere benodigde generatietijd."
|
||||
]
|
||||
},
|
||||
"paramPositiveConditioning": {
|
||||
"heading": "Positieve prompt",
|
||||
"paragraphs": [
|
||||
"Begeleidt het generartieproces. Gebruik een woord of frase naar keuze.",
|
||||
"Syntaxes en embeddings voor Compel en dynamische prompts."
|
||||
]
|
||||
},
|
||||
"lora": {
|
||||
"heading": "Gewicht LoRA",
|
||||
"paragraphs": [
|
||||
"Een hogere LoRA-gewicht zal leiden tot een groter effect op de uiteindelijke afbeelding."
|
||||
]
|
||||
}
|
||||
},
|
||||
"metadata": {
|
||||
"seamless": "Naadloos",
|
||||
"positivePrompt": "Positieve prompt",
|
||||
"negativePrompt": "Negatieve prompt",
|
||||
"generationMode": "Generatiemodus",
|
||||
"Threshold": "Drempelwaarde ruis",
|
||||
"metadata": "Metagegevens",
|
||||
"strength": "Sterkte Afbeelding naar afbeelding",
|
||||
"seed": "Seedwaarde",
|
||||
"imageDetails": "Afbeeldingsdetails",
|
||||
"perlin": "Perlin-ruis",
|
||||
"model": "Model",
|
||||
"noImageDetails": "Geen afbeeldingsdetails gevonden",
|
||||
"hiresFix": "Optimalisatie voor hoge resolutie",
|
||||
"cfgScale": "CFG-schaal",
|
||||
"fit": "Schaal aanpassen in Afbeelding naar afbeelding",
|
||||
"initImage": "Initiële afbeelding",
|
||||
"recallParameters": "Opnieuw aan te roepen parameters",
|
||||
"height": "Hoogte",
|
||||
"variations": "Paren seedwaarde-gewicht",
|
||||
"noMetaData": "Geen metagegevens gevonden",
|
||||
"width": "Breedte",
|
||||
"createdBy": "Gemaakt door",
|
||||
"workflow": "Werkstroom",
|
||||
"steps": "Stappen",
|
||||
"scheduler": "Planner",
|
||||
"noRecallParameters": "Geen opnieuw uit te voeren parameters gevonden"
|
||||
},
|
||||
"queue": {
|
||||
"status": "Status",
|
||||
"pruneSucceeded": "{{item_count}} voltooide onderdelen uit wachtrij gesnoeid",
|
||||
"cancelTooltip": "Annuleer huidig onderdeel",
|
||||
"queueEmpty": "Wachtrij leeg",
|
||||
"pauseSucceeded": "Verwerker onderbroken",
|
||||
"in_progress": "Bezig",
|
||||
"queueFront": "Voeg toe aan voorkant van wachtrij",
|
||||
"notReady": "Kan niet in wachtrij plaatsen",
|
||||
"batchFailedToQueue": "Fout bij reeks in wachtrij plaatsen",
|
||||
"completed": "Voltooid",
|
||||
"queueBack": "Voeg toe aan wachtrij",
|
||||
"batchValues": "Reekswaarden",
|
||||
"cancelFailed": "Fout bij annuleren onderdeel",
|
||||
"queueCountPrediction": "Voeg {{predicted}} toe aan wachtrij",
|
||||
"batchQueued": "Reeks in wachtrij geplaatst",
|
||||
"pauseFailed": "Fout bij onderbreken verwerker",
|
||||
"clearFailed": "Fout bij wissen van wachtrij",
|
||||
"queuedCount": "{{pending}} wachtend",
|
||||
"front": "begin",
|
||||
"clearSucceeded": "Wachtrij gewist",
|
||||
"pause": "Onderbreek",
|
||||
"pruneTooltip": "Snoei {{item_count}} voltooide onderdelen",
|
||||
"cancelSucceeded": "Onderdeel geannuleerd",
|
||||
"batchQueuedDesc_one": "Voeg {{count}} sessie toe aan het {{direction}} van de wachtrij",
|
||||
"batchQueuedDesc_other": "Voeg {{count}} sessies toe aan het {{direction}} van de wachtrij",
|
||||
"graphQueued": "Graaf in wachtrij geplaatst",
|
||||
"queue": "Wachtrij",
|
||||
"batch": "Reeks",
|
||||
"clearQueueAlertDialog": "Als je de wachtrij onmiddellijk wist, dan worden alle onderdelen die bezig zijn geannuleerd en wordt de gehele wachtrij gewist.",
|
||||
"pending": "Wachtend",
|
||||
"completedIn": "Voltooid na",
|
||||
"resumeFailed": "Fout bij hervatten verwerker",
|
||||
"clear": "Wis",
|
||||
"prune": "Snoei",
|
||||
"total": "Totaal",
|
||||
"canceled": "Geannuleerd",
|
||||
"pruneFailed": "Fout bij snoeien van wachtrij",
|
||||
"cancelBatchSucceeded": "Reeks geannuleerd",
|
||||
"clearTooltip": "Annuleer en wis alle onderdelen",
|
||||
"current": "Huidig",
|
||||
"pauseTooltip": "Onderbreek verwerker",
|
||||
"failed": "Mislukt",
|
||||
"cancelItem": "Annuleer onderdeel",
|
||||
"next": "Volgende",
|
||||
"cancelBatch": "Annuleer reeks",
|
||||
"back": "eind",
|
||||
"cancel": "Annuleer",
|
||||
"session": "Sessie",
|
||||
"queueTotal": "Totaal {{total}}",
|
||||
"resumeSucceeded": "Verwerker hervat",
|
||||
"enqueueing": "Toevoegen van reeks aan wachtrij",
|
||||
"resumeTooltip": "Hervat verwerker",
|
||||
"queueMaxExceeded": "Max. aantal van {{max_queue_size}} overschreden, {{skip}} worden overgeslagen",
|
||||
"resume": "Hervat",
|
||||
"cancelBatchFailed": "Fout bij annuleren van reeks",
|
||||
"clearQueueAlertDialog2": "Weet je zeker dat je de wachtrij wilt wissen?",
|
||||
"item": "Onderdeel",
|
||||
"graphFailedToQueue": "Fout bij toevoegen graaf aan wachtrij"
|
||||
},
|
||||
"sdxl": {
|
||||
"refinerStart": "Startwaarde verfijner",
|
||||
"selectAModel": "Kies een model",
|
||||
"scheduler": "Planner",
|
||||
"cfgScale": "CFG-schaal",
|
||||
"negStylePrompt": "Negatieve-stijlprompt",
|
||||
"noModelsAvailable": "Geen modellen beschikbaar",
|
||||
"refiner": "Verfijner",
|
||||
"negAestheticScore": "Negatieve aantrekkelijkheidsscore",
|
||||
"useRefiner": "Gebruik verfijner",
|
||||
"denoisingStrength": "Sterkte ontruising",
|
||||
"refinermodel": "Verfijnermodel",
|
||||
"posAestheticScore": "Positieve aantrekkelijkheidsscore",
|
||||
"concatPromptStyle": "Plak prompt- en stijltekst aan elkaar",
|
||||
"loading": "Bezig met laden...",
|
||||
"steps": "Stappen",
|
||||
"posStylePrompt": "Positieve-stijlprompt"
|
||||
},
|
||||
"models": {
|
||||
"noMatchingModels": "Geen overeenkomend modellen",
|
||||
"loading": "bezig met laden",
|
||||
"noMatchingLoRAs": "Geen overeenkomende LoRA's",
|
||||
"noLoRAsAvailable": "Geen LoRA's beschikbaar",
|
||||
"noModelsAvailable": "Geen modellen beschikbaar",
|
||||
"selectModel": "Kies een model",
|
||||
"selectLoRA": "Kies een LoRA"
|
||||
},
|
||||
"boards": {
|
||||
"autoAddBoard": "Voeg automatisch bord toe",
|
||||
"topMessage": "Dit bord bevat afbeeldingen die in gebruik zijn door de volgende functies:",
|
||||
"move": "Verplaats",
|
||||
"menuItemAutoAdd": "Voeg dit automatisch toe aan bord",
|
||||
"myBoard": "Mijn bord",
|
||||
"searchBoard": "Zoek borden...",
|
||||
"noMatching": "Geen overeenkomende borden",
|
||||
"selectBoard": "Kies een bord",
|
||||
"cancel": "Annuleer",
|
||||
"addBoard": "Voeg bord toe",
|
||||
