Compare commits
619 Commits
feat/dynam
...
feat/nodes
| Author | SHA1 | Date | |
|---|---|---|---|
| 8918501869 | |||
| b152fbf72f | |||
| f95111772a | |||
| 14ce7cf09c | |||
| 28a1a6939f | |||
| 6d2b4013f8 | |||
| ca7a7b57bb | |||
| c5d0e65a24 | |||
| 6cc7b55ec5 | |||
| 883e9973ec | |||
| 9e7d829906 | |||
| 456a0a59e0 | |||
| 4f2bf7e7e8 | |||
| 77e93888cf | |||
| fa54974bff | |||
| 7ac99d6bc3 | |||
| aa82f9360c | |||
| 5aefa49d7d | |||
| b6e9cd4fe2 | |||
| 6d1057c560 | |||
| b4790002c7 | |||
| e02700a782 | |||
| 83ce8ef1ec | |||
| 19e487b5ee | |||
| aa4b56baf2 | |||
| d3a2be69f1 | |||
| 02c087ee37 | |||
| cab8d9bb20 | |||
| 28e6a7139b | |||
| 1625854eaf | |||
| f87b042162 | |||
| 183e2c3ee0 | |||
| 098d506b95 | |||
| 7aa33c352b | |||
| bf62553150 | |||
| 2b08d9e53b | |||
| 8954953eca | |||
| eb2fcbe28a | |||
| e78b36a9f7 | |||
| 144ede031e | |||
| 8ca37bba33 | |||
| a608340c89 | |||
| 7fecebf7db | |||
| b915d74127 | |||
| 6ec347bd41 | |||
| e54843acc9 | |||
| 0960518088 | |||
| 21de74fac4 | |||
| 8ce9b6c51e | |||
| b64ade586d | |||
| 3c44a74ba5 | |||
| 24d0901d8e | |||
| b1b5f70ea6 | |||
| 6392098961 | |||
| 2c39aec22d | |||
| d066bc6d19 | |||
| e487bcd0f7 | |||
| e0f8274f49 | |||
| 69e3513e90 | |||
| 7e706f02cb | |||
| 41dad2013a | |||
| 3f554d6824 | |||
| 202c5a48c6 | |||
| 2d71f6f4b8 | |||
| 0420874f56 | |||
| f222b871e9 | |||
| 8b8d589033 | |||
| f4c895257a | |||
| 10af5a26f2 | |||
| 1088adeb0a | |||
| ad49380cd1 | |||
| b2fe24c401 | |||
| b128db1d58 | |||
| f7f0630d97 | |||
| 5075e9c899 | |||
| 3c1549cf5c | |||
| 9faa53ceb1 | |||
| 32672cfeda | |||
| b5266f89ad | |||
| 7a3b467ce0 | |||
| bdfdf854fc | |||
| 1c38cce16d | |||
| 4cdca45228 | |||
| bfed08673a | |||
| c1aa2b82eb | |||
| 0a09f84b07 | |||
| b7938d9ca9 | |||
| 977e348a35 | |||
| 864f2270c3 | |||
| 8b44d83859 | |||
| 0b6315de71 | |||
| 578e682562 | |||
| 92b49e45bb | |||
| b05b8ef677 | |||
| 382e2139bd | |||
| d7ebe3f048 | |||
| 5c2bdf626b | |||
| 390a1c9fbb | |||
| c46d9b8768 | |||
| ef8d9843dd | |||
| dc2e1a42bc | |||
| 1869874433 | |||
| 94f16b1c69 | |||
| cc0482ae8b | |||
| fdf9833c39 | |||
| 5a961bb58e | |||
| 627750eded | |||
| 2a3909da94 | |||
| e0dddbd38e | |||
| 231b7a5000 | |||
| b7773c9962 | |||
| 11c501fc80 | |||
| 7be5743011 | |||
| c48e648cbb | |||
| 29b4ddcc7f | |||
| 7ee13879e3 | |||
| ced297ed21 | |||
| 3e813ead1f | |||
| 820ec08e9a | |||
| 4dd289b337 | |||
| b60b1e359e | |||
| 208286e97a | |||
| f7b64304ae | |||
| 834751e877 | |||
| d94d4ef83f | |||
| e7a10d310f | |||
| 682d6998bc | |||
| 2ce07a4730 | |||
| dc9074f65d | |||
| 45d5ab20ec | |||
| b75c56768d | |||
| 343df03a92 | |||
| b57acb7353 | |||
| 7bf7c16a5d | |||
| 56340c24c8 | |||
| afe9756667 | |||
| ff3150a818 | |||
| fcea65770f | |||
| 273271f091 | |||
| 54dc912c83 | |||
| 571f50adf7 | |||
| 368bd6f778 | |||
| 7481251127 | |||
| 16664da5b6 | |||
| c104807201 | |||
| 990ce9a1da | |||
| 604fc006b1 | |||
| 5a42774fbe | |||
| 704e016f05 | |||
| a1ef079d1f | |||
| 34a09cb4ca | |||
| 18095ecc44 | |||
| fe19f11abf | |||
| c2f074dc2f | |||
| e02a557454 | |||
| fca60862e2 | |||
| 94c186bb4c | |||
| a22c8cb3a1 | |||
| 781e8521d5 | |||
| d114d0ba95 | |||
| cc8b7a74da | |||
| 388554448a | |||
| cadc0839a6 | |||
| d5160648d0 | |||
| 6d0ea42a94 | |||
| 0f93991087 | |||
| 2c1100509f | |||
| ad5f61e3b5 | |||
| f6738d647e | |||
| c34b359c36 | |||
| 77d135967f | |||
| ebf26687cb | |||
| 2f5e923008 | |||
| b7296000e4 | |||
| fab055995e | |||
| 1c8991a3df | |||
| 3d52656176 | |||
| d989c7fa34 | |||
| a2777decd4 | |||
| d219167849 | |||
| 090db1ab3a | |||
| 468253aa14 | |||
| 3ee9a21647 | |||
| 0d823901ef | |||
| 7ee55489bb | |||
| 163ece9aee | |||
| 3920d5c90d | |||
| 0f0366f1f3 | |||
| 4e05dcfe2e | |||
| 8c63173b0c | |||
| 30792cb259 | |||
| a88f16b81c | |||
| fb188ce63e | |||
| 57ebf735e6 | |||
| ec0f6e7248 | |||
| 93c55ebcf2 | |||
| 41f2eaa4de | |||
| 244201b45d | |||
| 486b8506aa | |||
| 79ca181276 | |||
| dbde08f3d4 | |||
| e542608534 | |||
| 99ee47b79b | |||
| 005087a652 | |||
| e9f5814c6d | |||
| c68b55f8e6 | |||
| a21f5f259c | |||
| 7b2e6deaf1 | |||
| 63f94579c5 | |||
| e467ca7f1b | |||
| 0450c28f14 | |||
| e88d7c242f | |||
| caea6d11c6 | |||
| 5615c31799 | |||
| 4390a051ca | |||
| fafa21569a | |||
| 77a4fabc66 | |||
| 5cbdcdaa1f | |||
| 044b6ac07a | |||
| 774ade679d | |||
| bf6c5cbe77 | |||
| 7dd20090c2 | |||
| 7c3fb3c54a | |||
| 2c8521b25d | |||
| 179a3aaa71 | |||
| 49423a791d | |||
| 666b5d7a60 | |||
| 2a0dbe3b5b | |||
| eb48718459 | |||
| d4143136d0 | |||
| f6ced9f54b | |||
| c82ea5a812 | |||
| 17891ae703 | |||
| e94dc47d56 | |||
| 3dfff278aa | |||
| aa7d945b23 | |||
| e060fef540 | |||
| 88db094cf2 | |||
| 183f66c70c | |||
| abc50ce88b | |||
| 50a0691514 | |||
| a255624984 | |||
| 2630fe3608 | |||
| dee6f86d5e | |||
| 6ca6cf713c | |||
| 3f7d5b4e0f | |||
| 91596d9527 | |||
| d0a7832326 | |||
| 75bc43b2a5 | |||
| 4395ee3c03 | |||
| 1d2636aa90 | |||
| 24d9357fdc | |||
| 74cc409c72 | |||
| cc92ce3da5 | |||
| 7254a6a517 | |||
| dc771d9645 | |||
| d669f0855d | |||
| b2d5b53b5f | |||
| ddc148b70b | |||
| 47ea71d9bd | |||
| dccf291f64 | |||
| d3a94e5853 | |||
| 0166d7ba2b | |||
| b700809e14 | |||
| 501cb4c1e2 | |||
| 56399a650a | |||
| e4035a51af | |||
| cf83ddea15 | |||
| c2d43f007b | |||
| a79d5901c7 | |||
| 7703bf2ca1 | |||
| a98c37b7a3 | |||
| 252adb9e70 | |||
| 40a0b2c366 | |||
| cfc4caf231 | |||
| 23fdf0156f | |||
| cdbf40c9b2 | |||
| 46c9dcb113 | |||
| 6df79045fa | |||
| d776e0a0a9 | |||
| e16598c48a | |||
| 6506ce3e68 | |||
| 3afa73cd33 | |||
| 81ea742aea | |||
| 15d28bfdbf | |||
| 0e5eac7c21 | |||
| 0a1c5bea05 | |||
| 9c290f4575 | |||
| 500f3046a9 | |||
| 53f2369d18 | |||
| 357912285a | |||
| 0f2b8dd7df | |||
| ba2ce72584 | |||
| c54c1f603b | |||
| 9caa2a2043 | |||
| 86185f2fe3 | |||
| dfbcb773da | |||
| 04c0a83bff | |||
| 7a30162583 | |||
| 2c65ffa305 | |||
| 331a6227cc | |||
| eb90ea41fd | |||
| 94ec3da7b5 | |||
| f44496a579 | |||
| f134804fe7 | |||
| c59c3ae499 | |||
| 42ee95ee97 | |||
| b008fd4a5f | |||
| 6b850d506a | |||
| 99fe95ab03 | |||
| 3f3e0ab9f5 | |||
| 8b305651f9 | |||
| 95ecb1a0c1 | |||
| bd15874cf6 | |||
| 52bd2bbb13 | |||
| a9fafad5b5 | |||
| c5b9c8fc3a | |||
| fb5ac78191 | |||
| 871b9286d1 | |||
| c49b436f06 | |||
| d2e327add9 | |||
| 2ab75bc52e | |||
| 30ab81b6bb | |||
| 384ad2df6a | |||
| 78195491bc | |||
| 94115b5217 | |||
| 10eec546ad | |||
| c63390f6e1 | |||
| ac3bf81ca4 | |||
| cbd451c610 | |||
| b0f91f2e75 | |||
| 3ac68cde66 | |||
| a69b1cd598 | |||
| 65a76a086b | |||
| 07381e5a26 | |||
| 6bb378a101 | |||
| edd64bd537 | |||
| 8795ea8b06 | |||
| b1ef3370fa | |||
| db4af7c287 | |||
| 78cc5a7825 | |||
| 438bc70dfd | |||
| 1f6c868212 | |||
| 52d15e06bf | |||
| 3dbb0e1bfb | |||
| d6317bc53f | |||
| 4aca264308 | |||
| d9148fb619 | |||
| 59cb6305b9 | |||
| 945b9e3a0a | |||
| 920fc0e751 | |||
| 34e3c2e000 | |||
| d65553841e | |||
| 446dc6bea1 | |||
| 92975130bd | |||
| a765f01c08 | |||
| 09803b075d | |||
| 1062fc4796 | |||
| 17170e9dab | |||
| d69f3a03bb | |||
| 95f44ff343 | |||
| f9c3c07d98 | |||
| c91ba2dbe7 | |||
| 917c2c480e | |||
| fee5cd9c7e | |||
| b0cce8008a | |||
| 368c2bf08b | |||
| 0a70a856e5 | |||
| 56204e84bc | |||
| f1a01c473d | |||
| e27819f18f | |||
| f1f7778e73 | |||
| 7763594839 | |||
| c965d3eb6b | |||
| 85879d3013 | |||
| 4fa66b2ba8 | |||
| 6cfabc585a | |||
| b5f42bedce | |||
| fded8bee39 | |||
| ec09e21fc2 | |||
| 7d50e413bc | |||
| 7df67d077a | |||
| 625b08cff7 | |||
| 89b724d222 | |||
| 6f6d920686 | |||
| 699dfa222e | |||
| 288aec7080 | |||
| 2c754cfce7 | |||
| 8fa2302956 | |||
| ec2b44bfbd | |||
| f8bb1f7a3e | |||
| 9c3405e0c0 | |||
| 4b78deba92 | |||
| d099924ae9 | |||
| b761807219 | |||
| 45259894e0 | |||
| 94473c541d | |||
| 0a7d06f8c6 | |||
| 3288d9b31a | |||
| 9cb04f6f80 | |||
| 7269ed2a0a | |||
| 4092d051e8 | |||
| 46bc6968b8 | |||
| 48484e9fc8 | |||
| 26f7adeaa3 | |||
| a12fbc7406 | |||
| ba2048dbc6 | |||
| 497f66e682 | |||
| b73216ef81 | |||
| 469fc49a2f | |||
| a36cf2f1dd | |||
| 5151798a16 | |||
| 1a9f552a75 | |||
| fb1b03960e | |||
| 74bfb5e1f9 | |||
| 10e4d8b72d | |||
| 6c2786201b | |||
| bc1bce18b0 | |||
| 2cb57ef301 | |||
| 44b49c7f2d | |||
| 52a5f1f56f | |||
| 7a295cbfd5 | |||
| 6f162c5dec | |||
| b94ec14853 | |||
| 54cda8ea42 | |||
| 0d3d880323 | |||
| a74e2108bb | |||
| ca5689dc54 | |||
| b567d65032 | |||
| 35ac8e78bd | |||
| e90fd96eee | |||
| ed72d51969 | |||
| 942ecbbde4 | |||
| 79db0e9e93 | |||
| d5267357b1 | |||
| e085eb63bd | |||
| 8e470f9b6f | |||
| 0c17f8604f | |||
| 054edc4077 | |||
| 5a9993772d | |||
| f2cd9e9ae2 | |||
| 9f86cfa471 | |||
| 8c1390166f | |||
| 1ad98ce999 | |||
| 83163ddd9a | |||
| 715686477e | |||
| 05e203570d | |||
| 2bd3cf28ea | |||
| 3cd2d3b764 | |||
| 4bac36356a | |||
| 97763f778a | |||
| 754666ed09 | |||
| 4c407328f2 | |||
| 943bedadf2 | |||
| 667d4deeb7 | |||
| adfdb02c1b | |||
| 24d44ca559 | |||
| 216dff143e | |||
| 4047343503 | |||
| f2334ec302 | |||
| 044d4c107a | |||
| ae05d34584 | |||
| 94d0c18cbd | |||
| 7b49f96472 | |||
| 9a2c0554de | |||
| 68fd07a606 | |||
| 71591d0bee | |||
| 8014fc2f4f | |||
| 29112f96d2 | |||
| 4405c39e48 | |||
| 1d6be7f7fd | |||
| 64723f0628 | |||
| 8982543312 | |||
| d8ce20c06f | |||
| 0ed6a141f1 | |||
| 33cb6cb4d8 | |||
| 600e9ecf8d | |||
| ca15b8b33e | |||
| 8562dbaaa8 | |||
| db4d35ed45 | |||
| 65fb6af01f | |||
| c6bab14043 | |||
| 55f19aff3a | |||
| 1b6586dd8c | |||
| b5da7faafb | |||
| b13a06f650 | |||
| 8e4d288f02 | |||
| 8d4caaabb0 | |||
| 171a0eaf51 | |||
| 2469859c01 | |||
| cff391aa1d | |||
| 4fd4aee2ab | |||
| 5f4a62810e | |||
| 35b7ae90ae | |||
| 9ed4d487d2 | |||
| 69d37217b8 | |||
| 7afdefb0e5 | |||
| f5c5f59220 | |||
| 9afc909ff0 | |||
| 176d41d624 | |||
| 9eed8cdc27 | |||
| 98e905ee48 | |||
| 52c2397498 | |||
| 9f9807d7f7 | |||
| 11fa87388b | |||
| 258b0814a8 | |||
| dd2057322c | |||
| 41c5963e41 | |||
| ed1456e0cc | |||
| 15a927b517 | |||
| 121396f844 | |||
| d251124196 | |||
| 243e76dd80 | |||
| cfee8d9804 | |||
| 68dc3c6cb4 | |||
| 4196c669a0 | |||
| a1398dec91 | |||
| c4bec0e81b | |||
| a03233bd8a | |||
| 6fdeeb8ce8 | |||
| 9993e4b02e | |||
| e6b677873a | |||
| 44e77589b7 | |||
| d0c74822eb | |||
| 383d008529 | |||
| 59511783fc | |||
| 605e13eac0 | |||
| 2a1d7342a7 | |||
| d1efabaf2f | |||
| 577464091c | |||
| aaae471910 | |||
| 56ed76fd95 | |||
| 5133825efb | |||
| 99475ab800 | |||
| 50a266e064 | |||
| 87bb4d8f6e | |||
| fcb60a7a59 | |||
| b5dac99411 | |||
| a08d22587b | |||
| 0ea67050f1 | |||
| 6db19a8dee | |||
| ef58635a76 | |||
| 594e547c3b | |||
| 2bf747caf6 | |||
| cd548f73fd | |||
| bb085c5fba | |||
| 3efb1f6f17 | |||
| 1ed0d7bf3c | |||
| a5fe6c8af6 | |||
| 3c37245804 | |||
| e60af40c8d | |||
| 421f5b7d75 | |||
| 3ef36707a8 | |||
| 00ca9b027a | |||
| e81e17ccb6 | |||
| b9731cb434 | |||
| 502570e083 | |||
| 1f476692da | |||
| 5fdd25501b | |||
| 4f00dbe704 | |||
| b65c9ad612 | |||
| ef3bf2803f | |||
| f87b2364b7 | |||
| 3e6c49001c | |||
| 19e0f360e7 | |||
| ea40a7844a | |||
| 0d2e194213 | |||
| c6d00387a7 | |||
| 3de45af734 | |||
| 526c7e7737 | |||
| 1811b54727 | |||
| 95883c2efd | |||
| b5a83bbc8a | |||
| 38851ae19a | |||
| 71c3955530 | |||
| 3f8d17d6b7 | |||
| b18695df6f | |||
| 249048aae7 | |||
| 521da555d6 | |||
| c923d094c6 | |||
| 226721ce51 | |||
| af3e316cee | |||
| 382a55afd3 | |||
| e9633a3adb | |||
| 61224e5cfe | |||
| dc581350e6 | |||
| 64c5b20ce3 | |||
| 8a79798fa6 | |||
| dff466244d | |||
| 7ab3d3861c | |||
| 8e90468637 | |||
| ac942a2034 | |||
| d52a096607 | |||
| 7caccb11fa | |||
| e22c797fa3 | |||
| 0c5736d9c9 | |||
| 2d8f7d425c | |||
| 7d1942e9f0 | |||
| 5d8cd62e44 | |||
| b6dc5c0fee | |||
| c1b8e4b501 | |||
| 65feb92286 | |||
| f5d95ffed5 | |||
| 6f9c1c6d4e | |||
| 811c82a677 | |||
| 4f0e43ec1b | |||
| 3798c8bdb0 | |||
| c49851e027 | |||
| 3c43594c26 | |||
| 26a7b7b66d | |||
| 8611ffe32d | |||
| cfd827cfad | |||
| e9a294f733 | |||
| b213335316 | |||
| ff5c725586 | |||
| bf0dfcac2f | |||
| 5aa7bfebd4 | |||
| e7d9e552a7 | |||
| d2c55dc011 |
38
.github/CODEOWNERS
vendored
@ -1,34 +1,34 @@
|
||||
# continuous integration
|
||||
/.github/workflows/ @lstein @blessedcoolant
|
||||
/.github/workflows/ @lstein @blessedcoolant @hipsterusername
|
||||
|
||||
# documentation
|
||||
/docs/ @lstein @blessedcoolant @hipsterusername
|
||||
/mkdocs.yml @lstein @blessedcoolant
|
||||
/docs/ @lstein @blessedcoolant @hipsterusername @Millu
|
||||
/mkdocs.yml @lstein @blessedcoolant @hipsterusername @Millu
|
||||
|
||||
# nodes
|
||||
/invokeai/app/ @Kyle0654 @blessedcoolant @psychedelicious @brandonrising
|
||||
/invokeai/app/ @Kyle0654 @blessedcoolant @psychedelicious @brandonrising @hipsterusername
|
||||
|
||||
# installation and configuration
|
||||
/pyproject.toml @lstein @blessedcoolant
|
||||
/docker/ @lstein @blessedcoolant
|
||||
/scripts/ @ebr @lstein
|
||||
/installer/ @lstein @ebr
|
||||
/invokeai/assets @lstein @ebr
|
||||
/invokeai/configs @lstein
|
||||
/invokeai/version @lstein @blessedcoolant
|
||||
/pyproject.toml @lstein @blessedcoolant @hipsterusername
|
||||
/docker/ @lstein @blessedcoolant @hipsterusername
|
||||
/scripts/ @ebr @lstein @hipsterusername
|
||||
/installer/ @lstein @ebr @hipsterusername
|
||||
/invokeai/assets @lstein @ebr @hipsterusername
|
||||
/invokeai/configs @lstein @hipsterusername
|
||||
/invokeai/version @lstein @blessedcoolant @hipsterusername
|
||||
|
||||
# web ui
|
||||
/invokeai/frontend @blessedcoolant @psychedelicious @lstein @maryhipp
|
||||
/invokeai/backend @blessedcoolant @psychedelicious @lstein @maryhipp
|
||||
/invokeai/frontend @blessedcoolant @psychedelicious @lstein @maryhipp @hipsterusername
|
||||
/invokeai/backend @blessedcoolant @psychedelicious @lstein @maryhipp @hipsterusername
|
||||
|
||||
# generation, model management, postprocessing
|
||||
/invokeai/backend @damian0815 @lstein @blessedcoolant @gregghelt2 @StAlKeR7779 @brandonrising
|
||||
/invokeai/backend @damian0815 @lstein @blessedcoolant @gregghelt2 @StAlKeR7779 @brandonrising @ryanjdick @hipsterusername
|
||||
|
||||
# front ends
|
||||
/invokeai/frontend/CLI @lstein
|
||||
/invokeai/frontend/install @lstein @ebr
|
||||
/invokeai/frontend/merge @lstein @blessedcoolant
|
||||
/invokeai/frontend/training @lstein @blessedcoolant
|
||||
/invokeai/frontend/web @psychedelicious @blessedcoolant @maryhipp
|
||||
/invokeai/frontend/CLI @lstein @hipsterusername
|
||||
/invokeai/frontend/install @lstein @ebr @hipsterusername
|
||||
/invokeai/frontend/merge @lstein @blessedcoolant @hipsterusername
|
||||
/invokeai/frontend/training @lstein @blessedcoolant @hipsterusername
|
||||
/invokeai/frontend/web @psychedelicious @blessedcoolant @maryhipp @hipsterusername
|
||||
|
||||
|
||||
|
||||
17
.github/ISSUE_TEMPLATE/FEATURE_REQUEST.yml
vendored
@ -1,5 +1,5 @@
|
||||
name: Feature Request
|
||||
description: Commit a idea or Request a new feature
|
||||
description: Contribute a idea or request a new feature
|
||||
title: '[enhancement]: '
|
||||
labels: ['enhancement']
|
||||
# assignees:
|
||||
@ -9,14 +9,14 @@ body:
|
||||
- type: markdown
|
||||
attributes:
|
||||
value: |
|
||||
Thanks for taking the time to fill out this Feature request!
|
||||
Thanks for taking the time to fill out this feature request!
|
||||
|
||||
- type: checkboxes
|
||||
attributes:
|
||||
label: Is there an existing issue for this?
|
||||
description: |
|
||||
Please make use of the [search function](https://github.com/invoke-ai/InvokeAI/labels/enhancement)
|
||||
to see if a simmilar issue already exists for the feature you want to request
|
||||
to see if a similar issue already exists for the feature you want to request
|
||||
options:
|
||||
- label: I have searched the existing issues
|
||||
required: true
|
||||
@ -34,12 +34,9 @@ body:
|
||||
id: whatisexpected
|
||||
attributes:
|
||||
label: What should this feature add?
|
||||
description: Please try to explain the functionality this feature should add
|
||||
description: Explain the functionality this feature should add. Feature requests should be for single features. Please create multiple requests if you want to request multiple features.
|
||||
placeholder: |
|
||||
Instead of one huge textfield, it would be nice to have forms for bug-reports, feature-requests, ...
|
||||
Great benefits with automatic labeling, assigning and other functionalitys not available in that form
|
||||
via old-fashioned markdown-templates. I would also love to see the use of a moderator bot 🤖 like
|
||||
https://github.com/marketplace/actions/issue-moderator-with-commands to auto close old issues and other things
|
||||
I'd like a button that creates an image of banana sushi every time I press it. Each image should be different. There should be a toggle next to the button that enables strawberry mode, in which the images are of strawberry sushi instead.
|
||||
validations:
|
||||
required: true
|
||||
|
||||
@ -51,6 +48,6 @@ body:
|
||||
|
||||
- type: textarea
|
||||
attributes:
|
||||
label: Aditional Content
|
||||
label: Additional Content
|
||||
description: Add any other context or screenshots about the feature request here.
|
||||
placeholder: This is a Mockup of the design how I imagine it <screenshot>
|
||||
placeholder: This is a mockup of the design how I imagine it <screenshot>
|
||||
|
||||
6
.github/workflows/style-checks.yml
vendored
@ -1,6 +1,4 @@
|
||||
name: style checks
|
||||
# just formatting and flake8 for now
|
||||
# TODO: add isort later
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
@ -20,8 +18,8 @@ jobs:
|
||||
|
||||
- name: Install dependencies with pip
|
||||
run: |
|
||||
pip install black flake8 Flake8-pyproject
|
||||
pip install black flake8 Flake8-pyproject isort
|
||||
|
||||
# - run: isort --check-only .
|
||||
- run: isort --check-only .
|
||||
- run: black --check .
|
||||
- run: flake8
|
||||
|
||||
@ -15,3 +15,10 @@ repos:
|
||||
language: system
|
||||
entry: flake8
|
||||
types: [python]
|
||||
|
||||
- id: isort
|
||||
name: isort
|
||||
stages: [commit]
|
||||
language: system
|
||||
entry: isort
|
||||
types: [python]
|
||||
29
README.md
@ -46,13 +46,13 @@ the foundation for multiple commercial products.
|
||||
Install](https://invoke-ai.github.io/InvokeAI/installation/INSTALLATION/)] [<a
|
||||
href="https://discord.gg/ZmtBAhwWhy">Discord Server</a>] [<a
|
||||
href="https://invoke-ai.github.io/InvokeAI/">Documentation and
|
||||
Tutorials</a>] [<a
|
||||
href="https://github.com/invoke-ai/InvokeAI/">Code and
|
||||
Downloads</a>] [<a
|
||||
href="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>]
|
||||
Tutorials</a>]
|
||||
[<a href="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>]
|
||||
[<a
|
||||
href="https://github.com/invoke-ai/InvokeAI/discussions">Discussion,
|
||||
Ideas & Q&A</a>]
|
||||
Ideas & Q&A</a>]
|
||||
[<a
|
||||
href="https://invoke-ai.github.io/InvokeAI/contributing/CONTRIBUTING/">Contributing</a>]
|
||||
|
||||
<div align="center">
|
||||
|
||||
@ -368,9 +368,9 @@ InvokeAI offers a locally hosted Web Server & React Frontend, with an industry l
|
||||
|
||||
The Unified Canvas is a fully integrated canvas implementation with support for all core generation capabilities, in/outpainting, brush tools, and more. This creative tool unlocks the capability for artists to create with AI as a creative collaborator, and can be used to augment AI-generated imagery, sketches, photography, renders, and more.
|
||||
|
||||
### *Node Architecture & Editor (Beta)*
|
||||
### *Workflows & Nodes*
|
||||
|
||||
Invoke AI's backend is built on a graph-based execution architecture. This allows for customizable generation pipelines to be developed by professional users looking to create specific workflows to support their production use-cases, and will be extended in the future with additional capabilities.
|
||||
InvokeAI offers a fully featured workflow management solution, enabling users to combine the power of nodes based workflows with the easy of a UI. This allows for customizable generation pipelines to be developed and shared by users looking to create specific workflows to support their production use-cases.
|
||||
|
||||
### *Board & Gallery Management*
|
||||
|
||||
@ -383,8 +383,9 @@ Invoke AI provides an organized gallery system for easily storing, accessing, an
|
||||
- *Upscaling Tools*
|
||||
- *Embedding Manager & Support*
|
||||
- *Model Manager & Support*
|
||||
- *Workflow creation & management*
|
||||
- *Node-Based Architecture*
|
||||
- *Node-Based Plug-&-Play UI (Beta)*
|
||||
|
||||
|
||||
### Latest Changes
|
||||
|
||||
@ -395,20 +396,18 @@ Notes](https://github.com/invoke-ai/InvokeAI/releases) and the
|
||||
### Troubleshooting
|
||||
|
||||
Please check out our **[Q&A](https://invoke-ai.github.io/InvokeAI/help/TROUBLESHOOT/#faq)** to get solutions for common installation
|
||||
problems and other issues.
|
||||
problems and other issues. For more help, please join our [Discord][discord link]
|
||||
|
||||
## Contributing
|
||||
|
||||
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code
|
||||
cleanup, testing, or code reviews, is very much encouraged to do so.
|
||||
|
||||
To join, just raise your hand on the InvokeAI Discord server (#dev-chat) or the GitHub discussion board.
|
||||
|
||||
If you'd like to help with translation, please see our [translation guide](docs/other/TRANSLATION.md).
|
||||
Get started with contributing by reading our [Contribution documentation](https://invoke-ai.github.io/InvokeAI/contributing/CONTRIBUTING/), joining the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) or the GitHub discussion board.
|
||||
|
||||
If you are unfamiliar with how
|
||||
to contribute to GitHub projects, here is a
|
||||
[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github). A full set of contribution guidelines, along with templates, are in progress. You can **make your pull request against the "main" branch**.
|
||||
to contribute to GitHub projects, we have a new contributor checklist you can follow to get started contributing:
|
||||
[New Contributor Checklist](https://invoke-ai.github.io/InvokeAI/contributing/contribution_guides/newContributorChecklist/).
|
||||
|
||||
We hope you enjoy using our software as much as we enjoy creating it,
|
||||
and we hope that some of those of you who are reading this will elect
|
||||
@ -424,7 +423,7 @@ their time, hard work and effort.
|
||||
|
||||
### Support
|
||||
|
||||
For support, please use this repository's GitHub Issues tracking service, or join the Discord.
|
||||
For support, please use this repository's GitHub Issues tracking service, or join the [Discord][discord link].
|
||||
|
||||
Original portions of the software are Copyright (c) 2023 by respective contributors.
|
||||
|
||||
|
||||
{kind=link}
|
Before Width: | Height: | Size: 490 KiB After Width: | Height: | Size: 228 KiB |
{kind=link}
|
Before Width: | Height: | Size: 319 KiB After Width: | Height: | Size: 194 KiB |
{kind=link}
|
Before Width: | Height: | Size: 217 KiB After Width: | Height: | Size: 209 KiB |
{kind=link}
|
Before Width: | Height: | Size: 244 KiB After Width: | Height: | Size: 114 KiB |
{kind=link}
|
Before Width: | Height: | Size: 948 KiB After Width: | Height: | Size: 187 KiB |
{kind=link}
|
Before Width: | Height: | Size: 292 KiB After Width: | Height: | Size: 112 KiB |
{kind=link}
|
Before Width: | Height: | Size: 420 KiB After Width: | Height: | Size: 132 KiB |
{kind=link}
|
Before Width: | Height: | Size: 197 KiB After Width: | Height: | Size: 167 KiB |
{kind=link}
|
Before Width: | Height: | Size: 216 KiB After Width: | Height: | Size: 70 KiB |
BIN
docs/assets/nodes/linearview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 59 KiB |
BIN
docs/assets/prompt_syntax/sdxl-prompt-concatenated.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
docs/assets/prompt_syntax/sdxl-prompt.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 42 KiB |
@ -1,39 +1,41 @@
|
||||
# How to Contribute
|
||||
# Contributing
|
||||
|
||||
## Welcome to Invoke AI
|
||||
Invoke AI originated as a project built by the community, and that vision carries forward today as we aim to build the best pro-grade tools available. We work together to incorporate the latest in AI/ML research, making these tools available in over 20 languages to artists and creatives around the world as part of our fully permissive OSS project designed for individual users to self-host and use.
|
||||
|
||||
|
||||
## Contributing to Invoke AI
|
||||
# Methods of Contributing to Invoke AI
|
||||
Anyone who wishes to contribute to InvokeAI, whether features, bug fixes, code cleanup, testing, code reviews, documentation or translation is very much encouraged to do so.
|
||||
|
||||
To join, just raise your hand on the InvokeAI Discord server (#dev-chat) or the GitHub discussion board.
|
||||
## Development
|
||||
If you’d like to help with development, please see our [development guide](contribution_guides/development.md).
|
||||
|
||||
### Areas of contribution:
|
||||
**New Contributors:** If you’re unfamiliar with contributing to open source projects, take a look at our [new contributor guide](contribution_guides/newContributorChecklist.md).
|
||||
|
||||
#### Development
|
||||
If you’d like to help with development, please see our [development guide](contribution_guides/development.md). If you’re unfamiliar with contributing to open source projects, there is a tutorial contained within the development guide.
|
||||
## Nodes
|
||||
If you’d like to add a Node, please see our [nodes contribution guide](../nodes/contributingNodes.md).
|
||||
|
||||
#### Nodes
|
||||
If you’d like to help with development, please see our [nodes contribution guide](/nodes/contributingNodes). If you’re unfamiliar with contributing to open source projects, there is a tutorial contained within the development guide.
|
||||
## Support and Triaging
|
||||
Helping support other users in [Discord](https://discord.gg/ZmtBAhwWhy) and on Github are valuable forms of contribution that we greatly appreciate.
|
||||
|
||||
#### Documentation
|
||||
We receive many issues and requests for help from users. We're limited in bandwidth relative to our the user base, so providing answers to questions or helping identify causes of issues is very helpful. By doing this, you enable us to spend time on the highest priority work.
|
||||
|
||||
## Documentation
|
||||
If you’d like to help with documentation, please see our [documentation guide](contribution_guides/documentation.md).
|
||||
|
||||
#### Translation
|
||||
## Translation
|
||||
If you'd like to help with translation, please see our [translation guide](contribution_guides/translation.md).
|
||||
|
||||
#### Tutorials
|
||||
## Tutorials
|
||||
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
|
||||
|
||||
We hope you enjoy using our software as much as we enjoy creating it, and we hope that some of those of you who are reading this will elect to become part of our contributor community.
|
||||
|
||||
|
||||
### Contributors
|
||||
# Contributors
|
||||
|
||||
This project is a combined effort of dedicated people from across the world. [Check out the list of all these amazing people](https://invoke-ai.github.io/InvokeAI/other/CONTRIBUTORS/). We thank them for their time, hard work and effort.
|
||||
|
||||
### Code of Conduct
|
||||
# Code of Conduct
|
||||
|
||||
The InvokeAI community is a welcoming place, and we want your help in maintaining that. Please review our [Code of Conduct](https://github.com/invoke-ai/InvokeAI/blob/main/CODE_OF_CONDUCT.md) to learn more - it's essential to maintaining a respectful and inclusive environment.
|
||||
|
||||
@ -47,8 +49,7 @@ By making a contribution to this project, you certify that:
|
||||
This disclaimer is not a license and does not grant any rights or permissions. You must obtain necessary permissions and licenses, including from third parties, before contributing to this project.
|
||||
|
||||
This disclaimer is provided "as is" without warranty of any kind, whether expressed or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose, or non-infringement. In no event shall the authors or copyright holders be liable for any claim, damages, or other liability, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the contribution or the use or other dealings in the contribution.
|
||||
|
||||
### Support
|
||||
# Support
|
||||
|
||||
For support, please use this repository's [GitHub Issues](https://github.com/invoke-ai/InvokeAI/issues), or join the [Discord](https://discord.gg/ZmtBAhwWhy).
|
||||
|
||||
|
||||
@ -29,12 +29,13 @@ The first set of things we need to do when creating a new Invocation are -
|
||||
|
||||
- Create a new class that derives from a predefined parent class called
|
||||
`BaseInvocation`.
|
||||
- The name of every Invocation must end with the word `Invocation` in order for
|
||||
it to be recognized as an Invocation.
|
||||
- Every Invocation must have a `docstring` that describes what this Invocation
|
||||
does.
|
||||
- Every Invocation must have a unique `type` field defined which becomes its
|
||||
indentifier.
|
||||
- While not strictly required, we suggest every invocation class name ends in
|
||||
"Invocation", eg "CropImageInvocation".
|
||||
- Every Invocation must use the `@invocation` decorator to provide its unique
|
||||
invocation type. You may also provide its title, tags and category using the
|
||||
decorator.
|
||||
- Invocations are strictly typed. We make use of the native
|
||||
[typing](https://docs.python.org/3/library/typing.html) library and the
|
||||
installed [pydantic](https://pydantic-docs.helpmanual.io/) library for
|
||||
@ -43,12 +44,11 @@ The first set of things we need to do when creating a new Invocation are -
|
||||
So let us do that.
|
||||
|
||||
```python
|
||||
from typing import Literal
|
||||
from .baseinvocation import BaseInvocation
|
||||
from .baseinvocation import BaseInvocation, invocation
|
||||
|
||||
@invocation('resize')
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
```
|
||||
|
||||
That's great.
|
||||
@ -62,8 +62,10 @@ our Invocation takes.
|
||||
|
||||
### **Inputs**
|
||||
|
||||
Every Invocation input is a pydantic `Field` and like everything else should be
|
||||
strictly typed and defined.
|
||||
Every Invocation input must be defined using the `InputField` function. This is
|
||||
a wrapper around the pydantic `Field` function, which handles a few extra things
|
||||
and provides type hints. Like everything else, this should be strictly typed and
|
||||
defined.
|
||||
|
||||
So let us create these inputs for our Invocation. First up, the `image` input we
|
||||
need. Generally, we can use standard variable types in Python but InvokeAI
|
||||
@ -76,55 +78,51 @@ create your own custom field types later in this guide. For now, let's go ahead
|
||||
and use it.
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation
|
||||
from ..models.image import ImageField
|
||||
from .baseinvocation import BaseInvocation, InputField, invocation
|
||||
from .primitives import ImageField
|
||||
|
||||
@invocation('resize')
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
image: ImageField = InputField(description="The input image")
|
||||
```
|
||||
|
||||
Let us break down our input code.
|
||||
|
||||
```python
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
image: ImageField = InputField(description="The input image")
|
||||
```
|
||||
|
||||
| Part | Value | Description |
|
||||
| --------- | ---------------------------------------------------- | -------------------------------------------------------------------------------------------------- |
|
||||
| Name | `image` | The variable that will hold our image |
|
||||
| Type Hint | `Union[ImageField, None]` | The types for our field. Indicates that the image can either be an `ImageField` type or `None` |
|
||||
| Field | `Field(description="The input image", default=None)` | The image variable is a field which needs a description and a default value that we set to `None`. |
|
||||
| Part | Value | Description |
|
||||
| --------- | ------------------------------------------- | ------------------------------------------------------------------------------- |
|
||||
| Name | `image` | The variable that will hold our image |
|
||||
| Type Hint | `ImageField` | The types for our field. Indicates that the image must be an `ImageField` type. |
|
||||
| Field | `InputField(description="The input image")` | The image variable is an `InputField` which needs a description. |
|
||||
|
||||
Great. Now let us create our other inputs for `width` and `height`
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation
|
||||
from ..models.image import ImageField
|
||||
from .baseinvocation import BaseInvocation, InputField, invocation
|
||||
from .primitives import ImageField
|
||||
|
||||
@invocation('resize')
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
width: int = Field(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = Field(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
image: ImageField = InputField(description="The input image")
|
||||
width: int = InputField(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = InputField(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
```
|
||||
|
||||
As you might have noticed, we added two new parameters to the field type for
|
||||
`width` and `height` called `gt` and `le`. These basically stand for _greater
|
||||
than or equal to_ and _less than or equal to_. There are various other param
|
||||
types for field that you can find on the **pydantic** documentation.
|
||||
As you might have noticed, we added two new arguments to the `InputField`
|
||||
definition for `width` and `height`, called `gt` and `le`. They stand for
|
||||
_greater than or equal to_ and _less than or equal to_.
|
||||
|
||||
These impose contraints on those fields, and will raise an exception if the
|
||||
values do not meet the constraints. Field constraints are provided by
|
||||
**pydantic**, so anything you see in the **pydantic docs** will work.
|
||||
|
||||
**Note:** _Any time it is possible to define constraints for our field, we
|
||||
should do it so the frontend has more information on how to parse this field._
|
||||
@ -141,20 +139,17 @@ that are provided by it by InvokeAI.
|
||||
Let us create this function first.
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation, InvocationContext
|
||||
from ..models.image import ImageField
|
||||
from .baseinvocation import BaseInvocation, InputField, invocation
|
||||
from .primitives import ImageField
|
||||
|
||||
@invocation('resize')
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
width: int = Field(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = Field(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
image: ImageField = InputField(description="The input image")
|
||||
width: int = InputField(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = InputField(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
|
||||
def invoke(self, context: InvocationContext):
|
||||
pass
|
||||
@ -173,21 +168,18 @@ all the necessary info related to image outputs. So let us use that.
|
||||
We will cover how to create your own output types later in this guide.
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation, InvocationContext
|
||||
from ..models.image import ImageField
|
||||
from .baseinvocation import BaseInvocation, InputField, invocation
|
||||
from .primitives import ImageField
|
||||
from .image import ImageOutput
|
||||
|
||||
@invocation('resize')
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
width: int = Field(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = Field(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
image: ImageField = InputField(description="The input image")
|
||||
width: int = InputField(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = InputField(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pass
|
||||
@ -195,39 +187,34 @@ class ResizeInvocation(BaseInvocation):
|
||||
|
||||
Perfect. Now that we have our Invocation setup, let us do what we want to do.
|
||||
|
||||
- We will first load the image. Generally we do this using the `PIL` library but
|
||||
we can use one of the services provided by InvokeAI to load the image.
|
||||
- We will first load the image using one of the services provided by InvokeAI to
|
||||
load the image.
|
||||
- We will resize the image using `PIL` to our input data.
|
||||
- We will output this image in the format we set above.
|
||||
|
||||
So let's do that.
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation, InvocationContext
|
||||
from ..models.image import ImageField, ResourceOrigin, ImageCategory
|
||||
from .baseinvocation import BaseInvocation, InputField, invocation
|
||||
from .primitives import ImageField
|
||||
from .image import ImageOutput
|
||||
|
||||
@invocation("resize")
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
"""Resizes an image"""
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
width: int = Field(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = Field(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
image: ImageField = InputField(description="The input image")
|
||||
width: int = InputField(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = InputField(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
# Load the image using InvokeAI's predefined Image Service.
|
||||
image = context.services.images.get_pil_image(self.image.image_origin, self.image.image_name)
|
||||
# Load the image using InvokeAI's predefined Image Service. Returns the PIL image.
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# Resizing the image
|
||||
# Because we used the above service, we already have a PIL image. So we can simply resize.
|
||||
resized_image = image.resize((self.width, self.height))
|
||||
|
||||
# Preparing the image for output using InvokeAI's predefined Image Service.
|
||||
# Save the image using InvokeAI's predefined Image Service. Returns the prepared PIL image.
|
||||
output_image = context.services.images.create(
|
||||
image=resized_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
@ -241,7 +228,6 @@ class ResizeInvocation(BaseInvocation):
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=output_image.image_name,
|
||||
image_origin=output_image.image_origin,
|
||||
),
|
||||
width=output_image.width,
|
||||
height=output_image.height,
|
||||
@ -253,6 +239,24 @@ certain way that the images need to be dispatched in order to be stored and read
|
||||
correctly. In 99% of the cases when dealing with an image output, you can simply
|
||||
copy-paste the template above.
|
||||
|
||||
### Customization
|
||||
|
||||
We can use the `@invocation` decorator to provide some additional info to the
|
||||
UI, like a custom title, tags and category.
|
||||
|
||||
We also encourage providing a version. This must be a
|
||||
[semver](https://semver.org/) version string ("$MAJOR.$MINOR.$PATCH"). The UI
|
||||
will let users know if their workflow is using a mismatched version of the node.
|
||||
|
||||
```python
|
||||
@invocation("resize", title="My Resizer", tags=["resize", "image"], category="My Invocations", version="1.0.0")
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
"""Resizes an image"""
|
||||
|
||||
image: ImageField = InputField(description="The input image")
|
||||
...
|
||||
```
|
||||
|
||||
That's it. You made your own **Resize Invocation**.
|
||||
|
||||
## Result
|
||||
@ -271,10 +275,55 @@ new Invocation ready to be used.
|
||||

|
||||
|
||||
## Contributing Nodes
|
||||
Once you've created a Node, the next step is to share it with the community! The best way to do this is to submit a Pull Request to add the Node to the [Community Nodes](nodes/communityNodes) list. If you're not sure how to do that, take a look a at our [contributing nodes overview](contributingNodes).
|
||||
|
||||
Once you've created a Node, the next step is to share it with the community! The
|
||||
best way to do this is to submit a Pull Request to add the Node to the
|
||||
[Community Nodes](nodes/communityNodes) list. If you're not sure how to do that,
|
||||
take a look a at our [contributing nodes overview](contributingNodes).
|
||||
|
||||
## Advanced
|
||||
|
||||
### Custom Output Types
|
||||
|
||||
Like with custom inputs, sometimes you might find yourself needing custom
|
||||
outputs that InvokeAI does not provide. We can easily set one up.
|
||||
|
||||
Now that you are familiar with Invocations and Inputs, let us use that knowledge
|
||||
to create an output that has an `image` field, a `color` field and a `string`
|
||||
field.
|
||||
|
||||
- An invocation output is a class that derives from the parent class of
|
||||
`BaseInvocationOutput`.
|
||||
- All invocation outputs must use the `@invocation_output` decorator to provide
|
||||
their unique output type.
|
||||
- Output fields must use the provided `OutputField` function. This is very
|
||||
similar to the `InputField` function described earlier - it's a wrapper around
|
||||
`pydantic`'s `Field()`.
|
||||
- It is not mandatory but we recommend using names ending with `Output` for
|
||||
output types.
|
||||
- It is not mandatory but we highly recommend adding a `docstring` to describe
|
||||
what your output type is for.
|
||||
|
||||
Now that we know the basic rules for creating a new output type, let us go ahead
|
||||
and make it.
|
||||
|
||||
```python
|
||||
from .baseinvocation import BaseInvocationOutput, OutputField, invocation_output
|
||||
from .primitives import ImageField, ColorField
|
||||
|
||||
@invocation_output('image_color_string_output')
|
||||
class ImageColorStringOutput(BaseInvocationOutput):
|
||||
'''Base class for nodes that output a single image'''
|
||||
|
||||
image: ImageField = OutputField(description="The image")
|
||||
color: ColorField = OutputField(description="The color")
|
||||
text: str = OutputField(description="The string")
|
||||
```
|
||||
|
||||
That's all there is to it.
|
||||
|
||||
<!-- TODO: DANGER - we probably do not want people to create their own field types, because this requires a lot of work on the frontend to accomodate.
|
||||
|
||||
### Custom Input Fields
|
||||
|
||||
Now that you know how to create your own Invocations, let us dive into slightly
|
||||
@ -329,172 +378,6 @@ like this.
|
||||
color: ColorField = Field(default=ColorField(r=0, g=0, b=0, a=0), description='Background color of an image')
|
||||
```
|
||||
|
||||
**Extra Config**
|
||||
|
||||
All input fields also take an additional `Config` class that you can use to do
|
||||
various advanced things like setting required parameters and etc.
|
||||
|
||||
Let us do that for our _ColorField_ and enforce all the values because we did
|
||||
not define any defaults for our fields.
|
||||
|
||||
```python
|
||||
class ColorField(BaseModel):
|
||||
'''A field that holds the rgba values of a color'''
|
||||
r: int = Field(ge=0, le=255, description="The red channel")
|
||||
g: int = Field(ge=0, le=255, description="The green channel")
|
||||
b: int = Field(ge=0, le=255, description="The blue channel")
|
||||
a: int = Field(ge=0, le=255, description="The alpha channel")
|
||||
|
||||
class Config:
|
||||
schema_extra = {"required": ["r", "g", "b", "a"]}
|
||||
```
|
||||
|
||||
Now it becomes mandatory for the user to supply all the values required by our
|
||||
input field.
|
||||
|
||||
We will discuss the `Config` class in extra detail later in this guide and how
|
||||
you can use it to make your Invocations more robust.
|
||||
|
||||
### Custom Output Types
|
||||
|
||||
Like with custom inputs, sometimes you might find yourself needing custom
|
||||
outputs that InvokeAI does not provide. We can easily set one up.
|
||||
|
||||
Now that you are familiar with Invocations and Inputs, let us use that knowledge
|
||||
to put together a custom output type for an Invocation that returns _width_,
|
||||
_height_ and _background_color_ that we need to create a blank image.
|
||||
|
||||
- A custom output type is a class that derives from the parent class of
|
||||
`BaseInvocationOutput`.
|
||||
- It is not mandatory but we recommend using names ending with `Output` for
|
||||
output types. So we'll call our class `BlankImageOutput`
|
||||
- It is not mandatory but we highly recommend adding a `docstring` to describe
|
||||
what your output type is for.
|
||||
- Like Invocations, each output type should have a `type` variable that is
|
||||
**unique**
|
||||
|
||||
Now that we know the basic rules for creating a new output type, let us go ahead
|
||||
and make it.
|
||||
|
||||
```python
|
||||
from typing import Literal
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocationOutput
|
||||
|
||||
class BlankImageOutput(BaseInvocationOutput):
|
||||
'''Base output type for creating a blank image'''
|
||||
type: Literal['blank_image_output'] = 'blank_image_output'
|
||||
|
||||
# Inputs
|
||||
width: int = Field(description='Width of blank image')
|
||||
height: int = Field(description='Height of blank image')
|
||||
bg_color: ColorField = Field(description='Background color of blank image')
|
||||
|
||||
class Config:
|
||||
schema_extra = {"required": ["type", "width", "height", "bg_color"]}
|
||||
```
|
||||
|
||||
All set. We now have an output type that requires what we need to create a
|
||||
blank_image. And if you noticed it, we even used the `Config` class to ensure
|
||||
the fields are required.
|
||||
|
||||
### Custom Configuration
|
||||
|
||||
As you might have noticed when making inputs and outputs, we used a class called
|
||||
`Config` from _pydantic_ to further customize them. Because our inputs and
|
||||
outputs essentially inherit from _pydantic_'s `BaseModel` class, all
|
||||
[configuration options](https://docs.pydantic.dev/latest/usage/schema/#schema-customization)
|
||||
that are valid for _pydantic_ classes are also valid for our inputs and outputs.
|
||||
You can do the same for your Invocations too but InvokeAI makes our life a
|
||||
little bit easier on that end.
|
||||
|
||||
InvokeAI provides a custom configuration class called `InvocationConfig`
|
||||
particularly for configuring Invocations. This is exactly the same as the raw
|
||||
`Config` class from _pydantic_ with some extra stuff on top to help faciliate
|
||||
parsing of the scheme in the frontend UI.
|
||||
|
||||
At the current moment, tihs `InvocationConfig` class is further improved with
|
||||
the following features related the `ui`.
|
||||
|
||||
| Config Option | Field Type | Example |
|
||||
| ------------- | ------------------------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------- |
|
||||
| type_hints | `Dict[str, Literal["integer", "float", "boolean", "string", "enum", "image", "latents", "model", "control"]]` | `type_hint: "model"` provides type hints related to the model like displaying a list of available models |
|
||||
| tags | `List[str]` | `tags: ['resize', 'image']` will classify your invocation under the tags of resize and image. |
|
||||
| title | `str` | `title: 'Resize Image` will rename your to this custom title rather than infer from the name of the Invocation class. |
|
||||
|
||||
So let us update your `ResizeInvocation` with some extra configuration and see
|
||||
how that works.
