mirror of
https://github.com/invoke-ai/InvokeAI
synced 2024-08-30 20:32:17 +00:00
Compare commits
418 Commits
feat/nodes
...
feat/restr
| Author | SHA1 | Date | |
|---|---|---|---|
| 09609cd553 | |||
| 0aedd6d9f0 | |||
| 70a1202deb | |||
| 9a1aea9caf | |||
| 388d36b839 | |||
| bedb35af8c | |||
| dc232438fb | |||
| d7edf5aaad | |||
| 3ad1226d1e | |||
| 86ca9f122d | |||
| 2c6772f92f | |||
| e6c1e03b8b | |||
| c9d95e5758 | |||
| 10755718b8 | |||
| 459c7b3b74 | |||
| 353719f81d | |||
| bd4b260c23 | |||
| 3e389d3f60 | |||
| ffb01f1345 | |||
| faa0a8236c | |||
| e4d73d3659 | |||
| 6994783c17 | |||
| 3f9708f166 | |||
| bcf0d8a590 | |||
| 2060ee22f2 | |||
| 3fd79b837f | |||
| 1c099e0abb | |||
| 95cca9493c | |||
| 779c902402 | |||
| 99e6bb48ba | |||
| c3d6ff5b11 | |||
| bba962b82f | |||
| 78b8cfede3 | |||
| e9879b9e1f | |||
| e21f3af5ab | |||
| 2ab7c5f783 | |||
| 8bbd938be9 | |||
| b4cee46936 | |||
| 48626c40fd | |||
| a1001b6d10 | |||
| 50df641e1b | |||
| 22dd64dfa4 | |||
| 0a929ca3de | |||
| 8c61cda4b8 | |||
| 75663ec81e | |||
| 40a568c060 | |||
| 8e7aa74a16 | |||
| fcba4382b2 | |||
| bf9f7271dd | |||
| d3821594df | |||
| 631ad1596f | |||
| dfe32e467d | |||
| 3575cf3b3b | |||
| 15cabc4968 | |||
| 29c3f49182 | |||
| 21d5969942 | |||
| 334dcf71c4 | |||
| d2149a8380 | |||
| 6532d9ffa1 | |||
| 52274087f3 | |||
| 89db8c83c2 | |||
| fc09ab7e13 | |||
| 9646157ad5 | |||
| b89ec2b9c3 | |||
| d2fb29cf0d | |||
| d1fce4b70b | |||
| f50f95a81d | |||
| 3611029057 | |||
| 402cf9b0ee | |||
| 88bee96ca3 | |||
| 5048fc7c9e | |||
| 2a35d93a4d | |||
| 10fac5c085 | |||
| 58850ded22 | |||
| f21ebdfaca | |||
| c4f1e94cc4 | |||
| dbbcce9f70 | |||
| cc52896bd9 | |||
| d12314fb8b | |||
| 07b88e3017 | |||
| 0b85f2487c | |||
| 5530d3fcd2 | |||
| 7b1b24900f | |||
| f52fb45276 | |||
| fb9f0339a2 | |||
| ac501ee742 | |||
| 2182ccf8d1 | |||
| fc674ff1b8 | |||
| 708ac6a511 | |||
| d0e0b64fc8 | |||
| a23580664d | |||
| 0edf01d927 | |||
| 4af5b9cbf7 | |||
| 1bf973d46e | |||
| 72252e3ff7 | |||
| 8d2596c288 | |||
| 0ffb7ecaa8 | |||
| 10f30fc599 | |||
| 136570aa1d | |||
| 5a30b507e0 | |||
| d47fbf283c | |||
| 7c24312d3f | |||
| 905cd8c639 | |||
| b13ba55c26 | |||
| 82747e2260 | |||
| 910553f49a | |||
| faabd83717 | |||
| 5ad77ece4b | |||
| 6b3c413a5b | |||
| 2a923d1f69 | |||
| c54a5ce10e | |||
| 14fbe41834 | |||
| 64ebe042b5 | |||
| 5b2ed4ffb4 | |||
| a49b8febed | |||
| e543db5a5d | |||
| 670f3aa165 | |||
| c0534d6519 | |||
| 7bc6c23dfa | |||
| 851ce36250 | |||
| d631088566 | |||
| f0bf733309 | |||
| 65af7dd8f8 | |||
| 74c666aaa2 | |||
| 45f9aca7e5 | |||
| 9fb624f390 | |||
| 962e51320b | |||
| 44932923eb | |||
| ffcf6dfde6 | |||
| be52eb153c | |||
| bd97c6b708 | |||
| 9940cbfa87 | |||
| 77aeb9a421 | |||
| 2bad8b9f29 | |||
| 8e943b2ce1 | |||
| 5d3ab4f333 | |||
| 1047d08835 | |||
| 516cc258f9 | |||
| 7c2aa1dc20 | |||
| 035f1e12e1 | |||
| 4c93202ee4 | |||
| 227046bdb0 | |||
| 83b123f1f6 | |||
| 320ef15ee9 | |||
| 6905c61912 | |||
| 494bde785e | |||
| 732ab38ca6 | |||
| ba38aa56a5 | |||
| 0a48c5a712 | |||
| 133ab91c8d | |||
| 7a672bd2b2 | |||
| 7dee6f51a3 | |||
| 3c029eee29 | |||
| 1a8f9d1ecb | |||
| 80d329c900 | |||
| 89db749d89 | |||
| 18164fc72a | |||
| 75de20af6a | |||
| cb1509bf52 | |||
| 10cd814cf7 | |||
| 8ef38ecc7c | |||
| 69937d68d2 | |||
| 40f9e49b5e | |||
| 98fa234529 | |||
| fe889235cc | |||
| 462c1d4c9b | |||
| 0ed36158c8 | |||
| f3c138a208 | |||
| 61242bf86a | |||
| d118d02df4 | |||
| 58b56e9b1e | |||
| 1f751f8c21 | |||
| ca95a3bd0d | |||
| 55b40a9425 | |||
| 90083cc88d | |||
| ead754432a | |||
| fa9ea93477 | |||
| fe0cf2c160 | |||
| a681fa4b03 | |||
| 1cc686734b | |||
| 82e8b92ba0 | |||
| e86658f864 | |||
| ad136c2680 | |||
| 35374ec531 | |||
| ed82bf6bb8 | |||
| 078c9b6964 | |||
| 1a9d2f1701 | |||
| 3e93159bce | |||
| b57ebe52e4 | |||
| ba4616ff89 | |||
| dcfbd49e1b | |||
| 913fc83cbf | |||
| 6b8ce34eb3 | |||
| 9508e0c9db | |||
| 9c720da021 | |||
| e1b576c72d | |||
| 971ccfb081 | |||
| 43a3c3c7ea | |||
| 4df1cdb34d | |||
| 3f860c3523 | |||
| d8d0c9af09 | |||
| 9403672ac0 | |||
| 94591840a7 | |||
| 26b91a538a | |||
| 7ca456d674 | |||
| 78828b6b9c | |||
| 166ff9d301 | |||
| 4f97bd4418 | |||
| e0e001758a | |||
| c1887135b3 | |||
| 096d195d6e | |||
| 7870b90717 | |||
| 9854b244fd | |||
| 7d800e1ce3 | |||
| 1c8b1fbc53 | |||
| 594a3aef93 | |||
| 78377469db | |||
| fbe6452c45 | |||
| 3f4ea073d1 | |||
| 8b7f8eaea2 | |||
| 88e16ce051 | |||
| 421440cae0 | |||
| 421021cede | |||
| 020d4302d1 | |||
| 8c59d2e5af | |||
| 17d451eaa7 | |||
| 23a06fd06d | |||
| 010c8e8038 | |||
| dfc635223c | |||
| 37121a3a24 | |||
| 51b5de799a | |||
| eadbe6abf7 | |||
| 16f48a816f | |||
| 95838e5559 | |||
| 3e8d62b1d1 | |||
| 2acc93eb8e | |||
| fbb61f2334 | |||
| be85c7972b | |||
| 3a586fc9c4 | |||
| dedead672f | |||
| 67366921c0 | |||
| 5a1019d858 | |||
| f4ba7be918 | |||
| 069d8b5812 | |||
| 24d73d484a | |||
| 2479a59e5e | |||
| 7d0ac2c36d | |||
| 519b892f0c | |||
| 763dcacfd3 | |||
| 3599d546e6 | |||
| 22a84930f6 | |||
| d64e17e043 | |||
| ba54277011 | |||
| 5915a4a51c | |||
| 4580ba0d87 | |||
| b9fd2e9e76 | |||
| 75b65597af | |||
| 2a3c0ab5d2 | |||
| 7d61373b82 | |||
| 7d65555a5a | |||
| 123f2b2dbc | |||
| 1e4e42556e | |||
| 1f6699ac43 | |||
| ace8665411 | |||
| 7fa5bae8fd | |||
| f9faca7c91 | |||
| 594fd3ba6d | |||
| 44d68f5ed5 | |||
| 4bda7d7df5 | |||
| 920c5dd686 | |||
| 4ce00a32f4 | |||
| dcbb25dfea | |||
| 6c8270dae2 | |||
| b19572199f | |||
| a673c0aa14 | |||
| 955ef3bc54 | |||
| f002ae8da5 | |||
| 208bf68ba2 | |||
| 1aba369c83 | |||
| 9ac11e793c | |||
| 9b39888e2f | |||
| c1715144f0 | |||
| 929557bc6f | |||
| 811dd93912 | |||
| 9a60dbd5cb | |||
| 637c5b0747 | |||
| 27164de8b8 | |||
| 08e40d6d16 | |||
| d905c54795 | |||
| dc1e804887 | |||
| 95fd2ee6ff | |||
| 5f4eb0c3b3 | |||
| d464ce509b | |||
| 3909e68527 | |||
| 848e51f72b | |||
| 52f8c9e16f | |||
| 5174f382b9 | |||
| c7f80cd163 | |||
| 309e2414ce | |||
| 6704f77d87 | |||
| 045d3f6139 | |||
| a0bd8c638e | |||
| de04a5f441 | |||
| 40ed218c26 | |||
| 807c6b41c5 | |||
| f6bbcd0589 | |||
| ada22a799e | |||
| a42ef9c855 | |||
| 034af2d9f8 | |||
| 676ccd8ebb | |||
| a263a4f4cc | |||
| ef0754cdec | |||
| 8158124679 | |||
| 5d31df0cb7 | |||
| bd63454e51 | |||
| 062df07de2 | |||
| 0fc14afcf0 | |||
| 4a0a1c30db | |||
| 3432fd72f8 | |||
| 05a43c41f9 | |||
| bb48617101 | |||
| aa2f68f608 | |||
| fbccce7573 | |||
| a35087ee6e | |||
| 03e463dc89 | |||
| d467e138a4 | |||
| ba4aaea45b | |||
| 53eb23b8b6 | |||
| 8b969053e7 | |||
| 98a076260b | |||
| 164877b610 | |||
| b3f4f28d76 | |||
| acee4bd282 | |||
| fc9a7320eb | |||
| 7c0a083b13 | |||
| 50d254fdb7 | |||
| 0cfc1c5f86 | |||
| f35dfa06bb | |||
| 407bca5063 | |||
| 1419977e89 | |||
| a953944894 | |||
| a4cdaa245e | |||
| 105a4234b0 | |||
| 34c563060f | |||
| d45c47db81 | |||
| c771a4027f | |||
| 3fd27b1aa9 | |||
| d59e534cad | |||
| 0c97a1e7e7 | |||
| c8b306d9f8 | |||
| edd2c54b9e | |||
| 727cc0dafe | |||
| 4530bd46dc | |||
| c8b109f52e | |||
| a2613948d8 | |||
| f8392b2f78 | |||
| 358116bc22 | |||
| 1e3590111d | |||
| 063b800280 | |||
| 3935bf92c8 | |||
| 066e09b517 | |||
| 869b4a8d49 | |||
| 399ebe443e | |||
| 13919ff300 | |||
| 634e5652ef | |||
| 9bdc718df5 | |||
| 73ca8ccdb3 | |||
| f37ffda966 | |||
| 5a9777d443 | |||
| 8072c05ee0 | |||
| 75ff4f4ca3 | |||
| 30df123221 | |||
| 06193ddbe8 | |||
| ce5122f87c | |||
| 43ebd68313 | |||
| ec19fcafb1 | |||
| 6fcc7d4c4b | |||
| 912087e4dc | |||
| 593fb95213 | |||
| 6d821b32d3 | |||
| 297f96c16b | |||
| 0e53b27655 | |||
| 35ae9f6e71 | |||
| a1d9e6b871 | |||
| f05379f965 | |||
| e34e6d6e80 | |||
| 86cb53342a | |||
| e3de996525 | |||
| 25a71a1791 | |||
| d16583ad1c | |||
| 46db1dd18f | |||
| 4c9344b0ee | |||
| cba31efd78 | |||
| 4d01b5c0f2 | |||
| e02af8f518 | |||
| c485cf568b | |||
| 51451cbf21 | |||
| 0363a06963 | |||
| cc280cbef1 | |||
| 7544eadd48 | |||
| 7d683b4db6 | |||
| 60b3c6a201 | |||
| 88c8cb61f0 | |||
| 43fbac26df | |||
| 627444e17c | |||
| 5601858f4f | |||
| b5e1ba34b3 | |||
| 58aa159a50 | |||
| d8f7c19030 | |||
| 24132a7950 | |||
| 45d172d5a8 | |||
| 3cb6d333f6 | |||
| 4570702dd0 | |||
| 1d107f30e5 | |||
| 79084e9e20 | |||
| fc9b4539a3 | |||
| 09ef57718e | |||
| cab8239ba8 |
2
.github/workflows/pypi-release.yml
vendored
2
.github/workflows/pypi-release.yml
vendored
@ -28,7 +28,7 @@ jobs:
|
||||
run: twine check dist/*
|
||||
|
||||
- name: check PyPI versions
|
||||
if: github.ref == 'refs/heads/main' || github.ref == 'refs/heads/v2.3'
|
||||
if: github.ref == 'refs/heads/main' || startsWith(github.ref, 'refs/heads/release/')
|
||||
run: |
|
||||
pip install --upgrade requests
|
||||
python -c "\
|
||||
|
||||
@ -47,34 +47,9 @@ pip install ".[dev,test]"
|
||||
These are optional groups of packages which are defined within the `pyproject.toml`
|
||||
and will be required for testing the changes you make to the code.
|
||||
|
||||
### Running Tests
|
||||
|
||||
We use [pytest](https://docs.pytest.org/en/7.2.x/) for our test suite. Tests can
|
||||
be found under the `./tests` folder and can be run with a single `pytest`
|
||||
command. Optionally, to review test coverage you can append `--cov`.
|
||||
|
||||
```zsh
|
||||
pytest --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition a more
|
||||
detailed report is created in both XML and HTML format in the `./coverage`
|
||||
folder. The HTML one in particular can help identify missing statements
|
||||
requiring tests to ensure coverage. This can be run by opening
|
||||
`./coverage/html/index.html`.
|
||||
|
||||
For example.
|
||||
|
||||
```zsh
|
||||
pytest --cov; open ./coverage/html/index.html
|
||||
```
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
### Tests
|
||||
|
||||
See the [tests documentation](./TESTS.md) for information about running and writing tests.
|
||||
### Reloading Changes
|
||||
|
||||
Experimenting with changes to the Python source code is a drag if you have to re-start the server —
|
||||
@ -167,6 +142,23 @@ and so you'll have access to the same python environment as the InvokeAI app.
|
||||
|
||||
This is _super_ handy.
|
||||
|
||||
#### Enabling Type-Checking with Pylance
|
||||
|
||||
We use python's typing system in InvokeAI. PR reviews will include checking that types are present and correct. We don't enforce types with `mypy` at this time, but that is on the horizon.
|
||||
|
||||
Using a code analysis tool to automatically type check your code (and types) is very important when writing with types. These tools provide immediate feedback in your editor when types are incorrect, and following their suggestions lead to fewer runtime bugs.
|
||||
|
||||
Pylance, installed at the beginning of this guide, is the de-facto python LSP (language server protocol). It provides type checking in the editor (among many other features). Once installed, you do need to enable type checking manually:
|
||||
|
||||
- Open a python file
|
||||
- Look along the status bar in VSCode for `{ } Python`
|
||||
- Click the `{ }`
|
||||
- Turn type checking on - basic is fine
|
||||
|
||||
You'll now see red squiggly lines where type issues are detected. Hover your cursor over the indicated symbols to see what's wrong.
|
||||
|
||||
In 99% of cases when the type checker says there is a problem, there really is a problem, and you should take some time to understand and resolve what it is pointing out.
|
||||
|
||||
#### Debugging configs with `launch.json`
|
||||
|
||||
Debugging configs are managed in a `launch.json` file. Like most VSCode configs,
|
||||
|
||||
89
docs/contributing/TESTS.md
Normal file
89
docs/contributing/TESTS.md
Normal file
@ -0,0 +1,89 @@
|
||||
# InvokeAI Backend Tests
|
||||
|
||||
We use `pytest` to run the backend python tests. (See [pyproject.toml](/pyproject.toml) for the default `pytest` options.)
|
||||
|
||||
## Fast vs. Slow
|
||||
All tests are categorized as either 'fast' (no test annotation) or 'slow' (annotated with the `@pytest.mark.slow` decorator).
|
||||
|
||||
'Fast' tests are run to validate every PR, and are fast enough that they can be run routinely during development.
|
||||
|
||||
'Slow' tests are currently only run manually on an ad-hoc basis. In the future, they may be automated to run nightly. Most developers are only expected to run the 'slow' tests that directly relate to the feature(s) that they are working on.
|
||||
|
||||
As a rule of thumb, tests should be marked as 'slow' if there is a chance that they take >1s (e.g. on a CPU-only machine with slow internet connection). Common examples of slow tests are tests that depend on downloading a model, or running model inference.
|
||||
|
||||
## Running Tests
|
||||
|
||||
Below are some common test commands:
|
||||
```bash
|
||||
# Run the fast tests. (This implicitly uses the configured default option: `-m "not slow"`.)
|
||||
pytest tests/
|
||||
|
||||
# Equivalent command to run the fast tests.
|
||||
pytest tests/ -m "not slow"
|
||||
|
||||
# Run the slow tests.
|
||||
pytest tests/ -m "slow"
|
||||
|
||||
# Run the slow tests from a specific file.
|
||||
pytest tests/path/to/slow_test.py -m "slow"
|
||||
|
||||
# Run all tests (fast and slow).
|
||||
pytest tests -m ""
|
||||
```
|
||||
|
||||
## Test Organization
|
||||
|
||||
All backend tests are in the [`tests/`](/tests/) directory. This directory mirrors the organization of the `invokeai/` directory. For example, tests for `invokeai/model_management/model_manager.py` would be found in `tests/model_management/test_model_manager.py`.
|
||||
|
||||
TODO: The above statement is aspirational. A re-organization of legacy tests is required to make it true.
|
||||
|
||||
## Tests that depend on models
|
||||
|
||||
There are a few things to keep in mind when adding tests that depend on models.
|
||||
|
||||
1. If a required model is not already present, it should automatically be downloaded as part of the test setup.
|
||||
2. If a model is already downloaded, it should not be re-downloaded unnecessarily.
|
||||
3. Take reasonable care to keep the total number of models required for the tests low. Whenever possible, re-use models that are already required for other tests. If you are adding a new model, consider including a comment to explain why it is required/unique.
|
||||
|
||||
There are several utilities to help with model setup for tests. Here is a sample test that depends on a model:
|
||||
```python
|
||||
import pytest
|
||||
import torch
|
||||
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.util.test_utils import install_and_load_model
|
||||
|
||||
@pytest.mark.slow
|
||||
def test_model(model_installer, torch_device):
|
||||
model_info = install_and_load_model(
|
||||
model_installer=model_installer,
|
||||
model_path_id_or_url="HF/dummy_model_id",
|
||||
model_name="dummy_model",
|
||||
base_model=BaseModelType.StableDiffusion1,
|
||||
model_type=ModelType.Dummy,
|
||||
)
|
||||
|
||||
dummy_input = build_dummy_input(torch_device)
|
||||
|
||||
with torch.no_grad(), model_info as model:
|
||||
model.to(torch_device, dtype=torch.float32)
|
||||
output = model(dummy_input)
|
||||
|
||||
# Validate output...
|
||||
|
||||
```
|
||||
|
||||
## Test Coverage
|
||||
|
||||
To review test coverage, append `--cov` to your pytest command:
|
||||
```bash
|
||||
pytest tests/ --cov
|
||||
```
|
||||
|
||||
Test outcomes and coverage will be reported in the terminal. In addition, a more detailed report is created in both XML and HTML format in the `./coverage` folder. The HTML output is particularly helpful in identifying untested statements where coverage should be improved. The HTML report can be viewed by opening `./coverage/html/index.html`.
|
||||
|
||||
??? info "HTML coverage report output"
|
||||
|
||||

|
||||
|
||||

|
||||
@ -12,7 +12,7 @@ To get started, take a look at our [new contributors checklist](newContributorCh
|
||||
Once you're setup, for more information, you can review the documentation specific to your area of interest:
|
||||
|
||||
* #### [InvokeAI Architecure](../ARCHITECTURE.md)
|
||||
* #### [Frontend Documentation](development_guides/contributingToFrontend.md)
|
||||
* #### [Frontend Documentation](./contributingToFrontend.md)
|
||||
* #### [Node Documentation](../INVOCATIONS.md)
|
||||
* #### [Local Development](../LOCAL_DEVELOPMENT.md)
|
||||
|
||||
@ -38,9 +38,9 @@ There are two paths to making a development contribution:
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
|
||||
For frontend related work, **@pyschedelicious** is the best person to reach out to.
|
||||
For frontend related work, **@psychedelicious** is the best person to reach out to.
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@psychedelicious**.
|
||||
|
||||
|
||||
## **What does the Code of Conduct mean for me?**
|
||||
|
||||
@ -10,4 +10,4 @@ When updating or creating documentation, please keep in mind InvokeAI is a tool
|
||||
|
||||
## Help & Questions
|
||||
|
||||
Please ping @imic1 or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
Please ping @imic or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
|
||||
@ -1,13 +1,11 @@
|
||||
---
|
||||
title: ControlNet
|
||||
title: Control Adapters
|
||||
---
|
||||
|
||||
# :material-loupe: ControlNet
|
||||
# :material-loupe: Control Adapters
|
||||
|
||||
## ControlNet
|
||||
|
||||
ControlNet
|
||||
|
||||
ControlNet is a powerful set of features developed by the open-source
|
||||
community (notably, Stanford researcher
|
||||
[**@ilyasviel**](https://github.com/lllyasviel)) that allows you to
|
||||
@ -20,7 +18,7 @@ towards generating images that better fit your desired style or
|
||||
outcome.
|
||||
|
||||
|
||||
### How it works
|
||||
#### How it works
|
||||
|
||||
ControlNet works by analyzing an input image, pre-processing that
|
||||
image to identify relevant information that can be interpreted by each
|
||||
@ -30,7 +28,7 @@ composition, or other aspects of the image to better achieve a
|
||||
specific result.
|
||||
|
||||
|
||||
### Models
|
||||
#### Models
|
||||
|
||||
InvokeAI provides access to a series of ControlNet models that provide
|
||||
different effects or styles in your generated images. Currently
|
||||
@ -96,6 +94,8 @@ A model that generates normal maps from input images, allowing for more realisti
|
||||
**Image Segmentation**:
|
||||
A model that divides input images into segments or regions, each of which corresponds to a different object or part of the image. (More details coming soon)
|
||||
|
||||
**QR Code Monster**:
|
||||
A model that helps generate creative QR codes that still scan. Can also be used to create images with text, logos or shapes within them.
|
||||
|
||||
**Openpose**:
|
||||
The OpenPose control model allows for the identification of the general pose of a character by pre-processing an existing image with a clear human structure. With advanced options, Openpose can also detect the face or hands in the image.
|
||||
@ -120,7 +120,7 @@ With Pix2Pix, you can input an image into the controlnet, and then "instruct" th
|
||||
Each of these models can be adjusted and combined with other ControlNet models to achieve different results, giving you even more control over your image generation process.
|
||||
|
||||
|
||||
## Using ControlNet
|
||||
### Using ControlNet
|
||||
|
||||
To use ControlNet, you can simply select the desired model and adjust both the ControlNet and Pre-processor settings to achieve the desired result. You can also use multiple ControlNet models at the same time, allowing you to achieve even more complex effects or styles in your generated images.
|
||||
|
||||
@ -132,3 +132,31 @@ Weight - Strength of the Controlnet model applied to the generation for the sect
|
||||
Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the ControlNet applied.
|
||||
|
||||
Additionally, each ControlNet section can be expanded in order to manipulate settings for the image pre-processor that adjusts your uploaded image before using it in when you Invoke.
|
||||
|
||||
|
||||
## IP-Adapter
|
||||
|
||||
[IP-Adapter](https://ip-adapter.github.io) is a tooling that allows for image prompt capabilities with text-to-image diffusion models. IP-Adapter works by analyzing the given image prompt to extract features, then passing those features to the UNet along with any other conditioning provided.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
#### Installation
|
||||
There are several ways to install IP-Adapter models with an existing InvokeAI installation:
|
||||
|
||||
1. Through the command line interface launched from the invoke.sh / invoke.bat scripts, option [5] to download models.
|
||||
2. Through the Model Manager UI with models from the *Tools* section of [www.models.invoke.ai](www.models.invoke.ai). To do this, copy the repo ID from the desired model page, and paste it in the Add Model field of the model manager. **Note** Both the IP-Adapter and the Image Encoder must be installed for IP-Adapter to work. For example, the [SD 1.5 IP-Adapter](https://models.invoke.ai/InvokeAI/ip_adapter_plus_sd15) and [SD1.5 Image Encoder](https://models.invoke.ai/InvokeAI/ip_adapter_sd_image_encoder) must be installed to use IP-Adapter with SD1.5 based models.
|
||||
3. **Advanced -- Not recommended ** Manually downloading the IP-Adapter and Image Encoder files - Image Encoder folders shouid be placed in the `models\any\clip_vision` folders. IP Adapter Model folders should be placed in the relevant `ip-adapter` folder of relevant base model folder of Invoke root directory. For example, for the SDXL IP-Adapter, files should be added to the `model/sdxl/ip_adapter/` folder.
|
||||
|
||||
#### Using IP-Adapter
|
||||
|
||||
IP-Adapter can be used by navigating to the *Control Adapters* options and enabling IP-Adapter.
|
||||
|
||||
IP-Adapter requires an image to be used as the Image Prompt. It can also be used in conjunction with text prompts, Image-to-Image, Inpainting, Outpainting, ControlNets and LoRAs.
|
||||
|
||||
|
||||
Each IP-Adapter has two settings that are applied to the IP-Adapter:
|
||||
|
||||
* Weight - Strength of the IP-Adapter model applied to the generation for the section, defined by start/end
|
||||
* Start/End - 0 represents the start of the generation, 1 represents the end. The Start/end setting controls what steps during the generation process have the IP-Adapter applied.
|
||||
|
||||
@ -256,6 +256,10 @@ manager, please follow these steps:
|
||||
*highly recommended** if your virtual environment is located outside of
|
||||
your runtime directory.
|
||||
|
||||
!!! tip
|
||||
|
||||
On linux, it is recommended to run invokeai with the following env var: `MALLOC_MMAP_THRESHOLD_=1048576`. For example: `MALLOC_MMAP_THRESHOLD_=1048576 invokeai --web`. This helps to prevent memory fragmentation that can lead to memory accumulation over time. This env var is set automatically when running via `invoke.sh`.
|
||||
|
||||
10. Render away!
|
||||
|
||||
Browse the [features](../features/index.md) section to learn about all the
|
||||
@ -296,8 +300,18 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
You will also need to install the [frontend development toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md).
|
||||
|
||||
If you have a "normal" installation, you should create a totally separate virtual environment for the git-based installation, else the two may interfere.
|
||||
|
||||
> **Why do I need the frontend toolchain**?
|
||||
>
|
||||
> The InvokeAI project uses trunk-based development. That means our `main` branch is the development branch, and releases are tags on that branch. Because development is very active, we don't keep an updated build of the UI in `main` - we only build it for production releases.
|
||||
>
|
||||
> That means that between releases, to have a functioning application when running directly from the repo, you will need to run the UI in dev mode or build it regularly (any time the UI code changes).
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
2. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
@ -305,10 +319,10 @@ Guide](https://github.com/git-guides/install-git)
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
3. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
3. Enter the InvokeAI repository directory and run one of these
|
||||
4. Enter the InvokeAI repository directory and run one of these
|
||||
commands, based on your GPU:
|
||||
|
||||
=== "CUDA (NVidia)"
|
||||
@ -334,11 +348,15 @@ installation protocol (important!)
|
||||
Be sure to pass `-e` (for an editable install) and don't forget the
|
||||
dot ("."). It is part of the command.
|
||||
|
||||
You can now run `invokeai` and its related commands. The code will be
|
||||
5. Install the [frontend toolchain](https://github.com/invoke-ai/InvokeAI/blob/main/docs/contributing/contribution_guides/contributingToFrontend.md) and do a production build of the UI as described.
|
||||
|
||||
6. You can now run `invokeai` and its related commands. The code will be
|
||||
read from the repository, so that you can edit the .py source files
|
||||
and watch the code's behavior change.
|
||||
|
||||
4. If you wish to contribute to the InvokeAI project, you are
|
||||
When you pull in new changes to the repo, be sure to re-build the UI.
|
||||
|
||||
7. If you wish to contribute to the InvokeAI project, you are
|
||||
encouraged to establish a GitHub account and "fork"
|
||||
https://github.com/invoke-ai/InvokeAI into your own copy of the
|
||||
repository. You can then use GitHub functions to create and submit
|
||||
|
||||
@ -171,3 +171,16 @@ subfolders and organize them as you wish.
|
||||
|
||||
The location of the autoimport directories are controlled by settings
|
||||
in `invokeai.yaml`. See [Configuration](../features/CONFIGURATION.md).
|
||||
|
||||
### Installing models that live in HuggingFace subfolders
|
||||
|
||||
On rare occasions you may need to install a diffusers-style model that
|
||||
lives in a subfolder of a HuggingFace repo id. In this event, simply
|
||||
add ":_subfolder-name_" to the end of the repo id. For example, if the
|
||||
repo id is "monster-labs/control_v1p_sd15_qrcode_monster" and the model
|
||||
you wish to fetch lives in a subfolder named "v2", then the repo id to
|
||||
pass to the various model installers should be
|
||||
|
||||
```
|
||||
monster-labs/control_v1p_sd15_qrcode_monster:v2
|
||||
```
|
||||
|
||||
@ -4,12 +4,12 @@ The workflow editor is a blank canvas allowing for the use of individual functio
|
||||
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Workflow Editor and build workflows to suit your needs.
|
||||
|
||||
## UI Features
|
||||
## Features
|
||||
|
||||
### Linear View
|
||||
The Workflow Editor allows you to create a UI for your workflow, to make it easier to iterate on your generations.
|
||||
|
||||
To add an input to the Linear UI, right click on the input and select "Add to Linear View".
|
||||
To add an input to the Linear UI, right click on the input label and select "Add to Linear View".
|
||||
|
||||
The Linear UI View will also be part of the saved workflow, allowing you share workflows and enable other to use them, regardless of complexity.
|
||||
|
||||
@ -25,6 +25,10 @@ Any node or input field can be renamed in the workflow editor. If the input fiel
|
||||
* Backspace/Delete to delete a node
|
||||
* Shift+Click to drag and select multiple nodes
|
||||
|
||||
### Node Caching
|
||||
|
||||
Nodes have a "Use Cache" option in their footer. This allows for performance improvements by using the previously cached values during the workflow processing.
|
||||
|
||||
|
||||
## Important Concepts
|
||||
|
||||
|
||||
@ -8,26 +8,42 @@ To download a node, simply download the `.py` node file from the link and add it
|
||||
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
## Community Nodes
|
||||
- Community Nodes
|
||||
+ [Depth Map from Wavefront OBJ](#depth-map-from-wavefront-obj)
|
||||
+ [Film Grain](#film-grain)
|
||||
+ [Generative Grammar-Based Prompt Nodes](#generative-grammar-based-prompt-nodes)
|
||||
+ [GPT2RandomPromptMaker](#gpt2randompromptmaker)
|
||||
+ [Grid to Gif](#grid-to-gif)
|
||||
+ [Halftone](#halftone)
|
||||
+ [Ideal Size](#ideal-size)
|
||||
+ [Image and Mask Composition Pack](#image-and-mask-composition-pack)
|
||||
+ [Image to Character Art Image Nodes](#image-to-character-art-image-nodes)
|
||||
+ [Image Picker](#image-picker)
|
||||
+ [Load Video Frame](#load-video-frame)
|
||||
+ [Make 3D](#make-3d)
|
||||
+ [Oobabooga](#oobabooga)
|
||||
+ [Prompt Tools](#prompt-tools)
|
||||
+ [Retroize](#retroize)
|
||||
+ [Size Stepper Nodes](#size-stepper-nodes)
|
||||
+ [Text font to Image](#text-font-to-image)
|
||||
+ [Thresholding](#thresholding)
|
||||
+ [XY Image to Grid and Images to Grids nodes](#xy-image-to-grid-and-images-to-grids-nodes)
|
||||
- [Example Node Template](#example-node-template)
|
||||
- [Disclaimer](#disclaimer)
|
||||
- [Help](#help)
|
||||
|
||||
### FaceTools
|
||||
|
||||
**Description:** FaceTools is a collection of nodes created to manipulate faces as you would in Unified Canvas. It includes FaceMask, FaceOff, and FacePlace. FaceMask autodetects a face in the image using MediaPipe and creates a mask from it. FaceOff similarly detects a face, then takes the face off of the image by adding a square bounding box around it and cropping/scaling it. FacePlace puts the bounded face image from FaceOff back onto the original image. Using these nodes with other inpainting node(s), you can put new faces on existing things, put new things around existing faces, and work closer with a face as a bounded image. Additionally, you can supply X and Y offset values to scale/change the shape of the mask for finer control on FaceMask and FaceOff. See GitHub repository below for usage examples.
|
||||
|
||||
**Node Link:** https://github.com/ymgenesis/FaceTools/
|
||||
|
||||
**FaceMask Output Examples**
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
### Depth Map from Wavefront OBJ
|
||||
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
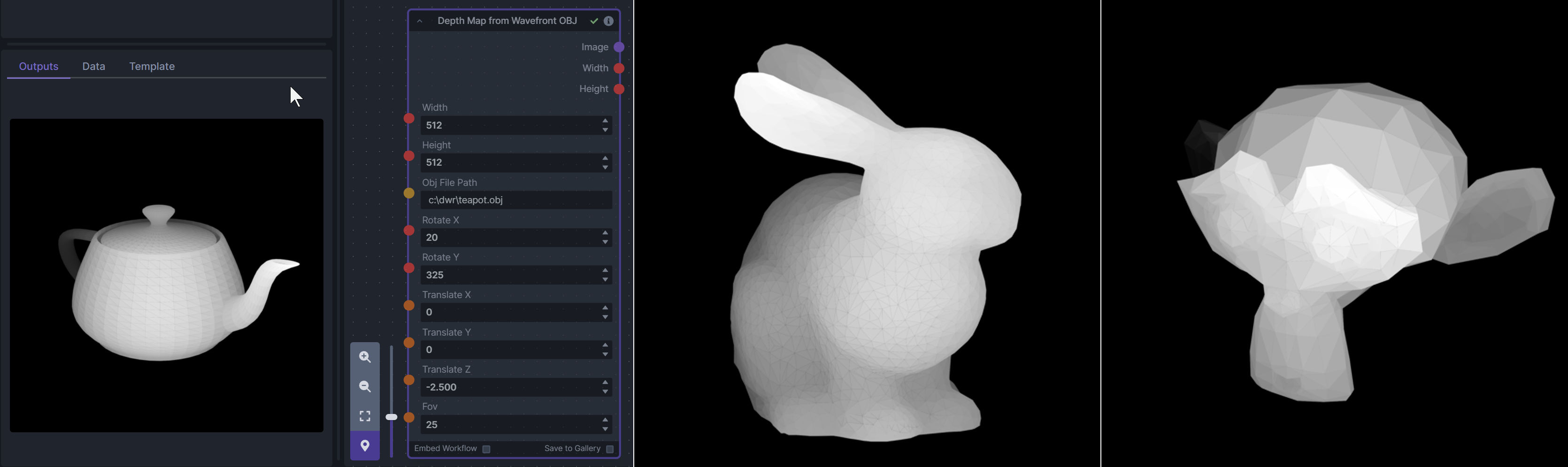
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/depth-from-obj-node/main/depth_from_obj_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
@ -37,22 +53,19 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
**Node Link:** https://github.com/JPPhoto/film-grain-node
|
||||
|
||||
--------------------------------
|
||||
### Image Picker
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
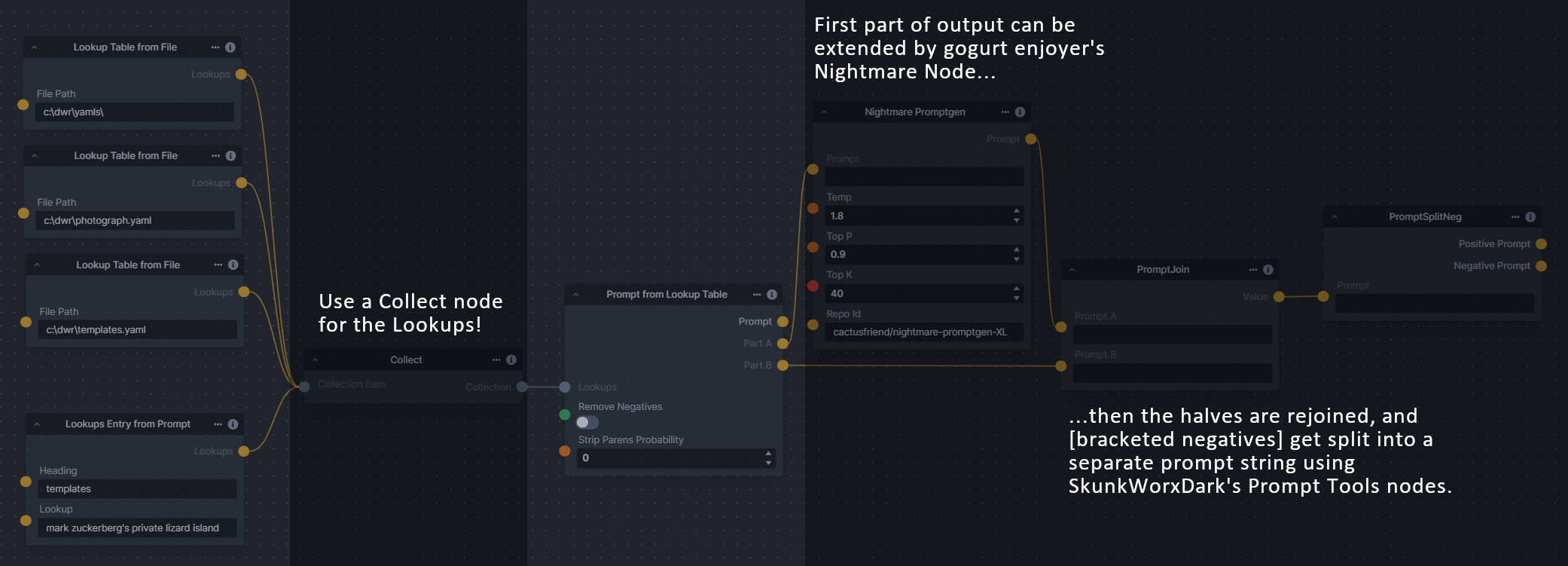
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no nonterminal terms remain in the string.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||

|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/generative-grammar-prompt-nodes/main/lookuptables_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### GPT2RandomPromptMaker
|
||||
@ -65,31 +78,133 @@ To use a community workflow, download the the `.json` node graph file and load i
|
||||
|
||||
Generated Prompt: An enchanted weapon will be usable by any character regardless of their alignment.