"bottomMessage": "Als je dit bord en alle afbeeldingen erop verwijdert, dan worden alle functies teruggezet die ervan gebruik maken.",
|
||||
"uncategorized": "Zonder categorie",
|
||||
"downloadBoard": "Download bord",
|
||||
"changeBoard": "Wijzig bord",
|
||||
"loading": "Bezig met laden...",
|
||||
"clearSearch": "Maak zoekopdracht leeg"
|
||||
},
|
||||
"invocationCache": {
|
||||
"disable": "Schakel uit",
|
||||
"misses": "Mislukt cacheverzoek",
|
||||
"enableFailed": "Fout bij inschakelen aanroepcache",
|
||||
"invocationCache": "Aanroepcache",
|
||||
"clearSucceeded": "Aanroepcache gewist",
|
||||
"enableSucceeded": "Aanroepcache ingeschakeld",
|
||||
"clearFailed": "Fout bij wissen aanroepcache",
|
||||
"hits": "Gelukt cacheverzoek",
|
||||
"disableSucceeded": "Aanroepcache uitgeschakeld",
|
||||
"disableFailed": "Fout bij uitschakelen aanroepcache",
|
||||
"enable": "Schakel in",
|
||||
"clear": "Wis",
|
||||
"maxCacheSize": "Max. grootte cache",
|
||||
"cacheSize": "Grootte cache"
|
||||
},
|
||||
"embedding": {
|
||||
"noMatchingEmbedding": "Geen overeenkomende embeddings",
|
||||
"addEmbedding": "Voeg embedding toe",
|
||||
"incompatibleModel": "Niet-compatibel basismodel:"
|
||||
}
|
||||
}
|
||||
|
||||
@ -88,7 +88,9 @@
|
||||
"t2iAdapter": "T2I Adapter",
|
||||
"ipAdapter": "IP Adapter",
|
||||
"controlAdapter": "Control Adapter",
|
||||
"controlNet": "ControlNet"
|
||||
"controlNet": "ControlNet",
|
||||
"on": "开",
|
||||
"auto": "自动"
|
||||
},
|
||||
"gallery": {
|
||||
"generations": "生成的图像",
|
||||
@ -472,7 +474,8 @@
|
||||
"vae": "VAE",
|
||||
"oliveModels": "Olive",
|
||||
"loraModels": "LoRA",
|
||||
"alpha": "Alpha"
|
||||
"alpha": "Alpha",
|
||||
"vaePrecision": "VAE 精度"
|
||||
},
|
||||
"parameters": {
|
||||
"images": "图像",
|
||||
@ -595,7 +598,11 @@
|
||||
"useX2Model": "图像太大,无法使用 x4 模型,使用 x2 模型作为替代",
|
||||
"tooLarge": "图像太大无法进行放大,请选择更小的图像"
|
||||
},
|
||||
"iterationsWithCount_other": "{{count}} 次迭代生成"
|
||||
"iterationsWithCount_other": "{{count}} 次迭代生成",
|
||||
"seamlessX&Y": "无缝 X & Y",
|
||||
"aspectRatioFree": "自由",
|
||||
"seamlessX": "无缝 X",
|
||||
"seamlessY": "无缝 Y"
|
||||
},
|
||||
"settings": {
|
||||
"models": "模型",
|
||||
@ -628,10 +635,11 @@
|
||||
"clearIntermediates": "清除中间产物",
|
||||
"clearIntermediatesDesc3": "您图库中的图像不会被删除。",
|
||||
"clearIntermediatesDesc2": "中间产物图像是生成过程中产生的副产品,与图库中的结果图像不同。清除中间产物可释放磁盘空间。",
|
||||
"intermediatesCleared_other": "已清除 {{number}} 个中间产物",
|
||||
"intermediatesCleared_other": "已清除 {{count}} 个中间产物",
|
||||
"clearIntermediatesDesc1": "清除中间产物会重置您的画布和 ControlNet 状态。",
|
||||
"intermediatesClearedFailed": "清除中间产物时出现问题",
|
||||
"noIntermediates": "没有可清除的中间产物"
|
||||
"clearIntermediatesWithCount_other": "清除 {{count}} 个中间产物",
|
||||
"clearIntermediatesDisabled": "队列为空才能清理中间产物"
|
||||
},
|
||||
"toast": {
|
||||
"tempFoldersEmptied": "临时文件夹已清空",
|
||||
@ -714,7 +722,7 @@
|
||||
"canvasSavedGallery": "画布已保存到图库",
|
||||
"imageUploadFailed": "图像上传失败",
|
||||
"problemImportingMask": "导入遮罩时出现问题",
|
||||
"baseModelChangedCleared_other": "基础模型已更改, 已清除或禁用 {{number}} 个不兼容的子模型"
|
||||
"baseModelChangedCleared_other": "基础模型已更改, 已清除或禁用 {{count}} 个不兼容的子模型"
|
||||
},
|
||||
"unifiedCanvas": {
|
||||
"layer": "图层",
|
||||
@ -1003,7 +1011,27 @@
|
||||
"booleanCollection": "布尔值合集",
|
||||
"imageCollectionDescription": "一个图像合集。",
|
||||
"loRAModelField": "LoRA",
|
||||
"imageCollection": "图像合集"
|
||||
"imageCollection": "图像合集",
|
||||
"ipAdapterPolymorphicDescription": "一个 IP-Adapters Collection 合集。",
|
||||
"ipAdapterCollection": "IP-Adapters 合集",
|
||||
"conditioningCollection": "条件合集",
|
||||
"ipAdapterPolymorphic": "IP-Adapters 多态",
|
||||
"conditioningCollectionDescription": "条件可以在节点间传递。",
|
||||
"colorPolymorphic": "颜色多态",
|
||||
"conditioningPolymorphic": "条件多态",
|
||||
"latentsCollection": "Latents 合集",
|
||||
"stringPolymorphic": "字符多态",
|
||||
"conditioningPolymorphicDescription": "条件可以在节点间传递。",
|
||||
"imagePolymorphic": "图像多态",
|
||||
"floatPolymorphic": "浮点多态",
|
||||
"ipAdapterCollectionDescription": "一个 IP-Adapters Collection 合集。",
|
||||
"ipAdapter": "IP-Adapter",
|
||||
"booleanPolymorphic": "布尔多态",
|
||||
"conditioningFieldDescription": "条件可以在节点间传递。",
|
||||
"integerPolymorphic": "整数多态",
|
||||
"latentsPolymorphic": "Latents 多态",
|
||||
"conditioningField": "条件",
|
||||
"latentsField": "Latents"
|
||||
},
|
||||
"controlnet": {
|
||||
"resize": "直接缩放",
|
||||
@ -1087,7 +1115,7 @@
|
||||
"depthZoe": "Depth (Zoe)",
|
||||
"colorMap": "Color",
|
||||
"openPose": "Openpose",
|
||||
"controlAdapter": "Control Adapter",
|
||||
"controlAdapter_other": "Control Adapters",
|
||||
"lineartAnime": "Lineart Anime",
|
||||
"canny": "Canny"
|
||||
},
|
||||
@ -1141,7 +1169,7 @@
|
||||
"queuedCount": "{{pending}} 待处理",
|
||||
"front": "前",
|
||||
"pruneTooltip": "修剪 {{item_count}} 个已完成的项目",
|
||||
"batchQueuedDesc": "在队列的 {{direction}} 中添加了 {{item_count}} 个会话",
|
||||
"batchQueuedDesc_other": "在队列的 {{direction}} 中添加了 {{count}} 个会话",
|
||||
"graphQueued": "节点图已加入队列",
|
||||
"back": "后",
|
||||
"session": "会话",
|
||||
@ -1192,7 +1220,9 @@
|
||||
"steps": "步数",
|
||||
"scheduler": "调度器",
|
||||
"seamless": "无缝",
|
||||
"fit": "图生图适应"
|
||||
"fit": "图生图匹配",
|
||||
"recallParameters": "召回参数",
|
||||
"noRecallParameters": "未找到要召回的参数"
|
||||
},
|
||||
"models": {
|
||||
"noMatchingModels": "无相匹配的模型",
|
||||
|
||||
@ -44,7 +44,7 @@ export const addCanvasMergedListener = () => {
|
||||
}
|
||||
|
||||
const baseLayerRect = canvasBaseLayer.getClientRect({
|
||||
relativeTo: canvasBaseLayer.getParent(),
|
||||
relativeTo: canvasBaseLayer.getParent() ?? undefined,
|
||||
});
|
||||
|
||||
const imageDTO = await dispatch(
|
||||
|
||||
@ -151,7 +151,9 @@ export const addRequestedSingleImageDeletionListener = () => {
|
||||
|
||||
if (wasImageDeleted) {
|
||||
dispatch(
|
||||
api.util.invalidateTags([{ type: 'Board', id: imageDTO.board_id }])
|
||||
api.util.invalidateTags([
|
||||
{ type: 'Board', id: imageDTO.board_id ?? 'none' },
|
||||
])
|
||||
);
|
||||
}
|
||||
},
|
||||
|
||||
@ -39,7 +39,8 @@ export type SDFeature =
|
||||
| 'hires'
|
||||
| 'lora'
|
||||
| 'embedding'
|
||||
| 'vae';
|
||||
| 'vae'
|
||||
| 'hrf';
|
||||
|
||||
/**
|
||||
* Configuration options for the InvokeAI UI.