|
||||
|
||||
```python
|
||||
from typing import Literal, Union
|
||||
from pydantic import Field
|
||||
|
||||
from .baseinvocation import BaseInvocation, InvocationContext, InvocationConfig
|
||||
from ..models.image import ImageField, ResourceOrigin, ImageCategory
|
||||
from .image import ImageOutput
|
||||
|
||||
class ResizeInvocation(BaseInvocation):
|
||||
'''Resizes an image'''
|
||||
type: Literal['resize'] = 'resize'
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
width: int = Field(default=512, ge=64, le=2048, description="Width of the new image")
|
||||
height: int = Field(default=512, ge=64, le=2048, description="Height of the new image")
|
||||
|
||||
class Config(InvocationConfig):
|
||||
schema_extra: {
|
||||
ui: {
|
||||
tags: ['resize', 'image'],
|
||||
title: ['My Custom Resize']
|
||||
}
|
||||
}
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
# Load the image using InvokeAI's predefined Image Service.
|
||||
image = context.services.images.get_pil_image(self.image.image_origin, self.image.image_name)
|
||||
|
||||
# Resizing the image
|
||||
# Because we used the above service, we already have a PIL image. So we can simply resize.
|
||||
resized_image = image.resize((self.width, self.height))
|
||||
|
||||
# Preparing the image for output using InvokeAI's predefined Image Service.
|
||||
output_image = context.services.images.create(
|
||||
image=resized_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
# Returning the Image
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=output_image.image_name,
|
||||
image_origin=output_image.image_origin,
|
||||
),
|
||||
width=output_image.width,
|
||||
height=output_image.height,
|
||||
)
|
||||
```
|
||||
|
||||
We now customized our code to let the frontend know that our Invocation falls
|
||||
under `resize` and `image` categories. So when the user searches for these
|
||||
particular words, our Invocation will show up too.
|
||||
|
||||
We also set a custom title for our Invocation. So instead of being called
|
||||
`Resize`, it will be called `My Custom Resize`.
|
||||
|
||||
As simple as that.
|
||||
|
||||
As time goes by, InvokeAI will further improve and add more customizability for
|
||||
Invocation configuration. We will have more documentation regarding this at a
|
||||
later time.
|
||||
|
||||
# **[TODO]**
|
||||
|
||||
### Custom Components For Frontend
|
||||
|
||||
Every backend input type should have a corresponding frontend component so the
|
||||
@ -513,282 +396,4 @@ Let us create a new component for our custom color field we created above. When
|
||||
we use a color field, let us say we want the UI to display a color picker for
|
||||
the user to pick from rather than entering values. That is what we will build
|
||||
now.
|
||||
|
||||
---
|
||||
|
||||
<!-- # OLD -- TO BE DELETED OR MOVED LATER
|
||||
|
||||
---
|
||||
|
||||
## Creating a new invocation
|
||||
|
||||
To create a new invocation, either find the appropriate module file in
|
||||
`/ldm/invoke/app/invocations` to add your invocation to, or create a new one in
|
||||
that folder. All invocations in that folder will be discovered and made
|
||||
available to the CLI and API automatically. Invocations make use of
|
||||
[typing](https://docs.python.org/3/library/typing.html) and
|
||||
[pydantic](https://pydantic-docs.helpmanual.io/) for validation and integration
|
||||
into the CLI and API.
|
||||
|
||||
An invocation looks like this:
|
||||
|
||||
```py
|
||||
class UpscaleInvocation(BaseInvocation):
|
||||
"""Upscales an image."""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["upscale"] = "upscale"
|
||||
|
||||
# Inputs
|
||||
image: Union[ImageField, None] = Field(description="The input image", default=None)
|
||||
strength: float = Field(default=0.75, gt=0, le=1, description="The strength")
|
||||
level: Literal[2, 4] = Field(default=2, description="The upscale level")
|
||||
# fmt: on
|
||||
|
||||
# Schema customisation
|
||||
class Config(InvocationConfig):
|
||||
schema_extra = {
|
||||
"ui": {
|
||||
"tags": ["upscaling", "image"],
|
||||
},
|
||||
}
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(
|
||||
self.image.image_origin, self.image.image_name
|
||||
)
|
||||
results = context.services.restoration.upscale_and_reconstruct(
|
||||
image_list=[[image, 0]],
|
||||
upscale=(self.level, self.strength),
|
||||
strength=0.0, # GFPGAN strength
|
||||
save_original=False,
|
||||
image_callback=None,
|
||||
)
|
||||
|
||||
# Results are image and seed, unwrap for now
|
||||
# TODO: can this return multiple results?
|
||||
image_dto = context.services.images.create(
|
||||
image=results[0][0],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
image_origin=image_dto.image_origin,
|
||||
),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
```
|
||||
|
||||
Each portion is important to implement correctly.
|
||||
|
||||
### Class definition and type
|
||||
|
||||
```py
|
||||
class UpscaleInvocation(BaseInvocation):
|
||||
"""Upscales an image."""
|
||||
type: Literal['upscale'] = 'upscale'
|
||||
```
|
||||
|
||||
All invocations must derive from `BaseInvocation`. They should have a docstring
|
||||
that declares what they do in a single, short line. They should also have a
|
||||
`type` with a type hint that's `Literal["command_name"]`, where `command_name`
|
||||
is what the user will type on the CLI or use in the API to create this
|
||||
invocation. The `command_name` must be unique. The `type` must be assigned to
|
||||
the value of the literal in the type hint.
|
||||
|
||||
### Inputs
|
||||
|
||||
```py
|
||||
# Inputs
|
||||
image: Union[ImageField,None] = Field(description="The input image")
|
||||
strength: float = Field(default=0.75, gt=0, le=1, description="The strength")
|
||||
level: Literal[2,4] = Field(default=2, description="The upscale level")
|
||||
```
|
||||
|
||||
Inputs consist of three parts: a name, a type hint, and a `Field` with default,
|
||||
description, and validation information. For example:
|
||||
|
||||
| Part | Value | Description |
|
||||
| --------- | ------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Name | `strength` | This field is referred to as `strength` |
|
||||
| Type Hint | `float` | This field must be of type `float` |
|
||||
| Field | `Field(default=0.75, gt=0, le=1, description="The strength")` | The default value is `0.75`, the value must be in the range (0,1], and help text will show "The strength" for this field. |
|
||||
|
||||
Notice that `image` has type `Union[ImageField,None]`. The `Union` allows this
|
||||
field to be parsed with `None` as a value, which enables linking to previous
|
||||
invocations. All fields should either provide a default value or allow `None` as
|
||||
a value, so that they can be overwritten with a linked output from another
|
||||
invocation.
|
||||
|
||||
The special type `ImageField` is also used here. All images are passed as
|
||||
`ImageField`, which protects them from pydantic validation errors (since images
|
||||
only ever come from links).
|
||||
|
||||
Finally, note that for all linking, the `type` of the linked fields must match.
|
||||
If the `name` also matches, then the field can be **automatically linked** to a
|
||||
previous invocation by name and matching.
|
||||
|
||||
### Config
|
||||
|
||||
```py
|
||||
# Schema customisation
|
||||
class Config(InvocationConfig):
|
||||
schema_extra = {
|
||||
"ui": {
|
||||
"tags": ["upscaling", "image"],
|
||||
},
|
||||
}
|
||||
```
|
||||
|
||||
This is an optional configuration for the invocation. It inherits from
|
||||
pydantic's model `Config` class, and it used primarily to customize the
|
||||
autogenerated OpenAPI schema.
|
||||
|
||||
The UI relies on the OpenAPI schema in two ways:
|
||||
|
||||
- An API client & Typescript types are generated from it. This happens at build
|
||||
time.
|
||||
- The node editor parses the schema into a template used by the UI to create the
|
||||
node editor UI. This parsing happens at runtime.
|
||||
|
||||
In this example, a `ui` key has been added to the `schema_extra` dict to provide
|
||||
some tags for the UI, to facilitate filtering nodes.
|
||||
|
||||
See the Schema Generation section below for more information.
|
||||
|
||||
### Invoke Function
|
||||
|
||||
```py
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(
|
||||
self.image.image_origin, self.image.image_name
|
||||
)
|
||||
results = context.services.restoration.upscale_and_reconstruct(
|
||||
image_list=[[image, 0]],
|
||||
upscale=(self.level, self.strength),
|
||||
strength=0.0, # GFPGAN strength
|
||||
save_original=False,
|
||||
image_callback=None,
|
||||
)
|
||||
|
||||
# Results are image and seed, unwrap for now
|
||||
# TODO: can this return multiple results?
|
||||
image_dto = context.services.images.create(
|
||||
image=results[0][0],
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
image_origin=image_dto.image_origin,
|
||||
),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
```
|
||||
|
||||
The `invoke` function is the last portion of an invocation. It is provided an
|
||||
`InvocationContext` which contains services to perform work as well as a
|
||||
`session_id` for use as needed. It should return a class with output values that
|
||||
derives from `BaseInvocationOutput`.
|
||||
|
||||
Before being called, the invocation will have all of its fields set from
|
||||
defaults, inputs, and finally links (overriding in that order).
|
||||
|
||||
Assume that this invocation may be running simultaneously with other
|
||||
invocations, may be running on another machine, or in other interesting
|
||||
scenarios. If you need functionality, please provide it as a service in the
|
||||
`InvocationServices` class, and make sure it can be overridden.
|
||||
|
||||
### Outputs
|
||||
|
||||
```py
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for invocations that output an image"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["image_output"] = "image_output"
|
||||
image: ImageField = Field(default=None, description="The output image")
|
||||
width: int = Field(description="The width of the image in pixels")
|
||||
height: int = Field(description="The height of the image in pixels")
|
||||
# fmt: on
|
||||
|
||||
class Config:
|
||||
schema_extra = {"required": ["type", "image", "width", "height"]}
|
||||
```
|
||||
|
||||
Output classes look like an invocation class without the invoke method. Prefer
|
||||
to use an existing output class if available, and prefer to name inputs the same
|
||||
as outputs when possible, to promote automatic invocation linking.
|
||||
|
||||
## Schema Generation
|
||||
|
||||
Invocation, output and related classes are used to generate an OpenAPI schema.
|
||||
|
||||
### Required Properties
|
||||
|
||||
The schema generation treat all properties with default values as optional. This
|
||||
makes sense internally, but when when using these classes via the generated
|
||||
schema, we end up with e.g. the `ImageOutput` class having its `image` property
|
||||
marked as optional.
|
||||
|
||||
We know that this property will always be present, so the additional logic
|
||||
needed to always check if the property exists adds a lot of extraneous cruft.
|
||||
|
||||
To fix this, we can leverage `pydantic`'s
|
||||
[schema customisation](https://docs.pydantic.dev/usage/schema/#schema-customization)
|
||||
to mark properties that we know will always be present as required.
|
||||
|
||||
Here's that `ImageOutput` class, without the needed schema customisation:
|
||||
|
||||
```python
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for invocations that output an image"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["image_output"] = "image_output"
|
||||
image: ImageField = Field(default=None, description="The output image")
|
||||
width: int = Field(description="The width of the image in pixels")
|
||||
height: int = Field(description="The height of the image in pixels")
|
||||
# fmt: on
|
||||
```
|
||||
|
||||
The OpenAPI schema that results from this `ImageOutput` will have the `type`,
|
||||
`image`, `width` and `height` properties marked as optional, even though we know
|
||||
they will always have a value.
|
||||
|
||||
```python
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for invocations that output an image"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["image_output"] = "image_output"
|
||||
image: ImageField = Field(default=None, description="The output image")
|
||||
width: int = Field(description="The width of the image in pixels")
|
||||
height: int = Field(description="The height of the image in pixels")
|
||||
# fmt: on
|
||||
|
||||
# Add schema customization
|
||||
class Config:
|
||||
schema_extra = {"required": ["type", "image", "width", "height"]}
|
||||
```
|
||||
|
||||
With the customization in place, the schema will now show these properties as
|
||||
required, obviating the need for extensive null checks in client code.
|
||||
|
||||
See this `pydantic` issue for discussion on this solution:
|
||||
<https://github.com/pydantic/pydantic/discussions/4577> -->
|
||||
|
||||
-->
|
||||
|
||||
@ -4,14 +4,21 @@
|
||||
|
||||
If you are looking to help to with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
|
||||
|
||||
For more information, please review our area specific documentation:
|
||||
|
||||
## **Get Started**
|
||||
|
||||
To get started, take a look at our [new contributors checklist](newContributorChecklist.md)
|
||||
|
||||
Once you're setup, for more information, you can review the documentation specific to your area of interest:
|
||||
|
||||
* #### [InvokeAI Architecure](../ARCHITECTURE.md)
|
||||
* #### [Frontend Documentation](development_guides/contributingToFrontend.md)
|
||||
* #### [Node Documentation](../INVOCATIONS.md)
|
||||
* #### [Local Development](../LOCAL_DEVELOPMENT.md)
|
||||
|
||||
If you don't feel ready to make a code contribution yet, no problem! You can also help out in other ways, such as [documentation](documentation.md) or [translation](translation.md).
|
||||
|
||||
|
||||
If you don't feel ready to make a code contribution yet, no problem! You can also help out in other ways, such as [documentation](documentation.md), [translation](translation.md) or helping support other users and triage issues as they're reported in GitHub.
|
||||
|
||||
There are two paths to making a development contribution:
|
||||
|
||||
@ -23,60 +30,10 @@ There are two paths to making a development contribution:
|
||||
|
||||
## Best Practices:
|
||||
* Keep your pull requests small. Smaller pull requests are more likely to be accepted and merged
|
||||
* Comments! Commenting your code helps reviwers easily understand your contribution
|
||||
* Comments! Commenting your code helps reviewers easily understand your contribution
|
||||
* Use Python and Typescript’s typing systems, and consider using an editor with [LSP](https://microsoft.github.io/language-server-protocol/) support to streamline development
|
||||
* Make all communications public. This ensure knowledge is shared with the whole community
|
||||
|
||||
## **How do I make a contribution?**
|
||||
|
||||
Never made an open source contribution before? Wondering how contributions work in our project? Here's a quick rundown!
|
||||
|
||||
Before starting these steps, ensure you have your local environment [configured for development](../LOCAL_DEVELOPMENT.md).
|
||||
|
||||
1. Find a [good first issue](https://github.com/invoke-ai/InvokeAI/contribute) that you are interested in addressing or a feature that you would like to add. Then, reach out to our team in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord to ensure you are setup for success.
|
||||
2. Fork the [InvokeAI](https://github.com/invoke-ai/InvokeAI) repository to your GitHub profile. This means that you will have a copy of the repository under **your-GitHub-username/InvokeAI**.
|
||||
3. Clone the repository to your local machine using:
|
||||
|
||||
```bash
|
||||
git clone https://github.com/your-GitHub-username/InvokeAI.git
|
||||
```
|
||||
|
||||
If you're unfamiliar with using Git through the commandline, [GitHub Desktop](https://desktop.github.com) is a easy-to-use alternative with a UI. You can do all the same steps listed here, but through the interface.
|
||||
|
||||
4. Create a new branch for your fix using:
|
||||
|
||||
```bash
|
||||
git checkout -b branch-name-here
|
||||
```
|
||||
|
||||
5. Make the appropriate changes for the issue you are trying to address or the feature that you want to add.
|
||||
6. Add the file contents of the changed files to the "snapshot" git uses to manage the state of the project, also known as the index:
|
||||
|
||||
```bash
|
||||
git add insert-paths-of-changed-files-here
|
||||
```
|
||||
|
||||
7. Store the contents of the index with a descriptive message.
|
||||
|
||||
```bash
|
||||
git commit -m "Insert a short message of the changes made here"
|
||||
```
|
||||
|
||||
8. Push the changes to the remote repository using
|
||||
|
||||
```markdown
|
||||
git push origin branch-name-here
|
||||
```
|
||||
|
||||
9. Submit a pull request to the **main** branch of the InvokeAI repository.
|
||||
10. Title the pull request with a short description of the changes made and the issue or bug number associated with your change. For example, you can title an issue like so "Added more log outputting to resolve #1234".
|
||||
11. In the description of the pull request, explain the changes that you made, any issues you think exist with the pull request you made, and any questions you have for the maintainer. It's OK if your pull request is not perfect (no pull request is), the reviewer will be able to help you fix any problems and improve it!
|
||||
12. Wait for the pull request to be reviewed by other collaborators.
|
||||
13. Make changes to the pull request if the reviewer(s) recommend them.
|
||||
14. Celebrate your success after your pull request is merged!
|
||||
|
||||
If you’d like to learn more about contributing to Open Source projects, here is a [Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github).
|
||||
|
||||
## **Where can I go for help?**
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
@ -85,6 +42,7 @@ For frontend related work, **@pyschedelicious** is the best person to reach out
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
|
||||
|
||||
## **What does the Code of Conduct mean for me?**
|
||||
|
||||
Our [Code of Conduct](CODE_OF_CONDUCT.md) means that you are responsible for treating everyone on the project with respect and courtesy regardless of their identity. If you are the victim of any inappropriate behavior or comments as described in our Code of Conduct, we are here for you and will do the best to ensure that the abuser is reprimanded appropriately, per our code.
|
||||
|
||||
@ -0,0 +1,68 @@
|
||||
# New Contributor Guide
|
||||
|
||||
If you're a new contributor to InvokeAI or Open Source Projects, this is the guide for you.
|
||||
|
||||
## New Contributor Checklist
|
||||
- [x] Set up your local development environment & fork of InvokAI by following [the steps outlined here](../../installation/020_INSTALL_MANUAL.md#developer-install)
|
||||
- [x] Set up your local tooling with [this guide](InvokeAI/contributing/LOCAL_DEVELOPMENT/#developing-invokeai-in-vscode). Feel free to skip this step if you already have tooling you're comfortable with.
|
||||
- [x] Familiarize yourself with [Git](https://www.atlassian.com/git) & our project structure by reading through the [development documentation](development.md)
|
||||
- [x] Join the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord
|
||||
- [x] Choose an issue to work on! This can be achieved by asking in the #dev-chat channel, tackling a [good first issue](https://github.com/invoke-ai/InvokeAI/contribute) or finding an item on the [roadmap](https://github.com/orgs/invoke-ai/projects/7). If nothing in any of those places catches your eye, feel free to work on something of interest to you!
|
||||
- [x] Make your first Pull Request with the guide below
|
||||
- [x] Happy development! Don't be afraid to ask for help - we're happy to help you contribute!
|
||||
|
||||
|
||||
## How do I make a contribution?
|
||||
|
||||
Never made an open source contribution before? Wondering how contributions work in our project? Here's a quick rundown!
|
||||
|
||||
Before starting these steps, ensure you have your local environment [configured for development](../LOCAL_DEVELOPMENT.md).
|
||||
|
||||
1. Find a [good first issue](https://github.com/invoke-ai/InvokeAI/contribute) that you are interested in addressing or a feature that you would like to add. Then, reach out to our team in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord to ensure you are setup for success.
|
||||
2. Fork the [InvokeAI](https://github.com/invoke-ai/InvokeAI) repository to your GitHub profile. This means that you will have a copy of the repository under **your-GitHub-username/InvokeAI**.
|
||||
3. Clone the repository to your local machine using:
|
||||
```bash
|
||||
git clone https://github.com/your-GitHub-username/InvokeAI.git
|
||||
```
|
||||
If you're unfamiliar with using Git through the commandline, [GitHub Desktop](https://desktop.github.com) is a easy-to-use alternative with a UI. You can do all the same steps listed here, but through the interface.
|
||||
4. Create a new branch for your fix using:
|
||||
```bash
|
||||
git checkout -b branch-name-here
|
||||
```
|
||||
5. Make the appropriate changes for the issue you are trying to address or the feature that you want to add.
|
||||
6. Add the file contents of the changed files to the "snapshot" git uses to manage the state of the project, also known as the index:
|
||||
```bash
|
||||
git add -A
|
||||
```
|
||||
7. Store the contents of the index with a descriptive message.
|
||||
```bash
|
||||
git commit -m "Insert a short message of the changes made here"
|
||||
```
|
||||
8. Push the changes to the remote repository using
|
||||
```bash
|
||||
git push origin branch-name-here
|
||||
```
|
||||
9. Submit a pull request to the **main** branch of the InvokeAI repository. If you're not sure how to, [follow this guide](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request)
|
||||
10. Title the pull request with a short description of the changes made and the issue or bug number associated with your change. For example, you can title an issue like so "Added more log outputting to resolve #1234".
|
||||
11. In the description of the pull request, explain the changes that you made, any issues you think exist with the pull request you made, and any questions you have for the maintainer. It's OK if your pull request is not perfect (no pull request is), the reviewer will be able to help you fix any problems and improve it!
|
||||
12. Wait for the pull request to be reviewed by other collaborators.
|
||||
13. Make changes to the pull request if the reviewer(s) recommend them.
|
||||
14. Celebrate your success after your pull request is merged!
|
||||
|
||||
If you’d like to learn more about contributing to Open Source projects, here is a [Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github).
|
||||
|
||||
|
||||
## Best Practices:
|
||||
* Keep your pull requests small. Smaller pull requests are more likely to be accepted and merged
|
||||
* Comments! Commenting your code helps reviewers easily understand your contribution
|
||||
* Use Python and Typescript’s typing systems, and consider using an editor with [LSP](https://microsoft.github.io/language-server-protocol/) support to streamline development
|
||||
* Make all communications public. This ensure knowledge is shared with the whole community
|
||||
|
||||
|
||||
## **Where can I go for help?**
|
||||
|
||||
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
|
||||
|
||||
For frontend related work, **@pyschedelicious** is the best person to reach out to.
|
||||
|
||||
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
|
||||
@ -21,8 +21,8 @@ TI files that you'll encounter are `.pt` and `.bin` files, which are produced by
|
||||
different TI training packages. InvokeAI supports both formats, but its
|
||||
[built-in TI training system](TRAINING.md) produces `.pt`.
|
||||
|
||||
The [Hugging Face company](https://huggingface.co/sd-concepts-library) has
|
||||
amassed a large ligrary of >800 community-contributed TI files covering a
|
||||
[Hugging Face](https://huggingface.co/sd-concepts-library) has
|
||||
amassed a large library of >800 community-contributed TI files covering a
|
||||
broad range of subjects and styles. You can also install your own or others' TI files
|
||||
by placing them in the designated directory for the compatible model type
|
||||
|
||||
|
||||
@ -159,7 +159,7 @@ groups in `invokeia.yaml`:
|
||||
| `host` | `localhost` | Name or IP address of the network interface that the web server will listen on |
|
||||
| `port` | `9090` | Network port number that the web server will listen on |
|
||||
| `allow_origins` | `[]` | A list of host names or IP addresses that are allowed to connect to the InvokeAI API in the format `['host1','host2',...]` |
|
||||
| `allow_credentials | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_credentials` | `true` | Require credentials for a foreign host to access the InvokeAI API (don't change this) |
|
||||
| `allow_methods` | `*` | List of HTTP methods ("GET", "POST") that the web server is allowed to use when accessing the API |
|
||||
| `allow_headers` | `*` | List of HTTP headers that the web server will accept when accessing the API |
|
||||
|
||||
|
||||
@ -104,7 +104,7 @@ The OpenPose control model allows for the identification of the general pose of
|
||||
|
||||
The MediaPipe Face identification processor is able to clearly identify facial features in order to capture vivid expressions of human faces.
|
||||
|
||||
**Tile (experimental)**:
|
||||
**Tile**:
|
||||
|
||||
The Tile model fills out details in the image to match the image, rather than the prompt. The Tile Model is a versatile tool that offers a range of functionalities. Its primary capabilities can be boiled down to two main behaviors:
|
||||
|
||||
@ -117,8 +117,6 @@ The Tile Model can be a powerful tool in your arsenal for enhancing image qualit
|
||||
|
||||
With Pix2Pix, you can input an image into the controlnet, and then "instruct" the model to change it using your prompt. For example, you can say "Make it winter" to add more wintry elements to a scene.
|
||||
|
||||
**Inpaint**: Coming Soon - Currently this model is available but not functional on the Canvas. An upcoming release will provide additional capabilities for using this model when inpainting.
|
||||
|
||||
Each of these models can be adjusted and combined with other ControlNet models to achieve different results, giving you even more control over your image generation process.
|
||||
|
||||
|
||||
|
||||
@ -2,17 +2,50 @@
|
||||
title: Model Merging
|
||||
---
|
||||
|
||||
# :material-image-off: Model Merging
|
||||
|
||||
## How to Merge Models
|
||||
|
||||
As of version 2.3, InvokeAI comes with a script that allows you to
|
||||
merge two or three diffusers-type models into a new merged model. The
|
||||
InvokeAI provides the ability to merge two or three diffusers-type models into a new merged model. The
|
||||
resulting model will combine characteristics of the original, and can
|
||||
be used to teach an old model new tricks.
|
||||
|
||||
## How to Merge Models
|
||||
|
||||
Model Merging can be be done by navigating to the Model Manager and clicking the "Merge Models" tab. From there, you can select the models and settings you want to use to merge th models.
|
||||
|
||||
## Settings
|
||||
|
||||
* Model Selection: there are three multiple choice fields that
|
||||
display all the diffusers-style models that InvokeAI knows about.
|
||||
If you do not see the model you are looking for, then it is probably
|
||||
a legacy checkpoint model and needs to be converted using the
|
||||
`invoke` command-line client and its `!optimize` command. You
|
||||
must select at least two models to merge. The third can be left at
|
||||
"None" if you desire.
|
||||
|
||||
* Alpha: This is the ratio to use when combining models. It ranges
|
||||
from 0 to 1. The higher the value, the more weight is given to the
|
||||
2d and (optionally) 3d models. So if you have two models named "A"
|
||||
and "B", an alpha value of 0.25 will give you a merged model that is
|
||||
25% A and 75% B.
|
||||
|
||||
* Interpolation Method: This is the method used to combine
|
||||
weights. The options are "weighted_sum" (the default), "sigmoid",
|
||||
"inv_sigmoid" and "add_difference". Each produces slightly different
|
||||
results. When three models are in use, only "add_difference" is
|
||||
available.
|
||||
|
||||
* Save Location: The location you want the merged model to be saved in. Default is in the InvokeAI root folder
|
||||
|
||||
* Name for merged model: This is the name for the new model. Please
|
||||
use InvokeAI conventions - only alphanumeric letters and the
|
||||
characters ".+-".
|
||||
|
||||
* Ignore Mismatches / Force: Not all models are compatible with each other. The merge
|
||||
script will check for compatibility and refuse to merge ones that
|
||||
are incompatible. Set this checkbox to try merging anyway.
|
||||
|
||||
|
||||
|
||||
You may run the merge script by starting the invoke launcher
|
||||
(`invoke.sh` or `invoke.bat`) and choosing the option for _merge
|
||||
(`invoke.sh` or `invoke.bat`) and choosing the option (4) for _merge
|
||||
models_. This will launch a text-based interactive user interface that
|
||||
prompts you to select the models to merge, how to merge them, and the
|
||||
merged model name.
|
||||
@ -40,34 +73,4 @@ this to get back.
|
||||
If the merge runs successfully, it will create a new diffusers model
|
||||
under the selected name and register it with InvokeAI.
|
||||
|
||||
## The Settings
|
||||
|
||||
* Model Selection -- there are three multiple choice fields that
|
||||
display all the diffusers-style models that InvokeAI knows about.
|
||||
If you do not see the model you are looking for, then it is probably
|
||||
a legacy checkpoint model and needs to be converted using the
|
||||
`invoke` command-line client and its `!optimize` command. You
|
||||
must select at least two models to merge. The third can be left at
|
||||
"None" if you desire.
|
||||
|
||||
* Alpha -- This is the ratio to use when combining models. It ranges
|
||||
from 0 to 1. The higher the value, the more weight is given to the
|
||||
2d and (optionally) 3d models. So if you have two models named "A"
|
||||
and "B", an alpha value of 0.25 will give you a merged model that is
|
||||
25% A and 75% B.
|
||||
|
||||
* Interpolation Method -- This is the method used to combine
|
||||
weights. The options are "weighted_sum" (the default), "sigmoid",
|
||||
"inv_sigmoid" and "add_difference". Each produces slightly different
|
||||
results. When three models are in use, only "add_difference" is
|
||||
available. (TODO: cite a reference that describes what these
|
||||
interpolation methods actually do and how to decide among them).
|
||||
|
||||
* Force -- Not all models are compatible with each other. The merge
|
||||
script will check for compatibility and refuse to merge ones that
|
||||
are incompatible. Set this checkbox to try merging anyway.
|
||||
|
||||
* Name for merged model - This is the name for the new model. Please
|
||||
use InvokeAI conventions - only alphanumeric letters and the
|
||||
characters ".+-".
|
||||
|
||||
|
||||
@ -142,7 +142,7 @@ Prompt2prompt `.swap()` is not compatible with xformers, which will be temporari
|
||||
The `prompt2prompt` code is based off
|
||||
[bloc97's colab](https://github.com/bloc97/CrossAttentionControl).
|
||||
|
||||
### Escaping parentheses () and speech marks ""
|
||||
### Escaping parentheses and speech marks
|
||||
|
||||
If the model you are using has parentheses () or speech marks "" as part of its
|
||||
syntax, you will need to "escape" these using a backslash, so that`(my_keyword)`
|
||||
@ -246,7 +246,7 @@ To create a Dynamic Prompt, follow these steps:
|
||||
Within the braces, separate each option using a vertical bar |.
|
||||
If you want to include multiple options from a single group, prefix with the desired number and $$.
|
||||
|
||||
For instance: A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} designed in {2$$style1|style2|style3}.
|
||||
For instance: A {house|apartment|lodge|cottage} in {summer|winter|autumn|spring} designed in {style1|style2|style3}.
|
||||
### How Dynamic Prompts Work
|
||||
|
||||
Once a Dynamic Prompt is configured, the system generates an array of combinations using the options provided. Each group of options in curly braces is treated independently, with the system selecting one option from each group. For a prefixed set (e.g., 2$$), the system will select two distinct options.
|
||||
@ -273,3 +273,36 @@ Below are some useful strategies for creating Dynamic Prompts:
|
||||
Experiment with different quantities for the prefix. For example, 3$$ will select three distinct options.
|
||||
Be aware of coherence in your prompts. Although the system can generate all possible combinations, not all may semantically make sense. Therefore, carefully choose the options for each group.
|
||||
Always review and fine-tune the generated prompts as needed. While Dynamic Prompts can help you generate a multitude of combinations, the final polishing and refining remain in your hands.
|
||||
|
||||
|
||||
## SDXL Prompting
|
||||
|
||||
Prompting with SDXL is slightly different than prompting with SD1.5 or SD2.1 models - SDXL expects a prompt _and_ a style.
|
||||
|
||||
|
||||
### Prompting
|
||||
<figure markdown>
|
||||
|
||||

|
||||
|
||||
</figure>
|
||||
|
||||
In the prompt box, enter a positive or negative prompt as you normally would.
|
||||
|
||||
For the style box you can enter a style that you want the image to be generated in. You can use styles from this example list, or any other style you wish: anime, photographic, digital art, comic book, fantasy art, analog film, neon punk, isometric, low poly, origami, line art, cinematic, 3d model, pixel art, etc.
|
||||
|
||||
|
||||
### Concatenated Prompts
|
||||
|
||||
|
||||
InvokeAI also has the option to concatenate the prompt and style inputs, by pressing the "link" button in the Positive Prompt box.
|
||||
|
||||
This concatenates the prompt & style inputs, and passes the joined prompt and style to the SDXL model.
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -43,27 +43,22 @@ into the directory
|
||||
|
||||
InvokeAI 2.3 and higher comes with a text console-based training front
|
||||
end. From within the `invoke.sh`/`invoke.bat` Invoke launcher script,
|
||||
start the front end by selecting choice (3):
|
||||
start training tool selecting choice (3):
|
||||
|
||||
```sh
|
||||
Do you want to generate images using the
|
||||
1: Browser-based UI
|
||||
2: Command-line interface
|
||||
3: Run textual inversion training
|
||||
4: Merge models (diffusers type only)
|
||||
5: Download and install models
|
||||
6: Change InvokeAI startup options
|
||||
7: Re-run the configure script to fix a broken install
|
||||
8: Open the developer console
|
||||
9: Update InvokeAI
|
||||
10: Command-line help
|
||||
Q: Quit
|
||||
|
||||
Please enter 1-10, Q: [1]
|
||||
1 "Generate images with a browser-based interface"
|
||||
2 "Explore InvokeAI nodes using a command-line interface"
|
||||
3 "Textual inversion training"
|
||||
4 "Merge models (diffusers type only)"
|
||||
5 "Download and install models"
|
||||
6 "Change InvokeAI startup options"
|
||||
7 "Re-run the configure script to fix a broken install or to complete a major upgrade"
|
||||
8 "Open the developer console"
|
||||
9 "Update InvokeAI"
|
||||
```
|
||||
|
||||
From the command line, with the InvokeAI virtual environment active,
|
||||
you can launch the front end with the command `invokeai-ti --gui`.
|
||||
Alternatively, you can select option (8) or from the command line, with the InvokeAI virtual environment active,
|
||||
you can then launch the front end with the command `invokeai-ti --gui`.
|
||||
|
||||
This will launch a text-based front end that will look like this:
|
||||
|
||||
|
||||
336
docs/features/UTILITIES.md
Normal file
@ -0,0 +1,336 @@
|
||||
---
|
||||
title: Command-line Utilities
|
||||
---
|
||||
|
||||
# :material-file-document: Utilities
|
||||
|
||||
# Command-line Utilities
|
||||
|
||||
InvokeAI comes with several scripts that are accessible via the
|
||||
command line. To access these commands, start the "developer's
|
||||
console" from the launcher (`invoke.bat` menu item [8]). Users who are
|
||||
familiar with Python can alternatively activate InvokeAI's virtual
|
||||
environment (typically, but not necessarily `invokeai/.venv`).
|
||||
|
||||
In the developer's console, type the script's name to run it. To get a
|
||||
synopsis of what a utility does and the command-line arguments it
|
||||
accepts, pass it the `-h` argument, e.g.
|
||||
|
||||
```bash
|
||||
invokeai-merge -h
|
||||
```
|
||||
## **invokeai-web**
|
||||
|
||||
This script launches the web server and is effectively identical to
|
||||
selecting option [1] in the launcher. An advantage of launching the
|
||||
server from the command line is that you can override any setting
|
||||
configuration option in `invokeai.yaml` using like-named command-line
|
||||
arguments. For example, to temporarily change the size of the RAM
|
||||
cache to 7 GB, you can launch as follows:
|
||||
|
||||
```bash
|
||||
invokeai-web --ram 7
|
||||
```
|
||||
|
||||
## **invokeai-merge**
|
||||
|
||||
This is the model merge script, the same as launcher option [4]. Call
|
||||
it with the `--gui` command-line argument to start the interactive
|
||||
console-based GUI. Alternatively, you can run it non-interactively
|
||||
using command-line arguments as illustrated in the example below which
|
||||
merges models named `stable-diffusion-1.5` and `inkdiffusion` into a new model named
|
||||
`my_new_model`:
|
||||
|
||||
```bash
|
||||
invokeai-merge --force --base-model sd-1 --models stable-diffusion-1.5 inkdiffusion --merged_model_name my_new_model
|
||||
```
|
||||
|
||||
## **invokeai-ti**
|
||||
|
||||
This is the textual inversion training script that is run by launcher
|
||||
option [3]. Call it with `--gui` to run the interactive console-based
|
||||
front end. It can also be run non-interactively. It has about a
|
||||
zillion arguments, but a typical training session can be launched
|
||||
with:
|
||||
|
||||
```bash
|
||||
invokeai-ti --model stable-diffusion-1.5 \
|
||||
--placeholder_token 'jello' \
|
||||
--learnable_property object \
|
||||
--num_train_epochs 50 \
|
||||
--train_data_dir /path/to/training/images \
|
||||
--output_dir /path/to/trained/model
|
||||
```
|
||||
|
||||
(Note that \\ is the Linux/Mac long-line continuation character. Use ^
|
||||
in Windows).
|
||||
|
||||
## **invokeai-install**
|
||||
|
||||
This is the console-based model install script that is run by launcher
|
||||
option [5]. If called without arguments, it will launch the
|
||||
interactive console-based interface. It can also be used
|
||||
non-interactively to list, add and remove models as shown by these
|
||||
examples:
|
||||
|
||||
* This will download and install three models from CivitAI, HuggingFace,
|
||||
and local disk:
|
||||
|
||||
```bash
|
||||
invokeai-install --add https://civitai.com/api/download/models/161302 ^
|
||||
gsdf/Counterfeit-V3.0 ^
|
||||
D:\Models\merge_model_two.safetensors
|
||||
```
|
||||
(Note that ^ is the Windows long-line continuation character. Use \\ on
|
||||
Linux/Mac).
|
||||
|
||||
* This will list installed models of type `main`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --list-models main
|
||||
```
|
||||
|
||||
* This will delete the models named `voxel-ish` and `realisticVision`:
|
||||
|
||||
```bash
|
||||
invokeai-model-install --delete voxel-ish realisticVision
|
||||
```
|
||||
|
||||
## **invokeai-configure**
|
||||
|
||||
This is the console-based configure script that ran when InvokeAI was
|
||||
first installed. You can run it again at any time to change the
|
||||
configuration, repair a broken install.
|
||||
|
||||
Called without any arguments, `invokeai-configure` enters interactive
|
||||
mode with two screens. The first screen is a form that provides access
|
||||
to most of InvokeAI's configuration options. The second screen lets
|
||||
you download, add, and delete models interactively. When you exit the
|
||||
second screen, the script will add any missing "support models"
|
||||
needed for core functionality, and any selected "sd weights" which are
|
||||
the model checkpoint/diffusers files.
|
||||
|
||||
This behavior can be changed via a series of command-line
|
||||
arguments. Here are some of the useful ones:
|
||||
|
||||
* `invokeai-configure --skip-sd-weights --skip-support-models`
|
||||
This will run just the configuration part of the utility, skipping
|
||||
downloading of support models and stable diffusion weights.
|
||||
|
||||
* `invokeai-configure --yes`
|
||||
This will run the configure script non-interactively. It will set the
|
||||
configuration options to their default values, install/repair support
|
||||
models, and download the "recommended" set of SD models.
|
||||
|
||||
* `invokeai-configure --yes --default_only`
|
||||
This will run the configure script non-interactively. In contrast to
|
||||
the previous command, it will only download the default SD model,
|
||||
Stable Diffusion v1.5
|
||||
|
||||
* `invokeai-configure --yes --default_only --skip-sd-weights`
|
||||
This is similar to the previous command, but will not download any
|
||||
SD models at all. It is usually used to repair a broken install.
|
||||
|
||||
By default, `invokeai-configure` runs on the currently active InvokeAI
|
||||
root folder. To run it against a different root, pass it the `--root
|
||||
</path/to/root>` argument.
|
||||
|
||||
Lastly, you can use `invokeai-configure` to create a working root
|
||||
directory entirely from scratch. Assuming you wish to make a root directory
|
||||
named `InvokeAI-New`, run this command:
|
||||
|
||||
```bash
|
||||
invokeai-configure --root InvokeAI-New --yes --default_only
|
||||
```
|
||||
This will create a minimally functional root directory. You can now
|
||||
launch the web server against it with `invokeai-web --root InvokeAI-New`.
|
||||
|
||||
## **invokeai-update**
|
||||
|
||||
This is the interactive console-based script that is run by launcher
|
||||
menu item [9] to update to a new version of InvokeAI. It takes no
|
||||
command-line arguments.
|
||||
|
||||
## **invokeai-metadata**
|
||||
|
||||
This is a script which takes a list of InvokeAI-generated images and
|
||||
outputs their metadata in the same JSON format that you get from the
|
||||
`</>` button in the Web GUI. For example:
|
||||
|
||||
```bash
|
||||
$ invokeai-metadata ffe2a115-b492-493c-afff-7679aa034b50.png
|
||||
ffe2a115-b492-493c-afff-7679aa034b50.png:
|
||||
{
|
||||
"app_version": "3.1.0",
|
||||
"cfg_scale": 8.0,
|
||||
"clip_skip": 0,
|
||||
"controlnets": [],
|
||||
"generation_mode": "sdxl_txt2img",
|
||||
"height": 1024,
|
||||
"loras": [],
|
||||
"model": {
|
||||
"base_model": "sdxl",
|
||||
"model_name": "stable-diffusion-xl-base-1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"negative_prompt": "",
|
||||
"negative_style_prompt": "",
|
||||
"positive_prompt": "military grade sushi dinner for shock troopers",
|
||||
"positive_style_prompt": "",
|
||||
"rand_device": "cpu",
|
||||
"refiner_cfg_scale": 7.5,
|
||||
"refiner_model": {
|
||||
"base_model": "sdxl-refiner",
|
||||
"model_name": "sd_xl_refiner_1.0",
|
||||
"model_type": "main"
|
||||
},
|
||||
"refiner_negative_aesthetic_score": 2.5,
|
||||
"refiner_positive_aesthetic_score": 6.0,
|
||||
"refiner_scheduler": "euler",
|
||||
"refiner_start": 0.8,
|
||||
"refiner_steps": 20,
|
||||
"scheduler": "euler",
|
||||
"seed": 387129902,
|
||||
"steps": 25,
|
||||
"width": 1024
|
||||
}
|
||||
```
|
||||
|
||||
You may list multiple files on the command line.
|
||||
|
||||
## **invokeai-import-images**
|
||||
|
||||
InvokeAI uses a database to store information about images it
|
||||
generated, and just copying the image files from one InvokeAI root
|
||||
directory to another does not automatically import those images into
|
||||
the destination's gallery. This script allows you to bulk import
|
||||
images generated by one instance of InvokeAI into a gallery maintained
|
||||
by another. It also works on images generated by older versions of
|
||||
InvokeAI, going way back to version 1.
|
||||
|
||||
This script has an interactive mode only. The following example shows
|
||||
it in action:
|
||||
|
||||
```bash
|
||||
$ invokeai-import-images
|
||||
===============================================================================
|
||||
This script will import images generated by earlier versions of
|
||||
InvokeAI into the currently installed root directory:
|
||||
/home/XXXX/invokeai-main
|
||||
If this is not what you want to do, type ctrl-C now to cancel.
|
||||
===============================================================================
|
||||
= Configuration & Settings
|
||||
Found invokeai.yaml file at /home/XXXX/invokeai-main/invokeai.yaml:
|
||||
Database : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs : /home/XXXX/invokeai-main/outputs/images
|
||||
|
||||
Use these paths for import (yes) or choose different ones (no) [Yn]:
|
||||
Inputs: Specify absolute path containing InvokeAI .png images to import: /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Include files from subfolders recursively [yN]?
|
||||
|
||||
Options for board selection for imported images:
|
||||
1) Select an existing board name. (found 4)
|
||||
2) Specify a board name to create/add to.
|
||||
3) Create/add to board named 'IMPORT'.
|
||||
4) Create/add to board named 'IMPORT' with the current datetime string appended (.e.g IMPORT_20230919T203519Z).
|
||||
5) Create/add to board named 'IMPORT' with a the original file app_version appended (.e.g IMPORT_2.2.5).
|
||||
Specify desired board option: 3
|
||||
|
||||
===============================================================================
|
||||
= Import Settings Confirmation
|
||||
|
||||
Database File Path : /home/XXXX/invokeai-main/databases/invokeai.db
|
||||
Outputs/Images Directory : /home/XXXX/invokeai-main/outputs/images
|
||||
Import Image Source Directory : /home/XXXX/invokeai-2.3/outputs/images/
|
||||
Recurse Source SubDirectories : No
|
||||
Count of .png file(s) found : 5785
|
||||
Board name option specified : IMPORT
|
||||
Database backup will be taken at : /home/XXXX/invokeai-main/databases/backup
|
||||
|
||||
Notes about the import process:
|
||||
- Source image files will not be modified, only copied to the outputs directory.
|
||||
- If the same file name already exists in the destination, the file will be skipped.
|
||||
- If the same file name already has a record in the database, the file will be skipped.
|
||||
- Invoke AI metadata tags will be updated/written into the imported copy only.
|
||||
- On the imported copy, only Invoke AI known tags (latest and legacy) will be retained (dream, sd-metadata, invokeai, invokeai_metadata)
|
||||
- A property 'imported_app_version' will be added to metadata that can be viewed in the UI's metadata viewer.
|
||||
- The new 3.x InvokeAI outputs folder structure is flat so recursively found source imges will all be placed into the single outputs/images folder.
|
||||
|
||||
Do you wish to continue with the import [Yn] ?
|
||||
|
||||
Making DB Backup at /home/lstein/invokeai-main/databases/backup/backup-20230919T203519Z-invokeai.db...Done!
|
||||
|
||||
===============================================================================
|
||||
Importing /home/XXXX/invokeai-2.3/outputs/images/17d09907-297d-4db3-a18a-60b337feac66.png
|
||||
... (5785 more lines) ...
|
||||
===============================================================================
|
||||
= Import Complete - Elpased Time: 0.28 second(s)
|
||||
|
||||
Source File(s) : 5785
|
||||
Total Imported : 5783
|
||||
Skipped b/c file already exists on disk : 1
|
||||
Skipped b/c file already exists in db : 0
|
||||
Errors during import : 1
|
||||
```
|
||||
## **invokeai-db-maintenance**
|
||||
|
||||
This script helps maintain the integrity of your InvokeAI database by
|
||||
finding and fixing three problems that can arise over time:
|
||||
|
||||
1. An image was manually deleted from the outputs directory, leaving a
|
||||
dangling image record in the InvokeAI database. This will cause a
|
||||
black image to appear in the gallery. This is an "orphaned database
|
||||
image record." The script can fix this by running a "clean"
|
||||
operation on the database, removing the orphaned entries.
|
||||
|
||||
2. An image is present in the outputs directory but there is no
|
||||
corresponding entry in the database. This can happen when the image
|
||||
is added manually to the outputs directory, or if a crash occurred
|
||||
after the image was generated but before the database was
|
||||
completely updated. The symptom is that the image is present in the
|
||||
outputs folder but doesn't appear in the InvokeAI gallery. This is
|
||||
called an "orphaned image file." The script can fix this problem by
|
||||
running an "archive" operation in which orphaned files are moved
|
||||
into a directory named `outputs/images-archive`. If you wish, you
|
||||
can then run `invokeai-image-import` to reimport these images back
|
||||
into the database.
|
||||
|
||||
3. The thumbnail for an image is missing, again causing a black
|
||||
gallery thumbnail. This is fixed by running the "thumbnaiils"
|
||||
operation, which simply regenerates and re-registers the missing
|
||||
thumbnail.
|
||||
|
||||
You can find and fix all three of these problems in a single go by
|
||||
executing this command:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance --operation all
|
||||
```
|
||||
|
||||
Or you can run just the clean and thumbnail operations like this:
|
||||
|
||||
```bash
|
||||
invokeai-db-maintenance -operation clean, thumbnail
|
||||
```
|
||||
|
||||
If called without any arguments, the script will ask you which
|
||||
operations you wish to perform.
|
||||
|
||||
## **invokeai-migrate3**
|
||||
|
||||
This script will migrate settings and models (but not images!) from an
|
||||
InvokeAI v2.3 root folder to an InvokeAI 3.X folder. Call it with the
|
||||
source and destination root folders like this:
|
||||
|
||||
```bash
|
||||
invokeai-migrate3 --from ~/invokeai-2.3 --to invokeai-3.1.1
|
||||
```
|
||||
|
||||
Both directories must previously have been properly created and
|
||||
initialized by `invokeai-configure`. If you wish to migrate the images
|
||||
contained in the older root as well, you can use the
|
||||
`invokeai-image-migrate` script described earlier.
|
||||
|
||||
---
|
||||
|
||||
Copyright (c) 2023, Lincoln Stein and the InvokeAI Development Team
|
||||
@ -51,6 +51,9 @@ Prevent InvokeAI from displaying unwanted racy images.
|
||||
### * [Controlling Logging](LOGGING.md)
|
||||
Control how InvokeAI logs status messages.
|
||||
|
||||
### * [Command-line Utilities](UTILITIES.md)
|
||||
A list of the command-line utilities available with InvokeAI.
|
||||
|
||||
<!-- OUT OF DATE
|
||||
### * [Miscellaneous](OTHER.md)
|
||||
Run InvokeAI on Google Colab, generate images with repeating patterns,
|
||||
|
||||
@ -15,7 +15,8 @@ title: Home
|
||||
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@fortawesome/fontawesome-free@6.2.1/css/fontawesome.min.css">
|
||||
<style>
|
||||
.button {
|
||||
width: 300px;
|
||||
width: 100%;
|
||||
max-width: 100%;
|
||||
height: 50px;
|
||||
background-color: #448AFF;
|
||||
color: #fff;
|
||||
@ -27,8 +28,9 @@ title: Home
|
||||
|
||||
.button-container {
|
||||
display: grid;
|
||||
grid-template-columns: repeat(3, 300px);
|
||||
grid-template-columns: repeat(auto-fit, minmax(200px, 1fr));
|
||||
gap: 20px;
|
||||
justify-content: center;
|
||||
}
|
||||
|
||||
.button:hover {
|
||||
@ -145,6 +147,7 @@ Mac and Linux machines, and runs on GPU cards with as little as 4 GB of RAM.
|
||||
|
||||
### InvokeAI Configuration
|
||||
- [Guide to InvokeAI Runtime Settings](features/CONFIGURATION.md)
|
||||
- [Database Maintenance and other Command Line Utilities](features/UTILITIES.md)
|
||||
|
||||
## :octicons-log-16: Important Changes Since Version 2.3
|
||||
|
||||
|
||||
@ -287,7 +287,7 @@ manager, please follow these steps:
|
||||
Leave off the `--gui` option to run the script using command-line arguments. Pass the `--help` argument
|
||||
to get usage instructions.
|
||||
|
||||
### Developer Install
|
||||
## Developer Install
|
||||
|
||||
If you have an interest in how InvokeAI works, or you would like to
|
||||
add features or bugfixes, you are encouraged to install the source
|
||||
@ -296,13 +296,14 @@ code for InvokeAI. For this to work, you will need to install the
|
||||
on your system, please see the [Git Installation
|
||||
Guide](https://github.com/git-guides/install-git)
|
||||
|
||||
1. Create a fork of the InvokeAI repository through the GitHub UI or [this link](https://github.com/invoke-ai/InvokeAI/fork)
|
||||
1. From the command line, run this command:
|
||||
```bash
|
||||
git clone https://github.com/invoke-ai/InvokeAI.git
|
||||
git clone https://github.com/<your_github_username>/InvokeAI.git
|
||||
```
|
||||
|
||||
This will create a directory named `InvokeAI` and populate it with the
|
||||
full source code from the InvokeAI repository.
|
||||
full source code from your fork of the InvokeAI repository.
|
||||
|
||||
2. Activate the InvokeAI virtual environment as per step (4) of the manual
|
||||
installation protocol (important!)
|
||||
|
||||
@ -57,6 +57,30 @@ familiar with containerization technologies such as Docker.
|
||||
For downloads and instructions, visit the [NVIDIA CUDA Container
|
||||
Runtime Site](https://developer.nvidia.com/nvidia-container-runtime)
|
||||
|
||||
### cuDNN Installation for 40/30 Series Optimization* (Optional)
|
||||
|
||||
1. Find the InvokeAI folder
|
||||
2. Click on .venv folder - e.g., YourInvokeFolderHere\\.venv
|
||||
3. Click on Lib folder - e.g., YourInvokeFolderHere\\.venv\Lib
|
||||
4. Click on site-packages folder - e.g., YourInvokeFolderHere\\.venv\Lib\site-packages
|
||||
5. Click on Torch directory - e.g., YourInvokeFolderHere\InvokeAI\\.venv\Lib\site-packages\torch
|
||||
6. Click on the lib folder - e.g., YourInvokeFolderHere\\.venv\Lib\site-packages\torch\lib
|
||||
7. Copy everything inside the folder and save it elsewhere as a backup.
|
||||
8. Go to __https://developer.nvidia.com/cudnn__
|
||||
9. Login or create an Account.
|
||||
10. Choose the newer version of cuDNN. **Note:**
|
||||
There are two versions, 11.x or 12.x for the differents architectures(Turing,Maxwell Etc...) of GPUs.
|
||||
You can find which version you should download from [this link](https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html).
|
||||
13. Download the latest version and extract it from the download location
|
||||
14. Find the bin folder E\cudnn-windows-x86_64-__Whatever Version__\bin
|
||||
15. Copy and paste the .dll files into YourInvokeFolderHere\\.venv\Lib\site-packages\torch\lib **Make sure to copy, and not move the files**
|
||||
16. If prompted, replace any existing files
|
||||
|
||||
**Notes:**
|
||||
* If no change is seen or any issues are encountered, follow the same steps as above and paste the torch/lib backup folder you made earlier and replace it. If you didn't make a backup, you can also uninstall and reinstall torch through the command line to repair this folder.
|
||||
* This optimization is intended for the newer version of graphics card (40/30 series) but results have been seen with older graphics card.
|
||||
|
||||
|
||||
### Torch Installation
|
||||
|
||||
When installing torch and torchvision manually with `pip`, remember to provide
|
||||
|
||||
@ -17,14 +17,32 @@ This fork is supported across Linux, Windows and Macintosh. Linux users can use
|
||||
either an Nvidia-based card (with CUDA support) or an AMD card (using the ROCm
|
||||
driver).
|
||||
|
||||
### [Installation Getting Started Guide](installation)
|
||||
#### **[Automated Installer](010_INSTALL_AUTOMATED.md)**
|
||||
|
||||
## **[Automated Installer](010_INSTALL_AUTOMATED.md)**
|
||||
✅ This is the recommended installation method for first-time users.
|
||||
#### [Manual Installation](020_INSTALL_MANUAL.md)
|
||||
This method is recommended for experienced users and developers
|
||||
#### [Docker Installation](040_INSTALL_DOCKER.md)
|
||||
This method is recommended for those familiar with running Docker containers
|
||||
### Other Installation Guides
|
||||
|
||||
This is a script that will install all of InvokeAI's essential
|
||||
third party libraries and InvokeAI itself. It includes access to a
|
||||
"developer console" which will help us debug problems with you and
|
||||
give you to access experimental features.
|
||||
|
||||
## **[Manual Installation](020_INSTALL_MANUAL.md)**
|
||||
This method is recommended for experienced users and developers.
|
||||
|
||||
In this method you will manually run the commands needed to install
|
||||
InvokeAI and its dependencies. We offer two recipes: one suited to
|
||||
those who prefer the `conda` tool, and one suited to those who prefer
|
||||
`pip` and Python virtual environments. In our hands the pip install
|
||||
is faster and more reliable, but your mileage may vary.
|
||||
Note that the conda installation method is currently deprecated and
|
||||
will not be supported at some point in the future.
|
||||
|
||||
## **[Docker Installation](040_INSTALL_DOCKER.md)**
|
||||
This method is recommended for those familiar with running Docker containers.
|
||||
|
||||
We offer a method for creating Docker containers containing InvokeAI and its dependencies. This method is recommended for individuals with experience with Docker containers and understand the pluses and minuses of a container-based install.
|
||||
|
||||
## Other Installation Guides
|
||||
- [PyPatchMatch](060_INSTALL_PATCHMATCH.md)
|
||||
- [XFormers](070_INSTALL_XFORMERS.md)
|
||||
- [CUDA and ROCm Drivers](030_INSTALL_CUDA_AND_ROCM.md)
|
||||
@ -63,43 +81,3 @@ images in full-precision mode:
|
||||
- GTX 1650 series cards
|
||||
- GTX 1660 series cards
|
||||
|
||||
## Installation options
|
||||
|
||||
1. [Automated Installer](010_INSTALL_AUTOMATED.md)
|
||||
|
||||
This is a script that will install all of InvokeAI's essential
|
||||
third party libraries and InvokeAI itself. It includes access to a
|
||||
"developer console" which will help us debug problems with you and
|
||||
give you to access experimental features.
|
||||
|
||||
|
||||
✅ This is the recommended option for first time users.
|
||||
|
||||
2. [Manual Installation](020_INSTALL_MANUAL.md)
|
||||
|
||||
In this method you will manually run the commands needed to install
|
||||
InvokeAI and its dependencies. We offer two recipes: one suited to
|
||||
those who prefer the `conda` tool, and one suited to those who prefer
|
||||
`pip` and Python virtual environments. In our hands the pip install
|
||||
is faster and more reliable, but your mileage may vary.
|
||||
Note that the conda installation method is currently deprecated and
|
||||
will not be supported at some point in the future.
|
||||
|
||||
This method is recommended for users who have previously used `conda`
|
||||
or `pip` in the past, developers, and anyone who wishes to remain on
|
||||
the cutting edge of future InvokeAI development and is willing to put
|
||||
up with occasional glitches and breakage.
|
||||
|
||||
3. [Docker Installation](040_INSTALL_DOCKER.md)
|
||||
|
||||
We also offer a method for creating Docker containers containing
|
||||
InvokeAI and its dependencies. This method is recommended for
|
||||
individuals with experience with Docker containers and understand
|
||||
the pluses and minuses of a container-based install.
|
||||
|
||||
## Quick Guides
|
||||
|
||||
* [Installing CUDA and ROCm Drivers](./030_INSTALL_CUDA_AND_ROCM.md)
|
||||
* [Installing XFormers](./070_INSTALL_XFORMERS.md)
|
||||
* [Installing PyPatchMatch](./060_INSTALL_PATCHMATCH.md)
|
||||
* [Installing New Models](./050_INSTALLING_MODELS.md)
|
||||
|
||||
@ -1,13 +1,32 @@
|
||||
# Using the Node Editor
|
||||
# Using the Workflow Editor
|
||||
|
||||
The nodes editor is a blank canvas allowing for the use of individual functions and image transformations to control the image generation workflow. Nodes take in inputs on the left side of the node, and return an output on the right side of the node. A node graph is composed of multiple nodes that are connected together to create a workflow. Nodes' inputs and outputs are connected by dragging connectors from node to node. Inputs and outputs are color coded for ease of use.
|
||||
The workflow editor is a blank canvas allowing for the use of individual functions and image transformations to control the image generation workflow. Nodes take in inputs on the left side of the node, and return an output on the right side of the node. A node graph is composed of multiple nodes that are connected together to create a workflow. Nodes' inputs and outputs are connected by dragging connectors from node to node. Inputs and outputs are color coded for ease of use.
|
||||
|
||||
To better understand how nodes are used, think of how an electric power bar works. It takes in one input (electricity from a wall outlet) and passes it to multiple devices through multiple outputs. Similarly, a node could have multiple inputs and outputs functioning at the same (or different) time, but all node outputs pass information onward like a power bar passes electricity. Not all outputs are compatible with all inputs, however - Each node has different constraints on how it is expecting to input/output information. In general, node outputs are colour-coded to match compatible inputs of other nodes.