|
||||
|
||||

|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/8496ba09-bcdd-4ff7-8076-ff213b6a1e4c" width="200" />
|
||||
|
||||
--------------------------------
|
||||
### Grid to Gif
|
||||
|
||||
**Description:** One node that turns a grid image into an image collection, one node that turns an image collection into a gif.
|
||||
|
||||
**Node Link:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/GridToGif.py
|
||||
|
||||
**Example Node Graph:** https://github.com/mildmisery/invokeai-GridToGifNode/blob/main/Grid%20to%20Gif%20Example%20Workflow.json
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/input.png" width="300" />
|
||||
<img src="https://raw.githubusercontent.com/mildmisery/invokeai-GridToGifNode/main/output.gif" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Halftone
|
||||
|
||||
**Description**: Halftone converts the source image to grayscale and then performs halftoning. CMYK Halftone converts the image to CMYK and applies a per-channel halftoning to make the source image look like a magazine or newspaper. For both nodes, you can specify angles and halftone dot spacing.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/halftone-node
|
||||
|
||||
**Example**
|
||||
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/fd5efb9f-4355-4409-a1c2-c1ca99e0cab4" width="300" />
|
||||
|
||||
Halftone Output:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/7e606f29-e68f-4d46-b3d5-97f799a4ec2f" width="300" />
|
||||
|
||||
CMYK Halftone Output:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c59c578f-db8e-4d66-8c66-2851752d75ea" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
|
||||
--------------------------------
|
||||
### Image and Mask Composition Pack
|
||||
|
||||
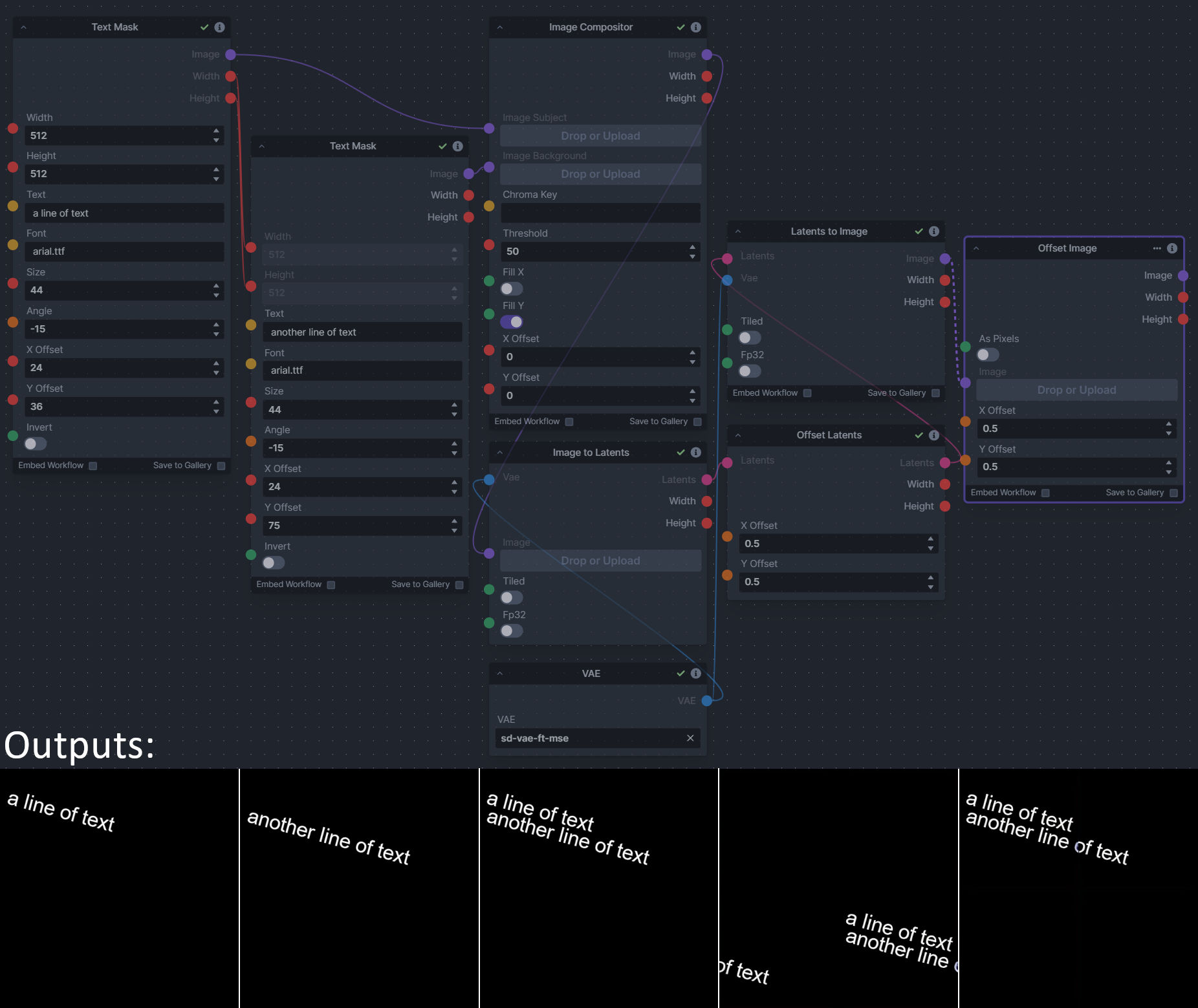
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 15 Nodes:
|
||||
|
||||
- *Adjust Image Hue Plus* - Rotate the hue of an image in one of several different color spaces.
|
||||
- *Blend Latents/Noise (Masked)* - Use a mask to blend part of one latents tensor [including Noise outputs] into another. Can be used to "renoise" sections during a multi-stage [masked] denoising process.
|
||||
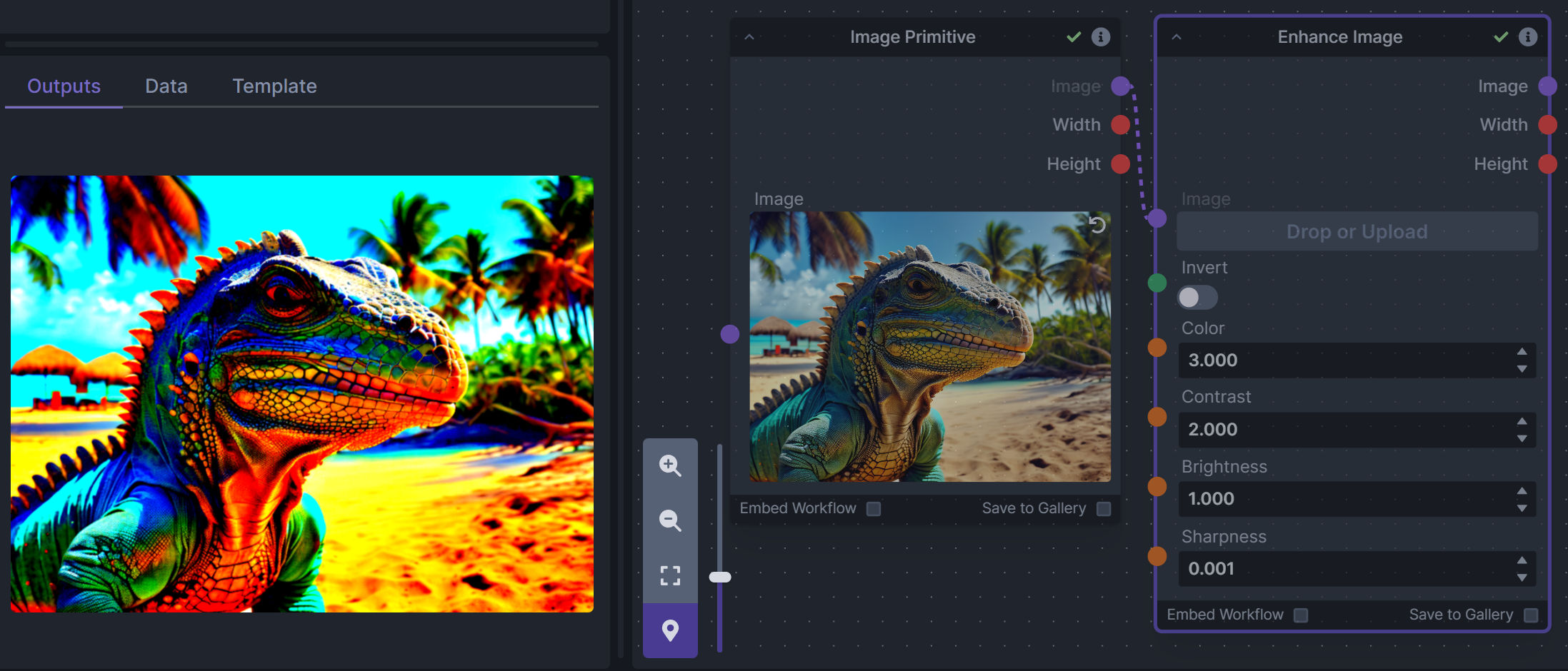
- *Enhance Image* - Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
- *Equivalent Achromatic Lightness* - Calculates image lightness accounting for Helmholtz-Kohlrausch effect based on a method described by High, Green, and Nussbaum (2023).
|
||||
- *Text to Mask (Clipseg)* - Input a prompt and an image to generate a mask representing areas of the image matched by the prompt.
|
||||
- *Text to Mask Advanced (Clipseg)* - Output up to four prompt masks combined with logical "and", logical "or", or as separate channels of an RGBA image.
|
||||
- *Image Layer Blend* - Perform a layered blend of two images using alpha compositing. Opacity of top layer is selectable, with optional mask and several different blend modes/color spaces.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Image Dilate or Erode* - Dilate or expand a mask (or any image!). This is equivalent to an expand/contract operation.
|
||||
- *Image Value Thresholds* - Clip an image to pure black/white beyond specified thresholds.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Rotate/Flip Image* - Rotate an image in degrees clockwise/counterclockwise about its center, optionally resizing the image boundaries to fit, or flipping it about the vertical and/or horizontal axes.
|
||||
- *Shadows/Highlights/Midtones* - Extract three masks (with adjustable hard or soft thresholds) representing shadows, midtones, and highlights regions of an image.
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/composition-nodes/main/composition_pack_overview.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Image to Character Art Image Nodes
|
||||
|
||||
**Description:** Group of nodes to convert an input image into ascii/unicode art Image
|
||||
|
||||
**Node Link:** https://github.com/mickr777/imagetoasciiimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://user-images.githubusercontent.com/115216705/271817646-8e061fcc-9a2c-4fa9-bcc7-c0f7b01e9056.png" width="300" /><img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/3c4990eb-2f42-46b9-90f9-0088b939dc6a" width="300" /></br>
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/fee7f800-a4a8-41e2-a66b-c66e4343307e" width="300" />
|
||||
<img src="https://github.com/mickr777/imagetoasciiimage/assets/115216705/1d9c1003-a45f-45c2-aac7-46470bb89330" width="300" />
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Image Picker
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
=======
|
||||

|
||||
|
||||
<img src="https://github.com/helix4u/load_video_frame/blob/main/testmp4_embed_converted.gif" width="500" />
|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
--------------------------------
|
||||
### Make 3D
|
||||
|
||||
**Description:** Create compelling 3D stereo images from 2D originals.
|
||||
|
||||
**Node Link:** [https://gitlab.com/srcrr/shift3d/-/raw/main/make3d.py](https://gitlab.com/srcrr/shift3d)
|
||||
|
||||
**Example Node Graph:** https://gitlab.com/srcrr/shift3d/-/raw/main/example-workflow.json?ref_type=heads&inline=false
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-1.png" width="300" />
|
||||
<img src="https://gitlab.com/srcrr/shift3d/-/raw/main/example-2.png" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Oobabooga
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
|
||||
|
||||
**Example:**
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
@ -99,7 +214,7 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
|
||||

|
||||
<img src="https://github.com/sammyf/oobabooga-node/assets/42468608/cecdd820-93dd-4c35-abbf-607e001fb2ed" width="300" />
|
||||
|
||||
**Requirement**
|
||||
|
||||
@ -107,98 +222,12 @@ a Text-Generation-Webui instance (might work remotely too, but I never tried it)
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independantly of the LLM's output.
|
||||
This node works best with SDXL models, especially as the style can be described independently of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Depth Map from Wavefront OBJ
|
||||
|
||||
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no more nonterminal terms remain in the string.
|
||||
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Image and Mask Composition Pack
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
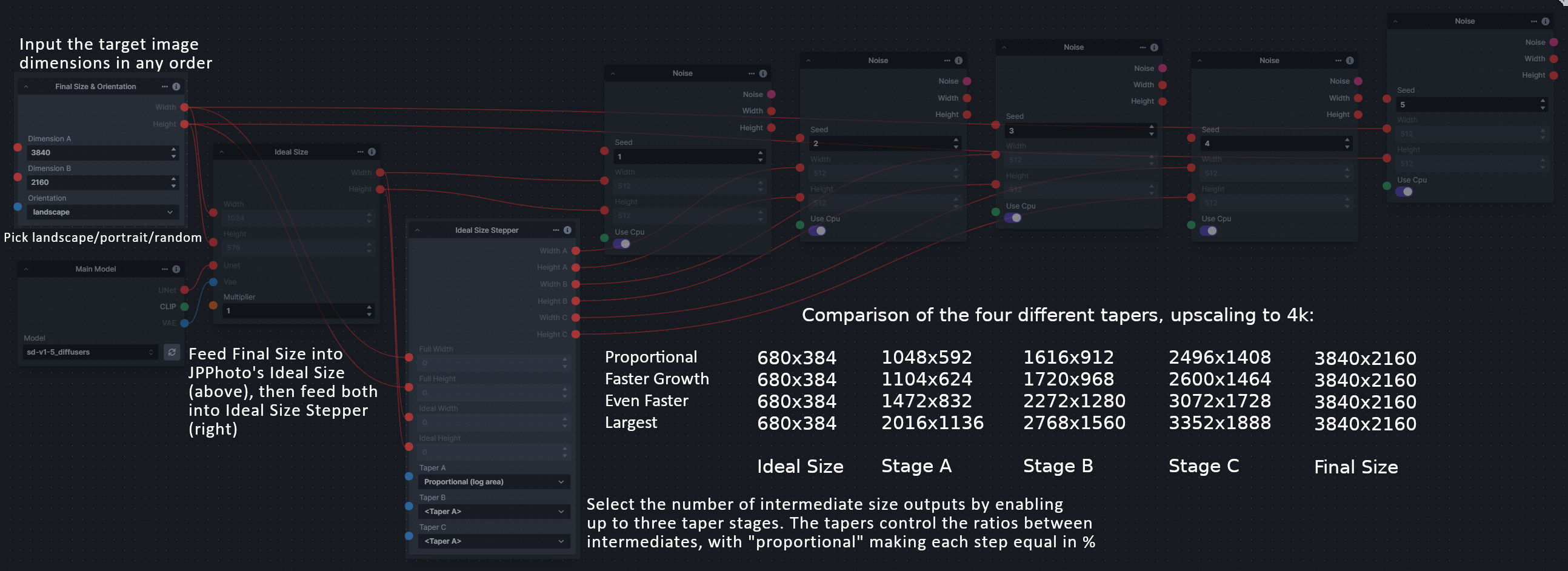
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||

|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
--------------------------------
|
||||
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These were written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
@ -215,21 +244,83 @@ See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/mai
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
|
||||
**Node Link:** https://github.com/Ar7ific1al/invokeai-retroizeinode/
|
||||
|
||||
**Retroize Output Examples**
|
||||
|
||||
<img src="https://github.com/Ar7ific1al/InvokeAI_nodes_retroize/assets/2306586/de8b4fa6-324c-4c2d-b36c-297600c73974" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
</br><img src="https://raw.githubusercontent.com/dwringer/size-stepper-nodes/main/size_nodes_usage.jpg" width="500" />
|
||||
|
||||
--------------------------------
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/c21b0af3-d9c6-4c16-9152-846a23effd36" width="300" />
|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/915f1a53-968e-43eb-aa61-07cd8f1a733a" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/821ef89e-8a60-44f5-b94e-471a9d8690cc" width="300" />
|
||||
<img src="https://github.com/mickr777/InvokeAI/assets/115216705/2befcb6d-49f4-4bfd-b5fc-1fee19274f89" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### Thresholding
|
||||
|
||||
**Description:** This node generates masks for highlights, midtones, and shadows given an input image. You can optionally specify a blur for the lookup table used in making those masks from the source image.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/thresholding-node
|
||||
|
||||
**Examples**
|
||||
|
||||
Input:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/c88ada13-fb3d-484c-a4fe-947b44712632" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows:
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/727021c1-36ff-4ec8-90c8-105e00de986d" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0b721bfc-f051-404e-b905-2f16b824ddfe" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/04c1297f-1c88-42b6-a7df-dd090b976286" width="300" />
|
||||
|
||||
Highlights/Midtones/Shadows (with LUT blur enabled):
|
||||
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/19aa718a-70c1-4668-8169-d68f4bd13771" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0a440e43-697f-4d17-82ee-f287467df0a5" width="300" />
|
||||
<img src="https://github.com/invoke-ai/InvokeAI/assets/34005131/0701fd0f-2ca7-4fe2-8613-2b52547bafce" width="300" />
|
||||
|
||||
--------------------------------
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then multiple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporting nodes. See example node setups for more details.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
@ -240,7 +331,7 @@ See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/READ
|
||||
|
||||
**Output Examples**
|
||||
|
||||
{: style="height:115px;width:240px"}
|
||||
</br><img src="https://invoke-ai.github.io/InvokeAI/assets/invoke_ai_banner.png" width="500" />
|
||||
|
||||
|
||||
## Disclaimer
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# List of Default Nodes
|
||||
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
The table below contains a list of the default nodes shipped with InvokeAI and their descriptions.
|
||||
|
||||
| Node <img width=160 align="right"> | Function |
|
||||
|: ---------------------------------- | :--------------------------------------------------------------------------------------|
|
||||
@ -17,11 +17,12 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Conditioning Primitive | A conditioning tensor primitive value|
|
||||
|Content Shuffle Processor | Applies content shuffle processing to image|
|
||||
|ControlNet | Collects ControlNet info to pass to other nodes|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Denoise Latents | Denoises noisy latents to decodable images|
|
||||
|Divide Integers | Divides two numbers|
|
||||
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|[FaceMask](./detailedNodes/faceTools.md#facemask) | Generates masks for faces in an image to use with Inpainting|
|
||||
|[FaceIdentifier](./detailedNodes/faceTools.md#faceidentifier) | Identifies and labels faces in an image|
|
||||
|[FaceOff](./detailedNodes/faceTools.md#faceoff) | Creates a new image that is a scaled bounding box with a mask on the face for Inpainting|
|
||||
|Float Math | Perform basic math operations on two floats|
|
||||
|Float Primitive Collection | A collection of float primitive values|
|
||||
|Float Primitive | A float primitive value|
|
||||
@ -76,6 +77,7 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|ONNX Prompt (Raw) | A node to process inputs and produce outputs. May use dependency injection in __init__ to receive providers.|
|
||||
|ONNX Text to Latents | Generates latents from conditionings.|
|
||||
|ONNX Model Loader | Loads a main model, outputting its submodels.|
|
||||
|OpenCV Inpaint | Simple inpaint using opencv.|
|
||||
|Openpose Processor | Applies Openpose processing to image|
|
||||
|PIDI Processor | Applies PIDI processing to image|
|
||||
|Prompts from File | Loads prompts from a text file|
|
||||
@ -97,5 +99,6 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|String Primitive | A string primitive value|
|
||||
|Subtract Integers | Subtracts two numbers|
|
||||
|Tile Resample Processor | Tile resampler processor|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|VAE Loader | Loads a VAE model, outputting a VaeLoaderOutput|
|
||||
|Zoe (Depth) Processor | Applies Zoe depth processing to image|
|
||||
154
docs/nodes/detailedNodes/faceTools.md
Normal file
154
docs/nodes/detailedNodes/faceTools.md
Normal file
@ -0,0 +1,154 @@
|
||||
# Face Nodes
|
||||
|
||||
## FaceOff
|
||||
|
||||
FaceOff mimics a user finding a face in an image and resizing the bounding box
|
||||
around the head in Canvas.
|
||||
|
||||
Enter a face ID (found with FaceIdentifier) to choose which face to mask.
|
||||
|
||||
Just as you would add more context inside the bounding box by making it larger
|
||||
in Canvas, the node gives you a padding input (in pixels) which will
|
||||
simultaneously add more context, and increase the resolution of the bounding box
|
||||
so the face remains the same size inside it.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If the detected masks are imperfect and stray
|
||||
too far outside/inside of faces, the node gives you X & Y offsets to shrink/grow
|
||||
the masks by a multiplier.
|
||||
|
||||
FaceOff will output the face in a bounded image, taking the face off of the
|
||||
original image for input into any node that accepts image inputs. The node also
|
||||
outputs a face mask with the dimensions of the bounded image. The X & Y outputs
|
||||
are for connecting to the X & Y inputs of the Paste Image node, which will place
|
||||
the bounded image back on the original image using these coordinates.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face ID | The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Padding | All-axis padding around the mask in pixels |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------------- | ------------------------------------------------ |
|
||||
| Bounded Image | Original image bound, cropped, and resized |
|
||||
| Width | The width of the bounded image in pixels |
|
||||
| Height | The height of the bounded image in pixels |
|
||||
| Mask | The output mask |
|
||||
| X | The x coordinate of the bounding box's left side |
|
||||
| Y | The y coordinate of the bounding box's top side |
|
||||
|
||||
## FaceMask
|
||||
|
||||
FaceMask mimics a user drawing masks on faces in an image in Canvas.
|
||||
|
||||
The "Face IDs" input allows the user to select specific faces to be masked.
|
||||
Leave empty to detect and mask all faces, or a comma-separated list for a
|
||||
specific combination of faces (ex: `1,2,4`). A single integer will detect and
|
||||
mask that specific face. Find face IDs with the FaceIdentifier node.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing.
|
||||
|
||||
If the detected masks are imperfect and stray too far outside/inside of faces,
|
||||
the node gives you X & Y offsets to shrink/grow the masks by a multiplier. All
|
||||
masks shrink/grow together by the X & Y offset values.
|
||||
|
||||
By default, masks are created to change faces. When masks are inverted, they
|
||||
change surrounding areas, protecting faces.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Face IDs | Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node. |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| X Offset | X-axis offset of the mask |
|
||||
| Y Offset | Y-axis offset of the mask |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
| Invert Mask | Toggle to invert the face mask |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | --------------------------------- |
|
||||
| Image | The original image |
|
||||
| Width | The width of the image in pixels |
|
||||
| Height | The height of the image in pixels |
|
||||
| Mask | The output face mask |
|
||||
|
||||
## FaceIdentifier
|
||||
|
||||
FaceIdentifier outputs an image with detected face IDs printed in white numbers
|
||||
onto each face.
|
||||
|
||||
Face IDs can then be used in FaceMask and FaceOff to selectively mask all, a
|
||||
specific combination, or single faces.
|
||||
|
||||
The FaceIdentifier output image is generated for user reference, and isn't meant
|
||||
to be passed on to other image-processing nodes.
|
||||
|
||||
The "Minimum Confidence" input defaults to 0.5 (50%), and represents a pass/fail
|
||||
threshold a detected face must reach for it to be processed. Lowering this value
|
||||
may help if detection is failing. If an image is changed in the slightest, run
|
||||
it through FaceIdentifier again to get updated FaceIDs.
|
||||
|
||||
###### Inputs/Outputs
|
||||
|
||||
| Input | Description |
|
||||
| ------------------ | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Image | Image for face detection |
|
||||
| Minimum Confidence | Minimum confidence for face detection (lower if detection is failing) |
|
||||
| Chunk | Chunk (or divide) the image into sections to greatly improve face detection success. Defaults to off, but will activate if no faces are detected normally. Activate to chunk by default. |
|
||||
|
||||
| Output | Description |
|
||||
| ------ | ------------------------------------------------------------------------------------------------ |
|
||||
| Image | The original image with small face ID numbers printed in white onto each face for user reference |
|
||||
| Width | The width of the original image in pixels |
|
||||
| Height | The height of the original image in pixels |
|
||||
|
||||
## Tips
|
||||
|
||||
- If not all target faces are being detected, activate Chunk to bypass full
|
||||
image face detection and greatly improve detection success.
|
||||
- Final results will vary between full-image detection and chunking for faces
|
||||
that are detectable by both due to the nature of the process. Try either to
|
||||
your taste.
|
||||
- Be sure Minimum Confidence is set the same when using FaceIdentifier with
|
||||
FaceOff/FaceMask.
|
||||
- For FaceOff, use the color correction node before faceplace to correct edges
|
||||
being noticeable in the final image (see example screenshot).
|
||||
- Non-inpainting models may struggle to paint/generate correctly around faces.
|
||||
- If your face won't change the way you want it to no matter what you change,
|
||||
consider that the change you're trying to make is too much at that resolution.
|
||||
For example, if an image is only 512x768 total, the face might only be 128x128
|
||||
or 256x256, much smaller than the 512x512 your SD1.5 model was probably
|
||||
trained on. Try increasing the resolution of the image by upscaling or
|
||||
resizing, add padding to increase the bounding box's resolution, or use an
|
||||
image where the face takes up more pixels.
|
||||
- If the resulting face seems out of place pasted back on the original image
|
||||
(ie. too large, not proportional), add more padding on the FaceOff node to
|
||||
give inpainting more context. Context and good prompting are important to
|
||||
keeping things proportional.
|
||||
- If you find the mask is too big/small and going too far outside/inside the
|
||||
area you want to affect, adjust the x & y offsets to shrink/grow the mask area
|
||||
- Use a higher denoise start value to resemble aspects of the original face or
|
||||
surroundings. Denoise start = 0 & denoise end = 1 will make something new,
|
||||
while denoise start = 0.50 & denoise end = 1 will be 50% old and 50% new.
|
||||
- mediapipe isn't good at detecting faces with lots of face paint, hair covering
|
||||
the face, etc. Anything that obstructs the face will likely result in no faces
|
||||
being detected.
|
||||
- If you find your face isn't being detected, try lowering the minimum
|
||||
confidence value from 0.5. This could result in false positives, however
|
||||
(random areas being detected as faces and masked).
|
||||
- After altering an image and wanting to process a different face in the newly
|
||||
altered image, run the altered image through FaceIdentifier again to see the
|
||||
new Face IDs. MediaPipe will most likely detect faces in a different order
|
||||
after an image has been changed in the slightest.
|
||||
@ -9,5 +9,6 @@ If you're interested in finding more workflows, checkout the [#share-your-workfl
|
||||
* [SD1.5 / SD2 Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/Text_to_Image.json)
|
||||
* [SDXL Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [SDXL (with Refiner) Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)ß
|
||||
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)
|
||||
* [FaceMask](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceMask.json)
|
||||
* [FaceOff with 2x Face Scaling](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/FaceOff_FaceScale2x.json)
|
||||
|
||||
1041
docs/workflows/FaceMask.json
Normal file
1041
docs/workflows/FaceMask.json
Normal file
File diff suppressed because it is too large
Load Diff
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
1395
docs/workflows/FaceOff_FaceScale2x.json
Normal file
File diff suppressed because it is too large
Load Diff
@ -332,6 +332,7 @@ class InvokeAiInstance:
|
||||
Configure the InvokeAI runtime directory
|
||||
"""
|
||||
|
||||
auto_install = False
|
||||
# set sys.argv to a consistent state
|
||||
new_argv = [sys.argv[0]]
|
||||
for i in range(1, len(sys.argv)):
|
||||
@ -340,13 +341,17 @@ class InvokeAiInstance:
|
||||
new_argv.append(el)
|
||||
new_argv.append(sys.argv[i + 1])
|
||||
elif el in ["-y", "--yes", "--yes-to-all"]:
|
||||
new_argv.append(el)
|
||||
auto_install = True
|
||||
sys.argv = new_argv
|
||||
|
||||
import messages
|
||||
import requests # to catch download exceptions
|
||||
from messages import introduction
|
||||
|
||||
introduction()
|
||||
auto_install = auto_install or messages.user_wants_auto_configuration()
|
||||
if auto_install:
|
||||
sys.argv.append("--yes")
|
||||
else:
|
||||
messages.introduction()
|
||||
|
||||
from invokeai.frontend.install.invokeai_configure import invokeai_configure
|
||||
|
||||
|
||||
@ -7,7 +7,7 @@ import os
|
||||
import platform
|
||||
from pathlib import Path
|
||||
|
||||
from prompt_toolkit import prompt
|
||||
from prompt_toolkit import HTML, prompt
|
||||
from prompt_toolkit.completion import PathCompleter
|
||||
from prompt_toolkit.validation import Validator
|
||||
from rich import box, print
|
||||
@ -65,17 +65,50 @@ def confirm_install(dest: Path) -> bool:
|
||||
if dest.exists():
|
||||
print(f":exclamation: Directory {dest} already exists :exclamation:")
|
||||
dest_confirmed = Confirm.ask(
|
||||
":stop_sign: Are you sure you want to (re)install in this location?",
|
||||
":stop_sign: (re)install in this location?",
|
||||
default=False,
|
||||
)
|
||||
else:
|
||||
print(f"InvokeAI will be installed in {dest}")
|
||||
dest_confirmed = not Confirm.ask("Would you like to pick a different location?", default=False)
|
||||
dest_confirmed = Confirm.ask("Use this location?", default=True)
|
||||
console.line()
|
||||
|
||||
return dest_confirmed
|
||||
|
||||
|
||||
def user_wants_auto_configuration() -> bool:
|
||||
"""Prompt the user to choose between manual and auto configuration."""
|
||||
console.rule("InvokeAI Configuration Section")
|
||||
console.print(
|
||||
Panel(
|
||||
Group(
|
||||
"\n".join(
|
||||
[
|
||||
"Libraries are installed and InvokeAI will now set up its root directory and configuration. Choose between:",
|
||||
"",
|
||||
" * AUTOMATIC configuration: install reasonable defaults and a minimal set of starter models.",
|
||||
" * MANUAL configuration: manually inspect and adjust configuration options and pick from a larger set of starter models.",
|
||||
"",
|
||||
"Later you can fine tune your configuration by selecting option [6] 'Change InvokeAI startup options' from the invoke.bat/invoke.sh launcher script.",
|
||||
]
|
||||
),
|
||||
),
|
||||
box=box.MINIMAL,
|
||||
padding=(1, 1),
|
||||
)
|
||||
)
|
||||
choice = (
|
||||
prompt(
|
||||
HTML("Choose <b><a></b>utomatic or <b><m></b>anual configuration [a/m] (a): "),
|
||||
validator=Validator.from_callable(
|
||||
lambda n: n == "" or n.startswith(("a", "A", "m", "M")), error_message="Please select 'a' or 'm'"
|
||||
),
|
||||
)
|
||||
or "a"
|
||||
)
|
||||
return choice.lower().startswith("a")
|
||||
|
||||
|
||||
def dest_path(dest=None) -> Path:
|
||||
"""
|
||||
Prompt the user for the destination path and create the path
|
||||
|
||||
@ -46,6 +46,9 @@ if [ "$(uname -s)" == "Darwin" ]; then
|
||||
export PYTORCH_ENABLE_MPS_FALLBACK=1
|
||||
fi
|
||||
|
||||
# Avoid glibc memory fragmentation. See invokeai/backend/model_management/README.md for details.
|
||||
export MALLOC_MMAP_THRESHOLD_=1048576
|
||||
|
||||
# Primary function for the case statement to determine user input
|
||||
do_choice() {
|
||||
case $1 in
|
||||
|
||||
@ -1,35 +1,35 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
import sqlite3
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import SqliteBoardImageRecordStorage
|
||||
from invokeai.app.services.board_images import BoardImagesService, BoardImagesServiceDependencies
|
||||
from invokeai.app.services.board_record_storage import SqliteBoardRecordStorage
|
||||
from invokeai.app.services.boards import BoardService, BoardServiceDependencies
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.image_record_storage import SqliteImageRecordStorage
|
||||
from invokeai.app.services.images import ImageService, ImageServiceDependencies
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_memory import MemoryInvocationCache
|
||||
from invokeai.app.services.resource_name import SimpleNameService
|
||||
from invokeai.app.services.session_processor.session_processor_default import DefaultSessionProcessor
|
||||
from invokeai.app.services.session_queue.session_queue_sqlite import SqliteSessionQueue
|
||||
from invokeai.app.services.urls import LocalUrlService
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
from ..services.default_graphs import create_system_graphs
|
||||
from ..services.graph import GraphExecutionState, LibraryGraph
|
||||
from ..services.image_file_storage import DiskImageFileStorage
|
||||
from ..services.invocation_queue import MemoryInvocationQueue
|
||||
from ..services.board_image_records.board_image_records_sqlite import SqliteBoardImageRecordStorage
|
||||
from ..services.board_images.board_images_default import BoardImagesService
|
||||
from ..services.board_records.board_records_sqlite import SqliteBoardRecordStorage
|
||||
from ..services.boards.boards_default import BoardService
|
||||
from ..services.config import InvokeAIAppConfig
|
||||
from ..services.image_files.image_files_disk import DiskImageFileStorage
|
||||
from ..services.image_records.image_records_sqlite import SqliteImageRecordStorage
|
||||
from ..services.images.images_default import ImageService
|
||||
from ..services.invocation_cache.invocation_cache_memory import MemoryInvocationCache
|
||||
from ..services.invocation_processor.invocation_processor_default import DefaultInvocationProcessor
|
||||
from ..services.invocation_queue.invocation_queue_memory import MemoryInvocationQueue
|
||||
from ..services.invocation_services import InvocationServices
|
||||
from ..services.invocation_stats import InvocationStatsService
|
||||
from ..services.invocation_stats.invocation_stats_default import InvocationStatsService
|
||||
from ..services.invoker import Invoker
|
||||
from ..services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from ..services.model_manager_service import ModelManagerService
|
||||
from ..services.processor import DefaultInvocationProcessor
|
||||
from ..services.sqlite import SqliteItemStorage
|
||||
from ..services.thread import lock
|
||||
from ..services.item_storage.item_storage_sqlite import SqliteItemStorage
|
||||
from ..services.latents_storage.latents_storage_disk import DiskLatentsStorage
|
||||
from ..services.latents_storage.latents_storage_forward_cache import ForwardCacheLatentsStorage
|
||||
from ..services.model_manager.model_manager_default import ModelManagerService
|
||||
from ..services.names.names_default import SimpleNameService
|
||||
from ..services.session_processor.session_processor_default import DefaultSessionProcessor
|
||||
from ..services.session_queue.session_queue_sqlite import SqliteSessionQueue
|
||||
from ..services.shared.default_graphs import create_system_graphs
|
||||
from ..services.shared.graph import GraphExecutionState, LibraryGraph
|
||||
from ..services.shared.sqlite import SqliteDatabase
|
||||
from ..services.urls.urls_default import LocalUrlService
|
||||
from .events import FastAPIEventService
|
||||
|
||||
|
||||
@ -49,7 +49,7 @@ def check_internet() -> bool:
|
||||
return False
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger()
|
||||
logger = InvokeAILogger.get_logger()
|
||||
|
||||
|
||||
class ApiDependencies:
|
||||
@ -63,100 +63,64 @@ class ApiDependencies:
|
||||
logger.info(f"Root directory = {str(config.root_path)}")
|
||||
logger.debug(f"Internet connectivity is {config.internet_available}")
|
||||
|
||||
events = FastAPIEventService(event_handler_id)