|
||||
@ -110,6 +111,14 @@ export type AppConfig = {
|
||||
fineStep: number;
|
||||
coarseStep: number;
|
||||
};
|
||||
hrfStrength: {
|
||||
initial: number;
|
||||
min: number;
|
||||
sliderMax: number;
|
||||
inputMax: number;
|
||||
fineStep: number;
|
||||
coarseStep: number;
|
||||
};
|
||||
dynamicPrompts: {
|
||||
maxPrompts: {
|
||||
initial: number;
|
||||
|
||||
@ -2,6 +2,7 @@ import { PopoverProps } from '@chakra-ui/react';
|
||||
|
||||
export type Feature =
|
||||
| 'clipSkip'
|
||||
| 'hrf'
|
||||
| 'paramNegativeConditioning'
|
||||
| 'paramPositiveConditioning'
|
||||
| 'paramScheduler'
|
||||
|
||||
@ -6,7 +6,7 @@ import { useMantineMultiSelectStyles } from 'mantine-theme/hooks/useMantineMulti
|
||||
import { KeyboardEvent, RefObject, memo, useCallback } from 'react';
|
||||
|
||||
type IAIMultiSelectProps = Omit<MultiSelectProps, 'label'> & {
|
||||
tooltip?: string;
|
||||
tooltip?: string | null;
|
||||
inputRef?: RefObject<HTMLInputElement>;
|
||||
label?: string;
|
||||
};
|
||||
|
||||
@ -12,7 +12,7 @@ export type IAISelectDataType = {
|
||||
};
|
||||
|
||||
type IAISelectProps = Omit<SelectProps, 'label'> & {
|
||||
tooltip?: string;
|
||||
tooltip?: string | null;
|
||||
label?: string;
|
||||
inputRef?: RefObject<HTMLInputElement>;
|
||||
};
|
||||
|
||||
@ -10,7 +10,7 @@ export type IAISelectDataType = {
|
||||
};
|
||||
|
||||
export type IAISelectProps = Omit<SelectProps, 'label'> & {
|
||||
tooltip?: string;
|
||||
tooltip?: string | null;
|
||||
inputRef?: RefObject<HTMLInputElement>;
|
||||
label?: string;
|
||||
};
|
||||
|
||||
@ -30,6 +30,7 @@ import {
|
||||
isCanvasMaskLine,
|
||||
} from './canvasTypes';
|
||||
import { appSocketQueueItemStatusChanged } from 'services/events/actions';
|
||||
import { queueApi } from 'services/api/endpoints/queue';
|
||||
|
||||
export const initialLayerState: CanvasLayerState = {
|
||||
objects: [],
|
||||
@ -812,6 +813,20 @@ export const canvasSlice = createSlice({
|
||||
);
|
||||
}
|
||||
});
|
||||
builder.addMatcher(
|
||||
queueApi.endpoints.clearQueue.matchFulfilled,
|
||||
(state) => {
|
||||
state.batchIds = [];
|
||||
}
|
||||
);
|
||||
builder.addMatcher(
|
||||
queueApi.endpoints.cancelByBatchIds.matchFulfilled,
|
||||
(state, action) => {
|
||||
state.batchIds = state.batchIds.filter(
|
||||
(id) => !action.meta.arg.originalArgs.batch_ids.includes(id)
|
||||
);
|
||||
}
|
||||
);
|
||||
},
|
||||
});
|
||||
|
||||
|
||||
@ -90,9 +90,7 @@ const ControlAdaptersCollapse = () => {
|
||||
|
||||
return (
|
||||
<IAICollapse
|
||||
label={t('controlnet.controlAdapter', {
|
||||
count: controlAdapterIds.length,
|
||||
})}
|
||||
label={t('controlnet.controlAdapter_other')}
|
||||
activeLabel={activeLabel}
|
||||
>
|
||||
<Flex sx={{ flexDir: 'column', gap: 2 }}>
|
||||
|
||||
@ -39,7 +39,10 @@ export const dynamicPromptsSlice = createSlice({
|
||||
promptsChanged: (state, action: PayloadAction<string[]>) => {
|
||||
state.prompts = action.payload;
|
||||
},
|
||||
parsingErrorChanged: (state, action: PayloadAction<string | undefined>) => {
|
||||
parsingErrorChanged: (
|
||||
state,
|
||||
action: PayloadAction<string | null | undefined>
|
||||
) => {
|
||||
state.parsingError = action.payload;
|
||||
},
|
||||
isErrorChanged: (state, action: PayloadAction<boolean>) => {
|
||||
|
||||
@ -18,6 +18,7 @@ import ImageMetadataActions from './ImageMetadataActions';
|
||||
import { useAppSelector } from '../../../../app/store/storeHooks';
|
||||
import { configSelector } from '../../../system/store/configSelectors';
|
||||
import { useTranslation } from 'react-i18next';
|
||||
import ScrollableContent from 'features/nodes/components/sidePanel/ScrollableContent';
|
||||
|
||||
type ImageMetadataViewerProps = {
|
||||
image: ImageDTO;
|
||||
@ -65,19 +66,32 @@ const ImageMetadataViewer = ({ image }: ImageMetadataViewerProps) => {
|
||||
</Link>
|
||||
</Flex>
|
||||
|
||||
<ImageMetadataActions metadata={metadata} />
|
||||
|
||||
<Tabs
|
||||
variant="line"
|
||||
sx={{ display: 'flex', flexDir: 'column', w: 'full', h: 'full' }}
|
||||
sx={{
|
||||
display: 'flex',
|
||||
flexDir: 'column',
|
||||
w: 'full',
|
||||
h: 'full',
|
||||
}}
|
||||
>
|
||||
<TabList>
|
||||
<Tab>{t('metadata.recallParameters')}</Tab>
|
||||
<Tab>{t('metadata.metadata')}</Tab>
|
||||
<Tab>{t('metadata.imageDetails')}</Tab>
|
||||
<Tab>{t('metadata.workflow')}</Tab>
|
||||
</TabList>
|
||||
|
||||
<TabPanels>
|
||||
<TabPanel>
|
||||
{metadata ? (
|
||||
<ScrollableContent>
|
||||
<ImageMetadataActions metadata={metadata} />
|
||||
</ScrollableContent>
|
||||
) : (
|
||||
<IAINoContentFallback label={t('metadata.noRecallParameters')} />
|
||||
)}
|
||||
</TabPanel>
|
||||
<TabPanel>
|
||||
{metadata ? (
|
||||
<DataViewer data={metadata} label={t('metadata.metadata')} />
|
||||
|
||||
@ -10,7 +10,7 @@ import {
|
||||
} from 'features/parameters/types/parameterSchemas';
|
||||
import i18n from 'i18next';
|
||||
import { has, keyBy } from 'lodash-es';
|
||||
import { OpenAPIV3 } from 'openapi-types';
|
||||
import { OpenAPIV3_1 } from 'openapi-types';
|
||||
import { RgbaColor } from 'react-colorful';
|
||||
import { Node } from 'reactflow';
|
||||
import { Graph, _InputField, _OutputField } from 'services/api/types';
|
||||
@ -791,9 +791,9 @@ export type IntegerInputFieldTemplate = InputFieldTemplateBase & {
|
||||
default: number;
|
||||
multipleOf?: number;
|
||||
maximum?: number;
|
||||
exclusiveMaximum?: boolean;
|
||||
exclusiveMaximum?: number;
|
||||
minimum?: number;
|
||||
exclusiveMinimum?: boolean;
|
||||
exclusiveMinimum?: number;
|
||||
};
|
||||
|
||||
export type IntegerCollectionInputFieldTemplate = InputFieldTemplateBase & {
|
||||
@ -814,9 +814,9 @@ export type FloatInputFieldTemplate = InputFieldTemplateBase & {
|
||||
default: number;
|
||||
multipleOf?: number;
|
||||
maximum?: number;
|
||||
exclusiveMaximum?: boolean;
|
||||
exclusiveMaximum?: number;
|
||||
minimum?: number;
|
||||
exclusiveMinimum?: boolean;
|
||||
exclusiveMinimum?: number;
|
||||
};
|
||||
|
||||
export type FloatCollectionInputFieldTemplate = InputFieldTemplateBase & {
|
||||
@ -1163,20 +1163,20 @@ export type TypeHints = {
|
||||
};
|
||||
|
||||
export type InvocationSchemaExtra = {
|
||||
output: OpenAPIV3.ReferenceObject; // the output of the invocation
|
||||
output: OpenAPIV3_1.ReferenceObject; // the output of the invocation
|
||||
title: string;
|
||||
category?: string;
|
||||
tags?: string[];
|
||||
version?: string;
|
||||
properties: Omit<
|
||||
NonNullable<OpenAPIV3.SchemaObject['properties']> &
|
||||
NonNullable<OpenAPIV3_1.SchemaObject['properties']> &
|
||||
(_InputField | _OutputField),
|
||||
'type'
|
||||
> & {
|
||||
type: Omit<OpenAPIV3.SchemaObject, 'default'> & {
|
||||
type: Omit<OpenAPIV3_1.SchemaObject, 'default'> & {
|
||||
default: AnyInvocationType;
|
||||
};
|
||||
use_cache: Omit<OpenAPIV3.SchemaObject, 'default'> & {
|
||||
use_cache: Omit<OpenAPIV3_1.SchemaObject, 'default'> & {
|
||||
default: boolean;
|
||||
};
|
||||
};
|
||||
@ -1187,17 +1187,17 @@ export type InvocationSchemaType = {
|
||||
};
|
||||
|
||||
export type InvocationBaseSchemaObject = Omit<
|
||||
OpenAPIV3.BaseSchemaObject,
|
||||
OpenAPIV3_1.BaseSchemaObject,
|
||||
'title' | 'type' | 'properties'
|
||||
> &
|
||||
InvocationSchemaExtra;
|
||||
|
||||
export type InvocationOutputSchemaObject = Omit<
|
||||
OpenAPIV3.SchemaObject,
|
||||
OpenAPIV3_1.SchemaObject,
|
||||
'properties'
|
||||
> & {
|
||||
properties: OpenAPIV3.SchemaObject['properties'] & {
|
||||
type: Omit<OpenAPIV3.SchemaObject, 'default'> & {
|
||||
properties: OpenAPIV3_1.SchemaObject['properties'] & {
|
||||
type: Omit<OpenAPIV3_1.SchemaObject, 'default'> & {
|
||||
default: string;
|
||||
};
|
||||
} & {
|
||||
@ -1205,14 +1205,18 @@ export type InvocationOutputSchemaObject = Omit<
|
||||
};
|
||||
};
|
||||
|
||||
export type InvocationFieldSchema = OpenAPIV3.SchemaObject & _InputField;
|
||||
export type InvocationFieldSchema = OpenAPIV3_1.SchemaObject & _InputField;
|
||||
|
||||
export type OpenAPIV3_1SchemaOrRef =
|
||||
| OpenAPIV3_1.ReferenceObject
|
||||
| OpenAPIV3_1.SchemaObject;
|
||||
|
||||
export interface ArraySchemaObject extends InvocationBaseSchemaObject {
|
||||
type: OpenAPIV3.ArraySchemaObjectType;
|
||||
items: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject;
|
||||
type: OpenAPIV3_1.ArraySchemaObjectType;
|
||||
items: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject;
|
||||
}
|
||||
export interface NonArraySchemaObject extends InvocationBaseSchemaObject {
|
||||
type?: OpenAPIV3.NonArraySchemaObjectType;
|
||||
type?: OpenAPIV3_1.NonArraySchemaObjectType;
|
||||
}
|
||||
|
||||
export type InvocationSchemaObject = (
|
||||
@ -1221,41 +1225,41 @@ export type InvocationSchemaObject = (
|
||||
) & { class: 'invocation' };
|
||||
|
||||
export const isSchemaObject = (
|
||||
obj: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject | undefined
|
||||
): obj is OpenAPIV3.SchemaObject => Boolean(obj && !('$ref' in obj));
|
||||
obj: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject | undefined
|
||||
): obj is OpenAPIV3_1.SchemaObject => Boolean(obj && !('$ref' in obj));
|
||||
|
||||
export const isArraySchemaObject = (
|
||||
obj: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject | undefined
|
||||
): obj is OpenAPIV3.ArraySchemaObject =>
|
||||
obj: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject | undefined
|
||||
): obj is OpenAPIV3_1.ArraySchemaObject =>