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Workflow Editor and build workflows to suit your needs.
|
||||
|
||||
## UI Features
|
||||
|
||||
### Linear View
|
||||
The Workflow Editor allows you to create a UI for your workflow, to make it easier to iterate on your generations.
|
||||
|
||||
To add an input to the Linear UI, right click on the input and select "Add to Linear View".
|
||||
|
||||
The Linear UI View will also be part of the saved workflow, allowing you share workflows and enable other to use them, regardless of complexity.
|
||||
|
||||

|
||||
|
||||
### Renaming Fields and Nodes
|
||||
Any node or input field can be renamed in the workflow editor. If the input field you have renamed has been added to the Linear View, the changed name will be reflected in the Linear View and the node.
|
||||
|
||||
### Managing Nodes
|
||||
|
||||
* Ctrl+C to copy a node
|
||||
* Ctrl+V to paste a node
|
||||
* Backspace/Delete to delete a node
|
||||
* Shift+Click to drag and select multiple nodes
|
||||
|
||||
|
||||
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Nodes Editor and build workflows to suit your needs.
|
||||
|
||||
## Important Concepts
|
||||
## Important Concepts
|
||||
|
||||
There are several node grouping concepts that can be examined with a narrow focus. These (and other) groupings can be pieced together to make up functional graph setups, and are important to understanding how groups of nodes work together as part of a whole. Note that the screenshots below aren't examples of complete functioning node graphs (see Examples).
|
||||
|
||||
@ -37,7 +56,7 @@ It is common to want to use both the same seed (for continuity) and random seeds
|
||||
|
||||
### ControlNet
|
||||
|
||||
The ControlNet node outputs a Control, which can be provided as input to non-image *ToLatents nodes. Depending on the type of ControlNet desired, ControlNet nodes usually require an image processor node, such as a Canny Processor or Depth Processor, which prepares an input image for use with ControlNet.
|
||||
The ControlNet node outputs a Control, which can be provided as input to a Denoise Latents node. Depending on the type of ControlNet desired, ControlNet nodes usually require an image processor node, such as a Canny Processor or Depth Processor, which prepares an input image for use with ControlNet.
|
||||
|
||||

|
||||
|
||||
@ -59,10 +78,9 @@ Iteration is a common concept in any processing, and means to repeat a process w
|
||||
|
||||

|
||||
|
||||
### Multiple Image Generation + Random Seeds
|
||||
### Batch / Multiple Image Generation + Random Seeds
|
||||
|
||||
Multiple image generation in the node editor is done using the RandomRange node. In this case, the 'Size' field represents the number of images to generate. As RandomRange produces a collection of integers, we need to add the Iterate node to iterate through the collection.
|
||||
|
||||
To control seeds across generations takes some care. The first row in the screenshot will generate multiple images with different seeds, but using the same RandomRange parameters across invocations will result in the same group of random seeds being used across the images, producing repeatable results. In the second row, adding the RandomInt node as input to RandomRange's 'Seed' edge point will ensure that seeds are varied across all images across invocations, producing varied results.
|
||||
Batch or multiple image generation in the workflow editor is done using the RandomRange node. In this case, the 'Size' field represents the number of images to generate, meaning this example will generate 4 images. As RandomRange produces a collection of integers, we need to add the Iterate node to iterate through the collection. This noise can then be fed to the Denoise Latents node for it to iterate through the denoising process with the different seeds provided.
|
||||
|
||||

|
||||
|
||||
|
||||
@ -4,9 +4,9 @@ These are nodes that have been developed by the community, for the community. If
|
||||
|
||||
If you'd like to submit a node for the community, please refer to the [node creation overview](contributingNodes.md).
|
||||
|
||||
To download a node, simply download the `.py` node file from the link and add it to the `invokeai/app/invocations` folder in your Invoke AI install location. Along with the node, an example node graph should be provided to help you get started with the node.
|
||||
To download a node, simply download the `.py` node file from the link and add it to the `invokeai/app/invocations` folder in your Invoke AI install location. If you used the automated installation, this can be found inside the `.venv` folder. Along with the node, an example node graph should be provided to help you get started with the node.
|
||||
|
||||
To use a community node graph, download the the `.json` node graph file and load it into Invoke AI via the **Load Nodes** button on the Node Editor.
|
||||
To use a community workflow, download the the `.json` node graph file and load it into Invoke AI via the **Load Workflow** button in the Workflow Editor.
|
||||
|
||||
## Community Nodes
|
||||
|
||||
@ -22,16 +22,28 @@ To use a community node graph, download the the `.json` node graph file and load
|
||||

|
||||

|
||||
|
||||
<hr>
|
||||
|
||||
--------------------------------
|
||||
### Ideal Size
|
||||
|
||||
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/ideal-size-node
|
||||
|
||||
<hr>
|
||||
--------------------------------
|
||||
### Film Grain
|
||||
|
||||
**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/film-grain-node
|
||||
|
||||
--------------------------------
|
||||
### Image Picker
|
||||
|
||||
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
|
||||
|
||||
**Node Link:** https://github.com/JPPhoto/image-picker-node
|
||||
|
||||
--------------------------------
|
||||
### Retroize
|
||||
|
||||
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
|
||||
@ -55,9 +67,169 @@ Generated Prompt: An enchanted weapon will be usable by any character regardless
|
||||
|
||||

|
||||
|
||||
--------------------------------
|
||||
### Load Video Frame
|
||||
|
||||
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such for invokeAI node experimentation. Think animation + ControlNet outputs.
|
||||
|
||||
**Node Link:** https://github.com/helix4u/load_video_frame
|
||||
|
||||
**Example Node Graph:** https://github.com/helix4u/load_video_frame/blob/main/Example_Workflow.json
|
||||
|
||||
**Output Example:**
|
||||
=======
|
||||

|
||||
[Full mp4 of Example Output test.mp4](https://github.com/helix4u/load_video_frame/blob/main/test.mp4)
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Oobabooga
|
||||
|
||||
**Description:** asks a local LLM running in Oobabooga's Text-Generation-Webui to write a prompt based on the user input.
|
||||
|
||||
**Link:** https://github.com/sammyf/oobabooga-node
|
||||
|
||||
|
||||
**Example:**
|
||||
|
||||
"describe a new mystical creature in its natural environment"
|
||||
|
||||
*can return*
|
||||
|
||||
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
|
||||
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
|
||||
|
||||

|
||||
|
||||
**Requirement**
|
||||
|
||||
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
|
||||
|
||||
**Note**
|
||||
|
||||
This node works best with SDXL models, especially as the style can be described independantly of the LLM's output.
|
||||
|
||||
--------------------------------
|
||||
### Depth Map from Wavefront OBJ
|
||||
|
||||
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
|
||||
|
||||
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/depth-from-obj-node
|
||||
|
||||
**Example Usage:**
|
||||
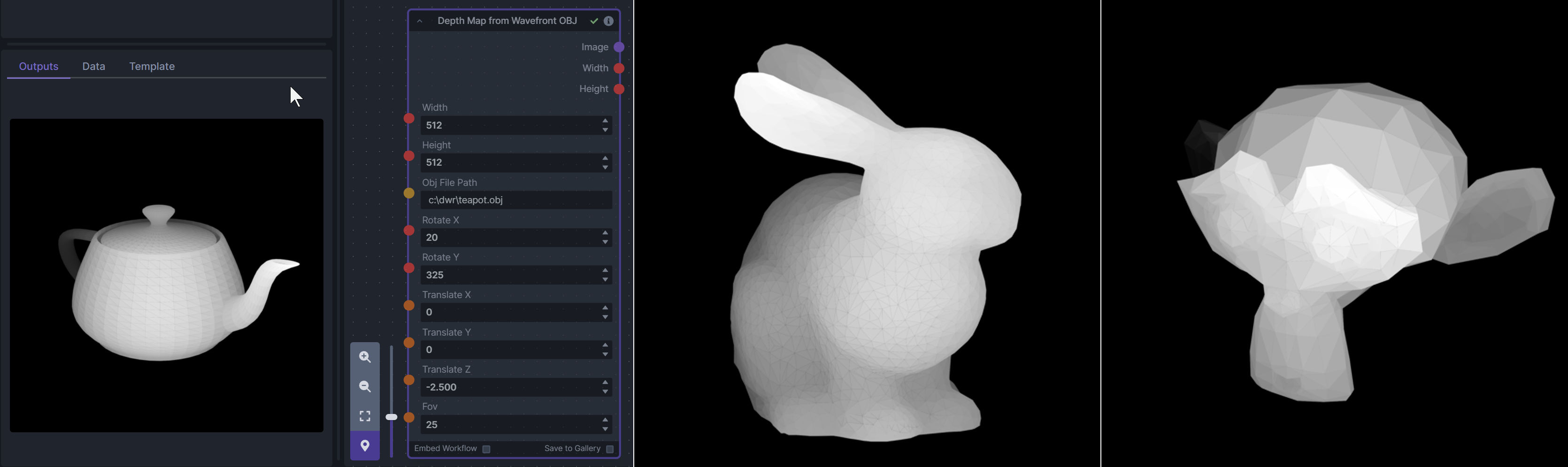
|
||||
|
||||
--------------------------------
|
||||
### Enhance Image (simple adjustments)
|
||||
|
||||
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
|
||||
|
||||
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/image-enhance-node
|
||||
|
||||
**Example Usage:**
|
||||
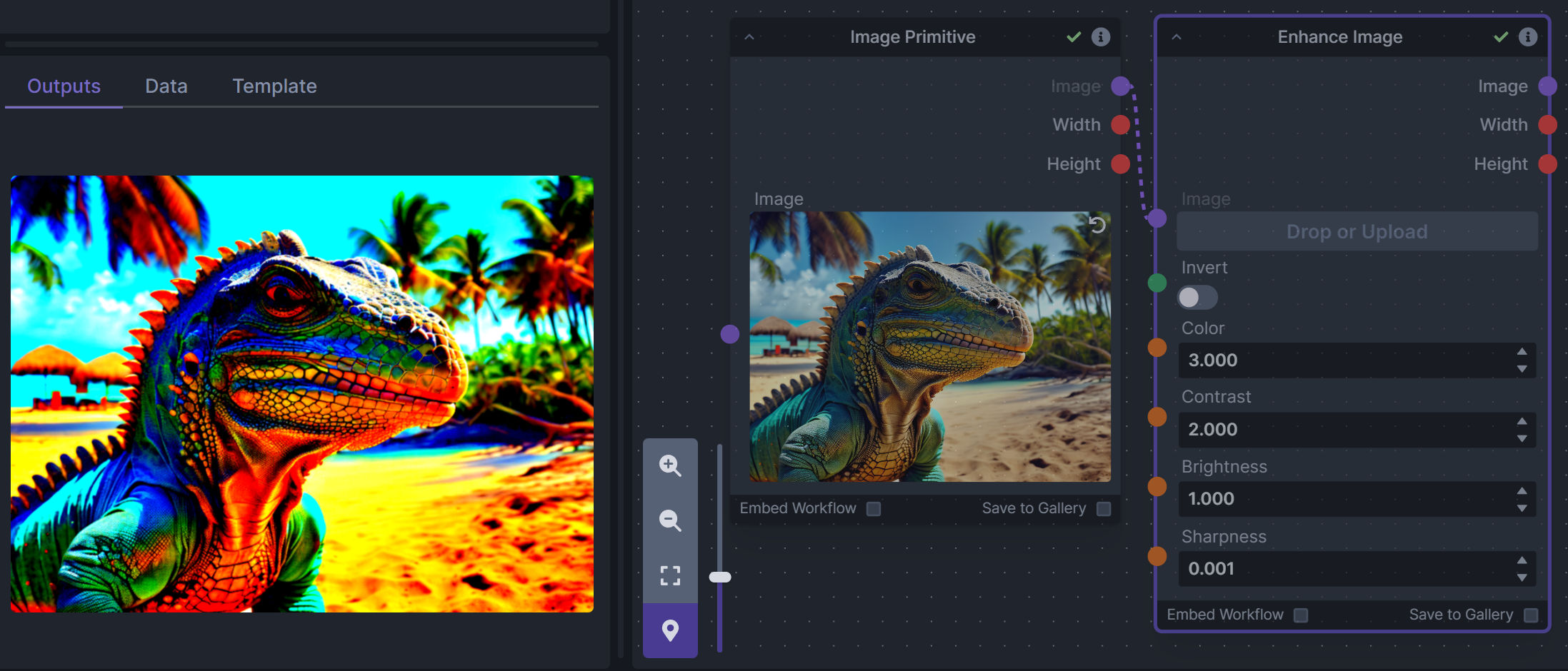
|
||||
|
||||
--------------------------------
|
||||
### Generative Grammar-Based Prompt Nodes
|
||||
|
||||
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no more nonterminal terms remain in the string.
|
||||
|
||||
This includes 3 Nodes:
|
||||
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
|
||||
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
|
||||
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/generative-grammar-prompt-nodes
|
||||
|
||||
**Example Usage:**
|
||||
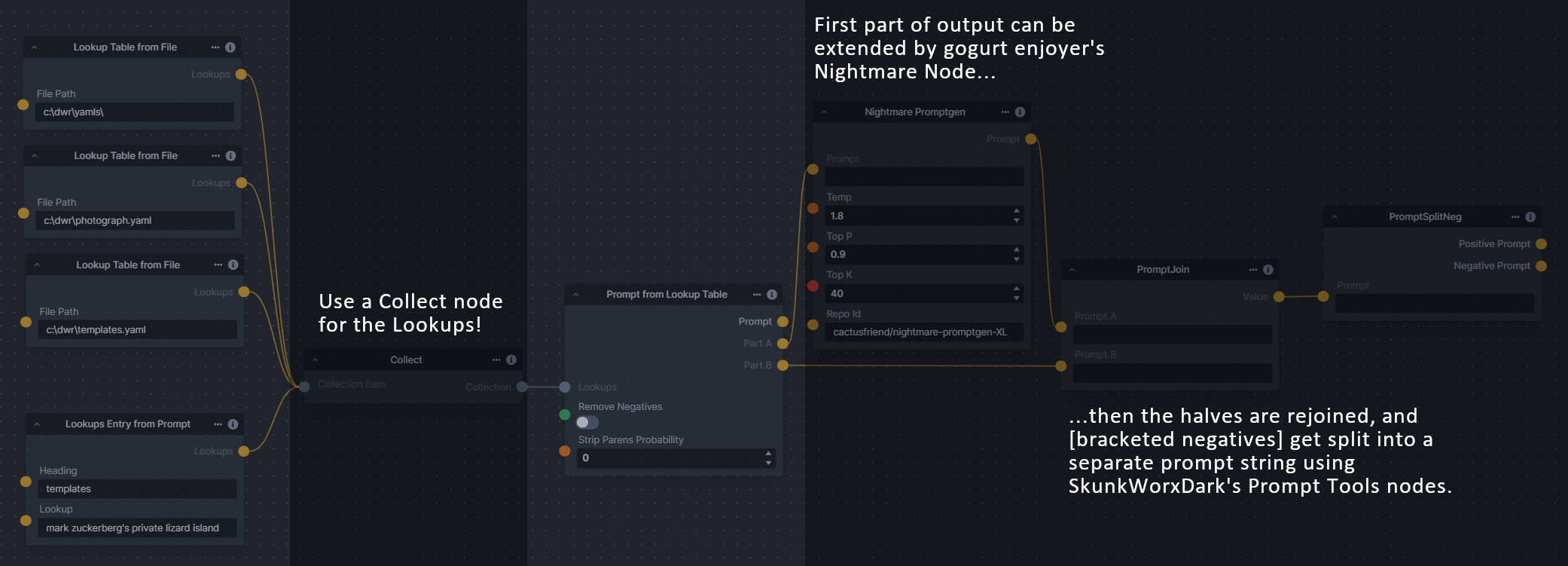
|
||||
|
||||
--------------------------------
|
||||
### Image and Mask Composition Pack
|
||||
|
||||
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
|
||||
|
||||
This includes 4 Nodes:
|
||||
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
|
||||
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
|
||||
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/composition-nodes
|
||||
|
||||
**Example Usage:**
|
||||
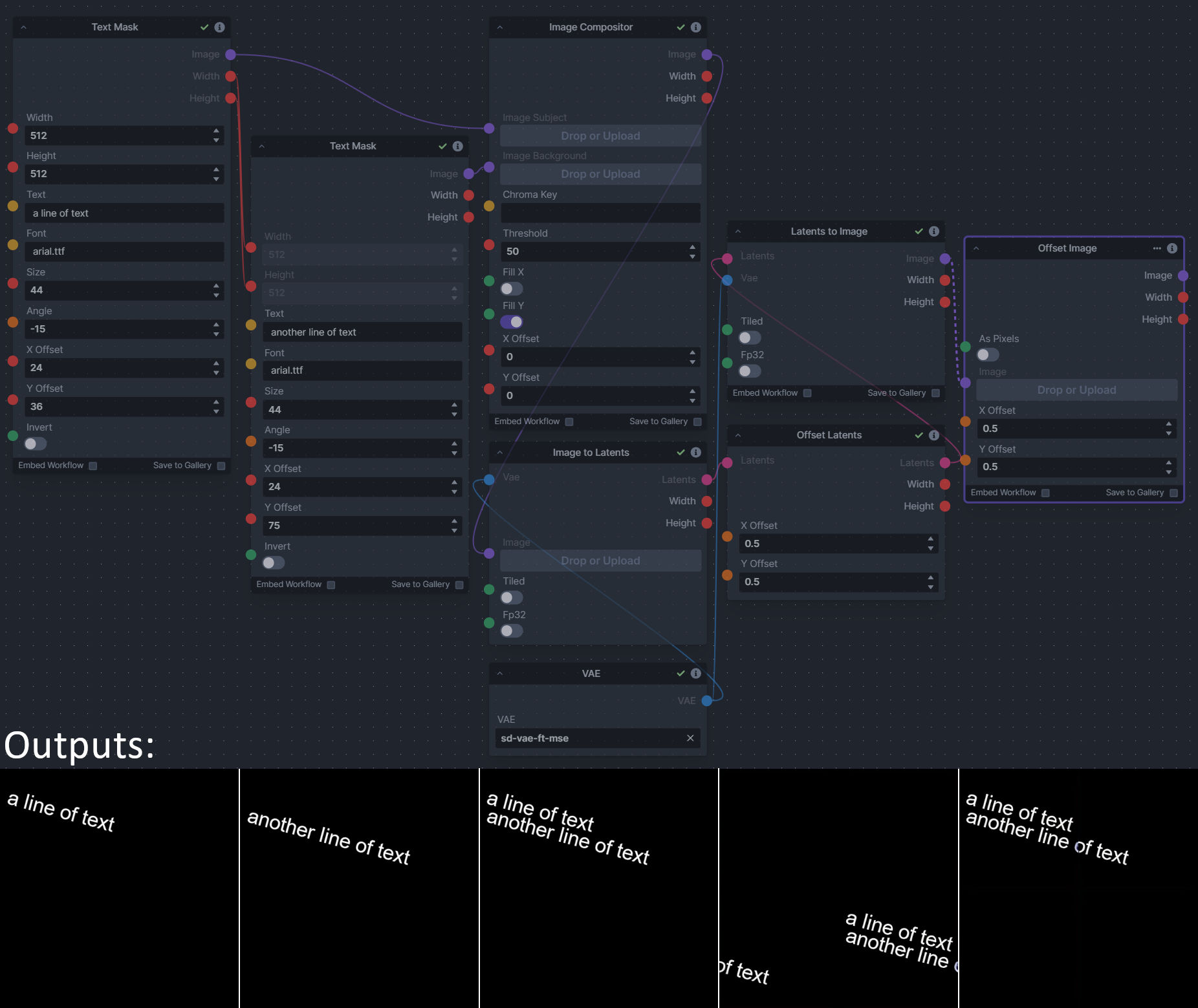
|
||||
|
||||
--------------------------------
|
||||
### Size Stepper Nodes
|
||||
|
||||
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
|
||||
|
||||
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
|
||||
|
||||
**Node Link:** https://github.com/dwringer/size-stepper-nodes
|
||||
|
||||
**Example Usage:**
|
||||
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Text font to Image
|
||||
|
||||
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
|
||||
|
||||
**Node Link:** https://github.com/mickr777/textfontimage
|
||||
|
||||
**Output Examples**
|
||||
|
||||

|
||||
|
||||
Results after using the depth controlnet
|
||||
|
||||

|
||||

|
||||

|
||||
|
||||
--------------------------------
|
||||
|
||||
### Prompt Tools
|
||||
|
||||
**Description:** A set of InvokeAI nodes that add general prompt manipulation tools. These where written to accompany the PromptsFromFile node and other prompt generation nodes.
|
||||
|
||||
1. PromptJoin - Joins to prompts into one.
|
||||
2. PromptReplace - performs a search and replace on a prompt. With the option of using regex.
|
||||
3. PromptSplitNeg - splits a prompt into positive and negative using the old V2 method of [] for negative.
|
||||
4. PromptToFile - saves a prompt or collection of prompts to a file. one per line. There is an append/overwrite option.
|
||||
5. PTFieldsCollect - Converts image generation fields into a Json format string that can be passed to Prompt to file.
|
||||
6. PTFieldsExpand - Takes Json string and converts it to individual generation parameters This can be fed from the Prompts to file node.
|
||||
7. PromptJoinThree - Joins 3 prompt together.
|
||||
8. PromptStrength - This take a string and float and outputs another string in the format of (string)strength like the weighted format of compel.
|
||||
9. PromptStrengthCombine - This takes a collection of prompt strength strings and outputs a string in the .and() or .blend() format that can be fed into a proper prompt node.
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/Prompt-tools-nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/Prompt-tools-nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### XY Image to Grid and Images to Grids nodes
|
||||
|
||||
**Description:** Image to grid nodes and supporting tools.
|
||||
|
||||
1. "Images To Grids" node - Takes a collection of images and creates a grid(s) of images. If there are more images than the size of a single grid then mutilple grids will be created until it runs out of images.
|
||||
2. "XYImage To Grid" node - Converts a collection of XYImages into a labeled Grid of images. The XYImages collection has to be built using the supporoting nodes. See example node setups for more details.
|
||||
|
||||
|
||||
See full docs here: https://github.com/skunkworxdark/XYGrid_nodes/edit/main/README.md
|
||||
|
||||
**Node Link:** https://github.com/skunkworxdark/XYGrid_nodes
|
||||
|
||||
--------------------------------
|
||||
|
||||
### Example Node Template
|
||||
|
||||
**Description:** This node allows you to do super cool things with InvokeAI.
|
||||
|
||||
@ -4,10 +4,10 @@ To learn about the specifics of creating a new node, please visit our [Node crea
|
||||
|
||||
Once you’ve created a node and confirmed that it behaves as expected locally, follow these steps:
|
||||
|
||||
- Make sure the node is contained in a new Python (.py) file
|
||||
- Submit a pull request with a link to your node in GitHub against the `nodes` branch to add the node to the [Community Nodes](Community Nodes) list
|
||||
- Make sure you are following the template below and have provided all relevant details about the node and what it does.
|
||||
- A maintainer will review the pull request and node. If the node is aligned with the direction of the project, you might be asked for permission to include it in the core project.
|
||||
- Make sure the node is contained in a new Python (.py) file. Preferrably, the node is in a repo with a README detaling the nodes usage & examples to help others more easily use your node.
|
||||
- Submit a pull request with a link to your node(s) repo in GitHub against the `main` branch to add the node to the [Community Nodes](communityNodes.md) list
|
||||
- Make sure you are following the template below and have provided all relevant details about the node and what it does. Example output images and workflows are very helpful for other users looking to use your node.
|
||||
- A maintainer will review the pull request and node. If the node is aligned with the direction of the project, you may be asked for permission to include it in the core project.
|
||||
|
||||
### Community Node Template
|
||||
|
||||
|
||||
@ -22,6 +22,7 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Divide Integers | Divides two numbers|
|
||||
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|
||||
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|
||||
|Float Math | Perform basic math operations on two floats|
|
||||
|Float Primitive Collection | A collection of float primitive values|
|
||||
|Float Primitive | A float primitive value|
|
||||
|Float Range | Creates a range|
|
||||
@ -29,19 +30,22 @@ The table below contains a list of the default nodes shipped with InvokeAI and t
|
||||
|Blur Image | Blurs an image|
|
||||
|Extract Image Channel | Gets a channel from an image.|
|
||||
|Image Primitive Collection | A collection of image primitive values|
|
||||
|Integer Math | Perform basic math operations on two integers|
|
||||
|Convert Image Mode | Converts an image to a different mode.|
|
||||
|Crop Image | Crops an image to a specified box. The box can be outside of the image.|
|
||||
|Image Hue Adjustment | Adjusts the Hue of an image.|
|
||||
|Inverse Lerp Image | Inverse linear interpolation of all pixels of an image|
|
||||
|Image Primitive | An image primitive value|
|
||||
|Lerp Image | Linear interpolation of all pixels of an image|
|
||||
|Image Luminosity Adjustment | Adjusts the Luminosity (Value) of an image.|
|
||||
|Offset Image Channel | Add to or subtract from an image color channel by a uniform value.|
|
||||
|Multiply Image Channel | Multiply or Invert an image color channel by a scalar value.|
|
||||
|Multiply Images | Multiplies two images together using `PIL.ImageChops.multiply()`.|
|
||||
|Blur NSFW Image | Add blur to NSFW-flagged images|
|
||||
|Paste Image | Pastes an image into another image.|
|
||||
|ImageProcessor | Base class for invocations that preprocess images for ControlNet|
|
||||
|Resize Image | Resizes an image to specific dimensions|
|
||||
|Image Saturation Adjustment | Adjusts the Saturation of an image.|
|
||||
|Round Float | Rounds a float to a specified number of decimal places|
|
||||
|Float to Integer | Converts a float to an integer. Optionally rounds to an even multiple of a input number.|
|
||||
|Scale Image | Scales an image by a factor|
|
||||
|Image to Latents | Encodes an image into latents.|
|
||||
|Add Invisible Watermark | Add an invisible watermark to an image|
|
||||
|
||||
@ -1,15 +1,13 @@
|
||||
# Example Workflows
|
||||
|
||||
TODO: Will update once uploading workflows is available.
|
||||
We've curated some example workflows for you to get started with Workflows in InvokeAI
|
||||
|
||||
## Text2Image
|
||||
To use them, right click on your desired workflow, press "Download Linked File". You can then use the "Load Workflow" functionality in InvokeAI to load the workflow and start generating images!
|
||||
|
||||
## Image2Image
|
||||
If you're interested in finding more workflows, checkout the [#share-your-workflows](https://discord.com/channels/1020123559063990373/1130291608097661000) channel in the InvokeAI Discord.
|
||||
|
||||
## ControlNet
|
||||
* [SD1.5 / SD2 Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/Text_to_Image.json)
|
||||
* [SDXL Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [SDXL (with Refiner) Text to Image](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/SDXL_Text_to_Image.json)
|
||||
* [Tiled Upscaling with ControlNet](https://github.com/invoke-ai/InvokeAI/blob/main/docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json)ß
|
||||
|
||||
## Upscaling
|
||||
|
||||
## Inpainting / Outpainting
|
||||
|
||||
## LoRAs
|
||||
|
||||
1010
docs/workflows/ESRGAN_img2img_upscale w_Canny_ControlNet.json
Normal file
735
docs/workflows/SDXL_Text_to_Image.json
Normal file
@ -0,0 +1,735 @@
|
||||
{
|
||||
"name": "SDXL Text to Image",
|
||||
"author": "InvokeAI",
|
||||
"description": "Sample text to image workflow for SDXL",
|
||||
"version": "1.0.1",
|
||||
"contact": "invoke@invoke.ai",
|
||||
"tags": "text2image, SDXL, default",
|
||||
"notes": "",
|
||||
"exposedFields": [
|
||||
{
|
||||
"nodeId": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"fieldName": "model"
|
||||
},
|
||||
{
|
||||
"nodeId": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"fieldName": "prompt"
|
||||
},
|
||||
{
|
||||
"nodeId": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"fieldName": "style"
|
||||
},
|
||||
{
|
||||
"nodeId": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"fieldName": "prompt"
|
||||
},
|
||||
{
|
||||
"nodeId": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"fieldName": "style"
|
||||
},
|
||||
{
|
||||
"nodeId": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"fieldName": "steps"
|
||||
}
|
||||
],
|
||||
"meta": {
|
||||
"version": "1.0.0"
|
||||
},
|
||||
"nodes": [
|
||||
{
|
||||
"id": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"type": "sdxl_compel_prompt",
|
||||
"inputs": {
|
||||
"prompt": {
|
||||
"id": "5a6889e6-95cb-462f-8f4a-6b93ae7afaec",
|
||||
"name": "prompt",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Negative Prompt",
|
||||
"value": ""
|
||||
},
|
||||
"style": {
|
||||
"id": "f240d0e6-3a1c-4320-af23-20ebb707c276",
|
||||
"name": "style",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Negative Style",
|
||||
"value": ""
|
||||
},
|
||||
"original_width": {
|
||||
"id": "05af07b0-99a0-4a68-8ad2-697bbdb7fc7e",
|
||||
"name": "original_width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"original_height": {
|
||||
"id": "2c771996-a998-43b7-9dd3-3792664d4e5b",
|
||||
"name": "original_height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"crop_top": {
|
||||
"id": "66519dca-a151-4e3e-ae1f-88f1f9877bde",
|
||||
"name": "crop_top",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"crop_left": {
|
||||
"id": "349cf2e9-f3d0-4e16-9ae2-7097d25b6a51",
|
||||
"name": "crop_left",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"target_width": {
|
||||
"id": "44499347-7bd6-4a73-99d6-5a982786db05",
|
||||
"name": "target_width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"target_height": {
|
||||
"id": "fda359b0-ab80-4f3c-805b-c9f61319d7d2",
|
||||
"name": "target_height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"clip": {
|
||||
"id": "b447adaf-a649-4a76-a827-046a9fc8d89b",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"clip2": {
|
||||
"id": "86ee4e32-08f9-4baa-9163-31d93f5c0187",
|
||||
"name": "clip2",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"conditioning": {
|
||||
"id": "7c10118e-7b4e-4911-b98e-d3ba6347dfd0",
|
||||
"name": "conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "SDXL Negative Compel Prompt",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 764,
|
||||
"position": {
|
||||
"x": 1275,
|
||||
"y": -350
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"type": "noise",
|
||||
"inputs": {
|
||||
"seed": {
|
||||
"id": "6431737c-918a-425d-a3b4-5d57e2f35d4d",
|
||||
"name": "seed",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"width": {
|
||||
"id": "38fc5b66-fe6e-47c8-bba9-daf58e454ed7",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"height": {
|
||||
"id": "16298330-e2bf-4872-a514-d6923df53cbb",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"use_cpu": {
|
||||
"id": "c7c436d3-7a7a-4e76-91e4-c6deb271623c",
|
||||
"name": "use_cpu",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": true
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"noise": {
|
||||
"id": "50f650dc-0184-4e23-a927-0497a96fe954",
|
||||
"name": "noise",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "bb8a452b-133d-42d1-ae4a-3843d7e4109a",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "35cfaa12-3b8b-4b7a-a884-327ff3abddd9",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": false,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 32,
|
||||
"position": {
|
||||
"x": 1650,
|
||||
"y": -300
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"type": "l2i",
|
||||
"inputs": {
|
||||
"tiled": {
|
||||
"id": "24f5bc7b-f6a1-425d-8ab1-f50b4db5d0df",
|
||||
"name": "tiled",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": false
|
||||
},
|
||||
"fp32": {
|
||||
"id": "b146d873-ffb9-4767-986a-5360504841a2",
|
||||
"name": "fp32",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": true
|
||||
},
|
||||
"latents": {
|
||||
"id": "65441abd-7713-4b00-9d8d-3771404002e8",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"vae": {
|
||||
"id": "a478b833-6e13-4611-9a10-842c89603c74",
|
||||
"name": "vae",
|
||||
"type": "VaeField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"image": {
|
||||
"id": "c87ae925-f858-417a-8940-8708ba9b4b53",
|
||||
"name": "image",
|
||||
"type": "ImageField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "4bcb8512-b5a1-45f1-9e52-6e92849f9d6c",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "23e41c00-a354-48e8-8f59-5875679c27ab",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": true,
|
||||
"isIntermediate": false
|
||||
},
|
||||
"width": 320,
|
||||
"height": 224,
|
||||
"position": {
|
||||
"x": 2025,
|
||||
"y": -250
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"type": "rand_int",
|
||||
"inputs": {
|
||||
"low": {
|
||||
"id": "3ec65a37-60ba-4b6c-a0b2-553dd7a84b84",
|
||||
"name": "low",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"high": {
|
||||
"id": "085f853a-1a5f-494d-8bec-e4ba29a3f2d1",
|
||||
"name": "high",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 2147483647
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"value": {
|
||||
"id": "812ade4d-7699-4261-b9fc-a6c9d2ab55ee",
|
||||
"name": "value",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "Random Seed",
|
||||
"isOpen": false,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 32,
|
||||
"position": {
|
||||
"x": 1650,
|
||||
"y": -350
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"type": "sdxl_model_loader",
|
||||
"inputs": {
|
||||
"model": {
|
||||
"id": "39f9e799-bc95-4318-a200-30eed9e60c42",
|
||||
"name": "model",
|
||||
"type": "SDXLMainModelField",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": {
|
||||
"model_name": "stable-diffusion-xl-base-1.0",
|
||||
"base_model": "sdxl",
|
||||
"model_type": "main"
|
||||
}
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"unet": {
|
||||
"id": "2626a45e-59aa-4609-b131-2d45c5eaed69",
|
||||
"name": "unet",
|
||||
"type": "UNetField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"clip": {
|
||||
"id": "7c9c42fa-93d5-4639-ab8b-c4d9b0559baf",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"clip2": {
|
||||
"id": "0dafddcf-a472-49c1-a47c-7b8fab4c8bc9",
|
||||
"name": "clip2",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"vae": {
|
||||
"id": "ee6a6997-1b3c-4ff3-99ce-1e7bfba2750c",
|
||||
"name": "vae",
|
||||
"type": "VaeField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 234,
|
||||
"position": {
|
||||
"x": 475,
|
||||
"y": 25
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"type": "sdxl_compel_prompt",
|
||||
"inputs": {
|
||||
"prompt": {
|
||||
"id": "5a6889e6-95cb-462f-8f4a-6b93ae7afaec",
|
||||
"name": "prompt",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Positive Prompt",
|
||||
"value": ""
|
||||
},
|
||||
"style": {
|
||||
"id": "f240d0e6-3a1c-4320-af23-20ebb707c276",
|
||||
"name": "style",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Positive Style",
|
||||
"value": ""
|
||||
},
|
||||
"original_width": {
|
||||
"id": "05af07b0-99a0-4a68-8ad2-697bbdb7fc7e",
|
||||
"name": "original_width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"original_height": {
|
||||
"id": "2c771996-a998-43b7-9dd3-3792664d4e5b",
|
||||
"name": "original_height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"crop_top": {
|
||||
"id": "66519dca-a151-4e3e-ae1f-88f1f9877bde",
|
||||
"name": "crop_top",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"crop_left": {
|
||||
"id": "349cf2e9-f3d0-4e16-9ae2-7097d25b6a51",
|
||||
"name": "crop_left",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"target_width": {
|
||||
"id": "44499347-7bd6-4a73-99d6-5a982786db05",
|
||||
"name": "target_width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"target_height": {
|
||||
"id": "fda359b0-ab80-4f3c-805b-c9f61319d7d2",
|
||||
"name": "target_height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1024
|
||||
},
|
||||
"clip": {
|
||||
"id": "b447adaf-a649-4a76-a827-046a9fc8d89b",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"clip2": {
|
||||
"id": "86ee4e32-08f9-4baa-9163-31d93f5c0187",
|
||||
"name": "clip2",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"conditioning": {
|
||||
"id": "7c10118e-7b4e-4911-b98e-d3ba6347dfd0",
|
||||
"name": "conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "SDXL Positive Compel Prompt",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 764,
|
||||
"position": {
|
||||
"x": 900,
|
||||
"y": -350
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"type": "denoise_latents",
|
||||
"inputs": {
|
||||
"noise": {
|
||||
"id": "4884a4b7-cc19-4fea-83c7-1f940e6edd24",
|
||||
"name": "noise",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"steps": {
|
||||
"id": "4c61675c-b6b9-41ac-b187-b5c13b587039",
|
||||
"name": "steps",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 36
|
||||
},
|
||||
"cfg_scale": {
|
||||
"id": "f8213f35-4637-4a1a-83f4-1f8cfb9ccd2c",
|
||||
"name": "cfg_scale",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 7.5
|
||||
},
|
||||
"denoising_start": {
|
||||
"id": "01e2f30d-0acd-4e21-98b9-a9b8e24c6db2",
|
||||
"name": "denoising_start",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"denoising_end": {
|
||||
"id": "3db95479-a73b-4c75-9b44-08daec16b224",
|
||||
"name": "denoising_end",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1
|
||||
},
|
||||
"scheduler": {
|
||||
"id": "db8430a9-64c3-4c54-ae38-9f597cf7b6d5",
|
||||
"name": "scheduler",
|
||||
"type": "Scheduler",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": "euler"
|
||||
},
|
||||
"control": {
|
||||
"id": "599b49e8-6435-4576-be41-a5155f3a17e3",
|
||||
"name": "control",
|
||||
"type": "ControlField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"latents": {
|
||||
"id": "226f9e91-454e-4159-9fa6-019c0cf29277",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"denoise_mask": {
|
||||
"id": "de019cb6-7fb5-45bf-a266-22e20889893f",
|
||||
"name": "denoise_mask",
|
||||
"type": "DenoiseMaskField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"positive_conditioning": {
|
||||
"id": "02fc400a-110d-470e-8411-f404f966a949",
|
||||
"name": "positive_conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"negative_conditioning": {
|
||||
"id": "4bd3bdfa-fcf4-42be-8e47-1e314255798f",
|
||||
"name": "negative_conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"unet": {
|
||||
"id": "7c2d58a8-b5f1-4e63-8ffd-8ada52c35832",
|
||||
"name": "unet",
|
||||
"type": "UNetField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"latents": {
|
||||
"id": "6a6fa492-de26-4e95-b1d9-a322fe37eb13",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "a9790729-7d6c-4418-903d-4da961fccf56",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "fa74efe5-7330-4a3c-b256-c82a544585b4",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 558,
|
||||
"position": {
|
||||
"x": 1650,
|
||||
"y": -250
|
||||
}
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"source": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"target": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"id": "ea94bc37-d995-4a83-aa99-4af42479f2f2-55705012-79b9-4aac-9f26-c0b10309785b-collapsed",
|
||||
"type": "collapsed"
|
||||
},
|
||||
{
|
||||
"source": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"sourceHandle": "value",
|
||||
"target": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"targetHandle": "seed",
|
||||
"id": "reactflow__edge-ea94bc37-d995-4a83-aa99-4af42479f2f2value-55705012-79b9-4aac-9f26-c0b10309785bseed",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "clip",
|
||||
"target": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"targetHandle": "clip",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22clip-faf965a4-7530-427b-b1f3-4ba6505c2a08clip",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "clip2",
|
||||
"target": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"targetHandle": "clip2",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22clip2-faf965a4-7530-427b-b1f3-4ba6505c2a08clip2",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "clip",
|
||||
"target": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"targetHandle": "clip",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22clip-3193ad09-a7c2-4bf4-a3a9-1c61cc33a204clip",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "clip2",
|
||||
"target": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"targetHandle": "clip2",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22clip2-3193ad09-a7c2-4bf4-a3a9-1c61cc33a204clip2",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "vae",
|
||||
"target": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"targetHandle": "vae",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22vae-dbcd2f98-d809-48c8-bf64-2635f88a2fe9vae",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"sourceHandle": "latents",
|
||||
"target": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"targetHandle": "latents",
|
||||
"id": "reactflow__edge-87ee6243-fb0d-4f77-ad5f-56591659339elatents-dbcd2f98-d809-48c8-bf64-2635f88a2fe9latents",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "faf965a4-7530-427b-b1f3-4ba6505c2a08",
|
||||
"sourceHandle": "conditioning",
|
||||
"target": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"targetHandle": "positive_conditioning",
|
||||
"id": "reactflow__edge-faf965a4-7530-427b-b1f3-4ba6505c2a08conditioning-87ee6243-fb0d-4f77-ad5f-56591659339epositive_conditioning",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "3193ad09-a7c2-4bf4-a3a9-1c61cc33a204",
|
||||
"sourceHandle": "conditioning",
|
||||
"target": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"targetHandle": "negative_conditioning",
|
||||
"id": "reactflow__edge-3193ad09-a7c2-4bf4-a3a9-1c61cc33a204conditioning-87ee6243-fb0d-4f77-ad5f-56591659339enegative_conditioning",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "30d3289c-773c-4152-a9d2-bd8a99c8fd22",
|
||||
"sourceHandle": "unet",
|
||||
"target": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"targetHandle": "unet",
|
||||
"id": "reactflow__edge-30d3289c-773c-4152-a9d2-bd8a99c8fd22unet-87ee6243-fb0d-4f77-ad5f-56591659339eunet",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"sourceHandle": "noise",
|
||||
"target": "87ee6243-fb0d-4f77-ad5f-56591659339e",
|
||||
"targetHandle": "noise",
|
||||
"id": "reactflow__edge-55705012-79b9-4aac-9f26-c0b10309785bnoise-87ee6243-fb0d-4f77-ad5f-56591659339enoise",
|
||||
"type": "default"
|
||||
}
|
||||
]
|
||||
}
|
||||
1404
docs/workflows/SDXL_w_Refiner_Text_to_Image.json
Normal file
573
docs/workflows/Text_to_Image.json
Normal file
@ -0,0 +1,573 @@
|
||||
{
|
||||
"name": "Text to Image",
|
||||
"author": "InvokeAI",
|
||||
"description": "Sample text to image workflow for Stable Diffusion 1.5/2",
|
||||
"version": "1.0.1",
|
||||
"contact": "invoke@invoke.ai",
|
||||
"tags": "text2image, SD1.5, SD2, default",
|
||||
"notes": "",
|
||||
"exposedFields": [
|
||||
{
|
||||
"nodeId": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"fieldName": "model"
|
||||
},
|
||||
{
|
||||
"nodeId": "7d8bf987-284f-413a-b2fd-d825445a5d6c",
|
||||
"fieldName": "prompt"
|
||||
},
|
||||
{
|
||||
"nodeId": "93dc02a4-d05b-48ed-b99c-c9b616af3402",
|
||||
"fieldName": "prompt"
|
||||
},
|
||||
{
|
||||
"nodeId": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"fieldName": "steps"
|
||||
}
|
||||
],
|
||||
"meta": {
|
||||
"version": "1.0.0"
|
||||
},
|
||||
"nodes": [
|
||||
{
|
||||
"id": "93dc02a4-d05b-48ed-b99c-c9b616af3402",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "93dc02a4-d05b-48ed-b99c-c9b616af3402",
|
||||
"type": "compel",
|
||||
"inputs": {
|
||||
"prompt": {
|
||||
"id": "7739aff6-26cb-4016-8897-5a1fb2305e4e",
|
||||
"name": "prompt",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Negative Prompt",
|
||||
"value": ""
|
||||
},
|
||||
"clip": {
|
||||
"id": "48d23dce-a6ae-472a-9f8c-22a714ea5ce0",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"conditioning": {
|
||||
"id": "37cf3a9d-f6b7-4b64-8ff6-2558c5ecc447",
|
||||
"name": "conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "Negative Compel Prompt",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 235,
|
||||
"position": {
|
||||
"x": 1400,
|
||||
"y": -75
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"type": "noise",
|
||||
"inputs": {
|
||||
"seed": {
|
||||
"id": "6431737c-918a-425d-a3b4-5d57e2f35d4d",
|
||||
"name": "seed",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"width": {
|
||||
"id": "38fc5b66-fe6e-47c8-bba9-daf58e454ed7",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 512
|
||||
},
|
||||
"height": {
|
||||
"id": "16298330-e2bf-4872-a514-d6923df53cbb",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 512
|
||||
},
|
||||
"use_cpu": {
|
||||
"id": "c7c436d3-7a7a-4e76-91e4-c6deb271623c",
|
||||
"name": "use_cpu",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": true
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"noise": {
|
||||
"id": "50f650dc-0184-4e23-a927-0497a96fe954",
|
||||
"name": "noise",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "bb8a452b-133d-42d1-ae4a-3843d7e4109a",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "35cfaa12-3b8b-4b7a-a884-327ff3abddd9",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 364,
|
||||
"position": {
|
||||
"x": 1000,
|
||||
"y": 350
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"type": "l2i",
|
||||
"inputs": {
|
||||
"tiled": {
|
||||
"id": "24f5bc7b-f6a1-425d-8ab1-f50b4db5d0df",
|
||||
"name": "tiled",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": false
|
||||
},
|
||||
"fp32": {
|
||||
"id": "b146d873-ffb9-4767-986a-5360504841a2",
|
||||
"name": "fp32",
|
||||
"type": "boolean",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": false
|
||||
},
|
||||
"latents": {
|
||||
"id": "65441abd-7713-4b00-9d8d-3771404002e8",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"vae": {
|
||||
"id": "a478b833-6e13-4611-9a10-842c89603c74",
|
||||
"name": "vae",
|
||||
"type": "VaeField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"image": {
|
||||
"id": "c87ae925-f858-417a-8940-8708ba9b4b53",
|
||||
"name": "image",
|
||||
"type": "ImageField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "4bcb8512-b5a1-45f1-9e52-6e92849f9d6c",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "23e41c00-a354-48e8-8f59-5875679c27ab",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": true,
|
||||
"isIntermediate": false
|
||||
},
|
||||
"width": 320,
|
||||
"height": 266,
|
||||
"position": {
|
||||
"x": 1800,
|
||||
"y": 200
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"type": "main_model_loader",
|
||||
"inputs": {
|
||||
"model": {
|
||||
"id": "993eabd2-40fd-44fe-bce7-5d0c7075ddab",
|
||||
"name": "model",
|
||||
"type": "MainModelField",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": {
|
||||
"model_name": "stable-diffusion-v1-5",
|
||||
"base_model": "sd-1",
|
||||
"model_type": "main"
|
||||
}
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"unet": {
|
||||
"id": "5c18c9db-328d-46d0-8cb9-143391c410be",
|
||||
"name": "unet",
|
||||
"type": "UNetField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"clip": {
|
||||
"id": "6effcac0-ec2f-4bf5-a49e-a2c29cf921f4",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"vae": {
|
||||
"id": "57683ba3-f5f5-4f58-b9a2-4b83dacad4a1",
|
||||
"name": "vae",
|
||||
"type": "VaeField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": false,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 32,
|
||||
"position": {
|
||||
"x": 1000,
|
||||
"y": 200
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "7d8bf987-284f-413a-b2fd-d825445a5d6c",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "7d8bf987-284f-413a-b2fd-d825445a5d6c",
|
||||
"type": "compel",
|
||||
"inputs": {
|
||||
"prompt": {
|
||||
"id": "7739aff6-26cb-4016-8897-5a1fb2305e4e",
|
||||
"name": "prompt",
|
||||
"type": "string",
|
||||
"fieldKind": "input",
|
||||
"label": "Positive Prompt",
|
||||
"value": ""
|
||||
},
|
||||
"clip": {
|
||||
"id": "48d23dce-a6ae-472a-9f8c-22a714ea5ce0",
|
||||
"name": "clip",
|
||||
"type": "ClipField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"conditioning": {
|
||||
"id": "37cf3a9d-f6b7-4b64-8ff6-2558c5ecc447",
|
||||
"name": "conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "Positive Compel Prompt",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 235,
|
||||
"position": {
|
||||
"x": 1000,
|
||||
"y": -75
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"type": "rand_int",
|
||||
"inputs": {
|
||||
"low": {
|
||||
"id": "3ec65a37-60ba-4b6c-a0b2-553dd7a84b84",
|
||||
"name": "low",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"high": {
|
||||
"id": "085f853a-1a5f-494d-8bec-e4ba29a3f2d1",
|
||||
"name": "high",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 2147483647
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"value": {
|
||||
"id": "812ade4d-7699-4261-b9fc-a6c9d2ab55ee",
|
||||
"name": "value",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "Random Seed",
|
||||
"isOpen": false,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 32,
|
||||
"position": {
|
||||
"x": 1000,
|
||||
"y": 275
|
||||
}
|
||||
},
|
||||
{
|
||||
"id": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"type": "invocation",
|
||||
"data": {
|
||||
"version": "1.0.0",
|
||||
"id": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"type": "denoise_latents",
|
||||
"inputs": {
|
||||
"noise": {
|
||||
"id": "8b18f3eb-40d2-45c1-9a9d-28d6af0dce2b",
|
||||
"name": "noise",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"steps": {
|
||||
"id": "0be4373c-46f3-441c-80a7-a4bb6ceb498c",
|
||||
"name": "steps",
|
||||
"type": "integer",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 36
|
||||
},
|
||||
"cfg_scale": {
|
||||
"id": "107267ce-4666-4cd7-94b3-7476b7973ae9",
|
||||
"name": "cfg_scale",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 7.5
|
||||
},
|
||||
"denoising_start": {
|
||||
"id": "d2ce9f0f-5fc2-48b2-b917-53442941e9a1",
|
||||
"name": "denoising_start",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 0
|
||||
},
|
||||
"denoising_end": {
|
||||
"id": "8ad51505-b8d0-422a-beb8-96fc6fc6b65f",
|
||||
"name": "denoising_end",
|
||||
"type": "float",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": 1
|
||||
},
|
||||
"scheduler": {
|
||||
"id": "53092874-a43b-4623-91a2-76e62fdb1f2e",
|
||||
"name": "scheduler",
|
||||
"type": "Scheduler",
|
||||
"fieldKind": "input",
|
||||
"label": "",
|
||||
"value": "euler"
|
||||
},
|
||||
"control": {
|
||||
"id": "7abe57cc-469d-437e-ad72-a18efa28215f",
|
||||
"name": "control",
|
||||
"type": "ControlField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"latents": {
|
||||
"id": "add8bbe5-14d0-42d4-a867-9c65ab8dd129",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"denoise_mask": {
|
||||
"id": "f373a190-0fc8-45b7-ae62-c4aa8e9687e1",
|
||||
"name": "denoise_mask",
|
||||
"type": "DenoiseMaskField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"positive_conditioning": {
|
||||
"id": "c7160303-8a23-4f15-9197-855d48802a7f",
|
||||
"name": "positive_conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"negative_conditioning": {
|
||||
"id": "fd750efa-1dfc-4d0b-accb-828e905ba320",
|
||||
"name": "negative_conditioning",
|
||||
"type": "ConditioningField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
},
|
||||
"unet": {
|
||||
"id": "af1f41ba-ce2a-4314-8d7f-494bb5800381",
|
||||
"name": "unet",
|
||||
"type": "UNetField",
|
||||
"fieldKind": "input",
|
||||
"label": ""
|
||||
}
|
||||
},
|
||||
"outputs": {
|
||||
"latents": {
|
||||
"id": "8508d04d-f999-4a44-94d0-388ab1401d27",
|
||||
"name": "latents",
|
||||
"type": "LatentsField",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"width": {
|
||||
"id": "93dc8287-0a2a-4320-83a4-5e994b7ba23e",
|
||||
"name": "width",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
},
|
||||
"height": {
|
||||
"id": "d9862f5c-0ab5-46fa-8c29-5059bb581d96",
|
||||
"name": "height",
|
||||
"type": "integer",
|
||||
"fieldKind": "output"
|
||||
}
|
||||
},
|
||||
"label": "",
|
||||
"isOpen": true,
|
||||
"notes": "",
|
||||
"embedWorkflow": false,
|
||||
"isIntermediate": true
|
||||
},
|
||||
"width": 320,
|
||||
"height": 558,
|
||||
"position": {
|
||||
"x": 1400,
|
||||
"y": 200
|
||||
}
|
||||
}
|
||||
],
|
||||
"edges": [
|
||||
{
|
||||
"source": "ea94bc37-d995-4a83-aa99-4af42479f2f2",
|
||||
"sourceHandle": "value",
|
||||
"target": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"targetHandle": "seed",
|
||||
"id": "reactflow__edge-ea94bc37-d995-4a83-aa99-4af42479f2f2value-55705012-79b9-4aac-9f26-c0b10309785bseed",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"sourceHandle": "clip",
|
||||
"target": "7d8bf987-284f-413a-b2fd-d825445a5d6c",
|
||||
"targetHandle": "clip",
|
||||
"id": "reactflow__edge-c8d55139-f380-4695-b7f2-8b3d1e1e3db8clip-7d8bf987-284f-413a-b2fd-d825445a5d6cclip",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"sourceHandle": "clip",
|
||||
"target": "93dc02a4-d05b-48ed-b99c-c9b616af3402",
|
||||
"targetHandle": "clip",
|
||||
"id": "reactflow__edge-c8d55139-f380-4695-b7f2-8b3d1e1e3db8clip-93dc02a4-d05b-48ed-b99c-c9b616af3402clip",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"sourceHandle": "vae",
|
||||
"target": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"targetHandle": "vae",
|
||||
"id": "reactflow__edge-c8d55139-f380-4695-b7f2-8b3d1e1e3db8vae-dbcd2f98-d809-48c8-bf64-2635f88a2fe9vae",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"sourceHandle": "latents",
|
||||
"target": "dbcd2f98-d809-48c8-bf64-2635f88a2fe9",
|
||||
"targetHandle": "latents",
|
||||
"id": "reactflow__edge-75899702-fa44-46d2-b2d5-3e17f234c3e7latents-dbcd2f98-d809-48c8-bf64-2635f88a2fe9latents",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "7d8bf987-284f-413a-b2fd-d825445a5d6c",
|
||||
"sourceHandle": "conditioning",
|
||||
"target": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"targetHandle": "positive_conditioning",
|
||||
"id": "reactflow__edge-7d8bf987-284f-413a-b2fd-d825445a5d6cconditioning-75899702-fa44-46d2-b2d5-3e17f234c3e7positive_conditioning",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "93dc02a4-d05b-48ed-b99c-c9b616af3402",
|
||||
"sourceHandle": "conditioning",
|
||||
"target": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"targetHandle": "negative_conditioning",
|
||||
"id": "reactflow__edge-93dc02a4-d05b-48ed-b99c-c9b616af3402conditioning-75899702-fa44-46d2-b2d5-3e17f234c3e7negative_conditioning",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "c8d55139-f380-4695-b7f2-8b3d1e1e3db8",
|
||||
"sourceHandle": "unet",
|
||||
"target": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"targetHandle": "unet",
|
||||
"id": "reactflow__edge-c8d55139-f380-4695-b7f2-8b3d1e1e3db8unet-75899702-fa44-46d2-b2d5-3e17f234c3e7unet",
|
||||
"type": "default"
|
||||
},
|
||||
{
|
||||
"source": "55705012-79b9-4aac-9f26-c0b10309785b",
|
||||
"sourceHandle": "noise",
|
||||
"target": "75899702-fa44-46d2-b2d5-3e17f234c3e7",
|
||||
"targetHandle": "noise",
|
||||
"id": "reactflow__edge-55705012-79b9-4aac-9f26-c0b10309785bnoise-75899702-fa44-46d2-b2d5-3e17f234c3e7noise",
|
||||
"type": "default"
|
||||
}
|
||||
]
|
||||
}
|
||||
@ -14,7 +14,7 @@ fi
|
||||
VERSION=$(cd ..; python -c "from invokeai.version import __version__ as version; print(version)")
|
||||
PATCH=""
|
||||
VERSION="v${VERSION}${PATCH}"
|
||||
LATEST_TAG="v3.0-latest"
|
||||
LATEST_TAG="v3-latest"
|
||||
|
||||
echo Building installer for version $VERSION
|
||||
echo "Be certain that you're in the 'installer' directory before continuing."