|
||||
|
||||
output_folder = config.output_path
|
||||
|
||||
# TODO: build a file/path manager?
|
||||
if config.use_memory_db:
|
||||
db_location = ":memory:"
|
||||
else:
|
||||
db_path = config.db_path
|
||||
db_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
db_location = str(db_path)
|
||||
db = SqliteDatabase(config, logger)
|
||||
|
||||
logger.info(f"Using database at {db_location}")
|
||||
db_conn = sqlite3.connect(db_location, check_same_thread=False) # TODO: figure out a better threading solution
|
||||
configuration = config
|
||||
logger = logger
|
||||
|
||||
if config.log_sql:
|
||||
db_conn.set_trace_callback(print)
|
||||
db_conn.execute("PRAGMA foreign_keys = ON;")
|
||||
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](
|
||||
conn=db_conn, table_name="graph_executions", lock=lock
|
||||
)
|
||||
|
||||
urls = LocalUrlService()
|
||||
image_record_storage = SqliteImageRecordStorage(conn=db_conn, lock=lock)
|
||||
image_file_storage = DiskImageFileStorage(f"{output_folder}/images")
|
||||
names = SimpleNameService()
|
||||
board_image_records = SqliteBoardImageRecordStorage(db=db)
|
||||
board_images = BoardImagesService()
|
||||
board_records = SqliteBoardRecordStorage(db=db)
|
||||
boards = BoardService()
|
||||
events = FastAPIEventService(event_handler_id)
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](db=db, table_name="graph_executions")
|
||||
graph_library = SqliteItemStorage[LibraryGraph](db=db, table_name="graphs")
|
||||
image_files = DiskImageFileStorage(f"{output_folder}/images")
|
||||
image_records = SqliteImageRecordStorage(db=db)
|
||||
images = ImageService()
|
||||
invocation_cache = MemoryInvocationCache(max_cache_size=config.node_cache_size)
|
||||
latents = ForwardCacheLatentsStorage(DiskLatentsStorage(f"{output_folder}/latents"))
|
||||
|
||||
board_record_storage = SqliteBoardRecordStorage(conn=db_conn, lock=lock)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(conn=db_conn, lock=lock)
|
||||
|
||||
boards = BoardService(
|
||||
services=BoardServiceDependencies(
|
||||
board_image_record_storage=board_image_record_storage,
|
||||
board_record_storage=board_record_storage,
|
||||
image_record_storage=image_record_storage,
|
||||
url=urls,
|
||||
logger=logger,
|
||||
)
|
||||
)
|
||||
|
||||
board_images = BoardImagesService(
|
||||
services=BoardImagesServiceDependencies(
|
||||
board_image_record_storage=board_image_record_storage,
|
||||
board_record_storage=board_record_storage,
|
||||
image_record_storage=image_record_storage,
|
||||
url=urls,
|
||||
logger=logger,
|
||||
)
|
||||
)
|
||||
|
||||
images = ImageService(
|
||||
services=ImageServiceDependencies(
|
||||
board_image_record_storage=board_image_record_storage,
|
||||
image_record_storage=image_record_storage,
|
||||
image_file_storage=image_file_storage,
|
||||
url=urls,
|
||||
logger=logger,
|
||||
names=names,
|
||||
graph_execution_manager=graph_execution_manager,
|
||||
)
|
||||
)
|
||||
model_manager = ModelManagerService(config, logger)
|
||||
names = SimpleNameService()
|
||||
performance_statistics = InvocationStatsService()
|
||||
processor = DefaultInvocationProcessor()
|
||||
queue = MemoryInvocationQueue()
|
||||
session_processor = DefaultSessionProcessor()
|
||||
session_queue = SqliteSessionQueue(db=db)
|
||||
urls = LocalUrlService()
|
||||
|
||||
services = InvocationServices(
|
||||
model_manager=ModelManagerService(config, logger),
|
||||
events=events,
|
||||
latents=latents,
|
||||
images=images,
|
||||
boards=boards,
|
||||
board_image_records=board_image_records,
|
||||
board_images=board_images,
|
||||
queue=MemoryInvocationQueue(),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](conn=db_conn, lock=lock, table_name="graphs"),
|
||||
board_records=board_records,
|
||||
boards=boards,
|
||||
configuration=configuration,
|
||||
events=events,
|
||||
graph_execution_manager=graph_execution_manager,
|
||||
processor=DefaultInvocationProcessor(),
|
||||
configuration=config,
|
||||
performance_statistics=InvocationStatsService(graph_execution_manager),
|
||||
graph_library=graph_library,
|
||||
image_files=image_files,
|
||||
image_records=image_records,
|
||||
images=images,
|
||||
invocation_cache=invocation_cache,
|
||||
latents=latents,
|
||||
logger=logger,
|
||||
session_queue=SqliteSessionQueue(conn=db_conn, lock=lock),
|
||||
session_processor=DefaultSessionProcessor(),
|
||||
invocation_cache=MemoryInvocationCache(max_cache_size=config.node_cache_size),
|
||||
model_manager=model_manager,
|
||||
names=names,
|
||||
performance_statistics=performance_statistics,
|
||||
processor=processor,
|
||||
queue=queue,
|
||||
session_processor=session_processor,
|
||||
session_queue=session_queue,
|
||||
urls=urls,
|
||||
)
|
||||
|
||||
create_system_graphs(services.graph_library)
|
||||
|
||||
ApiDependencies.invoker = Invoker(services)
|
||||
|
||||
try:
|
||||
lock.acquire()
|
||||
db_conn.execute("VACUUM;")
|
||||
db_conn.commit()
|
||||
logger.info("Cleaned database")
|
||||
finally:
|
||||
lock.release()
|
||||
db.clean()
|
||||
|
||||
@staticmethod
|
||||
def shutdown():
|
||||
|
||||
@ -7,7 +7,7 @@ from typing import Any
|
||||
|
||||
from fastapi_events.dispatcher import dispatch
|
||||
|
||||
from ..services.events import EventServiceBase
|
||||
from ..services.events.events_base import EventServiceBase
|
||||
|
||||
|
||||
class FastAPIEventService(EventServiceBase):
|
||||
|
||||
@ -4,9 +4,9 @@ from fastapi import Body, HTTPException, Path, Query
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.services.board_record_storage import BoardChanges
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.board_record import BoardDTO
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
|
||||
@ -8,9 +8,9 @@ from PIL import Image
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.metadata import ImageMetadata
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.image_record import ImageDTO, ImageRecordChanges, ImageUrlsDTO
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ImageRecordChanges, ResourceOrigin
|
||||
from invokeai.app.services.images.images_common import ImageDTO, ImageUrlsDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
@ -42,7 +42,7 @@ async def upload_image(
|
||||
crop_visible: Optional[bool] = Query(default=False, description="Whether to crop the image"),
|
||||
) -> ImageDTO:
|
||||
"""Uploads an image"""
|
||||
if not file.content_type.startswith("image"):
|
||||
if not file.content_type or not file.content_type.startswith("image"):
|
||||
raise HTTPException(status_code=415, detail="Not an image")
|
||||
|
||||
contents = await file.read()
|
||||
@ -322,3 +322,20 @@ async def unstar_images_in_list(
|
||||
return ImagesUpdatedFromListResult(updated_image_names=updated_image_names)
|
||||
except Exception:
|
||||
raise HTTPException(status_code=500, detail="Failed to unstar images")
|
||||
|
||||
|
||||
class ImagesDownloaded(BaseModel):
|
||||
response: Optional[str] = Field(
|
||||
description="If defined, the message to display to the user when images begin downloading"
|
||||
)
|
||||
|
||||
|
||||
@images_router.post("/download", operation_id="download_images_from_list", response_model=ImagesDownloaded)
|
||||
async def download_images_from_list(
|
||||
image_names: list[str] = Body(description="The list of names of images to download", embed=True),
|
||||
board_id: Optional[str] = Body(
|
||||
default=None, description="The board from which image should be downloaded from", embed=True
|
||||
),
|
||||
) -> ImagesDownloaded:
|
||||
# return ImagesDownloaded(response="Your images are downloading")
|
||||
raise HTTPException(status_code=501, detail="Endpoint is not yet implemented")
|
||||
|
||||
@ -2,11 +2,11 @@
|
||||
|
||||
|
||||
import pathlib
|
||||
from typing import List, Literal, Optional, Union
|
||||
from typing import Annotated, List, Literal, Optional, Union
|
||||
|
||||
from fastapi import Body, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel, parse_obj_as
|
||||
from pydantic import BaseModel, ConfigDict, Field, TypeAdapter
|
||||
from starlette.exceptions import HTTPException
|
||||
|
||||
from invokeai.backend import BaseModelType, ModelType
|
||||
@ -23,8 +23,14 @@ from ..dependencies import ApiDependencies
|
||||
models_router = APIRouter(prefix="/v1/models", tags=["models"])
|
||||
|
||||
UpdateModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
update_models_response_adapter = TypeAdapter(UpdateModelResponse)
|
||||
|
||||
ImportModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
import_models_response_adapter = TypeAdapter(ImportModelResponse)
|
||||
|
||||
ConvertModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
convert_models_response_adapter = TypeAdapter(ConvertModelResponse)
|
||||
|
||||
MergeModelResponse = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
ImportModelAttributes = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
|
||||
@ -32,6 +38,11 @@ ImportModelAttributes = Union[tuple(OPENAPI_MODEL_CONFIGS)]
|
||||
class ModelsList(BaseModel):
|
||||
models: list[Union[tuple(OPENAPI_MODEL_CONFIGS)]]
|
||||
|
||||
model_config = ConfigDict(use_enum_values=True)
|
||||
|
||||
|
||||
models_list_adapter = TypeAdapter(ModelsList)
|
||||
|
||||
|
||||
@models_router.get(
|
||||
"/",
|
||||
@ -49,7 +60,7 @@ async def list_models(
|
||||
models_raw.extend(ApiDependencies.invoker.services.model_manager.list_models(base_model, model_type))
|
||||
else:
|
||||
models_raw = ApiDependencies.invoker.services.model_manager.list_models(None, model_type)
|
||||
models = parse_obj_as(ModelsList, {"models": models_raw})
|
||||
models = models_list_adapter.validate_python({"models": models_raw})
|
||||
return models
|
||||
|
||||
|
||||
@ -105,11 +116,14 @@ async def update_model(
|
||||
info.path = new_info.get("path")
|
||||
|
||||
# replace empty string values with None/null to avoid phenomenon of vae: ''
|
||||
info_dict = info.dict()
|
||||
info_dict = info.model_dump()
|
||||
info_dict = {x: info_dict[x] if info_dict[x] else None for x in info_dict.keys()}
|
||||
|
||||
ApiDependencies.invoker.services.model_manager.update_model(
|
||||
model_name=model_name, base_model=base_model, model_type=model_type, model_attributes=info_dict
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
model_attributes=info_dict,
|
||||
)
|
||||
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
@ -117,7 +131,7 @@ async def update_model(
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
)
|
||||
model_response = parse_obj_as(UpdateModelResponse, model_raw)
|
||||
model_response = update_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
except ValueError as e:
|
||||
@ -146,18 +160,21 @@ async def update_model(
|
||||
async def import_model(
|
||||
location: str = Body(description="A model path, repo_id or URL to import"),
|
||||
prediction_type: Optional[Literal["v_prediction", "epsilon", "sample"]] = Body(
|
||||
description="Prediction type for SDv2 checkpoint files", default="v_prediction"
|
||||
description="Prediction type for SDv2 checkpoints and rare SDv1 checkpoints",
|
||||
default=None,
|
||||
),
|
||||
) -> ImportModelResponse:
|
||||
"""Add a model using its local path, repo_id, or remote URL. Model characteristics will be probed and configured automatically"""
|
||||
|
||||
location = location.strip("\"' ")
|
||||
items_to_import = {location}
|
||||
prediction_types = {x.value: x for x in SchedulerPredictionType}
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
|
||||
try:
|
||||
installed_models = ApiDependencies.invoker.services.model_manager.heuristic_import(
|
||||
items_to_import=items_to_import, prediction_type_helper=lambda x: prediction_types.get(prediction_type)
|
||||
items_to_import=items_to_import,
|
||||
prediction_type_helper=lambda x: prediction_types.get(prediction_type),
|
||||
)
|
||||
info = installed_models.get(location)
|
||||
|
||||
@ -169,7 +186,7 @@ async def import_model(
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.name, base_model=info.base_model, model_type=info.model_type
|
||||
)
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
return import_models_response_adapter.validate_python(model_raw)
|
||||
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
@ -203,13 +220,18 @@ async def add_model(
|
||||
|
||||
try:
|
||||
ApiDependencies.invoker.services.model_manager.add_model(
|
||||
info.model_name, info.base_model, info.model_type, model_attributes=info.dict()
|
||||
info.model_name,
|
||||
info.base_model,
|
||||
info.model_type,
|
||||
model_attributes=info.model_dump(),
|
||||
)
|
||||
logger.info(f"Successfully added {info.model_name}")
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name=info.model_name, base_model=info.base_model, model_type=info.model_type
|
||||
model_name=info.model_name,
|
||||
base_model=info.base_model,
|
||||
model_type=info.model_type,
|
||||
)
|
||||
return parse_obj_as(ImportModelResponse, model_raw)
|
||||
return import_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
logger.error(str(e))
|
||||
raise HTTPException(status_code=404, detail=str(e))
|
||||
@ -221,7 +243,10 @@ async def add_model(
|
||||
@models_router.delete(
|
||||
"/{base_model}/{model_type}/{model_name}",
|
||||
operation_id="del_model",
|
||||
responses={204: {"description": "Model deleted successfully"}, 404: {"description": "Model not found"}},
|
||||
responses={
|
||||
204: {"description": "Model deleted successfully"},
|
||||
404: {"description": "Model not found"},
|
||||
},
|
||||
status_code=204,
|
||||
response_model=None,
|
||||
)
|
||||
@ -277,7 +302,7 @@ async def convert_model(
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
model_name, base_model=base_model, model_type=model_type
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
response = convert_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException as e:
|
||||
raise HTTPException(status_code=404, detail=f"Model '{model_name}' not found: {str(e)}")
|
||||
except ValueError as e:
|
||||
@ -300,7 +325,8 @@ async def search_for_models(
|
||||
) -> List[pathlib.Path]:
|
||||
if not search_path.is_dir():
|
||||
raise HTTPException(
|
||||
status_code=404, detail=f"The search path '{search_path}' does not exist or is not directory"
|
||||
status_code=404,
|
||||
detail=f"The search path '{search_path}' does not exist or is not directory",
|
||||
)
|
||||
return ApiDependencies.invoker.services.model_manager.search_for_models(search_path)
|
||||
|
||||
@ -335,6 +361,26 @@ async def sync_to_config() -> bool:
|
||||
return True
|
||||
|
||||
|
||||
# There's some weird pydantic-fastapi behaviour that requires this to be a separate class
|
||||
# TODO: After a few updates, see if it works inside the route operation handler?
|
||||
class MergeModelsBody(BaseModel):
|
||||
model_names: List[str] = Field(description="model name", min_length=2, max_length=3)
|
||||
merged_model_name: Optional[str] = Field(description="Name of destination model")
|
||||
alpha: Optional[float] = Field(description="Alpha weighting strength to apply to 2d and 3d models", default=0.5)
|
||||
interp: Optional[MergeInterpolationMethod] = Field(description="Interpolation method")
|
||||
force: Optional[bool] = Field(
|
||||
description="Force merging of models created with different versions of diffusers",
|
||||
default=False,
|
||||
)
|
||||
|
||||
merge_dest_directory: Optional[str] = Field(
|
||||
description="Save the merged model to the designated directory (with 'merged_model_name' appended)",
|
||||
default=None,
|
||||
)
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@models_router.put(
|
||||
"/merge/{base_model}",
|
||||
operation_id="merge_models",
|
||||
@ -347,31 +393,23 @@ async def sync_to_config() -> bool:
|
||||
response_model=MergeModelResponse,
|
||||
)
|
||||
async def merge_models(
|
||||
body: Annotated[MergeModelsBody, Body(description="Model configuration", embed=True)],
|
||||
base_model: BaseModelType = Path(description="Base model"),
|
||||
model_names: List[str] = Body(description="model name", min_items=2, max_items=3),
|
||||
merged_model_name: Optional[str] = Body(description="Name of destination model"),
|
||||
alpha: Optional[float] = Body(description="Alpha weighting strength to apply to 2d and 3d models", default=0.5),
|
||||
interp: Optional[MergeInterpolationMethod] = Body(description="Interpolation method"),
|
||||
force: Optional[bool] = Body(
|
||||
description="Force merging of models created with different versions of diffusers", default=False
|
||||
),
|
||||
merge_dest_directory: Optional[str] = Body(
|
||||
description="Save the merged model to the designated directory (with 'merged_model_name' appended)",
|
||||
default=None,
|
||||
),
|
||||
) -> MergeModelResponse:
|
||||
"""Convert a checkpoint model into a diffusers model"""
|
||||
logger = ApiDependencies.invoker.services.logger
|
||||
try:
|
||||
logger.info(f"Merging models: {model_names} into {merge_dest_directory or '<MODELS>'}/{merged_model_name}")
|
||||
dest = pathlib.Path(merge_dest_directory) if merge_dest_directory else None
|
||||
logger.info(
|
||||
f"Merging models: {body.model_names} into {body.merge_dest_directory or '<MODELS>'}/{body.merged_model_name}"
|
||||
)
|
||||
dest = pathlib.Path(body.merge_dest_directory) if body.merge_dest_directory else None
|
||||
result = ApiDependencies.invoker.services.model_manager.merge_models(
|
||||
model_names,
|
||||
base_model,
|
||||
merged_model_name=merged_model_name or "+".join(model_names),
|
||||
alpha=alpha,
|
||||
interp=interp,
|
||||
force=force,
|
||||
model_names=body.model_names,
|
||||
base_model=base_model,
|
||||
merged_model_name=body.merged_model_name or "+".join(body.model_names),
|
||||
alpha=body.alpha,
|
||||
interp=body.interp,
|
||||
force=body.force,
|
||||
merge_dest_directory=dest,
|
||||
)
|
||||
model_raw = ApiDependencies.invoker.services.model_manager.list_model(
|
||||
@ -379,9 +417,12 @@ async def merge_models(
|
||||
base_model=base_model,
|
||||
model_type=ModelType.Main,
|
||||
)
|
||||
response = parse_obj_as(ConvertModelResponse, model_raw)
|
||||
response = convert_models_response_adapter.validate_python(model_raw)
|
||||
except ModelNotFoundException:
|
||||
raise HTTPException(status_code=404, detail=f"One or more of the models '{model_names}' not found")
|
||||
raise HTTPException(
|
||||
status_code=404,
|
||||
detail=f"One or more of the models '{body.model_names}' not found",
|
||||
)
|
||||
except ValueError as e:
|
||||
raise HTTPException(status_code=400, detail=str(e))
|
||||
return response
|
||||
|
||||
@ -18,9 +18,9 @@ from invokeai.app.services.session_queue.session_queue_common import (
|
||||
SessionQueueItemDTO,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.services.shared.models import CursorPaginatedResults
|
||||
from invokeai.app.services.shared.graph import Graph
|
||||
from invokeai.app.services.shared.pagination import CursorPaginatedResults
|
||||
|
||||
from ...services.graph import Graph
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
session_queue_router = APIRouter(prefix="/v1/queue", tags=["queue"])
|
||||
|
||||
@ -6,11 +6,12 @@ from fastapi import Body, HTTPException, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic.fields import Field
|
||||
|
||||
from invokeai.app.services.shared.pagination import PaginatedResults
|
||||
|
||||
# Importing * is bad karma but needed here for node detection
|
||||
from ...invocations import * # noqa: F401 F403
|
||||
from ...invocations.baseinvocation import BaseInvocation
|
||||
from ...services.graph import Edge, EdgeConnection, Graph, GraphExecutionState, NodeAlreadyExecutedError
|
||||
from ...services.item_storage import PaginatedResults
|
||||
from ...services.shared.graph import Edge, EdgeConnection, Graph, GraphExecutionState, NodeAlreadyExecutedError
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
session_router = APIRouter(prefix="/v1/sessions", tags=["sessions"])
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
from typing import Optional
|
||||
from typing import Optional, Union
|
||||
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
from fastapi import Body
|
||||
@ -27,6 +27,7 @@ async def parse_dynamicprompts(
|
||||
combinatorial: bool = Body(default=True, description="Whether to use the combinatorial generator"),
|
||||
) -> DynamicPromptsResponse:
|
||||
"""Creates a batch process"""
|
||||
generator: Union[RandomPromptGenerator, CombinatorialPromptGenerator]
|
||||
try:
|
||||
error: Optional[str] = None
|
||||
if combinatorial:
|
||||
|
||||
@ -5,7 +5,7 @@ from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.typing import Event
|
||||
from socketio import ASGIApp, AsyncServer
|
||||
|
||||
from ..services.events import EventServiceBase
|
||||
from ..services.events.events_base import EventServiceBase
|
||||
|
||||
|
||||
class SocketIO:
|
||||
@ -30,8 +30,8 @@ class SocketIO:
|
||||
|
||||
async def _handle_sub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
async def _handle_unsub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
await self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
@ -8,7 +8,6 @@ app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
@ -23,7 +22,7 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from pydantic.schema import schema
|
||||
from pydantic.json_schema import models_json_schema
|
||||
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
@ -32,7 +31,7 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
|
||||
from ..backend.util.logging import InvokeAILogger
|
||||
from .api.dependencies import ApiDependencies
|
||||
from .api.routers import app_info, board_images, boards, images, models, session_queue, sessions, utilities
|
||||
from .api.routers import app_info, board_images, boards, images, models, session_queue, utilities
|
||||
from .api.sockets import SocketIO
|
||||
from .invocations.baseinvocation import BaseInvocation, UIConfigBase, _InputField, _OutputField
|
||||
|
||||
@ -41,7 +40,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(config=app_config)
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
app_config.parse_args()
|
||||
logger = InvokeAILogger.get_logger(config=app_config)
|
||||
|
||||
# fix for windows mimetypes registry entries being borked
|
||||
# see https://github.com/invoke-ai/InvokeAI/discussions/3684#discussioncomment-6391352
|
||||
@ -50,7 +51,7 @@ mimetypes.add_type("text/css", ".css")
|
||||
|
||||
# Create the app
|
||||
# TODO: create this all in a method so configuration/etc. can be passed in?
|
||||
app = FastAPI(title="Invoke AI", docs_url=None, redoc_url=None)
|
||||
app = FastAPI(title="Invoke AI", docs_url=None, redoc_url=None, separate_input_output_schemas=False)
|
||||
|
||||
# Add event handler
|
||||
event_handler_id: int = id(app)
|
||||
@ -62,18 +63,18 @@ app.add_middleware(
|
||||
|
||||
socket_io = SocketIO(app)
|
||||
|
||||
app.add_middleware(
|
||||
CORSMiddleware,
|
||||
allow_origins=app_config.allow_origins,
|
||||
allow_credentials=app_config.allow_credentials,
|
||||
allow_methods=app_config.allow_methods,
|
||||
allow_headers=app_config.allow_headers,
|
||||
)
|
||||
|
||||
|
||||
# Add startup event to load dependencies
|
||||
@app.on_event("startup")
|
||||
async def startup_event():
|
||||
app.add_middleware(
|
||||
CORSMiddleware,
|
||||
allow_origins=app_config.allow_origins,
|
||||
allow_credentials=app_config.allow_credentials,
|
||||
allow_methods=app_config.allow_methods,
|
||||
allow_headers=app_config.allow_headers,
|
||||
)
|
||||
|
||||
ApiDependencies.initialize(config=app_config, event_handler_id=event_handler_id, logger=logger)
|
||||
|
||||
|
||||
@ -84,12 +85,7 @@ async def shutdown_event():
|
||||
|
||||
|
||||
# Include all routers
|
||||
# TODO: REMOVE
|
||||
# app.include_router(
|
||||
# invocation.invocation_router,
|
||||
# prefix = '/api')
|
||||
|
||||
app.include_router(sessions.session_router, prefix="/api")
|
||||
# app.include_router(sessions.session_router, prefix="/api")
|
||||
|
||||
app.include_router(utilities.utilities_router, prefix="/api")
|
||||
|
||||
@ -116,6 +112,7 @@ def custom_openapi():
|
||||
description="An API for invoking AI image operations",
|
||||
version="1.0.0",
|
||||
routes=app.routes,
|
||||
separate_input_output_schemas=False, # https://fastapi.tiangolo.com/how-to/separate-openapi-schemas/
|
||||
)
|
||||
|
||||
# Add all outputs
|
||||
@ -126,29 +123,32 @@ def custom_openapi():
|
||||
output_type = signature(invoker.invoke).return_annotation
|
||||
output_types.add(output_type)
|
||||
|
||||
output_schemas = schema(output_types, ref_prefix="#/components/schemas/")
|
||||
for schema_key, output_schema in output_schemas["definitions"].items():
|
||||
output_schema["class"] = "output"
|
||||
openapi_schema["components"]["schemas"][schema_key] = output_schema
|
||||
|
||||
output_schemas = models_json_schema(
|
||||
models=[(o, "serialization") for o in output_types], ref_template="#/components/schemas/{model}"
|
||||
)
|
||||
for schema_key, output_schema in output_schemas[1]["$defs"].items():
|
||||
# TODO: note that we assume the schema_key here is the TYPE.__name__
|
||||
# This could break in some cases, figure out a better way to do it
|
||||
output_type_titles[schema_key] = output_schema["title"]
|
||||
|
||||
# Add Node Editor UI helper schemas
|
||||
ui_config_schemas = schema([UIConfigBase, _InputField, _OutputField], ref_prefix="#/components/schemas/")
|
||||
for schema_key, ui_config_schema in ui_config_schemas["definitions"].items():
|
||||
ui_config_schemas = models_json_schema(
|
||||
[(UIConfigBase, "serialization"), (_InputField, "serialization"), (_OutputField, "serialization")],
|
||||
ref_template="#/components/schemas/{model}",
|
||||
)
|
||||
for schema_key, ui_config_schema in ui_config_schemas[1]["$defs"].items():
|
||||
openapi_schema["components"]["schemas"][schema_key] = ui_config_schema
|
||||
|
||||
# Add a reference to the output type to additionalProperties of the invoker schema
|
||||
for invoker in all_invocations:
|
||||
invoker_name = invoker.__name__
|
||||
output_type = signature(invoker.invoke).return_annotation
|
||||
output_type = signature(obj=invoker.invoke).return_annotation
|
||||
output_type_title = output_type_titles[output_type.__name__]
|
||||
invoker_schema = openapi_schema["components"]["schemas"][invoker_name]
|
||||
invoker_schema = openapi_schema["components"]["schemas"][f"{invoker_name}"]
|
||||
outputs_ref = {"$ref": f"#/components/schemas/{output_type_title}"}
|
||||
invoker_schema["output"] = outputs_ref
|
||||
invoker_schema["class"] = "invocation"
|
||||
openapi_schema["components"]["schemas"][f"{output_type_title}"]["class"] = "output"
|
||||
|
||||
from invokeai.backend.model_management.models import get_model_config_enums
|
||||
|
||||
@ -171,7 +171,7 @@ def custom_openapi():
|
||||
return app.openapi_schema
|
||||
|
||||
|
||||
app.openapi = custom_openapi
|
||||
app.openapi = custom_openapi # type: ignore [method-assign] # this is a valid assignment
|
||||
|
||||
# Override API doc favicons
|
||||
app.mount("/static", StaticFiles(directory=Path(web_dir.__path__[0], "static/dream_web")), name="static")
|
||||
@ -223,7 +223,7 @@ def invoke_api():
|
||||
exc_info=e,
|
||||
)
|
||||
else:
|
||||
jurigged.watch(logger=InvokeAILogger.getLogger(name="jurigged").info)
|
||||
jurigged.watch(logger=InvokeAILogger.get_logger(name="jurigged").info)
|
||||
|
||||
port = find_port(app_config.port)
|
||||
if port != app_config.port:
|
||||
@ -242,7 +242,7 @@ def invoke_api():
|
||||
|
||||
# replace uvicorn's loggers with InvokeAI's for consistent appearance
|
||||
for logname in ["uvicorn.access", "uvicorn"]:
|
||||
log = logging.getLogger(logname)
|
||||
log = InvokeAILogger.get_logger(logname)
|
||||
log.handlers.clear()
|
||||
for ch in logger.handlers:
|
||||
log.addHandler(ch)
|
||||
|
||||
@ -24,8 +24,8 @@ def add_field_argument(command_parser, name: str, field, default_override=None):
|
||||
if field.default_factory is None
|
||||
else field.default_factory()
|
||||
)
|
||||
if get_origin(field.type_) == Literal:
|
||||
allowed_values = get_args(field.type_)
|
||||
if get_origin(field.annotation) == Literal:
|
||||
allowed_values = get_args(field.annotation)
|
||||
allowed_types = set()
|
||||
for val in allowed_values:
|
||||
allowed_types.add(type(val))
|
||||
@ -38,15 +38,15 @@ def add_field_argument(command_parser, name: str, field, default_override=None):
|
||||
type=field_type,
|
||||
default=default,
|
||||
choices=allowed_values,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
else:
|
||||
command_parser.add_argument(
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
|
||||
@ -142,7 +142,6 @@ class BaseCommand(ABC, BaseModel):
|
||||
"""A CLI command"""
|
||||
|
||||
# All commands must include a type name like this:
|
||||
# type: Literal['your_command_name'] = 'your_command_name'
|
||||
|
||||
@classmethod
|
||||
def get_all_subclasses(cls):
|
||||
|
||||
@ -7,8 +7,6 @@ from .services.config import InvokeAIAppConfig
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import argparse
|
||||
@ -61,8 +59,9 @@ if True: # hack to make flake8 happy with imports coming after setting up the c
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
logger = InvokeAILogger().get_logger(config=config)
|
||||
|
||||
|
||||
class CliCommand(BaseModel):
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
@ -2,7 +2,7 @@
|
||||
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
from pydantic import ValidationInfo, field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import IntegerCollectionOutput
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
@ -20,9 +20,9 @@ class RangeInvocation(BaseInvocation):
|
||||
stop: int = InputField(default=10, description="The stop of the range")
|
||||
step: int = InputField(default=1, description="The step of the range")
|
||||
|
||||
@validator("stop")
|
||||
def stop_gt_start(cls, v, values):
|
||||
if "start" in values and v <= values["start"]:
|
||||
@field_validator("stop")
|
||||
def stop_gt_start(cls, v: int, info: ValidationInfo):
|
||||
if "start" in info.data and v <= info.data["start"]:
|
||||
raise ValueError("stop must be greater than start")
|
||||
return v
|
||||
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Union
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import torch
|
||||
from compel import Compel, ReturnedEmbeddingsType
|
||||
@ -43,7 +43,13 @@ class ConditioningFieldData:
|
||||
# PerpNeg = "perp_neg"
|
||||
|
||||
|
||||
@invocation("compel", title="Prompt", tags=["prompt", "compel"], category="conditioning", version="1.0.0")
|
||||
@invocation(
|
||||
"compel",
|
||||
title="Prompt",
|
||||
tags=["prompt", "compel"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class CompelInvocation(BaseInvocation):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
@ -60,23 +66,21 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
context=context,
|
||||
tokenizer_info = context.get_model(
|
||||
**self.clip.tokenizer.model_dump(),
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
context=context,
|
||||
text_encoder_info = context.get_model(
|
||||
**self.clip.text_encoder.model_dump(),
|
||||
)
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.clip.loras:
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.get_model(**lora.model_dump(exclude={"weight"}))
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
# loras = [(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
# loras = [(context.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight) for lora in self.clip.loras]
|
||||
|
||||
ti_list = []
|
||||
for trigger in re.findall(r"<[a-zA-Z0-9., _-]+>", self.prompt):
|
||||
@ -85,11 +89,10 @@ class CompelInvocation(BaseInvocation):
|
||||
ti_list.append(
|
||||
(
|
||||
name,
|
||||
context.services.model_manager.get_model(
|
||||
context.get_model(
|
||||
model_name=name,
|
||||
base_model=self.clip.text_encoder.base_model,
|
||||
model_type=ModelType.TextualInversion,
|
||||
context=context,
|
||||
).context.model,
|
||||
)
|
||||
)
|
||||
@ -118,7 +121,7 @@ class CompelInvocation(BaseInvocation):
|
||||
|
||||
conjunction = Compel.parse_prompt_string(self.prompt)
|
||||
|
||||
if context.services.configuration.log_tokenization:
|
||||
if context.config.log_tokenization:
|
||||
log_tokenization_for_conjunction(conjunction, tokenizer)
|
||||
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
@ -139,8 +142,7 @@ class CompelInvocation(BaseInvocation):
|
||||
]
|
||||
)
|
||||
|
||||
conditioning_name = f"{context.graph_execution_state_id}_{self.id}_conditioning"
|
||||
context.services.latents.save(conditioning_name, conditioning_data)
|
||||
conditioning_name = context.save_conditioning(conditioning_data)
|
||||
|
||||
return ConditioningOutput(
|
||||
conditioning=ConditioningField(
|
||||
@ -160,11 +162,11 @@ class SDXLPromptInvocationBase:
|
||||
zero_on_empty: bool,
|
||||
):
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**clip_field.tokenizer.dict(),
|
||||
**clip_field.tokenizer.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**clip_field.text_encoder.dict(),
|
||||
**clip_field.text_encoder.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -172,7 +174,11 @@ class SDXLPromptInvocationBase:
|
||||
if prompt == "" and zero_on_empty:
|
||||
cpu_text_encoder = text_encoder_info.context.model
|
||||
c = torch.zeros(
|
||||
(1, cpu_text_encoder.config.max_position_embeddings, cpu_text_encoder.config.hidden_size),
|
||||
(
|
||||
1,
|
||||
cpu_text_encoder.config.max_position_embeddings,
|
||||
cpu_text_encoder.config.hidden_size,
|
||||
),
|
||||
dtype=text_encoder_info.context.cache.precision,
|
||||
)
|
||||
if get_pooled:
|
||||
@ -186,7 +192,9 @@ class SDXLPromptInvocationBase:
|
||||
|
||||
def _lora_loader():
|
||||
for lora in clip_field.loras:
|
||||
lora_info = context.services.model_manager.get_model(**lora.dict(exclude={"weight"}), context=context)
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.model_dump(exclude={"weight"}), context=context
|
||||
)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
@ -273,8 +281,16 @@ class SDXLPromptInvocationBase:
|
||||
class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
prompt: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
style: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
prompt: str = InputField(
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
style: str = InputField(
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
original_width: int = InputField(default=1024, description="")
|
||||
original_height: int = InputField(default=1024, description="")
|
||||
crop_top: int = InputField(default=0, description="")
|
||||
@ -310,7 +326,9 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
[
|
||||
c1,
|
||||
torch.zeros(
|
||||
(c1.shape[0], c2.shape[1] - c1.shape[1], c1.shape[2]), device=c1.device, dtype=c1.dtype
|
||||
(c1.shape[0], c2.shape[1] - c1.shape[1], c1.shape[2]),
|
||||
device=c1.device,
|
||||
dtype=c1.dtype,
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
@ -321,7 +339,9 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
[
|
||||
c2,
|
||||
torch.zeros(
|
||||
(c2.shape[0], c1.shape[1] - c2.shape[1], c2.shape[2]), device=c2.device, dtype=c2.dtype
|
||||
(c2.shape[0], c1.shape[1] - c2.shape[1], c2.shape[2]),
|
||||
device=c2.device,
|
||||
dtype=c2.dtype,
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
@ -359,7 +379,9 @@ class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
style: str = InputField(
|
||||
default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
ui_component=UIComponent.Textarea,
|
||||
) # TODO: ?
|
||||
original_width: int = InputField(default=1024, description="")
|
||||
original_height: int = InputField(default=1024, description="")
|
||||
@ -403,10 +425,16 @@ class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase
|
||||
class ClipSkipInvocationOutput(BaseInvocationOutput):
|
||||
"""Clip skip node output"""
|
||||
|
||||
clip: ClipField = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
|
||||
|
||||
@invocation("clip_skip", title="CLIP Skip", tags=["clipskip", "clip", "skip"], category="conditioning", version="1.0.0")
|
||||
@invocation(
|
||||
"clip_skip",
|
||||
title="CLIP Skip",
|
||||
tags=["clipskip", "clip", "skip"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ClipSkipInvocation(BaseInvocation):
|
||||
"""Skip layers in clip text_encoder model."""