|
||||
Boolean(obj && !('$ref' in obj) && obj.type === 'array');
|
||||
|
||||
export const isNonArraySchemaObject = (
|
||||
obj: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject | undefined
|
||||
): obj is OpenAPIV3.NonArraySchemaObject =>
|
||||
obj: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject | undefined
|
||||
): obj is OpenAPIV3_1.NonArraySchemaObject =>
|
||||
Boolean(obj && !('$ref' in obj) && obj.type !== 'array');
|
||||
|
||||
export const isRefObject = (
|
||||
obj: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject | undefined
|
||||
): obj is OpenAPIV3.ReferenceObject => Boolean(obj && '$ref' in obj);
|
||||
obj: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject | undefined
|
||||
): obj is OpenAPIV3_1.ReferenceObject => Boolean(obj && '$ref' in obj);
|
||||
|
||||
export const isInvocationSchemaObject = (
|
||||
obj:
|
||||
| OpenAPIV3.ReferenceObject
|
||||
| OpenAPIV3.SchemaObject
|
||||
| OpenAPIV3_1.ReferenceObject
|
||||
| OpenAPIV3_1.SchemaObject
|
||||
| InvocationSchemaObject
|
||||
): obj is InvocationSchemaObject =>
|
||||
'class' in obj && obj.class === 'invocation';
|
||||
|
||||
export const isInvocationOutputSchemaObject = (
|
||||
obj:
|
||||
| OpenAPIV3.ReferenceObject
|
||||
| OpenAPIV3.SchemaObject
|
||||
| OpenAPIV3_1.ReferenceObject
|
||||
| OpenAPIV3_1.SchemaObject
|
||||
| InvocationOutputSchemaObject
|
||||
): obj is InvocationOutputSchemaObject =>
|
||||
'class' in obj && obj.class === 'output';
|
||||
|
||||
export const isInvocationFieldSchema = (
|
||||
obj: OpenAPIV3.ReferenceObject | OpenAPIV3.SchemaObject
|
||||
obj: OpenAPIV3_1.ReferenceObject | OpenAPIV3_1.SchemaObject
|
||||
): obj is InvocationFieldSchema => !('$ref' in obj);
|
||||
|
||||
export type InvocationEdgeExtra = { type: 'default' | 'collapsed' };
|
||||
|
||||
@ -1,5 +1,12 @@
|
||||
import { isBoolean, isInteger, isNumber, isString } from 'lodash-es';
|
||||
import { OpenAPIV3 } from 'openapi-types';
|
||||
import {
|
||||
isArray,
|
||||
isBoolean,
|
||||
isInteger,
|
||||
isNumber,
|
||||
isString,
|
||||
startCase,
|
||||
} from 'lodash-es';
|
||||
import { OpenAPIV3_1 } from 'openapi-types';
|
||||
import {
|
||||
COLLECTION_MAP,
|
||||
POLYMORPHIC_TYPES,
|
||||
@ -72,6 +79,7 @@ import {
|
||||
T2IAdapterCollectionInputFieldTemplate,
|
||||
BoardInputFieldTemplate,
|
||||
InputFieldTemplate,
|
||||
OpenAPIV3_1SchemaOrRef,
|
||||
} from '../types/types';
|
||||
import { ControlField } from 'services/api/types';
|
||||
|
||||
@ -90,7 +98,7 @@ export type BuildInputFieldArg = {
|
||||
* @example
|
||||
* refObjectToFieldType({ "$ref": "#/components/schemas/ImageField" }) --> 'ImageField'
|
||||
*/
|
||||
export const refObjectToSchemaName = (refObject: OpenAPIV3.ReferenceObject) =>
|
||||
export const refObjectToSchemaName = (refObject: OpenAPIV3_1.ReferenceObject) =>
|
||||
refObject.$ref.split('/').slice(-1)[0];
|
||||
|
||||
const buildIntegerInputFieldTemplate = ({
|
||||
@ -111,7 +119,10 @@ const buildIntegerInputFieldTemplate = ({
|
||||
template.maximum = schemaObject.maximum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMaximum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMaximum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMaximum)
|
||||
) {
|
||||
template.exclusiveMaximum = schemaObject.exclusiveMaximum;
|
||||
}
|
||||
|
||||
@ -119,7 +130,10 @@ const buildIntegerInputFieldTemplate = ({
|
||||
template.minimum = schemaObject.minimum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMinimum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMinimum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMinimum)
|
||||
) {
|
||||
template.exclusiveMinimum = schemaObject.exclusiveMinimum;
|
||||
}
|
||||
|
||||
@ -144,7 +158,10 @@ const buildIntegerPolymorphicInputFieldTemplate = ({
|
||||
template.maximum = schemaObject.maximum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMaximum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMaximum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMaximum)
|
||||
) {
|
||||
template.exclusiveMaximum = schemaObject.exclusiveMaximum;
|
||||
}
|
||||
|
||||
@ -152,7 +169,10 @@ const buildIntegerPolymorphicInputFieldTemplate = ({
|
||||
template.minimum = schemaObject.minimum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMinimum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMinimum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMinimum)
|
||||
) {
|
||||
template.exclusiveMinimum = schemaObject.exclusiveMinimum;
|
||||
}
|
||||
|
||||
@ -195,7 +215,10 @@ const buildFloatInputFieldTemplate = ({
|
||||
template.maximum = schemaObject.maximum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMaximum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMaximum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMaximum)
|
||||
) {
|
||||
template.exclusiveMaximum = schemaObject.exclusiveMaximum;
|
||||
}
|
||||
|
||||
@ -203,7 +226,10 @@ const buildFloatInputFieldTemplate = ({
|
||||
template.minimum = schemaObject.minimum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMinimum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMinimum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMinimum)
|
||||
) {
|
||||
template.exclusiveMinimum = schemaObject.exclusiveMinimum;
|
||||
}
|
||||
|
||||
@ -227,7 +253,10 @@ const buildFloatPolymorphicInputFieldTemplate = ({
|
||||
template.maximum = schemaObject.maximum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMaximum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMaximum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMaximum)
|
||||
) {
|
||||
template.exclusiveMaximum = schemaObject.exclusiveMaximum;
|
||||
}
|
||||
|
||||
@ -235,7 +264,10 @@ const buildFloatPolymorphicInputFieldTemplate = ({
|
||||
template.minimum = schemaObject.minimum;
|
||||
}
|
||||
|
||||
if (schemaObject.exclusiveMinimum !== undefined) {
|
||||
if (
|
||||
schemaObject.exclusiveMinimum !== undefined &&
|
||||
isNumber(schemaObject.exclusiveMinimum)
|
||||
) {
|
||||
template.exclusiveMinimum = schemaObject.exclusiveMinimum;
|
||||
}
|
||||
return template;
|
||||
@ -872,84 +904,106 @@ const buildSchedulerInputFieldTemplate = ({
|
||||
};
|
||||
|
||||
export const getFieldType = (
|
||||
schemaObject: InvocationFieldSchema
|
||||
schemaObject: OpenAPIV3_1SchemaOrRef
|
||||
): string | undefined => {
|
||||
if (schemaObject?.ui_type) {
|
||||
return schemaObject.ui_type;
|
||||
} else if (!schemaObject.type) {
|
||||
// if schemaObject has no type, then it should have one of allOf, anyOf, oneOf
|
||||
if (isSchemaObject(schemaObject)) {
|
||||
if (!schemaObject.type) {
|
||||
// if schemaObject has no type, then it should have one of allOf, anyOf, oneOf
|
||||
|
||||
if (schemaObject.allOf) {
|
||||
const allOf = schemaObject.allOf;
|
||||
if (allOf && allOf[0] && isRefObject(allOf[0])) {
|
||||
return refObjectToSchemaName(allOf[0]);
|
||||
}
|
||||
} else if (schemaObject.anyOf) {
|
||||
const anyOf = schemaObject.anyOf;
|
||||
/**
|
||||
* Handle Polymorphic inputs, eg string | string[]. In OpenAPI, this is:
|
||||
* - an `anyOf` with two items
|
||||
* - one is an `ArraySchemaObject` with a single `SchemaObject or ReferenceObject` of type T in its `items`
|
||||
* - the other is a `SchemaObject` or `ReferenceObject` of type T
|
||||
*
|
||||
* Any other cases we ignore.
|
||||
*/
|
||||
|
||||
let firstType: string | undefined;
|
||||
let secondType: string | undefined;
|
||||
|
||||
if (isArraySchemaObject(anyOf[0])) {
|
||||
// first is array, second is not
|
||||
const first = anyOf[0].items;
|
||||
const second = anyOf[1];
|
||||
if (isRefObject(first) && isRefObject(second)) {
|
||||
firstType = refObjectToSchemaName(first);
|
||||
secondType = refObjectToSchemaName(second);
|
||||
} else if (
|
||||
isNonArraySchemaObject(first) &&
|
||||
isNonArraySchemaObject(second)
|
||||
) {
|
||||
firstType = first.type;
|
||||
secondType = second.type;
|
||||
if (schemaObject.allOf) {
|
||||
const allOf = schemaObject.allOf;
|
||||
if (allOf && allOf[0] && isRefObject(allOf[0])) {
|
||||
return refObjectToSchemaName(allOf[0]);
|
||||
}
|
||||
} else if (isArraySchemaObject(anyOf[1])) {
|
||||
// first is not array, second is
|
||||
const first = anyOf[0];
|
||||
const second = anyOf[1].items;
|
||||
if (isRefObject(first) && isRefObject(second)) {
|
||||
firstType = refObjectToSchemaName(first);
|
||||
secondType = refObjectToSchemaName(second);
|
||||
} else if (
|
||||
isNonArraySchemaObject(first) &&
|
||||
isNonArraySchemaObject(second)
|
||||
) {
|
||||
firstType = first.type;
|
||||
secondType = second.type;
|
||||
} else if (schemaObject.anyOf) {
|
||||
// ignore null types
|
||||
const anyOf = schemaObject.anyOf.filter((i) => {
|
||||
if (isSchemaObject(i)) {
|
||||
if (i.type === 'null') {
|
||||
return false;
|
||||
}
|
||||
}
|
||||
return true;
|
||||
});
|
||||
if (anyOf.length === 1) {
|
||||
if (isRefObject(anyOf[0])) {
|
||||
return refObjectToSchemaName(anyOf[0]);
|
||||
} else if (isSchemaObject(anyOf[0])) {
|
||||
return getFieldType(anyOf[0]);
|
||||
}
|
||||
}
|
||||
/**
|
||||
* Handle Polymorphic inputs, eg string | string[]. In OpenAPI, this is:
|
||||
* - an `anyOf` with two items
|
||||
* - one is an `ArraySchemaObject` with a single `SchemaObject or ReferenceObject` of type T in its `items`
|
||||
* - the other is a `SchemaObject` or `ReferenceObject` of type T
|
||||
*
|
||||
* Any other cases we ignore.