|
||||
@ -46,6 +46,7 @@ if [[ $(python -c 'from importlib.util import find_spec; print(find_spec("build"
|
||||
pip install --user build
|
||||
fi
|
||||
|
||||
rm -r ../build
|
||||
python -m build --wheel --outdir dist/ ../.
|
||||
|
||||
# ----------------------
|
||||
|
||||
@ -5,6 +5,7 @@ InvokeAI Installer
|
||||
import argparse
|
||||
import os
|
||||
from pathlib import Path
|
||||
|
||||
from installer import Installer
|
||||
|
||||
if __name__ == "__main__":
|
||||
|
||||
@ -17,9 +17,10 @@ echo 6. Change InvokeAI startup options
|
||||
echo 7. Re-run the configure script to fix a broken install or to complete a major upgrade
|
||||
echo 8. Open the developer console
|
||||
echo 9. Update InvokeAI
|
||||
echo 10. Command-line help
|
||||
echo 10. Run the InvokeAI image database maintenance script
|
||||
echo 11. Command-line help
|
||||
echo Q - Quit
|
||||
set /P choice="Please enter 1-10, Q: [1] "
|
||||
set /P choice="Please enter 1-11, Q: [1] "
|
||||
if not defined choice set choice=1
|
||||
IF /I "%choice%" == "1" (
|
||||
echo Starting the InvokeAI browser-based UI..
|
||||
@ -58,8 +59,11 @@ IF /I "%choice%" == "1" (
|
||||
echo Running invokeai-update...
|
||||
python -m invokeai.frontend.install.invokeai_update
|
||||
) ELSE IF /I "%choice%" == "10" (
|
||||
echo Running the db maintenance script...
|
||||
python .venv\Scripts\invokeai-db-maintenance.exe
|
||||
) ELSE IF /I "%choice%" == "11" (
|
||||
echo Displaying command line help...
|
||||
python .venv\Scripts\invokeai.exe --help %*
|
||||
python .venv\Scripts\invokeai-web.exe --help %*
|
||||
pause
|
||||
exit /b
|
||||
) ELSE IF /I "%choice%" == "q" (
|
||||
|
||||
@ -97,13 +97,13 @@ do_choice() {
|
||||
;;
|
||||
10)
|
||||
clear
|
||||
printf "Command-line help\n"
|
||||
invokeai --help
|
||||
printf "Running the db maintenance script\n"
|
||||
invokeai-db-maintenance --root ${INVOKEAI_ROOT}
|
||||
;;
|
||||
"HELP 1")
|
||||
11)
|
||||
clear
|
||||
printf "Command-line help\n"
|
||||
invokeai --help
|
||||
invokeai-web --help
|
||||
;;
|
||||
*)
|
||||
clear
|
||||
@ -125,7 +125,10 @@ do_dialog() {
|
||||
6 "Change InvokeAI startup options"
|
||||
7 "Re-run the configure script to fix a broken install or to complete a major upgrade"
|
||||
8 "Open the developer console"
|
||||
9 "Update InvokeAI")
|
||||
9 "Update InvokeAI"
|
||||
10 "Run the InvokeAI image database maintenance script"
|
||||
11 "Command-line help"
|
||||
)
|
||||
|
||||
choice=$(dialog --clear \
|
||||
--backtitle "\Zb\Zu\Z3InvokeAI" \
|
||||
@ -157,9 +160,10 @@ do_line_input() {
|
||||
printf "7: Re-run the configure script to fix a broken install\n"
|
||||
printf "8: Open the developer console\n"
|
||||
printf "9: Update InvokeAI\n"
|
||||
printf "10: Command-line help\n"
|
||||
printf "10: Run the InvokeAI image database maintenance script\n"
|
||||
printf "11: Command-line help\n"
|
||||
printf "Q: Quit\n\n"
|
||||
read -p "Please enter 1-10, Q: [1] " yn
|
||||
read -p "Please enter 1-11, Q: [1] " yn
|
||||
choice=${yn:='1'}
|
||||
do_choice $choice
|
||||
clear
|
||||
|
||||
@ -1,34 +1,35 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
import sqlite3
|
||||
from logging import Logger
|
||||
from invokeai.app.services.board_image_record_storage import (
|
||||
SqliteBoardImageRecordStorage,
|
||||
)
|
||||
from invokeai.app.services.board_images import (
|
||||
BoardImagesService,
|
||||
BoardImagesServiceDependencies,
|
||||
)
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import SqliteBoardImageRecordStorage
|
||||
from invokeai.app.services.board_images import BoardImagesService, BoardImagesServiceDependencies
|
||||
from invokeai.app.services.board_record_storage import SqliteBoardRecordStorage
|
||||
from invokeai.app.services.boards import BoardService, BoardServiceDependencies
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.image_record_storage import SqliteImageRecordStorage
|
||||
from invokeai.app.services.images import ImageService, ImageServiceDependencies
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_memory import MemoryInvocationCache
|
||||
from invokeai.app.services.resource_name import SimpleNameService
|
||||
from invokeai.app.services.session_processor.session_processor_default import DefaultSessionProcessor
|
||||
from invokeai.app.services.session_queue.session_queue_sqlite import SqliteSessionQueue
|
||||
from invokeai.app.services.urls import LocalUrlService
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
from ..services.default_graphs import create_system_graphs
|
||||
from ..services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from ..services.graph import GraphExecutionState, LibraryGraph
|
||||
from ..services.image_file_storage import DiskImageFileStorage
|
||||
from ..services.invocation_queue import MemoryInvocationQueue
|
||||
from ..services.invocation_services import InvocationServices
|
||||
from ..services.invocation_stats import InvocationStatsService
|
||||
from ..services.invoker import Invoker
|
||||
from ..services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from ..services.model_manager_service import ModelManagerService
|
||||
from ..services.processor import DefaultInvocationProcessor
|
||||
from ..services.sqlite import SqliteItemStorage
|
||||
from ..services.model_manager_service import ModelManagerService
|
||||
from ..services.invocation_stats import InvocationStatsService
|
||||
from ..services.thread import lock
|
||||
from .events import FastAPIEventService
|
||||
|
||||
|
||||
@ -67,22 +68,32 @@ class ApiDependencies:
|
||||
output_folder = config.output_path
|
||||
|
||||
# TODO: build a file/path manager?
|
||||
db_path = config.db_path
|
||||
db_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
db_location = str(db_path)
|
||||
if config.use_memory_db:
|
||||
db_location = ":memory:"
|
||||
else:
|
||||
db_path = config.db_path
|
||||
db_path.parent.mkdir(parents=True, exist_ok=True)
|
||||
db_location = str(db_path)
|
||||
|
||||
logger.info(f"Using database at {db_location}")
|
||||
db_conn = sqlite3.connect(db_location, check_same_thread=False) # TODO: figure out a better threading solution
|
||||
|
||||
if config.log_sql:
|
||||
db_conn.set_trace_callback(print)
|
||||
db_conn.execute("PRAGMA foreign_keys = ON;")
|
||||
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](
|
||||
filename=db_location, table_name="graph_executions"
|
||||
conn=db_conn, table_name="graph_executions", lock=lock
|
||||
)
|
||||
|
||||
urls = LocalUrlService()
|
||||
image_record_storage = SqliteImageRecordStorage(db_location)
|
||||
image_record_storage = SqliteImageRecordStorage(conn=db_conn, lock=lock)
|
||||
image_file_storage = DiskImageFileStorage(f"{output_folder}/images")
|
||||
names = SimpleNameService()
|
||||
latents = ForwardCacheLatentsStorage(DiskLatentsStorage(f"{output_folder}/latents"))
|
||||
|
||||
board_record_storage = SqliteBoardRecordStorage(db_location)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(db_location)
|
||||
board_record_storage = SqliteBoardRecordStorage(conn=db_conn, lock=lock)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(conn=db_conn, lock=lock)
|
||||
|
||||
boards = BoardService(
|
||||
services=BoardServiceDependencies(
|
||||
@ -124,18 +135,29 @@ class ApiDependencies:
|
||||
boards=boards,
|
||||
board_images=board_images,
|
||||
queue=MemoryInvocationQueue(),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](filename=db_location, table_name="graphs"),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](conn=db_conn, lock=lock, table_name="graphs"),
|
||||
graph_execution_manager=graph_execution_manager,
|
||||
processor=DefaultInvocationProcessor(),
|
||||
configuration=config,
|
||||
performance_statistics=InvocationStatsService(graph_execution_manager),
|
||||
logger=logger,
|
||||
session_queue=SqliteSessionQueue(conn=db_conn, lock=lock),
|
||||
session_processor=DefaultSessionProcessor(),
|
||||
invocation_cache=MemoryInvocationCache(max_cache_size=config.node_cache_size),
|
||||
)
|
||||
|
||||
create_system_graphs(services.graph_library)
|
||||
|
||||
ApiDependencies.invoker = Invoker(services)
|
||||
|
||||
try:
|
||||
lock.acquire()
|
||||
db_conn.execute("VACUUM;")
|
||||
db_conn.commit()
|
||||
logger.info("Cleaned database")
|
||||
finally:
|
||||
lock.release()
|
||||
|
||||
@staticmethod
|
||||
def shutdown():
|
||||
if ApiDependencies.invoker:
|
||||
|
||||
@ -1,19 +1,20 @@
|
||||
import typing
|
||||
from enum import Enum
|
||||
from pathlib import Path
|
||||
|
||||
from fastapi import Body
|
||||
from fastapi.routing import APIRouter
|
||||
from pathlib import Path
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.upscale import ESRGAN_MODELS
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.app.invocations.upscale import ESRGAN_MODELS
|
||||
|
||||
from invokeai.backend.util.logging import logging
|
||||
from invokeai.version import __version__
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
from invokeai.backend.util.logging import logging
|
||||
|
||||
|
||||
class LogLevel(int, Enum):
|
||||
@ -55,7 +56,7 @@ async def get_version() -> AppVersion:
|
||||
|
||||
@app_router.get("/config", operation_id="get_config", status_code=200, response_model=AppConfig)
|
||||
async def get_config() -> AppConfig:
|
||||
infill_methods = ["tile", "lama"]
|
||||
infill_methods = ["tile", "lama", "cv2"]
|
||||
if PatchMatch.patchmatch_available():
|
||||
infill_methods.append("patchmatch")
|
||||
|
||||
@ -103,3 +104,43 @@ async def set_log_level(
|
||||
"""Sets the log verbosity level"""
|
||||
ApiDependencies.invoker.services.logger.setLevel(level)
|
||||
return LogLevel(ApiDependencies.invoker.services.logger.level)
|
||||
|
||||
|
||||
@app_router.delete(
|
||||
"/invocation_cache",
|
||||
operation_id="clear_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def clear_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.clear()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/enable",
|
||||
operation_id="enable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def enable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.enable()
|
||||
|
||||
|
||||
@app_router.put(
|
||||
"/invocation_cache/disable",
|
||||
operation_id="disable_invocation_cache",
|
||||
responses={200: {"description": "The operation was successful"}},
|
||||
)
|
||||
async def disable_invocation_cache() -> None:
|
||||
"""Clears the invocation cache"""
|
||||
ApiDependencies.invoker.services.invocation_cache.disable()
|
||||
|
||||
|
||||
@app_router.get(
|
||||
"/invocation_cache/status",
|
||||
operation_id="get_invocation_cache_status",
|
||||
responses={200: {"model": InvocationCacheStatus}},
|
||||
)
|
||||
async def get_invocation_cache_status() -> InvocationCacheStatus:
|
||||
"""Clears the invocation cache"""
|
||||
return ApiDependencies.invoker.services.invocation_cache.get_status()
|
||||
|
||||
@ -1,20 +1,17 @@
|
||||
import io
|
||||
from typing import Optional
|
||||
|
||||
from PIL import Image
|
||||
from fastapi import Body, HTTPException, Path, Query, Request, Response, UploadFile
|
||||
from fastapi.responses import FileResponse
|
||||
from fastapi.routing import APIRouter
|
||||
from PIL import Image
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.metadata import ImageMetadata
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.image_record import (
|
||||
ImageDTO,
|
||||
ImageRecordChanges,
|
||||
ImageUrlsDTO,
|
||||
)
|
||||
from invokeai.app.services.models.image_record import ImageDTO, ImageRecordChanges, ImageUrlsDTO
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
images_router = APIRouter(prefix="/v1/images", tags=["images"])
|
||||
|
||||
@ -2,7 +2,7 @@
|
||||
|
||||
|
||||
import pathlib
|
||||
from typing import Literal, List, Optional, Union
|
||||
from typing import List, Literal, Optional, Union
|
||||
|
||||
from fastapi import Body, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
@ -10,13 +10,13 @@ from pydantic import BaseModel, parse_obj_as
|
||||
from starlette.exceptions import HTTPException
|
||||
|
||||
from invokeai.backend import BaseModelType, ModelType
|
||||
from invokeai.backend.model_management import MergeInterpolationMethod
|
||||
from invokeai.backend.model_management.models import (
|
||||
OPENAPI_MODEL_CONFIGS,
|
||||
SchedulerPredictionType,
|
||||
ModelNotFoundException,
|
||||
InvalidModelException,
|
||||
ModelNotFoundException,
|
||||
SchedulerPredictionType,
|
||||
)
|
||||
from invokeai.backend.model_management import MergeInterpolationMethod
|
||||
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
|
||||
247
invokeai/app/api/routers/session_queue.py
Normal file
@ -0,0 +1,247 @@
|
||||
from typing import Optional
|
||||
|
||||
from fastapi import Body, Path, Query
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel
|
||||
|
||||
from invokeai.app.services.session_processor.session_processor_common import SessionProcessorStatus
|
||||
from invokeai.app.services.session_queue.session_queue_common import (
|
||||
QUEUE_ITEM_STATUS,
|
||||
Batch,
|
||||
BatchStatus,
|
||||
CancelByBatchIDsResult,
|
||||
ClearResult,
|
||||
EnqueueBatchResult,
|
||||
EnqueueGraphResult,
|
||||
PruneResult,
|
||||
SessionQueueItem,
|
||||
SessionQueueItemDTO,
|
||||
SessionQueueStatus,
|
||||
)
|
||||
from invokeai.app.services.shared.models import CursorPaginatedResults
|
||||
|
||||
from ...services.graph import Graph
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
session_queue_router = APIRouter(prefix="/v1/queue", tags=["queue"])
|
||||
|
||||
|
||||
class SessionQueueAndProcessorStatus(BaseModel):
|
||||
"""The overall status of session queue and processor"""
|
||||
|
||||
queue: SessionQueueStatus
|
||||
processor: SessionProcessorStatus
|
||||
|
||||
|
||||
@session_queue_router.post(
|
||||
"/{queue_id}/enqueue_graph",
|
||||
operation_id="enqueue_graph",
|
||||
responses={
|
||||
201: {"model": EnqueueGraphResult},
|
||||
},
|
||||
)
|
||||
async def enqueue_graph(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
graph: Graph = Body(description="The graph to enqueue"),
|
||||
prepend: bool = Body(default=False, description="Whether or not to prepend this batch in the queue"),
|
||||
) -> EnqueueGraphResult:
|
||||
"""Enqueues a graph for single execution."""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.enqueue_graph(queue_id=queue_id, graph=graph, prepend=prepend)
|
||||
|
||||
|
||||
@session_queue_router.post(
|
||||
"/{queue_id}/enqueue_batch",
|
||||
operation_id="enqueue_batch",
|
||||
responses={
|
||||
201: {"model": EnqueueBatchResult},
|
||||
},
|
||||
)
|
||||
async def enqueue_batch(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
batch: Batch = Body(description="Batch to process"),
|
||||
prepend: bool = Body(default=False, description="Whether or not to prepend this batch in the queue"),
|
||||
) -> EnqueueBatchResult:
|
||||
"""Processes a batch and enqueues the output graphs for execution."""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.enqueue_batch(queue_id=queue_id, batch=batch, prepend=prepend)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/list",
|
||||
operation_id="list_queue_items",
|
||||
responses={
|
||||
200: {"model": CursorPaginatedResults[SessionQueueItemDTO]},
|
||||
},
|
||||
)
|
||||
async def list_queue_items(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
limit: int = Query(default=50, description="The number of items to fetch"),
|
||||
status: Optional[QUEUE_ITEM_STATUS] = Query(default=None, description="The status of items to fetch"),
|
||||
cursor: Optional[int] = Query(default=None, description="The pagination cursor"),
|
||||
priority: int = Query(default=0, description="The pagination cursor priority"),
|
||||
) -> CursorPaginatedResults[SessionQueueItemDTO]:
|
||||
"""Gets all queue items (without graphs)"""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.list_queue_items(
|
||||
queue_id=queue_id, limit=limit, status=status, cursor=cursor, priority=priority
|
||||
)
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/processor/resume",
|
||||
operation_id="resume",
|
||||
responses={200: {"model": SessionProcessorStatus}},
|
||||
)
|
||||
async def resume(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> SessionProcessorStatus:
|
||||
"""Resumes session processor"""
|
||||
return ApiDependencies.invoker.services.session_processor.resume()
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/processor/pause",
|
||||
operation_id="pause",
|
||||
responses={200: {"model": SessionProcessorStatus}},
|
||||
)
|
||||
async def Pause(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> SessionProcessorStatus:
|
||||
"""Pauses session processor"""
|
||||
return ApiDependencies.invoker.services.session_processor.pause()
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/cancel_by_batch_ids",
|
||||
operation_id="cancel_by_batch_ids",
|
||||
responses={200: {"model": CancelByBatchIDsResult}},
|
||||
)
|
||||
async def cancel_by_batch_ids(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
batch_ids: list[str] = Body(description="The list of batch_ids to cancel all queue items for", embed=True),
|
||||
) -> CancelByBatchIDsResult:
|
||||
"""Immediately cancels all queue items from the given batch ids"""
|
||||
return ApiDependencies.invoker.services.session_queue.cancel_by_batch_ids(queue_id=queue_id, batch_ids=batch_ids)
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/clear",
|
||||
operation_id="clear",
|
||||
responses={
|
||||
200: {"model": ClearResult},
|
||||
},
|
||||
)
|
||||
async def clear(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> ClearResult:
|
||||
"""Clears the queue entirely, immediately canceling the currently-executing session"""
|
||||
queue_item = ApiDependencies.invoker.services.session_queue.get_current(queue_id)
|
||||
if queue_item is not None:
|
||||
ApiDependencies.invoker.services.session_queue.cancel_queue_item(queue_item.item_id)
|
||||
clear_result = ApiDependencies.invoker.services.session_queue.clear(queue_id)
|
||||
return clear_result
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/prune",
|
||||
operation_id="prune",
|
||||
responses={
|
||||
200: {"model": PruneResult},
|
||||
},
|
||||
)
|
||||
async def prune(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> PruneResult:
|
||||
"""Prunes all completed or errored queue items"""
|
||||
return ApiDependencies.invoker.services.session_queue.prune(queue_id)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/current",
|
||||
operation_id="get_current_queue_item",
|
||||
responses={
|
||||
200: {"model": Optional[SessionQueueItem]},
|
||||
},
|
||||
)
|
||||
async def get_current_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> Optional[SessionQueueItem]:
|
||||
"""Gets the currently execution queue item"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_current(queue_id)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/next",
|
||||
operation_id="get_next_queue_item",
|
||||
responses={
|
||||
200: {"model": Optional[SessionQueueItem]},
|
||||
},
|
||||
)
|
||||
async def get_next_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> Optional[SessionQueueItem]:
|
||||
"""Gets the next queue item, without executing it"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_next(queue_id)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/status",
|
||||
operation_id="get_queue_status",
|
||||
responses={
|
||||
200: {"model": SessionQueueAndProcessorStatus},
|
||||
},
|
||||
)
|
||||
async def get_queue_status(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
) -> SessionQueueAndProcessorStatus:
|
||||
"""Gets the status of the session queue"""
|
||||
queue = ApiDependencies.invoker.services.session_queue.get_queue_status(queue_id)
|
||||
processor = ApiDependencies.invoker.services.session_processor.get_status()
|
||||
return SessionQueueAndProcessorStatus(queue=queue, processor=processor)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/b/{batch_id}/status",
|
||||
operation_id="get_batch_status",
|
||||
responses={
|
||||
200: {"model": BatchStatus},
|
||||
},
|
||||
)
|
||||
async def get_batch_status(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
batch_id: str = Path(description="The batch to get the status of"),
|
||||
) -> BatchStatus:
|
||||
"""Gets the status of the session queue"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_batch_status(queue_id=queue_id, batch_id=batch_id)
|
||||
|
||||
|
||||
@session_queue_router.get(
|
||||
"/{queue_id}/i/{item_id}",
|
||||
operation_id="get_queue_item",
|
||||
responses={
|
||||
200: {"model": SessionQueueItem},
|
||||
},
|
||||
)
|
||||
async def get_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: int = Path(description="The queue item to get"),
|
||||
) -> SessionQueueItem:
|
||||
"""Gets a queue item"""
|
||||
return ApiDependencies.invoker.services.session_queue.get_queue_item(item_id)
|
||||
|
||||
|
||||
@session_queue_router.put(
|
||||
"/{queue_id}/i/{item_id}/cancel",
|
||||
operation_id="cancel_queue_item",
|
||||
responses={
|
||||
200: {"model": SessionQueueItem},
|
||||
},
|
||||
)
|
||||
async def cancel_queue_item(
|
||||
queue_id: str = Path(description="The queue id to perform this operation on"),
|
||||
item_id: int = Path(description="The queue item to cancel"),
|
||||
) -> SessionQueueItem:
|
||||
"""Deletes a queue item"""
|
||||
|
||||
return ApiDependencies.invoker.services.session_queue.cancel_queue_item(item_id)
|
||||
@ -1,24 +1,16 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from typing import Annotated, Literal, Optional, Union
|
||||
from typing import Annotated, Optional, Union
|
||||
|
||||
from fastapi import Body, HTTPException, Path, Query, Response
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic.fields import Field
|
||||
|
||||
from invokeai.app.services.item_storage import PaginatedResults
|
||||
|
||||
# Importing * is bad karma but needed here for node detection
|
||||
from ...invocations import * # noqa: F401 F403
|
||||
from ...invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from ...services.graph import (
|
||||
Edge,
|
||||
EdgeConnection,
|
||||
Graph,
|
||||
GraphExecutionState,
|
||||
NodeAlreadyExecutedError,
|
||||
update_invocations_union,
|
||||
)
|
||||
from ...invocations.baseinvocation import BaseInvocation
|
||||
from ...services.graph import Edge, EdgeConnection, Graph, GraphExecutionState, NodeAlreadyExecutedError
|
||||
from ...services.item_storage import PaginatedResults
|
||||
from ..dependencies import ApiDependencies
|
||||
|
||||
session_router = APIRouter(prefix="/v1/sessions", tags=["sessions"])
|
||||
@ -31,37 +23,22 @@ session_router = APIRouter(prefix="/v1/sessions", tags=["sessions"])
|
||||
200: {"model": GraphExecutionState},
|
||||
400: {"description": "Invalid json"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def create_session(
|
||||
graph: Optional[Graph] = Body(default=None, description="The graph to initialize the session with")
|
||||
queue_id: str = Query(default="", description="The id of the queue to associate the session with"),
|
||||
graph: Optional[Graph] = Body(default=None, description="The graph to initialize the session with"),
|
||||
) -> GraphExecutionState:
|
||||
"""Creates a new session, optionally initializing it with an invocation graph"""
|
||||
session = ApiDependencies.invoker.create_execution_state(graph)
|
||||
session = ApiDependencies.invoker.create_execution_state(queue_id=queue_id, graph=graph)
|
||||
return session
|
||||
|
||||
|
||||
@session_router.post(
|
||||
"/update_nodes",
|
||||
operation_id="update_nodes",
|
||||
)
|
||||
async def update_nodes() -> None:
|
||||
class TestFromRouterOutput(BaseInvocationOutput):
|
||||
type: Literal["test_from_router"] = "test_from_router"
|
||||
|
||||
class TestInvocationFromRouter(BaseInvocation):
|
||||
type: Literal["test_from_router_output"] = "test_from_router_output"
|
||||
|
||||
def invoke(self, context) -> TestFromRouterOutput:
|
||||
return TestFromRouterOutput()
|
||||
|
||||
# doesn't work from here... hmm...
|
||||
update_invocations_union()
|
||||
|
||||
|
||||
@session_router.get(
|
||||
"/",
|
||||
operation_id="list_sessions",
|
||||
responses={200: {"model": PaginatedResults[GraphExecutionState]}},
|
||||
deprecated=True,
|
||||
)
|
||||
async def list_sessions(
|
||||
page: int = Query(default=0, description="The page of results to get"),
|
||||
@ -83,6 +60,7 @@ async def list_sessions(
|
||||
200: {"model": GraphExecutionState},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def get_session(
|
||||
session_id: str = Path(description="The id of the session to get"),
|
||||
@ -103,6 +81,7 @@ async def get_session(
|
||||
400: {"description": "Invalid node or link"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def add_node(
|
||||
session_id: str = Path(description="The id of the session"),
|
||||
@ -135,6 +114,7 @@ async def add_node(
|
||||
400: {"description": "Invalid node or link"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def update_node(
|
||||
session_id: str = Path(description="The id of the session"),
|
||||
@ -168,6 +148,7 @@ async def update_node(
|
||||
400: {"description": "Invalid node or link"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def delete_node(
|
||||
session_id: str = Path(description="The id of the session"),
|
||||
@ -198,6 +179,7 @@ async def delete_node(
|
||||
400: {"description": "Invalid node or link"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def add_edge(
|
||||
session_id: str = Path(description="The id of the session"),
|
||||
@ -229,6 +211,7 @@ async def add_edge(
|
||||
400: {"description": "Invalid node or link"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def delete_edge(
|
||||
session_id: str = Path(description="The id of the session"),
|
||||
@ -267,8 +250,10 @@ async def delete_edge(
|
||||
400: {"description": "The session has no invocations ready to invoke"},
|
||||
404: {"description": "Session not found"},
|
||||
},
|
||||
deprecated=True,
|
||||
)
|
||||
async def invoke_session(
|
||||
queue_id: str = Query(description="The id of the queue to associate the session with"),
|
||||
session_id: str = Path(description="The id of the session to invoke"),
|
||||
all: bool = Query(default=False, description="Whether or not to invoke all remaining invocations"),
|
||||
) -> Response:
|
||||
@ -280,7 +265,7 @@ async def invoke_session(
|
||||
if session.is_complete():
|
||||
raise HTTPException(status_code=400)
|
||||
|
||||
ApiDependencies.invoker.invoke(session, invoke_all=all)
|
||||
ApiDependencies.invoker.invoke(queue_id, session, invoke_all=all)
|
||||
return Response(status_code=202)
|
||||
|
||||
|
||||
@ -288,6 +273,7 @@ async def invoke_session(
|
||||
"/{session_id}/invoke",
|
||||
operation_id="cancel_session_invoke",
|
||||
responses={202: {"description": "The invocation is canceled"}},
|
||||
deprecated=True,
|
||||
)
|
||||
async def cancel_session_invoke(
|
||||
session_id: str = Path(description="The id of the session to cancel"),
|
||||
|
||||
41
invokeai/app/api/routers/utilities.py
Normal file
@ -0,0 +1,41 @@
|
||||
from typing import Optional
|
||||
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
from fastapi import Body
|
||||
from fastapi.routing import APIRouter
|
||||
from pydantic import BaseModel
|
||||
from pyparsing import ParseException
|
||||
|
||||
utilities_router = APIRouter(prefix="/v1/utilities", tags=["utilities"])
|
||||
|
||||
|
||||
class DynamicPromptsResponse(BaseModel):
|
||||
prompts: list[str]
|
||||
error: Optional[str] = None
|
||||
|
||||
|
||||
@utilities_router.post(
|
||||
"/dynamicprompts",
|
||||
operation_id="parse_dynamicprompts",
|
||||
responses={
|
||||
200: {"model": DynamicPromptsResponse},
|
||||
},
|
||||
)
|
||||
async def parse_dynamicprompts(
|
||||
prompt: str = Body(description="The prompt to parse with dynamicprompts"),
|
||||
max_prompts: int = Body(default=1000, description="The max number of prompts to generate"),
|
||||
combinatorial: bool = Body(default=True, description="Whether to use the combinatorial generator"),
|
||||
) -> DynamicPromptsResponse:
|
||||
"""Creates a batch process"""
|
||||
try:
|
||||
error: Optional[str] = None
|
||||
if combinatorial:
|
||||
generator = CombinatorialPromptGenerator()
|
||||
prompts = generator.generate(prompt, max_prompts=max_prompts)
|
||||
else:
|
||||
generator = RandomPromptGenerator()
|
||||
prompts = generator.generate(prompt, num_images=max_prompts)
|
||||
except ParseException as e:
|
||||
prompts = [prompt]
|
||||
error = str(e)
|
||||
return DynamicPromptsResponse(prompts=prompts if prompts else [""], error=error)
|
||||
@ -3,34 +3,35 @@
|
||||
from fastapi import FastAPI
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.typing import Event
|
||||
from fastapi_socketio import SocketManager
|
||||
from socketio import ASGIApp, AsyncServer
|
||||
|
||||
from ..services.events import EventServiceBase
|
||||
|
||||
|
||||
class SocketIO:
|
||||
__sio: SocketManager
|
||||
__sio: AsyncServer
|
||||
__app: ASGIApp
|
||||
|
||||
def __init__(self, app: FastAPI):
|
||||
self.__sio = SocketManager(app=app)
|
||||
self.__sio.on("subscribe", handler=self._handle_sub)
|
||||
self.__sio.on("unsubscribe", handler=self._handle_unsub)
|
||||
self.__sio = AsyncServer(async_mode="asgi", cors_allowed_origins="*")
|
||||
self.__app = ASGIApp(socketio_server=self.__sio, socketio_path="socket.io")
|
||||
app.mount("/ws", self.__app)
|
||||
|
||||
local_handler.register(event_name=EventServiceBase.session_event, _func=self._handle_session_event)
|
||||
self.__sio.on("subscribe_queue", handler=self._handle_sub_queue)
|
||||
self.__sio.on("unsubscribe_queue", handler=self._handle_unsub_queue)
|
||||
local_handler.register(event_name=EventServiceBase.queue_event, _func=self._handle_queue_event)
|
||||
|
||||
async def _handle_session_event(self, event: Event):
|
||||
async def _handle_queue_event(self, event: Event):
|
||||
await self.__sio.emit(
|
||||
event=event[1]["event"],
|
||||
data=event[1]["data"],
|
||||
room=event[1]["data"]["graph_execution_state_id"],
|
||||
room=event[1]["data"]["queue_id"],
|
||||
)
|
||||
|
||||
async def _handle_sub(self, sid, data, *args, **kwargs):
|
||||
if "session" in data:
|
||||
self.__sio.enter_room(sid, data["session"])
|
||||
async def _handle_sub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
# @app.sio.on('unsubscribe')
|
||||
|
||||
async def _handle_unsub(self, sid, data, *args, **kwargs):
|
||||
if "session" in data:
|
||||
self.__sio.leave_room(sid, data["session"])
|
||||
async def _handle_unsub_queue(self, sid, data, *args, **kwargs):
|
||||
if "queue_id" in data:
|
||||
self.__sio.enter_room(sid, data["queue_id"])
|
||||
|
||||
@ -1,42 +1,46 @@
|
||||
# Copyright (c) 2022-2023 Kyle Schouviller (https://github.com/kyle0654) and the InvokeAI Team
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
from pathlib import Path
|
||||
from typing import Literal
|
||||
|
||||
import torch
|
||||
import uvicorn
|
||||
from fastapi import FastAPI
|
||||
from fastapi.middleware.cors import CORSMiddleware
|
||||
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
|
||||
from fastapi.openapi.utils import get_openapi
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from pydantic.schema import schema
|
||||
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
import invokeai.frontend.web as web_dir
|
||||
from invokeai.app.services.graph import update_invocations_union
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
from .api.dependencies import ApiDependencies
|
||||
from .api.routers import sessions, models, images, boards, board_images, app_info
|
||||
from .api.sockets import SocketIO
|
||||
from .invocations.baseinvocation import BaseInvocation, _InputField, _OutputField, BaseInvocationOutput, UIConfigBase
|
||||
from .services.config import InvokeAIAppConfig
|
||||
from ..backend.util.logging import InvokeAILogger
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
app_config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import asyncio
|
||||
import logging
|
||||
import mimetypes
|
||||
import socket
|
||||
from inspect import signature
|
||||
from pathlib import Path
|
||||
|
||||
import torch
|
||||
import uvicorn
|
||||
from fastapi import FastAPI
|
||||
from fastapi.middleware.cors import CORSMiddleware
|
||||
from fastapi.openapi.docs import get_redoc_html, get_swagger_ui_html
|
||||
from fastapi.openapi.utils import get_openapi
|
||||
from fastapi.staticfiles import StaticFiles
|
||||
from fastapi_events.handlers.local import local_handler
|
||||
from fastapi_events.middleware import EventHandlerASGIMiddleware
|
||||
from pydantic.schema import schema
|
||||
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
import invokeai.frontend.web as web_dir
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
from ..backend.util.logging import InvokeAILogger
|
||||
from .api.dependencies import ApiDependencies
|
||||
from .api.routers import app_info, board_images, boards, images, models, session_queue, sessions, utilities
|
||||
from .api.sockets import SocketIO
|
||||
from .invocations.baseinvocation import BaseInvocation, UIConfigBase, _InputField, _OutputField
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
# noinspection PyUnresolvedReferences
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger.getLogger(config=app_config)
|
||||
|
||||
# fix for windows mimetypes registry entries being borked
|
||||
@ -87,6 +91,8 @@ async def shutdown_event():
|
||||
|
||||
app.include_router(sessions.session_router, prefix="/api")
|
||||
|
||||
app.include_router(utilities.utilities_router, prefix="/api")
|
||||
|
||||
app.include_router(models.models_router, prefix="/api")
|
||||
|
||||
app.include_router(images.images_router, prefix="/api")
|
||||
@ -97,12 +103,14 @@ app.include_router(board_images.board_images_router, prefix="/api")
|
||||
|
||||
app.include_router(app_info.app_router, prefix="/api")
|
||||
|
||||
app.include_router(session_queue.session_queue_router, prefix="/api")
|
||||
|
||||
|
||||
# Build a custom OpenAPI to include all outputs
|
||||
# TODO: can outputs be included on metadata of invocation schemas somehow?
|
||||
def custom_openapi():
|
||||
# if app.openapi_schema:
|
||||
# return app.openapi_schema
|
||||
if app.openapi_schema:
|
||||
return app.openapi_schema
|
||||
openapi_schema = get_openapi(
|
||||
title=app.title,
|
||||
description="An API for invoking AI image operations",
|
||||
@ -137,9 +145,6 @@ def custom_openapi():
|
||||
invoker_name = invoker.__name__
|
||||
output_type = signature(invoker.invoke).return_annotation
|
||||
output_type_title = output_type_titles[output_type.__name__]
|
||||
if invoker_name not in openapi_schema["components"]["schemas"]:
|
||||
openapi_schema["components"]["schemas"][invoker_name] = invoker.schema()
|
||||
|
||||
invoker_schema = openapi_schema["components"]["schemas"][invoker_name]
|
||||
outputs_ref = {"$ref": f"#/components/schemas/{output_type_title}"}
|
||||
invoker_schema["output"] = outputs_ref
|
||||
@ -211,14 +216,14 @@ def invoke_api():
|
||||
|
||||
if app_config.dev_reload:
|
||||
try:
|
||||
from invokeai.app.util.dev_reload import start_reloader
|
||||
import jurigged
|
||||
except ImportError as e:
|
||||
logger.error(
|
||||
'Can\'t start `--dev_reload` because jurigged is not found; `pip install -e ".[dev]"` to include development dependencies.',
|
||||
exc_info=e,
|
||||
)
|
||||
else:
|
||||
start_reloader()
|
||||
jurigged.watch(logger=InvokeAILogger.getLogger(name="jurigged").info)
|
||||
|
||||
port = find_port(app_config.port)
|
||||
if port != app_config.port:
|
||||
@ -242,26 +247,6 @@ def invoke_api():
|
||||
for ch in logger.handlers:
|
||||
log.addHandler(ch)
|
||||
|
||||
class Test1Output(BaseInvocationOutput):
|
||||
type: Literal["test1_output"] = "test1_output"
|
||||
|
||||
class Test1Invocation(BaseInvocation):
|
||||
type: Literal["test1"] = "test1"
|
||||
|
||||
def invoke(self, context) -> Test1Output:
|
||||
return Test1Output()
|
||||
|
||||
class Test2Output(BaseInvocationOutput):
|
||||
type: Literal["test2_output"] = "test2_output"
|
||||
|
||||
class TestInvocation2(BaseInvocation):
|
||||
type: Literal["test2"] = "test2"
|
||||
|
||||
def invoke(self, context) -> Test2Output:
|
||||
return Test2Output()
|
||||
|
||||
update_invocations_union()
|
||||
|
||||
loop.run_until_complete(server.serve())
|
||||
|
||||
|
||||
|
||||
@ -1,16 +1,18 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
import argparse
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Any, Callable, Iterable, Literal, Union, get_args, get_origin, get_type_hints
|
||||
from pydantic import BaseModel, Field
|
||||
import networkx as nx
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
|
||||
from ..invocations.baseinvocation import BaseInvocation
|
||||
from ..invocations.image import ImageField
|
||||
from ..services.graph import GraphExecutionState, LibraryGraph, Edge
|
||||
from ..services.graph import Edge, GraphExecutionState, LibraryGraph
|
||||
from ..services.invoker import Invoker
|
||||
|
||||
|
||||
|
||||
@ -6,15 +6,15 @@ completer object.
|
||||
import atexit
|
||||
import readline
|
||||
import shlex
|
||||
|
||||
from pathlib import Path
|
||||
from typing import List, Dict, Literal, get_args, get_type_hints, get_origin
|
||||
from typing import Dict, List, Literal, get_args, get_origin, get_type_hints
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
|
||||
from ...backend import ModelManager
|
||||
from ..invocations.baseinvocation import BaseInvocation
|
||||
from .commands import BaseCommand
|
||||
from ..services.invocation_services import InvocationServices
|
||||
from .commands import BaseCommand
|
||||
|
||||
# singleton object, class variable
|
||||
completer = None
|
||||
|
||||
@ -1,67 +1,67 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654) and the InvokeAI Team
|
||||
|
||||
import argparse
|
||||
import re
|
||||
import shlex
|
||||
import sys
|
||||
import time
|
||||
from typing import Union, get_type_hints, Optional
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_memory import MemoryInvocationCache
|
||||
|
||||
from pydantic import BaseModel, ValidationError
|
||||
from pydantic.fields import Field
|
||||
|
||||
# This should come early so that the logger can pick up its configuration options
|
||||
from .services.config import InvokeAIAppConfig
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import (
|
||||
SqliteBoardImageRecordStorage,
|
||||
)
|
||||
from invokeai.app.services.board_images import (
|
||||
BoardImagesService,
|
||||
BoardImagesServiceDependencies,
|
||||
)
|
||||
from invokeai.app.services.board_record_storage import SqliteBoardRecordStorage
|
||||
from invokeai.app.services.boards import BoardService, BoardServiceDependencies
|
||||
from invokeai.app.services.image_record_storage import SqliteImageRecordStorage
|
||||
from invokeai.app.services.images import ImageService, ImageServiceDependencies
|
||||
from invokeai.app.services.resource_name import SimpleNameService
|
||||
from invokeai.app.services.urls import LocalUrlService
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsService
|
||||
from .services.default_graphs import default_text_to_image_graph_id, create_system_graphs
|
||||
from .services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
|
||||
from .cli.commands import BaseCommand, CliContext, ExitCli, SortedHelpFormatter, add_graph_parsers, add_parsers
|
||||
from .cli.completer import set_autocompleter
|
||||
from .invocations.baseinvocation import BaseInvocation
|
||||
from .services.events import EventServiceBase
|
||||
from .services.graph import (
|
||||
Edge,
|
||||
EdgeConnection,
|
||||
GraphExecutionState,
|
||||
GraphInvocation,
|
||||
LibraryGraph,
|
||||
are_connection_types_compatible,
|
||||
)
|
||||
from .services.image_file_storage import DiskImageFileStorage
|
||||
from .services.invocation_queue import MemoryInvocationQueue
|
||||
from .services.invocation_services import InvocationServices
|
||||
from .services.invoker import Invoker
|
||||
from .services.model_manager_service import ModelManagerService
|
||||
from .services.processor import DefaultInvocationProcessor
|
||||
from .services.sqlite import SqliteItemStorage
|
||||
|
||||
import torch
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
# parse_args() must be called before any other imports. if it is not called first, consumers of the config
|
||||
# which are imported/used before parse_args() is called will get the default config values instead of the
|
||||
# values from the command line or config file.
|
||||
config = InvokeAIAppConfig.get_config()
|
||||
config.parse_args()
|
||||
|
||||
if True: # hack to make flake8 happy with imports coming after setting up the config
|
||||
import argparse
|
||||
import re
|
||||
import shlex
|
||||
import sqlite3
|
||||
import sys
|
||||
import time
|
||||
from typing import Optional, Union, get_type_hints
|
||||
|
||||
import torch
|
||||
from pydantic import BaseModel, ValidationError
|
||||
from pydantic.fields import Field
|
||||
|
||||
import invokeai.backend.util.hotfixes # noqa: F401 (monkeypatching on import)
|
||||
from invokeai.app.services.board_image_record_storage import SqliteBoardImageRecordStorage
|
||||
from invokeai.app.services.board_images import BoardImagesService, BoardImagesServiceDependencies
|
||||
from invokeai.app.services.board_record_storage import SqliteBoardRecordStorage
|
||||
from invokeai.app.services.boards import BoardService, BoardServiceDependencies
|
||||
from invokeai.app.services.image_record_storage import SqliteImageRecordStorage
|
||||
from invokeai.app.services.images import ImageService, ImageServiceDependencies
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsService
|
||||
from invokeai.app.services.resource_name import SimpleNameService
|
||||
from invokeai.app.services.urls import LocalUrlService
|
||||
from invokeai.backend.util.logging import InvokeAILogger
|
||||
from invokeai.version.invokeai_version import __version__
|
||||
|
||||
from .cli.commands import BaseCommand, CliContext, ExitCli, SortedHelpFormatter, add_graph_parsers, add_parsers
|
||||
from .cli.completer import set_autocompleter
|
||||
from .invocations.baseinvocation import BaseInvocation
|
||||
from .services.default_graphs import create_system_graphs, default_text_to_image_graph_id
|
||||
from .services.events import EventServiceBase
|
||||
from .services.graph import (
|
||||
Edge,
|
||||
EdgeConnection,
|
||||
GraphExecutionState,
|
||||
GraphInvocation,
|
||||
LibraryGraph,
|
||||
are_connection_types_compatible,
|
||||
)
|
||||
from .services.image_file_storage import DiskImageFileStorage
|
||||
from .services.invocation_queue import MemoryInvocationQueue
|
||||
from .services.invocation_services import InvocationServices
|
||||
from .services.invoker import Invoker
|
||||
from .services.latent_storage import DiskLatentsStorage, ForwardCacheLatentsStorage
|
||||
from .services.model_manager_service import ModelManagerService
|
||||
from .services.processor import DefaultInvocationProcessor
|
||||
from .services.sqlite import SqliteItemStorage
|
||||
|
||||
if torch.backends.mps.is_available():
|
||||
import invokeai.backend.util.mps_fixes # noqa: F401 (monkeypatching on import)
|
||||
|
||||
|
||||
logger = InvokeAILogger().getLogger(config=config)
|
||||
|
||||
|
||||
@ -252,19 +252,18 @@ def invoke_cli():
|
||||
db_location = config.db_path
|
||||
db_location.parent.mkdir(parents=True, exist_ok=True)
|
||||
|
||||
db_conn = sqlite3.connect(db_location, check_same_thread=False) # TODO: figure out a better threading solution
|
||||
logger.info(f'InvokeAI database location is "{db_location}"')
|
||||
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](
|
||||
filename=db_location, table_name="graph_executions"
|
||||
)
|
||||
graph_execution_manager = SqliteItemStorage[GraphExecutionState](conn=db_conn, table_name="graph_executions")
|
||||
|
||||
urls = LocalUrlService()
|
||||
image_record_storage = SqliteImageRecordStorage(db_location)
|
||||
image_record_storage = SqliteImageRecordStorage(conn=db_conn)
|
||||
image_file_storage = DiskImageFileStorage(f"{output_folder}/images")
|
||||
names = SimpleNameService()
|
||||
|
||||
board_record_storage = SqliteBoardRecordStorage(db_location)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(db_location)
|
||||
board_record_storage = SqliteBoardRecordStorage(conn=db_conn)
|
||||
board_image_record_storage = SqliteBoardImageRecordStorage(conn=db_conn)
|
||||
|
||||
boards = BoardService(
|
||||
services=BoardServiceDependencies(
|
||||
@ -306,12 +305,13 @@ def invoke_cli():
|
||||
boards=boards,
|
||||
board_images=board_images,
|
||||
queue=MemoryInvocationQueue(),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](filename=db_location, table_name="graphs"),
|
||||
graph_library=SqliteItemStorage[LibraryGraph](conn=db_conn, table_name="graphs"),
|
||||
graph_execution_manager=graph_execution_manager,
|
||||
processor=DefaultInvocationProcessor(),
|
||||
performance_statistics=InvocationStatsService(graph_execution_manager),
|
||||
logger=logger,
|
||||
configuration=config,
|
||||
invocation_cache=MemoryInvocationCache(max_cache_size=config.node_cache_size),
|
||||
)
|
||||
|
||||
system_graphs = create_system_graphs(services.graph_library)
|
||||
|
||||
@ -2,6 +2,8 @@
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import json
|
||||
import re
|
||||
from abc import ABC, abstractmethod
|
||||
from enum import Enum
|
||||
from inspect import signature
|
||||
@ -11,6 +13,7 @@ from typing import (
|
||||
Any,
|
||||
Callable,
|
||||
ClassVar,
|
||||
Literal,
|
||||
Mapping,
|
||||
Optional,
|
||||
Type,
|
||||
@ -20,14 +23,21 @@ from typing import (
|
||||
get_type_hints,
|
||||
)
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from pydantic.fields import Undefined
|
||||
import semver
|
||||
from pydantic import BaseModel, Field, validator
|
||||
from pydantic.fields import ModelField, Undefined
|
||||
from pydantic.typing import NoArgAnyCallable
|
||||
|
||||
from invokeai.app.services.config.invokeai_config import InvokeAIAppConfig
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from ..services.invocation_services import InvocationServices
|
||||
|
||||
|
||||
class InvalidVersionError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class FieldDescriptions:
|
||||
denoising_start = "When to start denoising, expressed a percentage of total steps"
|
||||
denoising_end = "When to stop denoising, expressed a percentage of total steps"
|
||||
@ -57,6 +67,7 @@ class FieldDescriptions:
|
||||
width = "Width of output (px)"
|
||||
height = "Height of output (px)"
|
||||
control = "ControlNet(s) to apply"
|
||||
ip_adapter = "IP-Adapter to apply"
|
||||
denoised_latents = "Denoised latents tensor"
|
||||
latents = "Latents tensor"
|
||||
strength = "Strength of denoising (proportional to steps)"
|
||||
@ -102,24 +113,39 @@ class UIType(str, Enum):
|
||||
"""
|
||||
|
||||
# region Primitives
|
||||
Integer = "integer"
|
||||
Float = "float"
|
||||
Boolean = "boolean"
|
||||
String = "string"
|
||||
Array = "array"
|
||||
Image = "ImageField"
|
||||
Latents = "LatentsField"
|
||||
Color = "ColorField"
|
||||
Conditioning = "ConditioningField"
|
||||
Control = "ControlField"
|
||||
Color = "ColorField"
|
||||
ImageCollection = "ImageCollection"
|
||||
ConditioningCollection = "ConditioningCollection"
|
||||
ColorCollection = "ColorCollection"
|
||||
LatentsCollection = "LatentsCollection"
|
||||
IntegerCollection = "IntegerCollection"
|
||||
FloatCollection = "FloatCollection"
|
||||
StringCollection = "StringCollection"
|
||||
Float = "float"
|
||||
Image = "ImageField"
|
||||
Integer = "integer"
|
||||
Latents = "LatentsField"
|
||||
String = "string"
|
||||
# endregion
|
||||
|
||||
# region Collection Primitives
|
||||
BooleanCollection = "BooleanCollection"
|
||||
ColorCollection = "ColorCollection"
|
||||
ConditioningCollection = "ConditioningCollection"
|
||||
ControlCollection = "ControlCollection"
|
||||
FloatCollection = "FloatCollection"
|
||||
ImageCollection = "ImageCollection"
|
||||
IntegerCollection = "IntegerCollection"
|
||||
LatentsCollection = "LatentsCollection"
|
||||
StringCollection = "StringCollection"
|
||||
# endregion
|
||||
|
||||
# region Polymorphic Primitives
|
||||
BooleanPolymorphic = "BooleanPolymorphic"
|
||||
ColorPolymorphic = "ColorPolymorphic"
|
||||
ConditioningPolymorphic = "ConditioningPolymorphic"
|
||||
ControlPolymorphic = "ControlPolymorphic"
|
||||
FloatPolymorphic = "FloatPolymorphic"
|
||||
ImagePolymorphic = "ImagePolymorphic"
|
||||
IntegerPolymorphic = "IntegerPolymorphic"
|
||||
LatentsPolymorphic = "LatentsPolymorphic"
|
||||
StringPolymorphic = "StringPolymorphic"
|
||||
# endregion
|
||||
|
||||
# region Models
|
||||
@ -130,6 +156,7 @@ class UIType(str, Enum):
|
||||
VaeModel = "VaeModelField"
|
||||
LoRAModel = "LoRAModelField"
|
||||
ControlNetModel = "ControlNetModelField"
|
||||
IPAdapterModel = "IPAdapterModelField"
|
||||
UNet = "UNetField"
|
||||
Vae = "VaeField"
|
||||
CLIP = "ClipField"
|
||||
@ -141,9 +168,11 @@ class UIType(str, Enum):
|
||||
# endregion
|
||||
|
||||
# region Misc
|
||||
FilePath = "FilePath"
|
||||
Enum = "enum"
|
||||
Scheduler = "Scheduler"
|
||||
WorkflowField = "WorkflowField"
|
||||
IsIntermediate = "IsIntermediate"
|
||||
MetadataField = "MetadataField"
|
||||
# endregion
|
||||
|
||||
|
||||
@ -171,6 +200,8 @@ class _InputField(BaseModel):
|
||||
ui_type: Optional[UIType]
|
||||
ui_component: Optional[UIComponent]
|
||||
ui_order: Optional[int]
|
||||
ui_choice_labels: Optional[dict[str, str]]
|
||||
item_default: Optional[Any]
|
||||
|
||||
|
||||
class _OutputField(BaseModel):
|
||||
@ -218,6 +249,8 @@ def InputField(
|
||||
ui_component: Optional[UIComponent] = None,
|
||||
ui_hidden: bool = False,
|
||||
ui_order: Optional[int] = None,
|
||||
ui_choice_labels: Optional[dict[str, str]] = None,
|
||||
item_default: Optional[Any] = None,
|
||||
**kwargs: Any,
|
||||
) -> Any:
|
||||
"""
|
||||
@ -244,6 +277,11 @@ def InputField(
|
||||
For this case, you could provide `UIComponent.Textarea`.