|
||||
|
||||
@ -421,7 +449,9 @@ class ClipSkipInvocation(BaseInvocation):
|
||||
|
||||
|
||||
def get_max_token_count(
|
||||
tokenizer, prompt: Union[FlattenedPrompt, Blend, Conjunction], truncate_if_too_long=False
|
||||
tokenizer,
|
||||
prompt: Union[FlattenedPrompt, Blend, Conjunction],
|
||||
truncate_if_too_long=False,
|
||||
) -> int:
|
||||
if type(prompt) is Blend:
|
||||
blend: Blend = prompt
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
# initial implementation by Gregg Helt, 2023
|
||||
# heavily leverages controlnet_aux package: https://github.com/patrickvonplaten/controlnet_aux
|
||||
from builtins import bool, float
|
||||
from typing import Dict, List, Literal, Optional, Union
|
||||
from typing import Dict, List, Literal, Union
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
@ -24,12 +24,12 @@ from controlnet_aux import (
|
||||
)
|
||||
from controlnet_aux.util import HWC3, ade_palette
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field, validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
|
||||
from ...backend.model_management import BaseModelType
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
@ -57,6 +57,8 @@ class ControlNetModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the ControlNet model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class ControlField(BaseModel):
|
||||
image: ImageField = Field(description="The control image")
|
||||
@ -71,7 +73,7 @@ class ControlField(BaseModel):
|
||||
control_mode: CONTROLNET_MODE_VALUES = Field(default="balanced", description="The control mode to use")
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
@validator("control_weight")
|
||||
@field_validator("control_weight")
|
||||
def validate_control_weight(cls, v):
|
||||
"""Validate that all control weights in the valid range"""
|
||||
if isinstance(v, list):
|
||||
@ -124,9 +126,7 @@ class ControlNetInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"image_processor", title="Base Image Processor", tags=["controlnet"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
# This invocation exists for other invocations to subclass it - do not register with @invocation!
|
||||
class ImageProcessorInvocation(BaseInvocation):
|
||||
"""Base class for invocations that preprocess images for ControlNet"""
|
||||
|
||||
@ -393,9 +393,9 @@ class ContentShuffleImageProcessorInvocation(ImageProcessorInvocation):
|
||||
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
h: Optional[int] = InputField(default=512, ge=0, description="Content shuffle `h` parameter")
|
||||
w: Optional[int] = InputField(default=512, ge=0, description="Content shuffle `w` parameter")
|
||||
f: Optional[int] = InputField(default=256, ge=0, description="Content shuffle `f` parameter")
|
||||
h: int = InputField(default=512, ge=0, description="Content shuffle `h` parameter")
|
||||
w: int = InputField(default=512, ge=0, description="Content shuffle `w` parameter")
|
||||
f: int = InputField(default=256, ge=0, description="Content shuffle `f` parameter")
|
||||
|
||||
def run_processor(self, image):
|
||||
content_shuffle_processor = ContentShuffleDetector()
|
||||
@ -559,3 +559,33 @@ class SamDetectorReproducibleColors(SamDetector):
|
||||
img[:, :] = ann_color
|
||||
final_img.paste(Image.fromarray(img, mode="RGB"), (0, 0), Image.fromarray(np.uint8(m * 255)))
|
||||
return np.array(final_img, dtype=np.uint8)
|
||||
|
||||
|
||||
@invocation(
|
||||
"color_map_image_processor",
|
||||
title="Color Map Processor",
|
||||
tags=["controlnet"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorMapImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Generates a color map from the provided image"""
|
||||
|
||||
color_map_tile_size: int = InputField(default=64, ge=0, description=FieldDescriptions.tile_size)
|
||||
|
||||
def run_processor(self, image: Image.Image):
|
||||
image = image.convert("RGB")
|
||||
np_image = np.array(image, dtype=np.uint8)
|
||||
height, width = np_image.shape[:2]
|
||||
|
||||
width_tile_size = min(self.color_map_tile_size, width)
|
||||
height_tile_size = min(self.color_map_tile_size, height)
|
||||
|
||||
color_map = cv2.resize(
|
||||
np_image,
|
||||
(width // width_tile_size, height // height_tile_size),
|
||||
interpolation=cv2.INTER_CUBIC,
|
||||
)
|
||||
color_map = cv2.resize(color_map, (width, height), interpolation=cv2.INTER_NEAREST)
|
||||
color_map = Image.fromarray(color_map)
|
||||
return color_map
|
||||
|
||||
@ -6,7 +6,7 @@ import numpy
|
||||
from PIL import Image, ImageOps
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
724
invokeai/app/invocations/facetools.py
Normal file
724
invokeai/app/invocations/facetools.py
Normal file
@ -0,0 +1,724 @@
|
||||
import math
|
||||
import re
|
||||
from pathlib import Path
|
||||
from typing import Optional, TypedDict
|
||||
|
||||
import cv2
|
||||
import numpy as np
|
||||
from mediapipe.python.solutions.face_mesh import FaceMesh # type: ignore[import]
|
||||
from PIL import Image, ImageDraw, ImageFilter, ImageFont, ImageOps
|
||||
from PIL.Image import Image as ImageType
|
||||
from pydantic import field_validator
|
||||
|
||||
import invokeai.assets.fonts as font_assets
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
|
||||
|
||||
@invocation_output("face_mask_output")
|
||||
class FaceMaskOutput(ImageOutput):
|
||||
"""Base class for FaceMask output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
|
||||
|
||||
@invocation_output("face_off_output")
|
||||
class FaceOffOutput(ImageOutput):
|
||||
"""Base class for FaceOff Output"""
|
||||
|
||||
mask: ImageField = OutputField(description="The output mask")
|
||||
x: int = OutputField(description="The x coordinate of the bounding box's left side")
|
||||
y: int = OutputField(description="The y coordinate of the bounding box's top side")
|
||||
|
||||
|
||||
class FaceResultData(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
x_center: float
|
||||
y_center: float
|
||||
mesh_width: int
|
||||
mesh_height: int
|
||||
chunk_x_offset: int
|
||||
chunk_y_offset: int
|
||||
|
||||
|
||||
class FaceResultDataWithId(FaceResultData):
|
||||
face_id: int
|
||||
|
||||
|
||||
class ExtractFaceData(TypedDict):
|
||||
bounded_image: ImageType
|
||||
bounded_mask: ImageType
|
||||
x_min: int
|
||||
y_min: int
|
||||
x_max: int
|
||||
y_max: int
|
||||
|
||||
|
||||
class FaceMaskResult(TypedDict):
|
||||
image: ImageType
|
||||
mask: ImageType
|
||||
|
||||
|
||||
def create_white_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=255)
|
||||
|
||||
|
||||
def create_black_image(w: int, h: int) -> ImageType:
|
||||
return Image.new("L", (w, h), color=0)
|
||||
|
||||
|
||||
FONT_SIZE = 32
|
||||
FONT_STROKE_WIDTH = 4
|
||||
|
||||
|
||||
def coalesce_faces(face1: FaceResultData, face2: FaceResultData) -> FaceResultData:
|
||||
face1_x_offset = face1["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face2_x_offset = face2["chunk_x_offset"] - min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
face1_y_offset = face1["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
face2_y_offset = face2["chunk_y_offset"] - min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
|
||||
new_im_width = (
|
||||
max(face1["image"].width, face2["image"].width)
|
||||
+ max(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
- min(face1["chunk_x_offset"], face2["chunk_x_offset"])
|
||||
)
|
||||
new_im_height = (
|
||||
max(face1["image"].height, face2["image"].height)
|
||||
+ max(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
- min(face1["chunk_y_offset"], face2["chunk_y_offset"])
|
||||
)
|
||||
pil_image = Image.new(mode=face1["image"].mode, size=(new_im_width, new_im_height))
|
||||
pil_image.paste(face1["image"], (face1_x_offset, face1_y_offset))
|
||||
pil_image.paste(face2["image"], (face2_x_offset, face2_y_offset))
|
||||
|
||||
# Mask images are always from the origin
|
||||
new_mask_im_width = max(face1["mask"].width, face2["mask"].width)
|
||||
new_mask_im_height = max(face1["mask"].height, face2["mask"].height)
|
||||
mask_pil = create_white_image(new_mask_im_width, new_mask_im_height)
|
||||
black_image = create_black_image(face1["mask"].width, face1["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face1["mask"]))
|
||||
black_image = create_black_image(face2["mask"].width, face2["mask"].height)
|
||||
mask_pil.paste(black_image, (0, 0), ImageOps.invert(face2["mask"]))
|
||||
|
||||
new_face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil,
|
||||
x_center=max(face1["x_center"], face2["x_center"]),
|
||||
y_center=max(face1["y_center"], face2["y_center"]),
|
||||
mesh_width=max(face1["mesh_width"], face2["mesh_width"]),
|
||||
mesh_height=max(face1["mesh_height"], face2["mesh_height"]),
|
||||
chunk_x_offset=max(face1["chunk_x_offset"], face2["chunk_x_offset"]),
|
||||
chunk_y_offset=max(face2["chunk_y_offset"], face2["chunk_y_offset"]),
|
||||
)
|
||||
return new_face
|
||||
|
||||
|
||||
def prepare_faces_list(
|
||||
face_result_list: list[FaceResultData],
|
||||
) -> list[FaceResultDataWithId]:
|
||||
"""Deduplicates a list of faces, adding IDs to them."""
|
||||
deduped_faces: list[FaceResultData] = []
|
||||
|
||||
if len(face_result_list) == 0:
|
||||
return list()
|
||||
|
||||
for candidate in face_result_list:
|
||||
should_add = True
|
||||
candidate_x_center = candidate["x_center"]
|
||||
candidate_y_center = candidate["y_center"]
|
||||
for idx, face in enumerate(deduped_faces):
|
||||
face_center_x = face["x_center"]
|
||||
face_center_y = face["y_center"]
|
||||
face_radius_w = face["mesh_width"] / 2
|
||||
face_radius_h = face["mesh_height"] / 2
|
||||
# Determine if the center of the candidate_face is inside the ellipse of the added face
|
||||
# p < 1 -> Inside
|
||||
# p = 1 -> Exactly on the ellipse
|
||||
# p > 1 -> Outside
|
||||
p = (math.pow((candidate_x_center - face_center_x), 2) / math.pow(face_radius_w, 2)) + (
|
||||
math.pow((candidate_y_center - face_center_y), 2) / math.pow(face_radius_h, 2)
|
||||
)
|
||||
|
||||
if p < 1: # Inside of the already-added face's radius
|
||||
deduped_faces[idx] = coalesce_faces(face, candidate)
|
||||
should_add = False
|
||||
break
|
||||
|
||||
if should_add is True:
|
||||
deduped_faces.append(candidate)
|
||||
|
||||
sorted_faces = sorted(deduped_faces, key=lambda x: x["y_center"])
|
||||
sorted_faces = sorted(sorted_faces, key=lambda x: x["x_center"])
|
||||
|
||||
# add face_id for reference
|
||||
sorted_faces_with_ids: list[FaceResultDataWithId] = []
|
||||
face_id_counter = 0
|
||||
for face in sorted_faces:
|
||||
sorted_faces_with_ids.append(
|
||||
FaceResultDataWithId(
|
||||
**face,
|
||||
face_id=face_id_counter,
|
||||
)
|
||||
)
|
||||
face_id_counter += 1
|
||||
|
||||
return sorted_faces_with_ids
|
||||
|
||||
|
||||
def generate_face_box_mask(
|
||||
context: InvocationContext,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
pil_image: ImageType,
|
||||
chunk_x_offset: int = 0,
|
||||
chunk_y_offset: int = 0,
|
||||
draw_mesh: bool = True,
|
||||
) -> list[FaceResultData]:
|
||||
result = []
|
||||
mask_pil = None
|
||||
|
||||
# Convert the PIL image to a NumPy array.
|
||||
np_image = np.array(pil_image, dtype=np.uint8)
|
||||
|
||||
# Check if the input image has four channels (RGBA).
|
||||
if np_image.shape[2] == 4:
|
||||
# Convert RGBA to RGB by removing the alpha channel.
|
||||
np_image = np_image[:, :, :3]
|
||||
|
||||
# Create a FaceMesh object for face landmark detection and mesh generation.
|
||||
face_mesh = FaceMesh(
|
||||
max_num_faces=999,
|
||||
min_detection_confidence=minimum_confidence,
|
||||
min_tracking_confidence=minimum_confidence,
|
||||
)
|
||||
|
||||
# Detect the face landmarks and mesh in the input image.
|
||||
results = face_mesh.process(np_image)
|
||||
|
||||
# Check if any face is detected.
|
||||
if results.multi_face_landmarks: # type: ignore # this are via protobuf and not typed
|
||||
# Search for the face_id in the detected faces.
|
||||
for face_id, face_landmarks in enumerate(results.multi_face_landmarks): # type: ignore #this are via protobuf and not typed
|
||||
# Get the bounding box of the face mesh.
|
||||
x_coordinates = [landmark.x for landmark in face_landmarks.landmark]
|
||||
y_coordinates = [landmark.y for landmark in face_landmarks.landmark]
|
||||
x_min, x_max = min(x_coordinates), max(x_coordinates)
|
||||
y_min, y_max = min(y_coordinates), max(y_coordinates)
|
||||
|
||||
# Calculate the width and height of the face mesh.
|
||||
mesh_width = int((x_max - x_min) * np_image.shape[1])
|
||||
mesh_height = int((y_max - y_min) * np_image.shape[0])
|
||||
|
||||
# Get the center of the face.
|
||||
x_center = np.mean([landmark.x * np_image.shape[1] for landmark in face_landmarks.landmark])
|
||||
y_center = np.mean([landmark.y * np_image.shape[0] for landmark in face_landmarks.landmark])
|
||||
|
||||
face_landmark_points = np.array(
|
||||
[
|
||||
[landmark.x * np_image.shape[1], landmark.y * np_image.shape[0]]
|
||||
for landmark in face_landmarks.landmark
|
||||
]
|
||||
)
|
||||
|
||||
# Apply the scaling offsets to the face landmark points with a multiplier.
|
||||
scale_multiplier = 0.2
|
||||
x_center = np.mean(face_landmark_points[:, 0])
|
||||
y_center = np.mean(face_landmark_points[:, 1])
|
||||
|
||||
if draw_mesh:
|
||||
x_scaled = face_landmark_points[:, 0] + scale_multiplier * x_offset * (
|
||||
face_landmark_points[:, 0] - x_center
|
||||
)
|
||||
y_scaled = face_landmark_points[:, 1] + scale_multiplier * y_offset * (
|
||||
face_landmark_points[:, 1] - y_center
|
||||
)
|
||||
|
||||
convex_hull = cv2.convexHull(np.column_stack((x_scaled, y_scaled)).astype(np.int32))
|
||||
|
||||
# Generate a binary face mask using the face mesh.
|
||||
mask_image = np.ones(np_image.shape[:2], dtype=np.uint8) * 255
|
||||
cv2.fillConvexPoly(mask_image, convex_hull, 0)
|
||||
|
||||
# Convert the binary mask image to a PIL Image.
|
||||
init_mask_pil = Image.fromarray(mask_image, mode="L")
|
||||
w, h = init_mask_pil.size
|
||||
mask_pil = create_white_image(w + chunk_x_offset, h + chunk_y_offset)
|
||||
mask_pil.paste(init_mask_pil, (chunk_x_offset, chunk_y_offset))
|
||||
|
||||
x_center = float(x_center)
|
||||
y_center = float(y_center)
|
||||
face = FaceResultData(
|
||||
image=pil_image,
|
||||
mask=mask_pil or create_white_image(*pil_image.size),
|
||||
x_center=x_center + chunk_x_offset,
|
||||
y_center=y_center + chunk_y_offset,
|
||||
mesh_width=mesh_width,
|
||||
mesh_height=mesh_height,
|
||||
chunk_x_offset=chunk_x_offset,
|
||||
chunk_y_offset=chunk_y_offset,
|
||||
)
|
||||
|
||||
result.append(face)
|
||||
|
||||
return result
|
||||
|
||||
|
||||
def extract_face(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
face: FaceResultData,
|
||||
padding: int,
|
||||
) -> ExtractFaceData:
|
||||
mask = face["mask"]
|
||||
center_x = face["x_center"]
|
||||
center_y = face["y_center"]
|
||||
mesh_width = face["mesh_width"]
|
||||
mesh_height = face["mesh_height"]
|
||||
|
||||
# Determine the minimum size of the square crop
|
||||
min_size = min(mask.width, mask.height)
|
||||
|
||||
# Calculate the crop boundaries for the output image and mask.
|
||||
mesh_width += 128 + padding # add pixels to account for mask variance
|
||||
mesh_height += 128 + padding # add pixels to account for mask variance
|
||||
crop_size = min(
|
||||
max(mesh_width, mesh_height, 128), min_size
|
||||
) # Choose the smaller of the two (given value or face mask size)
|
||||
if crop_size > 128:
|
||||
crop_size = (crop_size + 7) // 8 * 8 # Ensure crop side is multiple of 8
|
||||
|
||||
# Calculate the actual crop boundaries within the bounds of the original image.
|
||||
x_min = int(center_x - crop_size / 2)
|
||||
y_min = int(center_y - crop_size / 2)
|
||||
x_max = int(center_x + crop_size / 2)
|
||||
y_max = int(center_y + crop_size / 2)
|
||||
|
||||
# Adjust the crop boundaries to stay within the original image's dimensions
|
||||
if x_min < 0:
|
||||
context.services.logger.warning("FaceTools --> -X-axis padding reached image edge.")
|
||||
x_max -= x_min
|
||||
x_min = 0
|
||||
elif x_max > mask.width:
|
||||
context.services.logger.warning("FaceTools --> +X-axis padding reached image edge.")
|
||||
x_min -= x_max - mask.width
|
||||
x_max = mask.width
|
||||
|
||||
if y_min < 0:
|
||||
context.services.logger.warning("FaceTools --> +Y-axis padding reached image edge.")
|
||||
y_max -= y_min
|
||||
y_min = 0
|
||||
elif y_max > mask.height:
|
||||
context.services.logger.warning("FaceTools --> -Y-axis padding reached image edge.")
|
||||
y_min -= y_max - mask.height
|
||||
y_max = mask.height
|
||||
|
||||
# Ensure the crop is square and adjust the boundaries if needed
|
||||
if x_max - x_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting x-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (x_max - x_min)
|
||||
x_min -= diff // 2
|
||||
x_max += diff - diff // 2
|
||||
|
||||
if y_max - y_min != crop_size:
|
||||
context.services.logger.warning("FaceTools --> Limiting y-axis padding to constrain bounding box to a square.")
|
||||
diff = crop_size - (y_max - y_min)
|
||||
y_min -= diff // 2
|
||||
y_max += diff - diff // 2
|
||||
|
||||
context.services.logger.info(f"FaceTools --> Calculated bounding box (8 multiple): {crop_size}")
|
||||
|
||||
# Crop the output image to the specified size with the center of the face mesh as the center.
|
||||
mask = mask.crop((x_min, y_min, x_max, y_max))
|
||||
bounded_image = image.crop((x_min, y_min, x_max, y_max))
|
||||
|
||||
# blur mask edge by small radius
|
||||
mask = mask.filter(ImageFilter.GaussianBlur(radius=2))
|
||||
|
||||
return ExtractFaceData(
|
||||
bounded_image=bounded_image,
|
||||
bounded_mask=mask,
|
||||
x_min=x_min,
|
||||
y_min=y_min,
|
||||
x_max=x_max,
|
||||
y_max=y_max,
|
||||
)
|
||||
|
||||
|
||||
def get_faces_list(
|
||||
context: InvocationContext,
|
||||
image: ImageType,
|
||||
should_chunk: bool,
|
||||
minimum_confidence: float,
|
||||
x_offset: float,
|
||||
y_offset: float,
|
||||
draw_mesh: bool = True,
|
||||
) -> list[FaceResultDataWithId]:
|
||||
result = []
|
||||
|
||||
# Generate the face box mask and get the center of the face.
|
||||
if not should_chunk:
|
||||
context.services.logger.info("FaceTools --> Attempting full image face detection.")
|
||||
result = generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image,
|
||||
chunk_x_offset=0,
|
||||
chunk_y_offset=0,
|
||||
draw_mesh=draw_mesh,
|
||||
)
|
||||
if should_chunk or len(result) == 0:
|
||||
context.services.logger.info("FaceTools --> Chunking image (chunk toggled on, or no face found in full image).")
|
||||
width, height = image.size
|
||||
image_chunks = []
|
||||
x_offsets = []
|
||||
y_offsets = []
|
||||
result = []
|
||||
|
||||
# If width == height, there's nothing more we can do... otherwise...
|
||||
if width > height:
|
||||
# Landscape - slice the image horizontally
|
||||
fx = 0.0
|
||||
steps = int(width * 2 / height) + 1
|
||||
increment = (width - height) / (steps - 1)
|
||||
while fx <= (width - height):
|
||||
x = int(fx)
|
||||
image_chunks.append(image.crop((x, 0, x + height, height)))
|
||||
x_offsets.append(x)
|
||||
y_offsets.append(0)
|
||||
fx += increment
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at x = {x}")
|
||||
elif height > width:
|
||||
# Portrait - slice the image vertically
|
||||
fy = 0.0
|
||||
steps = int(height * 2 / width) + 1
|
||||
increment = (height - width) / (steps - 1)
|
||||
while fy <= (height - width):
|
||||
y = int(fy)
|
||||
image_chunks.append(image.crop((0, y, width, y + width)))
|
||||
x_offsets.append(0)
|
||||
y_offsets.append(y)
|
||||
fy += increment
|
||||
context.services.logger.info(f"FaceTools --> Chunk starting at y = {y}")
|
||||
|
||||
for idx in range(len(image_chunks)):
|
||||
context.services.logger.info(f"FaceTools --> Evaluating faces in chunk {idx}")
|
||||
result = result + generate_face_box_mask(
|
||||
context=context,
|
||||
minimum_confidence=minimum_confidence,
|
||||
x_offset=x_offset,
|
||||
y_offset=y_offset,
|
||||
pil_image=image_chunks[idx],
|
||||
chunk_x_offset=x_offsets[idx],
|
||||
chunk_y_offset=y_offsets[idx],
|
||||
draw_mesh=draw_mesh,
|
||||
)
|
||||
|
||||
if len(result) == 0:
|
||||
# Give up
|
||||
context.services.logger.warning(
|
||||
"FaceTools --> No face detected in chunked input image. Passing through original image."
|
||||
)
|
||||
|
||||
all_faces = prepare_faces_list(result)
|
||||
|
||||
return all_faces
|
||||
|
||||
|
||||
@invocation("face_off", title="FaceOff", tags=["image", "faceoff", "face", "mask"], category="image", version="1.0.2")
|
||||
class FaceOffInvocation(BaseInvocation):
|
||||
"""Bound, extract, and mask a face from an image using MediaPipe detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image for face detection")
|
||||
face_id: int = InputField(
|
||||
default=0,
|
||||
ge=0,
|
||||
description="The face ID to process, numbered from 0. Multiple faces not supported. Find a face's ID with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="X-axis offset of the mask")
|
||||
y_offset: float = InputField(default=0.0, description="Y-axis offset of the mask")
|
||||
padding: int = InputField(default=0, description="All-axis padding around the mask in pixels")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceoff(self, context: InvocationContext, image: ImageType) -> Optional[ExtractFaceData]:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
if len(all_faces) == 0:
|
||||
context.services.logger.warning("FaceOff --> No faces detected. Passing through original image.")
|
||||
return None
|
||||
|
||||
if self.face_id > len(all_faces) - 1:
|
||||
context.services.logger.warning(
|
||||
f"FaceOff --> Face ID {self.face_id} is outside of the number of faces detected ({len(all_faces)}). Passing through original image."
|
||||
)
|
||||
return None
|
||||
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[self.face_id], padding=self.padding)
|
||||
# Convert the input image to RGBA mode to ensure it has an alpha channel.
|
||||
face_data["bounded_image"] = face_data["bounded_image"].convert("RGBA")
|
||||
|
||||
return face_data
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceOffOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.faceoff(context=context, image=image)
|
||||
|
||||
if result is None:
|
||||
result_image = image
|
||||
result_mask = create_white_image(*image.size)
|
||||
x = 0
|
||||
y = 0
|
||||
else:
|
||||
result_image = result["bounded_image"]
|
||||
result_mask = result["bounded_mask"]
|
||||
x = result["x_min"]
|
||||
y = result["y_min"]
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result_mask,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceOffOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
x=x,
|
||||
y=y,
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation("face_mask_detection", title="FaceMask", tags=["image", "face", "mask"], category="image", version="1.0.2")
|
||||
class FaceMaskInvocation(BaseInvocation):
|
||||
"""Face mask creation using mediapipe face detection"""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
face_ids: str = InputField(
|
||||
default="",
|
||||
description="Comma-separated list of face ids to mask eg '0,2,7'. Numbered from 0. Leave empty to mask all. Find face IDs with FaceIdentifier node.",
|
||||
)
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
x_offset: float = InputField(default=0.0, description="Offset for the X-axis of the face mask")
|
||||
y_offset: float = InputField(default=0.0, description="Offset for the Y-axis of the face mask")
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
invert_mask: bool = InputField(default=False, description="Toggle to invert the mask")
|
||||
|
||||
@field_validator("face_ids")
|
||||
def validate_comma_separated_ints(cls, v) -> str:
|
||||
comma_separated_ints_regex = re.compile(r"^\d*(,\d+)*$")
|
||||
if comma_separated_ints_regex.match(v) is None:
|
||||
raise ValueError('Face IDs must be a comma-separated list of integers (e.g. "1,2,3")')
|
||||
return v
|
||||
|
||||
def facemask(self, context: InvocationContext, image: ImageType) -> FaceMaskResult:
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=self.x_offset,
|
||||
y_offset=self.y_offset,
|
||||
draw_mesh=True,
|
||||
)
|
||||
|
||||
mask_pil = create_white_image(*image.size)
|
||||
|
||||
id_range = list(range(0, len(all_faces)))
|
||||
ids_to_extract = id_range
|
||||
if self.face_ids != "":
|
||||
parsed_face_ids = [int(id) for id in self.face_ids.split(",")]
|
||||
# get requested face_ids that are in range
|
||||
intersected_face_ids = set(parsed_face_ids) & set(id_range)
|
||||
|
||||
if len(intersected_face_ids) == 0:
|
||||
id_range_str = ",".join([str(id) for id in id_range])
|
||||
context.services.logger.warning(
|
||||
f"Face IDs must be in range of detected faces - requested {self.face_ids}, detected {id_range_str}. Passing through original image."
|
||||
)
|
||||
return FaceMaskResult(
|
||||
image=image, # original image
|
||||
mask=mask_pil, # white mask
|
||||
)
|
||||
|
||||
ids_to_extract = list(intersected_face_ids)
|
||||
|
||||
for face_id in ids_to_extract:
|
||||
face_data = extract_face(context=context, image=image, face=all_faces[face_id], padding=0)
|
||||
face_mask_pil = face_data["bounded_mask"]
|
||||
x_min = face_data["x_min"]
|
||||
y_min = face_data["y_min"]
|
||||
x_max = face_data["x_max"]
|
||||
y_max = face_data["y_max"]
|
||||
|
||||
mask_pil.paste(
|
||||
create_black_image(x_max - x_min, y_max - y_min),
|
||||
box=(x_min, y_min),
|
||||
mask=ImageOps.invert(face_mask_pil),
|
||||
)
|
||||
|
||||
if self.invert_mask:
|
||||
mask_pil = ImageOps.invert(mask_pil)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return FaceMaskResult(
|
||||
image=image,
|
||||
mask=mask_pil,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FaceMaskOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result = self.facemask(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result["image"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
mask_dto = context.services.images.create(
|
||||
image=result["mask"],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.MASK,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
output = FaceMaskOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
mask=ImageField(image_name=mask_dto.image_name),
|
||||
)
|
||||
|
||||
return output
|
||||
|
||||
|
||||
@invocation(
|
||||
"face_identifier", title="FaceIdentifier", tags=["image", "face", "identifier"], category="image", version="1.0.2"
|
||||
)
|
||||
class FaceIdentifierInvocation(BaseInvocation):
|
||||
"""Outputs an image with detected face IDs printed on each face. For use with other FaceTools."""
|
||||
|
||||
image: ImageField = InputField(description="Image to face detect")
|
||||
minimum_confidence: float = InputField(
|
||||
default=0.5, description="Minimum confidence for face detection (lower if detection is failing)"
|
||||
)
|
||||
chunk: bool = InputField(
|
||||
default=False,
|
||||
description="Whether to bypass full image face detection and default to image chunking. Chunking will occur if no faces are found in the full image.",
|
||||
)
|
||||
|
||||
def faceidentifier(self, context: InvocationContext, image: ImageType) -> ImageType:
|
||||
image = image.copy()
|
||||
|
||||
all_faces = get_faces_list(
|
||||
context=context,
|
||||
image=image,
|
||||
should_chunk=self.chunk,
|
||||
minimum_confidence=self.minimum_confidence,
|
||||
x_offset=0,
|
||||
y_offset=0,
|
||||
draw_mesh=False,
|
||||
)
|
||||
|
||||
# Note - font may be found either in the repo if running an editable install, or in the venv if running a package install
|
||||
font_path = [x for x in [Path(y, "inter/Inter-Regular.ttf") for y in font_assets.__path__] if x.exists()]
|
||||
font = ImageFont.truetype(font_path[0].as_posix(), FONT_SIZE)
|
||||
|
||||
# Paste face IDs on the output image
|
||||
draw = ImageDraw.Draw(image)
|
||||
for face in all_faces:
|
||||
x_coord = face["x_center"]
|
||||
y_coord = face["y_center"]
|
||||
text = str(face["face_id"])
|
||||
# get bbox of the text so we can center the id on the face
|
||||
_, _, bbox_w, bbox_h = draw.textbbox(xy=(0, 0), text=text, font=font, stroke_width=FONT_STROKE_WIDTH)
|
||||
x = x_coord - bbox_w / 2
|
||||
y = y_coord - bbox_h / 2
|
||||
draw.text(
|
||||
xy=(x, y),
|
||||
text=str(text),
|
||||
fill=(255, 255, 255, 255),
|
||||
font=font,
|
||||
stroke_width=FONT_STROKE_WIDTH,
|
||||
stroke_fill=(0, 0, 0, 255),
|
||||
)
|
||||
|
||||
# Create an RGBA image with transparency
|
||||
image = image.convert("RGBA")
|
||||
|
||||
return image
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
result_image = self.faceidentifier(context=context, image=image)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=result_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
@ -8,12 +8,12 @@ import numpy
|
||||
from PIL import Image, ImageChops, ImageFilter, ImageOps
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.invocations.primitives import BoardField, ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, Input, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("show_image", title="Show Image", tags=["image"], category="image", version="1.0.0")
|
||||
@ -36,7 +36,13 @@ class ShowImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("blank_image", title="Blank Image", tags=["image"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"blank_image",
|
||||
title="Blank Image",
|
||||
tags=["image"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class BlankImageInvocation(BaseInvocation):
|
||||
"""Creates a blank image and forwards it to the pipeline"""
|
||||
|
||||
@ -65,7 +71,13 @@ class BlankImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_crop", title="Crop Image", tags=["image", "crop"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_crop",
|
||||
title="Crop Image",
|
||||
tags=["image", "crop"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageCropInvocation(BaseInvocation):
|
||||
"""Crops an image to a specified box. The box can be outside of the image."""
|
||||
|
||||
@ -98,7 +110,13 @@ class ImageCropInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_paste", title="Paste Image", tags=["image", "paste"], category="image", version="1.0.1")
|
||||
@invocation(
|
||||
"img_paste",
|
||||
title="Paste Image",
|
||||
tags=["image", "paste"],
|
||||
category="image",
|
||||
version="1.0.1",
|
||||
)
|
||||
class ImagePasteInvocation(BaseInvocation):
|
||||
"""Pastes an image into another image."""
|
||||
|
||||
@ -151,7 +169,13 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("tomask", title="Mask from Alpha", tags=["image", "mask"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"tomask",
|
||||
title="Mask from Alpha",
|
||||
tags=["image", "mask"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskFromAlphaInvocation(BaseInvocation):
|
||||
"""Extracts the alpha channel of an image as a mask."""
|
||||
|
||||
@ -182,7 +206,13 @@ class MaskFromAlphaInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_mul", title="Multiply Images", tags=["image", "multiply"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_mul",
|
||||
title="Multiply Images",
|
||||
tags=["image", "multiply"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageMultiplyInvocation(BaseInvocation):
|
||||
"""Multiplies two images together using `PIL.ImageChops.multiply()`."""
|
||||
|
||||
@ -215,7 +245,13 @@ class ImageMultiplyInvocation(BaseInvocation):
|
||||
IMAGE_CHANNELS = Literal["A", "R", "G", "B"]
|
||||
|
||||
|
||||
@invocation("img_chan", title="Extract Image Channel", tags=["image", "channel"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_chan",
|
||||
title="Extract Image Channel",
|
||||
tags=["image", "channel"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageChannelInvocation(BaseInvocation):
|
||||
"""Gets a channel from an image."""
|
||||
|
||||
@ -247,7 +283,13 @@ class ImageChannelInvocation(BaseInvocation):
|
||||
IMAGE_MODES = Literal["L", "RGB", "RGBA", "CMYK", "YCbCr", "LAB", "HSV", "I", "F"]
|
||||
|
||||
|
||||
@invocation("img_conv", title="Convert Image Mode", tags=["image", "convert"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_conv",
|
||||
title="Convert Image Mode",
|
||||
tags=["image", "convert"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageConvertInvocation(BaseInvocation):
|
||||
"""Converts an image to a different mode."""
|
||||
|
||||
@ -276,7 +318,13 @@ class ImageConvertInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_blur", title="Blur Image", tags=["image", "blur"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_blur",
|
||||
title="Blur Image",
|
||||
tags=["image", "blur"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageBlurInvocation(BaseInvocation):
|
||||
"""Blurs an image"""
|
||||
|
||||
@ -330,7 +378,13 @@ PIL_RESAMPLING_MAP = {
|
||||
}
|
||||
|
||||
|
||||
@invocation("img_resize", title="Resize Image", tags=["image", "resize"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_resize",
|
||||
title="Resize Image",
|
||||
tags=["image", "resize"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageResizeInvocation(BaseInvocation):
|
||||
"""Resizes an image to specific dimensions"""
|
||||
|
||||
@ -343,7 +397,7 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
image = context.get_image(self.image.image_name)
|
||||
|
||||
resample_mode = PIL_RESAMPLING_MAP[self.resample_mode]
|
||||
|
||||
@ -352,25 +406,22 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
resample=resample_mode,
|
||||
)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=resize_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
image_name = context.save_image(image=resize_image)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
image=ImageField(image_name=image_name),
|
||||
width=resize_image.width,
|
||||
height=resize_image.height,
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_scale", title="Scale Image", tags=["image", "scale"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_scale",
|
||||
title="Scale Image",
|
||||
tags=["image", "scale"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageScaleInvocation(BaseInvocation):
|
||||
"""Scales an image by a factor"""
|
||||
|
||||
@ -411,7 +462,13 @@ class ImageScaleInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_lerp", title="Lerp Image", tags=["image", "lerp"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_lerp",
|
||||
title="Lerp Image",
|
||||
tags=["image", "lerp"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageLerpInvocation(BaseInvocation):
|
||||
"""Linear interpolation of all pixels of an image"""
|
||||
|
||||
@ -444,7 +501,13 @@ class ImageLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_ilerp", title="Inverse Lerp Image", tags=["image", "ilerp"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_ilerp",
|
||||
title="Inverse Lerp Image",
|
||||
tags=["image", "ilerp"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageInverseLerpInvocation(BaseInvocation):
|
||||
"""Inverse linear interpolation of all pixels of an image"""
|
||||
|
||||
@ -456,7 +519,7 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
image_arr = numpy.asarray(image, dtype=numpy.float32)
|
||||
image_arr = numpy.minimum(numpy.maximum(image_arr - self.min, 0) / float(self.max - self.min), 1) * 255
|
||||
image_arr = numpy.minimum(numpy.maximum(image_arr - self.min, 0) / float(self.max - self.min), 1) * 255 # type: ignore [assignment]
|
||||
|
||||
ilerp_image = Image.fromarray(numpy.uint8(image_arr))
|
||||
|
||||
@ -477,7 +540,13 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_nsfw", title="Blur NSFW Image", tags=["image", "nsfw"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_nsfw",
|
||||
title="Blur NSFW Image",
|
||||
tags=["image", "nsfw"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
"""Add blur to NSFW-flagged images"""
|
||||
|
||||
@ -505,7 +574,7 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -515,7 +584,7 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
def _get_caution_img(self) -> Image:
|
||||
def _get_caution_img(self) -> Image.Image:
|
||||
import invokeai.app.assets.images as image_assets
|
||||
|
||||
caution = Image.open(Path(image_assets.__path__[0]) / "caution.png")
|
||||
@ -523,7 +592,11 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"img_watermark", title="Add Invisible Watermark", tags=["image", "watermark"], category="image", version="1.0.0"
|
||||
"img_watermark",
|
||||
title="Add Invisible Watermark",
|
||||
tags=["image", "watermark"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageWatermarkInvocation(BaseInvocation):
|
||||
"""Add an invisible watermark to an image"""
|
||||
@ -544,7 +617,7 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -555,7 +628,13 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("mask_edge", title="Mask Edge", tags=["image", "mask", "inpaint"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"mask_edge",
|
||||
title="Mask Edge",
|
||||
tags=["image", "mask", "inpaint"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskEdgeInvocation(BaseInvocation):
|
||||
"""Applies an edge mask to an image"""
|
||||
|
||||
@ -601,7 +680,11 @@ class MaskEdgeInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"mask_combine", title="Combine Masks", tags=["image", "mask", "multiply"], category="image", version="1.0.0"
|
||||
"mask_combine",
|
||||
title="Combine Masks",
|
||||
tags=["image", "mask", "multiply"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MaskCombineInvocation(BaseInvocation):
|
||||
"""Combine two masks together by multiplying them using `PIL.ImageChops.multiply()`."""
|
||||
@ -632,7 +715,13 @@ class MaskCombineInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("color_correct", title="Color Correct", tags=["image", "color"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"color_correct",
|
||||
title="Color Correct",
|
||||
tags=["image", "color"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ColorCorrectInvocation(BaseInvocation):
|
||||
"""
|
||||
Shifts the colors of a target image to match the reference image, optionally
|
||||
@ -742,7 +831,13 @@ class ColorCorrectInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("img_hue_adjust", title="Adjust Image Hue", tags=["image", "hue"], category="image", version="1.0.0")
|
||||
@invocation(
|
||||
"img_hue_adjust",
|
||||
title="Adjust Image Hue",
|
||||
tags=["image", "hue"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageHueAdjustmentInvocation(BaseInvocation):
|
||||
"""Adjusts the Hue of an image."""
|
||||
|
||||
@ -972,14 +1067,15 @@ class ImageChannelMultiplyInvocation(BaseInvocation):
|
||||
title="Save Image",
|
||||
tags=["primitives", "image"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
version="1.0.1",
|
||||
use_cache=False,
|
||||
)
|
||||
class SaveImageInvocation(BaseInvocation):
|
||||
"""Saves an image. Unlike an image primitive, this invocation stores a copy of the image."""
|
||||
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
metadata: CoreMetadata = InputField(
|
||||
image: ImageField = InputField(description=FieldDescriptions.image)
|
||||
board: Optional[BoardField] = InputField(default=None, description=FieldDescriptions.board, input=Input.Direct)
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
ui_hidden=True,
|
||||
@ -992,10 +1088,11 @@ class SaveImageInvocation(BaseInvocation):
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
board_id=self.board.board_id if self.board else None,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
|
||||
@ -7,12 +7,12 @@ import numpy as np
|
||||
from PIL import Image, ImageOps
|
||||
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
from invokeai.backend.image_util.cv2_inpaint import cv2_inpaint
|
||||
from invokeai.backend.image_util.lama import LaMA
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
from .image import PIL_RESAMPLING_MAP, PIL_RESAMPLING_MODES
|
||||
|
||||
@ -269,7 +269,7 @@ class LaMaInfillInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint")
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class CV2InfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using OpenCV Inpainting"""
|
||||
|
||||
|
||||
@ -2,7 +2,7 @@ import os
|
||||
from builtins import float
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
@ -25,11 +25,15 @@ class IPAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the IP-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class CLIPVisionModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the CLIP Vision image encoder model")
|
||||
base_model: BaseModelType = Field(description="Base model (usually 'Any')")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
|
||||
@ -10,7 +10,7 @@ import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.models.adapter import FullAdapterXL, T2IAdapter
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@ -19,7 +19,7 @@ from diffusers.models.attention_processor import (
|
||||
)
|
||||
from diffusers.schedulers import DPMSolverSDEScheduler
|
||||
from diffusers.schedulers import SchedulerMixin as Scheduler
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
@ -33,6 +33,8 @@ from invokeai.app.invocations.primitives import (
|
||||
LatentsOutput,
|
||||
build_latents_output,
|
||||
)
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
@ -47,12 +49,12 @@ from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
T2IAdapterData,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
from ...backend.stable_diffusion.diffusion.shared_invokeai_diffusion import PostprocessingSettings
|
||||
from ...backend.stable_diffusion.schedulers import SCHEDULER_MAP
|
||||
from ...backend.util.devices import choose_precision, choose_torch_device
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
@ -82,12 +84,20 @@ class SchedulerOutput(BaseInvocationOutput):
|
||||
scheduler: SAMPLER_NAME_VALUES = OutputField(description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler)
|
||||
|
||||
|
||||
@invocation("scheduler", title="Scheduler", tags=["scheduler"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"scheduler",
|
||||
title="Scheduler",
|
||||
tags=["scheduler"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SchedulerInvocation(BaseInvocation):
|
||||
"""Selects a scheduler."""
|
||||
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler
|
||||
default="euler",
|
||||
description=FieldDescriptions.scheduler,
|
||||
ui_type=UIType.Scheduler,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SchedulerOutput:
|
||||
@ -95,7 +105,11 @@ class SchedulerInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"create_denoise_mask", title="Create Denoise Mask", tags=["mask", "denoise"], category="latents", version="1.0.0"
|
||||
"create_denoise_mask",
|
||||
title="Create Denoise Mask",
|
||||
tags=["mask", "denoise"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
"""Creates mask for denoising model run."""