|
||||
*/
|
||||
|
||||
let firstType: string | undefined;
|
||||
let secondType: string | undefined;
|
||||
|
||||
if (isArraySchemaObject(anyOf[0])) {
|
||||
// first is array, second is not
|
||||
const first = anyOf[0].items;
|
||||
const second = anyOf[1];
|
||||
if (isRefObject(first) && isRefObject(second)) {
|
||||
firstType = refObjectToSchemaName(first);
|
||||
secondType = refObjectToSchemaName(second);
|
||||
} else if (
|
||||
isNonArraySchemaObject(first) &&
|
||||
isNonArraySchemaObject(second)
|
||||
) {
|
||||
firstType = first.type;
|
||||
secondType = second.type;
|
||||
}
|
||||
} else if (isArraySchemaObject(anyOf[1])) {
|
||||
// first is not array, second is
|
||||
const first = anyOf[0];
|
||||
const second = anyOf[1].items;
|
||||
if (isRefObject(first) && isRefObject(second)) {
|
||||
firstType = refObjectToSchemaName(first);
|
||||
secondType = refObjectToSchemaName(second);
|
||||
} else if (
|
||||
isNonArraySchemaObject(first) &&
|
||||
isNonArraySchemaObject(second)
|
||||
) {
|
||||
firstType = first.type;
|
||||
secondType = second.type;
|
||||
}
|
||||
}
|
||||
if (firstType === secondType && isPolymorphicItemType(firstType)) {
|
||||
return SINGLE_TO_POLYMORPHIC_MAP[firstType];
|
||||
}
|
||||
}
|
||||
if (firstType === secondType && isPolymorphicItemType(firstType)) {
|
||||
return SINGLE_TO_POLYMORPHIC_MAP[firstType];
|
||||
} else if (schemaObject.enum) {
|
||||
return 'enum';
|
||||
} else if (schemaObject.type) {
|
||||
if (schemaObject.type === 'number') {
|
||||
// floats are "number" in OpenAPI, while ints are "integer" - we need to distinguish them
|
||||
return 'float';
|
||||
} else if (schemaObject.type === 'array') {
|
||||
const itemType = isSchemaObject(schemaObject.items)
|
||||
? schemaObject.items.type
|
||||
: refObjectToSchemaName(schemaObject.items);
|
||||
|
||||
if (isArray(itemType)) {
|
||||
// This is a nested array, which we don't support
|
||||
return;
|
||||
}
|
||||
|
||||
if (isCollectionItemType(itemType)) {
|
||||
return COLLECTION_MAP[itemType];
|
||||
}
|
||||
|
||||
return;
|
||||
} else if (!isArray(schemaObject.type)) {
|
||||
return schemaObject.type;
|
||||
}
|
||||
}
|
||||
} else if (schemaObject.enum) {
|
||||
return 'enum';
|
||||
} else if (schemaObject.type) {
|
||||
if (schemaObject.type === 'number') {
|
||||
// floats are "number" in OpenAPI, while ints are "integer" - we need to distinguish them
|
||||
return 'float';
|
||||
} else if (schemaObject.type === 'array') {
|
||||
const itemType = isSchemaObject(schemaObject.items)
|
||||
? schemaObject.items.type
|
||||
: refObjectToSchemaName(schemaObject.items);
|
||||
|
||||
if (isCollectionItemType(itemType)) {
|
||||
return COLLECTION_MAP[itemType];
|
||||
}
|
||||
|
||||
return;
|
||||
} else {
|
||||
return schemaObject.type;
|
||||
}
|
||||
} else if (isRefObject(schemaObject)) {
|
||||
return refObjectToSchemaName(schemaObject);
|
||||
}
|
||||
return;
|
||||
};
|
||||
@ -1025,7 +1079,15 @@ export const buildInputFieldTemplate = (
|
||||
name: string,
|
||||
fieldType: FieldType
|
||||
) => {
|
||||
const { input, ui_hidden, ui_component, ui_type, ui_order } = fieldSchema;
|
||||
const {
|
||||
input,
|
||||
ui_hidden,
|
||||
ui_component,
|
||||
ui_type,
|
||||
ui_order,
|
||||
ui_choice_labels,
|
||||
item_default,
|
||||
} = fieldSchema;
|
||||
|
||||
const extra = {
|
||||
// TODO: Can we support polymorphic inputs in the UI?
|
||||
@ -1035,11 +1097,13 @@ export const buildInputFieldTemplate = (
|
||||
ui_type,
|
||||
required: nodeSchema.required?.includes(name) ?? false,
|
||||
ui_order,
|
||||
ui_choice_labels,
|
||||
item_default,
|
||||
};
|
||||
|
||||
const baseField = {
|
||||
name,
|
||||
title: fieldSchema.title ?? '',
|
||||
title: fieldSchema.title ?? (name ? startCase(name) : ''),
|
||||
description: fieldSchema.description ?? '',
|
||||
fieldKind: 'input' as const,
|
||||
...extra,
|
||||
|
||||
@ -0,0 +1,247 @@
|
||||
import { RootState } from 'app/store/store';
|
||||
import { NonNullableGraph } from 'features/nodes/types/types';
|
||||
import {
|
||||
DenoiseLatentsInvocation,
|
||||
ResizeLatentsInvocation,
|
||||
NoiseInvocation,
|
||||
LatentsToImageInvocation,
|
||||
Edge,
|
||||
} from 'services/api/types';
|
||||
import {
|
||||
LATENTS_TO_IMAGE,
|
||||
DENOISE_LATENTS,
|
||||
NOISE,
|
||||
MAIN_MODEL_LOADER,
|
||||
METADATA_ACCUMULATOR,
|
||||
LATENTS_TO_IMAGE_HRF,
|
||||
DENOISE_LATENTS_HRF,
|
||||
RESCALE_LATENTS,
|
||||
NOISE_HRF,
|
||||
VAE_LOADER,
|
||||
} from './constants';
|
||||
import { logger } from 'app/logging/logger';
|
||||
|
||||
// Copy certain connections from previous DENOISE_LATENTS to new DENOISE_LATENTS_HRF.
|
||||
function copyConnectionsToDenoiseLatentsHrf(graph: NonNullableGraph): void {
|
||||
const destinationFields = [
|
||||
'vae',
|
||||
'control',
|
||||
'ip_adapter',
|
||||
'metadata',
|
||||
'unet',
|
||||
'positive_conditioning',
|
||||
'negative_conditioning',
|
||||
];
|
||||
const newEdges: Edge[] = [];
|
||||
|
||||
// Loop through the existing edges connected to DENOISE_LATENTS
|
||||
graph.edges.forEach((edge: Edge) => {
|
||||
if (
|
||||
edge.destination.node_id === DENOISE_LATENTS &&
|
||||
destinationFields.includes(edge.destination.field)
|
||||
) {
|
||||
// Add a similar connection to DENOISE_LATENTS_HRF
|
||||
newEdges.push({
|
||||
source: {
|
||||
node_id: edge.source.node_id,
|
||||
field: edge.source.field,
|
||||
},
|
||||
destination: {
|
||||
node_id: DENOISE_LATENTS_HRF,
|
||||
field: edge.destination.field,
|
||||
},
|
||||
});
|
||||
}
|
||||
});
|
||||
graph.edges = graph.edges.concat(newEdges);
|
||||
}
|
||||
|
||||
// Adds the high-res fix feature to the given graph.
|
||||
export const addHrfToGraph = (
|
||||
state: RootState,
|
||||
graph: NonNullableGraph
|
||||
): void => {
|
||||
// Double check hrf is enabled.
|
||||
if (
|
||||
!state.generation.hrfEnabled ||
|
||||
state.config.disabledSDFeatures.includes('hrf') ||
|
||||
state.generation.model?.model_type === 'onnx' // TODO: ONNX support
|
||||
) {
|
||||
return;
|
||||
}
|
||||
const log = logger('txt2img');
|
||||
|
||||
const { vae } = state.generation;
|
||||
const isAutoVae = !vae;
|
||||
const hrfWidth = state.generation.hrfWidth;
|
||||
const hrfHeight = state.generation.hrfHeight;
|
||||
|
||||
// Pre-existing (original) graph nodes.
|
||||
const originalDenoiseLatentsNode = graph.nodes[DENOISE_LATENTS] as
|
||||
| DenoiseLatentsInvocation
|
||||
| undefined;
|
||||
const originalNoiseNode = graph.nodes[NOISE] as NoiseInvocation | undefined;
|
||||
// Original latents to image should pick this up.