|
||||
|
||||
: param bool ui_hidden: [False] Specifies whether or not this field should be hidden in the UI.
|
||||
|
||||
: param int ui_order: [None] Specifies the order in which this field should be rendered in the UI. \
|
||||
|
||||
: param bool item_default: [None] Specifies the default item value, if this is a collection input. \
|
||||
Ignored for non-collection fields..
|
||||
"""
|
||||
return Field(
|
||||
*args,
|
||||
@ -277,6 +315,8 @@ def InputField(
|
||||
ui_component=ui_component,
|
||||
ui_hidden=ui_hidden,
|
||||
ui_order=ui_order,
|
||||
item_default=item_default,
|
||||
ui_choice_labels=ui_choice_labels,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
@ -327,6 +367,8 @@ def OutputField(
|
||||
`UIType.SDXLMainModelField` to indicate that the field is an SDXL main model field.
|
||||
|
||||
: param bool ui_hidden: [False] Specifies whether or not this field should be hidden in the UI. \
|
||||
|
||||
: param int ui_order: [None] Specifies the order in which this field should be rendered in the UI. \
|
||||
"""
|
||||
return Field(
|
||||
*args,
|
||||
@ -365,28 +407,47 @@ def OutputField(
|
||||
class UIConfigBase(BaseModel):
|
||||
"""
|
||||
Provides additional node configuration to the UI.
|
||||
This is used internally by the @tags and @title decorator logic. You probably want to use those
|
||||
decorators, though you may add this class to a node definition to specify the title and tags.
|
||||
This is used internally by the @invocation decorator logic. Do not use this directly.
|
||||
"""
|
||||
|
||||
tags: Optional[list[str]] = Field(default_factory=None, description="The tags to display in the UI")
|
||||
title: Optional[str] = Field(default=None, description="The display name of the node")
|
||||
tags: Optional[list[str]] = Field(default_factory=None, description="The node's tags")
|
||||
title: Optional[str] = Field(default=None, description="The node's display name")
|
||||
category: Optional[str] = Field(default=None, description="The node's category")
|
||||
version: Optional[str] = Field(
|
||||
default=None, description='The node\'s version. Should be a valid semver string e.g. "1.0.0" or "3.8.13".'
|
||||
)
|
||||
|
||||
|
||||
class InvocationContext:
|
||||
"""Initialized and provided to on execution of invocations."""
|
||||
|
||||
services: InvocationServices
|
||||
graph_execution_state_id: str
|
||||
queue_id: str
|
||||
queue_item_id: int
|
||||
queue_batch_id: str
|
||||
|
||||
def __init__(self, services: InvocationServices, graph_execution_state_id: str):
|
||||
def __init__(
|
||||
self,
|
||||
services: InvocationServices,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
):
|
||||
self.services = services
|
||||
self.graph_execution_state_id = graph_execution_state_id
|
||||
self.queue_id = queue_id
|
||||
self.queue_item_id = queue_item_id
|
||||
self.queue_batch_id = queue_batch_id
|
||||
|
||||
|
||||
class BaseInvocationOutput(BaseModel):
|
||||
"""Base class for all invocation outputs"""
|
||||
"""
|
||||
Base class for all invocation outputs.
|
||||
|
||||
# All outputs must include a type name like this:
|
||||
# type: Literal['your_output_name'] # noqa f821
|
||||
All invocation outputs must use the `@invocation_output` decorator to provide their unique type.
|
||||
"""
|
||||
|
||||
@classmethod
|
||||
def get_all_subclasses_tuple(cls):
|
||||
@ -422,15 +483,16 @@ class MissingInputException(Exception):
|
||||
|
||||
|
||||
class BaseInvocation(ABC, BaseModel):
|
||||
"""A node to process inputs and produce outputs.
|
||||
May use dependency injection in __init__ to receive providers.
|
||||
"""
|
||||
A node to process inputs and produce outputs.
|
||||
May use dependency injection in __init__ to receive providers.
|
||||
|
||||
# All invocations must include a type name like this:
|
||||
# type: Literal['your_output_name'] # noqa f821
|
||||
All invocations must use the `@invocation` decorator to provide their unique type.
|
||||
"""
|
||||
|
||||
@classmethod
|
||||
def get_all_subclasses(cls):
|
||||
app_config = InvokeAIAppConfig.get_config()
|
||||
subclasses = []
|
||||
toprocess = [cls]
|
||||
while len(toprocess) > 0:
|
||||
@ -438,7 +500,23 @@ class BaseInvocation(ABC, BaseModel):
|
||||
next_subclasses = next.__subclasses__()
|
||||
subclasses.extend(next_subclasses)
|
||||
toprocess.extend(next_subclasses)
|
||||
return subclasses
|
||||
allowed_invocations = []
|
||||
for sc in subclasses:
|
||||
is_in_allowlist = (
|
||||
sc.__fields__.get("type").default in app_config.allow_nodes
|
||||
if isinstance(app_config.allow_nodes, list)
|
||||
else True
|
||||
)
|
||||
|
||||
is_in_denylist = (
|
||||
sc.__fields__.get("type").default in app_config.deny_nodes
|
||||
if isinstance(app_config.deny_nodes, list)
|
||||
else False
|
||||
)
|
||||
|
||||
if is_in_allowlist and not is_in_denylist:
|
||||
allowed_invocations.append(sc)
|
||||
return allowed_invocations
|
||||
|
||||
@classmethod
|
||||
def get_invocations(cls):
|
||||
@ -459,6 +537,9 @@ class BaseInvocation(ABC, BaseModel):
|
||||
return signature(cls.invoke).return_annotation
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
validate_all = True
|
||||
|
||||
@staticmethod
|
||||
def schema_extra(schema: dict[str, Any], model_class: Type[BaseModel]) -> None:
|
||||
uiconfig = getattr(model_class, "UIConfig", None)
|
||||
@ -466,6 +547,10 @@ class BaseInvocation(ABC, BaseModel):
|
||||
schema["title"] = uiconfig.title
|
||||
if uiconfig and hasattr(uiconfig, "tags"):
|
||||
schema["tags"] = uiconfig.tags
|
||||
if uiconfig and hasattr(uiconfig, "category"):
|
||||
schema["category"] = uiconfig.category
|
||||
if uiconfig and hasattr(uiconfig, "version"):
|
||||
schema["version"] = uiconfig.version
|
||||
if "required" not in schema or not isinstance(schema["required"], list):
|
||||
schema["required"] = list()
|
||||
schema["required"].extend(["type", "id"])
|
||||
@ -503,39 +588,152 @@ class BaseInvocation(ABC, BaseModel):
|
||||
raise RequiredConnectionException(self.__fields__["type"].default, field_name)
|
||||
elif _input == Input.Any:
|
||||
raise MissingInputException(self.__fields__["type"].default, field_name)
|
||||
return self.invoke(context)
|
||||
|
||||
id: str = Field(description="The id of this node. Must be unique among all nodes.")
|
||||
is_intermediate: bool = InputField(
|
||||
default=False, description="Whether or not this node is an intermediate node.", input=Input.Direct
|
||||
# skip node cache codepath if it's disabled
|
||||
if context.services.configuration.node_cache_size == 0:
|
||||
return self.invoke(context)
|
||||
|
||||
output: BaseInvocationOutput
|
||||
if self.use_cache:
|
||||
key = context.services.invocation_cache.create_key(self)
|
||||
cached_value = context.services.invocation_cache.get(key)
|
||||
if cached_value is None:
|
||||
context.services.logger.debug(f'Invocation cache miss for type "{self.get_type()}": {self.id}')
|
||||
output = self.invoke(context)
|
||||
context.services.invocation_cache.save(key, output)
|
||||
return output
|
||||
else:
|
||||
context.services.logger.debug(f'Invocation cache hit for type "{self.get_type()}": {self.id}')
|
||||
return cached_value
|
||||
else:
|
||||
context.services.logger.debug(f'Skipping invocation cache for "{self.get_type()}": {self.id}')
|
||||
return self.invoke(context)
|
||||
|
||||
def get_type(self) -> str:
|
||||
return self.__fields__["type"].default
|
||||
|
||||
id: str = Field(
|
||||
description="The id of this instance of an invocation. Must be unique among all instances of invocations."
|
||||
)
|
||||
is_intermediate: bool = InputField(
|
||||
default=False, description="Whether or not this is an intermediate invocation.", ui_type=UIType.IsIntermediate
|
||||
)
|
||||
workflow: Optional[str] = InputField(
|
||||
default=None,
|
||||
description="The workflow to save with the image",
|
||||
ui_type=UIType.WorkflowField,
|
||||
)
|
||||
use_cache: bool = InputField(default=True, description="Whether or not to use the cache")
|
||||
|
||||
@validator("workflow", pre=True)
|
||||
def validate_workflow_is_json(cls, v):
|
||||
if v is None:
|
||||
return None
|
||||
try:
|
||||
json.loads(v)
|
||||
except json.decoder.JSONDecodeError:
|
||||
raise ValueError("Workflow must be valid JSON")
|
||||
return v
|
||||
|
||||
UIConfig: ClassVar[Type[UIConfigBase]]
|
||||
|
||||
|
||||
T = TypeVar("T", bound=BaseInvocation)
|
||||
GenericBaseInvocation = TypeVar("GenericBaseInvocation", bound=BaseInvocation)
|
||||
|
||||
|
||||
def title(title: str) -> Callable[[Type[T]], Type[T]]:
|
||||
"""Adds a title to the invocation. Use this to override the default title generation, which is based on the class name."""
|
||||
def invocation(
|
||||
invocation_type: str,
|
||||
title: Optional[str] = None,
|
||||
tags: Optional[list[str]] = None,
|
||||
category: Optional[str] = None,
|
||||
version: Optional[str] = None,
|
||||
use_cache: Optional[bool] = True,
|
||||
) -> Callable[[Type[GenericBaseInvocation]], Type[GenericBaseInvocation]]:
|
||||
"""
|
||||
Adds metadata to an invocation.
|
||||
|
||||
def wrapper(cls: Type[T]) -> Type[T]:
|
||||
:param str invocation_type: The type of the invocation. Must be unique among all invocations.
|
||||
:param Optional[str] title: Adds a title to the invocation. Use if the auto-generated title isn't quite right. Defaults to None.
|
||||
:param Optional[list[str]] tags: Adds tags to the invocation. Invocations may be searched for by their tags. Defaults to None.
|
||||
:param Optional[str] category: Adds a category to the invocation. Used to group the invocations in the UI. Defaults to None.
|
||||
"""
|
||||
|
||||
def wrapper(cls: Type[GenericBaseInvocation]) -> Type[GenericBaseInvocation]:
|
||||
# Validate invocation types on creation of invocation classes
|
||||
# TODO: ensure unique?
|
||||
if re.compile(r"^\S+$").match(invocation_type) is None:
|
||||
raise ValueError(f'"invocation_type" must consist of non-whitespace characters, got "{invocation_type}"')
|
||||
|
||||
# Add OpenAPI schema extras
|
||||
uiconf_name = cls.__qualname__ + ".UIConfig"
|
||||
if not hasattr(cls, "UIConfig") or cls.UIConfig.__qualname__ != uiconf_name:
|
||||
cls.UIConfig = type(uiconf_name, (UIConfigBase,), dict())
|
||||
cls.UIConfig.title = title
|
||||
if title is not None:
|
||||
cls.UIConfig.title = title
|
||||
if tags is not None:
|
||||
cls.UIConfig.tags = tags
|
||||
if category is not None:
|
||||
cls.UIConfig.category = category
|
||||
if version is not None:
|
||||
try:
|
||||
semver.Version.parse(version)
|
||||
except ValueError as e:
|
||||
raise InvalidVersionError(f'Invalid version string for node "{invocation_type}": "{version}"') from e
|
||||
cls.UIConfig.version = version
|
||||
if use_cache is not None:
|
||||
cls.__fields__["use_cache"].default = use_cache
|
||||
|
||||
# Add the invocation type to the pydantic model of the invocation
|
||||
invocation_type_annotation = Literal[invocation_type] # type: ignore
|
||||
invocation_type_field = ModelField.infer(
|
||||
name="type",
|
||||
value=invocation_type,
|
||||
annotation=invocation_type_annotation,
|
||||
class_validators=None,
|
||||
config=cls.__config__,
|
||||
)
|
||||
cls.__fields__.update({"type": invocation_type_field})
|
||||
# to support 3.9, 3.10 and 3.11, as described in https://docs.python.org/3/howto/annotations.html
|
||||
if annotations := cls.__dict__.get("__annotations__", None):
|
||||
annotations.update({"type": invocation_type_annotation})
|
||||
return cls
|
||||
|
||||
return wrapper
|
||||
|
||||
|
||||
def tags(*tags: str) -> Callable[[Type[T]], Type[T]]:
|
||||
"""Adds tags to the invocation. Use this to improve the streamline finding the invocation in the UI."""
|
||||
GenericBaseInvocationOutput = TypeVar("GenericBaseInvocationOutput", bound=BaseInvocationOutput)
|
||||
|
||||
|
||||
def invocation_output(
|
||||
output_type: str,
|
||||
) -> Callable[[Type[GenericBaseInvocationOutput]], Type[GenericBaseInvocationOutput]]:
|
||||
"""
|
||||
Adds metadata to an invocation output.
|
||||
|
||||
:param str output_type: The type of the invocation output. Must be unique among all invocation outputs.
|
||||
"""
|
||||
|
||||
def wrapper(cls: Type[GenericBaseInvocationOutput]) -> Type[GenericBaseInvocationOutput]:
|
||||
# Validate output types on creation of invocation output classes
|
||||
# TODO: ensure unique?
|
||||
if re.compile(r"^\S+$").match(output_type) is None:
|
||||
raise ValueError(f'"output_type" must consist of non-whitespace characters, got "{output_type}"')
|
||||
|
||||
# Add the output type to the pydantic model of the invocation output
|
||||
output_type_annotation = Literal[output_type] # type: ignore
|
||||
output_type_field = ModelField.infer(
|
||||
name="type",
|
||||
value=output_type,
|
||||
annotation=output_type_annotation,
|
||||
class_validators=None,
|
||||
config=cls.__config__,
|
||||
)
|
||||
cls.__fields__.update({"type": output_type_field})
|
||||
|
||||
# to support 3.9, 3.10 and 3.11, as described in https://docs.python.org/3/howto/annotations.html
|
||||
if annotations := cls.__dict__.get("__annotations__", None):
|
||||
annotations.update({"type": output_type_annotation})
|
||||
|
||||
def wrapper(cls: Type[T]) -> Type[T]:
|
||||
uiconf_name = cls.__qualname__ + ".UIConfig"
|
||||
if not hasattr(cls, "UIConfig") or cls.UIConfig.__qualname__ != uiconf_name:
|
||||
cls.UIConfig = type(uiconf_name, (UIConfigBase,), dict())
|
||||
cls.UIConfig.tags = list(tags)
|
||||
return cls
|
||||
|
||||
return wrapper
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654) and the InvokeAI Team
|
||||
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
@ -8,17 +7,15 @@ from pydantic import validator
|
||||
from invokeai.app.invocations.primitives import IntegerCollectionOutput
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, tags, title
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@title("Integer Range")
|
||||
@tags("collection", "integer", "range")
|
||||
@invocation(
|
||||
"range", title="Integer Range", tags=["collection", "integer", "range"], category="collections", version="1.0.0"
|
||||
)
|
||||
class RangeInvocation(BaseInvocation):
|
||||
"""Creates a range of numbers from start to stop with step"""
|
||||
|
||||
type: Literal["range"] = "range"
|
||||
|
||||
# Inputs
|
||||
start: int = InputField(default=0, description="The start of the range")
|
||||
stop: int = InputField(default=10, description="The stop of the range")
|
||||
step: int = InputField(default=1, description="The step of the range")
|
||||
@ -33,30 +30,37 @@ class RangeInvocation(BaseInvocation):
|
||||
return IntegerCollectionOutput(collection=list(range(self.start, self.stop, self.step)))
|
||||
|
||||
|
||||
@title("Integer Range of Size")
|
||||
@tags("range", "integer", "size", "collection")
|
||||
@invocation(
|
||||
"range_of_size",
|
||||
title="Integer Range of Size",
|
||||
tags=["collection", "integer", "size", "range"],
|
||||
category="collections",
|
||||
version="1.0.0",
|
||||
)
|
||||
class RangeOfSizeInvocation(BaseInvocation):
|
||||
"""Creates a range from start to start + size with step"""
|
||||
"""Creates a range from start to start + (size * step) incremented by step"""
|
||||
|
||||
type: Literal["range_of_size"] = "range_of_size"
|
||||
|
||||
# Inputs
|
||||
start: int = InputField(default=0, description="The start of the range")
|
||||
size: int = InputField(default=1, description="The number of values")
|
||||
size: int = InputField(default=1, gt=0, description="The number of values")
|
||||
step: int = InputField(default=1, description="The step of the range")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerCollectionOutput:
|
||||
return IntegerCollectionOutput(collection=list(range(self.start, self.start + self.size, self.step)))
|
||||
return IntegerCollectionOutput(
|
||||
collection=list(range(self.start, self.start + (self.step * self.size), self.step))
|
||||
)
|
||||
|
||||
|
||||
@title("Random Range")
|
||||
@tags("range", "integer", "random", "collection")
|
||||
@invocation(
|
||||
"random_range",
|
||||
title="Random Range",
|
||||
tags=["range", "integer", "random", "collection"],
|
||||
category="collections",
|
||||
version="1.0.0",
|
||||
use_cache=False,
|
||||
)
|
||||
class RandomRangeInvocation(BaseInvocation):
|
||||
"""Creates a collection of random numbers"""
|
||||
|
||||
type: Literal["random_range"] = "random_range"
|
||||
|
||||
# Inputs
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
size: int = InputField(default=1, description="The number of values to generate")
|
||||
|
||||
@ -1,21 +1,20 @@
|
||||
import re
|
||||
from dataclasses import dataclass
|
||||
from typing import List, Literal, Union
|
||||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
from compel import Compel, ReturnedEmbeddingsType
|
||||
from compel.prompt_parser import Blend, Conjunction, CrossAttentionControlSubstitute, FlattenedPrompt, Fragment
|
||||
from invokeai.app.invocations.primitives import ConditioningField, ConditioningOutput
|
||||
|
||||
from invokeai.backend.stable_diffusion.diffusion.shared_invokeai_diffusion import (
|
||||
from invokeai.app.invocations.primitives import ConditioningField, ConditioningOutput
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import (
|
||||
BasicConditioningInfo,
|
||||
ExtraConditioningInfo,
|
||||
SDXLConditioningInfo,
|
||||
)
|
||||
|
||||
from ...backend.model_management.models import ModelType
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import ModelNotFoundException
|
||||
from ...backend.stable_diffusion.diffusion import InvokeAIDiffuserComponent
|
||||
from ...backend.model_management.models import ModelNotFoundException, ModelType
|
||||
from ...backend.util.devices import torch_dtype
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
@ -26,8 +25,8 @@ from .baseinvocation import (
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIComponent,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from .model import ClipField
|
||||
|
||||
@ -44,13 +43,10 @@ class ConditioningFieldData:
|
||||
# PerpNeg = "perp_neg"
|
||||
|
||||
|
||||
@title("Compel Prompt")
|
||||
@tags("prompt", "compel")
|
||||
@invocation("compel", title="Prompt", tags=["prompt", "compel"], category="conditioning", version="1.0.0")
|
||||
class CompelInvocation(BaseInvocation):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
type: Literal["compel"] = "compel"
|
||||
|
||||
prompt: str = InputField(
|
||||
default="",
|
||||
description=FieldDescriptions.compel_prompt,
|
||||
@ -103,31 +99,31 @@ class CompelInvocation(BaseInvocation):
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with ModelPatcher.apply_lora_text_encoder(
|
||||
text_encoder_info.context.model, _lora_loader()
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, self.clip.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
with (
|
||||
ModelPatcher.apply_lora_text_encoder(text_encoder_info.context.model, _lora_loader()),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, self.clip.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
textual_inversion_manager=ti_manager,
|
||||
dtype_for_device_getter=torch_dtype,
|
||||
truncate_long_prompts=True,
|
||||
truncate_long_prompts=False,
|
||||
)
|
||||
|
||||
conjunction = Compel.parse_prompt_string(self.prompt)
|
||||
prompt: Union[FlattenedPrompt, Blend] = conjunction.prompts[0]
|
||||
|
||||
if context.services.configuration.log_tokenization:
|
||||
log_tokenization_for_prompt_object(prompt, tokenizer)
|
||||
log_tokenization_for_conjunction(conjunction, tokenizer)
|
||||
|
||||
c, options = compel.build_conditioning_tensor_for_prompt_object(prompt)
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
ec = ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@ -218,20 +214,21 @@ class SDXLPromptInvocationBase:
|
||||
# print(traceback.format_exc())
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
|
||||
with ModelPatcher.apply_lora(
|
||||
text_encoder_info.context.model, _lora_loader(), lora_prefix
|
||||
), ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
), ModelPatcher.apply_clip_skip(
|
||||
text_encoder_info.context.model, clip_field.skipped_layers
|
||||
), text_encoder_info as text_encoder:
|
||||
with (
|
||||
ModelPatcher.apply_lora(text_encoder_info.context.model, _lora_loader(), lora_prefix),
|
||||
ModelPatcher.apply_ti(tokenizer_info.context.model, text_encoder_info.context.model, ti_list) as (
|
||||
tokenizer,
|
||||
ti_manager,
|
||||
),
|
||||
ModelPatcher.apply_clip_skip(text_encoder_info.context.model, clip_field.skipped_layers),
|
||||
text_encoder_info as text_encoder,
|
||||
):
|
||||
compel = Compel(
|
||||
tokenizer=tokenizer,
|
||||
text_encoder=text_encoder,
|
||||
textual_inversion_manager=ti_manager,
|
||||
dtype_for_device_getter=torch_dtype,
|
||||
truncate_long_prompts=True, # TODO:
|
||||
truncate_long_prompts=False, # TODO:
|
||||
returned_embeddings_type=ReturnedEmbeddingsType.PENULTIMATE_HIDDEN_STATES_NON_NORMALIZED, # TODO: clip skip
|
||||
requires_pooled=get_pooled,
|
||||
)
|
||||
@ -240,8 +237,7 @@ class SDXLPromptInvocationBase:
|
||||
|
||||
if context.services.configuration.log_tokenization:
|
||||
# TODO: better logging for and syntax
|
||||
for prompt_obj in conjunction.prompts:
|
||||
log_tokenization_for_prompt_object(prompt_obj, tokenizer)
|
||||
log_tokenization_for_conjunction(conjunction, tokenizer)
|
||||
|
||||
# TODO: ask for optimizations? to not run text_encoder twice
|
||||
c, options = compel.build_conditioning_tensor_for_conjunction(conjunction)
|
||||
@ -250,7 +246,7 @@ class SDXLPromptInvocationBase:
|
||||
else:
|
||||
c_pooled = None
|
||||
|
||||
ec = InvokeAIDiffuserComponent.ExtraConditioningInfo(
|
||||
ec = ExtraConditioningInfo(
|
||||
tokens_count_including_eos_bos=get_max_token_count(tokenizer, conjunction),
|
||||
cross_attention_control_args=options.get("cross_attention_control", None),
|
||||
)
|
||||
@ -267,13 +263,16 @@ class SDXLPromptInvocationBase:
|
||||
return c, c_pooled, ec
|
||||
|
||||
|
||||
@title("SDXL Compel Prompt")
|
||||
@tags("sdxl", "compel", "prompt")
|
||||
@invocation(
|
||||
"sdxl_compel_prompt",
|
||||
title="SDXL Prompt",
|
||||
tags=["sdxl", "compel", "prompt"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
type: Literal["sdxl_compel_prompt"] = "sdxl_compel_prompt"
|
||||
|
||||
prompt: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
style: str = InputField(default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea)
|
||||
original_width: int = InputField(default=1024, description="")
|
||||
@ -282,8 +281,8 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
crop_left: int = InputField(default=0, description="")
|
||||
target_width: int = InputField(default=1024, description="")
|
||||
target_height: int = InputField(default=1024, description="")
|
||||
clip: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection)
|
||||
clip2: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection)
|
||||
clip: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 1")
|
||||
clip2: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 2")
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
@ -305,6 +304,29 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
|
||||
add_time_ids = torch.tensor([original_size + crop_coords + target_size])
|
||||
|
||||
# [1, 77, 768], [1, 154, 1280]
|
||||
if c1.shape[1] < c2.shape[1]:
|
||||
c1 = torch.cat(
|
||||
[
|
||||
c1,
|
||||
torch.zeros(
|
||||
(c1.shape[0], c2.shape[1] - c1.shape[1], c1.shape[2]), device=c1.device, dtype=c1.dtype
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
)
|
||||
|
||||
elif c1.shape[1] > c2.shape[1]:
|
||||
c2 = torch.cat(
|
||||
[
|
||||
c2,
|
||||
torch.zeros(
|
||||
(c2.shape[0], c1.shape[1] - c2.shape[1], c2.shape[2]), device=c2.device, dtype=c2.dtype
|
||||
),
|
||||
],
|
||||
dim=1,
|
||||
)
|
||||
|
||||
conditioning_data = ConditioningFieldData(
|
||||
conditionings=[
|
||||
SDXLConditioningInfo(
|
||||
@ -326,13 +348,16 @@ class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
)
|
||||
|
||||
|
||||
@title("SDXL Refiner Compel Prompt")
|
||||
@tags("sdxl", "compel", "prompt")
|
||||
@invocation(
|
||||
"sdxl_refiner_compel_prompt",
|
||||
title="SDXL Refiner Prompt",
|
||||
tags=["sdxl", "compel", "prompt"],
|
||||
category="conditioning",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
|
||||
"""Parse prompt using compel package to conditioning."""
|
||||
|
||||
type: Literal["sdxl_refiner_compel_prompt"] = "sdxl_refiner_compel_prompt"
|
||||
|
||||
style: str = InputField(
|
||||
default="", description=FieldDescriptions.compel_prompt, ui_component=UIComponent.Textarea
|
||||
) # TODO: ?
|
||||
@ -374,20 +399,17 @@ class SDXLRefinerCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("clip_skip_output")
|
||||
class ClipSkipInvocationOutput(BaseInvocationOutput):
|
||||
"""Clip skip node output"""
|
||||
|
||||
type: Literal["clip_skip_output"] = "clip_skip_output"
|
||||
clip: ClipField = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
|
||||
|
||||
@title("CLIP Skip")
|
||||
@tags("clipskip", "clip", "skip")
|
||||
@invocation("clip_skip", title="CLIP Skip", tags=["clipskip", "clip", "skip"], category="conditioning", version="1.0.0")
|
||||
class ClipSkipInvocation(BaseInvocation):
|
||||
"""Skip layers in clip text_encoder model."""
|
||||
|
||||
type: Literal["clip_skip"] = "clip_skip"
|
||||
|
||||
clip: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection, title="CLIP")
|
||||
skipped_layers: int = InputField(default=0, description=FieldDescriptions.skipped_layers)
|
||||
|
||||
@ -416,9 +438,11 @@ def get_tokens_for_prompt_object(tokenizer, parsed_prompt: FlattenedPrompt, trun
|
||||
raise ValueError("Blend is not supported here - you need to get tokens for each of its .children")
|
||||
|
||||
text_fragments = [
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
(
|
||||
x.text
|
||||
if type(x) is Fragment
|
||||
else (" ".join([f.text for f in x.original]) if type(x) is CrossAttentionControlSubstitute else str(x))
|
||||
)
|
||||
for x in parsed_prompt.children
|
||||
]
|
||||
text = " ".join(text_fragments)
|
||||
|
||||
@ -28,23 +28,20 @@ from pydantic import BaseModel, Field, validator
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
|
||||
|
||||
from ...backend.model_management import BaseModelType
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
InputField,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
|
||||
|
||||
CONTROLNET_MODE_VALUES = Literal["balanced", "more_prompt", "more_control", "unbalanced"]
|
||||
CONTROLNET_RESIZE_VALUES = Literal[
|
||||
"just_resize",
|
||||
@ -87,29 +84,22 @@ class ControlField(BaseModel):
|
||||
return v
|
||||
|
||||
|
||||
@invocation_output("control_output")
|
||||
class ControlOutput(BaseInvocationOutput):
|
||||
"""node output for ControlNet info"""
|
||||
|
||||
type: Literal["control_output"] = "control_output"
|
||||
|
||||
# Outputs
|
||||
control: ControlField = OutputField(description=FieldDescriptions.control)
|
||||
|
||||
|
||||
@title("ControlNet")
|
||||
@tags("controlnet")
|
||||
@invocation("controlnet", title="ControlNet", tags=["controlnet"], category="controlnet", version="1.0.0")
|
||||
class ControlNetInvocation(BaseInvocation):
|
||||
"""Collects ControlNet info to pass to other nodes"""
|
||||
|
||||
type: Literal["controlnet"] = "controlnet"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The control image")
|
||||
control_model: ControlNetModelField = InputField(
|
||||
default="lllyasviel/sd-controlnet-canny", description=FieldDescriptions.controlnet_model, input=Input.Direct
|
||||
)
|
||||
control_model: ControlNetModelField = InputField(description=FieldDescriptions.controlnet_model, input=Input.Direct)
|
||||
control_weight: Union[float, List[float]] = InputField(
|
||||
default=1.0, description="The weight given to the ControlNet", ui_type=UIType.Float
|
||||
default=1.0, description="The weight given to the ControlNet"
|
||||
)
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the ControlNet is first applied (% of total steps)"
|
||||
@ -134,12 +124,12 @@ class ControlNetInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"image_processor", title="Base Image Processor", tags=["controlnet"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
class ImageProcessorInvocation(BaseInvocation):
|
||||
"""Base class for invocations that preprocess images for ControlNet"""
|
||||
|
||||
type: Literal["image_processor"] = "image_processor"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to process")
|
||||
|
||||
def run_processor(self, image):
|
||||
@ -151,11 +141,6 @@ class ImageProcessorInvocation(BaseInvocation):
|
||||
# image type should be PIL.PngImagePlugin.PngImageFile ?
|
||||
processed_image = self.run_processor(raw_image)
|
||||
|
||||
# FIXME: what happened to image metadata?
|
||||
# metadata = context.services.metadata.build_metadata(
|
||||
# session_id=context.graph_execution_state_id, node=self
|
||||
# )
|
||||
|
||||
# currently can't see processed image in node UI without a showImage node,
|
||||
# so for now setting image_type to RESULT instead of INTERMEDIATE so will get saved in gallery
|
||||
image_dto = context.services.images.create(
|
||||
@ -165,6 +150,7 @@ class ImageProcessorInvocation(BaseInvocation):
|
||||
session_id=context.graph_execution_state_id,
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
"""Builds an ImageOutput and its ImageField"""
|
||||
@ -179,14 +165,16 @@ class ImageProcessorInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Canny Processor")
|
||||
@tags("controlnet", "canny")
|
||||
@invocation(
|
||||
"canny_image_processor",
|
||||
title="Canny Processor",
|
||||
tags=["controlnet", "canny"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class CannyImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Canny edge detection for ControlNet"""
|
||||
|
||||
type: Literal["canny_image_processor"] = "canny_image_processor"
|
||||
|
||||
# Input
|
||||
low_threshold: int = InputField(
|
||||
default=100, ge=0, le=255, description="The low threshold of the Canny pixel gradient (0-255)"
|
||||
)
|
||||
@ -200,14 +188,16 @@ class CannyImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("HED (softedge) Processor")
|
||||
@tags("controlnet", "hed", "softedge")
|
||||
@invocation(
|
||||
"hed_image_processor",
|
||||
title="HED (softedge) Processor",
|
||||
tags=["controlnet", "hed", "softedge"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class HedImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies HED edge detection to image"""
|
||||
|
||||
type: Literal["hed_image_processor"] = "hed_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
# safe not supported in controlnet_aux v0.0.3
|
||||
@ -227,14 +217,16 @@ class HedImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Lineart Processor")
|
||||
@tags("controlnet", "lineart")
|
||||
@invocation(
|
||||
"lineart_image_processor",
|
||||
title="Lineart Processor",
|
||||
tags=["controlnet", "lineart"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LineartImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies line art processing to image"""
|
||||
|
||||
type: Literal["lineart_image_processor"] = "lineart_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
coarse: bool = InputField(default=False, description="Whether to use coarse mode")
|
||||
@ -247,14 +239,16 @@ class LineartImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Lineart Anime Processor")
|
||||
@tags("controlnet", "lineart", "anime")
|
||||
@invocation(
|
||||
"lineart_anime_image_processor",
|
||||
title="Lineart Anime Processor",
|
||||
tags=["controlnet", "lineart", "anime"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LineartAnimeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies line art anime processing to image"""
|
||||
|
||||
type: Literal["lineart_anime_image_processor"] = "lineart_anime_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
|
||||
@ -268,14 +262,16 @@ class LineartAnimeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Openpose Processor")
|
||||
@tags("controlnet", "openpose", "pose")
|
||||
@invocation(
|
||||
"openpose_image_processor",
|
||||
title="Openpose Processor",
|
||||
tags=["controlnet", "openpose", "pose"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class OpenposeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies Openpose processing to image"""
|
||||
|
||||
type: Literal["openpose_image_processor"] = "openpose_image_processor"
|
||||
|
||||
# Inputs
|
||||
hand_and_face: bool = InputField(default=False, description="Whether to use hands and face mode")
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
@ -291,14 +287,16 @@ class OpenposeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Midas (Depth) Processor")
|
||||
@tags("controlnet", "midas", "depth")
|
||||
@invocation(
|
||||
"midas_depth_image_processor",
|
||||
title="Midas Depth Processor",
|
||||
tags=["controlnet", "midas"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MidasDepthImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies Midas depth processing to image"""
|
||||
|
||||
type: Literal["midas_depth_image_processor"] = "midas_depth_image_processor"
|
||||
|
||||
# Inputs
|
||||
a_mult: float = InputField(default=2.0, ge=0, description="Midas parameter `a_mult` (a = a_mult * PI)")
|
||||
bg_th: float = InputField(default=0.1, ge=0, description="Midas parameter `bg_th`")
|
||||
# depth_and_normal not supported in controlnet_aux v0.0.3
|
||||
@ -316,14 +314,16 @@ class MidasDepthImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Normal BAE Processor")
|
||||
@tags("controlnet", "normal", "bae")
|
||||
@invocation(
|
||||
"normalbae_image_processor",
|
||||
title="Normal BAE Processor",
|
||||
tags=["controlnet"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class NormalbaeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies NormalBae processing to image"""
|
||||
|
||||
type: Literal["normalbae_image_processor"] = "normalbae_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
|
||||
@ -335,14 +335,12 @@ class NormalbaeImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("MLSD Processor")
|
||||
@tags("controlnet", "mlsd")
|
||||
@invocation(
|
||||
"mlsd_image_processor", title="MLSD Processor", tags=["controlnet", "mlsd"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
class MlsdImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies MLSD processing to image"""
|
||||
|
||||
type: Literal["mlsd_image_processor"] = "mlsd_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
thr_v: float = InputField(default=0.1, ge=0, description="MLSD parameter `thr_v`")
|
||||
@ -360,14 +358,12 @@ class MlsdImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("PIDI Processor")
|
||||
@tags("controlnet", "pidi")
|
||||
@invocation(
|
||||
"pidi_image_processor", title="PIDI Processor", tags=["controlnet", "pidi"], category="controlnet", version="1.0.0"
|
||||
)
|
||||
class PidiImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies PIDI processing to image"""
|
||||
|
||||
type: Literal["pidi_image_processor"] = "pidi_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
safe: bool = InputField(default=False, description=FieldDescriptions.safe_mode)
|
||||
@ -385,14 +381,16 @@ class PidiImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Content Shuffle Processor")
|
||||
@tags("controlnet", "contentshuffle")
|
||||
@invocation(
|
||||
"content_shuffle_image_processor",
|
||||
title="Content Shuffle Processor",
|
||||
tags=["controlnet", "contentshuffle"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ContentShuffleImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies content shuffle processing to image"""
|
||||
|
||||
type: Literal["content_shuffle_image_processor"] = "content_shuffle_image_processor"
|
||||
|
||||
# Inputs
|
||||
detect_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.detect_res)
|
||||
image_resolution: int = InputField(default=512, ge=0, description=FieldDescriptions.image_res)
|
||||
h: Optional[int] = InputField(default=512, ge=0, description="Content shuffle `h` parameter")
|
||||
@ -413,27 +411,32 @@ class ContentShuffleImageProcessorInvocation(ImageProcessorInvocation):
|
||||
|
||||
|
||||
# should work with controlnet_aux >= 0.0.4 and timm <= 0.6.13
|
||||
@title("Zoe (Depth) Processor")
|
||||
@tags("controlnet", "zoe", "depth")
|
||||
@invocation(
|
||||
"zoe_depth_image_processor",
|
||||
title="Zoe (Depth) Processor",
|
||||
tags=["controlnet", "zoe", "depth"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ZoeDepthImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies Zoe depth processing to image"""
|
||||
|
||||
type: Literal["zoe_depth_image_processor"] = "zoe_depth_image_processor"
|
||||
|
||||
def run_processor(self, image):
|
||||
zoe_depth_processor = ZoeDetector.from_pretrained("lllyasviel/Annotators")
|
||||
processed_image = zoe_depth_processor(image)
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Mediapipe Face Processor")
|
||||
@tags("controlnet", "mediapipe", "face")
|
||||
@invocation(
|
||||
"mediapipe_face_processor",
|
||||
title="Mediapipe Face Processor",
|
||||
tags=["controlnet", "mediapipe", "face"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class MediapipeFaceProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies mediapipe face processing to image"""
|
||||
|
||||
type: Literal["mediapipe_face_processor"] = "mediapipe_face_processor"
|
||||
|
||||
# Inputs
|
||||
max_faces: int = InputField(default=1, ge=1, description="Maximum number of faces to detect")
|
||||
min_confidence: float = InputField(default=0.5, ge=0, le=1, description="Minimum confidence for face detection")
|
||||
|
||||
@ -447,14 +450,16 @@ class MediapipeFaceProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Leres (Depth) Processor")
|
||||
@tags("controlnet", "leres", "depth")
|
||||
@invocation(
|
||||
"leres_image_processor",
|
||||
title="Leres (Depth) Processor",
|
||||
tags=["controlnet", "leres", "depth"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LeresImageProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies leres processing to image"""
|
||||
|
||||
type: Literal["leres_image_processor"] = "leres_image_processor"
|
||||
|
||||
# Inputs
|
||||
thr_a: float = InputField(default=0, description="Leres parameter `thr_a`")
|
||||
thr_b: float = InputField(default=0, description="Leres parameter `thr_b`")
|
||||
boost: bool = InputField(default=False, description="Whether to use boost mode")
|
||||
@ -474,14 +479,16 @@ class LeresImageProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Tile Resample Processor")
|
||||
@tags("controlnet", "tile")
|
||||
@invocation(
|
||||
"tile_image_processor",
|
||||
title="Tile Resample Processor",
|
||||
tags=["controlnet", "tile"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class TileResamplerProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Tile resampler processor"""
|
||||
|
||||
type: Literal["tile_image_processor"] = "tile_image_processor"
|
||||
|
||||
# Inputs
|
||||
# res: int = InputField(default=512, ge=0, le=1024, description="The pixel resolution for each tile")
|
||||
down_sampling_rate: float = InputField(default=1.0, ge=1.0, le=8.0, description="Down sampling rate")
|
||||
|
||||
@ -512,13 +519,16 @@ class TileResamplerProcessorInvocation(ImageProcessorInvocation):
|
||||
return processed_image
|
||||
|
||||
|
||||
@title("Segment Anything Processor")
|
||||
@tags("controlnet", "segmentanything")
|
||||
@invocation(
|
||||
"segment_anything_processor",
|
||||
title="Segment Anything Processor",
|
||||
tags=["controlnet", "segmentanything"],
|
||||
category="controlnet",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SegmentAnythingProcessorInvocation(ImageProcessorInvocation):
|
||||
"""Applies segment anything processing to image"""
|
||||
|
||||
type: Literal["segment_anything_processor"] = "segment_anything_processor"
|
||||
|
||||
def run_processor(self, image):
|
||||
# segment_anything_processor = SamDetector.from_pretrained("ybelkada/segment-anything", subfolder="checkpoints")
|
||||
segment_anything_processor = SamDetectorReproducibleColors.from_pretrained(
|
||||
|
||||
@ -1,24 +1,20 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from typing import Literal
|
||||
|
||||
import cv2 as cv
|
||||
import numpy
|
||||
from PIL import Image, ImageOps
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, tags, title
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@title("OpenCV Inpaint")
|
||||
@tags("opencv", "inpaint")
|
||||
@invocation("cv_inpaint", title="OpenCV Inpaint", tags=["opencv", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class CvInpaintInvocation(BaseInvocation):
|
||||
"""Simple inpaint using opencv."""
|
||||
|
||||
type: Literal["cv_inpaint"] = "cv_inpaint"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to inpaint")
|
||||
mask: ImageField = InputField(description="The mask to use when inpainting")
|
||||
|
||||
@ -45,6 +41,7 @@ class CvInpaintInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
|
||||
@ -13,18 +13,13 @@ from invokeai.backend.image_util.invisible_watermark import InvisibleWatermark
|
||||
from invokeai.backend.image_util.safety_checker import SafetyChecker
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, tags, title
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@title("Show Image")
|
||||
@tags("image")
|
||||
@invocation("show_image", title="Show Image", tags=["image"], category="image", version="1.0.0")
|
||||
class ShowImageInvocation(BaseInvocation):
|
||||
"""Displays a provided image, and passes it forward in the pipeline."""