|
||||
@ -104,7 +118,11 @@ class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
image: Optional[ImageField] = InputField(default=None, description="Image which will be masked", ui_order=1)
|
||||
mask: ImageField = InputField(description="The mask to use when pasting", ui_order=2)
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled, ui_order=3)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32, ui_order=4)
|
||||
fp32: bool = InputField(
|
||||
default=DEFAULT_PRECISION == "float32",
|
||||
description=FieldDescriptions.fp32,
|
||||
ui_order=4,
|
||||
)
|
||||
|
||||
def prep_mask_tensor(self, mask_image):
|
||||
if mask_image.mode != "L":
|
||||
@ -132,7 +150,7 @@ class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
|
||||
if image is not None:
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -164,9 +182,8 @@ def get_scheduler(
|
||||
seed: int,
|
||||
) -> Scheduler:
|
||||
scheduler_class, scheduler_extra_config = SCHEDULER_MAP.get(scheduler_name, SCHEDULER_MAP["ddim"])
|
||||
orig_scheduler_info = context.services.model_manager.get_model(
|
||||
**scheduler_info.dict(),
|
||||
context=context,
|
||||
orig_scheduler_info = context.get_model(
|
||||
**scheduler_info.model_dump(),
|
||||
)
|
||||
with orig_scheduler_info as orig_scheduler:
|
||||
scheduler_config = orig_scheduler.config
|
||||
@ -196,7 +213,7 @@ def get_scheduler(
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.1.0",
|
||||
version="1.3.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
@ -207,31 +224,64 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
negative_conditioning: ConditioningField = InputField(
|
||||
description=FieldDescriptions.negative_cond, input=Input.Connection, ui_order=1
|
||||
)
|
||||
noise: Optional[LatentsField] = InputField(description=FieldDescriptions.noise, input=Input.Connection, ui_order=3)
|
||||
noise: Optional[LatentsField] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.noise,
|
||||
input=Input.Connection,
|
||||
ui_order=3,
|
||||
)
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
cfg_scale: Union[float, List[float]] = InputField(
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, title="CFG Scale"
|
||||
)
|
||||
denoising_start: float = InputField(default=0.0, ge=0, le=1, description=FieldDescriptions.denoising_start)
|
||||
denoising_start: float = InputField(
|
||||
default=0.0,
|
||||
ge=0,
|
||||
le=1,
|
||||
description=FieldDescriptions.denoising_start,
|
||||
)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler
|
||||
default="euler",
|
||||
description=FieldDescriptions.scheduler,
|
||||
ui_type=UIType.Scheduler,
|
||||
)
|
||||
unet: UNetField = InputField(description=FieldDescriptions.unet, input=Input.Connection, title="UNet", ui_order=2)
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
unet: UNetField = InputField(
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
ui_order=2,
|
||||
)
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[IPAdapterField] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.ip_adapter,
|
||||
title="IP-Adapter",
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=6,
|
||||
)
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]] = InputField(
|
||||
description=FieldDescriptions.t2i_adapter,
|
||||
title="T2I-Adapter",
|
||||
default=None,
|
||||
input=Input.Connection,
|
||||
ui_order=7,
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(
|
||||
default=None, description=FieldDescriptions.latents, input=Input.Connection
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=7
|
||||
default=None,
|
||||
description=FieldDescriptions.mask,
|
||||
input=Input.Connection,
|
||||
ui_order=8,
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@field_validator("cfg_scale")
|
||||
def ge_one(cls, v):
|
||||
"""validate that all cfg_scale values are >= 1"""
|
||||
if isinstance(v, list):
|
||||
@ -247,15 +297,12 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def dispatch_progress(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
source_node_id: str,
|
||||
intermediate_state: PipelineIntermediateState,
|
||||
base_model: BaseModelType,
|
||||
) -> None:
|
||||
stable_diffusion_step_callback(
|
||||
context=context,
|
||||
intermediate_state=intermediate_state,
|
||||
node=self.dict(),
|
||||
source_node_id=source_node_id,
|
||||
base_model=base_model,
|
||||
)
|
||||
|
||||
@ -266,11 +313,11 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
unet,
|
||||
seed,
|
||||
) -> ConditioningData:
|
||||
positive_cond_data = context.services.latents.get(self.positive_conditioning.conditioning_name)
|
||||
positive_cond_data = context.get_conditioning(self.positive_conditioning.conditioning_name)
|
||||
c = positive_cond_data.conditionings[0].to(device=unet.device, dtype=unet.dtype)
|
||||
extra_conditioning_info = c.extra_conditioning
|
||||
|
||||
negative_cond_data = context.services.latents.get(self.negative_conditioning.conditioning_name)
|
||||
negative_cond_data = context.get_conditioning(self.negative_conditioning.conditioning_name)
|
||||
uc = negative_cond_data.conditionings[0].to(device=unet.device, dtype=unet.dtype)
|
||||
|
||||
conditioning_data = ConditioningData(
|
||||
@ -357,17 +404,16 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
controlnet_data = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
context.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
# control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
input_image = context.get_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
@ -404,52 +450,148 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[IPAdapterField],
|
||||
ip_adapter: Optional[Union[IPAdapterField, list[IPAdapterField]]],
|
||||
conditioning_data: ConditioningData,
|
||||
unet: UNet2DConditionModel,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[IPAdapterData]:
|
||||
) -> Optional[list[IPAdapterData]]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
# ip_adapter could be a list or a single IPAdapterField. Normalize to a list here.
|
||||
if not isinstance(ip_adapter, list):
|
||||
ip_adapter = [ip_adapter]
|
||||
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
if len(ip_adapter) == 0:
|
||||
return None
|
||||
|
||||
input_image = context.services.images.get_pil_image(ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning = IPAdapterConditioningInfo(
|
||||
image_prompt_embeds, uncond_image_prompt_embeds
|
||||
ip_adapter_data_list = []
|
||||
conditioning_data.ip_adapter_conditioning = []
|
||||
for single_ip_adapter in ip_adapter:
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.get_model(
|
||||
model_name=single_ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=single_ip_adapter.ip_adapter_model.base_model,
|
||||
)
|
||||
)
|
||||
|
||||
return IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=ip_adapter.weight,
|
||||
begin_step_percent=ip_adapter.begin_step_percent,
|
||||
end_step_percent=ip_adapter.end_step_percent,
|
||||
)
|
||||
image_encoder_model_info = context.get_model(
|
||||
model_name=single_ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=single_ip_adapter.image_encoder_model.base_model,
|
||||
)
|
||||
|
||||
input_image = context.get_image(single_ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
(
|
||||
image_prompt_embeds,
|
||||
uncond_image_prompt_embeds,
|
||||
) = ip_adapter_model.get_image_embeds(input_image, image_encoder_model)
|
||||
conditioning_data.ip_adapter_conditioning.append(
|
||||
IPAdapterConditioningInfo(image_prompt_embeds, uncond_image_prompt_embeds)
|
||||
)
|
||||
|
||||
ip_adapter_data_list.append(
|
||||
IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=single_ip_adapter.weight,
|
||||
begin_step_percent=single_ip_adapter.begin_step_percent,
|
||||
end_step_percent=single_ip_adapter.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return ip_adapter_data_list
|
||||
|
||||
def run_t2i_adapters(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
t2i_adapter: Optional[Union[T2IAdapterField, list[T2IAdapterField]]],
|
||||
latents_shape: list[int],
|
||||
do_classifier_free_guidance: bool,
|
||||
) -> Optional[list[T2IAdapterData]]:
|
||||
if t2i_adapter is None:
|
||||
return None
|
||||
|
||||
# Handle the possibility that t2i_adapter could be a list or a single T2IAdapterField.
|
||||
if isinstance(t2i_adapter, T2IAdapterField):
|
||||
t2i_adapter = [t2i_adapter]
|
||||
|
||||
if len(t2i_adapter) == 0:
|
||||
return None
|
||||
|
||||
t2i_adapter_data = []
|
||||
for t2i_adapter_field in t2i_adapter:
|
||||
t2i_adapter_model_info = context.get_model(
|
||||
model_name=t2i_adapter_field.t2i_adapter_model.model_name,
|
||||
model_type=ModelType.T2IAdapter,
|
||||
base_model=t2i_adapter_field.t2i_adapter_model.base_model,
|
||||
)
|
||||
image = context.get_image(t2i_adapter_field.image.image_name)
|
||||
|
||||
# The max_unet_downscale is the maximum amount that the UNet model downscales the latent image internally.
|
||||
if t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusion1:
|
||||
max_unet_downscale = 8
|
||||
elif t2i_adapter_field.t2i_adapter_model.base_model == BaseModelType.StableDiffusionXL:
|
||||
max_unet_downscale = 4
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Unexpected T2I-Adapter base model type: '{t2i_adapter_field.t2i_adapter_model.base_model}'."
|
||||
)
|
||||
|
||||
t2i_adapter_model: T2IAdapter
|
||||
with t2i_adapter_model_info as t2i_adapter_model:
|
||||
total_downscale_factor = t2i_adapter_model.total_downscale_factor
|
||||
if isinstance(t2i_adapter_model.adapter, FullAdapterXL):
|
||||
# HACK(ryand): Work around a bug in FullAdapterXL. This is being addressed upstream in diffusers by
|
||||
# this PR: https://github.com/huggingface/diffusers/pull/5134.
|
||||
total_downscale_factor = total_downscale_factor // 2
|
||||
|
||||
# Resize the T2I-Adapter input image.
|
||||
# We select the resize dimensions so that after the T2I-Adapter's total_downscale_factor is applied, the
|
||||
# result will match the latent image's dimensions after max_unet_downscale is applied.
|
||||
t2i_input_height = latents_shape[2] // max_unet_downscale * total_downscale_factor
|
||||
t2i_input_width = latents_shape[3] // max_unet_downscale * total_downscale_factor
|
||||
|
||||
# Note: We have hard-coded `do_classifier_free_guidance=False`. This is because we only want to prepare
|
||||
# a single image. If CFG is enabled, we will duplicate the resultant tensor after applying the
|
||||
# T2I-Adapter model.
|
||||
#
|
||||
# Note: We re-use the `prepare_control_image(...)` from ControlNet for T2I-Adapter, because it has many
|
||||
# of the same requirements (e.g. preserving binary masks during resize).
|
||||
t2i_image = prepare_control_image(
|
||||
image=image,
|
||||
do_classifier_free_guidance=False,
|
||||
width=t2i_input_width,
|
||||
height=t2i_input_height,
|
||||
num_channels=t2i_adapter_model.config.in_channels,
|
||||
device=t2i_adapter_model.device,
|
||||
dtype=t2i_adapter_model.dtype,
|
||||
resize_mode=t2i_adapter_field.resize_mode,
|
||||
)
|
||||
|
||||
adapter_state = t2i_adapter_model(t2i_image)
|
||||
|
||||
if do_classifier_free_guidance:
|
||||
for idx, value in enumerate(adapter_state):
|
||||
adapter_state[idx] = torch.cat([value] * 2, dim=0)
|
||||
|
||||
t2i_adapter_data.append(
|
||||
T2IAdapterData(
|
||||
adapter_state=adapter_state,
|
||||
weight=t2i_adapter_field.weight,
|
||||
begin_step_percent=t2i_adapter_field.begin_step_percent,
|
||||
end_step_percent=t2i_adapter_field.end_step_percent,
|
||||
)
|
||||
)
|
||||
|
||||
return t2i_adapter_data
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
@ -501,11 +643,11 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
seed = None
|
||||
noise = None
|
||||
if self.noise is not None:
|
||||
noise = context.services.latents.get(self.noise.latents_name)
|
||||
noise = context.get_latents(self.noise.latents_name)
|
||||
seed = self.noise.seed
|
||||
|
||||
if self.latents is not None:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
latents = context.get_latents(self.latents.latents_name)
|
||||
if seed is None:
|
||||
seed = self.latents.seed
|
||||
|
||||
@ -522,26 +664,29 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
|
||||
mask, masked_latents = self.prep_inpaint_mask(context, latents)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[self.id]
|
||||
# TODO(ryand): I have hard-coded `do_classifier_free_guidance=True` to mirror the behaviour of ControlNets,
|
||||
# below. Investigate whether this is appropriate.
|
||||
t2i_adapter_data = self.run_t2i_adapters(
|
||||
context,
|
||||
self.t2i_adapter,
|
||||
latents.shape,
|
||||
do_classifier_free_guidance=True,
|
||||
)
|
||||
|
||||
def step_callback(state: PipelineIntermediateState):
|
||||
self.dispatch_progress(context, source_node_id, state, self.unet.unet.base_model)
|
||||
self.dispatch_progress(context, state, self.unet.unet.base_model)
|
||||
|
||||
def _lora_loader():
|
||||
for lora in self.unet.loras:
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.dict(exclude={"weight"}),
|
||||
context=context,
|
||||
lora_info = context.get_model(
|
||||
**lora.model_dump(exclude={"weight"}),
|
||||
)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
return
|
||||
|
||||
unet_info = context.services.model_manager.get_model(
|
||||
**self.unet.unet.dict(),
|
||||
context=context,
|
||||
unet_info = context.get_model(
|
||||
**self.unet.unet.model_dump(),
|
||||
)
|
||||
with (
|
||||
ExitStack() as exit_stack,
|
||||
@ -580,7 +725,6 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
unet=unet,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
@ -592,7 +736,10 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
denoising_end=self.denoising_end,
|
||||
)
|
||||
|
||||
result_latents, result_attention_map_saver = pipeline.latents_from_embeddings(
|
||||
(
|
||||
result_latents,
|
||||
result_attention_map_saver,
|
||||
) = pipeline.latents_from_embeddings(
|
||||
latents=latents,
|
||||
timesteps=timesteps,
|
||||
init_timestep=init_timestep,
|
||||
@ -602,8 +749,9 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=controlnet_data, # list[ControlNetData],
|
||||
ip_adapter_data=ip_adapter_data, # IPAdapterData,
|
||||
control_data=controlnet_data,
|
||||
ip_adapter_data=ip_adapter_data,
|
||||
t2i_adapter_data=t2i_adapter_data,
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
@ -613,13 +761,16 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
context.services.latents.save(name, result_latents)
|
||||
return build_latents_output(latents_name=name, latents=result_latents, seed=seed)
|
||||
latents_name = context.save_latents(result_latents)
|
||||
return build_latents_output(latents_name=latents_name, latents=result_latents, seed=seed)
|
||||
|
||||
|
||||
@invocation(
|
||||
"l2i", title="Latents to Image", tags=["latents", "image", "vae", "l2i"], category="latents", version="1.0.0"
|
||||
"l2i",
|
||||
title="Latents to Image",
|
||||
tags=["latents", "image", "vae", "l2i"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LatentsToImageInvocation(BaseInvocation):
|
||||
"""Generates an image from latents."""
|
||||
@ -634,7 +785,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
)
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32)
|
||||
metadata: CoreMetadata = InputField(
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
ui_hidden=True,
|
||||
@ -642,11 +793,10 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
latents = context.get_latents(self.latents.latents_name)
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
vae_info = context.get_model(
|
||||
**self.vae.vae.model_dump(),
|
||||
)
|
||||
|
||||
with set_seamless(vae_info.context.model, self.vae.seamless_axes), vae_info as vae:
|
||||
@ -676,7 +826,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
vae.to(dtype=torch.float16)
|
||||
latents = latents.half()
|
||||
|
||||
if self.tiled or context.services.configuration.tiled_decode:
|
||||
if self.tiled or context.config.tiled_decode:
|
||||
vae.enable_tiling()
|
||||
else:
|
||||
vae.disable_tiling()
|
||||
@ -700,28 +850,25 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
image_name = context.save_image(image, category=context.categories.GENERAL)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
image=ImageField(image_name=image_name),
|
||||
width=image.width,
|
||||
height=image.height,
|
||||
)
|
||||
|
||||
|
||||
LATENTS_INTERPOLATION_MODE = Literal["nearest", "linear", "bilinear", "bicubic", "trilinear", "area", "nearest-exact"]
|
||||
|
||||
|
||||
@invocation("lresize", title="Resize Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lresize",
|
||||
title="Resize Latents",
|
||||
tags=["latents", "resize"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ResizeLatentsInvocation(BaseInvocation):
|
||||
"""Resizes latents to explicit width/height (in pixels). Provided dimensions are floor-divided by 8."""
|
||||
|
||||
@ -767,7 +914,13 @@ class ResizeLatentsInvocation(BaseInvocation):
|
||||
return build_latents_output(latents_name=name, latents=resized_latents, seed=self.latents.seed)
|
||||
|
||||
|
||||
@invocation("lscale", title="Scale Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lscale",
|
||||
title="Scale Latents",
|
||||
tags=["latents", "resize"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ScaleLatentsInvocation(BaseInvocation):
|
||||
"""Scales latents by a given factor."""
|
||||
|
||||
@ -806,7 +959,11 @@ class ScaleLatentsInvocation(BaseInvocation):
|
||||
|
||||
|
||||
@invocation(
|
||||
"i2l", title="Image to Latents", tags=["latents", "image", "vae", "i2l"], category="latents", version="1.0.0"
|
||||
"i2l",
|
||||
title="Image to Latents",
|
||||
tags=["latents", "image", "vae", "i2l"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageToLatentsInvocation(BaseInvocation):
|
||||
"""Encodes an image into latents."""
|
||||
@ -870,7 +1027,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
@ -898,7 +1055,13 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
return vae.encode(image_tensor).latents
|
||||
|
||||
|
||||
@invocation("lblend", title="Blend Latents", tags=["latents", "blend"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"lblend",
|
||||
title="Blend Latents",
|
||||
tags=["latents", "blend"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class BlendLatentsInvocation(BaseInvocation):
|
||||
"""Blend two latents using a given alpha. Latents must have same size."""
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import FloatOutput, IntegerOutput
|
||||
|
||||
@ -65,13 +65,34 @@ class DivideInvocation(BaseInvocation):
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
low: int = InputField(default=0, description=FieldDescriptions.inclusive_low)
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description=FieldDescriptions.exclusive_high)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation(
|
||||
"rand_float",
|
||||
title="Random Float",
|
||||
tags=["math", "float", "random"],
|
||||
category="math",
|
||||
version="1.0.1",
|
||||
use_cache=False,
|
||||
)
|
||||
class RandomFloatInvocation(BaseInvocation):
|
||||
"""Outputs a single random float"""
|
||||
|
||||
low: float = InputField(default=0.0, description=FieldDescriptions.inclusive_low)
|
||||
high: float = InputField(default=1.0, description=FieldDescriptions.exclusive_high)
|
||||
decimals: int = InputField(default=2, description=FieldDescriptions.decimal_places)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
random_float = np.random.uniform(self.low, self.high)
|
||||
rounded_float = round(random_float, self.decimals)
|
||||
return FloatOutput(value=rounded_float)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
@ -164,7 +185,7 @@ class IntegerMathInvocation(BaseInvocation):
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
@field_validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
@ -238,7 +259,7 @@ class FloatMathInvocation(BaseInvocation):
|
||||
a: float = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: float = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
@field_validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
|
||||
@ -12,7 +12,10 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterModelField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.app.invocations.t2i_adapter import T2IAdapterField
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
from ...version import __version__
|
||||
@ -25,30 +28,47 @@ class LoRAMetadataField(BaseModelExcludeNull):
|
||||
weight: float = Field(description="The weight of the LoRA model")
|
||||
|
||||
|
||||
class IPAdapterMetadataField(BaseModelExcludeNull):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
weight: float = Field(description="The weight of the IP-Adapter model")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
class CoreMetadata(BaseModelExcludeNull):
|
||||
"""Core generation metadata for an image generated in InvokeAI."""
|
||||
|
||||
app_version: str = Field(default=__version__, description="The version of InvokeAI used to generate this image")
|
||||
generation_mode: str = Field(
|
||||
generation_mode: Optional[str] = Field(
|
||||
default=None,
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
created_by: Optional[str] = Field(description="The name of the creator of the image")
|
||||
positive_prompt: str = Field(description="The positive prompt parameter")
|
||||
negative_prompt: str = Field(description="The negative prompt parameter")
|
||||
width: int = Field(description="The width parameter")
|
||||
height: int = Field(description="The height parameter")
|
||||
seed: int = Field(description="The seed used for noise generation")
|
||||
rand_device: str = Field(description="The device used for random number generation")
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
positive_prompt: Optional[str] = Field(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = Field(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = Field(default=None, description="The width parameter")
|
||||
height: Optional[int] = Field(default=None, description="The height parameter")
|
||||
seed: Optional[int] = Field(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = Field(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = Field(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = Field(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = Field(default=None, description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = Field(description="The ControlNets used for inference")
|
||||
loras: list[LoRAMetadataField] = Field(description="The LoRAs used for inference")
|
||||
model: Optional[MainModelField] = Field(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = Field(default=None, description="The ControlNets used for inference")
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = Field(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = Field(default=None, description="The IP Adapters used for inference")
|
||||
loras: Optional[list[LoRAMetadataField]] = Field(default=None, description="The LoRAs used for inference")
|
||||
vae: Optional[VAEModelField] = Field(
|
||||
default=None,
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
@ -105,25 +125,34 @@ class MetadataAccumulatorOutput(BaseInvocationOutput):
|
||||
class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
"""Outputs a Core Metadata Object"""
|
||||
|
||||
generation_mode: str = InputField(
|
||||
generation_mode: Optional[str] = InputField(
|
||||
default=None,
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
positive_prompt: str = InputField(description="The positive prompt parameter")
|
||||
negative_prompt: str = InputField(description="The negative prompt parameter")
|
||||
width: int = InputField(description="The width parameter")
|
||||
height: int = InputField(description="The height parameter")
|
||||
seed: int = InputField(description="The seed used for noise generation")
|
||||
rand_device: str = InputField(description="The device used for random number generation")
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = Field(
|
||||
positive_prompt: Optional[str] = InputField(default=None, description="The positive prompt parameter")
|
||||
negative_prompt: Optional[str] = InputField(default=None, description="The negative prompt parameter")
|
||||
width: Optional[int] = InputField(default=None, description="The width parameter")
|
||||
height: Optional[int] = InputField(default=None, description="The height parameter")
|
||||
seed: Optional[int] = InputField(default=None, description="The seed used for noise generation")
|
||||
rand_device: Optional[str] = InputField(default=None, description="The device used for random number generation")
|
||||
cfg_scale: Optional[float] = InputField(default=None, description="The classifier-free guidance scale parameter")
|
||||
steps: Optional[int] = InputField(default=None, description="The number of steps used for inference")
|
||||
scheduler: Optional[str] = InputField(default=None, description="The scheduler used for inference")
|
||||
clip_skip: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
controlnets: list[ControlField] = InputField(description="The ControlNets used for inference")
|
||||
loras: list[LoRAMetadataField] = InputField(description="The LoRAs used for inference")
|
||||
model: Optional[MainModelField] = InputField(default=None, description="The main model used for inference")
|
||||
controlnets: Optional[list[ControlField]] = InputField(
|
||||
default=None, description="The ControlNets used for inference"
|
||||
)
|
||||
ipAdapters: Optional[list[IPAdapterMetadataField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
t2iAdapters: Optional[list[T2IAdapterField]] = InputField(
|
||||
default=None, description="The IP Adapters used for inference"
|
||||
)
|
||||
loras: Optional[list[LoRAMetadataField]] = InputField(default=None, description="The LoRAs used for inference")
|
||||
strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The strength used for latents-to-latents",
|
||||
@ -137,6 +166,20 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
description="The VAE used for decoding, if the main model's default was not used",
|
||||
)
|
||||
|
||||
# High resolution fix metadata.
|
||||
hrf_width: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_height: Optional[int] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix height and width multipler.",
|
||||
)
|
||||
hrf_strength: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The high resolution fix img2img strength used in the upscale pass.",
|
||||
)
|
||||
|
||||
# SDXL
|
||||
positive_style_prompt: Optional[str] = InputField(
|
||||
default=None,
|
||||
@ -180,4 +223,4 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
def invoke(self, context: InvocationContext) -> MetadataAccumulatorOutput:
|
||||
"""Collects and outputs a CoreMetadata object"""
|
||||
|
||||
return MetadataAccumulatorOutput(metadata=CoreMetadata(**self.dict()))
|
||||
return MetadataAccumulatorOutput(metadata=CoreMetadata(**self.model_dump()))
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
import copy
|
||||
from typing import List, Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from ...backend.model_management import BaseModelType, ModelType, SubModelType
|
||||
from .baseinvocation import (
|
||||
@ -24,6 +24,8 @@ class ModelInfo(BaseModel):
|
||||
model_type: ModelType = Field(description="Info to load submodel")
|
||||
submodel: Optional[SubModelType] = Field(default=None, description="Info to load submodel")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class LoraInfo(ModelInfo):
|
||||
weight: float = Field(description="Lora's weight which to use when apply to model")
|
||||
@ -65,6 +67,8 @@ class MainModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class LoRAModelField(BaseModel):
|
||||
"""LoRA model field"""
|
||||
@ -72,8 +76,16 @@ class LoRAModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the LoRA model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
@invocation("main_model_loader", title="Main Model", tags=["model"], category="model", version="1.0.0")
|
||||
|
||||
@invocation(
|
||||
"main_model_loader",
|
||||
title="Main Model",
|
||||
tags=["model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MainModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a main model, outputting its submodels."""
|
||||
|
||||
@ -86,7 +98,7 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
model_type = ModelType.Main
|
||||
|
||||
# TODO: not found exceptions
|
||||
if not context.services.model_manager.model_exists(
|
||||
if not context.model_exists(
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
model_type=model_type,
|
||||
@ -180,10 +192,16 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
clip: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> LoraLoaderOutput:
|
||||
@ -244,20 +262,35 @@ class SDXLLoraLoaderOutput(BaseInvocationOutput):
|
||||
clip2: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP 2")
|
||||
|
||||
|
||||
@invocation("sdxl_lora_loader", title="SDXL LoRA", tags=["lora", "model"], category="model", version="1.0.0")
|
||||
@invocation(
|
||||
"sdxl_lora_loader",
|
||||
title="SDXL LoRA",
|
||||
tags=["lora", "model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
clip: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 1"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP 1",
|
||||
)
|
||||
clip2: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 2"
|
||||
default=None,
|
||||
description=FieldDescriptions.clip,
|
||||
input=Input.Connection,
|
||||
title="CLIP 2",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SDXLLoraLoaderOutput:
|
||||
@ -330,6 +363,8 @@ class VAEModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@invocation_output("vae_loader_output")
|
||||
class VaeLoaderOutput(BaseInvocationOutput):
|
||||
@ -343,7 +378,10 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput"""
|
||||
|
||||
vae_model: VAEModelField = InputField(
|
||||
description=FieldDescriptions.vae_model, input=Input.Direct, ui_type=UIType.VaeModel, title="VAE"
|
||||
description=FieldDescriptions.vae_model,
|
||||
input=Input.Direct,
|
||||
ui_type=UIType.VaeModel,
|
||||
title="VAE",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> VaeLoaderOutput:
|
||||
@ -372,19 +410,31 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
class SeamlessModeOutput(BaseInvocationOutput):
|
||||
"""Modified Seamless Model output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(default=None, description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@invocation("seamless", title="Seamless", tags=["seamless", "model"], category="model", version="1.0.0")
|
||||
@invocation(
|
||||
"seamless",
|
||||
title="Seamless",
|
||||
tags=["seamless", "model"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SeamlessModeInvocation(BaseInvocation):
|
||||
"""Applies the seamless transformation to the Model UNet and VAE."""
|
||||
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
default=None,
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
title="UNet",
|
||||
)
|
||||
vae: Optional[VaeField] = InputField(
|
||||
default=None, description=FieldDescriptions.vae_model, input=Input.Connection, title="VAE"
|
||||
default=None,
|
||||
description=FieldDescriptions.vae_model,
|
||||
input=Input.Connection,
|
||||
title="VAE",
|
||||
)
|
||||
seamless_y: bool = InputField(default=True, input=Input.Any, description="Specify whether Y axis is seamless")
|
||||
seamless_x: bool = InputField(default=True, input=Input.Any, description="Specify whether X axis is seamless")
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
|
||||
import torch
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.latent import LatentsField
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
@ -65,7 +65,7 @@ Nodes
|
||||
class NoiseOutput(BaseInvocationOutput):
|
||||
"""Invocation noise output"""
|
||||
|
||||
noise: LatentsField = OutputField(default=None, description=FieldDescriptions.noise)
|
||||
noise: LatentsField = OutputField(description=FieldDescriptions.noise)
|
||||
width: int = OutputField(description=FieldDescriptions.width)
|
||||
height: int = OutputField(description=FieldDescriptions.height)
|
||||
|
||||
@ -78,7 +78,13 @@ def build_noise_output(latents_name: str, latents: torch.Tensor, seed: int):
|
||||
)
|
||||
|
||||
|
||||
@invocation("noise", title="Noise", tags=["latents", "noise"], category="latents", version="1.0.0")
|
||||
@invocation(
|
||||
"noise",
|
||||
title="Noise",
|
||||
tags=["latents", "noise"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class NoiseInvocation(BaseInvocation):
|
||||
"""Generates latent noise."""
|
||||
|
||||
@ -105,7 +111,7 @@ class NoiseInvocation(BaseInvocation):
|
||||
description="Use CPU for noise generation (for reproducible results across platforms)",
|
||||
)
|
||||
|
||||
@validator("seed", pre=True)
|
||||
@field_validator("seed", mode="before")
|
||||
def modulo_seed(cls, v):
|
||||
"""Returns the seed modulo (SEED_MAX + 1) to ensure it is within the valid range."""
|
||||
return v % (SEED_MAX + 1)
|
||||
@ -118,6 +124,5 @@ class NoiseInvocation(BaseInvocation):
|
||||
seed=self.seed,
|
||||
use_cpu=self.use_cpu,
|
||||
)
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
context.services.latents.save(name, noise)
|
||||
return build_noise_output(latents_name=name, latents=noise, seed=self.seed)
|
||||
latents_name = context.save_latents(noise)
|
||||
return build_noise_output(latents_name=latents_name, latents=noise, seed=self.seed)
|
||||
|
||||
@ -9,18 +9,18 @@ from typing import List, Literal, Optional, Union
|
||||
import numpy as np
|
||||
import torch
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from pydantic import BaseModel, Field, validator
|
||||
from pydantic import BaseModel, ConfigDict, Field, field_validator
|
||||
from tqdm import tqdm
|
||||
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import ConditioningField, ConditioningOutput, ImageField, ImageOutput
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend import BaseModelType, ModelType, SubModelType
|
||||
|
||||
from ...backend.model_management import ONNXModelPatcher
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.util import choose_torch_device
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
@ -63,14 +63,17 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
tokenizer_info = context.services.model_manager.get_model(
|
||||
**self.clip.tokenizer.dict(),
|
||||
**self.clip.tokenizer.model_dump(),
|
||||
)
|
||||
text_encoder_info = context.services.model_manager.get_model(
|
||||
**self.clip.text_encoder.dict(),
|
||||
**self.clip.text_encoder.model_dump(),
|
||||
)
|
||||
with tokenizer_info as orig_tokenizer, text_encoder_info as text_encoder: # , ExitStack() as stack:
|
||||
loras = [
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(
|
||||
context.services.model_manager.get_model(**lora.model_dump(exclude={"weight"})).context.model,
|
||||
lora.weight,
|
||||
)
|
||||
for lora in self.clip.loras
|
||||
]
|
||||
|
||||
@ -175,14 +178,14 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
description=FieldDescriptions.unet,
|
||||
input=Input.Connection,
|
||||
)
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
)
|
||||
# seamless: bool = InputField(default=False, description="Whether or not to generate an image that can tile without seams", )
|
||||
# seamless_axes: str = InputField(default="", description="The axes to tile the image on, 'x' and/or 'y'")
|
||||
|
||||
@validator("cfg_scale")
|
||||
@field_validator("cfg_scale")
|
||||
def ge_one(cls, v):
|
||||
"""validate that all cfg_scale values are >= 1"""
|
||||
if isinstance(v, list):
|
||||
@ -241,7 +244,7 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
stable_diffusion_step_callback(
|
||||
context=context,
|
||||
intermediate_state=intermediate_state,
|
||||
node=self.dict(),
|
||||
node=self.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
|
||||
@ -254,12 +257,15 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
eta=0.0,
|
||||
)
|
||||
|
||||
unet_info = context.services.model_manager.get_model(**self.unet.unet.dict())
|
||||
unet_info = context.services.model_manager.get_model(**self.unet.unet.model_dump())
|
||||
|
||||
with unet_info as unet: # , ExitStack() as stack:
|
||||
# loras = [(stack.enter_context(context.services.model_manager.get_model(**lora.dict(exclude={"weight"}))), lora.weight) for lora in self.unet.loras]
|
||||
loras = [
|
||||
(context.services.model_manager.get_model(**lora.dict(exclude={"weight"})).context.model, lora.weight)
|
||||
(
|
||||
context.services.model_manager.get_model(**lora.model_dump(exclude={"weight"})).context.model,
|
||||
lora.weight,
|
||||
)
|
||||
for lora in self.unet.loras
|
||||
]
|
||||
|
||||
@ -346,7 +352,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
raise Exception(f"Expected vae_decoder, found: {self.vae.vae.model_type}")
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
**self.vae.vae.model_dump(),
|
||||
)
|
||||
|
||||
# clear memory as vae decode can request a lot
|
||||
@ -375,7 +381,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
metadata=self.metadata.model_dump() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
@ -403,6 +409,8 @@ class OnnxModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
@invocation("onnx_model_loader", title="ONNX Main Model", tags=["onnx", "model"], category="model", version="1.0.0")
|
||||
class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
|
||||
@ -44,13 +44,22 @@ from invokeai.app.invocations.primitives import FloatCollectionOutput
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@invocation("float_range", title="Float Range", tags=["math", "range"], category="math", version="1.0.0")
|
||||
@invocation(
|
||||
"float_range",
|
||||
title="Float Range",
|
||||
tags=["math", "range"],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FloatLinearRangeInvocation(BaseInvocation):
|
||||
"""Creates a range"""
|
||||
|
||||
start: float = InputField(default=5, description="The first value of the range")
|
||||
stop: float = InputField(default=10, description="The last value of the range")
|
||||
steps: int = InputField(default=30, description="number of values to interpolate over (including start and stop)")
|
||||
steps: int = InputField(
|
||||
default=30,
|
||||
description="number of values to interpolate over (including start and stop)",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatCollectionOutput:
|
||||
param_list = list(np.linspace(self.start, self.stop, self.steps))
|
||||
@ -95,7 +104,13 @@ EASING_FUNCTION_KEYS = Literal[tuple(list(EASING_FUNCTIONS_MAP.keys()))]
|
||||
|
||||
|
||||
# actually I think for now could just use CollectionOutput (which is list[Any]
|
||||
@invocation("step_param_easing", title="Step Param Easing", tags=["step", "easing"], category="step", version="1.0.0")
|
||||
@invocation(
|
||||
"step_param_easing",
|
||||
title="Step Param Easing",
|
||||
tags=["step", "easing"],
|
||||
category="step",
|
||||
version="1.0.0",
|
||||
)
|
||||
class StepParamEasingInvocation(BaseInvocation):
|
||||
"""Experimental per-step parameter easing for denoising steps"""
|
||||
|
||||
@ -159,7 +174,9 @@ class StepParamEasingInvocation(BaseInvocation):
|
||||
context.services.logger.debug("base easing duration: " + str(base_easing_duration))
|
||||
even_num_steps = num_easing_steps % 2 == 0 # even number of steps
|
||||
easing_function = easing_class(
|
||||
start=self.start_value, end=self.end_value, duration=base_easing_duration - 1
|
||||
start=self.start_value,
|
||||
end=self.end_value,
|
||||
duration=base_easing_duration - 1,
|
||||
)
|
||||
base_easing_vals = list()
|
||||
for step_index in range(base_easing_duration):
|
||||
@ -199,7 +216,11 @@ class StepParamEasingInvocation(BaseInvocation):
|
||||
#
|
||||
|
||||
else: # no mirroring (default)
|
||||
easing_function = easing_class(start=self.start_value, end=self.end_value, duration=num_easing_steps - 1)
|
||||
easing_function = easing_class(
|
||||
start=self.start_value,
|
||||
end=self.end_value,
|
||||
duration=num_easing_steps - 1,
|
||||
)
|
||||
for step_index in range(num_easing_steps):
|
||||
step_val = easing_function.ease(step_index)
|
||||
easing_list.append(step_val)
|
||||
|
||||
@ -226,6 +226,12 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
class BoardField(BaseModel):
|
||||
"""A board primitive field"""
|
||||
|
||||
board_id: str = Field(description="The id of the board")
|
||||
|
||||
|
||||
@invocation_output("image_output")
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
@ -3,7 +3,7 @@ from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
from pydantic import validator
|
||||
from pydantic import field_validator
|
||||
|
||||
from invokeai.app.invocations.primitives import StringCollectionOutput
|
||||
|
||||
@ -21,7 +21,10 @@ from .baseinvocation import BaseInvocation, InputField, InvocationContext, UICom
|
||||
class DynamicPromptInvocation(BaseInvocation):
|
||||
"""Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator"""
|
||||
|
||||
prompt: str = InputField(description="The prompt to parse with dynamicprompts", ui_component=UIComponent.Textarea)
|
||||
prompt: str = InputField(
|
||||
description="The prompt to parse with dynamicprompts",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
max_prompts: int = InputField(default=1, description="The number of prompts to generate")
|
||||
combinatorial: bool = InputField(default=False, description="Whether to use the combinatorial generator")
|
||||
|
||||
@ -36,21 +39,31 @@ class DynamicPromptInvocation(BaseInvocation):
|
||||
return StringCollectionOutput(collection=prompts)
|
||||
|
||||
|
||||
@invocation("prompt_from_file", title="Prompts from File", tags=["prompt", "file"], category="prompt", version="1.0.0")
|
||||
@invocation(
|
||||
"prompt_from_file",
|
||||
title="Prompts from File",
|
||||
tags=["prompt", "file"],
|
||||
category="prompt",
|
||||
version="1.0.0",
|
||||
)
|
||||
class PromptsFromFileInvocation(BaseInvocation):
|
||||
"""Loads prompts from a text file"""
|
||||
|
||||
file_path: str = InputField(description="Path to prompt text file")
|
||||
pre_prompt: Optional[str] = InputField(
|
||||
default=None, description="String to prepend to each prompt", ui_component=UIComponent.Textarea
|
||||
default=None,
|
||||
description="String to prepend to each prompt",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
post_prompt: Optional[str] = InputField(
|
||||
default=None, description="String to append to each prompt", ui_component=UIComponent.Textarea
|
||||
default=None,
|
||||
description="String to append to each prompt",
|
||||
ui_component=UIComponent.Textarea,
|
||||
)
|
||||
start_line: int = InputField(default=1, ge=1, description="Line in the file to start start from")
|
||||
max_prompts: int = InputField(default=1, ge=0, description="Max lines to read from file (0=all)")
|
||||
|
||||
@validator("file_path")
|
||||
@field_validator("file_path")
|
||||
def file_path_exists(cls, v):
|
||||
if not exists(v):
|
||||
raise ValueError(FileNotFoundError)
|
||||
@ -79,6 +92,10 @@ class PromptsFromFileInvocation(BaseInvocation):
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringCollectionOutput:
|
||||
prompts = self.promptsFromFile(
|
||||
self.file_path, self.pre_prompt, self.post_prompt, self.start_line, self.max_prompts
|
||||
self.file_path,
|
||||
self.pre_prompt,
|
||||
self.post_prompt,
|
||||
self.start_line,
|
||||
self.max_prompts,
|
||||
)
|
||||
return StringCollectionOutput(collection=prompts)
|
||||
|
||||
85
invokeai/app/invocations/t2i_adapter.py
Normal file
85
invokeai/app/invocations/t2i_adapter.py
Normal file
@ -0,0 +1,85 @@
|
||||
from typing import Union
|
||||
|
||||
from pydantic import BaseModel, ConfigDict, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import CONTROLNET_RESIZE_VALUES
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_management.models.base import BaseModelType
|
||||
|
||||
|
||||
class T2IAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the T2I-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
|
||||
class T2IAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The T2I-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = Field(description="The T2I-Adapter model to use.")