|
||||
const originalLatentsToImageNode = graph.nodes[LATENTS_TO_IMAGE] as
|
||||
| LatentsToImageInvocation
|
||||
| undefined;
|
||||
// Check if originalDenoiseLatentsNode is undefined and log an error
|
||||
if (!originalDenoiseLatentsNode) {
|
||||
log.error('originalDenoiseLatentsNode is undefined');
|
||||
return;
|
||||
}
|
||||
// Check if originalNoiseNode is undefined and log an error
|
||||
if (!originalNoiseNode) {
|
||||
log.error('originalNoiseNode is undefined');
|
||||
return;
|
||||
}
|
||||
|
||||
// Check if originalLatentsToImageNode is undefined and log an error
|
||||
if (!originalLatentsToImageNode) {
|
||||
log.error('originalLatentsToImageNode is undefined');
|
||||
return;
|
||||
}
|
||||
// Change height and width of original noise node to initial resolution.
|
||||
if (originalNoiseNode) {
|
||||
originalNoiseNode.width = hrfWidth;
|
||||
originalNoiseNode.height = hrfHeight;
|
||||
}
|
||||
|
||||
// Define new nodes.
|
||||
// Denoise latents node to be run on upscaled latents.
|
||||
const denoiseLatentsHrfNode: DenoiseLatentsInvocation = {
|
||||
type: 'denoise_latents',
|
||||
id: DENOISE_LATENTS_HRF,
|
||||
is_intermediate: originalDenoiseLatentsNode?.is_intermediate,
|
||||
cfg_scale: originalDenoiseLatentsNode?.cfg_scale,
|
||||
scheduler: originalDenoiseLatentsNode?.scheduler,
|
||||
steps: originalDenoiseLatentsNode?.steps,
|
||||
denoising_start: 1 - state.generation.hrfStrength,
|
||||
denoising_end: 1,
|
||||
};
|
||||
|
||||
// New base resolution noise node.
|
||||
const hrfNoiseNode: NoiseInvocation = {
|
||||
type: 'noise',
|
||||
id: NOISE_HRF,
|
||||
seed: originalNoiseNode?.seed,
|
||||
use_cpu: originalNoiseNode?.use_cpu,
|
||||
is_intermediate: originalNoiseNode?.is_intermediate,
|
||||
};
|
||||
|
||||
const rescaleLatentsNode: ResizeLatentsInvocation = {
|
||||
id: RESCALE_LATENTS,
|
||||
type: 'lresize',
|
||||
width: state.generation.width,
|
||||
height: state.generation.height,
|
||||
};
|
||||
|
||||
// New node to convert latents to image.
|
||||
const latentsToImageHrfNode: LatentsToImageInvocation | undefined =
|
||||
originalLatentsToImageNode
|
||||
? {
|
||||
type: 'l2i',
|
||||
id: LATENTS_TO_IMAGE_HRF,
|
||||
fp32: originalLatentsToImageNode?.fp32,
|
||||
is_intermediate: originalLatentsToImageNode?.is_intermediate,
|
||||
}
|
||||
: undefined;
|
||||
|
||||
// Add new nodes to graph.
|
||||
graph.nodes[LATENTS_TO_IMAGE_HRF] =
|
||||
latentsToImageHrfNode as LatentsToImageInvocation;
|
||||
graph.nodes[DENOISE_LATENTS_HRF] =
|
||||
denoiseLatentsHrfNode as DenoiseLatentsInvocation;
|
||||
graph.nodes[NOISE_HRF] = hrfNoiseNode as NoiseInvocation;
|
||||
graph.nodes[RESCALE_LATENTS] = rescaleLatentsNode as ResizeLatentsInvocation;
|
||||
|
||||
// Connect nodes.
|
||||
graph.edges.push(
|
||||
{
|
||||
// Set up rescale latents.
|
||||
source: {
|
||||
node_id: DENOISE_LATENTS,
|
||||
field: 'latents',
|
||||
},
|
||||
destination: {
|
||||
node_id: RESCALE_LATENTS,
|
||||
field: 'latents',
|
||||
},
|
||||
},
|
||||
// Set up new noise node
|
||||
{
|
||||
source: {
|
||||
node_id: RESCALE_LATENTS,
|
||||
field: 'height',
|
||||
},
|
||||
destination: {
|
||||
node_id: NOISE_HRF,
|
||||
field: 'height',
|
||||
},
|
||||
},
|
||||
{
|
||||
source: {
|
||||
node_id: RESCALE_LATENTS,
|
||||
field: 'width',
|
||||
},
|
||||
destination: {
|
||||
node_id: NOISE_HRF,
|
||||
field: 'width',
|
||||
},
|
||||
},
|
||||
// Set up new denoise node.
|
||||
{
|
||||
source: {
|
||||
node_id: RESCALE_LATENTS,
|
||||
field: 'latents',
|
||||
},
|
||||
destination: {
|
||||
node_id: DENOISE_LATENTS_HRF,
|
||||
field: 'latents',
|
||||
},
|
||||
},
|
||||
{
|
||||
source: {
|
||||
node_id: NOISE_HRF,
|
||||
field: 'noise',
|
||||
},
|
||||
destination: {
|
||||
node_id: DENOISE_LATENTS_HRF,
|
||||
field: 'noise',
|
||||
},
|
||||
},
|
||||
// Set up new latents to image node.
|
||||
{
|
||||
source: {
|
||||
node_id: DENOISE_LATENTS_HRF,
|
||||
field: 'latents',
|
||||
},
|
||||
destination: {
|
||||
node_id: LATENTS_TO_IMAGE_HRF,
|
||||
field: 'latents',
|
||||
},
|
||||
},
|
||||
{
|
||||
source: {
|
||||
node_id: METADATA_ACCUMULATOR,
|
||||
field: 'metadata',
|
||||
},
|
||||
destination: {
|
||||
node_id: LATENTS_TO_IMAGE_HRF,
|
||||
field: 'metadata',
|
||||
},
|
||||
},
|
||||
{
|
||||
source: {
|
||||
node_id: isAutoVae ? MAIN_MODEL_LOADER : VAE_LOADER,
|
||||
field: 'vae',
|
||||
},
|
||||
destination: {
|
||||
node_id: LATENTS_TO_IMAGE_HRF,
|
||||
field: 'vae',
|
||||
},
|
||||
}
|
||||
);
|
||||
|
||||
copyConnectionsToDenoiseLatentsHrf(graph);
|
||||
};
|
||||
@ -2,6 +2,7 @@ import { NonNullableGraph } from 'features/nodes/types/types';
|
||||
import {
|
||||
CANVAS_OUTPUT,
|
||||
LATENTS_TO_IMAGE,
|
||||
LATENTS_TO_IMAGE_HRF,
|
||||
METADATA_ACCUMULATOR,
|
||||
NSFW_CHECKER,
|
||||
SAVE_IMAGE,
|
||||
@ -82,6 +83,14 @@ export const addSaveImageNode = (
|
||||
},
|
||||
destination,
|
||||
});
|
||||
} else if (LATENTS_TO_IMAGE_HRF in graph.nodes) {
|
||||
graph.edges.push({
|
||||
source: {
|
||||
node_id: LATENTS_TO_IMAGE_HRF,
|
||||
field: 'image',
|
||||
},
|
||||
destination,
|
||||
});
|
||||
} else if (LATENTS_TO_IMAGE in graph.nodes) {
|
||||
graph.edges.push({
|
||||
source: {
|
||||
|
||||
@ -86,7 +86,7 @@ export const addT2IAdaptersToLinearGraph = (
|
||||
|
||||
graph.nodes[t2iAdapterNode.id] = t2iAdapterNode as T2IAdapterInvocation;
|
||||
|
||||
if (metadataAccumulator?.ipAdapters) {
|
||||
if (metadataAccumulator?.t2iAdapters) {
|
||||
// metadata accumulator only needs a control field - not the whole node
|
||||
// extract what we need and add to the accumulator
|
||||
const t2iAdapterField = omit(t2iAdapterNode, [
|
||||
|
||||
@ -6,6 +6,7 @@ import {
|
||||
ONNXTextToLatentsInvocation,
|
||||
} from 'services/api/types';
|
||||
import { addControlNetToLinearGraph } from './addControlNetToLinearGraph';
|
||||
import { addHrfToGraph } from './addHrfToGraph';
|
||||
import { addIPAdapterToLinearGraph } from './addIPAdapterToLinearGraph';
|
||||
import { addLoRAsToGraph } from './addLoRAsToGraph';
|
||||
import { addNSFWCheckerToGraph } from './addNSFWCheckerToGraph';
|
||||
@ -47,6 +48,10 @@ export const buildLinearTextToImageGraph = (
|
||||
seamlessXAxis,
|
||||
seamlessYAxis,
|
||||
seed,
|
||||
hrfWidth,
|
||||
hrfHeight,
|
||||
hrfStrength,
|
||||
hrfEnabled: hrfEnabled,
|
||||
} = state.generation;
|
||||
|
||||
const use_cpu = shouldUseCpuNoise;
|
||||
@ -254,6 +259,9 @@ export const buildLinearTextToImageGraph = (
|
||||
ipAdapters: [], // populated in addIPAdapterToLinearGraph
|
||||
t2iAdapters: [], // populated in addT2IAdapterToLinearGraph
|
||||
clip_skip: clipSkip,
|
||||
hrf_width: hrfEnabled ? hrfWidth : undefined,
|
||||
hrf_height: hrfEnabled ? hrfHeight : undefined,
|
||||
hrf_strength: hrfEnabled ? hrfStrength : undefined,
|
||||
};
|
||||
|
||||
graph.edges.push({
|
||||
@ -287,6 +295,12 @@ export const buildLinearTextToImageGraph = (
|
||||
|
||||
addT2IAdaptersToLinearGraph(state, graph, DENOISE_LATENTS);
|
||||
|
||||
// High resolution fix.
|
||||
// NOTE: Not supported for onnx models.
|
||||
if (state.generation.hrfEnabled && !isUsingOnnxModel) {
|
||||
addHrfToGraph(state, graph);
|
||||
}
|
||||
|
||||
// NSFW & watermark - must be last thing added to graph
|
||||
if (state.system.shouldUseNSFWChecker) {
|
||||
// must add before watermarker!