|
||||
"""Displays a provided image using the OS image viewer, and passes it forward in the pipeline."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["show_image"] = "show_image"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to show")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
@ -41,15 +36,10 @@ class ShowImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Blank Image")
|
||||
@tags("image")
|
||||
@invocation("blank_image", title="Blank Image", tags=["image"], category="image", version="1.0.0")
|
||||
class BlankImageInvocation(BaseInvocation):
|
||||
"""Creates a blank image and forwards it to the pipeline"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["blank_image"] = "blank_image"
|
||||
|
||||
# Inputs
|
||||
width: int = InputField(default=512, description="The width of the image")
|
||||
height: int = InputField(default=512, description="The height of the image")
|
||||
mode: Literal["RGB", "RGBA"] = InputField(default="RGB", description="The mode of the image")
|
||||
@ -65,6 +55,7 @@ class BlankImageInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -74,15 +65,10 @@ class BlankImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Crop Image")
|
||||
@tags("image", "crop")
|
||||
@invocation("img_crop", title="Crop Image", tags=["image", "crop"], category="image", version="1.0.0")
|
||||
class ImageCropInvocation(BaseInvocation):
|
||||
"""Crops an image to a specified box. The box can be outside of the image."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_crop"] = "img_crop"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to crop")
|
||||
x: int = InputField(default=0, description="The left x coordinate of the crop rectangle")
|
||||
y: int = InputField(default=0, description="The top y coordinate of the crop rectangle")
|
||||
@ -102,6 +88,7 @@ class ImageCropInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -111,15 +98,10 @@ class ImageCropInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Paste Image")
|
||||
@tags("image", "paste")
|
||||
@invocation("img_paste", title="Paste Image", tags=["image", "paste"], category="image", version="1.0.1")
|
||||
class ImagePasteInvocation(BaseInvocation):
|
||||
"""Pastes an image into another image."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_paste"] = "img_paste"
|
||||
|
||||
# Inputs
|
||||
base_image: ImageField = InputField(description="The base image")
|
||||
image: ImageField = InputField(description="The image to paste")
|
||||
mask: Optional[ImageField] = InputField(
|
||||
@ -128,6 +110,7 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
)
|
||||
x: int = InputField(default=0, description="The left x coordinate at which to paste the image")
|
||||
y: int = InputField(default=0, description="The top y coordinate at which to paste the image")
|
||||
crop: bool = InputField(default=False, description="Crop to base image dimensions")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
base_image = context.services.images.get_pil_image(self.base_image.image_name)
|
||||
@ -147,6 +130,10 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
new_image.paste(base_image, (abs(min_x), abs(min_y)))
|
||||
new_image.paste(image, (max(0, self.x), max(0, self.y)), mask=mask)
|
||||
|
||||
if self.crop:
|
||||
base_w, base_h = base_image.size
|
||||
new_image = new_image.crop((abs(min_x), abs(min_y), abs(min_x) + base_w, abs(min_y) + base_h))
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=new_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
@ -154,6 +141,7 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -163,15 +151,10 @@ class ImagePasteInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Mask from Alpha")
|
||||
@tags("image", "mask")
|
||||
@invocation("tomask", title="Mask from Alpha", tags=["image", "mask"], category="image", version="1.0.0")
|
||||
class MaskFromAlphaInvocation(BaseInvocation):
|
||||
"""Extracts the alpha channel of an image as a mask."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["tomask"] = "tomask"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to create the mask from")
|
||||
invert: bool = InputField(default=False, description="Whether or not to invert the mask")
|
||||
|
||||
@ -189,6 +172,7 @@ class MaskFromAlphaInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -198,15 +182,10 @@ class MaskFromAlphaInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Multiply Images")
|
||||
@tags("image", "multiply")
|
||||
@invocation("img_mul", title="Multiply Images", tags=["image", "multiply"], category="image", version="1.0.0")
|
||||
class ImageMultiplyInvocation(BaseInvocation):
|
||||
"""Multiplies two images together using `PIL.ImageChops.multiply()`."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_mul"] = "img_mul"
|
||||
|
||||
# Inputs
|
||||
image1: ImageField = InputField(description="The first image to multiply")
|
||||
image2: ImageField = InputField(description="The second image to multiply")
|
||||
|
||||
@ -223,6 +202,7 @@ class ImageMultiplyInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -235,15 +215,10 @@ class ImageMultiplyInvocation(BaseInvocation):
|
||||
IMAGE_CHANNELS = Literal["A", "R", "G", "B"]
|
||||
|
||||
|
||||
@title("Extract Image Channel")
|
||||
@tags("image", "channel")
|
||||
@invocation("img_chan", title="Extract Image Channel", tags=["image", "channel"], category="image", version="1.0.0")
|
||||
class ImageChannelInvocation(BaseInvocation):
|
||||
"""Gets a channel from an image."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_chan"] = "img_chan"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to get the channel from")
|
||||
channel: IMAGE_CHANNELS = InputField(default="A", description="The channel to get")
|
||||
|
||||
@ -259,6 +234,7 @@ class ImageChannelInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -271,15 +247,10 @@ class ImageChannelInvocation(BaseInvocation):
|
||||
IMAGE_MODES = Literal["L", "RGB", "RGBA", "CMYK", "YCbCr", "LAB", "HSV", "I", "F"]
|
||||
|
||||
|
||||
@title("Convert Image Mode")
|
||||
@tags("image", "convert")
|
||||
@invocation("img_conv", title="Convert Image Mode", tags=["image", "convert"], category="image", version="1.0.0")
|
||||
class ImageConvertInvocation(BaseInvocation):
|
||||
"""Converts an image to a different mode."""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_conv"] = "img_conv"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to convert")
|
||||
mode: IMAGE_MODES = InputField(default="L", description="The mode to convert to")
|
||||
|
||||
@ -295,6 +266,7 @@ class ImageConvertInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -304,15 +276,10 @@ class ImageConvertInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Blur Image")
|
||||
@tags("image", "blur")
|
||||
@invocation("img_blur", title="Blur Image", tags=["image", "blur"], category="image", version="1.0.0")
|
||||
class ImageBlurInvocation(BaseInvocation):
|
||||
"""Blurs an image"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_blur"] = "img_blur"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to blur")
|
||||
radius: float = InputField(default=8.0, ge=0, description="The blur radius")
|
||||
# Metadata
|
||||
@ -333,6 +300,7 @@ class ImageBlurInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -362,19 +330,17 @@ PIL_RESAMPLING_MAP = {
|
||||
}
|
||||
|
||||
|
||||
@title("Resize Image")
|
||||
@tags("image", "resize")
|
||||
@invocation("img_resize", title="Resize Image", tags=["image", "resize"], category="image", version="1.0.0")
|
||||
class ImageResizeInvocation(BaseInvocation):
|
||||
"""Resizes an image to specific dimensions"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_resize"] = "img_resize"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to resize")
|
||||
width: int = InputField(default=512, ge=64, multiple_of=8, description="The width to resize to (px)")
|
||||
height: int = InputField(default=512, ge=64, multiple_of=8, description="The height to resize to (px)")
|
||||
width: int = InputField(default=512, gt=0, description="The width to resize to (px)")
|
||||
height: int = InputField(default=512, gt=0, description="The height to resize to (px)")
|
||||
resample_mode: PIL_RESAMPLING_MODES = InputField(default="bicubic", description="The resampling mode")
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None, description=FieldDescriptions.core_metadata, ui_hidden=True
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
@ -393,6 +359,8 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -402,15 +370,10 @@ class ImageResizeInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Scale Image")
|
||||
@tags("image", "scale")
|
||||
@invocation("img_scale", title="Scale Image", tags=["image", "scale"], category="image", version="1.0.0")
|
||||
class ImageScaleInvocation(BaseInvocation):
|
||||
"""Scales an image by a factor"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_scale"] = "img_scale"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to scale")
|
||||
scale_factor: float = InputField(
|
||||
default=2.0,
|
||||
@ -438,6 +401,7 @@ class ImageScaleInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -447,15 +411,10 @@ class ImageScaleInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Lerp Image")
|
||||
@tags("image", "lerp")
|
||||
@invocation("img_lerp", title="Lerp Image", tags=["image", "lerp"], category="image", version="1.0.0")
|
||||
class ImageLerpInvocation(BaseInvocation):
|
||||
"""Linear interpolation of all pixels of an image"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_lerp"] = "img_lerp"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to lerp")
|
||||
min: int = InputField(default=0, ge=0, le=255, description="The minimum output value")
|
||||
max: int = InputField(default=255, ge=0, le=255, description="The maximum output value")
|
||||
@ -475,6 +434,7 @@ class ImageLerpInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -484,15 +444,10 @@ class ImageLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Inverse Lerp Image")
|
||||
@tags("image", "ilerp")
|
||||
@invocation("img_ilerp", title="Inverse Lerp Image", tags=["image", "ilerp"], category="image", version="1.0.0")
|
||||
class ImageInverseLerpInvocation(BaseInvocation):
|
||||
"""Inverse linear interpolation of all pixels of an image"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_ilerp"] = "img_ilerp"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to lerp")
|
||||
min: int = InputField(default=0, ge=0, le=255, description="The minimum input value")
|
||||
max: int = InputField(default=255, ge=0, le=255, description="The maximum input value")
|
||||
@ -512,6 +467,7 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -521,15 +477,10 @@ class ImageInverseLerpInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Blur NSFW Image")
|
||||
@tags("image", "nsfw")
|
||||
@invocation("img_nsfw", title="Blur NSFW Image", tags=["image", "nsfw"], category="image", version="1.0.0")
|
||||
class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
"""Add blur to NSFW-flagged images"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_nsfw"] = "img_nsfw"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to check")
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
default=None, description=FieldDescriptions.core_metadata, ui_hidden=True
|
||||
@ -555,6 +506,7 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -570,15 +522,12 @@ class ImageNSFWBlurInvocation(BaseInvocation):
|
||||
return caution.resize((caution.width // 2, caution.height // 2))
|
||||
|
||||
|
||||
@title("Add Invisible Watermark")
|
||||
@tags("image", "watermark")
|
||||
@invocation(
|
||||
"img_watermark", title="Add Invisible Watermark", tags=["image", "watermark"], category="image", version="1.0.0"
|
||||
)
|
||||
class ImageWatermarkInvocation(BaseInvocation):
|
||||
"""Add an invisible watermark to an image"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["img_watermark"] = "img_watermark"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to check")
|
||||
text: str = InputField(default="InvokeAI", description="Watermark text")
|
||||
metadata: Optional[CoreMetadata] = InputField(
|
||||
@ -596,6 +545,7 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -605,14 +555,10 @@ class ImageWatermarkInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Mask Edge")
|
||||
@tags("image", "mask", "inpaint")
|
||||
@invocation("mask_edge", title="Mask Edge", tags=["image", "mask", "inpaint"], category="image", version="1.0.0")
|
||||
class MaskEdgeInvocation(BaseInvocation):
|
||||
"""Applies an edge mask to an image"""
|
||||
|
||||
type: Literal["mask_edge"] = "mask_edge"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to apply the mask to")
|
||||
edge_size: int = InputField(description="The size of the edge")
|
||||
edge_blur: int = InputField(description="The amount of blur on the edge")
|
||||
@ -622,7 +568,7 @@ class MaskEdgeInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
mask = context.services.images.get_pil_image(self.image.image_name)
|
||||
mask = context.services.images.get_pil_image(self.image.image_name).convert("L")
|
||||
|
||||
npimg = numpy.asarray(mask, dtype=numpy.uint8)
|
||||
npgradient = numpy.uint8(255 * (1.0 - numpy.floor(numpy.abs(0.5 - numpy.float32(npimg) / 255.0) * 2.0)))
|
||||
@ -644,6 +590,7 @@ class MaskEdgeInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -653,14 +600,12 @@ class MaskEdgeInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Combine Mask")
|
||||
@tags("image", "mask", "multiply")
|
||||
@invocation(
|
||||
"mask_combine", title="Combine Masks", tags=["image", "mask", "multiply"], category="image", version="1.0.0"
|
||||
)
|
||||
class MaskCombineInvocation(BaseInvocation):
|
||||
"""Combine two masks together by multiplying them using `PIL.ImageChops.multiply()`."""
|
||||
|
||||
type: Literal["mask_combine"] = "mask_combine"
|
||||
|
||||
# Inputs
|
||||
mask1: ImageField = InputField(description="The first mask to combine")
|
||||
mask2: ImageField = InputField(description="The second image to combine")
|
||||
|
||||
@ -677,6 +622,7 @@ class MaskCombineInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -686,30 +632,32 @@ class MaskCombineInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Color Correct")
|
||||
@tags("image", "color")
|
||||
@invocation("color_correct", title="Color Correct", tags=["image", "color"], category="image", version="1.0.0")
|
||||
class ColorCorrectInvocation(BaseInvocation):
|
||||
"""
|
||||
Shifts the colors of a target image to match the reference image, optionally
|
||||
using a mask to only color-correct certain regions of the target image.
|
||||
"""
|
||||
|
||||
type: Literal["color_correct"] = "color_correct"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to color-correct")
|
||||
reference: ImageField = InputField(description="Reference image for color-correction")
|
||||
mask: Optional[ImageField] = InputField(default=None, description="Mask to use when applying color-correction")
|
||||
mask_blur_radius: float = InputField(default=8, description="Mask blur radius")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
result = context.services.images.get_pil_image(self.image.image_name).convert("RGBA")
|
||||
|
||||
init_image = context.services.images.get_pil_image(self.reference.image_name)
|
||||
# fit reference image to the input image
|
||||
if init_image.size != result.size:
|
||||
init_image = init_image.resize((result.width, result.height), Image.BILINEAR)
|
||||
|
||||
pil_init_mask = None
|
||||
if self.mask is not None:
|
||||
pil_init_mask = context.services.images.get_pil_image(self.mask.image_name).convert("L")
|
||||
|
||||
init_image = context.services.images.get_pil_image(self.reference.image_name)
|
||||
|
||||
result = context.services.images.get_pil_image(self.image.image_name).convert("RGBA")
|
||||
# fit mask to the input image
|
||||
if pil_init_mask.size != result.size:
|
||||
pil_init_mask = pil_init_mask.resize((result.width, result.height), Image.BILINEAR)
|
||||
|
||||
# if init_image is None or init_mask is None:
|
||||
# return result
|
||||
@ -763,8 +711,13 @@ class ColorCorrectInvocation(BaseInvocation):
|
||||
# Blur the mask out (into init image) by specified amount
|
||||
if self.mask_blur_radius > 0:
|
||||
nm = numpy.asarray(pil_init_mask, dtype=numpy.uint8)
|
||||
inverted_nm = 255 - nm
|
||||
dilation_size = int(round(self.mask_blur_radius) + 20)
|
||||
dilating_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (dilation_size, dilation_size))
|
||||
inverted_dilated_nm = cv2.dilate(inverted_nm, dilating_kernel)
|
||||
dilated_nm = 255 - inverted_dilated_nm
|
||||
nmd = cv2.erode(
|
||||
nm,
|
||||
dilated_nm,
|
||||
kernel=numpy.ones((3, 3), dtype=numpy.uint8),
|
||||
iterations=int(self.mask_blur_radius / 2),
|
||||
)
|
||||
@ -785,6 +738,7 @@ class ColorCorrectInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -794,14 +748,10 @@ class ColorCorrectInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Image Hue Adjustment")
|
||||
@tags("image", "hue", "hsl")
|
||||
@invocation("img_hue_adjust", title="Adjust Image Hue", tags=["image", "hue"], category="image", version="1.0.0")
|
||||
class ImageHueAdjustmentInvocation(BaseInvocation):
|
||||
"""Adjusts the Hue of an image."""
|
||||
|
||||
type: Literal["img_hue_adjust"] = "img_hue_adjust"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to adjust")
|
||||
hue: int = InputField(default=0, description="The degrees by which to rotate the hue, 0-360")
|
||||
|
||||
@ -827,6 +777,7 @@ class ImageHueAdjustmentInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
session_id=context.graph_execution_state_id,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -838,99 +789,224 @@ class ImageHueAdjustmentInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Image Luminosity Adjustment")
|
||||
@tags("image", "luminosity", "hsl")
|
||||
class ImageLuminosityAdjustmentInvocation(BaseInvocation):
|
||||
"""Adjusts the Luminosity (Value) of an image."""
|
||||
COLOR_CHANNELS = Literal[
|
||||
"Red (RGBA)",
|
||||
"Green (RGBA)",
|
||||
"Blue (RGBA)",
|
||||
"Alpha (RGBA)",
|
||||
"Cyan (CMYK)",
|
||||
"Magenta (CMYK)",
|
||||
"Yellow (CMYK)",
|
||||
"Black (CMYK)",
|
||||
"Hue (HSV)",
|
||||
"Saturation (HSV)",
|
||||
"Value (HSV)",
|
||||
"Luminosity (LAB)",
|
||||
"A (LAB)",
|
||||
"B (LAB)",
|
||||
"Y (YCbCr)",
|
||||
"Cb (YCbCr)",
|
||||
"Cr (YCbCr)",
|
||||
]
|
||||
|
||||
type: Literal["img_luminosity_adjust"] = "img_luminosity_adjust"
|
||||
CHANNEL_FORMATS = {
|
||||
"Red (RGBA)": ("RGBA", 0),
|
||||
"Green (RGBA)": ("RGBA", 1),
|
||||
"Blue (RGBA)": ("RGBA", 2),
|
||||
"Alpha (RGBA)": ("RGBA", 3),
|
||||
"Cyan (CMYK)": ("CMYK", 0),
|
||||
"Magenta (CMYK)": ("CMYK", 1),
|
||||
"Yellow (CMYK)": ("CMYK", 2),
|
||||
"Black (CMYK)": ("CMYK", 3),
|
||||
"Hue (HSV)": ("HSV", 0),
|
||||
"Saturation (HSV)": ("HSV", 1),
|
||||
"Value (HSV)": ("HSV", 2),
|
||||
"Luminosity (LAB)": ("LAB", 0),
|
||||
"A (LAB)": ("LAB", 1),
|
||||
"B (LAB)": ("LAB", 2),
|
||||
"Y (YCbCr)": ("YCbCr", 0),
|
||||
"Cb (YCbCr)": ("YCbCr", 1),
|
||||
"Cr (YCbCr)": ("YCbCr", 2),
|
||||
}
|
||||
|
||||
|
||||
@invocation(
|
||||
"img_channel_offset",
|
||||
title="Offset Image Channel",
|
||||
tags=[
|
||||
"image",
|
||||
"offset",
|
||||
"red",
|
||||
"green",
|
||||
"blue",
|
||||
"alpha",
|
||||
"cyan",
|
||||
"magenta",
|
||||
"yellow",
|
||||
"black",
|
||||
"hue",
|
||||
"saturation",
|
||||
"luminosity",
|
||||
"value",
|
||||
],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageChannelOffsetInvocation(BaseInvocation):
|
||||
"""Add or subtract a value from a specific color channel of an image."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to adjust")
|
||||
luminosity: float = InputField(
|
||||
default=1.0, ge=0, le=1, description="The factor by which to adjust the luminosity (value)"
|
||||
channel: COLOR_CHANNELS = InputField(description="Which channel to adjust")
|
||||
offset: int = InputField(default=0, ge=-255, le=255, description="The amount to adjust the channel by")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pil_image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# extract the channel and mode from the input and reference tuple
|
||||
mode = CHANNEL_FORMATS[self.channel][0]
|
||||
channel_number = CHANNEL_FORMATS[self.channel][1]
|
||||
|
||||
# Convert PIL image to new format
|
||||
converted_image = numpy.array(pil_image.convert(mode)).astype(int)
|
||||
image_channel = converted_image[:, :, channel_number]
|
||||
|
||||
# Adjust the value, clipping to 0..255
|
||||
image_channel = numpy.clip(image_channel + self.offset, 0, 255)
|
||||
|
||||
# Put the channel back into the image
|
||||
converted_image[:, :, channel_number] = image_channel
|
||||
|
||||
# Convert back to RGBA format and output
|
||||
pil_image = Image.fromarray(converted_image.astype(numpy.uint8), mode=mode).convert("RGBA")
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
session_id=context.graph_execution_state_id,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"img_channel_multiply",
|
||||
title="Multiply Image Channel",
|
||||
tags=[
|
||||
"image",
|
||||
"invert",
|
||||
"scale",
|
||||
"multiply",
|
||||
"red",
|
||||
"green",
|
||||
"blue",
|
||||
"alpha",
|
||||
"cyan",
|
||||
"magenta",
|
||||
"yellow",
|
||||
"black",
|
||||
"hue",
|
||||
"saturation",
|
||||
"luminosity",
|
||||
"value",
|
||||
],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageChannelMultiplyInvocation(BaseInvocation):
|
||||
"""Scale a specific color channel of an image."""
|
||||
|
||||
image: ImageField = InputField(description="The image to adjust")
|
||||
channel: COLOR_CHANNELS = InputField(description="Which channel to adjust")
|
||||
scale: float = InputField(default=1.0, ge=0.0, description="The amount to scale the channel by.")
|
||||
invert_channel: bool = InputField(default=False, description="Invert the channel after scaling")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pil_image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# extract the channel and mode from the input and reference tuple
|
||||
mode = CHANNEL_FORMATS[self.channel][0]
|
||||
channel_number = CHANNEL_FORMATS[self.channel][1]
|
||||
|
||||
# Convert PIL image to new format
|
||||
converted_image = numpy.array(pil_image.convert(mode)).astype(float)
|
||||
image_channel = converted_image[:, :, channel_number]
|
||||
|
||||
# Adjust the value, clipping to 0..255
|
||||
image_channel = numpy.clip(image_channel * self.scale, 0, 255)
|
||||
|
||||
# Invert the channel if requested
|
||||
if self.invert_channel:
|
||||
image_channel = 255 - image_channel
|
||||
|
||||
# Put the channel back into the image
|
||||
converted_image[:, :, channel_number] = image_channel
|
||||
|
||||
# Convert back to RGBA format and output
|
||||
pil_image = Image.fromarray(converted_image.astype(numpy.uint8), mode=mode).convert("RGBA")
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
session_id=context.graph_execution_state_id,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"save_image",
|
||||
title="Save Image",
|
||||
tags=["primitives", "image"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
use_cache=False,
|
||||
)
|
||||
class SaveImageInvocation(BaseInvocation):
|
||||
"""Saves an image. Unlike an image primitive, this invocation stores a copy of the image."""
|
||||
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
metadata: CoreMetadata = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.core_metadata,
|
||||
ui_hidden=True,
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pil_image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# Convert PIL image to OpenCV format (numpy array), note color channel
|
||||
# ordering is changed from RGB to BGR
|
||||
image = numpy.array(pil_image.convert("RGB"))[:, :, ::-1]
|
||||
|
||||
# Convert image to HSV color space
|
||||
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
|
||||
|
||||
# Adjust the luminosity (value)
|
||||
hsv_image[:, :, 2] = numpy.clip(hsv_image[:, :, 2] * self.luminosity, 0, 255)
|
||||
|
||||
# Convert image back to BGR color space
|
||||
image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR)
|
||||
|
||||
# Convert back to PIL format and to original color mode
|
||||
pil_image = Image.fromarray(image[:, :, ::-1], "RGB").convert("RGBA")
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image=image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
|
||||
@title("Image Saturation Adjustment")
|
||||
@tags("image", "saturation", "hsl")
|
||||
class ImageSaturationAdjustmentInvocation(BaseInvocation):
|
||||
"""Adjusts the Saturation of an image."""
|
||||
|
||||
type: Literal["img_saturation_adjust"] = "img_saturation_adjust"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to adjust")
|
||||
saturation: float = InputField(default=1.0, ge=0, le=1, description="The factor by which to adjust the saturation")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
pil_image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# Convert PIL image to OpenCV format (numpy array), note color channel
|
||||
# ordering is changed from RGB to BGR
|
||||
image = numpy.array(pil_image.convert("RGB"))[:, :, ::-1]
|
||||
|
||||
# Convert image to HSV color space
|
||||
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
|
||||
|
||||
# Adjust the saturation
|
||||
hsv_image[:, :, 1] = numpy.clip(hsv_image[:, :, 1] * self.saturation, 0, 255)
|
||||
|
||||
# Convert image back to BGR color space
|
||||
image = cv2.cvtColor(hsv_image, cv2.COLOR_HSV2BGR)
|
||||
|
||||
# Convert back to PIL format and to original color mode
|
||||
pil_image = Image.fromarray(image[:, :, ::-1], "RGB").convert("RGBA")
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=pil_image,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
session_id=context.graph_execution_state_id,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(
|
||||
image_name=image_dto.image_name,
|
||||
),
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
@ -8,19 +8,17 @@ from PIL import Image, ImageOps
|
||||
|
||||
from invokeai.app.invocations.primitives import ColorField, ImageField, ImageOutput
|
||||
from invokeai.app.util.misc import SEED_MAX, get_random_seed
|
||||
from invokeai.backend.image_util.cv2_inpaint import cv2_inpaint
|
||||
from invokeai.backend.image_util.lama import LaMA
|
||||
from invokeai.backend.image_util.patchmatch import PatchMatch
|
||||
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, tags, title
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
from .image import PIL_RESAMPLING_MAP, PIL_RESAMPLING_MODES
|
||||
|
||||
|
||||
def infill_methods() -> list[str]:
|
||||
methods = [
|
||||
"tile",
|
||||
"solid",
|
||||
"lama",
|
||||
]
|
||||
methods = ["tile", "solid", "lama", "cv2"]
|
||||
if PatchMatch.patchmatch_available():
|
||||
methods.insert(0, "patchmatch")
|
||||
return methods
|
||||
@ -49,6 +47,10 @@ def infill_patchmatch(im: Image.Image) -> Image.Image:
|
||||
return im_patched
|
||||
|
||||
|
||||
def infill_cv2(im: Image.Image) -> Image.Image:
|
||||
return cv2_inpaint(im)
|
||||
|
||||
|
||||
def get_tile_images(image: np.ndarray, width=8, height=8):
|
||||
_nrows, _ncols, depth = image.shape
|
||||
_strides = image.strides
|
||||
@ -116,14 +118,10 @@ def tile_fill_missing(im: Image.Image, tile_size: int = 16, seed: Optional[int]
|
||||
return si
|
||||
|
||||
|
||||
@title("Solid Color Infill")
|
||||
@tags("image", "inpaint")
|
||||
@invocation("infill_rgba", title="Solid Color Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class InfillColorInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image with a solid color"""
|
||||
|
||||
type: Literal["infill_rgba"] = "infill_rgba"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to infill")
|
||||
color: ColorField = InputField(
|
||||
default=ColorField(r=127, g=127, b=127, a=255),
|
||||
@ -145,6 +143,7 @@ class InfillColorInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -154,14 +153,10 @@ class InfillColorInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Tile Infill")
|
||||
@tags("image", "inpaint")
|
||||
@invocation("infill_tile", title="Tile Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class InfillTileInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image with tiles of the image"""
|
||||
|
||||
type: Literal["infill_tile"] = "infill_tile"
|
||||
|
||||
# Input
|
||||
image: ImageField = InputField(description="The image to infill")
|
||||
tile_size: int = InputField(default=32, ge=1, description="The tile size (px)")
|
||||
seed: int = InputField(
|
||||
@ -184,6 +179,7 @@ class InfillTileInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -193,24 +189,42 @@ class InfillTileInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("PatchMatch Infill")
|
||||
@tags("image", "inpaint")
|
||||
@invocation(
|
||||
"infill_patchmatch", title="PatchMatch Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0"
|
||||
)
|
||||
class InfillPatchMatchInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using the PatchMatch algorithm"""
|
||||
|
||||
type: Literal["infill_patchmatch"] = "infill_patchmatch"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to infill")
|
||||
downscale: float = InputField(default=2.0, gt=0, description="Run patchmatch on downscaled image to speedup infill")
|
||||
resample_mode: PIL_RESAMPLING_MODES = InputField(default="bicubic", description="The resampling mode")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
image = context.services.images.get_pil_image(self.image.image_name).convert("RGBA")
|
||||
|
||||
resample_mode = PIL_RESAMPLING_MAP[self.resample_mode]
|
||||
|
||||
infill_image = image.copy()
|
||||
width = int(image.width / self.downscale)
|
||||
height = int(image.height / self.downscale)
|
||||
infill_image = infill_image.resize(
|
||||
(width, height),
|
||||
resample=resample_mode,
|
||||
)
|
||||
|
||||
if PatchMatch.patchmatch_available():
|
||||
infilled = infill_patchmatch(image.copy())
|
||||
infilled = infill_patchmatch(infill_image)
|
||||
else:
|
||||
raise ValueError("PatchMatch is not available on this system")
|
||||
|
||||
infilled = infilled.resize(
|
||||
(image.width, image.height),
|
||||
resample=resample_mode,
|
||||
)
|
||||
|
||||
infilled.paste(image, (0, 0), mask=image.split()[-1])
|
||||
# image.paste(infilled, (0, 0), mask=image.split()[-1])
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=infilled,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
@ -218,6 +232,7 @@ class InfillPatchMatchInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -227,14 +242,10 @@ class InfillPatchMatchInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("LaMa Infill")
|
||||
@tags("image", "inpaint")
|
||||
@invocation("infill_lama", title="LaMa Infill", tags=["image", "inpaint"], category="inpaint", version="1.0.0")
|
||||
class LaMaInfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using the LaMa model"""
|
||||
|
||||
type: Literal["infill_lama"] = "infill_lama"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to infill")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
@ -256,3 +267,30 @@ class LaMaInfillInvocation(BaseInvocation):
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
|
||||
@invocation("infill_cv2", title="CV2 Infill", tags=["image", "inpaint"], category="inpaint")
|
||||
class CV2InfillInvocation(BaseInvocation):
|
||||
"""Infills transparent areas of an image using OpenCV Inpainting"""
|
||||
|
||||
image: ImageField = InputField(description="The image to infill")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
infilled = infill_cv2(image.copy())
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=infilled,
|
||||
image_origin=ResourceOrigin.INTERNAL,
|
||||
image_category=ImageCategory.GENERAL,
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
image=ImageField(image_name=image_dto.image_name),
|
||||
width=image_dto.width,
|
||||
height=image_dto.height,
|
||||
)
|
||||
|
||||
103
invokeai/app/invocations/ip_adapter.py
Normal file
@ -0,0 +1,103 @@
|
||||
import os
|
||||
from builtins import float
|
||||
from typing import List, Union
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.primitives import ImageField
|
||||
from invokeai.backend.model_management.models.base import BaseModelType, ModelType
|
||||
from invokeai.backend.model_management.models.ip_adapter import get_ip_adapter_image_encoder_model_id
|
||||
|
||||
|
||||
class IPAdapterModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the IP-Adapter model")
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
class CLIPVisionModelField(BaseModel):
|
||||
model_name: str = Field(description="Name of the CLIP Vision image encoder model")
|
||||
base_model: BaseModelType = Field(description="Base model (usually 'Any')")
|
||||
|
||||
|
||||
class IPAdapterField(BaseModel):
|
||||
image: ImageField = Field(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = Field(description="The IP-Adapter model to use.")
|
||||
image_encoder_model: CLIPVisionModelField = Field(description="The name of the CLIP image encoder model.")
|
||||
weight: Union[float, List[float]] = Field(default=1, description="The weight given to the ControlNet")
|
||||
# weight: float = Field(default=1.0, ge=0, description="The weight of the IP-Adapter.")
|
||||
begin_step_percent: float = Field(
|
||||
default=0, ge=0, le=1, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = Field(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("ip_adapter_output")
|
||||
class IPAdapterOutput(BaseInvocationOutput):
|
||||
# Outputs
|
||||
ip_adapter: IPAdapterField = OutputField(description=FieldDescriptions.ip_adapter, title="IP-Adapter")
|
||||
|
||||
|
||||
@invocation("ip_adapter", title="IP-Adapter", tags=["ip_adapter", "control"], category="ip_adapter", version="1.0.0")
|
||||
class IPAdapterInvocation(BaseInvocation):
|
||||
"""Collects IP-Adapter info to pass to other nodes."""
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The IP-Adapter image prompt.")
|
||||
ip_adapter_model: IPAdapterModelField = InputField(
|
||||
description="The IP-Adapter model.", title="IP-Adapter Model", input=Input.Direct, ui_order=-1
|
||||
)
|
||||
|
||||
# weight: float = InputField(default=1.0, description="The weight of the IP-Adapter.", ui_type=UIType.Float)
|
||||
weight: Union[float, List[float]] = InputField(
|
||||
default=1, ge=0, description="The weight given to the IP-Adapter", ui_type=UIType.Float, title="Weight"
|
||||
)
|
||||
|
||||
begin_step_percent: float = InputField(
|
||||
default=0, ge=-1, le=2, description="When the IP-Adapter is first applied (% of total steps)"
|
||||
)
|
||||
end_step_percent: float = InputField(
|
||||
default=1, ge=0, le=1, description="When the IP-Adapter is last applied (% of total steps)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IPAdapterOutput:
|
||||
# Lookup the CLIP Vision encoder that is intended to be used with the IP-Adapter model.
|
||||
ip_adapter_info = context.services.model_manager.model_info(
|
||||
self.ip_adapter_model.model_name, self.ip_adapter_model.base_model, ModelType.IPAdapter
|
||||
)
|
||||
# HACK(ryand): This is bad for a couple of reasons: 1) we are bypassing the model manager to read the model
|
||||
# directly, and 2) we are reading from disk every time this invocation is called without caching the result.
|
||||
# A better solution would be to store the image encoder model reference in the IP-Adapter model info, but this
|
||||
# is currently messy due to differences between how the model info is generated when installing a model from
|
||||
# disk vs. downloading the model.
|
||||
image_encoder_model_id = get_ip_adapter_image_encoder_model_id(
|
||||
os.path.join(context.services.configuration.get_config().models_path, ip_adapter_info["path"])
|
||||
)
|
||||
image_encoder_model_name = image_encoder_model_id.split("/")[-1].strip()
|
||||
image_encoder_model = CLIPVisionModelField(
|
||||
model_name=image_encoder_model_name,
|
||||
base_model=BaseModelType.Any,
|
||||
)
|
||||
return IPAdapterOutput(
|
||||
ip_adapter=IPAdapterField(
|
||||
image=self.image,
|
||||
ip_adapter_model=self.ip_adapter_model,
|
||||
image_encoder_model=image_encoder_model,
|
||||
weight=self.weight,
|
||||
begin_step_percent=self.begin_step_percent,
|
||||
end_step_percent=self.end_step_percent,
|
||||
),
|
||||
)
|
||||
@ -1,13 +1,16 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from contextlib import ExitStack
|
||||
from functools import singledispatchmethod
|
||||
from typing import List, Literal, Optional, Union
|
||||
|
||||
import einops
|
||||
import numpy as np
|
||||
import torch
|
||||
import torchvision.transforms as T
|
||||
from diffusers import AutoencoderKL, AutoencoderTiny
|
||||
from diffusers.image_processor import VaeImageProcessor
|
||||
from diffusers.models import UNet2DConditionModel
|
||||
from diffusers.models.attention_processor import (
|
||||
AttnProcessor2_0,
|
||||
LoRAAttnProcessor2_0,
|
||||
@ -19,8 +22,11 @@ from diffusers.schedulers import SchedulerMixin as Scheduler
|
||||
from pydantic import validator
|
||||
from torchvision.transforms.functional import resize as tv_resize
|
||||
|
||||
from invokeai.app.invocations.ip_adapter import IPAdapterField
|
||||
from invokeai.app.invocations.metadata import CoreMetadata
|
||||
from invokeai.app.invocations.primitives import (
|
||||
DenoiseMaskField,
|
||||
DenoiseMaskOutput,
|
||||
ImageField,
|
||||
ImageOutput,
|
||||
LatentsField,
|
||||
@ -29,14 +35,17 @@ from invokeai.app.invocations.primitives import (
|
||||
)
|
||||
from invokeai.app.util.controlnet_utils import prepare_control_image
|
||||
from invokeai.app.util.step_callback import stable_diffusion_step_callback
|
||||
from invokeai.backend.ip_adapter.ip_adapter import IPAdapter, IPAdapterPlus
|
||||
from invokeai.backend.model_management.models import ModelType, SilenceWarnings
|
||||
from invokeai.backend.stable_diffusion.diffusion.conditioning_data import ConditioningData, IPAdapterConditioningInfo
|
||||
|
||||
from ...backend.model_management.models import BaseModelType
|
||||
from ...backend.model_management.lora import ModelPatcher
|
||||
from ...backend.model_management.models import BaseModelType
|
||||
from ...backend.model_management.seamless import set_seamless
|
||||
from ...backend.stable_diffusion import PipelineIntermediateState
|
||||
from ...backend.stable_diffusion.diffusers_pipeline import (
|
||||
ConditioningData,
|
||||
ControlNetData,
|
||||
IPAdapterData,
|
||||
StableDiffusionGeneratorPipeline,
|
||||
image_resized_to_grid_as_tensor,
|
||||
)
|
||||
@ -46,24 +55,127 @@ from ...backend.util.devices import choose_precision, choose_torch_device
|
||||
from ..models.image import ImageCategory, ResourceOrigin
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from .compel import ConditioningField
|
||||
from .controlnet_image_processors import ControlField
|
||||
from .model import ModelInfo, UNetField, VaeField
|
||||
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
from torch import mps
|
||||
|
||||
DEFAULT_PRECISION = choose_precision(choose_torch_device())
|
||||
|
||||
|
||||
SAMPLER_NAME_VALUES = Literal[tuple(list(SCHEDULER_MAP.keys()))]
|
||||
|
||||
|
||||
def fit_latents(latents: torch.Tensor, max_latents_size: int, device: torch.device) -> torch.Tensor:
|
||||
if max_latents_size == 0:
|
||||
return latents
|
||||
|
||||
latents_area = latents.shape[2] * latents.shape[3]
|
||||
if latents_area <= max_latents_size:
|
||||
return latents
|
||||
|
||||
scale_factor = np.sqrt(max_latents_size / latents_area)
|
||||
scaled_latents = torch.nn.functional.interpolate(
|
||||
latents.to(device),
|
||||
scale_factor=scale_factor,
|
||||
mode="bilinear",
|
||||
antialias=True,
|
||||
)
|
||||
|
||||
return scaled_latents
|
||||
|
||||
|
||||
@invocation_output("scheduler_output")
|
||||
class SchedulerOutput(BaseInvocationOutput):
|
||||
scheduler: SAMPLER_NAME_VALUES = OutputField(description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler)
|
||||
|
||||
|
||||
@invocation("scheduler", title="Scheduler", tags=["scheduler"], category="latents", version="1.0.0")
|
||||
class SchedulerInvocation(BaseInvocation):
|
||||
"""Selects a scheduler."""
|
||||
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, ui_type=UIType.Scheduler
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SchedulerOutput:
|
||||
return SchedulerOutput(scheduler=self.scheduler)
|
||||
|
||||
|
||||
@invocation(
|
||||
"create_denoise_mask", title="Create Denoise Mask", tags=["mask", "denoise"], category="latents", version="1.0.0"
|
||||
)
|
||||
class CreateDenoiseMaskInvocation(BaseInvocation):
|
||||
"""Creates mask for denoising model run."""
|
||||
|
||||
vae: VaeField = InputField(description=FieldDescriptions.vae, input=Input.Connection, ui_order=0)
|
||||
image: Optional[ImageField] = InputField(default=None, description="Image which will be masked", ui_order=1)
|
||||
mask: ImageField = InputField(description="The mask to use when pasting", ui_order=2)
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled, ui_order=3)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32, ui_order=4)
|
||||
|
||||
def prep_mask_tensor(self, mask_image):
|
||||
if mask_image.mode != "L":
|
||||
mask_image = mask_image.convert("L")
|
||||
mask_tensor = image_resized_to_grid_as_tensor(mask_image, normalize=False)
|
||||
if mask_tensor.dim() == 3:
|
||||
mask_tensor = mask_tensor.unsqueeze(0)
|
||||
# if shape is not None:
|
||||
# mask_tensor = tv_resize(mask_tensor, shape, T.InterpolationMode.BILINEAR)
|
||||
return mask_tensor
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> DenoiseMaskOutput:
|
||||
if self.image is not None:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
image = image_resized_to_grid_as_tensor(image.convert("RGB"))
|
||||
if image.dim() == 3:
|
||||
image = image.unsqueeze(0)
|
||||
else:
|
||||
image = None
|
||||
|
||||
mask = self.prep_mask_tensor(
|
||||
context.services.images.get_pil_image(self.mask.image_name),
|
||||
)
|
||||
|
||||
if image is not None:
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
img_mask = tv_resize(mask, image.shape[-2:], T.InterpolationMode.BILINEAR, antialias=False)
|
||||
masked_image = image * torch.where(img_mask < 0.5, 0.0, 1.0)
|
||||
# TODO:
|
||||
masked_latents = ImageToLatentsInvocation.vae_encode(vae_info, self.fp32, self.tiled, masked_image.clone())
|
||||
|
||||
masked_latents_name = f"{context.graph_execution_state_id}__{self.id}_masked_latents"
|
||||
context.services.latents.save(masked_latents_name, masked_latents)
|
||||
else:
|
||||
masked_latents_name = None
|
||||
|
||||
mask_name = f"{context.graph_execution_state_id}__{self.id}_mask"
|
||||
context.services.latents.save(mask_name, mask)
|
||||
|
||||
return DenoiseMaskOutput(
|
||||
denoise_mask=DenoiseMaskField(
|
||||
mask_name=mask_name,
|
||||
masked_latents_name=masked_latents_name,
|
||||
),
|
||||
)
|
||||
|
||||
|
||||
def get_scheduler(
|
||||
context: InvocationContext,
|
||||
scheduler_info: ModelInfo,
|
||||
@ -98,14 +210,16 @@ def get_scheduler(
|
||||
return scheduler
|
||||
|
||||
|
||||
@title("Denoise Latents")
|
||||
@tags("latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l")
|
||||
@invocation(
|
||||
"denoise_latents",
|
||||
title="Denoise Latents",
|
||||
tags=["latents", "denoise", "txt2img", "t2i", "t2l", "img2img", "i2i", "l2l"],
|
||||
category="latents",
|
||||
version="1.1.0",
|
||||
)
|
||||
class DenoiseLatentsInvocation(BaseInvocation):
|
||||
"""Denoises noisy latents to decodable images"""
|
||||
|
||||
type: Literal["denoise_latents"] = "denoise_latents"
|
||||
|
||||
# Inputs
|
||||
positive_conditioning: ConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond, input=Input.Connection, ui_order=0
|
||||
)
|
||||
@ -115,7 +229,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
noise: Optional[LatentsField] = InputField(description=FieldDescriptions.noise, input=Input.Connection, ui_order=3)
|
||||
steps: int = InputField(default=10, gt=0, description=FieldDescriptions.steps)
|
||||
cfg_scale: Union[float, List[float]] = InputField(
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, ui_type=UIType.Float, title="CFG Scale"
|
||||
default=7.5, ge=1, description=FieldDescriptions.cfg_scale, title="CFG Scale"
|
||||
)
|
||||
denoising_start: float = InputField(default=0.0, ge=0, le=1, description=FieldDescriptions.denoising_start)
|
||||
denoising_end: float = InputField(default=1.0, ge=0, le=1, description=FieldDescriptions.denoising_end)
|
||||
@ -124,14 +238,16 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
)
|
||||
unet: UNetField = InputField(description=FieldDescriptions.unet, input=Input.Connection, title="UNet", ui_order=2)
|
||||
control: Union[ControlField, list[ControlField]] = InputField(
|
||||
default=None, description=FieldDescriptions.control, input=Input.Connection, ui_order=5
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(
|
||||
description=FieldDescriptions.latents, input=Input.Connection, ui_order=4
|
||||
)
|
||||
mask: Optional[ImageField] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.mask,
|
||||
input=Input.Connection,
|
||||
ui_order=5,
|
||||
)
|
||||
ip_adapter: Optional[IPAdapterField] = InputField(
|
||||
description=FieldDescriptions.ip_adapter, title="IP-Adapter", default=None, input=Input.Connection, ui_order=6
|
||||
)
|
||||
latents: Optional[LatentsField] = InputField(description=FieldDescriptions.latents, input=Input.Connection)
|
||||
denoise_mask: Optional[DenoiseMaskField] = InputField(
|
||||
default=None, description=FieldDescriptions.mask, input=Input.Connection, ui_order=7
|
||||
)
|
||||
|
||||
@validator("cfg_scale")
|
||||
@ -233,9 +349,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def prep_control_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
# really only need model for dtype and device
|
||||
model: StableDiffusionGeneratorPipeline,
|
||||
control_input: List[ControlField],
|
||||
control_input: Union[ControlField, List[ControlField]],
|
||||
latents_shape: List[int],
|
||||
exit_stack: ExitStack,
|
||||
do_classifier_free_guidance: bool = True,
|
||||
@ -254,128 +368,184 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
else:
|
||||
control_list = None
|
||||
if control_list is None:
|
||||
control_data = None
|
||||
# from above handling, any control that is not None should now be of type list[ControlField]
|
||||
else:
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
control_data = []
|
||||
control_models = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
return None
|
||||
# After above handling, any control that is not None should now be of type list[ControlField].
|
||||
|
||||
control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
# FIXME: add checks to skip entry if model or image is None
|
||||
# and if weight is None, populate with default 1.0?
|
||||
controlnet_data = []
|
||||
for control_info in control_list:
|
||||
control_model = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=control_info.control_model.model_name,
|
||||
model_type=ModelType.ControlNet,
|
||||
base_model=control_info.control_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
control_item = ControlNetData(
|
||||
model=control_model,
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
control_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
return control_data
|
||||
)
|
||||
|
||||
# control_models.append(control_model)
|
||||
control_image_field = control_info.image
|
||||
input_image = context.services.images.get_pil_image(control_image_field.image_name)
|
||||
# self.image.image_type, self.image.image_name
|
||||
# FIXME: still need to test with different widths, heights, devices, dtypes
|
||||
# and add in batch_size, num_images_per_prompt?
|
||||
# and do real check for classifier_free_guidance?
|
||||
# prepare_control_image should return torch.Tensor of shape(batch_size, 3, height, width)
|
||||
control_image = prepare_control_image(
|
||||
image=input_image,
|
||||
do_classifier_free_guidance=do_classifier_free_guidance,
|
||||
width=control_width_resize,
|
||||
height=control_height_resize,
|
||||
# batch_size=batch_size * num_images_per_prompt,
|
||||
# num_images_per_prompt=num_images_per_prompt,
|
||||
device=control_model.device,
|
||||
dtype=control_model.dtype,
|
||||
control_mode=control_info.control_mode,
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
control_item = ControlNetData(
|
||||
model=control_model, # model object
|
||||
image_tensor=control_image,
|
||||
weight=control_info.control_weight,
|
||||
begin_step_percent=control_info.begin_step_percent,
|
||||
end_step_percent=control_info.end_step_percent,
|
||||
control_mode=control_info.control_mode,
|
||||
# any resizing needed should currently be happening in prepare_control_image(),
|
||||
# but adding resize_mode to ControlNetData in case needed in the future
|
||||
resize_mode=control_info.resize_mode,
|
||||
)
|
||||
controlnet_data.append(control_item)
|
||||
# MultiControlNetModel has been refactored out, just need list[ControlNetData]
|
||||
|
||||
return controlnet_data
|
||||
|
||||
def prep_ip_adapter_data(
|
||||
self,
|
||||
context: InvocationContext,
|
||||
ip_adapter: Optional[IPAdapterField],
|
||||
conditioning_data: ConditioningData,
|
||||
unet: UNet2DConditionModel,
|
||||
exit_stack: ExitStack,
|
||||
) -> Optional[IPAdapterData]:
|
||||
"""If IP-Adapter is enabled, then this function loads the requisite models, and adds the image prompt embeddings
|
||||
to the `conditioning_data` (in-place).
|
||||
"""
|
||||
if ip_adapter is None:
|
||||
return None
|
||||
|
||||
image_encoder_model_info = context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.image_encoder_model.model_name,
|
||||
model_type=ModelType.CLIPVision,
|
||||
base_model=ip_adapter.image_encoder_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
|
||||
ip_adapter_model: Union[IPAdapter, IPAdapterPlus] = exit_stack.enter_context(
|
||||
context.services.model_manager.get_model(
|
||||
model_name=ip_adapter.ip_adapter_model.model_name,
|
||||
model_type=ModelType.IPAdapter,
|
||||
base_model=ip_adapter.ip_adapter_model.base_model,
|
||||
context=context,
|
||||
)
|
||||
)
|
||||
|
||||
input_image = context.services.images.get_pil_image(ip_adapter.image.image_name)
|
||||
|
||||
# TODO(ryand): With some effort, the step of running the CLIP Vision encoder could be done before any other
|
||||
# models are needed in memory. This would help to reduce peak memory utilization in low-memory environments.
|
||||
with image_encoder_model_info as image_encoder_model:
|
||||
# Get image embeddings from CLIP and ImageProjModel.
|
||||
image_prompt_embeds, uncond_image_prompt_embeds = ip_adapter_model.get_image_embeds(
|
||||
input_image, image_encoder_model
|
||||
)
|
||||
conditioning_data.ip_adapter_conditioning = IPAdapterConditioningInfo(
|
||||
image_prompt_embeds, uncond_image_prompt_embeds
|
||||
)
|
||||
|
||||
return IPAdapterData(
|
||||
ip_adapter_model=ip_adapter_model,
|
||||
weight=ip_adapter.weight,
|
||||
begin_step_percent=ip_adapter.begin_step_percent,
|
||||
end_step_percent=ip_adapter.end_step_percent,
|
||||
)
|
||||
|
||||
# original idea by https://github.com/AmericanPresidentJimmyCarter
|
||||
# TODO: research more for second order schedulers timesteps
|
||||
def init_scheduler(self, scheduler, device, steps, denoising_start, denoising_end):
|
||||
num_inference_steps = steps
|
||||
if scheduler.config.get("cpu_only", False):
|
||||
scheduler.set_timesteps(num_inference_steps, device="cpu")
|
||||
scheduler.set_timesteps(steps, device="cpu")
|
||||
timesteps = scheduler.timesteps.to(device=device)
|
||||
else:
|
||||
scheduler.set_timesteps(num_inference_steps, device=device)
|
||||
scheduler.set_timesteps(steps, device=device)
|
||||
timesteps = scheduler.timesteps
|
||||
|
||||
# apply denoising_start
|
||||
# skip greater order timesteps
|
||||
_timesteps = timesteps[:: scheduler.order]
|
||||
|
||||
# get start timestep index
|
||||
t_start_val = int(round(scheduler.config.num_train_timesteps * (1 - denoising_start)))
|
||||
t_start_idx = len(list(filter(lambda ts: ts >= t_start_val, timesteps)))
|
||||
timesteps = timesteps[t_start_idx:]
|
||||
if scheduler.order == 2 and t_start_idx > 0:
|
||||
timesteps = timesteps[1:]
|
||||
t_start_idx = len(list(filter(lambda ts: ts >= t_start_val, _timesteps)))
|
||||
|
||||
# save start timestep to apply noise
|
||||
init_timestep = timesteps[:1]
|
||||
|
||||
# apply denoising_end
|
||||
# get end timestep index
|
||||
t_end_val = int(round(scheduler.config.num_train_timesteps * (1 - denoising_end)))
|
||||
t_end_idx = len(list(filter(lambda ts: ts >= t_end_val, timesteps)))
|
||||
if scheduler.order == 2 and t_end_idx > 0:
|
||||
t_end_idx += 1
|
||||
timesteps = timesteps[:t_end_idx]
|
||||
t_end_idx = len(list(filter(lambda ts: ts >= t_end_val, _timesteps[t_start_idx:])))
|
||||
|
||||
# calculate step count based on scheduler order
|
||||
num_inference_steps = len(timesteps)
|
||||
if scheduler.order == 2:
|
||||
num_inference_steps += num_inference_steps % 2
|
||||
num_inference_steps = num_inference_steps // 2
|
||||
# apply order to indexes
|
||||
t_start_idx *= scheduler.order
|
||||
t_end_idx *= scheduler.order
|
||||
|
||||
init_timestep = timesteps[t_start_idx : t_start_idx + 1]
|
||||
timesteps = timesteps[t_start_idx : t_start_idx + t_end_idx]
|
||||
num_inference_steps = len(timesteps) // scheduler.order
|
||||
|
||||
return num_inference_steps, timesteps, init_timestep
|
||||
|
||||
def prep_mask_tensor(self, mask, context, lantents):
|
||||
if mask is None:
|
||||
return None
|
||||
def prep_inpaint_mask(self, context, latents):
|
||||
if self.denoise_mask is None:
|
||||
return None, None
|
||||
|
||||
mask_image = context.services.images.get_pil_image(mask.image_name)
|
||||
if mask_image.mode != "L":
|
||||
# FIXME: why do we get passed an RGB image here? We can only use single-channel.
|
||||
mask_image = mask_image.convert("L")
|
||||
mask_tensor = image_resized_to_grid_as_tensor(mask_image, normalize=False)
|
||||
if mask_tensor.dim() == 3:
|
||||
mask_tensor = mask_tensor.unsqueeze(0)
|
||||
mask_tensor = tv_resize(mask_tensor, lantents.shape[-2:], T.InterpolationMode.BILINEAR)
|
||||
return 1 - mask_tensor
|
||||
mask = context.services.latents.get(self.denoise_mask.mask_name)
|
||||
mask = tv_resize(mask, latents.shape[-2:], T.InterpolationMode.BILINEAR, antialias=False)
|
||||
if self.denoise_mask.masked_latents_name is not None:
|
||||
masked_latents = context.services.latents.get(self.denoise_mask.masked_latents_name)
|
||||
else:
|
||||
masked_latents = None
|
||||
|
||||
return 1 - mask, masked_latents
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
with SilenceWarnings(): # this quenches NSFW nag from diffusers
|
||||
seed = None
|
||||
noise = None
|
||||
max_image_size = context.services.configuration.max_image_size
|
||||
|
||||
if self.noise is not None:
|
||||
noise = context.services.latents.get(self.noise.latents_name)
|
||||
seed = self.noise.seed
|
||||
noise = fit_latents(latents=noise, max_latents_size=max_image_size // 64, device=choose_torch_device())
|
||||
|
||||
if self.latents is not None:
|
||||
latents = context.services.latents.get(self.latents.latents_name)
|
||||
if seed is None:
|
||||
seed = self.latents.seed
|
||||
else:
|
||||
latents = fit_latents(
|
||||
latents=latents, max_latents_size=max_image_size // 64, device=choose_torch_device()
|
||||
)
|
||||
|
||||
if noise is not None and noise.shape[1:] != latents.shape[1:]:
|
||||
raise Exception(f"Incompatable 'noise' and 'latents' shapes: {latents.shape=} {noise.shape=}")
|
||||
|
||||
elif noise is not None:
|
||||
latents = torch.zeros_like(noise)
|
||||
else:
|
||||
raise Exception("'latents' or 'noise' must be provided!")
|
||||
|
||||
if seed is None:
|
||||
seed = 0
|
||||
|
||||
mask = self.prep_mask_tensor(self.mask, context, latents)
|
||||
mask, masked_latents = self.prep_inpaint_mask(context, latents)
|
||||
|
||||
# Get the source node id (we are invoking the prepared node)
|
||||
graph_execution_state = context.services.graph_execution_manager.get(context.graph_execution_state_id)
|
||||
@ -387,8 +557,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
def _lora_loader():
|
||||
for lora in self.unet.loras:
|
||||
lora_info = context.services.model_manager.get_model(
|
||||
**lora.dict(exclude={"weight"}),
|
||||
context=context,
|
||||
**lora.dict(exclude={"weight"}), context=context
|
||||
)
|
||||
yield (lora_info.context.model, lora.weight)
|
||||
del lora_info
|
||||
@ -398,14 +567,19 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
**self.unet.unet.dict(),
|
||||
context=context,
|
||||
)
|
||||
with ExitStack() as exit_stack, ModelPatcher.apply_lora_unet(
|
||||
unet_info.context.model, _lora_loader()
|
||||
), unet_info as unet:
|
||||
with (
|
||||
ExitStack() as exit_stack,
|
||||
ModelPatcher.apply_lora_unet(unet_info.context.model, _lora_loader()),
|
||||
set_seamless(unet_info.context.model, self.unet.seamless_axes),
|
||||
unet_info as unet,
|
||||
):
|
||||
latents = latents.to(device=unet.device, dtype=unet.dtype)
|
||||
if noise is not None:
|
||||
noise = noise.to(device=unet.device, dtype=unet.dtype)
|
||||
if mask is not None:
|
||||
mask = mask.to(device=unet.device, dtype=unet.dtype)
|
||||
if masked_latents is not None:
|
||||
masked_latents = masked_latents.to(device=unet.device, dtype=unet.dtype)
|
||||
|
||||
scheduler = get_scheduler(
|
||||
context=context,
|
||||
@ -417,8 +591,7 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
pipeline = self.create_pipeline(unet, scheduler)
|
||||
conditioning_data = self.get_conditioning_data(context, scheduler, unet, seed)
|
||||
|
||||
control_data = self.prep_control_data(
|
||||
model=pipeline,
|
||||
controlnet_data = self.prep_control_data(
|
||||
context=context,
|
||||
control_input=self.control,
|
||||
latents_shape=latents.shape,
|
||||
@ -427,6 +600,14 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
ip_adapter_data = self.prep_ip_adapter_data(
|
||||
context=context,
|
||||
ip_adapter=self.ip_adapter,
|
||||
conditioning_data=conditioning_data,
|
||||
unet=unet,
|
||||
exit_stack=exit_stack,
|
||||
)
|
||||
|
||||
num_inference_steps, timesteps, init_timestep = self.init_scheduler(
|
||||
scheduler,
|
||||
device=unet.device,
|
||||
@ -442,29 +623,31 @@ class DenoiseLatentsInvocation(BaseInvocation):
|
||||
noise=noise,
|
||||
seed=seed,
|
||||
mask=mask,
|
||||
masked_latents=masked_latents,
|
||||
num_inference_steps=num_inference_steps,
|
||||
conditioning_data=conditioning_data,
|
||||
control_data=control_data, # list[ControlNetData]
|
||||
control_data=controlnet_data, # list[ControlNetData],
|
||||
ip_adapter_data=ip_adapter_data, # IPAdapterData,
|
||||
callback=step_callback,
|
||||
)
|
||||
|
||||
# https://discuss.huggingface.co/t/memory-usage-by-later-pipeline-stages/23699
|
||||
result_latents = result_latents.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
context.services.latents.save(name, result_latents)
|
||||
return build_latents_output(latents_name=name, latents=result_latents, seed=seed)
|
||||
|
||||
|
||||
@title("Latents to Image")
|
||||
@tags("latents", "image", "vae", "l2i")
|
||||
@invocation(
|
||||
"l2i", title="Latents to Image", tags=["latents", "image", "vae", "l2i"], category="latents", version="1.0.0"
|
||||
)
|
||||
class LatentsToImageInvocation(BaseInvocation):
|
||||
"""Generates an image from latents."""