|
||||
weight: Union[float, list[float]] = Field(default=1, description="The weight given to the T2I-Adapter")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = Field(default="just_resize", description="The resize mode to use")
|
||||
|
||||
|
||||
@invocation_output("t2i_adapter_output")
|
||||
class T2IAdapterOutput(BaseInvocationOutput):
|
||||
t2i_adapter: T2IAdapterField = OutputField(description=FieldDescriptions.t2i_adapter, title="T2I Adapter")
|
||||
|
||||
|
||||
@invocation(
|
||||
"t2i_adapter", title="T2I-Adapter", tags=["t2i_adapter", "control"], category="t2i_adapter", version="1.0.0"
|
||||
)
|
||||
class T2IAdapterInvocation(BaseInvocation):
|
||||
"""Collects T2I-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
t2i_adapter_model: T2IAdapterModelField = InputField(
|
||||
description="The T2I-Adapter model.",
|
||||
title="T2I-Adapter Model",
|
||||
input=Input.Direct,
|
||||
ui_order=-1,
|
||||
)
|
||||
weight: Union[float, list[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the T2I-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the T2I-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the T2I-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
resize_mode: CONTROLNET_RESIZE_VALUES = InputField(
|
||||
default="just_resize",
|
||||
description="The resize mode applied to the T2I-Adapter input image so that it matches the target output size.",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> T2IAdapterOutput:
|
||||
return T2IAdapterOutput(
|
||||
t2i_adapter=T2IAdapterField(
|
||||
image=self.image,
|
||||
t2i_adapter_model=self.t2i_adapter_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
resize_mode=self.resize_mode,
|
||||
)
|
||||
)
|
||||
@ -4,12 +4,15 @@ from typing import Literal
|
||||
|
||||
import cv2 as cv
|
||||
import numpy as np
|
||||
import torch
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from pydantic import ConfigDict
|
||||
from realesrgan import RealESRGANer
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.image_records.image_records_common import ImageCategory, ResourceOrigin
|
||||
from invokeai.backend.util.devices import choose_torch_device
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
@ -22,13 +25,21 @@ ESRGAN_MODELS = Literal[
|
||||
"RealESRGAN_x2plus.pth",
|
||||
]
|
||||
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
from torch import mps
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.0.0")
|
||||
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.1.0")
|
||||
class ESRGANInvocation(BaseInvocation):
|
||||
"""Upscales an image using RealESRGAN."""
|
||||
|
||||
image: ImageField = InputField(description="The input image")
|
||||
model_name: ESRGAN_MODELS = InputField(default="RealESRGAN_x4plus.pth", description="The Real-ESRGAN model to use")
|
||||
tile_size: int = InputField(
|
||||
default=400, ge=0, description="Tile size for tiled ESRGAN upscaling (0=tiling disabled)"
|
||||
)
|
||||
|
||||
model_config = ConfigDict(protected_namespaces=())
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
@ -86,9 +97,11 @@ class ESRGANInvocation(BaseInvocation):
|
||||
model_path=str(models_path / esrgan_model_path),
|
||||
model=rrdbnet_model,
|
||||
half=False,
|
||||
tile=self.tile_size,
|
||||
)
|
||||
|
||||
# prepare image - Real-ESRGAN uses cv2 internally, and cv2 uses BGR vs RGB for PIL
|
||||
# TODO: This strips the alpha... is that okay?
|
||||
cv_image = cv.cvtColor(np.array(image.convert("RGB")), cv.COLOR_RGB2BGR)
|
||||
|
||||
# We can pass an `outscale` value here, but it just resizes the image by that factor after
|
||||
@ -99,6 +112,10 @@ class ESRGANInvocation(BaseInvocation):
|
||||
# back to PIL
|
||||
pil_image = Image.fromarray(cv.cvtColor(upscaled_image, cv.COLOR_BGR2RGB)).convert("RGBA")
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
|
||||
@ -1,4 +0,0 @@
|
||||
class CanceledException(Exception):
|
||||
"""Execution canceled by user."""
|
||||
|
||||
pass
|
||||
@ -1,71 +0,0 @@
|
||||
from enum import Enum
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
|
||||
|
||||
class ProgressImage(BaseModel):
|
||||
"""The progress image sent intermittently during processing"""
|
||||
|
||||
width: int = Field(description="The effective width of the image in pixels")
|
||||
height: int = Field(description="The effective height of the image in pixels")
|
||||
dataURL: str = Field(description="The image data as a b64 data URL")
|
||||
|
||||
|
||||
class ResourceOrigin(str, Enum, metaclass=MetaEnum):
|
||||
"""The origin of a resource (eg image).
|
||||
|
||||
- INTERNAL: The resource was created by the application.
|
||||
- EXTERNAL: The resource was not created by the application.
|
||||
This may be a user-initiated upload, or an internal application upload (eg Canvas init image).
|
||||
"""
|
||||
|
||||
INTERNAL = "internal"
|
||||
"""The resource was created by the application."""
|
||||
EXTERNAL = "external"
|
||||
"""The resource was not created by the application.
|
||||
This may be a user-initiated upload, or an internal application upload (eg Canvas init image).
|
||||
"""
|
||||
|
||||
|
||||
class InvalidOriginException(ValueError):
|
||||
"""Raised when a provided value is not a valid ResourceOrigin.
|
||||
|
||||
Subclasses `ValueError`.
|
||||
"""
|
||||
|
||||
def __init__(self, message="Invalid resource origin."):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageCategory(str, Enum, metaclass=MetaEnum):
|
||||
"""The category of an image.
|
||||
|
||||
- GENERAL: The image is an output, init image, or otherwise an image without a specialized purpose.
|
||||
- MASK: The image is a mask image.
|
||||
- CONTROL: The image is a ControlNet control image.
|
||||
- USER: The image is a user-provide image.
|
||||
- OTHER: The image is some other type of image with a specialized purpose. To be used by external nodes.
|
||||
"""
|
||||
|
||||
GENERAL = "general"
|
||||
"""GENERAL: The image is an output, init image, or otherwise an image without a specialized purpose."""
|
||||
MASK = "mask"
|
||||
"""MASK: The image is a mask image."""
|
||||
CONTROL = "control"
|
||||
"""CONTROL: The image is a ControlNet control image."""
|
||||
USER = "user"
|
||||
"""USER: The image is a user-provide image."""
|
||||
OTHER = "other"
|
||||
"""OTHER: The image is some other type of image with a specialized purpose. To be used by external nodes."""
|
||||
|
||||
|
||||
class InvalidImageCategoryException(ValueError):
|
||||
"""Raised when a provided value is not a valid ImageCategory.
|
||||
|
||||
Subclasses `ValueError`.
|
||||
"""
|
||||
|
||||
def __init__(self, message="Invalid image category."):
|
||||
super().__init__(message)
|
||||
@ -0,0 +1,47 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class BoardImageRecordStorageBase(ABC):
|
||||
"""Abstract base class for the one-to-many board-image relationship record storage."""
|
||||
|
||||
@abstractmethod
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Adds an image to a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Removes an image from a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
"""Gets all board images for a board, as a list of the image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
"""Gets an image's board id, if it has one."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_image_count_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> int:
|
||||
"""Gets the number of images for a board."""
|
||||
pass
|
||||
@ -1,69 +1,24 @@
|
||||
import sqlite3
|
||||
import threading
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional, cast
|
||||
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.image_record import ImageRecord, deserialize_image_record
|
||||
from invokeai.app.services.image_records.image_records_common import ImageRecord, deserialize_image_record
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite import SqliteDatabase
|
||||
|
||||
|
||||
class BoardImageRecordStorageBase(ABC):
|
||||
"""Abstract base class for the one-to-many board-image relationship record storage."""
|
||||
|
||||
@abstractmethod
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Adds an image to a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Removes an image from a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
"""Gets all board images for a board, as a list of the image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
"""Gets an image's board id, if it has one."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_image_count_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> int:
|
||||
"""Gets the number of images for a board."""
|
||||
pass
|
||||
from .board_image_records_base import BoardImageRecordStorageBase
|
||||
|
||||
|
||||
class SqliteBoardImageRecordStorage(BoardImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._lock = db.lock
|
||||
self._conn = db.conn
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@ -1,112 +0,0 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
from typing import Optional
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.board_record_storage import BoardRecord, BoardRecordStorageBase
|
||||
from invokeai.app.services.image_record_storage import ImageRecordStorageBase
|
||||
from invokeai.app.services.models.board_record import BoardDTO
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
|
||||
|
||||
class BoardImagesServiceABC(ABC):
|
||||
"""High-level service for board-image relationship management."""
|
||||
|
||||
@abstractmethod
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Adds an image to a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Removes an image from a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
"""Gets all board images for a board, as a list of the image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
"""Gets an image's board id, if it has one."""
|
||||
pass
|
||||
|
||||
|
||||
class BoardImagesServiceDependencies:
|
||||
"""Service dependencies for the BoardImagesService."""
|
||||
|
||||
board_image_records: BoardImageRecordStorageBase
|
||||
board_records: BoardRecordStorageBase
|
||||
image_records: ImageRecordStorageBase
|
||||
urls: UrlServiceBase
|
||||
logger: Logger
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
board_image_record_storage: BoardImageRecordStorageBase,
|
||||
image_record_storage: ImageRecordStorageBase,
|
||||
board_record_storage: BoardRecordStorageBase,
|
||||
url: UrlServiceBase,
|
||||
logger: Logger,
|
||||
):
|
||||
self.board_image_records = board_image_record_storage
|
||||
self.image_records = image_record_storage
|
||||
self.board_records = board_record_storage
|
||||
self.urls = url
|
||||
self.logger = logger
|
||||
|
||||
|
||||
class BoardImagesService(BoardImagesServiceABC):
|
||||
_services: BoardImagesServiceDependencies
|
||||
|
||||
def __init__(self, services: BoardImagesServiceDependencies):
|
||||
self._services = services
|
||||
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
self._services.board_image_records.add_image_to_board(board_id, image_name)
|
||||
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
self._services.board_image_records.remove_image_from_board(image_name)
|
||||
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
return self._services.board_image_records.get_all_board_image_names_for_board(board_id)
|
||||
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
board_id = self._services.board_image_records.get_board_for_image(image_name)
|
||||
return board_id
|
||||
|
||||
|
||||
def board_record_to_dto(board_record: BoardRecord, cover_image_name: Optional[str], image_count: int) -> BoardDTO:
|
||||
"""Converts a board record to a board DTO."""
|
||||
return BoardDTO(
|
||||
**board_record.dict(exclude={"cover_image_name"}),
|
||||
cover_image_name=cover_image_name,
|
||||
image_count=image_count,
|
||||
)
|
||||
0
invokeai/app/services/board_images/__init__.py
Normal file
0
invokeai/app/services/board_images/__init__.py
Normal file
39
invokeai/app/services/board_images/board_images_base.py
Normal file
39
invokeai/app/services/board_images/board_images_base.py
Normal file
@ -0,0 +1,39 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class BoardImagesServiceABC(ABC):
|
||||
"""High-level service for board-image relationship management."""
|
||||
|
||||
@abstractmethod
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Adds an image to a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
"""Removes an image from a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
"""Gets all board images for a board, as a list of the image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
"""Gets an image's board id, if it has one."""
|
||||
pass
|
||||
38
invokeai/app/services/board_images/board_images_default.py
Normal file
38
invokeai/app/services/board_images/board_images_default.py
Normal file
@ -0,0 +1,38 @@
|
||||
from typing import Optional
|
||||
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
from .board_images_base import BoardImagesServiceABC
|
||||
|
||||
|
||||
class BoardImagesService(BoardImagesServiceABC):
|
||||
__invoker: Invoker
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
|
||||
def add_image_to_board(
|
||||
self,
|
||||
board_id: str,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
self.__invoker.services.board_image_records.add_image_to_board(board_id, image_name)
|
||||
|
||||
def remove_image_from_board(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> None:
|
||||
self.__invoker.services.board_image_records.remove_image_from_board(image_name)
|
||||
|
||||
def get_all_board_image_names_for_board(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> list[str]:
|
||||
return self.__invoker.services.board_image_records.get_all_board_image_names_for_board(board_id)
|
||||
|
||||
def get_board_for_image(
|
||||
self,
|
||||
image_name: str,
|
||||
) -> Optional[str]:
|
||||
board_id = self.__invoker.services.board_image_records.get_board_for_image(image_name)
|
||||
return board_id
|
||||
55
invokeai/app/services/board_records/board_records_base.py
Normal file
55
invokeai/app/services/board_records/board_records_base.py
Normal file
@ -0,0 +1,55 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from .board_records_common import BoardChanges, BoardRecord
|
||||
|
||||
|
||||
class BoardRecordStorageBase(ABC):
|
||||
"""Low-level service responsible for interfacing with the board record store."""
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, board_id: str) -> None:
|
||||
"""Deletes a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardRecord:
|
||||
"""Saves a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> BoardRecord:
|
||||
"""Gets a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardRecord:
|
||||
"""Updates a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
"""Gets many board records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self,
|
||||
) -> list[BoardRecord]:
|
||||
"""Gets all board records."""
|
||||
pass
|
||||
@ -1,7 +1,7 @@
|
||||
from datetime import datetime
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import Field
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
@ -18,21 +18,12 @@ class BoardRecord(BaseModelExcludeNull):
|
||||
"""The created timestamp of the image."""
|
||||
updated_at: Union[datetime, str] = Field(description="The updated timestamp of the board.")
|
||||
"""The updated timestamp of the image."""
|
||||
deleted_at: Union[datetime, str, None] = Field(description="The deleted timestamp of the board.")
|
||||
deleted_at: Optional[Union[datetime, str]] = Field(default=None, description="The deleted timestamp of the board.")
|
||||
"""The updated timestamp of the image."""
|
||||
cover_image_name: Optional[str] = Field(description="The name of the cover image of the board.")
|
||||
cover_image_name: Optional[str] = Field(default=None, description="The name of the cover image of the board.")
|
||||
"""The name of the cover image of the board."""
|
||||
|
||||
|
||||
class BoardDTO(BoardRecord):
|
||||
"""Deserialized board record with cover image URL and image count."""
|
||||
|
||||
cover_image_name: Optional[str] = Field(description="The name of the board's cover image.")
|
||||
"""The URL of the thumbnail of the most recent image in the board."""
|
||||
image_count: int = Field(description="The number of images in the board.")
|
||||
"""The number of images in the board."""
|
||||
|
||||
|
||||
def deserialize_board_record(board_dict: dict) -> BoardRecord:
|
||||
"""Deserializes a board record."""
|
||||
|
||||
@ -53,3 +44,29 @@ def deserialize_board_record(board_dict: dict) -> BoardRecord:
|
||||
updated_at=updated_at,
|
||||
deleted_at=deleted_at,
|
||||
)
|
||||
|
||||
|
||||
class BoardChanges(BaseModel, extra="forbid"):
|
||||
board_name: Optional[str] = Field(default=None, description="The board's new name.")
|
||||
cover_image_name: Optional[str] = Field(default=None, description="The name of the board's new cover image.")
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
"""Raised when an board record is not found."""
|
||||
|
||||
def __init__(self, message="Board record not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class BoardRecordSaveException(Exception):
|
||||
"""Raised when an board record cannot be saved."""
|
||||
|
||||
def __init__(self, message="Board record not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class BoardRecordDeleteException(Exception):
|
||||
"""Raised when an board record cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Board record not deleted"):
|
||||
super().__init__(message)
|
||||
@ -1,103 +1,32 @@
|
||||
import sqlite3
|
||||
import threading
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union, cast
|
||||
from typing import Union, cast
|
||||
|
||||
from pydantic import BaseModel, Extra, Field
|
||||
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.board_record import BoardRecord, deserialize_board_record
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite import SqliteDatabase
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
|
||||
class BoardChanges(BaseModel, extra=Extra.forbid):
|
||||
board_name: Optional[str] = Field(description="The board's new name.")
|
||||
cover_image_name: Optional[str] = Field(description="The name of the board's new cover image.")
|
||||
|
||||
|
||||
class BoardRecordNotFoundException(Exception):
|
||||
"""Raised when an board record is not found."""
|
||||
|
||||
def __init__(self, message="Board record not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class BoardRecordSaveException(Exception):
|
||||
"""Raised when an board record cannot be saved."""
|
||||
|
||||
def __init__(self, message="Board record not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class BoardRecordDeleteException(Exception):
|
||||
"""Raised when an board record cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Board record not deleted"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class BoardRecordStorageBase(ABC):
|
||||
"""Low-level service responsible for interfacing with the board record store."""
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, board_id: str) -> None:
|
||||
"""Deletes a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardRecord:
|
||||
"""Saves a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> BoardRecord:
|
||||
"""Gets a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardRecord:
|
||||
"""Updates a board record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
) -> OffsetPaginatedResults[BoardRecord]:
|
||||
"""Gets many board records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self,
|
||||
) -> list[BoardRecord]:
|
||||
"""Gets all board records."""
|
||||
pass
|
||||
from .board_records_base import BoardRecordStorageBase
|
||||
from .board_records_common import (
|
||||
BoardChanges,
|
||||
BoardRecord,
|
||||
BoardRecordDeleteException,
|
||||
BoardRecordNotFoundException,
|
||||
BoardRecordSaveException,
|
||||
deserialize_board_record,
|
||||
)
|
||||
|
||||
|
||||
class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._lock = db.lock
|
||||
self._conn = db.conn
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@ -1,158 +0,0 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.board_images import board_record_to_dto
|
||||
from invokeai.app.services.board_record_storage import BoardChanges, BoardRecordStorageBase
|
||||
from invokeai.app.services.image_record_storage import ImageRecordStorageBase, OffsetPaginatedResults
|
||||
from invokeai.app.services.models.board_record import BoardDTO
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
|
||||
|
||||
class BoardServiceABC(ABC):
|
||||
"""High-level service for board management."""
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardDTO:
|
||||
"""Creates a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_dto(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> BoardDTO:
|
||||
"""Gets a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardDTO:
|
||||
"""Updates a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> None:
|
||||
"""Deletes a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
"""Gets many boards."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self,
|
||||
) -> list[BoardDTO]:
|
||||
"""Gets all boards."""
|
||||
pass
|
||||
|
||||
|
||||
class BoardServiceDependencies:
|
||||
"""Service dependencies for the BoardService."""
|
||||
|
||||
board_image_records: BoardImageRecordStorageBase
|
||||
board_records: BoardRecordStorageBase
|
||||
image_records: ImageRecordStorageBase
|
||||
urls: UrlServiceBase
|
||||
logger: Logger
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
board_image_record_storage: BoardImageRecordStorageBase,
|
||||
image_record_storage: ImageRecordStorageBase,
|
||||
board_record_storage: BoardRecordStorageBase,
|
||||
url: UrlServiceBase,
|
||||
logger: Logger,
|
||||
):
|
||||
self.board_image_records = board_image_record_storage
|
||||
self.image_records = image_record_storage
|
||||
self.board_records = board_record_storage
|
||||
self.urls = url
|
||||
self.logger = logger
|
||||
|
||||
|
||||
class BoardService(BoardServiceABC):
|
||||
_services: BoardServiceDependencies
|
||||
|
||||
def __init__(self, services: BoardServiceDependencies):
|
||||
self._services = services
|
||||
|
||||
def create(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardDTO:
|
||||
board_record = self._services.board_records.save(board_name)
|
||||
return board_record_to_dto(board_record, None, 0)
|
||||
|
||||
def get_dto(self, board_id: str) -> BoardDTO:
|
||||
board_record = self._services.board_records.get(board_id)
|
||||
cover_image = self._services.image_records.get_most_recent_image_for_board(board_record.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
image_count = self._services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardDTO:
|
||||
board_record = self._services.board_records.update(board_id, changes)
|
||||
cover_image = self._services.image_records.get_most_recent_image_for_board(board_record.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self._services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
|
||||
def delete(self, board_id: str) -> None:
|
||||
self._services.board_records.delete(board_id)
|
||||
|
||||
def get_many(self, offset: int = 0, limit: int = 10) -> OffsetPaginatedResults[BoardDTO]:
|
||||
board_records = self._services.board_records.get_many(offset, limit)
|
||||
board_dtos = []
|
||||
for r in board_records.items:
|
||||
cover_image = self._services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self._services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
def get_all(self) -> list[BoardDTO]:
|
||||
board_records = self._services.board_records.get_all()
|
||||
board_dtos = []
|
||||
for r in board_records:
|
||||
cover_image = self._services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self._services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
|
||||
return board_dtos
|
||||
0
invokeai/app/services/boards/__init__.py
Normal file
0
invokeai/app/services/boards/__init__.py
Normal file
59
invokeai/app/services/boards/boards_base.py
Normal file
59
invokeai/app/services/boards/boards_base.py
Normal file
@ -0,0 +1,59 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from .boards_common import BoardDTO
|
||||
|
||||
|
||||
class BoardServiceABC(ABC):
|
||||
"""High-level service for board management."""
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardDTO:
|
||||
"""Creates a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_dto(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> BoardDTO:
|
||||
"""Gets a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardDTO:
|
||||
"""Updates a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(
|
||||
self,
|
||||
board_id: str,
|
||||
) -> None:
|
||||
"""Deletes a board."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
) -> OffsetPaginatedResults[BoardDTO]:
|
||||
"""Gets many boards."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_all(
|
||||
self,
|
||||
) -> list[BoardDTO]:
|
||||
"""Gets all boards."""
|
||||
pass
|
||||
23
invokeai/app/services/boards/boards_common.py
Normal file
23
invokeai/app/services/boards/boards_common.py
Normal file
@ -0,0 +1,23 @@
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from ..board_records.board_records_common import BoardRecord
|
||||
|
||||
|
||||
class BoardDTO(BoardRecord):
|
||||
"""Deserialized board record with cover image URL and image count."""
|
||||
|
||||
cover_image_name: Optional[str] = Field(description="The name of the board's cover image.")
|
||||
"""The URL of the thumbnail of the most recent image in the board."""
|
||||
image_count: int = Field(description="The number of images in the board.")
|
||||
"""The number of images in the board."""
|
||||
|
||||
|
||||
def board_record_to_dto(board_record: BoardRecord, cover_image_name: Optional[str], image_count: int) -> BoardDTO:
|
||||
"""Converts a board record to a board DTO."""
|
||||
return BoardDTO(
|
||||
**board_record.model_dump(exclude={"cover_image_name"}),
|
||||
cover_image_name=cover_image_name,
|
||||
image_count=image_count,
|
||||
)
|
||||
79
invokeai/app/services/boards/boards_default.py
Normal file
79
invokeai/app/services/boards/boards_default.py
Normal file
@ -0,0 +1,79 @@
|
||||
from invokeai.app.services.board_records.board_records_common import BoardChanges
|
||||
from invokeai.app.services.boards.boards_common import BoardDTO
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from .boards_base import BoardServiceABC
|
||||
from .boards_common import board_record_to_dto
|
||||
|
||||
|
||||
class BoardService(BoardServiceABC):
|
||||
__invoker: Invoker
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
|
||||
def create(
|
||||
self,
|
||||
board_name: str,
|
||||
) -> BoardDTO:
|
||||
board_record = self.__invoker.services.board_records.save(board_name)
|
||||
return board_record_to_dto(board_record, None, 0)
|
||||
|
||||
def get_dto(self, board_id: str) -> BoardDTO:
|
||||
board_record = self.__invoker.services.board_records.get(board_id)
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(board_record.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
|
||||
def update(
|
||||
self,
|
||||
board_id: str,
|
||||
changes: BoardChanges,
|
||||
) -> BoardDTO:
|
||||
board_record = self.__invoker.services.board_records.update(board_id, changes)
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(board_record.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(board_id)
|
||||
return board_record_to_dto(board_record, cover_image_name, image_count)
|
||||
|
||||
def delete(self, board_id: str) -> None:
|
||||
self.__invoker.services.board_records.delete(board_id)
|
||||
|
||||
def get_many(self, offset: int = 0, limit: int = 10) -> OffsetPaginatedResults[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_many(offset, limit)
|
||||
board_dtos = []
|
||||
for r in board_records.items:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
|
||||
return OffsetPaginatedResults[BoardDTO](items=board_dtos, offset=offset, limit=limit, total=len(board_dtos))
|
||||
|
||||
def get_all(self) -> list[BoardDTO]:
|
||||
board_records = self.__invoker.services.board_records.get_all()
|
||||
board_dtos = []
|
||||
for r in board_records:
|
||||
cover_image = self.__invoker.services.image_records.get_most_recent_image_for_board(r.board_id)
|
||||
if cover_image:
|
||||
cover_image_name = cover_image.image_name
|
||||
else:
|
||||
cover_image_name = None
|
||||
|
||||
image_count = self.__invoker.services.board_image_records.get_image_count_for_board(r.board_id)
|
||||
board_dtos.append(board_record_to_dto(r, cover_image_name, image_count))
|
||||
|
||||
return board_dtos
|
||||
@ -2,5 +2,5 @@
|
||||
Init file for InvokeAI configure package
|
||||
"""
|
||||
|
||||
from .base import PagingArgumentParser # noqa F401
|
||||
from .invokeai_config import InvokeAIAppConfig, get_invokeai_config # noqa F401
|
||||
from .config_base import PagingArgumentParser # noqa F401
|
||||
from .config_default import InvokeAIAppConfig, get_invokeai_config # noqa F401
|
||||
|
||||
@ -12,25 +12,15 @@ from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import pydoc
|
||||
import sys
|
||||
from argparse import ArgumentParser
|
||||
from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_args, get_origin, get_type_hints
|
||||
|
||||
from omegaconf import DictConfig, ListConfig, OmegaConf
|
||||
from pydantic import BaseSettings
|
||||
from pydantic_settings import BaseSettings, SettingsConfigDict
|
||||
|
||||
|
||||
class PagingArgumentParser(argparse.ArgumentParser):
|
||||
"""
|
||||
A custom ArgumentParser that uses pydoc to page its output.
|
||||
It also supports reading defaults from an init file.
|
||||
"""
|
||||
|
||||
def print_help(self, file=None):
|
||||
text = self.format_help()
|
||||
pydoc.pager(text)
|
||||
from invokeai.app.services.config.config_common import PagingArgumentParser, int_or_float_or_str
|
||||
|
||||
|
||||
class InvokeAISettings(BaseSettings):
|
||||
@ -42,12 +32,14 @@ class InvokeAISettings(BaseSettings):
|
||||
initconf: ClassVar[Optional[DictConfig]] = None
|
||||
argparse_groups: ClassVar[Dict] = {}
|
||||
|
||||
model_config = SettingsConfigDict(env_file_encoding="utf-8", arbitrary_types_allowed=True, case_sensitive=True)
|
||||
|
||||
def parse_args(self, argv: Optional[list] = sys.argv[1:]):
|
||||
parser = self.get_parser()
|
||||
opt, unknown_opts = parser.parse_known_args(argv)
|
||||
if len(unknown_opts) > 0:
|
||||
print("Unknown args:", unknown_opts)
|
||||
for name in self.__fields__:
|
||||
for name in self.model_fields:
|
||||
if name not in self._excluded():
|
||||
value = getattr(opt, name)
|
||||
if isinstance(value, ListConfig):
|
||||
@ -64,10 +56,12 @@ class InvokeAISettings(BaseSettings):
|
||||
cls = self.__class__
|
||||
type = get_args(get_type_hints(cls)["type"])[0]
|
||||
field_dict = dict({type: dict()})
|
||||
for name, field in self.__fields__.items():
|
||||
for name, field in self.model_fields.items():
|
||||
if name in cls._excluded_from_yaml():
|
||||
continue
|
||||
category = field.field_info.extra.get("category") or "Uncategorized"
|
||||
category = (
|
||||
field.json_schema_extra.get("category", "Uncategorized") if field.json_schema_extra else "Uncategorized"
|
||||
)
|
||||
value = getattr(self, name)
|
||||
if category not in field_dict[type]:
|
||||
field_dict[type][category] = dict()
|
||||
@ -83,7 +77,7 @@ class InvokeAISettings(BaseSettings):
|
||||
else:
|
||||
settings_stanza = "Uncategorized"
|
||||
|
||||
env_prefix = getattr(cls.Config, "env_prefix", None)
|
||||
env_prefix = getattr(cls.model_config, "env_prefix", None)
|
||||
env_prefix = env_prefix if env_prefix is not None else settings_stanza.upper()
|
||||
|
||||
initconf = (
|
||||
@ -99,14 +93,18 @@ class InvokeAISettings(BaseSettings):
|
||||
for key, value in os.environ.items():
|
||||
upcase_environ[key.upper()] = value
|
||||
|
||||
fields = cls.__fields__
|
||||
fields = cls.model_fields
|
||||
cls.argparse_groups = {}
|
||||
|
||||
for name, field in fields.items():
|
||||
if name not in cls._excluded():
|
||||
current_default = field.default
|
||||
|
||||
category = field.field_info.extra.get("category", "Uncategorized")
|
||||
category = (
|
||||
field.json_schema_extra.get("category", "Uncategorized")
|
||||
if field.json_schema_extra
|
||||
else "Uncategorized"
|
||||
)
|
||||
env_name = env_prefix + "_" + name
|
||||
if category in initconf and name in initconf.get(category):
|
||||
field.default = initconf.get(category).get(name)
|
||||
@ -156,11 +154,6 @@ class InvokeAISettings(BaseSettings):
|
||||
"tiled_decode",
|
||||
]
|
||||
|
||||
class Config:
|
||||
env_file_encoding = "utf-8"
|
||||
arbitrary_types_allowed = True
|
||||
case_sensitive = True
|
||||
|
||||
@classmethod
|
||||
def add_field_argument(cls, command_parser, name: str, field, default_override=None):
|
||||
field_type = get_type_hints(cls).get(name)
|
||||
@ -171,7 +164,7 @@ class InvokeAISettings(BaseSettings):
|
||||
if field.default_factory is None
|
||||
else field.default_factory()
|
||||
)
|
||||
if category := field.field_info.extra.get("category"):
|
||||
if category := (field.json_schema_extra.get("category", None) if field.json_schema_extra else None):
|
||||
if category not in cls.argparse_groups:
|
||||
cls.argparse_groups[category] = command_parser.add_argument_group(category)
|
||||
argparse_group = cls.argparse_groups[category]
|
||||
@ -179,7 +172,7 @@ class InvokeAISettings(BaseSettings):
|
||||
argparse_group = command_parser
|
||||
|
||||
if get_origin(field_type) == Literal:
|
||||
allowed_values = get_args(field.type_)
|
||||
allowed_values = get_args(field.annotation)
|
||||
allowed_types = set()
|
||||
for val in allowed_values:
|
||||
allowed_types.add(type(val))
|
||||
@ -192,7 +185,7 @@ class InvokeAISettings(BaseSettings):
|
||||
type=field_type,
|
||||
default=default,
|
||||
choices=allowed_values,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
elif get_origin(field_type) == Union:
|
||||
@ -201,7 +194,7 @@ class InvokeAISettings(BaseSettings):
|
||||
dest=name,
|
||||
type=int_or_float_or_str,
|
||||
default=default,
|
||||
help=field.field_info.description,
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
elif get_origin(field_type) == list:
|
||||
@ -209,32 +202,17 @@ class InvokeAISettings(BaseSettings):
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
nargs="*",
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
action=argparse.BooleanOptionalAction if field.type_ == bool else "store",
|
||||
help=field.field_info.description,
|
||||
action=argparse.BooleanOptionalAction if field.annotation == bool else "store",
|
||||
help=field.description,
|
||||
)
|
||||
else:
|
||||
argparse_group.add_argument(
|
||||
f"--{name}",
|
||||
dest=name,
|
||||
type=field.type_,
|
||||
type=field.annotation,
|
||||
default=default,
|
||||
action=argparse.BooleanOptionalAction if field.type_ == bool else "store",
|
||||
help=field.field_info.description,
|
||||
action=argparse.BooleanOptionalAction if field.annotation == bool else "store",
|
||||
help=field.description,
|
||||
)
|
||||
|
||||
|
||||
def int_or_float_or_str(value: str) -> Union[int, float, str]:
|
||||
"""
|
||||
Workaround for argparse type checking.
|
||||
"""
|
||||
try:
|
||||
return int(value)
|
||||
except Exception as e: # noqa F841
|
||||
pass
|
||||
try:
|
||||
return float(value)
|
||||
except Exception as e: # noqa F841
|
||||
pass
|
||||
return str(value)
|
||||
41
invokeai/app/services/config/config_common.py
Normal file
41
invokeai/app/services/config/config_common.py
Normal file
@ -0,0 +1,41 @@
|
||||
# Copyright (c) 2023 Lincoln Stein (https://github.com/lstein) and the InvokeAI Development Team
|
||||
|
||||
"""
|
||||
Base class for the InvokeAI configuration system.
|
||||
It defines a type of pydantic BaseSettings object that
|
||||
is able to read and write from an omegaconf-based config file,
|
||||
with overriding of settings from environment variables and/or
|
||||
the command line.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import pydoc
|
||||
from typing import Union
|
||||
|
||||
|
||||
class PagingArgumentParser(argparse.ArgumentParser):
|
||||
"""
|
||||
A custom ArgumentParser that uses pydoc to page its output.
|
||||
It also supports reading defaults from an init file.
|
||||
"""
|
||||
|
||||
def print_help(self, file=None):
|
||||
text = self.format_help()
|
||||
pydoc.pager(text)
|
||||
|
||||
|
||||
def int_or_float_or_str(value: str) -> Union[int, float, str]:
|
||||
"""
|
||||
Workaround for argparse type checking.