|
||||
|
||||
@ -2,11 +2,14 @@
|
||||
export const POSITIVE_CONDITIONING = 'positive_conditioning';
|
||||
export const NEGATIVE_CONDITIONING = 'negative_conditioning';
|
||||
export const DENOISE_LATENTS = 'denoise_latents';
|
||||
export const DENOISE_LATENTS_HRF = 'denoise_latents_hrf';
|
||||
export const LATENTS_TO_IMAGE = 'latents_to_image';
|
||||
export const LATENTS_TO_IMAGE_HRF = 'latents_to_image_hrf';
|
||||
export const SAVE_IMAGE = 'save_image';
|
||||
export const NSFW_CHECKER = 'nsfw_checker';
|
||||
export const WATERMARKER = 'invisible_watermark';
|
||||
export const NOISE = 'noise';
|
||||
export const NOISE_HRF = 'noise_hrf';
|
||||
export const RANDOM_INT = 'rand_int';
|
||||
export const RANGE_OF_SIZE = 'range_of_size';
|
||||
export const ITERATE = 'iterate';
|
||||
@ -18,6 +21,7 @@ export const CLIP_SKIP = 'clip_skip';
|
||||
export const IMAGE_TO_LATENTS = 'image_to_latents';
|
||||
export const LATENTS_TO_LATENTS = 'latents_to_latents';
|
||||
export const RESIZE = 'resize_image';
|
||||
export const RESCALE_LATENTS = 'rescale_latents';
|
||||
export const IMG2IMG_RESIZE = 'img2img_resize';
|
||||
export const CANVAS_OUTPUT = 'canvas_output';
|
||||
export const INPAINT_IMAGE = 'inpaint_image';
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
import { logger } from 'app/logging/logger';
|
||||
import { parseify } from 'common/util/serialize';
|
||||
import { reduce } from 'lodash-es';
|
||||
import { OpenAPIV3 } from 'openapi-types';
|
||||
import { reduce, startCase } from 'lodash-es';
|
||||
import { OpenAPIV3_1 } from 'openapi-types';
|
||||
import { AnyInvocationType } from 'services/events/types';
|
||||
import {
|
||||
FieldType,
|
||||
@ -60,7 +60,7 @@ const isNotInDenylist = (schema: InvocationSchemaObject) =>
|
||||
!invocationDenylist.includes(schema.properties.type.default);
|
||||
|
||||
export const parseSchema = (
|
||||
openAPI: OpenAPIV3.Document,
|
||||
openAPI: OpenAPIV3_1.Document,
|
||||
nodesAllowlistExtra: string[] | undefined = undefined,
|
||||
nodesDenylistExtra: string[] | undefined = undefined
|
||||
): Record<string, InvocationTemplate> => {
|
||||
@ -110,7 +110,7 @@ export const parseSchema = (
|
||||
return inputsAccumulator;
|
||||
}
|
||||
|
||||
const fieldType = getFieldType(property);
|
||||
const fieldType = property.ui_type ?? getFieldType(property);
|
||||
|
||||
if (!isFieldType(fieldType)) {
|
||||
logger('nodes').warn(
|
||||
@ -209,7 +209,7 @@ export const parseSchema = (
|
||||
return outputsAccumulator;
|
||||
}
|
||||
|
||||
const fieldType = getFieldType(property);
|
||||
const fieldType = property.ui_type ?? getFieldType(property);
|
||||
|
||||
if (!isFieldType(fieldType)) {
|
||||
logger('nodes').warn(
|
||||
@ -222,7 +222,8 @@ export const parseSchema = (
|
||||
outputsAccumulator[propertyName] = {
|
||||
fieldKind: 'output',
|
||||
name: propertyName,
|
||||
title: property.title ?? '',
|
||||
title:
|
||||
property.title ?? (propertyName ? startCase(propertyName) : ''),
|
||||
description: property.description ?? '',
|
||||
type: fieldType,
|
||||
ui_hidden: property.ui_hidden ?? false,
|
||||
|
||||
@ -0,0 +1,65 @@
|
||||
import { Flex } from '@chakra-ui/react';
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { RootState, stateSelector } from 'app/store/store';
|
||||
import { useAppSelector } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import IAICollapse from 'common/components/IAICollapse';
|
||||
import { useMemo } from 'react';
|
||||
import ParamHrfStrength from './ParamHrfStrength';
|
||||
import ParamHrfToggle from './ParamHrfToggle';
|
||||
import ParamHrfWidth from './ParamHrfWidth';
|
||||
import ParamHrfHeight from './ParamHrfHeight';
|
||||
import { useFeatureStatus } from 'features/system/hooks/useFeatureStatus';
|
||||
|
||||
const selector = createSelector(
|
||||
stateSelector,
|
||||
(state: RootState) => {
|
||||
const { hrfEnabled } = state.generation;
|
||||
|
||||
return { hrfEnabled };
|
||||
},
|
||||
defaultSelectorOptions
|
||||
);
|
||||
|
||||
export default function ParamHrfCollapse() {
|
||||
const isHRFFeatureEnabled = useFeatureStatus('hrf').isFeatureEnabled;
|
||||
const { hrfEnabled } = useAppSelector(selector);
|
||||
const activeLabel = useMemo(() => {
|
||||
if (hrfEnabled) {
|
||||
return 'On';
|
||||
} else {
|
||||
return 'Off';
|
||||
}
|
||||
}, [hrfEnabled]);
|
||||
|
||||
if (!isHRFFeatureEnabled) {
|
||||
return null;
|
||||
}
|
||||
|
||||
return (
|
||||
<IAICollapse label="High Resolution Fix" activeLabel={activeLabel}>
|
||||
<Flex sx={{ flexDir: 'column', gap: 2 }}>
|
||||
<ParamHrfToggle />
|
||||
{hrfEnabled && (
|
||||
<Flex
|
||||
sx={{
|
||||
gap: 2,
|
||||
p: 4,
|
||||
borderRadius: 4,
|
||||
flexDirection: 'column',
|
||||
w: 'full',
|
||||
bg: 'base.100',
|
||||
_dark: {
|
||||
bg: 'base.750',
|
||||
},
|
||||
}}
|
||||
>
|
||||
<ParamHrfWidth />
|
||||
<ParamHrfHeight />
|
||||
</Flex>
|
||||
)}
|
||||
{hrfEnabled && <ParamHrfStrength />}
|
||||
</Flex>
|
||||
</IAICollapse>
|
||||
);
|
||||
}
|
||||
@ -0,0 +1,87 @@
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import IAISlider, { IAIFullSliderProps } from 'common/components/IAISlider';
|
||||
import { roundToMultiple } from 'common/util/roundDownToMultiple';
|
||||
import {
|
||||
setHrfHeight,
|
||||
setHrfWidth,
|
||||
} from 'features/parameters/store/generationSlice';
|
||||
import { memo, useCallback } from 'react';
|
||||
|
||||
function findPrevMultipleOfEight(n: number): number {
|
||||
return Math.floor((n - 1) / 8) * 8;
|
||||
}
|
||||
|
||||
const selector = createSelector(
|
||||
[stateSelector],
|
||||
({ generation, hotkeys, config }) => {
|
||||
const { min, fineStep, coarseStep } = config.sd.height;
|
||||
const { model, height, hrfHeight, aspectRatio, hrfEnabled } = generation;
|
||||
|
||||
const step = hotkeys.shift ? fineStep : coarseStep;
|
||||
|
||||
return {
|
||||
model,
|
||||
height,
|
||||
hrfHeight,
|
||||
min,
|
||||
step,
|
||||
aspectRatio,
|
||||
hrfEnabled,
|
||||
};
|
||||
},
|
||||
defaultSelectorOptions
|
||||
);
|
||||
|
||||
type ParamHeightProps = Omit<
|
||||
IAIFullSliderProps,
|
||||
'label' | 'value' | 'onChange'
|
||||
>;
|
||||
|
||||
const ParamHrfHeight = (props: ParamHeightProps) => {
|
||||
const { height, hrfHeight, min, step, aspectRatio, hrfEnabled } =
|
||||
useAppSelector(selector);
|
||||
const dispatch = useAppDispatch();
|
||||
const maxHrfHeight = Math.max(findPrevMultipleOfEight(height), min);
|
||||
|
||||
const handleChange = useCallback(
|
||||
(v: number) => {
|
||||
dispatch(setHrfHeight(v));
|
||||
if (aspectRatio) {
|
||||
const newWidth = roundToMultiple(v * aspectRatio, 8);
|
||||
dispatch(setHrfWidth(newWidth));
|
||||
}
|
||||
},
|
||||
[dispatch, aspectRatio]
|
||||
);
|
||||
|
||||
const handleReset = useCallback(() => {
|
||||
dispatch(setHrfHeight(maxHrfHeight));
|
||||
if (aspectRatio) {
|
||||
const newWidth = roundToMultiple(maxHrfHeight * aspectRatio, 8);
|
||||
dispatch(setHrfWidth(newWidth));
|
||||
}
|
||||
}, [dispatch, maxHrfHeight, aspectRatio]);
|
||||
|
||||
return (
|
||||
<IAISlider
|
||||
label="Initial Height"
|
||||
value={hrfHeight}
|
||||
min={min}
|
||||
step={step}
|
||||
max={maxHrfHeight}
|
||||
onChange={handleChange}
|
||||
handleReset={handleReset}
|
||||
withInput
|
||||
withReset
|
||||
withSliderMarks
|
||||
sliderNumberInputProps={{ max: maxHrfHeight }}
|
||||
isDisabled={!hrfEnabled}
|
||||
{...props}
|
||||
/>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(ParamHrfHeight);
|
||||
@ -0,0 +1,64 @@
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { useAppSelector, useAppDispatch } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import { memo, useCallback } from 'react';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { setHrfStrength } from 'features/parameters/store/generationSlice';