|
||||
|
||||
type: Literal["l2i"] = "l2i"
|
||||
|
||||
# Inputs
|
||||
latents: LatentsField = InputField(
|
||||
description=FieldDescriptions.latents,
|
||||
input=Input.Connection,
|
||||
@ -490,7 +673,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
context=context,
|
||||
)
|
||||
|
||||
with vae_info as vae:
|
||||
with set_seamless(vae_info.context.model, self.vae.seamless_axes), vae_info as vae:
|
||||
latents = latents.to(vae.device)
|
||||
if self.fp32:
|
||||
vae.to(dtype=torch.float32)
|
||||
@ -524,6 +707,8 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
|
||||
# clear memory as vae decode can request a lot
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
with torch.inference_mode():
|
||||
# copied from diffusers pipeline
|
||||
@ -536,6 +721,8 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
image = VaeImageProcessor.numpy_to_pil(np_image)[0]
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
if choose_torch_device() == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
image_dto = context.services.images.create(
|
||||
image=image,
|
||||
@ -545,6 +732,7 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -557,14 +745,10 @@ class LatentsToImageInvocation(BaseInvocation):
|
||||
LATENTS_INTERPOLATION_MODE = Literal["nearest", "linear", "bilinear", "bicubic", "trilinear", "area", "nearest-exact"]
|
||||
|
||||
|
||||
@title("Resize Latents")
|
||||
@tags("latents", "resize")
|
||||
@invocation("lresize", title="Resize Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
class ResizeLatentsInvocation(BaseInvocation):
|
||||
"""Resizes latents to explicit width/height (in pixels). Provided dimensions are floor-divided by 8."""
|
||||
|
||||
type: Literal["lresize"] = "lresize"
|
||||
|
||||
# Inputs
|
||||
latents: LatentsField = InputField(
|
||||
description=FieldDescriptions.latents,
|
||||
input=Input.Connection,
|
||||
@ -598,6 +782,8 @@ class ResizeLatentsInvocation(BaseInvocation):
|
||||
# https://discuss.huggingface.co/t/memory-usage-by-later-pipeline-stages/23699
|
||||
resized_latents = resized_latents.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
if device == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
# context.services.latents.set(name, resized_latents)
|
||||
@ -605,14 +791,10 @@ class ResizeLatentsInvocation(BaseInvocation):
|
||||
return build_latents_output(latents_name=name, latents=resized_latents, seed=self.latents.seed)
|
||||
|
||||
|
||||
@title("Scale Latents")
|
||||
@tags("latents", "resize")
|
||||
@invocation("lscale", title="Scale Latents", tags=["latents", "resize"], category="latents", version="1.0.0")
|
||||
class ScaleLatentsInvocation(BaseInvocation):
|
||||
"""Scales latents by a given factor."""
|
||||
|
||||
type: Literal["lscale"] = "lscale"
|
||||
|
||||
# Inputs
|
||||
latents: LatentsField = InputField(
|
||||
description=FieldDescriptions.latents,
|
||||
input=Input.Connection,
|
||||
@ -638,6 +820,8 @@ class ScaleLatentsInvocation(BaseInvocation):
|
||||
# https://discuss.huggingface.co/t/memory-usage-by-later-pipeline-stages/23699
|
||||
resized_latents = resized_latents.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
if device == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
# context.services.latents.set(name, resized_latents)
|
||||
@ -645,14 +829,12 @@ class ScaleLatentsInvocation(BaseInvocation):
|
||||
return build_latents_output(latents_name=name, latents=resized_latents, seed=self.latents.seed)
|
||||
|
||||
|
||||
@title("Image to Latents")
|
||||
@tags("latents", "image", "vae", "i2l")
|
||||
@invocation(
|
||||
"i2l", title="Image to Latents", tags=["latents", "image", "vae", "i2l"], category="latents", version="1.0.0"
|
||||
)
|
||||
class ImageToLatentsInvocation(BaseInvocation):
|
||||
"""Encodes an image into latents."""
|
||||
|
||||
type: Literal["i2l"] = "i2l"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(
|
||||
description="The image to encode",
|
||||
)
|
||||
@ -663,26 +845,11 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
tiled: bool = InputField(default=False, description=FieldDescriptions.tiled)
|
||||
fp32: bool = InputField(default=DEFAULT_PRECISION == "float32", description=FieldDescriptions.fp32)
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
# image = context.services.images.get(
|
||||
# self.image.image_type, self.image.image_name
|
||||
# )
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
# vae_info = context.services.model_manager.get_model(**self.vae.vae.dict())
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
image_tensor = image_resized_to_grid_as_tensor(image.convert("RGB"))
|
||||
if image_tensor.dim() == 3:
|
||||
image_tensor = einops.rearrange(image_tensor, "c h w -> 1 c h w")
|
||||
|
||||
@staticmethod
|
||||
def vae_encode(vae_info, upcast, tiled, image_tensor):
|
||||
with vae_info as vae:
|
||||
orig_dtype = vae.dtype
|
||||
if self.fp32:
|
||||
if upcast:
|
||||
vae.to(dtype=torch.float32)
|
||||
|
||||
use_torch_2_0_or_xformers = isinstance(
|
||||
@ -707,7 +874,7 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
vae.to(dtype=torch.float16)
|
||||
# latents = latents.half()
|
||||
|
||||
if self.tiled:
|
||||
if tiled:
|
||||
vae.enable_tiling()
|
||||
else:
|
||||
vae.disable_tiling()
|
||||
@ -715,26 +882,50 @@ class ImageToLatentsInvocation(BaseInvocation):
|
||||
# non_noised_latents_from_image
|
||||
image_tensor = image_tensor.to(device=vae.device, dtype=vae.dtype)
|
||||
with torch.inference_mode():
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
latents = ImageToLatentsInvocation._encode_to_tensor(vae, image_tensor)
|
||||
|
||||
latents = vae.config.scaling_factor * latents
|
||||
latents = latents.to(dtype=orig_dtype)
|
||||
|
||||
return latents
|
||||
|
||||
@torch.no_grad()
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
image = context.services.images.get_pil_image(self.image.image_name)
|
||||
|
||||
vae_info = context.services.model_manager.get_model(
|
||||
**self.vae.vae.dict(),
|
||||
context=context,
|
||||
)
|
||||
|
||||
image_tensor = image_resized_to_grid_as_tensor(image.convert("RGB"))
|
||||
if image_tensor.dim() == 3:
|
||||
image_tensor = einops.rearrange(image_tensor, "c h w -> 1 c h w")
|
||||
|
||||
latents = self.vae_encode(vae_info, self.fp32, self.tiled, image_tensor)
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
latents = latents.to("cpu")
|
||||
context.services.latents.save(name, latents)
|
||||
return build_latents_output(latents_name=name, latents=latents, seed=None)
|
||||
|
||||
@singledispatchmethod
|
||||
@staticmethod
|
||||
def _encode_to_tensor(vae: AutoencoderKL, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
image_tensor_dist = vae.encode(image_tensor).latent_dist
|
||||
latents = image_tensor_dist.sample().to(dtype=vae.dtype) # FIXME: uses torch.randn. make reproducible!
|
||||
return latents
|
||||
|
||||
@title("Blend Latents")
|
||||
@tags("latents", "blend")
|
||||
@_encode_to_tensor.register
|
||||
@staticmethod
|
||||
def _(vae: AutoencoderTiny, image_tensor: torch.FloatTensor) -> torch.FloatTensor:
|
||||
return vae.encode(image_tensor).latents
|
||||
|
||||
|
||||
@invocation("lblend", title="Blend Latents", tags=["latents", "blend"], category="latents", version="1.0.0")
|
||||
class BlendLatentsInvocation(BaseInvocation):
|
||||
"""Blend two latents using a given alpha. Latents must have same size."""
|
||||
|
||||
type: Literal["lblend"] = "lblend"
|
||||
|
||||
# Inputs
|
||||
latents_a: LatentsField = InputField(
|
||||
description=FieldDescriptions.latents,
|
||||
input=Input.Connection,
|
||||
@ -798,6 +989,8 @@ class BlendLatentsInvocation(BaseInvocation):
|
||||
# https://discuss.huggingface.co/t/memory-usage-by-later-pipeline-stages/23699
|
||||
blended_latents = blended_latents.to("cpu")
|
||||
torch.cuda.empty_cache()
|
||||
if device == torch.device("mps"):
|
||||
mps.empty_cache()
|
||||
|
||||
name = f"{context.graph_execution_state_id}__{self.id}"
|
||||
# context.services.latents.set(name, resized_latents)
|
||||
|
||||
@ -3,20 +3,17 @@
|
||||
from typing import Literal
|
||||
|
||||
import numpy as np
|
||||
from pydantic import validator
|
||||
|
||||
from invokeai.app.invocations.primitives import IntegerOutput
|
||||
from invokeai.app.invocations.primitives import FloatOutput, IntegerOutput
|
||||
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, tags, title
|
||||
from .baseinvocation import BaseInvocation, FieldDescriptions, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@title("Add Integers")
|
||||
@tags("math")
|
||||
@invocation("add", title="Add Integers", tags=["math", "add"], category="math", version="1.0.0")
|
||||
class AddInvocation(BaseInvocation):
|
||||
"""Adds two numbers"""
|
||||
|
||||
type: Literal["add"] = "add"
|
||||
|
||||
# Inputs
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@ -24,14 +21,10 @@ class AddInvocation(BaseInvocation):
|
||||
return IntegerOutput(value=self.a + self.b)
|
||||
|
||||
|
||||
@title("Subtract Integers")
|
||||
@tags("math")
|
||||
@invocation("sub", title="Subtract Integers", tags=["math", "subtract"], category="math", version="1.0.0")
|
||||
class SubtractInvocation(BaseInvocation):
|
||||
"""Subtracts two numbers"""
|
||||
|
||||
type: Literal["sub"] = "sub"
|
||||
|
||||
# Inputs
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@ -39,14 +32,10 @@ class SubtractInvocation(BaseInvocation):
|
||||
return IntegerOutput(value=self.a - self.b)
|
||||
|
||||
|
||||
@title("Multiply Integers")
|
||||
@tags("math")
|
||||
@invocation("mul", title="Multiply Integers", tags=["math", "multiply"], category="math", version="1.0.0")
|
||||
class MultiplyInvocation(BaseInvocation):
|
||||
"""Multiplies two numbers"""
|
||||
|
||||
type: Literal["mul"] = "mul"
|
||||
|
||||
# Inputs
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@ -54,14 +43,10 @@ class MultiplyInvocation(BaseInvocation):
|
||||
return IntegerOutput(value=self.a * self.b)
|
||||
|
||||
|
||||
@title("Divide Integers")
|
||||
@tags("math")
|
||||
@invocation("div", title="Divide Integers", tags=["math", "divide"], category="math", version="1.0.0")
|
||||
class DivideInvocation(BaseInvocation):
|
||||
"""Divides two numbers"""
|
||||
|
||||
type: Literal["div"] = "div"
|
||||
|
||||
# Inputs
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@ -69,16 +54,217 @@ class DivideInvocation(BaseInvocation):
|
||||
return IntegerOutput(value=int(self.a / self.b))
|
||||
|
||||
|
||||
@title("Random Integer")
|
||||
@tags("math")
|
||||
@invocation(
|
||||
"rand_int",
|
||||
title="Random Integer",
|
||||
tags=["math", "random"],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
use_cache=False,
|
||||
)
|
||||
class RandomIntInvocation(BaseInvocation):
|
||||
"""Outputs a single random integer."""
|
||||
|
||||
type: Literal["rand_int"] = "rand_int"
|
||||
|
||||
# Inputs
|
||||
low: int = InputField(default=0, description="The inclusive low value")
|
||||
high: int = InputField(default=np.iinfo(np.int32).max, description="The exclusive high value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=np.random.randint(self.low, self.high))
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_to_int",
|
||||
title="Float To Integer",
|
||||
tags=["math", "round", "integer", "float", "convert"],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FloatToIntegerInvocation(BaseInvocation):
|
||||
"""Rounds a float number to (a multiple of) an integer."""
|
||||
|
||||
value: float = InputField(default=0, description="The value to round")
|
||||
multiple: int = InputField(default=1, ge=1, title="Multiple of", description="The multiple to round to")
|
||||
method: Literal["Nearest", "Floor", "Ceiling", "Truncate"] = InputField(
|
||||
default="Nearest", description="The method to use for rounding"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
if self.method == "Nearest":
|
||||
return IntegerOutput(value=round(self.value / self.multiple) * self.multiple)
|
||||
elif self.method == "Floor":
|
||||
return IntegerOutput(value=np.floor(self.value / self.multiple) * self.multiple)
|
||||
elif self.method == "Ceiling":
|
||||
return IntegerOutput(value=np.ceil(self.value / self.multiple) * self.multiple)
|
||||
else: # self.method == "Truncate"
|
||||
return IntegerOutput(value=int(self.value / self.multiple) * self.multiple)
|
||||
|
||||
|
||||
@invocation("round_float", title="Round Float", tags=["math", "round"], category="math", version="1.0.0")
|
||||
class RoundInvocation(BaseInvocation):
|
||||
"""Rounds a float to a specified number of decimal places."""
|
||||
|
||||
value: float = InputField(default=0, description="The float value")
|
||||
decimals: int = InputField(default=0, description="The number of decimal places")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
return FloatOutput(value=round(self.value, self.decimals))
|
||||
|
||||
|
||||
INTEGER_OPERATIONS = Literal[
|
||||
"ADD",
|
||||
"SUB",
|
||||
"MUL",
|
||||
"DIV",
|
||||
"EXP",
|
||||
"MOD",
|
||||
"ABS",
|
||||
"MIN",
|
||||
"MAX",
|
||||
]
|
||||
|
||||
|
||||
INTEGER_OPERATIONS_LABELS = dict(
|
||||
ADD="Add A+B",
|
||||
SUB="Subtract A-B",
|
||||
MUL="Multiply A*B",
|
||||
DIV="Divide A/B",
|
||||
EXP="Exponentiate A^B",
|
||||
MOD="Modulus A%B",
|
||||
ABS="Absolute Value of A",
|
||||
MIN="Minimum(A,B)",
|
||||
MAX="Maximum(A,B)",
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"integer_math",
|
||||
title="Integer Math",
|
||||
tags=[
|
||||
"math",
|
||||
"integer",
|
||||
"add",
|
||||
"subtract",
|
||||
"multiply",
|
||||
"divide",
|
||||
"modulus",
|
||||
"power",
|
||||
"absolute value",
|
||||
"min",
|
||||
"max",
|
||||
],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
)
|
||||
class IntegerMathInvocation(BaseInvocation):
|
||||
"""Performs integer math."""
|
||||
|
||||
operation: INTEGER_OPERATIONS = InputField(
|
||||
default="ADD", description="The operation to perform", ui_choice_labels=INTEGER_OPERATIONS_LABELS
|
||||
)
|
||||
a: int = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: int = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
elif values["operation"] == "MOD" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
elif values["operation"] == "EXP" and v < 0:
|
||||
raise ValueError("Result of exponentiation is not an integer")
|
||||
return v
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
# Python doesn't support switch statements until 3.10, but InvokeAI supports back to 3.9
|
||||
if self.operation == "ADD":
|
||||
return IntegerOutput(value=self.a + self.b)
|
||||
elif self.operation == "SUB":
|
||||
return IntegerOutput(value=self.a - self.b)
|
||||
elif self.operation == "MUL":
|
||||
return IntegerOutput(value=self.a * self.b)
|
||||
elif self.operation == "DIV":
|
||||
return IntegerOutput(value=int(self.a / self.b))
|
||||
elif self.operation == "EXP":
|
||||
return IntegerOutput(value=self.a**self.b)
|
||||
elif self.operation == "MOD":
|
||||
return IntegerOutput(value=self.a % self.b)
|
||||
elif self.operation == "ABS":
|
||||
return IntegerOutput(value=abs(self.a))
|
||||
elif self.operation == "MIN":
|
||||
return IntegerOutput(value=min(self.a, self.b))
|
||||
else: # self.operation == "MAX":
|
||||
return IntegerOutput(value=max(self.a, self.b))
|
||||
|
||||
|
||||
FLOAT_OPERATIONS = Literal[
|
||||
"ADD",
|
||||
"SUB",
|
||||
"MUL",
|
||||
"DIV",
|
||||
"EXP",
|
||||
"ABS",
|
||||
"SQRT",
|
||||
"MIN",
|
||||
"MAX",
|
||||
]
|
||||
|
||||
|
||||
FLOAT_OPERATIONS_LABELS = dict(
|
||||
ADD="Add A+B",
|
||||
SUB="Subtract A-B",
|
||||
MUL="Multiply A*B",
|
||||
DIV="Divide A/B",
|
||||
EXP="Exponentiate A^B",
|
||||
ABS="Absolute Value of A",
|
||||
SQRT="Square Root of A",
|
||||
MIN="Minimum(A,B)",
|
||||
MAX="Maximum(A,B)",
|
||||
)
|
||||
|
||||
|
||||
@invocation(
|
||||
"float_math",
|
||||
title="Float Math",
|
||||
tags=["math", "float", "add", "subtract", "multiply", "divide", "power", "root", "absolute value", "min", "max"],
|
||||
category="math",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FloatMathInvocation(BaseInvocation):
|
||||
"""Performs floating point math."""
|
||||
|
||||
operation: FLOAT_OPERATIONS = InputField(
|
||||
default="ADD", description="The operation to perform", ui_choice_labels=FLOAT_OPERATIONS_LABELS
|
||||
)
|
||||
a: float = InputField(default=0, description=FieldDescriptions.num_1)
|
||||
b: float = InputField(default=0, description=FieldDescriptions.num_2)
|
||||
|
||||
@validator("b")
|
||||
def no_unrepresentable_results(cls, v, values):
|
||||
if values["operation"] == "DIV" and v == 0:
|
||||
raise ValueError("Cannot divide by zero")
|
||||
elif values["operation"] == "EXP" and values["a"] == 0 and v < 0:
|
||||
raise ValueError("Cannot raise zero to a negative power")
|
||||
elif values["operation"] == "EXP" and type(values["a"] ** v) is complex:
|
||||
raise ValueError("Root operation resulted in a complex number")
|
||||
return v
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
# Python doesn't support switch statements until 3.10, but InvokeAI supports back to 3.9
|
||||
if self.operation == "ADD":
|
||||
return FloatOutput(value=self.a + self.b)
|
||||
elif self.operation == "SUB":
|
||||
return FloatOutput(value=self.a - self.b)
|
||||
elif self.operation == "MUL":
|
||||
return FloatOutput(value=self.a * self.b)
|
||||
elif self.operation == "DIV":
|
||||
return FloatOutput(value=self.a / self.b)
|
||||
elif self.operation == "EXP":
|
||||
return FloatOutput(value=self.a**self.b)
|
||||
elif self.operation == "SQRT":
|
||||
return FloatOutput(value=np.sqrt(self.a))
|
||||
elif self.operation == "ABS":
|
||||
return FloatOutput(value=abs(self.a))
|
||||
elif self.operation == "MIN":
|
||||
return FloatOutput(value=min(self.a, self.b))
|
||||
else: # self.operation == "MAX":
|
||||
return FloatOutput(value=max(self.a, self.b))
|
||||
|
||||
@ -1,4 +1,4 @@
|
||||
from typing import Literal, Optional
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import Field
|
||||
|
||||
@ -8,8 +8,8 @@ from invokeai.app.invocations.baseinvocation import (
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from invokeai.app.invocations.controlnet_image_processors import ControlField
|
||||
from invokeai.app.invocations.model import LoRAModelField, MainModelField, VAEModelField
|
||||
@ -42,7 +42,8 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
cfg_scale: float = Field(description="The classifier-free guidance scale parameter")
|
||||
steps: int = Field(description="The number of steps used for inference")
|
||||
scheduler: str = Field(description="The scheduler used for inference")
|
||||
clip_skip: int = Field(
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = Field(description="The main model used for inference")
|
||||
@ -72,10 +73,10 @@ class CoreMetadata(BaseModelExcludeNull):
|
||||
)
|
||||
refiner_steps: Optional[int] = Field(default=None, description="The number of steps used for the refiner")
|
||||
refiner_scheduler: Optional[str] = Field(default=None, description="The scheduler used for the refiner")
|
||||
refiner_positive_aesthetic_store: Optional[float] = Field(
|
||||
refiner_positive_aesthetic_score: Optional[float] = Field(
|
||||
default=None, description="The aesthetic score used for the refiner"
|
||||
)
|
||||
refiner_negative_aesthetic_store: Optional[float] = Field(
|
||||
refiner_negative_aesthetic_score: Optional[float] = Field(
|
||||
default=None, description="The aesthetic score used for the refiner"
|
||||
)
|
||||
refiner_start: Optional[float] = Field(default=None, description="The start value used for refiner denoising")
|
||||
@ -91,21 +92,19 @@ class ImageMetadata(BaseModelExcludeNull):
|
||||
graph: Optional[dict] = Field(default=None, description="The graph that created the image")
|
||||
|
||||
|
||||
@invocation_output("metadata_accumulator_output")
|
||||
class MetadataAccumulatorOutput(BaseInvocationOutput):
|
||||
"""The output of the MetadataAccumulator node"""
|
||||
|
||||
type: Literal["metadata_accumulator_output"] = "metadata_accumulator_output"
|
||||
|
||||
metadata: CoreMetadata = OutputField(description="The core metadata for the image")
|
||||
|
||||
|
||||
@title("Metadata Accumulator")
|
||||
@tags("metadata")
|
||||
@invocation(
|
||||
"metadata_accumulator", title="Metadata Accumulator", tags=["metadata"], category="metadata", version="1.0.0"
|
||||
)
|
||||
class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
"""Outputs a Core Metadata Object"""
|
||||
|
||||
type: Literal["metadata_accumulator"] = "metadata_accumulator"
|
||||
|
||||
generation_mode: str = InputField(
|
||||
description="The generation mode that output this image",
|
||||
)
|
||||
@ -118,7 +117,8 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
cfg_scale: float = InputField(description="The classifier-free guidance scale parameter")
|
||||
steps: int = InputField(description="The number of steps used for inference")
|
||||
scheduler: str = InputField(description="The scheduler used for inference")
|
||||
clip_skip: int = InputField(
|
||||
clip_skip: Optional[int] = Field(
|
||||
default=None,
|
||||
description="The number of skipped CLIP layers",
|
||||
)
|
||||
model: MainModelField = InputField(description="The main model used for inference")
|
||||
@ -164,11 +164,11 @@ class MetadataAccumulatorInvocation(BaseInvocation):
|
||||
default=None,
|
||||
description="The scheduler used for the refiner",
|
||||
)
|
||||
refiner_positive_aesthetic_store: Optional[float] = InputField(
|
||||
refiner_positive_aesthetic_score: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The aesthetic score used for the refiner",
|
||||
)
|
||||
refiner_negative_aesthetic_store: Optional[float] = InputField(
|
||||
refiner_negative_aesthetic_score: Optional[float] = InputField(
|
||||
default=None,
|
||||
description="The aesthetic score used for the refiner",
|
||||
)
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
import copy
|
||||
from typing import List, Literal, Optional
|
||||
from typing import List, Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
@ -8,13 +8,13 @@ from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
InputField,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
|
||||
|
||||
@ -33,6 +33,7 @@ class UNetField(BaseModel):
|
||||
unet: ModelInfo = Field(description="Info to load unet submodel")
|
||||
scheduler: ModelInfo = Field(description="Info to load scheduler submodel")
|
||||
loras: List[LoraInfo] = Field(description="Loras to apply on model loading")
|
||||
seamless_axes: List[str] = Field(default_factory=list, description='Axes("x" and "y") to which apply seamless')
|
||||
|
||||
|
||||
class ClipField(BaseModel):
|
||||
@ -45,13 +46,13 @@ class ClipField(BaseModel):
|
||||
class VaeField(BaseModel):
|
||||
# TODO: better naming?
|
||||
vae: ModelInfo = Field(description="Info to load vae submodel")
|
||||
seamless_axes: List[str] = Field(default_factory=list, description='Axes("x" and "y") to which apply seamless')
|
||||
|
||||
|
||||
@invocation_output("model_loader_output")
|
||||
class ModelLoaderOutput(BaseInvocationOutput):
|
||||
"""Model loader output"""
|
||||
|
||||
type: Literal["model_loader_output"] = "model_loader_output"
|
||||
|
||||
unet: UNetField = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
clip: ClipField = OutputField(description=FieldDescriptions.clip, title="CLIP")
|
||||
vae: VaeField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
@ -72,14 +73,10 @@ class LoRAModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
@title("Main Model")
|
||||
@tags("model")
|
||||
@invocation("main_model_loader", title="Main Model", tags=["model"], category="model", version="1.0.0")
|
||||
class MainModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a main model, outputting its submodels."""
|
||||
|
||||
type: Literal["main_model_loader"] = "main_model_loader"
|
||||
|
||||
# Inputs
|
||||
model: MainModelField = InputField(description=FieldDescriptions.main_model, input=Input.Direct)
|
||||
# TODO: precision?
|
||||
|
||||
@ -168,25 +165,18 @@ class MainModelLoaderInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("lora_loader_output")
|
||||
class LoraLoaderOutput(BaseInvocationOutput):
|
||||
"""Model loader output"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["lora_loader_output"] = "lora_loader_output"
|
||||
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
# fmt: on
|
||||
|
||||
|
||||
@title("LoRA")
|
||||
@tags("lora", "model")
|
||||
@invocation("lora_loader", title="LoRA", tags=["model"], category="model", version="1.0.0")
|
||||
class LoraLoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
type: Literal["lora_loader"] = "lora_loader"
|
||||
|
||||
# Inputs
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
@ -245,34 +235,28 @@ class LoraLoaderInvocation(BaseInvocation):
|
||||
return output
|
||||
|
||||
|
||||
@invocation_output("sdxl_lora_loader_output")
|
||||
class SDXLLoraLoaderOutput(BaseInvocationOutput):
|
||||
"""SDXL LoRA Loader Output"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["sdxl_lora_loader_output"] = "sdxl_lora_loader_output"
|
||||
|
||||
unet: Optional[UNetField] = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
clip: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP 1")
|
||||
clip2: Optional[ClipField] = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP 2")
|
||||
# fmt: on
|
||||
|
||||
|
||||
@title("SDXL LoRA")
|
||||
@tags("sdxl", "lora", "model")
|
||||
@invocation("sdxl_lora_loader", title="SDXL LoRA", tags=["lora", "model"], category="model", version="1.0.0")
|
||||
class SDXLLoraLoaderInvocation(BaseInvocation):
|
||||
"""Apply selected lora to unet and text_encoder."""
|
||||
|
||||
type: Literal["sdxl_lora_loader"] = "sdxl_lora_loader"
|
||||
|
||||
lora: LoRAModelField = InputField(description=FieldDescriptions.lora_model, input=Input.Direct, title="LoRA")
|
||||
weight: float = Field(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = Field(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNET"
|
||||
weight: float = InputField(default=0.75, description=FieldDescriptions.lora_weight)
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
)
|
||||
clip: Optional[ClipField] = Field(
|
||||
clip: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 1"
|
||||
)
|
||||
clip2: Optional[ClipField] = Field(
|
||||
clip2: Optional[ClipField] = InputField(
|
||||
default=None, description=FieldDescriptions.clip, input=Input.Connection, title="CLIP 2"
|
||||
)
|
||||
|
||||
@ -347,23 +331,17 @@ class VAEModelField(BaseModel):
|
||||
base_model: BaseModelType = Field(description="Base model")
|
||||
|
||||
|
||||
@invocation_output("vae_loader_output")
|
||||
class VaeLoaderOutput(BaseInvocationOutput):
|
||||
"""Model loader output"""
|
||||
"""VAE output"""
|
||||
|
||||
type: Literal["vae_loader_output"] = "vae_loader_output"
|
||||
|
||||
# Outputs
|
||||
vae: VaeField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@title("VAE")
|
||||
@tags("vae", "model")
|
||||
@invocation("vae_loader", title="VAE", tags=["vae", "model"], category="model", version="1.0.0")
|
||||
class VaeLoaderInvocation(BaseInvocation):
|
||||
"""Loads a VAE model, outputting a VaeLoaderOutput"""
|
||||
|
||||
type: Literal["vae_loader"] = "vae_loader"
|
||||
|
||||
# Inputs
|
||||
vae_model: VAEModelField = InputField(
|
||||
description=FieldDescriptions.vae_model, input=Input.Direct, ui_type=UIType.VaeModel, title="VAE"
|
||||
)
|
||||
@ -388,3 +366,44 @@ class VaeLoaderInvocation(BaseInvocation):
|
||||
)
|
||||
)
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("seamless_output")
|
||||
class SeamlessModeOutput(BaseInvocationOutput):
|
||||
"""Modified Seamless Model output"""
|
||||
|
||||
unet: Optional[UNetField] = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
vae: Optional[VaeField] = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@invocation("seamless", title="Seamless", tags=["seamless", "model"], category="model", version="1.0.0")
|
||||
class SeamlessModeInvocation(BaseInvocation):
|
||||
"""Applies the seamless transformation to the Model UNet and VAE."""
|
||||
|
||||
unet: Optional[UNetField] = InputField(
|
||||
default=None, description=FieldDescriptions.unet, input=Input.Connection, title="UNet"
|
||||
)
|
||||
vae: Optional[VaeField] = InputField(
|
||||
default=None, description=FieldDescriptions.vae_model, input=Input.Connection, title="VAE"
|
||||
)
|
||||
seamless_y: bool = InputField(default=True, input=Input.Any, description="Specify whether Y axis is seamless")
|
||||
seamless_x: bool = InputField(default=True, input=Input.Any, description="Specify whether X axis is seamless")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> SeamlessModeOutput:
|
||||
# Conditionally append 'x' and 'y' based on seamless_x and seamless_y
|
||||
unet = copy.deepcopy(self.unet)
|
||||
vae = copy.deepcopy(self.vae)
|
||||
|
||||
seamless_axes_list = []
|
||||
|
||||
if self.seamless_x:
|
||||
seamless_axes_list.append("x")
|
||||
if self.seamless_y:
|
||||
seamless_axes_list.append("y")
|
||||
|
||||
if unet is not None:
|
||||
unet.seamless_axes = seamless_axes_list
|
||||
if vae is not None:
|
||||
vae.seamless_axes = seamless_axes_list
|
||||
|
||||
return SeamlessModeOutput(unet=unet, vae=vae)
|
||||
|
||||
@ -1,6 +1,5 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654) & the InvokeAI Team
|
||||
|
||||
from typing import Literal
|
||||
|
||||
import torch
|
||||
from pydantic import validator
|
||||
@ -16,8 +15,8 @@ from .baseinvocation import (
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
|
||||
"""
|
||||
@ -62,12 +61,10 @@ Nodes
|
||||
"""
|
||||
|
||||
|
||||
@invocation_output("noise_output")
|
||||
class NoiseOutput(BaseInvocationOutput):
|
||||
"""Invocation noise output"""
|
||||
|
||||
type: Literal["noise_output"] = "noise_output"
|
||||
|
||||
# Inputs
|
||||
noise: LatentsField = OutputField(default=None, description=FieldDescriptions.noise)
|
||||
width: int = OutputField(description=FieldDescriptions.width)
|
||||
height: int = OutputField(description=FieldDescriptions.height)
|
||||
@ -81,14 +78,10 @@ def build_noise_output(latents_name: str, latents: torch.Tensor, seed: int):
|
||||
)
|
||||
|
||||
|
||||
@title("Noise")
|
||||
@tags("latents", "noise")
|
||||
@invocation("noise", title="Noise", tags=["latents", "noise"], category="latents", version="1.0.0")
|
||||
class NoiseInvocation(BaseInvocation):
|
||||
"""Generates latent noise."""
|
||||
|
||||
type: Literal["noise"] = "noise"
|
||||
|
||||
# Inputs
|
||||
seed: int = InputField(
|
||||
ge=0,
|
||||
le=SEED_MAX,
|
||||
|
||||
@ -25,14 +25,14 @@ from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
FieldDescriptions,
|
||||
InputField,
|
||||
Input,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIComponent,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from .controlnet_image_processors import ControlField
|
||||
from .latent import SAMPLER_NAME_VALUES, LatentsField, LatentsOutput, build_latents_output, get_scheduler
|
||||
@ -56,11 +56,8 @@ ORT_TO_NP_TYPE = {
|
||||
PRECISION_VALUES = Literal[tuple(list(ORT_TO_NP_TYPE.keys()))]
|
||||
|
||||
|
||||
@title("ONNX Prompt (Raw)")
|
||||
@tags("onnx", "prompt")
|
||||
@invocation("prompt_onnx", title="ONNX Prompt (Raw)", tags=["prompt", "onnx"], category="conditioning", version="1.0.0")
|
||||
class ONNXPromptInvocation(BaseInvocation):
|
||||
type: Literal["prompt_onnx"] = "prompt_onnx"
|
||||
|
||||
prompt: str = InputField(default="", description=FieldDescriptions.raw_prompt, ui_component=UIComponent.Textarea)
|
||||
clip: ClipField = InputField(description=FieldDescriptions.clip, input=Input.Connection)
|
||||
|
||||
@ -98,9 +95,10 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
print(f'Warn: trigger: "{trigger}" not found')
|
||||
if loras or ti_list:
|
||||
text_encoder.release_session()
|
||||
with ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras), ONNXModelPatcher.apply_ti(
|
||||
orig_tokenizer, text_encoder, ti_list
|
||||
) as (tokenizer, ti_manager):
|
||||
with (
|
||||
ONNXModelPatcher.apply_lora_text_encoder(text_encoder, loras),
|
||||
ONNXModelPatcher.apply_ti(orig_tokenizer, text_encoder, ti_list) as (tokenizer, ti_manager),
|
||||
):
|
||||
text_encoder.create_session()
|
||||
|
||||
# copy from
|
||||
@ -141,14 +139,16 @@ class ONNXPromptInvocation(BaseInvocation):
|
||||
|
||||
|
||||
# Text to image
|
||||
@title("ONNX Text to Latents")
|
||||
@tags("latents", "inference", "txt2img", "onnx")
|
||||
@invocation(
|
||||
"t2l_onnx",
|
||||
title="ONNX Text to Latents",
|
||||
tags=["latents", "inference", "txt2img", "onnx"],
|
||||
category="latents",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
"""Generates latents from conditionings."""
|
||||
|
||||
type: Literal["t2l_onnx"] = "t2l_onnx"
|
||||
|
||||
# Inputs
|
||||
positive_conditioning: ConditioningField = InputField(
|
||||
description=FieldDescriptions.positive_cond,
|
||||
input=Input.Connection,
|
||||
@ -166,7 +166,6 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
default=7.5,
|
||||
ge=1,
|
||||
description=FieldDescriptions.cfg_scale,
|
||||
ui_type=UIType.Float,
|
||||
)
|
||||
scheduler: SAMPLER_NAME_VALUES = InputField(
|
||||
default="euler", description=FieldDescriptions.scheduler, input=Input.Direct, ui_type=UIType.Scheduler
|
||||
@ -179,7 +178,6 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
control: Optional[Union[ControlField, list[ControlField]]] = InputField(
|
||||
default=None,
|
||||
description=FieldDescriptions.control,
|
||||
ui_type=UIType.Control,
|
||||
)
|
||||
# seamless: bool = InputField(default=False, description="Whether or not to generate an image that can tile without seams", )
|
||||
# seamless_axes: str = InputField(default="", description="The axes to tile the image on, 'x' and/or 'y'")
|
||||
@ -316,14 +314,16 @@ class ONNXTextToLatentsInvocation(BaseInvocation):
|
||||
|
||||
|
||||
# Latent to image
|
||||
@title("ONNX Latents to Image")
|
||||
@tags("latents", "image", "vae", "onnx")
|
||||
@invocation(
|
||||
"l2i_onnx",
|
||||
title="ONNX Latents to Image",
|
||||
tags=["latents", "image", "vae", "onnx"],
|
||||
category="image",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
"""Generates an image from latents."""
|
||||
|
||||
type: Literal["l2i_onnx"] = "l2i_onnx"
|
||||
|
||||
# Inputs
|
||||
latents: LatentsField = InputField(
|
||||
description=FieldDescriptions.denoised_latents,
|
||||
input=Input.Connection,
|
||||
@ -376,6 +376,7 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
metadata=self.metadata.dict() if self.metadata else None,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
@ -385,17 +386,14 @@ class ONNXLatentsToImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@invocation_output("model_loader_output_onnx")
|
||||
class ONNXModelLoaderOutput(BaseInvocationOutput):
|
||||
"""Model loader output"""
|
||||
|
||||
# fmt: off
|
||||
type: Literal["model_loader_output_onnx"] = "model_loader_output_onnx"
|
||||
|
||||
unet: UNetField = OutputField(default=None, description=FieldDescriptions.unet, title="UNet")
|
||||
clip: ClipField = OutputField(default=None, description=FieldDescriptions.clip, title="CLIP")
|
||||
vae_decoder: VaeField = OutputField(default=None, description=FieldDescriptions.vae, title="VAE Decoder")
|
||||
vae_encoder: VaeField = OutputField(default=None, description=FieldDescriptions.vae, title="VAE Encoder")
|
||||
# fmt: on
|
||||
|
||||
|
||||
class OnnxModelField(BaseModel):
|
||||
@ -406,14 +404,10 @@ class OnnxModelField(BaseModel):
|
||||
model_type: ModelType = Field(description="Model Type")
|
||||
|
||||
|
||||
@title("ONNX Main Model")
|
||||
@tags("onnx", "model")
|
||||
@invocation("onnx_model_loader", title="ONNX Main Model", tags=["onnx", "model"], category="model", version="1.0.0")
|
||||
class OnnxModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads a main model, outputting its submodels."""
|
||||
|
||||
type: Literal["onnx_model_loader"] = "onnx_model_loader"
|
||||
|
||||
# Inputs
|
||||
model: OnnxModelField = InputField(
|
||||
description=FieldDescriptions.onnx_main_model, input=Input.Direct, ui_type=UIType.ONNXModel
|
||||
)
|
||||
|
||||
@ -3,7 +3,6 @@ from typing import Literal, Optional
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import numpy as np
|
||||
|
||||
import PIL.Image
|
||||
from easing_functions import (
|
||||
BackEaseIn,
|
||||
@ -42,17 +41,13 @@ from matplotlib.ticker import MaxNLocator
|
||||
|
||||
from invokeai.app.invocations.primitives import FloatCollectionOutput
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, tags, title
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
|
||||
@title("Float Range")
|
||||
@tags("math", "range")
|
||||
@invocation("float_range", title="Float Range", tags=["math", "range"], category="math", version="1.0.0")
|
||||
class FloatLinearRangeInvocation(BaseInvocation):
|
||||
"""Creates a range"""
|
||||
|
||||
type: Literal["float_range"] = "float_range"
|
||||
|
||||
# Inputs
|
||||
start: float = InputField(default=5, description="The first value of the range")
|
||||
stop: float = InputField(default=10, description="The last value of the range")
|
||||
steps: int = InputField(default=30, description="number of values to interpolate over (including start and stop)")
|
||||
@ -100,14 +95,10 @@ EASING_FUNCTION_KEYS = Literal[tuple(list(EASING_FUNCTIONS_MAP.keys()))]
|
||||
|
||||
|
||||
# actually I think for now could just use CollectionOutput (which is list[Any]
|
||||
@title("Step Param Easing")
|
||||
@tags("step", "easing")
|
||||
@invocation("step_param_easing", title="Step Param Easing", tags=["step", "easing"], category="step", version="1.0.0")
|
||||
class StepParamEasingInvocation(BaseInvocation):
|
||||
"""Experimental per-step parameter easing for denoising steps"""
|
||||
|
||||
type: Literal["step_param_easing"] = "step_param_easing"
|
||||
|
||||
# Inputs
|
||||
easing: EASING_FUNCTION_KEYS = InputField(default="Linear", description="The easing function to use")
|
||||
num_steps: int = InputField(default=20, description="number of denoising steps")
|
||||
start_value: float = InputField(default=0.0, description="easing starting value")
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
# Copyright (c) 2023 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from typing import Literal, Optional, Tuple
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
from pydantic import BaseModel, Field
|
||||
@ -14,9 +14,8 @@ from .baseinvocation import (
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIComponent,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
|
||||
"""
|
||||
@ -29,47 +28,45 @@ Primitives: Boolean, Integer, Float, String, Image, Latents, Conditioning, Color
|
||||
# region Boolean
|
||||
|
||||
|
||||
@invocation_output("boolean_output")
|
||||
class BooleanOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single boolean"""
|
||||
|
||||
type: Literal["boolean_output"] = "boolean_output"
|
||||
value: bool = OutputField(description="The output boolean")
|
||||
|
||||
|
||||
@invocation_output("boolean_collection_output")
|
||||
class BooleanCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of booleans"""
|
||||
|
||||
type: Literal["boolean_collection_output"] = "boolean_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[bool] = OutputField(description="The output boolean collection", ui_type=UIType.BooleanCollection)
|
||||
collection: list[bool] = OutputField(
|
||||
description="The output boolean collection",
|
||||
)
|
||||
|
||||
|
||||
@title("Boolean Primitive")
|
||||
@tags("primitives", "boolean")
|
||||
@invocation(
|
||||
"boolean", title="Boolean Primitive", tags=["primitives", "boolean"], category="primitives", version="1.0.0"
|
||||
)
|
||||
class BooleanInvocation(BaseInvocation):
|
||||
"""A boolean primitive value"""
|
||||
|
||||
type: Literal["boolean"] = "boolean"
|
||||
|
||||
# Inputs
|
||||
value: bool = InputField(default=False, description="The boolean value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> BooleanOutput:
|
||||
return BooleanOutput(value=self.value)
|
||||
|
||||
|
||||
@title("Boolean Primitive Collection")
|
||||
@tags("primitives", "boolean", "collection")
|
||||
@invocation(
|
||||
"boolean_collection",
|
||||
title="Boolean Collection Primitive",
|
||||
tags=["primitives", "boolean", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class BooleanCollectionInvocation(BaseInvocation):
|
||||
"""A collection of boolean primitive values"""
|
||||
|
||||
type: Literal["boolean_collection"] = "boolean_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[bool] = InputField(
|
||||
default_factory=list, description="The collection of boolean values", ui_type=UIType.BooleanCollection
|
||||
)
|
||||
collection: list[bool] = InputField(default_factory=list, description="The collection of boolean values")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> BooleanCollectionOutput:
|
||||
return BooleanCollectionOutput(collection=self.collection)
|
||||
@ -80,47 +77,45 @@ class BooleanCollectionInvocation(BaseInvocation):
|
||||
# region Integer
|
||||
|
||||
|
||||
@invocation_output("integer_output")
|
||||
class IntegerOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single integer"""
|
||||
|
||||
type: Literal["integer_output"] = "integer_output"
|
||||
value: int = OutputField(description="The output integer")
|
||||
|
||||
|
||||
@invocation_output("integer_collection_output")
|
||||
class IntegerCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of integers"""
|
||||
|
||||
type: Literal["integer_collection_output"] = "integer_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[int] = OutputField(description="The int collection", ui_type=UIType.IntegerCollection)
|
||||
collection: list[int] = OutputField(
|
||||
description="The int collection",
|
||||
)
|
||||
|
||||
|
||||
@title("Integer Primitive")
|
||||
@tags("primitives", "integer")
|
||||
@invocation(
|
||||
"integer", title="Integer Primitive", tags=["primitives", "integer"], category="primitives", version="1.0.0"
|
||||
)
|
||||
class IntegerInvocation(BaseInvocation):
|
||||
"""An integer primitive value"""
|
||||
|
||||
type: Literal["integer"] = "integer"
|
||||
|
||||
# Inputs
|
||||
value: int = InputField(default=0, description="The integer value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerOutput:
|
||||
return IntegerOutput(value=self.value)
|
||||
|
||||
|
||||
@title("Integer Primitive Collection")
|
||||
@tags("primitives", "integer", "collection")
|
||||
@invocation(
|
||||
"integer_collection",
|
||||
title="Integer Collection Primitive",
|
||||
tags=["primitives", "integer", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class IntegerCollectionInvocation(BaseInvocation):
|
||||
"""A collection of integer primitive values"""
|
||||
|
||||
type: Literal["integer_collection"] = "integer_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[int] = InputField(
|
||||
default=0, description="The collection of integer values", ui_type=UIType.IntegerCollection
|
||||
)
|
||||
collection: list[int] = InputField(default_factory=list, description="The collection of integer values")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> IntegerCollectionOutput:
|
||||
return IntegerCollectionOutput(collection=self.collection)
|
||||
@ -131,47 +126,43 @@ class IntegerCollectionInvocation(BaseInvocation):
|
||||
# region Float
|
||||
|
||||
|
||||
@invocation_output("float_output")
|
||||
class FloatOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single float"""
|
||||
|
||||
type: Literal["float_output"] = "float_output"
|
||||
value: float = OutputField(description="The output float")
|
||||
|
||||
|
||||
@invocation_output("float_collection_output")
|
||||
class FloatCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of floats"""
|
||||
|
||||
type: Literal["float_collection_output"] = "float_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[float] = OutputField(description="The float collection", ui_type=UIType.FloatCollection)
|
||||
collection: list[float] = OutputField(
|
||||
description="The float collection",
|
||||
)
|
||||
|
||||
|
||||
@title("Float Primitive")
|
||||
@tags("primitives", "float")
|
||||
@invocation("float", title="Float Primitive", tags=["primitives", "float"], category="primitives", version="1.0.0")
|
||||
class FloatInvocation(BaseInvocation):
|
||||
"""A float primitive value"""
|
||||
|
||||
type: Literal["float"] = "float"
|
||||
|
||||
# Inputs
|
||||
value: float = InputField(default=0.0, description="The float value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatOutput:
|
||||
return FloatOutput(value=self.value)
|
||||
|
||||
|
||||
@title("Float Primitive Collection")
|
||||
@tags("primitives", "float", "collection")
|
||||
@invocation(
|
||||
"float_collection",
|
||||
title="Float Collection Primitive",
|
||||
tags=["primitives", "float", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class FloatCollectionInvocation(BaseInvocation):
|
||||
"""A collection of float primitive values"""
|
||||
|
||||
type: Literal["float_collection"] = "float_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[float] = InputField(
|
||||
default_factory=list, description="The collection of float values", ui_type=UIType.FloatCollection
|
||||
)
|
||||
collection: list[float] = InputField(default_factory=list, description="The collection of float values")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> FloatCollectionOutput:
|
||||
return FloatCollectionOutput(collection=self.collection)
|
||||
@ -182,47 +173,43 @@ class FloatCollectionInvocation(BaseInvocation):
|
||||
# region String
|
||||
|
||||
|
||||
@invocation_output("string_output")
|
||||
class StringOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single string"""
|
||||
|
||||
type: Literal["string_output"] = "string_output"
|
||||
value: str = OutputField(description="The output string")
|
||||
|
||||
|
||||
@invocation_output("string_collection_output")
|
||||
class StringCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of strings"""
|
||||
|
||||
type: Literal["string_collection_output"] = "string_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[str] = OutputField(description="The output strings", ui_type=UIType.StringCollection)
|
||||
collection: list[str] = OutputField(
|
||||
description="The output strings",
|
||||
)
|
||||
|
||||
|
||||
@title("String Primitive")
|
||||
@tags("primitives", "string")
|
||||
@invocation("string", title="String Primitive", tags=["primitives", "string"], category="primitives", version="1.0.0")
|
||||
class StringInvocation(BaseInvocation):
|
||||
"""A string primitive value"""
|
||||
|
||||
type: Literal["string"] = "string"
|
||||
|
||||
# Inputs
|
||||
value: str = InputField(default="", description="The string value", ui_component=UIComponent.Textarea)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringOutput:
|
||||
return StringOutput(value=self.value)
|
||||
|
||||
|
||||
@title("String Primitive Collection")
|
||||
@tags("primitives", "string", "collection")
|
||||
@invocation(
|
||||
"string_collection",
|
||||
title="String Collection Primitive",
|
||||
tags=["primitives", "string", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class StringCollectionInvocation(BaseInvocation):
|
||||
"""A collection of string primitive values"""
|
||||
|
||||
type: Literal["string_collection"] = "string_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[str] = InputField(
|
||||
default_factory=list, description="The collection of string values", ui_type=UIType.StringCollection
|
||||
)
|
||||
collection: list[str] = InputField(default_factory=list, description="The collection of string values")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringCollectionOutput:
|
||||
return StringCollectionOutput(collection=self.collection)
|
||||
@ -239,33 +226,28 @@ class ImageField(BaseModel):
|
||||
image_name: str = Field(description="The name of the image")
|
||||
|
||||
|
||||
@invocation_output("image_output")
|
||||
class ImageOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
type: Literal["image_output"] = "image_output"
|
||||
image: ImageField = OutputField(description="The output image")
|
||||
width: int = OutputField(description="The width of the image in pixels")
|
||||
height: int = OutputField(description="The height of the image in pixels")
|
||||
|
||||
|
||||
@invocation_output("image_collection_output")
|
||||
class ImageCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of images"""
|
||||
|
||||
type: Literal["image_collection_output"] = "image_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[ImageField] = OutputField(description="The output images", ui_type=UIType.ImageCollection)
|
||||
collection: list[ImageField] = OutputField(
|
||||
description="The output images",
|
||||
)
|
||||
|
||||
|
||||
@title("Image Primitive")
|
||||
@tags("primitives", "image")
|
||||
@invocation("image", title="Image Primitive", tags=["primitives", "image"], category="primitives", version="1.0.0")
|
||||
class ImageInvocation(BaseInvocation):
|
||||
"""An image primitive value"""
|
||||
|
||||
# Metadata
|
||||
type: Literal["image"] = "image"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The image to load")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageOutput:
|
||||
@ -278,22 +260,41 @@ class ImageInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("Image Primitive Collection")
|
||||
@tags("primitives", "image", "collection")
|
||||
@invocation(
|
||||
"image_collection",
|
||||
title="Image Collection Primitive",
|
||||
tags=["primitives", "image", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ImageCollectionInvocation(BaseInvocation):
|
||||
"""A collection of image primitive values"""
|
||||
|
||||
type: Literal["image_collection"] = "image_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[ImageField] = InputField(
|
||||
default=0, description="The collection of image values", ui_type=UIType.ImageCollection
|
||||
)
|
||||
collection: list[ImageField] = InputField(description="The collection of image values")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ImageCollectionOutput:
|
||||
return ImageCollectionOutput(collection=self.collection)
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region DenoiseMask
|
||||
|
||||
|
||||
class DenoiseMaskField(BaseModel):
|
||||
"""An inpaint mask field"""
|
||||
|
||||
mask_name: str = Field(description="The name of the mask image")
|
||||
masked_latents_name: Optional[str] = Field(description="The name of the masked image latents")
|
||||
|
||||
|
||||
@invocation_output("denoise_mask_output")
|
||||
class DenoiseMaskOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single image"""
|
||||
|
||||
denoise_mask: DenoiseMaskField = OutputField(description="Mask for denoise model run")
|
||||
|
||||
|
||||
# endregion
|
||||
|
||||
# region Latents
|
||||
@ -306,11 +307,10 @@ class LatentsField(BaseModel):
|
||||
seed: Optional[int] = Field(default=None, description="Seed used to generate this latents")
|
||||
|
||||
|
||||
@invocation_output("latents_output")
|
||||
class LatentsOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single latents tensor"""
|
||||
|
||||
type: Literal["latents_output"] = "latents_output"
|
||||
|
||||
latents: LatentsField = OutputField(
|
||||
description=FieldDescriptions.latents,
|
||||
)
|
||||
@ -318,25 +318,21 @@ class LatentsOutput(BaseInvocationOutput):
|
||||
height: int = OutputField(description=FieldDescriptions.height)
|
||||
|
||||
|
||||
@invocation_output("latents_collection_output")
|
||||
class LatentsCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of latents tensors"""
|
||||
|
||||
type: Literal["latents_collection_output"] = "latents_collection_output"
|
||||
|
||||
collection: list[LatentsField] = OutputField(
|
||||
description=FieldDescriptions.latents,
|
||||
ui_type=UIType.LatentsCollection,
|
||||
)
|
||||
|
||||
|
||||
@title("Latents Primitive")
|
||||
@tags("primitives", "latents")
|
||||
@invocation(
|
||||
"latents", title="Latents Primitive", tags=["primitives", "latents"], category="primitives", version="1.0.0"
|
||||
)
|
||||
class LatentsInvocation(BaseInvocation):
|
||||
"""A latents tensor primitive value"""
|
||||
|
||||
type: Literal["latents"] = "latents"
|
||||
|
||||
# Inputs
|
||||
latents: LatentsField = InputField(description="The latents tensor", input=Input.Connection)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> LatentsOutput:
|
||||
@ -345,16 +341,18 @@ class LatentsInvocation(BaseInvocation):
|
||||
return build_latents_output(self.latents.latents_name, latents)
|
||||
|
||||
|
||||
@title("Latents Primitive Collection")
|
||||
@tags("primitives", "latents", "collection")
|
||||
@invocation(
|
||||
"latents_collection",
|
||||
title="Latents Collection Primitive",
|
||||
tags=["primitives", "latents", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class LatentsCollectionInvocation(BaseInvocation):
|
||||
"""A collection of latents tensor primitive values"""
|
||||
|
||||
type: Literal["latents_collection"] = "latents_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[LatentsField] = InputField(
|
||||
description="The collection of latents tensors", ui_type=UIType.LatentsCollection
|
||||
description="The collection of latents tensors",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> LatentsCollectionOutput:
|
||||
@ -386,30 +384,26 @@ class ColorField(BaseModel):
|
||||
return (self.r, self.g, self.b, self.a)
|
||||
|
||||
|
||||
@invocation_output("color_output")
|
||||
class ColorOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single color"""
|
||||
|
||||
type: Literal["color_output"] = "color_output"
|
||||
color: ColorField = OutputField(description="The output color")
|
||||
|
||||
|
||||
@invocation_output("color_collection_output")
|
||||
class ColorCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of colors"""
|
||||
|
||||
type: Literal["color_collection_output"] = "color_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[ColorField] = OutputField(description="The output colors", ui_type=UIType.ColorCollection)
|
||||
collection: list[ColorField] = OutputField(
|
||||
description="The output colors",
|
||||
)
|
||||
|
||||
|
||||
@title("Color Primitive")
|
||||
@tags("primitives", "color")
|
||||
@invocation("color", title="Color Primitive", tags=["primitives", "color"], category="primitives", version="1.0.0")
|
||||
class ColorInvocation(BaseInvocation):
|
||||
"""A color primitive value"""
|
||||
|
||||
type: Literal["color"] = "color"
|
||||
|
||||
# Inputs
|
||||
color: ColorField = InputField(default=ColorField(r=0, g=0, b=0, a=255), description="The color value")
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ColorOutput:
|
||||
@ -427,49 +421,51 @@ class ConditioningField(BaseModel):
|
||||
conditioning_name: str = Field(description="The name of conditioning tensor")
|
||||
|
||||
|
||||
@invocation_output("conditioning_output")
|
||||
class ConditioningOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a single conditioning tensor"""
|
||||
|
||||
type: Literal["conditioning_output"] = "conditioning_output"
|
||||
|
||||
conditioning: ConditioningField = OutputField(description=FieldDescriptions.cond)
|
||||
|
||||
|
||||
@invocation_output("conditioning_collection_output")
|
||||
class ConditioningCollectionOutput(BaseInvocationOutput):
|
||||
"""Base class for nodes that output a collection of conditioning tensors"""
|
||||
|
||||
type: Literal["conditioning_collection_output"] = "conditioning_collection_output"
|
||||
|
||||
# Outputs
|
||||
collection: list[ConditioningField] = OutputField(
|
||||
description="The output conditioning tensors",
|
||||
ui_type=UIType.ConditioningCollection,
|
||||
)
|
||||
|
||||
|
||||
@title("Conditioning Primitive")
|
||||
@tags("primitives", "conditioning")
|
||||
@invocation(
|
||||
"conditioning",
|
||||
title="Conditioning Primitive",
|
||||
tags=["primitives", "conditioning"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ConditioningInvocation(BaseInvocation):
|
||||
"""A conditioning tensor primitive value"""
|
||||
|
||||
type: Literal["conditioning"] = "conditioning"
|
||||
|
||||
conditioning: ConditioningField = InputField(description=FieldDescriptions.cond, input=Input.Connection)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ConditioningOutput:
|
||||
return ConditioningOutput(conditioning=self.conditioning)
|
||||
|
||||
|
||||
@title("Conditioning Primitive Collection")
|
||||
@tags("primitives", "conditioning", "collection")
|
||||
@invocation(
|
||||
"conditioning_collection",
|
||||
title="Conditioning Collection Primitive",
|
||||
tags=["primitives", "conditioning", "collection"],
|
||||
category="primitives",
|
||||
version="1.0.0",
|
||||
)
|
||||
class ConditioningCollectionInvocation(BaseInvocation):
|
||||
"""A collection of conditioning tensor primitive values"""
|
||||
|
||||
type: Literal["conditioning_collection"] = "conditioning_collection"
|
||||
|
||||
# Inputs
|
||||
collection: list[ConditioningField] = InputField(
|
||||
default=0, description="The collection of conditioning tensors", ui_type=UIType.ConditioningCollection
|
||||
default_factory=list,
|
||||
description="The collection of conditioning tensors",
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> ConditioningCollectionOutput:
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
from os.path import exists
|
||||
from typing import Literal, Optional, Union
|
||||
from typing import Optional, Union
|
||||
|
||||
import numpy as np
|
||||
from dynamicprompts.generators import CombinatorialPromptGenerator, RandomPromptGenerator
|
||||
@ -7,17 +7,20 @@ from pydantic import validator
|
||||
|
||||
from invokeai.app.invocations.primitives import StringCollectionOutput
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, UIComponent, UIType, tags, title
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, UIComponent, invocation
|
||||
|
||||
|
||||
@title("Dynamic Prompt")
|
||||
@tags("prompt", "collection")
|
||||
@invocation(
|
||||
"dynamic_prompt",
|
||||
title="Dynamic Prompt",
|
||||
tags=["prompt", "collection"],
|
||||
category="prompt",
|
||||
version="1.0.0",
|
||||
use_cache=False,
|
||||
)
|
||||
class DynamicPromptInvocation(BaseInvocation):
|
||||
"""Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator"""
|
||||
|
||||
type: Literal["dynamic_prompt"] = "dynamic_prompt"
|
||||
|
||||
# Inputs
|
||||
prompt: str = InputField(description="The prompt to parse with dynamicprompts", ui_component=UIComponent.Textarea)
|
||||
max_prompts: int = InputField(default=1, description="The number of prompts to generate")
|
||||
combinatorial: bool = InputField(default=False, description="Whether to use the combinatorial generator")
|
||||
@ -33,15 +36,11 @@ class DynamicPromptInvocation(BaseInvocation):
|
||||
return StringCollectionOutput(collection=prompts)
|
||||
|
||||
|
||||
@title("Prompts from File")
|
||||
@tags("prompt", "file")
|
||||
@invocation("prompt_from_file", title="Prompts from File", tags=["prompt", "file"], category="prompt", version="1.0.0")
|
||||
class PromptsFromFileInvocation(BaseInvocation):
|
||||
"""Loads prompts from a text file"""
|
||||
|
||||
type: Literal["prompt_from_file"] = "prompt_from_file"
|
||||
|
||||
# Inputs
|
||||
file_path: str = InputField(description="Path to prompt text file", ui_type=UIType.FilePath)
|
||||
file_path: str = InputField(description="Path to prompt text file")
|
||||
pre_prompt: Optional[str] = InputField(
|
||||
default=None, description="String to prepend to each prompt", ui_component=UIComponent.Textarea
|
||||
)
|
||||
|
||||
@ -1,5 +1,3 @@
|
||||
from typing import Literal
|
||||
|
||||
from ...backend.model_management import ModelType, SubModelType
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
@ -10,41 +8,35 @@ from .baseinvocation import (
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
tags,
|
||||
title,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from .model import ClipField, MainModelField, ModelInfo, UNetField, VaeField
|
||||
|
||||
|
||||
@invocation_output("sdxl_model_loader_output")
|
||||
class SDXLModelLoaderOutput(BaseInvocationOutput):
|
||||
"""SDXL base model loader output"""
|
||||
|
||||
type: Literal["sdxl_model_loader_output"] = "sdxl_model_loader_output"
|
||||
|
||||
unet: UNetField = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
clip: ClipField = OutputField(description=FieldDescriptions.clip, title="CLIP 1")
|
||||
clip2: ClipField = OutputField(description=FieldDescriptions.clip, title="CLIP 2")
|
||||
vae: VaeField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@invocation_output("sdxl_refiner_model_loader_output")
|
||||
class SDXLRefinerModelLoaderOutput(BaseInvocationOutput):
|
||||
"""SDXL refiner model loader output"""
|
||||
|
||||
type: Literal["sdxl_refiner_model_loader_output"] = "sdxl_refiner_model_loader_output"
|
||||
|
||||
unet: UNetField = OutputField(description=FieldDescriptions.unet, title="UNet")
|
||||
clip2: ClipField = OutputField(description=FieldDescriptions.clip, title="CLIP 2")
|
||||
vae: VaeField = OutputField(description=FieldDescriptions.vae, title="VAE")
|
||||
|
||||
|
||||
@title("SDXL Main Model")
|
||||
@tags("model", "sdxl")
|
||||
@invocation("sdxl_model_loader", title="SDXL Main Model", tags=["model", "sdxl"], category="model", version="1.0.0")
|
||||
class SDXLModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads an sdxl base model, outputting its submodels."""