|
||||
"""
|
||||
try:
|
||||
return int(value)
|
||||
except Exception as e: # noqa F841
|
||||
pass
|
||||
try:
|
||||
return float(value)
|
||||
except Exception as e: # noqa F841
|
||||
pass
|
||||
return str(value)
|
||||
@ -144,8 +144,8 @@ which is set to the desired top-level name. For example, to create a
|
||||
|
||||
class InvokeBatch(InvokeAISettings):
|
||||
type: Literal["InvokeBatch"] = "InvokeBatch"
|
||||
node_count : int = Field(default=1, description="Number of nodes to run on", category='Resources')
|
||||
cpu_count : int = Field(default=8, description="Number of GPUs to run on per node", category='Resources')
|
||||
node_count : int = Field(default=1, description="Number of nodes to run on", json_schema_extra=dict(category='Resources'))
|
||||
cpu_count : int = Field(default=8, description="Number of GPUs to run on per node", json_schema_extra=dict(category='Resources'))
|
||||
|
||||
This will now read and write from the "InvokeBatch" section of the
|
||||
config file, look for environment variables named INVOKEBATCH_*, and
|
||||
@ -175,9 +175,10 @@ from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_type_hints
|
||||
|
||||
from omegaconf import DictConfig, OmegaConf
|
||||
from pydantic import Field, parse_obj_as
|
||||
from pydantic import Field, TypeAdapter
|
||||
from pydantic_settings import SettingsConfigDict
|
||||
|
||||
from .base import InvokeAISettings
|
||||
from .config_base import InvokeAISettings
|
||||
|
||||
INIT_FILE = Path("invokeai.yaml")
|
||||
DB_FILE = Path("invokeai.db")
|
||||
@ -185,6 +186,21 @@ LEGACY_INIT_FILE = Path("invokeai.init")
|
||||
DEFAULT_MAX_VRAM = 0.5
|
||||
|
||||
|
||||
class Categories(object):
|
||||
WebServer = dict(category="Web Server")
|
||||
Features = dict(category="Features")
|
||||
Paths = dict(category="Paths")
|
||||
Logging = dict(category="Logging")
|
||||
Development = dict(category="Development")
|
||||
Other = dict(category="Other")
|
||||
ModelCache = dict(category="Model Cache")
|
||||
Device = dict(category="Device")
|
||||
Generation = dict(category="Generation")
|
||||
Queue = dict(category="Queue")
|
||||
Nodes = dict(category="Nodes")
|
||||
MemoryPerformance = dict(category="Memory/Performance")
|
||||
|
||||
|
||||
class InvokeAIAppConfig(InvokeAISettings):
|
||||
"""
|
||||
Generate images using Stable Diffusion. Use "invokeai" to launch
|
||||
@ -201,85 +217,88 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
type: Literal["InvokeAI"] = "InvokeAI"
|
||||
|
||||
# WEB
|
||||
host : str = Field(default="127.0.0.1", description="IP address to bind to", category='Web Server')
|
||||
port : int = Field(default=9090, description="Port to bind to", category='Web Server')
|
||||
allow_origins : List[str] = Field(default=[], description="Allowed CORS origins", category='Web Server')
|
||||
allow_credentials : bool = Field(default=True, description="Allow CORS credentials", category='Web Server')
|
||||
allow_methods : List[str] = Field(default=["*"], description="Methods allowed for CORS", category='Web Server')
|
||||
allow_headers : List[str] = Field(default=["*"], description="Headers allowed for CORS", category='Web Server')
|
||||
host : str = Field(default="127.0.0.1", description="IP address to bind to", json_schema_extra=Categories.WebServer)
|
||||
port : int = Field(default=9090, description="Port to bind to", json_schema_extra=Categories.WebServer)
|
||||
allow_origins : List[str] = Field(default=[], description="Allowed CORS origins", json_schema_extra=Categories.WebServer)
|
||||
allow_credentials : bool = Field(default=True, description="Allow CORS credentials", json_schema_extra=Categories.WebServer)
|
||||
allow_methods : List[str] = Field(default=["*"], description="Methods allowed for CORS", json_schema_extra=Categories.WebServer)
|
||||
allow_headers : List[str] = Field(default=["*"], description="Headers allowed for CORS", json_schema_extra=Categories.WebServer)
|
||||
|
||||
# FEATURES
|
||||
esrgan : bool = Field(default=True, description="Enable/disable upscaling code", category='Features')
|
||||
internet_available : bool = Field(default=True, description="If true, attempt to download models on the fly; otherwise only use local models", category='Features')
|
||||
log_tokenization : bool = Field(default=False, description="Enable logging of parsed prompt tokens.", category='Features')
|
||||
patchmatch : bool = Field(default=True, description="Enable/disable patchmatch inpaint code", category='Features')
|
||||
ignore_missing_core_models : bool = Field(default=False, description='Ignore missing models in models/core/convert', category='Features')
|
||||
esrgan : bool = Field(default=True, description="Enable/disable upscaling code", json_schema_extra=Categories.Features)
|
||||
internet_available : bool = Field(default=True, description="If true, attempt to download models on the fly; otherwise only use local models", json_schema_extra=Categories.Features)
|
||||
log_tokenization : bool = Field(default=False, description="Enable logging of parsed prompt tokens.", json_schema_extra=Categories.Features)
|
||||
patchmatch : bool = Field(default=True, description="Enable/disable patchmatch inpaint code", json_schema_extra=Categories.Features)
|
||||
ignore_missing_core_models : bool = Field(default=False, description='Ignore missing models in models/core/convert', json_schema_extra=Categories.Features)
|
||||
|
||||
# PATHS
|
||||
root : Path = Field(default=None, description='InvokeAI runtime root directory', category='Paths')
|
||||
autoimport_dir : Path = Field(default='autoimport', description='Path to a directory of models files to be imported on startup.', category='Paths')
|
||||
lora_dir : Path = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', category='Paths')
|
||||
embedding_dir : Path = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', category='Paths')
|
||||
controlnet_dir : Path = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', category='Paths')
|
||||
conf_path : Path = Field(default='configs/models.yaml', description='Path to models definition file', category='Paths')
|
||||
models_dir : Path = Field(default='models', description='Path to the models directory', category='Paths')
|
||||
legacy_conf_dir : Path = Field(default='configs/stable-diffusion', description='Path to directory of legacy checkpoint config files', category='Paths')
|
||||
db_dir : Path = Field(default='databases', description='Path to InvokeAI databases directory', category='Paths')
|
||||
outdir : Path = Field(default='outputs', description='Default folder for output images', category='Paths')
|
||||
use_memory_db : bool = Field(default=False, description='Use in-memory database for storing image metadata', category='Paths')
|
||||
from_file : Path = Field(default=None, description='Take command input from the indicated file (command-line client only)', category='Paths')
|
||||
root : Optional[Path] = Field(default=None, description='InvokeAI runtime root directory', json_schema_extra=Categories.Paths)
|
||||
autoimport_dir : Optional[Path] = Field(default=Path('autoimport'), description='Path to a directory of models files to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
lora_dir : Optional[Path] = Field(default=None, description='Path to a directory of LoRA/LyCORIS models to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
embedding_dir : Optional[Path] = Field(default=None, description='Path to a directory of Textual Inversion embeddings to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
controlnet_dir : Optional[Path] = Field(default=None, description='Path to a directory of ControlNet embeddings to be imported on startup.', json_schema_extra=Categories.Paths)
|
||||
conf_path : Optional[Path] = Field(default=Path('configs/models.yaml'), description='Path to models definition file', json_schema_extra=Categories.Paths)
|
||||
models_dir : Optional[Path] = Field(default=Path('models'), description='Path to the models directory', json_schema_extra=Categories.Paths)
|
||||
legacy_conf_dir : Optional[Path] = Field(default=Path('configs/stable-diffusion'), description='Path to directory of legacy checkpoint config files', json_schema_extra=Categories.Paths)
|
||||
db_dir : Optional[Path] = Field(default=Path('databases'), description='Path to InvokeAI databases directory', json_schema_extra=Categories.Paths)
|
||||
outdir : Optional[Path] = Field(default=Path('outputs'), description='Default folder for output images', json_schema_extra=Categories.Paths)
|
||||
use_memory_db : bool = Field(default=False, description='Use in-memory database for storing image metadata', json_schema_extra=Categories.Paths)
|
||||
from_file : Optional[Path] = Field(default=None, description='Take command input from the indicated file (command-line client only)', json_schema_extra=Categories.Paths)
|
||||
|
||||
# LOGGING
|
||||
log_handlers : List[str] = Field(default=["console"], description='Log handler. Valid options are "console", "file=<path>", "syslog=path|address:host:port", "http=<url>"', category="Logging")
|
||||
log_handlers : List[str] = Field(default=["console"], description='Log handler. Valid options are "console", "file=<path>", "syslog=path|address:host:port", "http=<url>"', json_schema_extra=Categories.Logging)
|
||||
# note - would be better to read the log_format values from logging.py, but this creates circular dependencies issues
|
||||
log_format : Literal['plain', 'color', 'syslog', 'legacy'] = Field(default="color", description='Log format. Use "plain" for text-only, "color" for colorized output, "legacy" for 2.3-style logging and "syslog" for syslog-style', category="Logging")
|
||||
log_level : Literal["debug", "info", "warning", "error", "critical"] = Field(default="info", description="Emit logging messages at this level or higher", category="Logging")
|
||||
log_sql : bool = Field(default=False, description="Log SQL queries", category="Logging")
|
||||
log_format : Literal['plain', 'color', 'syslog', 'legacy'] = Field(default="color", description='Log format. Use "plain" for text-only, "color" for colorized output, "legacy" for 2.3-style logging and "syslog" for syslog-style', json_schema_extra=Categories.Logging)
|
||||
log_level : Literal["debug", "info", "warning", "error", "critical"] = Field(default="info", description="Emit logging messages at this level or higher", json_schema_extra=Categories.Logging)
|
||||
log_sql : bool = Field(default=False, description="Log SQL queries", json_schema_extra=Categories.Logging)
|
||||
|
||||
dev_reload : bool = Field(default=False, description="Automatically reload when Python sources are changed.", category="Development")
|
||||
dev_reload : bool = Field(default=False, description="Automatically reload when Python sources are changed.", json_schema_extra=Categories.Development)
|
||||
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", category="Other")
|
||||
version : bool = Field(default=False, description="Show InvokeAI version and exit", json_schema_extra=Categories.Other)
|
||||
|
||||
# CACHE
|
||||
ram : Union[float, Literal["auto"]] = Field(default=6.0, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number or 'auto')", category="Model Cache", )
|
||||
vram : Union[float, Literal["auto"]] = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number or 'auto')", category="Model Cache", )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
ram : float = Field(default=7.5, gt=0, description="Maximum memory amount used by model cache for rapid switching (floating point number, GB)", json_schema_extra=Categories.ModelCache, )
|
||||
vram : float = Field(default=0.25, ge=0, description="Amount of VRAM reserved for model storage (floating point number, GB)", json_schema_extra=Categories.ModelCache, )
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", json_schema_extra=Categories.ModelCache, )
|
||||
|
||||
# DEVICE
|
||||
device : Literal["auto", "cpu", "cuda", "cuda:1", "mps"] = Field(default="auto", description="Generation device", category="Device", )
|
||||
precision : Literal["auto", "float16", "float32", "autocast"] = Field(default="auto", description="Floating point precision", category="Device", )
|
||||
device : Literal["auto", "cpu", "cuda", "cuda:1", "mps"] = Field(default="auto", description="Generation device", json_schema_extra=Categories.Device)
|
||||
precision : Literal["auto", "float16", "float32", "autocast"] = Field(default="auto", description="Floating point precision", json_schema_extra=Categories.Device)
|
||||
|
||||
# GENERATION
|
||||
sequential_guidance : bool = Field(default=False, description="Whether to calculate guidance in serial instead of in parallel, lowering memory requirements", category="Generation", )
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", category="Generation", )
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
sequential_guidance : bool = Field(default=False, description="Whether to calculate guidance in serial instead of in parallel, lowering memory requirements", json_schema_extra=Categories.Generation)
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", json_schema_extra=Categories.Generation)
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', json_schema_extra=Categories.Generation)
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", json_schema_extra=Categories.Generation)
|
||||
png_compress_level : int = Field(default=6, description="The compress_level setting of PIL.Image.save(), used for PNG encoding. All settings are lossless. 0 = fastest, largest filesize, 9 = slowest, smallest filesize", json_schema_extra=Categories.Generation)
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", json_schema_extra=Categories.Queue)
|
||||
|
||||
# NODES
|
||||
allow_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.", category="Nodes")
|
||||
deny_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to deny. Omit to deny none.", category="Nodes")
|
||||
node_cache_size : int = Field(default=512, description="How many cached nodes to keep in memory", category="Nodes", )
|
||||
allow_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.", json_schema_extra=Categories.Nodes)
|
||||
deny_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to deny. Omit to deny none.", json_schema_extra=Categories.Nodes)
|
||||
node_cache_size : int = Field(default=512, description="How many cached nodes to keep in memory", json_schema_extra=Categories.Nodes)
|
||||
|
||||
# DEPRECATED FIELDS - STILL HERE IN ORDER TO OBTAN VALUES FROM PRE-3.1 CONFIG FILES
|
||||
always_use_cpu : bool = Field(default=False, description="If true, use the CPU for rendering even if a GPU is available.", category='Memory/Performance')
|
||||
free_gpu_mem : Optional[bool] = Field(default=None, description="If true, purge model from GPU after each generation.", category='Memory/Performance')
|
||||
max_cache_size : Optional[float] = Field(default=None, gt=0, description="Maximum memory amount used by model cache for rapid switching", category='Memory/Performance')
|
||||
max_vram_cache_size : Optional[float] = Field(default=None, ge=0, description="Amount of VRAM reserved for model storage", category='Memory/Performance')
|
||||
xformers_enabled : bool = Field(default=True, description="Enable/disable memory-efficient attention", category='Memory/Performance')
|
||||
tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category='Memory/Performance')
|
||||
always_use_cpu : bool = Field(default=False, description="If true, use the CPU for rendering even if a GPU is available.", json_schema_extra=Categories.MemoryPerformance)
|
||||
free_gpu_mem : Optional[bool] = Field(default=None, description="If true, purge model from GPU after each generation.", json_schema_extra=Categories.MemoryPerformance)
|
||||
max_cache_size : Optional[float] = Field(default=None, gt=0, description="Maximum memory amount used by model cache for rapid switching", json_schema_extra=Categories.MemoryPerformance)
|
||||
max_vram_cache_size : Optional[float] = Field(default=None, ge=0, description="Amount of VRAM reserved for model storage", json_schema_extra=Categories.MemoryPerformance)
|
||||
xformers_enabled : bool = Field(default=True, description="Enable/disable memory-efficient attention", json_schema_extra=Categories.MemoryPerformance)
|
||||
tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", json_schema_extra=Categories.MemoryPerformance)
|
||||
|
||||
# See InvokeAIAppConfig subclass below for CACHE and DEVICE categories
|
||||
# fmt: on
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
model_config = SettingsConfigDict(validate_assignment=True, env_prefix="INVOKEAI")
|
||||
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
def parse_args(
|
||||
self,
|
||||
argv: Optional[list[str]] = None,
|
||||
conf: Optional[DictConfig] = None,
|
||||
clobber=False,
|
||||
):
|
||||
"""
|
||||
Update settings with contents of init file, environment, and
|
||||
command-line settings.
|
||||
@ -307,7 +326,11 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
if self.singleton_init and not clobber:
|
||||
hints = get_type_hints(self.__class__)
|
||||
for k in self.singleton_init:
|
||||
setattr(self, k, parse_obj_as(hints[k], self.singleton_init[k]))
|
||||
setattr(
|
||||
self,
|
||||
k,
|
||||
TypeAdapter(hints[k]).validate_python(self.singleton_init[k]),
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def get_config(cls, **kwargs) -> InvokeAIAppConfig:
|
||||
0
invokeai/app/services/events/__init__.py
Normal file
0
invokeai/app/services/events/__init__.py
Normal file
@ -2,10 +2,16 @@
|
||||
|
||||
from typing import Any, Optional
|
||||
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
from invokeai.app.services.model_manager_service import BaseModelType, ModelInfo, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import EnqueueBatchResult, SessionQueueItem
|
||||
from invokeai.app.services.invocation_processor.invocation_processor_common import ProgressImage
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
BatchStatus,
|
||||
EnqueueBatchResult,
|
||||
SessionQueueItem,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
from invokeai.backend.model_management.model_manager import ModelInfo
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType, SubModelType
|
||||
|
||||
|
||||
class EventServiceBase:
|
||||
@ -49,7 +55,7 @@ class EventServiceBase:
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node.get("id"),
|
||||
source_node_id=source_node_id,
|
||||
progress_image=progress_image.dict() if progress_image is not None else None,
|
||||
progress_image=progress_image.model_dump() if progress_image is not None else None,
|
||||
step=step,
|
||||
order=order,
|
||||
total_steps=total_steps,
|
||||
@ -262,21 +268,31 @@ class EventServiceBase:
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_item_status_changed(self, session_queue_item: SessionQueueItem) -> None:
|
||||
def emit_queue_item_status_changed(
|
||||
self,
|
||||
session_queue_item: SessionQueueItem,
|
||||
batch_status: BatchStatus,
|
||||
queue_status: SessionQueueStatus,
|
||||
) -> None:
|
||||
"""Emitted when a queue item's status changes"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_item_status_changed",
|
||||
payload=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
queue_item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
queue_id=queue_status.queue_id,
|
||||
queue_item=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
batch_status=batch_status.model_dump(),
|
||||
queue_status=queue_status.model_dump(),
|
||||
),
|
||||
)
|
||||
|
||||
0
invokeai/app/services/image_files/__init__.py
Normal file
0
invokeai/app/services/image_files/__init__.py
Normal file
43
invokeai/app/services/image_files/image_files_base.py
Normal file
43
invokeai/app/services/image_files/image_files_base.py
Normal file
@ -0,0 +1,43 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from typing import Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
|
||||
|
||||
class ImageFileStorageBase(ABC):
|
||||
"""Low-level service responsible for storing and retrieving image files."""
|
||||
|
||||
@abstractmethod
|
||||
def get(self, image_name: str) -> PILImageType:
|
||||
"""Retrieves an image as PIL Image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> Path:
|
||||
"""Gets the internal path to an image or thumbnail."""
|
||||
pass
|
||||
|
||||
# TODO: We need to validate paths before starlette makes the FileResponse, else we get a
|
||||
# 500 internal server error. I don't like having this method on the service.
|
||||
@abstractmethod
|
||||
def validate_path(self, path: str) -> bool:
|
||||
"""Validates the path given for an image or thumbnail."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_name: str,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
thumbnail_size: int = 256,
|
||||
) -> None:
|
||||
"""Saves an image and a 256x256 WEBP thumbnail. Returns a tuple of the image name, thumbnail name, and created timestamp."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str) -> None:
|
||||
"""Deletes an image and its thumbnail (if one exists)."""
|
||||
pass
|
||||
20
invokeai/app/services/image_files/image_files_common.py
Normal file
20
invokeai/app/services/image_files/image_files_common.py
Normal file
@ -0,0 +1,20 @@
|
||||
# TODO: Should these excpetions subclass existing python exceptions?
|
||||
class ImageFileNotFoundException(Exception):
|
||||
"""Raised when an image file is not found in storage."""
|
||||
|
||||
def __init__(self, message="Image file not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageFileSaveException(Exception):
|
||||
"""Raised when an image cannot be saved."""
|
||||
|
||||
def __init__(self, message="Image file not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageFileDeleteException(Exception):
|
||||
"""Raised when an image cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Image file not deleted"):
|
||||
super().__init__(message)
|
||||
@ -1,6 +1,5 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654) and the InvokeAI Team
|
||||
import json
|
||||
from abc import ABC, abstractmethod
|
||||
from pathlib import Path
|
||||
from queue import Queue
|
||||
from typing import Dict, Optional, Union
|
||||
@ -9,67 +8,11 @@ from PIL import Image, PngImagePlugin
|
||||
from PIL.Image import Image as PILImageType
|
||||
from send2trash import send2trash
|
||||
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.util.thumbnails import get_thumbnail_name, make_thumbnail
|
||||
|
||||
|
||||
# TODO: Should these excpetions subclass existing python exceptions?
|
||||
class ImageFileNotFoundException(Exception):
|
||||
"""Raised when an image file is not found in storage."""
|
||||
|
||||
def __init__(self, message="Image file not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageFileSaveException(Exception):
|
||||
"""Raised when an image cannot be saved."""
|
||||
|
||||
def __init__(self, message="Image file not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageFileDeleteException(Exception):
|
||||
"""Raised when an image cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Image file not deleted"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageFileStorageBase(ABC):
|
||||
"""Low-level service responsible for storing and retrieving image files."""
|
||||
|
||||
@abstractmethod
|
||||
def get(self, image_name: str) -> PILImageType:
|
||||
"""Retrieves an image as PIL Image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
"""Gets the internal path to an image or thumbnail."""
|
||||
pass
|
||||
|
||||
# TODO: We need to validate paths before starlette makes the FileResponse, else we get a
|
||||
# 500 internal server error. I don't like having this method on the service.
|
||||
@abstractmethod
|
||||
def validate_path(self, path: str) -> bool:
|
||||
"""Validates the path given for an image or thumbnail."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_name: str,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
thumbnail_size: int = 256,
|
||||
) -> None:
|
||||
"""Saves an image and a 256x256 WEBP thumbnail. Returns a tuple of the image name, thumbnail name, and created timestamp."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str) -> None:
|
||||
"""Deletes an image and its thumbnail (if one exists)."""
|
||||
pass
|
||||
from .image_files_base import ImageFileStorageBase
|
||||
from .image_files_common import ImageFileDeleteException, ImageFileNotFoundException, ImageFileSaveException
|
||||
|
||||
|
||||
class DiskImageFileStorage(ImageFileStorageBase):
|
||||
@ -79,6 +22,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
__cache_ids: Queue # TODO: this is an incredibly naive cache
|
||||
__cache: Dict[Path, PILImageType]
|
||||
__max_cache_size: int
|
||||
__invoker: Invoker
|
||||
|
||||
def __init__(self, output_folder: Union[str, Path]):
|
||||
self.__cache = dict()
|
||||
@ -87,10 +31,12 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
|
||||
self.__output_folder: Path = output_folder if isinstance(output_folder, Path) else Path(output_folder)
|
||||
self.__thumbnails_folder = self.__output_folder / "thumbnails"
|
||||
|
||||
# Validate required output folders at launch
|
||||
self.__validate_storage_folders()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
|
||||
def get(self, image_name: str) -> PILImageType:
|
||||
try:
|
||||
image_path = self.get_path(image_name)
|
||||
@ -134,7 +80,12 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
if original_workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", original_workflow)
|
||||
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo)
|
||||
image.save(
|
||||
image_path,
|
||||
"PNG",
|
||||
pnginfo=pnginfo,
|
||||
compress_level=self.__invoker.services.configuration.png_compress_level,
|
||||
)
|
||||
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
thumbnail_path = self.get_path(thumbnail_name, thumbnail=True)
|
||||
0
invokeai/app/services/image_records/__init__.py
Normal file
0
invokeai/app/services/image_records/__init__.py
Normal file
84
invokeai/app/services/image_records/image_records_base.py
Normal file
84
invokeai/app/services/image_records/image_records_base.py
Normal file
@ -0,0 +1,84 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from datetime import datetime
|
||||
from typing import Optional
|
||||
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
from .image_records_common import ImageCategory, ImageRecord, ImageRecordChanges, ResourceOrigin
|
||||
|
||||
|
||||
class ImageRecordStorageBase(ABC):
|
||||
"""Low-level service responsible for interfacing with the image record store."""
|
||||
|
||||
# TODO: Implement an `update()` method
|
||||
|
||||
@abstractmethod
|
||||
def get(self, image_name: str) -> ImageRecord:
|
||||
"""Gets an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_metadata(self, image_name: str) -> Optional[dict]:
|
||||
"""Gets an image's metadata'."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> None:
|
||||
"""Updates an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageRecord]:
|
||||
"""Gets a page of image records."""
|
||||
pass
|
||||
|
||||
# TODO: The database has a nullable `deleted_at` column, currently unused.
|
||||
# Should we implement soft deletes? Would need coordination with ImageFileStorage.
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str) -> None:
|
||||
"""Deletes an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_many(self, image_names: list[str]) -> None:
|
||||
"""Deletes many image records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_intermediates(self) -> list[str]:
|
||||
"""Deletes all intermediate image records, returning a list of deleted image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
image_name: str,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
width: int,
|
||||
height: int,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
starred: Optional[bool] = False,
|
||||
session_id: Optional[str] = None,
|
||||
node_id: Optional[str] = None,
|
||||
metadata: Optional[dict] = None,
|
||||
) -> datetime:
|
||||
"""Saves an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_most_recent_image_for_board(self, board_id: str) -> Optional[ImageRecord]:
|
||||
"""Gets the most recent image for a board."""
|
||||
pass
|
||||
@ -1,13 +1,117 @@
|
||||
# TODO: Should these excpetions subclass existing python exceptions?
|
||||
import datetime
|
||||
from enum import Enum
|
||||
from typing import Optional, Union
|
||||
|
||||
from pydantic import Extra, Field, StrictBool, StrictStr
|
||||
from pydantic import Field, StrictBool, StrictStr
|
||||
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.util.metaenum import MetaEnum
|
||||
from invokeai.app.util.misc import get_iso_timestamp
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
|
||||
class ResourceOrigin(str, Enum, metaclass=MetaEnum):
|
||||
"""The origin of a resource (eg image).
|
||||
|
||||
- INTERNAL: The resource was created by the application.
|
||||
- EXTERNAL: The resource was not created by the application.
|
||||
This may be a user-initiated upload, or an internal application upload (eg Canvas init image).
|
||||
"""
|
||||
|
||||
INTERNAL = "internal"
|
||||
"""The resource was created by the application."""
|
||||
EXTERNAL = "external"
|
||||
"""The resource was not created by the application.
|
||||
This may be a user-initiated upload, or an internal application upload (eg Canvas init image).
|
||||
"""
|
||||
|
||||
|
||||
class InvalidOriginException(ValueError):
|
||||
"""Raised when a provided value is not a valid ResourceOrigin.
|
||||
|
||||
Subclasses `ValueError`.
|
||||
"""
|
||||
|
||||
def __init__(self, message="Invalid resource origin."):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageCategory(str, Enum, metaclass=MetaEnum):
|
||||
"""The category of an image.
|
||||
|
||||
- GENERAL: The image is an output, init image, or otherwise an image without a specialized purpose.
|
||||
- MASK: The image is a mask image.
|
||||
- CONTROL: The image is a ControlNet control image.
|
||||
- USER: The image is a user-provide image.
|
||||
- OTHER: The image is some other type of image with a specialized purpose. To be used by external nodes.
|
||||
"""
|
||||
|
||||
GENERAL = "general"
|
||||
"""GENERAL: The image is an output, init image, or otherwise an image without a specialized purpose."""
|
||||
MASK = "mask"
|
||||
"""MASK: The image is a mask image."""
|
||||
CONTROL = "control"
|
||||
"""CONTROL: The image is a ControlNet control image."""
|
||||
USER = "user"
|
||||
"""USER: The image is a user-provide image."""
|
||||
OTHER = "other"
|
||||
"""OTHER: The image is some other type of image with a specialized purpose. To be used by external nodes."""
|
||||
|
||||
|
||||
class InvalidImageCategoryException(ValueError):
|
||||
"""Raised when a provided value is not a valid ImageCategory.
|
||||
|
||||
Subclasses `ValueError`.
|
||||
"""
|
||||
|
||||
def __init__(self, message="Invalid image category."):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageRecordNotFoundException(Exception):
|
||||
"""Raised when an image record is not found."""
|
||||
|
||||
def __init__(self, message="Image record not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageRecordSaveException(Exception):
|
||||
"""Raised when an image record cannot be saved."""
|
||||
|
||||
def __init__(self, message="Image record not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageRecordDeleteException(Exception):
|
||||
"""Raised when an image record cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Image record not deleted"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
IMAGE_DTO_COLS = ", ".join(
|
||||
list(
|
||||
map(
|
||||
lambda c: "images." + c,
|
||||
[
|
||||
"image_name",
|
||||
"image_origin",
|
||||
"image_category",
|
||||
"width",
|
||||
"height",
|
||||
"session_id",
|
||||
"node_id",
|
||||
"is_intermediate",
|
||||
"created_at",
|
||||
"updated_at",
|
||||
"deleted_at",
|
||||
"starred",
|
||||
],
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
class ImageRecord(BaseModelExcludeNull):
|
||||
"""Deserialized image record without metadata."""
|
||||
|
||||
@ -25,7 +129,9 @@ class ImageRecord(BaseModelExcludeNull):
|
||||
"""The created timestamp of the image."""
|
||||
updated_at: Union[datetime.datetime, str] = Field(description="The updated timestamp of the image.")
|
||||
"""The updated timestamp of the image."""
|
||||
deleted_at: Union[datetime.datetime, str, None] = Field(description="The deleted timestamp of the image.")
|
||||
deleted_at: Optional[Union[datetime.datetime, str]] = Field(
|
||||
default=None, description="The deleted timestamp of the image."
|
||||
)
|
||||
"""The deleted timestamp of the image."""
|
||||
is_intermediate: bool = Field(description="Whether this is an intermediate image.")
|
||||
"""Whether this is an intermediate image."""
|
||||
@ -43,7 +149,7 @@ class ImageRecord(BaseModelExcludeNull):
|
||||
"""Whether this image is starred."""
|
||||
|
||||
|
||||
class ImageRecordChanges(BaseModelExcludeNull, extra=Extra.forbid):
|
||||
class ImageRecordChanges(BaseModelExcludeNull, extra="allow"):
|
||||
"""A set of changes to apply to an image record.
|
||||
|
||||
Only limited changes are valid:
|
||||
@ -66,41 +172,6 @@ class ImageRecordChanges(BaseModelExcludeNull, extra=Extra.forbid):
|
||||
"""The image's new `starred` state."""
|
||||
|
||||
|
||||
class ImageUrlsDTO(BaseModelExcludeNull):
|
||||
"""The URLs for an image and its thumbnail."""
|
||||
|
||||
image_name: str = Field(description="The unique name of the image.")
|
||||
"""The unique name of the image."""
|
||||
image_url: str = Field(description="The URL of the image.")
|
||||
"""The URL of the image."""
|
||||
thumbnail_url: str = Field(description="The URL of the image's thumbnail.")
|
||||
"""The URL of the image's thumbnail."""
|
||||
|
||||
|
||||
class ImageDTO(ImageRecord, ImageUrlsDTO):
|
||||
"""Deserialized image record, enriched for the frontend."""
|
||||
|
||||
board_id: Optional[str] = Field(description="The id of the board the image belongs to, if one exists.")
|
||||
"""The id of the board the image belongs to, if one exists."""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
def image_record_to_dto(
|
||||
image_record: ImageRecord,
|
||||
image_url: str,
|
||||
thumbnail_url: str,
|
||||
board_id: Optional[str],
|
||||
) -> ImageDTO:
|
||||
"""Converts an image record to an image DTO."""
|
||||
return ImageDTO(
|
||||
**image_record.dict(),
|
||||
image_url=image_url,
|
||||
thumbnail_url=thumbnail_url,
|
||||
board_id=board_id,
|
||||
)
|
||||
|
||||
|
||||
def deserialize_image_record(image_dict: dict) -> ImageRecord:
|
||||
"""Deserializes an image record."""
|
||||
|
||||
@ -1,164 +1,36 @@
|
||||
import json
|
||||
import sqlite3
|
||||
import threading
|
||||
from abc import ABC, abstractmethod
|
||||
from datetime import datetime
|
||||
from typing import Generic, Optional, TypeVar, cast
|
||||
from typing import Optional, Union, cast
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic.generics import GenericModel
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.services.shared.sqlite import SqliteDatabase
|
||||
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.models.image_record import ImageRecord, ImageRecordChanges, deserialize_image_record
|
||||
|
||||
T = TypeVar("T", bound=BaseModel)
|
||||
|
||||
|
||||
class OffsetPaginatedResults(GenericModel, Generic[T]):
|
||||
"""Offset-paginated results"""
|
||||
|
||||
# fmt: off
|
||||
items: list[T] = Field(description="Items")
|
||||
offset: int = Field(description="Offset from which to retrieve items")
|
||||
limit: int = Field(description="Limit of items to get")
|
||||
total: int = Field(description="Total number of items in result")
|
||||
# fmt: on
|
||||
|
||||
|
||||
# TODO: Should these excpetions subclass existing python exceptions?
|
||||
class ImageRecordNotFoundException(Exception):
|
||||
"""Raised when an image record is not found."""
|
||||
|
||||
def __init__(self, message="Image record not found"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageRecordSaveException(Exception):
|
||||
"""Raised when an image record cannot be saved."""
|
||||
|
||||
def __init__(self, message="Image record not saved"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
class ImageRecordDeleteException(Exception):
|
||||
"""Raised when an image record cannot be deleted."""
|
||||
|
||||
def __init__(self, message="Image record not deleted"):
|
||||
super().__init__(message)
|
||||
|
||||
|
||||
IMAGE_DTO_COLS = ", ".join(
|
||||
list(
|
||||
map(
|
||||
lambda c: "images." + c,
|
||||
[
|
||||
"image_name",
|
||||
"image_origin",
|
||||
"image_category",
|
||||
"width",
|
||||
"height",
|
||||
"session_id",
|
||||
"node_id",
|
||||
"is_intermediate",
|
||||
"created_at",
|
||||
"updated_at",
|
||||
"deleted_at",
|
||||
"starred",
|
||||
],
|
||||
)
|
||||
)
|
||||
from .image_records_base import ImageRecordStorageBase
|
||||
from .image_records_common import (
|
||||
IMAGE_DTO_COLS,
|
||||
ImageCategory,
|
||||
ImageRecord,
|
||||
ImageRecordChanges,
|
||||
ImageRecordDeleteException,
|
||||
ImageRecordNotFoundException,
|
||||
ImageRecordSaveException,
|
||||
ResourceOrigin,
|
||||
deserialize_image_record,
|
||||
)
|
||||
|
||||
|
||||
class ImageRecordStorageBase(ABC):
|
||||
"""Low-level service responsible for interfacing with the image record store."""
|
||||
|
||||
# TODO: Implement an `update()` method
|
||||
|
||||
@abstractmethod
|
||||
def get(self, image_name: str) -> ImageRecord:
|
||||
"""Gets an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_metadata(self, image_name: str) -> Optional[dict]:
|
||||
"""Gets an image's metadata'."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> None:
|
||||
"""Updates an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: Optional[int] = None,
|
||||
limit: Optional[int] = None,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageRecord]:
|
||||
"""Gets a page of image records."""
|
||||
pass
|
||||
|
||||
# TODO: The database has a nullable `deleted_at` column, currently unused.
|
||||
# Should we implement soft deletes? Would need coordination with ImageFileStorage.
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str) -> None:
|
||||
"""Deletes an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_many(self, image_names: list[str]) -> None:
|
||||
"""Deletes many image records."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_intermediates(self) -> list[str]:
|
||||
"""Deletes all intermediate image records, returning a list of deleted image names."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(
|
||||
self,
|
||||
image_name: str,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
width: int,
|
||||
height: int,
|
||||
session_id: Optional[str],
|
||||
node_id: Optional[str],
|
||||
metadata: Optional[dict],
|
||||
is_intermediate: bool = False,
|
||||
starred: bool = False,
|
||||
) -> datetime:
|
||||
"""Saves an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_most_recent_image_for_board(self, board_id: str) -> Optional[ImageRecord]:
|
||||
"""Gets the most recent image for a board."""
|
||||
pass
|
||||
|
||||
|
||||
class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
_lock: threading.RLock
|
||||
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
def __init__(self, db: SqliteDatabase) -> None:
|
||||
super().__init__()
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._lock = db.lock
|
||||
self._conn = db.conn
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
@ -245,7 +117,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
"""
|
||||
)
|
||||
|
||||
def get(self, image_name: str) -> Optional[ImageRecord]:
|
||||
def get(self, image_name: str) -> ImageRecord:
|
||||
try:
|
||||
self._lock.acquire()
|
||||
|
||||
@ -351,8 +223,8 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
offset: Optional[int] = None,
|
||||
limit: Optional[int] = None,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
@ -377,7 +249,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
"""
|
||||
|
||||
query_conditions = ""
|
||||
query_params = []
|
||||
query_params: list[Union[int, str, bool]] = []
|
||||
|
||||
if image_origin is not None:
|
||||
query_conditions += """--sql
|
||||
@ -515,13 +387,13 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
image_name: str,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
session_id: Optional[str],
|
||||
width: int,
|
||||
height: int,
|
||||
node_id: Optional[str],
|
||||
metadata: Optional[dict],
|
||||
is_intermediate: bool = False,
|
||||
starred: bool = False,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
starred: Optional[bool] = False,
|
||||
session_id: Optional[str] = None,
|
||||
node_id: Optional[str] = None,
|
||||
metadata: Optional[dict] = None,
|
||||
) -> datetime:
|
||||
try:
|
||||
metadata_json = None if metadata is None else json.dumps(metadata)
|
||||
@ -584,7 +456,7 @@ class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
FROM images
|
||||
JOIN board_images ON images.image_name = board_images.image_name
|
||||
WHERE board_images.board_id = ?
|
||||
ORDER BY images.created_at DESC
|
||||
ORDER BY images.starred DESC, images.created_at DESC
|
||||
LIMIT 1;
|
||||
""",
|
||||
(board_id,),
|
||||
@ -1,449 +0,0 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
from typing import TYPE_CHECKING, Callable, Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
|
||||
from invokeai.app.invocations.metadata import ImageMetadata
|
||||
from invokeai.app.models.image import (
|
||||
ImageCategory,
|
||||
InvalidImageCategoryException,
|
||||
InvalidOriginException,
|
||||
ResourceOrigin,
|
||||
)
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.image_file_storage import (
|
||||
ImageFileDeleteException,
|
||||
ImageFileNotFoundException,
|
||||
ImageFileSaveException,
|
||||
ImageFileStorageBase,
|
||||
)
|
||||
from invokeai.app.services.image_record_storage import (
|
||||
ImageRecordDeleteException,
|
||||
ImageRecordNotFoundException,
|
||||
ImageRecordSaveException,
|
||||
ImageRecordStorageBase,
|
||||
OffsetPaginatedResults,
|
||||
)
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.models.image_record import ImageDTO, ImageRecord, ImageRecordChanges, image_record_to_dto
|
||||
from invokeai.app.services.resource_name import NameServiceBase
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
from invokeai.app.util.metadata import get_metadata_graph_from_raw_session
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from invokeai.app.services.graph import GraphExecutionState
|
||||
|
||||
|
||||
class ImageServiceABC(ABC):
|
||||
"""High-level service for image management."""
|
||||
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an image is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an image is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
"""Creates an image, storing the file and its metadata."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> ImageDTO:
|
||||
"""Updates an image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_pil_image(self, image_name: str) -> PILImageType:
|
||||
"""Gets an image as a PIL image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_record(self, image_name: str) -> ImageRecord:
|
||||
"""Gets an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_dto(self, image_name: str) -> ImageDTO:
|
||||
"""Gets an image DTO."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_metadata(self, image_name: str) -> ImageMetadata:
|
||||
"""Gets an image's metadata."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
"""Gets an image's path."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def validate_path(self, path: str) -> bool:
|
||||
"""Validates an image's path."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_url(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
"""Gets an image's or thumbnail's URL."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageDTO]:
|
||||
"""Gets a paginated list of image DTOs."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str):
|
||||
"""Deletes an image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_intermediates(self) -> int:
|
||||
"""Deletes all intermediate images."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_images_on_board(self, board_id: str):
|
||||
"""Deletes all images on a board."""
|
||||
pass
|
||||
|
||||
|
||||
class ImageServiceDependencies:
|
||||
"""Service dependencies for the ImageService."""