|
||||
import IAISlider from 'common/components/IAISlider';
|
||||
|
||||
const selector = createSelector(
|
||||
[stateSelector],
|
||||
({ generation, hotkeys, config }) => {
|
||||
const { initial, min, sliderMax, inputMax, fineStep, coarseStep } =
|
||||
config.sd.hrfStrength;
|
||||
const { hrfStrength, hrfEnabled } = generation;
|
||||
const step = hotkeys.shift ? fineStep : coarseStep;
|
||||
|
||||
return {
|
||||
hrfStrength,
|
||||
initial,
|
||||
min,
|
||||
sliderMax,
|
||||
inputMax,
|
||||
step,
|
||||
hrfEnabled,
|
||||
};
|
||||
},
|
||||
defaultSelectorOptions
|
||||
);
|
||||
|
||||
const ParamHrfStrength = () => {
|
||||
const { hrfStrength, initial, min, sliderMax, step, hrfEnabled } =
|
||||
useAppSelector(selector);
|
||||
const dispatch = useAppDispatch();
|
||||
|
||||
const handleHrfStrengthReset = useCallback(() => {
|
||||
dispatch(setHrfStrength(initial));
|
||||
}, [dispatch, initial]);
|
||||
|
||||
const handleHrfStrengthChange = useCallback(
|
||||
(v: number) => {
|
||||
dispatch(setHrfStrength(v));
|
||||
},
|
||||
[dispatch]
|
||||
);
|
||||
|
||||
return (
|
||||
<IAISlider
|
||||
label="Denoising Strength"
|
||||
aria-label="High Resolution Denoising Strength"
|
||||
min={min}
|
||||
max={sliderMax}
|
||||
step={step}
|
||||
value={hrfStrength}
|
||||
onChange={handleHrfStrengthChange}
|
||||
withSliderMarks
|
||||
withInput
|
||||
withReset
|
||||
handleReset={handleHrfStrengthReset}
|
||||
isDisabled={!hrfEnabled}
|
||||
/>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(ParamHrfStrength);
|
||||
@ -0,0 +1,27 @@
|
||||
import { RootState } from 'app/store/store';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import IAISwitch from 'common/components/IAISwitch';
|
||||
import { setHrfEnabled } from 'features/parameters/store/generationSlice';
|
||||
import { ChangeEvent, useCallback } from 'react';
|
||||
|
||||
export default function ParamHrfToggle() {
|
||||
const dispatch = useAppDispatch();
|
||||
|
||||
const hrfEnabled = useAppSelector(
|
||||
(state: RootState) => state.generation.hrfEnabled
|
||||
);
|
||||
|
||||
const handleHrfEnabled = useCallback(
|
||||
(e: ChangeEvent<HTMLInputElement>) =>
|
||||
dispatch(setHrfEnabled(e.target.checked)),
|
||||
[dispatch]
|
||||
);
|
||||
|
||||
return (
|
||||
<IAISwitch
|
||||
label="Enable High Resolution Fix"
|
||||
isChecked={hrfEnabled}
|
||||
onChange={handleHrfEnabled}
|
||||
/>
|
||||
);
|
||||
}
|
||||
@ -0,0 +1,84 @@
|
||||
import { createSelector } from '@reduxjs/toolkit';
|
||||
import { stateSelector } from 'app/store/store';
|
||||
import { useAppDispatch, useAppSelector } from 'app/store/storeHooks';
|
||||
import { defaultSelectorOptions } from 'app/store/util/defaultMemoizeOptions';
|
||||
import IAISlider, { IAIFullSliderProps } from 'common/components/IAISlider';
|
||||
import { roundToMultiple } from 'common/util/roundDownToMultiple';
|
||||
import {
|
||||
setHrfHeight,
|
||||
setHrfWidth,
|
||||
} from 'features/parameters/store/generationSlice';
|
||||
import { memo, useCallback } from 'react';
|
||||
|
||||
function findPrevMultipleOfEight(n: number): number {
|
||||
return Math.floor((n - 1) / 8) * 8;
|
||||
}
|
||||
|
||||
const selector = createSelector(
|
||||
[stateSelector],
|
||||
({ generation, hotkeys, config }) => {
|
||||
const { min, fineStep, coarseStep } = config.sd.width;
|
||||
const { model, width, hrfWidth, aspectRatio, hrfEnabled } = generation;
|
||||
|
||||
const step = hotkeys.shift ? fineStep : coarseStep;
|
||||
|
||||
return {
|
||||
model,
|
||||
width,
|
||||
hrfWidth,
|
||||
min,
|
||||
step,
|
||||
aspectRatio,
|
||||
hrfEnabled,
|
||||
};
|
||||
},
|
||||
defaultSelectorOptions
|
||||
);
|
||||
|
||||
type ParamWidthProps = Omit<IAIFullSliderProps, 'label' | 'value' | 'onChange'>;
|
||||
|
||||
const ParamHrfWidth = (props: ParamWidthProps) => {
|
||||
const { width, hrfWidth, min, step, aspectRatio, hrfEnabled } =
|
||||
useAppSelector(selector);
|
||||
const dispatch = useAppDispatch();
|
||||
const maxHrfWidth = Math.max(findPrevMultipleOfEight(width), min);
|
||||
|
||||
const handleChange = useCallback(
|
||||
(v: number) => {
|
||||
dispatch(setHrfWidth(v));
|
||||
if (aspectRatio) {
|
||||
const newHeight = roundToMultiple(v / aspectRatio, 8);
|
||||
dispatch(setHrfHeight(newHeight));
|
||||
}
|
||||
},
|
||||
[dispatch, aspectRatio]
|
||||
);
|
||||
|
||||
const handleReset = useCallback(() => {
|
||||
dispatch(setHrfWidth(maxHrfWidth));
|
||||
if (aspectRatio) {
|
||||
const newHeight = roundToMultiple(maxHrfWidth / aspectRatio, 8);
|
||||
dispatch(setHrfHeight(newHeight));
|
||||
}
|
||||
}, [dispatch, maxHrfWidth, aspectRatio]);
|
||||
|
||||
return (
|
||||
<IAISlider
|
||||
label="Initial Width"
|
||||
value={hrfWidth}
|
||||
min={min}
|
||||
step={step}
|
||||
max={maxHrfWidth}
|
||||
onChange={handleChange}
|
||||
handleReset={handleReset}
|
||||
withInput
|
||||
withReset
|
||||
withSliderMarks
|
||||
sliderNumberInputProps={{ max: maxHrfWidth }}
|
||||
isDisabled={!hrfEnabled}
|
||||
{...props}
|
||||
/>
|
||||
);
|
||||
};
|
||||
|
||||
export default memo(ParamHrfWidth);
|
||||
@ -27,6 +27,10 @@ import {
|
||||
} from '../types/parameterSchemas';
|
||||
|
||||
export interface GenerationState {
|
||||
hrfHeight: HeightParam;
|
||||
hrfWidth: WidthParam;
|
||||
hrfEnabled: boolean;
|
||||
hrfStrength: StrengthParam;
|
||||
cfgScale: CfgScaleParam;
|
||||
height: HeightParam;
|
||||
img2imgStrength: StrengthParam;
|
||||
@ -69,6 +73,10 @@ export interface GenerationState {
|
||||
}
|
||||
|
||||
export const initialGenerationState: GenerationState = {
|
||||
hrfHeight: 64,
|
||||
hrfWidth: 64,
|
||||
hrfStrength: 0.75,
|
||||
hrfEnabled: false,
|
||||
cfgScale: 7.5,
|
||||
height: 512,
|
||||
img2imgStrength: 0.75,
|
||||
@ -271,6 +279,18 @@ export const generationSlice = createSlice({
|
||||
setClipSkip: (state, action: PayloadAction<number>) => {
|
||||
state.clipSkip = action.payload;
|
||||
},
|
||||
setHrfHeight: (state, action: PayloadAction<number>) => {
|
||||
state.hrfHeight = action.payload;
|
||||
},
|
||||
setHrfWidth: (state, action: PayloadAction<number>) => {
|
||||
state.hrfWidth = action.payload;
|
||||
},
|
||||
setHrfStrength: (state, action: PayloadAction<number>) => {
|
||||
state.hrfStrength = action.payload;
|
||||
},
|
||||
setHrfEnabled: (state, action: PayloadAction<boolean>) => {
|
||||
state.hrfEnabled = action.payload;
|
||||
},
|
||||
shouldUseCpuNoiseChanged: (state, action: PayloadAction<boolean>) => {
|
||||
state.shouldUseCpuNoise = action.payload;
|
||||
},
|
||||
@ -355,6 +375,10 @@ export const {
|
||||
setSeamlessXAxis,
|
||||
setSeamlessYAxis,
|
||||
setClipSkip,
|
||||
setHrfHeight,
|
||||
setHrfWidth,
|
||||
setHrfStrength,
|
||||
setHrfEnabled,
|
||||
shouldUseCpuNoiseChanged,
|
||||
setAspectRatio,
|
||||
setShouldLockAspectRatio,
|
||||
|
||||
@ -210,6 +210,15 @@ export type HeightParam = z.infer<typeof zHeight>;
|
||||
export const isValidHeight = (val: unknown): val is HeightParam =>
|
||||
zHeight.safeParse(val).success;
|
||||
|
||||
/**
|
||||
* Zod schema for resolution parameter
|
||||
*/
|
||||
export const zResolution = z.tuple([zWidth, zHeight]);
|
||||
/**
|
||||
* Type alias for resolution parameter, inferred from its zod schema
|
||||
*/
|
||||
export type ResolutionParam = z.infer<typeof zResolution>;
|
||||
|
||||
export const zBaseModel = z.enum([
|
||||
'any',
|
||||
'sd-1',
|
||||
|
||||
@ -7,7 +7,7 @@ const QueueItemCard = ({
|
||||
session_queue_item,
|
||||
label,
|
||||
}: {
|
||||
session_queue_item?: components['schemas']['SessionQueueItem'];
|
||||
session_queue_item?: components['schemas']['SessionQueueItem'] | null;
|
||||
label: string;
|
||||
}) => {
|
||||
return (
|
||||
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user