|
||||
|
||||
image_records: ImageRecordStorageBase
|
||||
image_files: ImageFileStorageBase
|
||||
board_image_records: BoardImageRecordStorageBase
|
||||
urls: UrlServiceBase
|
||||
logger: Logger
|
||||
names: NameServiceBase
|
||||
graph_execution_manager: ItemStorageABC["GraphExecutionState"]
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
image_record_storage: ImageRecordStorageBase,
|
||||
image_file_storage: ImageFileStorageBase,
|
||||
board_image_record_storage: BoardImageRecordStorageBase,
|
||||
url: UrlServiceBase,
|
||||
logger: Logger,
|
||||
names: NameServiceBase,
|
||||
graph_execution_manager: ItemStorageABC["GraphExecutionState"],
|
||||
):
|
||||
self.image_records = image_record_storage
|
||||
self.image_files = image_file_storage
|
||||
self.board_image_records = board_image_record_storage
|
||||
self.urls = url
|
||||
self.logger = logger
|
||||
self.names = names
|
||||
self.graph_execution_manager = graph_execution_manager
|
||||
|
||||
|
||||
class ImageService(ImageServiceABC):
|
||||
_services: ImageServiceDependencies
|
||||
|
||||
def __init__(self, services: ImageServiceDependencies):
|
||||
super().__init__()
|
||||
self._services = services
|
||||
|
||||
def create(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
if image_origin not in ResourceOrigin:
|
||||
raise InvalidOriginException
|
||||
|
||||
if image_category not in ImageCategory:
|
||||
raise InvalidImageCategoryException
|
||||
|
||||
image_name = self._services.names.create_image_name()
|
||||
|
||||
# TODO: Do we want to store the graph in the image at all? I don't think so...
|
||||
# graph = None
|
||||
# if session_id is not None:
|
||||
# session_raw = self._services.graph_execution_manager.get_raw(session_id)
|
||||
# if session_raw is not None:
|
||||
# try:
|
||||
# graph = get_metadata_graph_from_raw_session(session_raw)
|
||||
# except Exception as e:
|
||||
# self._services.logger.warn(f"Failed to parse session graph: {e}")
|
||||
# graph = None
|
||||
|
||||
(width, height) = image.size
|
||||
|
||||
try:
|
||||
# TODO: Consider using a transaction here to ensure consistency between storage and database
|
||||
self._services.image_records.save(
|
||||
# Non-nullable fields
|
||||
image_name=image_name,
|
||||
image_origin=image_origin,
|
||||
image_category=image_category,
|
||||
width=width,
|
||||
height=height,
|
||||
# Meta fields
|
||||
is_intermediate=is_intermediate,
|
||||
# Nullable fields
|
||||
node_id=node_id,
|
||||
metadata=metadata,
|
||||
session_id=session_id,
|
||||
)
|
||||
if board_id is not None:
|
||||
self._services.board_image_records.add_image_to_board(board_id=board_id, image_name=image_name)
|
||||
self._services.image_files.save(image_name=image_name, image=image, metadata=metadata, workflow=workflow)
|
||||
image_dto = self.get_dto(image_name)
|
||||
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self._services.logger.error("Failed to save image record")
|
||||
raise
|
||||
except ImageFileSaveException:
|
||||
self._services.logger.error("Failed to save image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error(f"Problem saving image record and file: {str(e)}")
|
||||
raise e
|
||||
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> ImageDTO:
|
||||
try:
|
||||
self._services.image_records.update(image_name, changes)
|
||||
image_dto = self.get_dto(image_name)
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self._services.logger.error("Failed to update image record")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem updating image record")
|
||||
raise e
|
||||
|
||||
def get_pil_image(self, image_name: str) -> PILImageType:
|
||||
try:
|
||||
return self._services.image_files.get(image_name)
|
||||
except ImageFileNotFoundException:
|
||||
self._services.logger.error("Failed to get image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image file")
|
||||
raise e
|
||||
|
||||
def get_record(self, image_name: str) -> ImageRecord:
|
||||
try:
|
||||
return self._services.image_records.get(image_name)
|
||||
except ImageRecordNotFoundException:
|
||||
self._services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image record")
|
||||
raise e
|
||||
|
||||
def get_dto(self, image_name: str) -> ImageDTO:
|
||||
try:
|
||||
image_record = self._services.image_records.get(image_name)
|
||||
|
||||
image_dto = image_record_to_dto(
|
||||
image_record,
|
||||
self._services.urls.get_image_url(image_name),
|
||||
self._services.urls.get_image_url(image_name, True),
|
||||
self._services.board_image_records.get_board_for_image(image_name),
|
||||
)
|
||||
|
||||
return image_dto
|
||||
except ImageRecordNotFoundException:
|
||||
self._services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image DTO")
|
||||
raise e
|
||||
|
||||
def get_metadata(self, image_name: str) -> Optional[ImageMetadata]:
|
||||
try:
|
||||
image_record = self._services.image_records.get(image_name)
|
||||
metadata = self._services.image_records.get_metadata(image_name)
|
||||
|
||||
if not image_record.session_id:
|
||||
return ImageMetadata(metadata=metadata)
|
||||
|
||||
session_raw = self._services.graph_execution_manager.get_raw(image_record.session_id)
|
||||
graph = None
|
||||
|
||||
if session_raw:
|
||||
try:
|
||||
graph = get_metadata_graph_from_raw_session(session_raw)
|
||||
except Exception as e:
|
||||
self._services.logger.warn(f"Failed to parse session graph: {e}")
|
||||
graph = None
|
||||
|
||||
return ImageMetadata(graph=graph, metadata=metadata)
|
||||
except ImageRecordNotFoundException:
|
||||
self._services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image DTO")
|
||||
raise e
|
||||
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
try:
|
||||
return self._services.image_files.get_path(image_name, thumbnail)
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image path")
|
||||
raise e
|
||||
|
||||
def validate_path(self, path: str) -> bool:
|
||||
try:
|
||||
return self._services.image_files.validate_path(path)
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem validating image path")
|
||||
raise e
|
||||
|
||||
def get_url(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
try:
|
||||
return self._services.urls.get_image_url(image_name, thumbnail)
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting image path")
|
||||
raise e
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageDTO]:
|
||||
try:
|
||||
results = self._services.image_records.get_many(
|
||||
offset,
|
||||
limit,
|
||||
image_origin,
|
||||
categories,
|
||||
is_intermediate,
|
||||
board_id,
|
||||
)
|
||||
|
||||
image_dtos = list(
|
||||
map(
|
||||
lambda r: image_record_to_dto(
|
||||
r,
|
||||
self._services.urls.get_image_url(r.image_name),
|
||||
self._services.urls.get_image_url(r.image_name, True),
|
||||
self._services.board_image_records.get_board_for_image(r.image_name),
|
||||
),
|
||||
results.items,
|
||||
)
|
||||
)
|
||||
|
||||
return OffsetPaginatedResults[ImageDTO](
|
||||
items=image_dtos,
|
||||
offset=results.offset,
|
||||
limit=results.limit,
|
||||
total=results.total,
|
||||
)
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem getting paginated image DTOs")
|
||||
raise e
|
||||
|
||||
def delete(self, image_name: str):
|
||||
try:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._services.image_records.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image record")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self._services.logger.error("Failed to delete image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem deleting image record and file")
|
||||
raise e
|
||||
|
||||
def delete_images_on_board(self, board_id: str):
|
||||
try:
|
||||
image_names = self._services.board_image_records.get_all_board_image_names_for_board(board_id)
|
||||
for image_name in image_names:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._services.image_records.delete_many(image_names)
|
||||
for image_name in image_names:
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image records")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self._services.logger.error("Failed to delete image files")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem deleting image records and files")
|
||||
raise e
|
||||
|
||||
def delete_intermediates(self) -> int:
|
||||
try:
|
||||
image_names = self._services.image_records.delete_intermediates()
|
||||
count = len(image_names)
|
||||
for image_name in image_names:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
return count
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image records")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self._services.logger.error("Failed to delete image files")
|
||||
raise
|
||||
except Exception as e:
|
||||
self._services.logger.error("Problem deleting image records and files")
|
||||
raise e
|
||||
0
invokeai/app/services/images/__init__.py
Normal file
0
invokeai/app/services/images/__init__.py
Normal file
129
invokeai/app/services/images/images_base.py
Normal file
129
invokeai/app/services/images/images_base.py
Normal file
@ -0,0 +1,129 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Callable, Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
|
||||
from invokeai.app.invocations.metadata import ImageMetadata
|
||||
from invokeai.app.services.image_records.image_records_common import (
|
||||
ImageCategory,
|
||||
ImageRecord,
|
||||
ImageRecordChanges,
|
||||
ResourceOrigin,
|
||||
)
|
||||
from invokeai.app.services.images.images_common import ImageDTO
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
|
||||
|
||||
class ImageServiceABC(ABC):
|
||||
"""High-level service for image management."""
|
||||
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an image is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an image is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
"""Creates an image, storing the file and its metadata."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> ImageDTO:
|
||||
"""Updates an image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_pil_image(self, image_name: str) -> PILImageType:
|
||||
"""Gets an image as a PIL image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_record(self, image_name: str) -> ImageRecord:
|
||||
"""Gets an image record."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_dto(self, image_name: str) -> ImageDTO:
|
||||
"""Gets an image DTO."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_metadata(self, image_name: str) -> ImageMetadata:
|
||||
"""Gets an image's metadata."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
"""Gets an image's path."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def validate_path(self, path: str) -> bool:
|
||||
"""Validates an image's path."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_url(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
"""Gets an image's or thumbnail's URL."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageDTO]:
|
||||
"""Gets a paginated list of image DTOs."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, image_name: str):
|
||||
"""Deletes an image."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_intermediates(self) -> int:
|
||||
"""Deletes all intermediate images."""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete_images_on_board(self, board_id: str):
|
||||
"""Deletes all images on a board."""
|
||||
pass
|
||||
43
invokeai/app/services/images/images_common.py
Normal file
43
invokeai/app/services/images/images_common.py
Normal file
@ -0,0 +1,43 @@
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
from invokeai.app.services.image_records.image_records_common import ImageRecord
|
||||
from invokeai.app.util.model_exclude_null import BaseModelExcludeNull
|
||||
|
||||
|
||||
class ImageUrlsDTO(BaseModelExcludeNull):
|
||||
"""The URLs for an image and its thumbnail."""
|
||||
|
||||
image_name: str = Field(description="The unique name of the image.")
|
||||
"""The unique name of the image."""
|
||||
image_url: str = Field(description="The URL of the image.")
|
||||
"""The URL of the image."""
|
||||
thumbnail_url: str = Field(description="The URL of the image's thumbnail.")
|
||||
"""The URL of the image's thumbnail."""
|
||||
|
||||
|
||||
class ImageDTO(ImageRecord, ImageUrlsDTO):
|
||||
"""Deserialized image record, enriched for the frontend."""
|
||||
|
||||
board_id: Optional[str] = Field(
|
||||
default=None, description="The id of the board the image belongs to, if one exists."
|
||||
)
|
||||
"""The id of the board the image belongs to, if one exists."""
|
||||
|
||||
pass
|
||||
|
||||
|
||||
def image_record_to_dto(
|
||||
image_record: ImageRecord,
|
||||
image_url: str,
|
||||
thumbnail_url: str,
|
||||
board_id: Optional[str],
|
||||
) -> ImageDTO:
|
||||
"""Converts an image record to an image DTO."""
|
||||
return ImageDTO(
|
||||
**image_record.model_dump(),
|
||||
image_url=image_url,
|
||||
thumbnail_url=thumbnail_url,
|
||||
board_id=board_id,
|
||||
)
|
||||
286
invokeai/app/services/images/images_default.py
Normal file
286
invokeai/app/services/images/images_default.py
Normal file
@ -0,0 +1,286 @@
|
||||
from typing import Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
|
||||
from invokeai.app.invocations.metadata import ImageMetadata
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
from invokeai.app.services.shared.pagination import OffsetPaginatedResults
|
||||
from invokeai.app.util.metadata import get_metadata_graph_from_raw_session
|
||||
|
||||
from ..image_files.image_files_common import (
|
||||
ImageFileDeleteException,
|
||||
ImageFileNotFoundException,
|
||||
ImageFileSaveException,
|
||||
)
|
||||
from ..image_records.image_records_common import (
|
||||
ImageCategory,
|
||||
ImageRecord,
|
||||
ImageRecordChanges,
|
||||
ImageRecordDeleteException,
|
||||
ImageRecordNotFoundException,
|
||||
ImageRecordSaveException,
|
||||
InvalidImageCategoryException,
|
||||
InvalidOriginException,
|
||||
ResourceOrigin,
|
||||
)
|
||||
from .images_base import ImageServiceABC
|
||||
from .images_common import ImageDTO, image_record_to_dto
|
||||
|
||||
|
||||
class ImageService(ImageServiceABC):
|
||||
__invoker: Invoker
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
|
||||
def create(
|
||||
self,
|
||||
image: PILImageType,
|
||||
image_origin: ResourceOrigin,
|
||||
image_category: ImageCategory,
|
||||
node_id: Optional[str] = None,
|
||||
session_id: Optional[str] = None,
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: Optional[bool] = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
if image_origin not in ResourceOrigin:
|
||||
raise InvalidOriginException
|
||||
|
||||
if image_category not in ImageCategory:
|
||||
raise InvalidImageCategoryException
|
||||
|
||||
image_name = self.__invoker.services.names.create_image_name()
|
||||
|
||||
(width, height) = image.size
|
||||
|
||||
try:
|
||||
# TODO: Consider using a transaction here to ensure consistency between storage and database
|
||||
self.__invoker.services.image_records.save(
|
||||
# Non-nullable fields
|
||||
image_name=image_name,
|
||||
image_origin=image_origin,
|
||||
image_category=image_category,
|
||||
width=width,
|
||||
height=height,
|
||||
# Meta fields
|
||||
is_intermediate=is_intermediate,
|
||||
# Nullable fields
|
||||
node_id=node_id,
|
||||
metadata=metadata,
|
||||
session_id=session_id,
|
||||
)
|
||||
if board_id is not None:
|
||||
self.__invoker.services.board_image_records.add_image_to_board(board_id=board_id, image_name=image_name)
|
||||
self.__invoker.services.image_files.save(
|
||||
image_name=image_name, image=image, metadata=metadata, workflow=workflow
|
||||
)
|
||||
image_dto = self.get_dto(image_name)
|
||||
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self.__invoker.services.logger.error("Failed to save image record")
|
||||
raise
|
||||
except ImageFileSaveException:
|
||||
self.__invoker.services.logger.error("Failed to save image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error(f"Problem saving image record and file: {str(e)}")
|
||||
raise e
|
||||
|
||||
def update(
|
||||
self,
|
||||
image_name: str,
|
||||
changes: ImageRecordChanges,
|
||||
) -> ImageDTO:
|
||||
try:
|
||||
self.__invoker.services.image_records.update(image_name, changes)
|
||||
image_dto = self.get_dto(image_name)
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self.__invoker.services.logger.error("Failed to update image record")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem updating image record")
|
||||
raise e
|
||||
|
||||
def get_pil_image(self, image_name: str) -> PILImageType:
|
||||
try:
|
||||
return self.__invoker.services.image_files.get(image_name)
|
||||
except ImageFileNotFoundException:
|
||||
self.__invoker.services.logger.error("Failed to get image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image file")
|
||||
raise e
|
||||
|
||||
def get_record(self, image_name: str) -> ImageRecord:
|
||||
try:
|
||||
return self.__invoker.services.image_records.get(image_name)
|
||||
except ImageRecordNotFoundException:
|
||||
self.__invoker.services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image record")
|
||||
raise e
|
||||
|
||||
def get_dto(self, image_name: str) -> ImageDTO:
|
||||
try:
|
||||
image_record = self.__invoker.services.image_records.get(image_name)
|
||||
|
||||
image_dto = image_record_to_dto(
|
||||
image_record,
|
||||
self.__invoker.services.urls.get_image_url(image_name),
|
||||
self.__invoker.services.urls.get_image_url(image_name, True),
|
||||
self.__invoker.services.board_image_records.get_board_for_image(image_name),
|
||||
)
|
||||
|
||||
return image_dto
|
||||
except ImageRecordNotFoundException:
|
||||
self.__invoker.services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image DTO")
|
||||
raise e
|
||||
|
||||
def get_metadata(self, image_name: str) -> ImageMetadata:
|
||||
try:
|
||||
image_record = self.__invoker.services.image_records.get(image_name)
|
||||
metadata = self.__invoker.services.image_records.get_metadata(image_name)
|
||||
|
||||
if not image_record.session_id:
|
||||
return ImageMetadata(metadata=metadata)
|
||||
|
||||
session_raw = self.__invoker.services.graph_execution_manager.get_raw(image_record.session_id)
|
||||
graph = None
|
||||
|
||||
if session_raw:
|
||||
try:
|
||||
graph = get_metadata_graph_from_raw_session(session_raw)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.warn(f"Failed to parse session graph: {e}")
|
||||
graph = None
|
||||
|
||||
return ImageMetadata(graph=graph, metadata=metadata)
|
||||
except ImageRecordNotFoundException:
|
||||
self.__invoker.services.logger.error("Image record not found")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image DTO")
|
||||
raise e
|
||||
|
||||
def get_path(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
try:
|
||||
return str(self.__invoker.services.image_files.get_path(image_name, thumbnail))
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image path")
|
||||
raise e
|
||||
|
||||
def validate_path(self, path: str) -> bool:
|
||||
try:
|
||||
return self.__invoker.services.image_files.validate_path(path)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem validating image path")
|
||||
raise e
|
||||
|
||||
def get_url(self, image_name: str, thumbnail: bool = False) -> str:
|
||||
try:
|
||||
return self.__invoker.services.urls.get_image_url(image_name, thumbnail)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting image path")
|
||||
raise e
|
||||
|
||||
def get_many(
|
||||
self,
|
||||
offset: int = 0,
|
||||
limit: int = 10,
|
||||
image_origin: Optional[ResourceOrigin] = None,
|
||||
categories: Optional[list[ImageCategory]] = None,
|
||||
is_intermediate: Optional[bool] = None,
|
||||
board_id: Optional[str] = None,
|
||||
) -> OffsetPaginatedResults[ImageDTO]:
|
||||
try:
|
||||
results = self.__invoker.services.image_records.get_many(
|
||||
offset,
|
||||
limit,
|
||||
image_origin,
|
||||
categories,
|
||||
is_intermediate,
|
||||
board_id,
|
||||
)
|
||||
|
||||
image_dtos = list(
|
||||
map(
|
||||
lambda r: image_record_to_dto(
|
||||
r,
|
||||
self.__invoker.services.urls.get_image_url(r.image_name),
|
||||
self.__invoker.services.urls.get_image_url(r.image_name, True),
|
||||
self.__invoker.services.board_image_records.get_board_for_image(r.image_name),
|
||||
),
|
||||
results.items,
|
||||
)
|
||||
)
|
||||
|
||||
return OffsetPaginatedResults[ImageDTO](
|
||||
items=image_dtos,
|
||||
offset=results.offset,
|
||||
limit=results.limit,
|
||||
total=results.total,
|
||||
)
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem getting paginated image DTOs")
|
||||
raise e
|
||||
|
||||
def delete(self, image_name: str):
|
||||
try:
|
||||
self.__invoker.services.image_files.delete(image_name)
|
||||
self.__invoker.services.image_records.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image record")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image file")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem deleting image record and file")
|
||||
raise e
|
||||
|
||||
def delete_images_on_board(self, board_id: str):
|
||||
try:
|
||||
image_names = self.__invoker.services.board_image_records.get_all_board_image_names_for_board(board_id)
|
||||
for image_name in image_names:
|
||||
self.__invoker.services.image_files.delete(image_name)
|
||||
self.__invoker.services.image_records.delete_many(image_names)
|
||||
for image_name in image_names:
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image records")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image files")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem deleting image records and files")
|
||||
raise e
|
||||
|
||||
def delete_intermediates(self) -> int:
|
||||
try:
|
||||
image_names = self.__invoker.services.image_records.delete_intermediates()
|
||||
count = len(image_names)
|
||||
for image_name in image_names:
|
||||
self.__invoker.services.image_files.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
return count
|
||||
except ImageRecordDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image records")
|
||||
raise
|
||||
except ImageFileDeleteException:
|
||||
self.__invoker.services.logger.error("Failed to delete image files")
|
||||
raise
|
||||
except Exception as e:
|
||||
self.__invoker.services.logger.error("Problem deleting image records and files")
|
||||
raise e
|
||||
@ -1,4 +1,6 @@
|
||||
from queue import Queue
|
||||
from collections import OrderedDict
|
||||
from dataclasses import dataclass, field
|
||||
from threading import Lock
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
@ -7,105 +9,123 @@ from invokeai.app.services.invocation_cache.invocation_cache_common import Invoc
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
@dataclass(order=True)
|
||||
class CachedItem:
|
||||
invocation_output: BaseInvocationOutput = field(compare=False)
|
||||
invocation_output_json: str = field(compare=False)
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
__cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
__max_cache_size: int
|
||||
__disabled: bool
|
||||
__hits: int
|
||||
__misses: int
|
||||
__cache_ids: Queue
|
||||
__invoker: Invoker
|
||||
_cache: OrderedDict[Union[int, str], CachedItem]
|
||||
_max_cache_size: int
|
||||
_disabled: bool
|
||||
_hits: int
|
||||
_misses: int
|
||||
_invoker: Invoker
|
||||
_lock: Lock
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self.__cache = dict()
|
||||
self.__max_cache_size = max_cache_size
|
||||
self.__disabled = False
|
||||
self.__hits = 0
|
||||
self.__misses = 0
|
||||
self.__cache_ids = Queue()
|
||||
self._cache = OrderedDict()
|
||||
self._max_cache_size = max_cache_size
|
||||
self._disabled = False
|
||||
self._hits = 0
|
||||
self._misses = 0
|
||||
self._lock = Lock()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
if self.__max_cache_size == 0:
|
||||
self._invoker = invoker
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self.__invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self.__invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self._invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
item = self.__cache.get(key, None)
|
||||
if item is not None:
|
||||
self.__hits += 1
|
||||
return item[0]
|
||||
self.__misses += 1
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled:
|
||||
return None
|
||||
item = self._cache.get(key, None)
|
||||
if item is not None:
|
||||
self._hits += 1
|
||||
self._cache.move_to_end(key)
|
||||
return item.invocation_output
|
||||
self._misses += 1
|
||||
return None
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0 or self._disabled or key in self._cache:
|
||||
return
|
||||
# If the cache is full, we need to remove the least used
|
||||
number_to_delete = len(self._cache) + 1 - self._max_cache_size
|
||||
self._delete_oldest_access(number_to_delete)
|
||||
self._cache[key] = CachedItem(
|
||||
invocation_output,
|
||||
invocation_output.model_dump_json(
|
||||
warnings=False, exclude_defaults=True, exclude_unset=True, include={"type"}
|
||||
),
|
||||
)
|
||||
|
||||
if key not in self.__cache:
|
||||
self.__cache[key] = (invocation_output, invocation_output.json())
|
||||
self.__cache_ids.put(key)
|
||||
if self.__cache_ids.qsize() > self.__max_cache_size:
|
||||
try:
|
||||
self.__cache.pop(self.__cache_ids.get())
|
||||
except KeyError:
|
||||
# this means the cache_ids are somehow out of sync w/ the cache
|
||||
pass
|
||||
def _delete_oldest_access(self, number_to_delete: int) -> None:
|
||||
number_to_delete = min(number_to_delete, len(self._cache))
|
||||
for _ in range(number_to_delete):
|
||||
self._cache.popitem(last=False)
|
||||
|
||||
def _delete(self, key: Union[int, str]) -> None:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
if key in self._cache:
|
||||
del self._cache[key]
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
if key in self.__cache:
|
||||
del self.__cache[key]
|
||||
with self._lock:
|
||||
return self._delete(key)
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._cache.clear()
|
||||
self._misses = 0
|
||||
self._hits = 0
|
||||
|
||||
self.__cache.clear()
|
||||
self.__cache_ids = Queue()
|
||||
self.__misses = 0
|
||||
self.__hits = 0
|
||||
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
@staticmethod
|
||||
def create_key(invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.model_dump_json(exclude={"id"}, warnings=False))
|
||||
|
||||
def disable(self) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
self.__disabled = True
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
self.__disabled = False
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
self._disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
return InvocationCacheStatus(
|
||||
hits=self.__hits,
|
||||
misses=self.__misses,
|
||||
enabled=not self.__disabled and self.__max_cache_size > 0,
|
||||
size=len(self.__cache),
|
||||
max_size=self.__max_cache_size,
|
||||
)
|
||||
with self._lock:
|
||||
return InvocationCacheStatus(
|
||||
hits=self._hits,
|
||||
misses=self._misses,
|
||||
enabled=not self._disabled and self._max_cache_size > 0,
|
||||
size=len(self._cache),
|
||||
max_size=self._max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
keys_to_delete = set()
|
||||
for key, value_tuple in self.__cache.items():
|
||||
if to_match in value_tuple[1]:
|
||||
keys_to_delete.add(key)
|
||||
|
||||
if not keys_to_delete:
|
||||
return
|
||||
|
||||
for key in keys_to_delete:
|
||||
self.delete(key)
|
||||
|
||||
self.__invoker.services.logger.debug(f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}")
|
||||
with self._lock:
|
||||
if self._max_cache_size == 0:
|
||||
return
|
||||
keys_to_delete = set()
|
||||
for key, cached_item in self._cache.items():
|
||||
if to_match in cached_item.invocation_output_json:
|
||||
keys_to_delete.add(key)
|
||||
if not keys_to_delete:
|
||||
return
|
||||
for key in keys_to_delete:
|
||||
self._delete(key)
|
||||
self._invoker.services.logger.debug(
|
||||
f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}"
|
||||
)
|
||||
|
||||
@ -0,0 +1,5 @@
|
||||
from abc import ABC
|
||||
|
||||
|
||||
class InvocationProcessorABC(ABC):
|
||||
pass
|
||||
@ -0,0 +1,15 @@
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class ProgressImage(BaseModel):
|
||||
"""The progress image sent intermittently during processing"""
|
||||
|
||||
width: int = Field(description="The effective width of the image in pixels")
|
||||
height: int = Field(description="The effective height of the image in pixels")
|
||||
dataURL: str = Field(description="The image data as a b64 data URL")
|
||||
|
||||
|
||||
class CanceledException(Exception):
|
||||
"""Execution canceled by user."""
|
||||
|
||||
pass
|
||||
@ -4,12 +4,12 @@ from threading import BoundedSemaphore, Event, Thread
|
||||
from typing import Optional
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.app.invocations.baseinvocation import AppInvocationContext
|
||||
from invokeai.app.services.invocation_queue.invocation_queue_common import InvocationQueueItem
|
||||
|
||||
from ..invocations.baseinvocation import InvocationContext
|
||||
from ..models.exceptions import CanceledException
|
||||
from .invocation_queue import InvocationQueueItem
|
||||
from .invocation_stats import InvocationStatsServiceBase
|
||||
from .invoker import InvocationProcessorABC, Invoker
|
||||
from ..invoker import Invoker
|
||||
from .invocation_processor_base import InvocationProcessorABC
|
||||
from .invocation_processor_common import CanceledException
|
||||
|
||||
|
||||
class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
@ -37,7 +37,6 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
def __process(self, stop_event: Event):
|
||||
try:
|
||||
self.__threadLimit.acquire()
|
||||
statistics: InvocationStatsServiceBase = self.__invoker.services.performance_statistics
|
||||
queue_item: Optional[InvocationQueueItem] = None
|
||||
|
||||
while not stop_event.is_set():
|
||||
@ -90,26 +89,28 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
|
||||
# Invoke
|
||||
try:
|
||||
graph_id = graph_execution_state.id
|
||||
model_manager = self.__invoker.services.model_manager
|
||||
with statistics.collect_stats(invocation, graph_id, model_manager):
|
||||
source_node_id = graph_execution_state.prepared_source_mapping[invocation.id]
|
||||
|
||||
with self.__invoker.services.performance_statistics.collect_stats(invocation, graph_id):
|
||||
# use the internal invoke_internal(), which wraps the node's invoke() method,
|
||||
# which handles a few things:
|
||||
# - nodes that require a value, but get it only from a connection
|
||||
# - referencing the invocation cache instead of executing the node
|
||||
outputs = invocation.invoke_internal(
|
||||
InvocationContext(
|
||||
AppInvocationContext(
|
||||
services=self.__invoker.services,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
queue_batch_id=queue_item.session_queue_batch_id,
|
||||
source_node_id=source_node_id,
|
||||
)
|
||||
)
|
||||
|
||||
@ -129,17 +130,17 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
result=outputs.dict(),
|
||||
result=outputs.model_dump(),
|
||||
)
|
||||
statistics.log_stats()
|
||||
self.__invoker.services.performance_statistics.log_stats()
|
||||
|
||||
except KeyboardInterrupt:
|
||||
pass
|
||||
|
||||
except CanceledException:
|
||||
statistics.reset_stats(graph_execution_state.id)
|
||||
self.__invoker.services.performance_statistics.reset_stats(graph_execution_state.id)
|
||||
pass
|
||||
|
||||
except Exception as e:
|
||||
@ -159,12 +160,12 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
error_type=e.__class__.__name__,
|
||||
error=error,
|
||||
)
|
||||
statistics.reset_stats(graph_execution_state.id)
|
||||
self.__invoker.services.performance_statistics.reset_stats(graph_execution_state.id)
|
||||
pass
|
||||
|
||||
# Check queue to see if this is canceled, and skip if so
|
||||
@ -189,7 +190,7 @@ class DefaultInvocationProcessor(InvocationProcessorABC):
|
||||
queue_item_id=queue_item.session_queue_item_id,
|
||||
queue_id=queue_item.session_queue_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
node=invocation.dict(),
|
||||
node=invocation.model_dump(),
|
||||
source_node_id=source_node_id,
|
||||
error_type=e.__class__.__name__,
|
||||
error=traceback.format_exc(),
|
||||
0
invokeai/app/services/invocation_queue/__init__.py
Normal file
0
invokeai/app/services/invocation_queue/__init__.py
Normal file
@ -0,0 +1,26 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional
|
||||
|
||||
from .invocation_queue_common import InvocationQueueItem
|
||||
|
||||
|
||||
class InvocationQueueABC(ABC):
|
||||
"""Abstract base class for all invocation queues"""
|
||||
|
||||
@abstractmethod
|
||||
def get(self) -> InvocationQueueItem:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def put(self, item: Optional[InvocationQueueItem]) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel(self, graph_execution_state_id: str) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def is_canceled(self, graph_execution_state_id: str) -> bool:
|
||||
pass
|
||||
@ -0,0 +1,19 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
import time
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationQueueItem(BaseModel):
|
||||
graph_execution_state_id: str = Field(description="The ID of the graph execution state")
|
||||
invocation_id: str = Field(description="The ID of the node being invoked")
|
||||
session_queue_id: str = Field(description="The ID of the session queue from which this invocation queue item came")
|
||||
session_queue_item_id: int = Field(
|
||||
description="The ID of session queue item from which this invocation queue item came"
|
||||
)
|
||||
session_queue_batch_id: str = Field(
|
||||
description="The ID of the session batch from which this invocation queue item came"
|
||||
)
|
||||
invoke_all: bool = Field(default=False)
|
||||
timestamp: float = Field(default_factory=time.time)
|
||||
@ -1,45 +1,11 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
from queue import Queue
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationQueueItem(BaseModel):
|
||||
graph_execution_state_id: str = Field(description="The ID of the graph execution state")
|
||||
invocation_id: str = Field(description="The ID of the node being invoked")
|
||||
session_queue_id: str = Field(description="The ID of the session queue from which this invocation queue item came")
|
||||
session_queue_item_id: int = Field(
|
||||
description="The ID of session queue item from which this invocation queue item came"
|
||||
)
|
||||
session_queue_batch_id: str = Field(
|
||||
description="The ID of the session batch from which this invocation queue item came"
|
||||
)
|
||||
invoke_all: bool = Field(default=False)
|
||||
timestamp: float = Field(default_factory=time.time)
|
||||
|
||||
|
||||
class InvocationQueueABC(ABC):
|
||||
"""Abstract base class for all invocation queues"""
|
||||
|
||||
@abstractmethod
|
||||
def get(self) -> InvocationQueueItem:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def put(self, item: Optional[InvocationQueueItem]) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def cancel(self, graph_execution_state_id: str) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def is_canceled(self, graph_execution_state_id: str) -> bool:
|
||||
pass
|
||||
from .invocation_queue_base import InvocationQueueABC
|
||||
from .invocation_queue_common import InvocationQueueItem
|
||||
|
||||
|
||||
class MemoryInvocationQueue(InvocationQueueABC):
|
||||
@ -6,21 +6,27 @@ from typing import TYPE_CHECKING
|
||||
if TYPE_CHECKING:
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.board_images import BoardImagesServiceABC
|
||||
from invokeai.app.services.boards import BoardServiceABC
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.events import EventServiceBase
|
||||
from invokeai.app.services.graph import GraphExecutionState, LibraryGraph
|
||||
from invokeai.app.services.images import ImageServiceABC
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_queue import InvocationQueueABC
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsServiceBase
|
||||
from invokeai.app.services.invoker import InvocationProcessorABC
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.latent_storage import LatentsStorageBase
|
||||
from invokeai.app.services.model_manager_service import ModelManagerServiceBase
|
||||
from invokeai.app.services.session_processor.session_processor_base import SessionProcessorBase
|
||||
from invokeai.app.services.session_queue.session_queue_base import SessionQueueBase
|
||||
from .board_image_records.board_image_records_base import BoardImageRecordStorageBase
|
||||
from .board_images.board_images_base import BoardImagesServiceABC
|
||||
from .board_records.board_records_base import BoardRecordStorageBase
|
||||
from .boards.boards_base import BoardServiceABC
|
||||
from .config import InvokeAIAppConfig
|
||||
from .events.events_base import EventServiceBase
|
||||
from .image_files.image_files_base import ImageFileStorageBase
|
||||
from .image_records.image_records_base import ImageRecordStorageBase
|
||||
from .images.images_base import ImageServiceABC
|
||||
from .invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from .invocation_processor.invocation_processor_base import InvocationProcessorABC
|
||||
from .invocation_queue.invocation_queue_base import InvocationQueueABC
|
||||
from .invocation_stats.invocation_stats_base import InvocationStatsServiceBase
|
||||
from .item_storage.item_storage_base import ItemStorageABC
|
||||
from .latents_storage.latents_storage_base import LatentsStorageBase
|
||||
from .model_manager.model_manager_base import ModelManagerServiceBase
|
||||
from .names.names_base import NameServiceBase
|
||||
from .session_processor.session_processor_base import SessionProcessorBase
|
||||
from .session_queue.session_queue_base import SessionQueueBase
|
||||
from .shared.graph import GraphExecutionState, LibraryGraph
|
||||
from .urls.urls_base import UrlServiceBase
|
||||
|
||||
|
||||
class InvocationServices:
|
||||
@ -28,12 +34,16 @@ class InvocationServices:
|
||||
|
||||
# TODO: Just forward-declared everything due to circular dependencies. Fix structure.
|
||||
board_images: "BoardImagesServiceABC"
|
||||
board_image_record_storage: "BoardImageRecordStorageBase"
|
||||
boards: "BoardServiceABC"
|
||||
board_records: "BoardRecordStorageBase"
|
||||
configuration: "InvokeAIAppConfig"
|
||||
events: "EventServiceBase"
|
||||
graph_execution_manager: "ItemStorageABC[GraphExecutionState]"
|
||||
graph_library: "ItemStorageABC[LibraryGraph]"
|
||||
images: "ImageServiceABC"
|
||||
image_records: "ImageRecordStorageBase"
|
||||
image_files: "ImageFileStorageBase"
|
||||
latents: "LatentsStorageBase"
|
||||
logger: "Logger"
|
||||
model_manager: "ModelManagerServiceBase"
|
||||
@ -43,16 +53,22 @@ class InvocationServices:
|
||||
session_queue: "SessionQueueBase"
|
||||
session_processor: "SessionProcessorBase"
|
||||
invocation_cache: "InvocationCacheBase"
|
||||
names: "NameServiceBase"
|
||||
urls: "UrlServiceBase"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
board_images: "BoardImagesServiceABC",
|
||||
board_image_records: "BoardImageRecordStorageBase",
|
||||
boards: "BoardServiceABC",
|
||||
board_records: "BoardRecordStorageBase",
|
||||
configuration: "InvokeAIAppConfig",
|
||||
events: "EventServiceBase",
|
||||
graph_execution_manager: "ItemStorageABC[GraphExecutionState]",
|
||||
graph_library: "ItemStorageABC[LibraryGraph]",
|
||||
images: "ImageServiceABC",
|
||||
image_files: "ImageFileStorageBase",
|
||||
image_records: "ImageRecordStorageBase",
|
||||
latents: "LatentsStorageBase",
|
||||
logger: "Logger",
|
||||
model_manager: "ModelManagerServiceBase",
|
||||
@ -62,14 +78,20 @@ class InvocationServices:
|
||||
session_queue: "SessionQueueBase",
|
||||
session_processor: "SessionProcessorBase",
|
||||
invocation_cache: "InvocationCacheBase",
|
||||
names: "NameServiceBase",
|
||||
urls: "UrlServiceBase",
|
||||
):
|
||||
self.board_images = board_images
|
||||
self.board_image_records = board_image_records
|
||||
self.boards = boards
|
||||
self.board_records = board_records
|
||||
self.configuration = configuration
|
||||
self.events = events
|
||||
self.graph_execution_manager = graph_execution_manager
|
||||
self.graph_library = graph_library
|
||||
self.images = images
|
||||
self.image_files = image_files
|
||||
self.image_records = image_records
|
||||
self.latents = latents
|
||||
self.logger = logger
|
||||
self.model_manager = model_manager
|
||||
@ -79,3 +101,5 @@ class InvocationServices:
|
||||
self.session_queue = session_queue
|
||||
self.session_processor = session_processor
|
||||
self.invocation_cache = invocation_cache
|
||||
self.names = names
|
||||
self.urls = urls
|
||||
|
||||
0
invokeai/app/services/invocation_stats/__init__.py
Normal file
0
invokeai/app/services/invocation_stats/__init__.py
Normal file
121
invokeai/app/services/invocation_stats/invocation_stats_base.py
Normal file
121
invokeai/app/services/invocation_stats/invocation_stats_base.py
Normal file
@ -0,0 +1,121 @@
|
||||
# Copyright 2023 Lincoln D. Stein <lincoln.stein@gmail.com>
|
||||
"""Utility to collect execution time and GPU usage stats on invocations in flight
|
||||
|
||||
Usage:
|
||||
|
||||
statistics = InvocationStatsService(graph_execution_manager)
|
||||
with statistics.collect_stats(invocation, graph_execution_state.id):
|
||||
... execute graphs...
|
||||
statistics.log_stats()
|
||||
|
||||
Typical output:
|
||||
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> Graph stats: c7764585-9c68-4d9d-a199-55e8186790f3
|
||||
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> Node Calls Seconds VRAM Used
|
||||
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> main_model_loader 1 0.005s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> clip_skip 1 0.004s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> compel 2 0.512s 0.26G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> rand_int 1 0.001s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> range_of_size 1 0.001s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> iterate 1 0.001s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> metadata_accumulator 1 0.002s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> noise 1 0.002s 0.01G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> t2l 1 3.541s 1.93G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> l2i 1 0.679s 0.58G
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> TOTAL GRAPH EXECUTION TIME: 4.749s
|
||||
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> Current VRAM utilization 0.01G
|
||||
|
||||
The abstract base class for this class is InvocationStatsServiceBase. An implementing class which
|
||||
writes to the system log is stored in InvocationServices.performance_statistics.
|
||||
"""
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from contextlib import AbstractContextManager
|
||||
from typing import Dict
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation
|
||||
from invokeai.backend.model_management.model_cache import CacheStats
|
||||
|
||||
from .invocation_stats_common import NodeLog
|
||||
|
||||
|
||||
class InvocationStatsServiceBase(ABC):
|
||||
"Abstract base class for recording node memory/time performance statistics"
|
||||
|
||||
# {graph_id => NodeLog}
|
||||
_stats: Dict[str, NodeLog]
|
||||
_cache_stats: Dict[str, CacheStats]
|
||||
ram_used: float
|
||||
ram_changed: float
|
||||
|
||||
@abstractmethod
|
||||
def __init__(self):
|
||||
"""
|
||||
Initialize the InvocationStatsService and reset counters to zero
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def collect_stats(
|
||||
self,
|
||||
invocation: BaseInvocation,
|
||||
graph_execution_state_id: str,
|
||||
) -> AbstractContextManager:
|
||||
"""
|
||||
Return a context object that will capture the statistics on the execution
|
||||
of invocaation. Use with: to place around the part of the code that executes the invocation.
|
||||
:param invocation: BaseInvocation object from the current graph.
|
||||
:param graph_execution_state_id: The id of the current session.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def reset_stats(self, graph_execution_state_id: str):
|
||||
"""
|
||||
Reset all statistics for the indicated graph
|
||||
:param graph_execution_state_id
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def reset_all_stats(self):
|
||||
"""Zero all statistics"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update_invocation_stats(
|
||||
self,
|
||||
graph_id: str,
|
||||
invocation_type: str,
|
||||
time_used: float,
|
||||
vram_used: float,
|
||||
):
|
||||
"""
|
||||
Add timing information on execution of a node. Usually
|
||||
used internally.
|
||||
:param graph_id: ID of the graph that is currently executing
|
||||
:param invocation_type: String literal type of the node
|
||||
:param time_used: Time used by node's exection (sec)
|
||||
:param vram_used: Maximum VRAM used during exection (GB)
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def log_stats(self):
|
||||
"""
|
||||
Write out the accumulated statistics to the log or somewhere else.
|
||||
"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def update_mem_stats(
|
||||
self,
|
||||
ram_used: float,
|
||||
ram_changed: float,
|
||||
):
|
||||
"""
|
||||
Update the collector with RAM memory usage info.
|
||||
|
||||
:param ram_used: How much RAM is currently in use.
|
||||
:param ram_changed: How much RAM changed since last generation.
|
||||
"""
|
||||
pass
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user