|
||||
|
||||
type: Literal["sdxl_model_loader"] = "sdxl_model_loader"
|
||||
|
||||
# Inputs
|
||||
model: MainModelField = InputField(
|
||||
description=FieldDescriptions.sdxl_main_model, input=Input.Direct, ui_type=UIType.SDXLMainModel
|
||||
)
|
||||
@ -122,14 +114,16 @@ class SDXLModelLoaderInvocation(BaseInvocation):
|
||||
)
|
||||
|
||||
|
||||
@title("SDXL Refiner Model")
|
||||
@tags("model", "sdxl", "refiner")
|
||||
@invocation(
|
||||
"sdxl_refiner_model_loader",
|
||||
title="SDXL Refiner Model",
|
||||
tags=["model", "sdxl", "refiner"],
|
||||
category="model",
|
||||
version="1.0.0",
|
||||
)
|
||||
class SDXLRefinerModelLoaderInvocation(BaseInvocation):
|
||||
"""Loads an sdxl refiner model, outputting its submodels."""
|
||||
|
||||
type: Literal["sdxl_refiner_model_loader"] = "sdxl_refiner_model_loader"
|
||||
|
||||
# Inputs
|
||||
model: MainModelField = InputField(
|
||||
description=FieldDescriptions.sdxl_refiner_model,
|
||||
input=Input.Direct,
|
||||
|
||||
139
invokeai/app/invocations/strings.py
Normal file
@ -0,0 +1,139 @@
|
||||
# 2023 skunkworxdark (https://github.com/skunkworxdark)
|
||||
|
||||
import re
|
||||
|
||||
from .baseinvocation import (
|
||||
BaseInvocation,
|
||||
BaseInvocationOutput,
|
||||
InputField,
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIComponent,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
from .primitives import StringOutput
|
||||
|
||||
|
||||
@invocation_output("string_pos_neg_output")
|
||||
class StringPosNegOutput(BaseInvocationOutput):
|
||||
"""Base class for invocations that output a positive and negative string"""
|
||||
|
||||
positive_string: str = OutputField(description="Positive string")
|
||||
negative_string: str = OutputField(description="Negative string")
|
||||
|
||||
|
||||
@invocation(
|
||||
"string_split_neg",
|
||||
title="String Split Negative",
|
||||
tags=["string", "split", "negative"],
|
||||
category="string",
|
||||
version="1.0.0",
|
||||
)
|
||||
class StringSplitNegInvocation(BaseInvocation):
|
||||
"""Splits string into two strings, inside [] goes into negative string everthing else goes into positive string. Each [ and ] character is replaced with a space"""
|
||||
|
||||
string: str = InputField(default="", description="String to split", ui_component=UIComponent.Textarea)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringPosNegOutput:
|
||||
p_string = ""
|
||||
n_string = ""
|
||||
brackets_depth = 0
|
||||
escaped = False
|
||||
|
||||
for char in self.string or "":
|
||||
if char == "[" and not escaped:
|
||||
n_string += " "
|
||||
brackets_depth += 1
|
||||
elif char == "]" and not escaped:
|
||||
brackets_depth -= 1
|
||||
char = " "
|
||||
elif brackets_depth > 0:
|
||||
n_string += char
|
||||
else:
|
||||
p_string += char
|
||||
|
||||
# keep track of the escape char but only if it isn't escaped already
|
||||
if char == "\\" and not escaped:
|
||||
escaped = True
|
||||
else:
|
||||
escaped = False
|
||||
|
||||
return StringPosNegOutput(positive_string=p_string, negative_string=n_string)
|
||||
|
||||
|
||||
@invocation_output("string_2_output")
|
||||
class String2Output(BaseInvocationOutput):
|
||||
"""Base class for invocations that output two strings"""
|
||||
|
||||
string_1: str = OutputField(description="string 1")
|
||||
string_2: str = OutputField(description="string 2")
|
||||
|
||||
|
||||
@invocation("string_split", title="String Split", tags=["string", "split"], category="string", version="1.0.0")
|
||||
class StringSplitInvocation(BaseInvocation):
|
||||
"""Splits string into two strings, based on the first occurance of the delimiter. The delimiter will be removed from the string"""
|
||||
|
||||
string: str = InputField(default="", description="String to split", ui_component=UIComponent.Textarea)
|
||||
delimiter: str = InputField(
|
||||
default="", description="Delimiter to spilt with. blank will split on the first whitespace"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> String2Output:
|
||||
result = self.string.split(self.delimiter, 1)
|
||||
if len(result) == 2:
|
||||
part1, part2 = result
|
||||
else:
|
||||
part1 = result[0]
|
||||
part2 = ""
|
||||
|
||||
return String2Output(string_1=part1, string_2=part2)
|
||||
|
||||
|
||||
@invocation("string_join", title="String Join", tags=["string", "join"], category="string", version="1.0.0")
|
||||
class StringJoinInvocation(BaseInvocation):
|
||||
"""Joins string left to string right"""
|
||||
|
||||
string_left: str = InputField(default="", description="String Left", ui_component=UIComponent.Textarea)
|
||||
string_right: str = InputField(default="", description="String Right", ui_component=UIComponent.Textarea)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringOutput:
|
||||
return StringOutput(value=((self.string_left or "") + (self.string_right or "")))
|
||||
|
||||
|
||||
@invocation("string_join_three", title="String Join Three", tags=["string", "join"], category="string", version="1.0.0")
|
||||
class StringJoinThreeInvocation(BaseInvocation):
|
||||
"""Joins string left to string middle to string right"""
|
||||
|
||||
string_left: str = InputField(default="", description="String Left", ui_component=UIComponent.Textarea)
|
||||
string_middle: str = InputField(default="", description="String Middle", ui_component=UIComponent.Textarea)
|
||||
string_right: str = InputField(default="", description="String Right", ui_component=UIComponent.Textarea)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringOutput:
|
||||
return StringOutput(value=((self.string_left or "") + (self.string_middle or "") + (self.string_right or "")))
|
||||
|
||||
|
||||
@invocation(
|
||||
"string_replace", title="String Replace", tags=["string", "replace", "regex"], category="string", version="1.0.0"
|
||||
)
|
||||
class StringReplaceInvocation(BaseInvocation):
|
||||
"""Replaces the search string with the replace string"""
|
||||
|
||||
string: str = InputField(default="", description="String to work on", ui_component=UIComponent.Textarea)
|
||||
search_string: str = InputField(default="", description="String to search for", ui_component=UIComponent.Textarea)
|
||||
replace_string: str = InputField(
|
||||
default="", description="String to replace the search", ui_component=UIComponent.Textarea
|
||||
)
|
||||
use_regex: bool = InputField(
|
||||
default=False, description="Use search string as a regex expression (non regex is case insensitive)"
|
||||
)
|
||||
|
||||
def invoke(self, context: InvocationContext) -> StringOutput:
|
||||
pattern = self.search_string or ""
|
||||
new_string = self.string or ""
|
||||
if len(pattern) > 0:
|
||||
if not self.use_regex:
|
||||
# None regex so make case insensitve
|
||||
pattern = "(?i)" + re.escape(pattern)
|
||||
new_string = re.sub(pattern, (self.replace_string or ""), new_string)
|
||||
return StringOutput(value=new_string)
|
||||
@ -7,11 +7,11 @@ import numpy as np
|
||||
from basicsr.archs.rrdbnet_arch import RRDBNet
|
||||
from PIL import Image
|
||||
from realesrgan import RealESRGANer
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
|
||||
from invokeai.app.invocations.primitives import ImageField, ImageOutput
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, title, tags
|
||||
from .baseinvocation import BaseInvocation, InputField, InvocationContext, invocation
|
||||
|
||||
# TODO: Populate this from disk?
|
||||
# TODO: Use model manager to load?
|
||||
@ -23,14 +23,10 @@ ESRGAN_MODELS = Literal[
|
||||
]
|
||||
|
||||
|
||||
@title("Upscale (RealESRGAN)")
|
||||
@tags("esrgan", "upscale")
|
||||
@invocation("esrgan", title="Upscale (RealESRGAN)", tags=["esrgan", "upscale"], category="esrgan", version="1.0.0")
|
||||
class ESRGANInvocation(BaseInvocation):
|
||||
"""Upscales an image using RealESRGAN."""
|
||||
|
||||
type: Literal["esrgan"] = "esrgan"
|
||||
|
||||
# Inputs
|
||||
image: ImageField = InputField(description="The input image")
|
||||
model_name: ESRGAN_MODELS = InputField(default="RealESRGAN_x4plus.pth", description="The Real-ESRGAN model to use")
|
||||
|
||||
@ -110,6 +106,7 @@ class ESRGANInvocation(BaseInvocation):
|
||||
node_id=self.id,
|
||||
session_id=context.graph_execution_state_id,
|
||||
is_intermediate=self.is_intermediate,
|
||||
workflow=self.workflow,
|
||||
)
|
||||
|
||||
return ImageOutput(
|
||||
|
||||
@ -1,13 +1,10 @@
|
||||
from abc import ABC, abstractmethod
|
||||
import sqlite3
|
||||
import threading
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional, cast
|
||||
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.image_record import (
|
||||
ImageRecord,
|
||||
deserialize_image_record,
|
||||
)
|
||||
from invokeai.app.services.models.image_record import ImageRecord, deserialize_image_record
|
||||
|
||||
|
||||
class BoardImageRecordStorageBase(ABC):
|
||||
@ -56,24 +53,20 @@ class BoardImageRecordStorageBase(ABC):
|
||||
|
||||
|
||||
class SqliteBoardImageRecordStorage(BoardImageRecordStorageBase):
|
||||
_filename: str
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, filename: str) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._filename = filename
|
||||
self._conn = sqlite3.connect(filename, check_same_thread=False)
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = threading.Lock()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
# Enable foreign keys
|
||||
self._conn.execute("PRAGMA foreign_keys = ON;")
|
||||
self._create_tables()
|
||||
self._conn.commit()
|
||||
finally:
|
||||
|
||||
@ -1,12 +1,9 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
from typing import Optional
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.board_record_storage import (
|
||||
BoardRecord,
|
||||
BoardRecordStorageBase,
|
||||
)
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.board_record_storage import BoardRecord, BoardRecordStorageBase
|
||||
from invokeai.app.services.image_record_storage import ImageRecordStorageBase
|
||||
from invokeai.app.services.models.board_record import BoardDTO
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
|
||||
@ -1,15 +1,13 @@
|
||||
import sqlite3
|
||||
import threading
|
||||
import uuid
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union, cast
|
||||
|
||||
import sqlite3
|
||||
from pydantic import BaseModel, Extra, Field
|
||||
|
||||
from invokeai.app.services.image_record_storage import OffsetPaginatedResults
|
||||
from invokeai.app.services.models.board_record import (
|
||||
BoardRecord,
|
||||
deserialize_board_record,
|
||||
)
|
||||
from pydantic import BaseModel, Field, Extra
|
||||
from invokeai.app.services.models.board_record import BoardRecord, deserialize_board_record
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
|
||||
class BoardChanges(BaseModel, extra=Extra.forbid):
|
||||
@ -89,24 +87,20 @@ class BoardRecordStorageBase(ABC):
|
||||
|
||||
|
||||
class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
_filename: str
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, filename: str) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._filename = filename
|
||||
self._conn = sqlite3.connect(filename, check_same_thread=False)
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = threading.Lock()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
# Enable foreign keys
|
||||
self._conn.execute("PRAGMA foreign_keys = ON;")
|
||||
self._create_tables()
|
||||
self._conn.commit()
|
||||
finally:
|
||||
@ -176,7 +170,7 @@ class SqliteBoardRecordStorage(BoardRecordStorageBase):
|
||||
board_name: str,
|
||||
) -> BoardRecord:
|
||||
try:
|
||||
board_id = str(uuid.uuid4())
|
||||
board_id = uuid_string()
|
||||
self._lock.acquire()
|
||||
self._cursor.execute(
|
||||
"""--sql
|
||||
|
||||
@ -1,17 +1,10 @@
|
||||
from abc import ABC, abstractmethod
|
||||
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.board_image_record_storage import BoardImageRecordStorageBase
|
||||
from invokeai.app.services.board_images import board_record_to_dto
|
||||
|
||||
from invokeai.app.services.board_record_storage import (
|
||||
BoardChanges,
|
||||
BoardRecordStorageBase,
|
||||
)
|
||||
from invokeai.app.services.image_record_storage import (
|
||||
ImageRecordStorageBase,
|
||||
OffsetPaginatedResults,
|
||||
)
|
||||
from invokeai.app.services.board_record_storage import BoardChanges, BoardRecordStorageBase
|
||||
from invokeai.app.services.image_record_storage import ImageRecordStorageBase, OffsetPaginatedResults
|
||||
from invokeai.app.services.models.board_record import BoardDTO
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
|
||||
|
||||
@ -2,7 +2,5 @@
|
||||
Init file for InvokeAI configure package
|
||||
"""
|
||||
|
||||
from .invokeai_config import ( # noqa F401
|
||||
InvokeAIAppConfig,
|
||||
get_invokeai_config,
|
||||
)
|
||||
from .base import PagingArgumentParser # noqa F401
|
||||
from .invokeai_config import InvokeAIAppConfig, get_invokeai_config # noqa F401
|
||||
|
||||
@ -9,15 +9,17 @@ the command line.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
import argparse
|
||||
import os
|
||||
import pydoc
|
||||
import sys
|
||||
from argparse import ArgumentParser
|
||||
from omegaconf import OmegaConf, DictConfig, ListConfig
|
||||
from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_args, get_origin, get_type_hints
|
||||
|
||||
from omegaconf import DictConfig, ListConfig, OmegaConf
|
||||
from pydantic import BaseSettings
|
||||
from typing import ClassVar, Dict, List, Literal, Union, get_origin, get_type_hints, get_args
|
||||
|
||||
|
||||
class PagingArgumentParser(argparse.ArgumentParser):
|
||||
@ -37,12 +39,14 @@ class InvokeAISettings(BaseSettings):
|
||||
read from an omegaconf .yaml file.
|
||||
"""
|
||||
|
||||
initconf: ClassVar[DictConfig] = None
|
||||
initconf: ClassVar[Optional[DictConfig]] = None
|
||||
argparse_groups: ClassVar[Dict] = {}
|
||||
|
||||
def parse_args(self, argv: list = sys.argv[1:]):
|
||||
def parse_args(self, argv: Optional[list] = sys.argv[1:]):
|
||||
parser = self.get_parser()
|
||||
opt = parser.parse_args(argv)
|
||||
opt, unknown_opts = parser.parse_known_args(argv)
|
||||
if len(unknown_opts) > 0:
|
||||
print("Unknown args:", unknown_opts)
|
||||
for name in self.__fields__:
|
||||
if name not in self._excluded():
|
||||
value = getattr(opt, name)
|
||||
@ -79,7 +83,8 @@ class InvokeAISettings(BaseSettings):
|
||||
else:
|
||||
settings_stanza = "Uncategorized"
|
||||
|
||||
env_prefix = cls.Config.env_prefix if hasattr(cls.Config, "env_prefix") else settings_stanza.upper()
|
||||
env_prefix = getattr(cls.Config, "env_prefix", None)
|
||||
env_prefix = env_prefix if env_prefix is not None else settings_stanza.upper()
|
||||
|
||||
initconf = (
|
||||
cls.initconf.get(settings_stanza)
|
||||
@ -112,8 +117,8 @@ class InvokeAISettings(BaseSettings):
|
||||
field.default = current_default
|
||||
|
||||
@classmethod
|
||||
def cmd_name(self, command_field: str = "type") -> str:
|
||||
hints = get_type_hints(self)
|
||||
def cmd_name(cls, command_field: str = "type") -> str:
|
||||
hints = get_type_hints(cls)
|
||||
if command_field in hints:
|
||||
return get_args(hints[command_field])[0]
|
||||
else:
|
||||
@ -129,16 +134,12 @@ class InvokeAISettings(BaseSettings):
|
||||
return parser
|
||||
|
||||
@classmethod
|
||||
def add_subparser(cls, parser: argparse.ArgumentParser):
|
||||
parser.add_parser(cls.cmd_name(), help=cls.__doc__)
|
||||
|
||||
@classmethod
|
||||
def _excluded(self) -> List[str]:
|
||||
def _excluded(cls) -> List[str]:
|
||||
# internal fields that shouldn't be exposed as command line options
|
||||
return ["type", "initconf"]
|
||||
|
||||
@classmethod
|
||||
def _excluded_from_yaml(self) -> List[str]:
|
||||
def _excluded_from_yaml(cls) -> List[str]:
|
||||
# combination of deprecated parameters and internal ones that shouldn't be exposed as invokeai.yaml options
|
||||
return [
|
||||
"type",
|
||||
|
||||
@ -172,9 +172,9 @@ from __future__ import annotations
|
||||
|
||||
import os
|
||||
from pathlib import Path
|
||||
from typing import ClassVar, Dict, List, Literal, Union, get_type_hints, Optional
|
||||
from typing import ClassVar, Dict, List, Literal, Optional, Union, get_type_hints
|
||||
|
||||
from omegaconf import OmegaConf, DictConfig
|
||||
from omegaconf import DictConfig, OmegaConf
|
||||
from pydantic import Field, parse_obj_as
|
||||
|
||||
from .base import InvokeAISettings
|
||||
@ -194,8 +194,8 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
setting environment variables INVOKEAI_<setting>.
|
||||
"""
|
||||
|
||||
singleton_config: ClassVar[InvokeAIAppConfig] = None
|
||||
singleton_init: ClassVar[Dict] = None
|
||||
singleton_config: ClassVar[Optional[InvokeAIAppConfig]] = None
|
||||
singleton_init: ClassVar[Optional[Dict]] = None
|
||||
|
||||
# fmt: off
|
||||
type: Literal["InvokeAI"] = "InvokeAI"
|
||||
@ -234,6 +234,7 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
# note - would be better to read the log_format values from logging.py, but this creates circular dependencies issues
|
||||
log_format : Literal['plain', 'color', 'syslog', 'legacy'] = Field(default="color", description='Log format. Use "plain" for text-only, "color" for colorized output, "legacy" for 2.3-style logging and "syslog" for syslog-style', category="Logging")
|
||||
log_level : Literal["debug", "info", "warning", "error", "critical"] = Field(default="info", description="Emit logging messages at this level or higher", category="Logging")
|
||||
log_sql : bool = Field(default=False, description="Log SQL queries", category="Logging")
|
||||
|
||||
dev_reload : bool = Field(default=False, description="Automatically reload when Python sources are changed.", category="Development")
|
||||
|
||||
@ -245,14 +246,24 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
lazy_offload : bool = Field(default=True, description="Keep models in VRAM until their space is needed", category="Model Cache", )
|
||||
|
||||
# DEVICE
|
||||
device : Literal[tuple(["auto", "cpu", "cuda", "cuda:1", "mps"])] = Field(default="auto", description="Generation device", category="Device", )
|
||||
precision: Literal[tuple(["auto", "float16", "float32", "autocast"])] = Field(default="auto", description="Floating point precision", category="Device", )
|
||||
device : Literal["auto", "cpu", "cuda", "cuda:1", "mps"] = Field(default="auto", description="Generation device", category="Device", )
|
||||
precision : Literal["auto", "float16", "float32", "autocast"] = Field(default="auto", description="Floating point precision", category="Device", )
|
||||
|
||||
# GENERATION
|
||||
sequential_guidance : bool = Field(default=False, description="Whether to calculate guidance in serial instead of in parallel, lowering memory requirements", category="Generation", )
|
||||
attention_type : Literal[tuple(["auto", "normal", "xformers", "sliced", "torch-sdp"])] = Field(default="auto", description="Attention type", category="Generation", )
|
||||
attention_slice_size: Literal[tuple(["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8])] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
attention_type : Literal["auto", "normal", "xformers", "sliced", "torch-sdp"] = Field(default="auto", description="Attention type", category="Generation", )
|
||||
attention_slice_size: Literal["auto", "balanced", "max", 1, 2, 3, 4, 5, 6, 7, 8] = Field(default="auto", description='Slice size, valid when attention_type=="sliced"', category="Generation", )
|
||||
force_tiled_decode : bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
force_tiled_decode: bool = Field(default=False, description="Whether to enable tiled VAE decode (reduces memory consumption with some performance penalty)", category="Generation",)
|
||||
max_image_size : int = Field(default=512 * 512, description="The maximum size of images, in pixels. The maximum size for latents is inferred from this evaluating `max_image_size // 8`. If the size is exceeded during denoising, the latents will be resized.", category="Generation", )
|
||||
|
||||
# QUEUE
|
||||
max_queue_size : int = Field(default=10000, gt=0, description="Maximum number of items in the session queue", category="Queue", )
|
||||
|
||||
# NODES
|
||||
allow_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to allow. Omit to allow all.", category="Nodes")
|
||||
deny_nodes : Optional[List[str]] = Field(default=None, description="List of nodes to deny. Omit to deny none.", category="Nodes")
|
||||
node_cache_size : int = Field(default=512, description="How many cached nodes to keep in memory", category="Nodes", )
|
||||
|
||||
# DEPRECATED FIELDS - STILL HERE IN ORDER TO OBTAN VALUES FROM PRE-3.1 CONFIG FILES
|
||||
always_use_cpu : bool = Field(default=False, description="If true, use the CPU for rendering even if a GPU is available.", category='Memory/Performance')
|
||||
@ -267,8 +278,9 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
|
||||
class Config:
|
||||
validate_assignment = True
|
||||
env_prefix = "INVOKEAI"
|
||||
|
||||
def parse_args(self, argv: List[str] = None, conf: DictConfig = None, clobber=False):
|
||||
def parse_args(self, argv: Optional[list[str]] = None, conf: Optional[DictConfig] = None, clobber=False):
|
||||
"""
|
||||
Update settings with contents of init file, environment, and
|
||||
command-line settings.
|
||||
@ -279,12 +291,16 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
# Set the runtime root directory. We parse command-line switches here
|
||||
# in order to pick up the --root_dir option.
|
||||
super().parse_args(argv)
|
||||
loaded_conf = None
|
||||
if conf is None:
|
||||
try:
|
||||
conf = OmegaConf.load(self.root_dir / INIT_FILE)
|
||||
loaded_conf = OmegaConf.load(self.root_dir / INIT_FILE)
|
||||
except Exception:
|
||||
pass
|
||||
InvokeAISettings.initconf = conf
|
||||
if isinstance(loaded_conf, DictConfig):
|
||||
InvokeAISettings.initconf = loaded_conf
|
||||
else:
|
||||
InvokeAISettings.initconf = conf
|
||||
|
||||
# parse args again in order to pick up settings in configuration file
|
||||
super().parse_args(argv)
|
||||
@ -372,13 +388,6 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
"""
|
||||
return self._resolve(self.models_dir)
|
||||
|
||||
@property
|
||||
def autoconvert_path(self) -> Path:
|
||||
"""
|
||||
Path to the directory containing models to be imported automatically at startup.
|
||||
"""
|
||||
return self._resolve(self.autoconvert_dir) if self.autoconvert_dir else None
|
||||
|
||||
# the following methods support legacy calls leftover from the Globals era
|
||||
@property
|
||||
def full_precision(self) -> bool:
|
||||
@ -401,11 +410,11 @@ class InvokeAIAppConfig(InvokeAISettings):
|
||||
return True
|
||||
|
||||
@property
|
||||
def ram_cache_size(self) -> float:
|
||||
def ram_cache_size(self) -> Union[Literal["auto"], float]:
|
||||
return self.max_cache_size or self.ram
|
||||
|
||||
@property
|
||||
def vram_cache_size(self) -> float:
|
||||
def vram_cache_size(self) -> Union[Literal["auto"], float]:
|
||||
return self.max_vram_cache_size or self.vram
|
||||
|
||||
@property
|
||||
|
||||
@ -1,67 +1,67 @@
|
||||
from ..invocations.latent import LatentsToImageInvocation, DenoiseLatentsInvocation
|
||||
from ..invocations.image import ImageNSFWBlurInvocation
|
||||
from ..invocations.noise import NoiseInvocation
|
||||
from ..invocations.compel import CompelInvocation
|
||||
from ..invocations.image import ImageNSFWBlurInvocation
|
||||
from ..invocations.latent import DenoiseLatentsInvocation, LatentsToImageInvocation
|
||||
from ..invocations.noise import NoiseInvocation
|
||||
from ..invocations.primitives import IntegerInvocation
|
||||
from .graph import Edge, EdgeConnection, ExposedNodeInput, ExposedNodeOutput, Graph, LibraryGraph
|
||||
from .item_storage import ItemStorageABC
|
||||
|
||||
|
||||
default_text_to_image_graph_id = "539b2af5-2b4d-4d8c-8071-e54a3255fc74"
|
||||
|
||||
|
||||
def create_text_to_image() -> LibraryGraph:
|
||||
graph = Graph(
|
||||
nodes={
|
||||
"width": IntegerInvocation(id="width", value=512),
|
||||
"height": IntegerInvocation(id="height", value=512),
|
||||
"seed": IntegerInvocation(id="seed", value=-1),
|
||||
"3": NoiseInvocation(id="3"),
|
||||
"4": CompelInvocation(id="4"),
|
||||
"5": CompelInvocation(id="5"),
|
||||
"6": DenoiseLatentsInvocation(id="6"),
|
||||
"7": LatentsToImageInvocation(id="7"),
|
||||
"8": ImageNSFWBlurInvocation(id="8"),
|
||||
},
|
||||
edges=[
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="width", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="width"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="height", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="height"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="seed", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="seed"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="3", field="noise"),
|
||||
destination=EdgeConnection(node_id="6", field="noise"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="6", field="latents"),
|
||||
destination=EdgeConnection(node_id="7", field="latents"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="4", field="conditioning"),
|
||||
destination=EdgeConnection(node_id="6", field="positive_conditioning"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="5", field="conditioning"),
|
||||
destination=EdgeConnection(node_id="6", field="negative_conditioning"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="7", field="image"),
|
||||
destination=EdgeConnection(node_id="8", field="image"),
|
||||
),
|
||||
],
|
||||
)
|
||||
return LibraryGraph(
|
||||
id=default_text_to_image_graph_id,
|
||||
name="t2i",
|
||||
description="Converts text to an image",
|
||||
graph=Graph(
|
||||
nodes={
|
||||
"width": IntegerInvocation(id="width", value=512),
|
||||
"height": IntegerInvocation(id="height", value=512),
|
||||
"seed": IntegerInvocation(id="seed", value=-1),
|
||||
"3": NoiseInvocation(id="3"),
|
||||
"4": CompelInvocation(id="4"),
|
||||
"5": CompelInvocation(id="5"),
|
||||
"6": DenoiseLatentsInvocation(id="6"),
|
||||
"7": LatentsToImageInvocation(id="7"),
|
||||
"8": ImageNSFWBlurInvocation(id="8"),
|
||||
},
|
||||
edges=[
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="width", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="width"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="height", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="height"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="seed", field="value"),
|
||||
destination=EdgeConnection(node_id="3", field="seed"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="3", field="noise"),
|
||||
destination=EdgeConnection(node_id="6", field="noise"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="6", field="latents"),
|
||||
destination=EdgeConnection(node_id="7", field="latents"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="4", field="conditioning"),
|
||||
destination=EdgeConnection(node_id="6", field="positive_conditioning"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="5", field="conditioning"),
|
||||
destination=EdgeConnection(node_id="6", field="negative_conditioning"),
|
||||
),
|
||||
Edge(
|
||||
source=EdgeConnection(node_id="7", field="image"),
|
||||
destination=EdgeConnection(node_id="8", field="image"),
|
||||
),
|
||||
],
|
||||
),
|
||||
graph=graph,
|
||||
exposed_inputs=[
|
||||
ExposedNodeInput(node_path="4", field="prompt", alias="positive_prompt"),
|
||||
ExposedNodeInput(node_path="5", field="prompt", alias="negative_prompt"),
|
||||
|
||||
@ -1,28 +1,26 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654)
|
||||
|
||||
from typing import Any, Optional
|
||||
|
||||
from invokeai.app.models.image import ProgressImage
|
||||
from invokeai.app.services.model_manager_service import BaseModelType, ModelInfo, ModelType, SubModelType
|
||||
from invokeai.app.services.session_queue.session_queue_common import EnqueueBatchResult, SessionQueueItem
|
||||
from invokeai.app.util.misc import get_timestamp
|
||||
from invokeai.app.services.model_manager_service import (
|
||||
BaseModelType,
|
||||
ModelType,
|
||||
SubModelType,
|
||||
ModelInfo,
|
||||
)
|
||||
|
||||
|
||||
class EventServiceBase:
|
||||
session_event: str = "session_event"
|
||||
queue_event: str = "queue_event"
|
||||
|
||||
"""Basic event bus, to have an empty stand-in when not needed"""
|
||||
|
||||
def dispatch(self, event_name: str, payload: Any) -> None:
|
||||
pass
|
||||
|
||||
def __emit_session_event(self, event_name: str, payload: dict) -> None:
|
||||
def __emit_queue_event(self, event_name: str, payload: dict) -> None:
|
||||
"""Queue events are emitted to a room with queue_id as the room name"""
|
||||
payload["timestamp"] = get_timestamp()
|
||||
self.dispatch(
|
||||
event_name=EventServiceBase.session_event,
|
||||
event_name=EventServiceBase.queue_event,
|
||||
payload=dict(event=event_name, data=payload),
|
||||
)
|
||||
|
||||
@ -30,6 +28,9 @@ class EventServiceBase:
|
||||
# This will make them easier to integrate until we find a schema generator.
|
||||
def emit_generator_progress(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@ -39,11 +40,14 @@ class EventServiceBase:
|
||||
total_steps: int,
|
||||
) -> None:
|
||||
"""Emitted when there is generation progress"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="generator_progress",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
node_id=node.get("id"),
|
||||
source_node_id=source_node_id,
|
||||
progress_image=progress_image.dict() if progress_image is not None else None,
|
||||
step=step,
|
||||
@ -54,15 +58,21 @@ class EventServiceBase:
|
||||
|
||||
def emit_invocation_complete(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
result: dict,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
) -> None:
|
||||
"""Emitted when an invocation has completed"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="invocation_complete",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@ -72,6 +82,9 @@ class EventServiceBase:
|
||||
|
||||
def emit_invocation_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
@ -79,9 +92,12 @@ class EventServiceBase:
|
||||
error: str,
|
||||
) -> None:
|
||||
"""Emitted when an invocation has completed"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="invocation_error",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
@ -90,28 +106,47 @@ class EventServiceBase:
|
||||
),
|
||||
)
|
||||
|
||||
def emit_invocation_started(self, graph_execution_state_id: str, node: dict, source_node_id: str) -> None:
|
||||
def emit_invocation_started(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node: dict,
|
||||
source_node_id: str,
|
||||
) -> None:
|
||||
"""Emitted when an invocation has started"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="invocation_started",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node=node,
|
||||
source_node_id=source_node_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_graph_execution_complete(self, graph_execution_state_id: str) -> None:
|
||||
def emit_graph_execution_complete(
|
||||
self, queue_id: str, queue_item_id: int, queue_batch_id: str, graph_execution_state_id: str
|
||||
) -> None:
|
||||
"""Emitted when a session has completed all invocations"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="graph_execution_state_complete",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_model_load_started(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
@ -119,9 +154,12 @@ class EventServiceBase:
|
||||
submodel: SubModelType,
|
||||
) -> None:
|
||||
"""Emitted when a model is requested"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="model_load_started",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
@ -132,6 +170,9 @@ class EventServiceBase:
|
||||
|
||||
def emit_model_load_completed(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
model_name: str,
|
||||
base_model: BaseModelType,
|
||||
@ -140,9 +181,12 @@ class EventServiceBase:
|
||||
model_info: ModelInfo,
|
||||
) -> None:
|
||||
"""Emitted when a model is correctly loaded (returns model info)"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="model_load_completed",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
model_name=model_name,
|
||||
base_model=base_model,
|
||||
@ -156,14 +200,20 @@ class EventServiceBase:
|
||||
|
||||
def emit_session_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
error_type: str,
|
||||
error: str,
|
||||
) -> None:
|
||||
"""Emitted when session retrieval fails"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="session_retrieval_error",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
error_type=error_type,
|
||||
error=error,
|
||||
@ -172,18 +222,78 @@ class EventServiceBase:
|
||||
|
||||
def emit_invocation_retrieval_error(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
node_id: str,
|
||||
error_type: str,
|
||||
error: str,
|
||||
) -> None:
|
||||
"""Emitted when invocation retrieval fails"""
|
||||
self.__emit_session_event(
|
||||
self.__emit_queue_event(
|
||||
event_name="invocation_retrieval_error",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
node_id=node_id,
|
||||
error_type=error_type,
|
||||
error=error,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_session_canceled(
|
||||
self,
|
||||
queue_id: str,
|
||||
queue_item_id: int,
|
||||
queue_batch_id: str,
|
||||
graph_execution_state_id: str,
|
||||
) -> None:
|
||||
"""Emitted when a session is canceled"""
|
||||
self.__emit_queue_event(
|
||||
event_name="session_canceled",
|
||||
payload=dict(
|
||||
queue_id=queue_id,
|
||||
queue_item_id=queue_item_id,
|
||||
queue_batch_id=queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state_id,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_item_status_changed(self, session_queue_item: SessionQueueItem) -> None:
|
||||
"""Emitted when a queue item's status changes"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_item_status_changed",
|
||||
payload=dict(
|
||||
queue_id=session_queue_item.queue_id,
|
||||
queue_item_id=session_queue_item.item_id,
|
||||
status=session_queue_item.status,
|
||||
batch_id=session_queue_item.batch_id,
|
||||
session_id=session_queue_item.session_id,
|
||||
error=session_queue_item.error,
|
||||
created_at=str(session_queue_item.created_at) if session_queue_item.created_at else None,
|
||||
updated_at=str(session_queue_item.updated_at) if session_queue_item.updated_at else None,
|
||||
started_at=str(session_queue_item.started_at) if session_queue_item.started_at else None,
|
||||
completed_at=str(session_queue_item.completed_at) if session_queue_item.completed_at else None,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_batch_enqueued(self, enqueue_result: EnqueueBatchResult) -> None:
|
||||
"""Emitted when a batch is enqueued"""
|
||||
self.__emit_queue_event(
|
||||
event_name="batch_enqueued",
|
||||
payload=dict(
|
||||
queue_id=enqueue_result.queue_id,
|
||||
batch_id=enqueue_result.batch.batch_id,
|
||||
enqueued=enqueue_result.enqueued,
|
||||
),
|
||||
)
|
||||
|
||||
def emit_queue_cleared(self, queue_id: str) -> None:
|
||||
"""Emitted when the queue is cleared"""
|
||||
self.__emit_queue_event(
|
||||
event_name="queue_cleared",
|
||||
payload=dict(queue_id=queue_id),
|
||||
)
|
||||
|
||||
@ -2,12 +2,13 @@
|
||||
|
||||
import copy
|
||||
import itertools
|
||||
import uuid
|
||||
from typing import Annotated, Any, Literal, Optional, Union, get_args, get_origin, get_type_hints
|
||||
from typing import Annotated, Any, Optional, Union, cast, get_args, get_origin, get_type_hints
|
||||
|
||||
import networkx as nx
|
||||
from pydantic import BaseModel, root_validator, validator
|
||||
from pydantic.fields import Field, ModelField
|
||||
from pydantic.fields import Field
|
||||
|
||||
from invokeai.app.util.misc import uuid_string
|
||||
|
||||
# Importing * is bad karma but needed here for node detection
|
||||
from ..invocations import * # noqa: F401 F403
|
||||
@ -19,6 +20,8 @@ from ..invocations.baseinvocation import (
|
||||
InvocationContext,
|
||||
OutputField,
|
||||
UIType,
|
||||
invocation,
|
||||
invocation_output,
|
||||
)
|
||||
|
||||
# in 3.10 this would be "from types import NoneType"
|
||||
@ -110,6 +113,10 @@ def are_connection_types_compatible(from_type: Any, to_type: Any) -> bool:
|
||||
if to_type in get_args(from_type):
|
||||
return True
|
||||
|
||||
# allow int -> float, pydantic will cast for us
|
||||
if from_type is int and to_type is float:
|
||||
return True
|
||||
|
||||
# if not issubclass(from_type, to_type):
|
||||
if not is_union_subtype(from_type, to_type):
|
||||
return False
|
||||
@ -131,41 +138,45 @@ def are_connections_compatible(
|
||||
return are_connection_types_compatible(from_node_field, to_node_field)
|
||||
|
||||
|
||||
class NodeAlreadyInGraphError(Exception):
|
||||
class NodeAlreadyInGraphError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class InvalidEdgeError(Exception):
|
||||
class InvalidEdgeError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class NodeNotFoundError(Exception):
|
||||
class NodeNotFoundError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class NodeAlreadyExecutedError(Exception):
|
||||
class NodeAlreadyExecutedError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class DuplicateNodeIdError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class NodeFieldNotFoundError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
class NodeIdMismatchError(ValueError):
|
||||
pass
|
||||
|
||||
|
||||
# TODO: Create and use an Empty output?
|
||||
@invocation_output("graph_output")
|
||||
class GraphInvocationOutput(BaseInvocationOutput):
|
||||
type: Literal["graph_output"] = "graph_output"
|
||||
|
||||
class Config:
|
||||
schema_extra = {
|
||||
"required": [
|
||||
"type",
|
||||
"image",
|
||||
]
|
||||
}
|
||||
pass
|
||||
|
||||
|
||||
# TODO: Fill this out and move to invocations
|
||||
@invocation("graph")
|
||||
class GraphInvocation(BaseInvocation):
|
||||
"""Execute a graph"""
|
||||
|
||||
type: Literal["graph"] = "graph"
|
||||
|
||||
# TODO: figure out how to create a default here
|
||||
graph: "Graph" = Field(description="The graph to run", default=None)
|
||||
|
||||
@ -174,22 +185,20 @@ class GraphInvocation(BaseInvocation):
|
||||
return GraphInvocationOutput()
|
||||
|
||||
|
||||
@invocation_output("iterate_output")
|
||||
class IterateInvocationOutput(BaseInvocationOutput):
|
||||
"""Used to connect iteration outputs. Will be expanded to a specific output."""
|
||||
|
||||
type: Literal["iterate_output"] = "iterate_output"
|
||||
|
||||
item: Any = OutputField(
|
||||
description="The item being iterated over", title="Collection Item", ui_type=UIType.CollectionItem
|
||||
)
|
||||
|
||||
|
||||
# TODO: Fill this out and move to invocations
|
||||
@invocation("iterate", version="1.0.0")
|
||||
class IterateInvocation(BaseInvocation):
|
||||
"""Iterates over a list of items"""
|
||||
|
||||
type: Literal["iterate"] = "iterate"
|
||||
|
||||
collection: list[Any] = InputField(
|
||||
description="The list of items to iterate over", default_factory=list, ui_type=UIType.Collection
|
||||
)
|
||||
@ -200,19 +209,17 @@ class IterateInvocation(BaseInvocation):
|
||||
return IterateInvocationOutput(item=self.collection[self.index])
|
||||
|
||||
|
||||
@invocation_output("collect_output")
|
||||
class CollectInvocationOutput(BaseInvocationOutput):
|
||||
type: Literal["collect_output"] = "collect_output"
|
||||
|
||||
collection: list[Any] = OutputField(
|
||||
description="The collection of input items", title="Collection", ui_type=UIType.Collection
|
||||
)
|
||||
|
||||
|
||||
@invocation("collect", version="1.0.0")
|
||||
class CollectInvocation(BaseInvocation):
|
||||
"""Collects values into a collection"""
|
||||
|
||||
type: Literal["collect"] = "collect"
|
||||
|
||||
item: Any = InputField(
|
||||
description="The item to collect (all inputs must be of the same type)",
|
||||
ui_type=UIType.CollectionItem,
|
||||
@ -232,40 +239,8 @@ InvocationsUnion = Union[BaseInvocation.get_invocations()] # type: ignore
|
||||
InvocationOutputsUnion = Union[BaseInvocationOutput.get_all_subclasses_tuple()] # type: ignore
|
||||
|
||||
|
||||
class DynamicBaseModel(BaseModel):
|
||||
"""https://github.com/pydantic/pydantic/issues/1937#issuecomment-695313040"""
|
||||
|
||||
@classmethod
|
||||
def add_fields(cls, **field_definitions: Any):
|
||||
new_fields: dict[str, ModelField] = {}
|
||||
new_annotations: dict[str, Optional[type]] = {}
|
||||
|
||||
for f_name, f_def in field_definitions.items():
|
||||
if isinstance(f_def, tuple):
|
||||
try:
|
||||
f_annotation, f_value = f_def
|
||||
except ValueError as e:
|
||||
raise Exception(
|
||||
"field definitions should either be a tuple of (<type>, <default>) or just a "
|
||||
"default value, unfortunately this means tuples as "
|
||||
"default values are not allowed"
|
||||
) from e
|
||||
else:
|
||||
f_annotation, f_value = None, f_def
|
||||
|
||||
if f_annotation:
|
||||
new_annotations[f_name] = f_annotation
|
||||
|
||||
new_fields[f_name] = ModelField.infer(
|
||||
name=f_name, value=f_value, annotation=f_annotation, class_validators=None, config=cls.__config__
|
||||
)
|
||||
|
||||
cls.__fields__.update(new_fields)
|
||||
cls.__annotations__.update(new_annotations)
|
||||
|
||||
|
||||
class Graph(DynamicBaseModel):
|
||||
id: str = Field(description="The id of this graph", default_factory=lambda: uuid.uuid4().__str__())
|
||||
class Graph(BaseModel):
|
||||
id: str = Field(description="The id of this graph", default_factory=uuid_string)
|
||||
# TODO: use a list (and never use dict in a BaseModel) because pydantic/fastapi hates me
|
||||
nodes: dict[str, Annotated[InvocationsUnion, Field(discriminator="type")]] = Field(
|
||||
description="The nodes in this graph", default_factory=dict
|
||||
@ -275,6 +250,59 @@ class Graph(DynamicBaseModel):
|
||||
default_factory=list,
|
||||
)
|
||||
|
||||
@root_validator
|
||||
def validate_nodes_and_edges(cls, values):
|
||||
"""Validates that all edges match nodes in the graph"""
|
||||
nodes = cast(Optional[dict[str, BaseInvocation]], values.get("nodes"))
|
||||
edges = cast(Optional[list[Edge]], values.get("edges"))
|
||||
|
||||
if nodes is not None:
|
||||
# Validate that all node ids are unique
|
||||
node_ids = [n.id for n in nodes.values()]
|
||||
duplicate_node_ids = set([node_id for node_id in node_ids if node_ids.count(node_id) >= 2])
|
||||
if duplicate_node_ids:
|
||||
raise DuplicateNodeIdError(f"Node ids must be unique, found duplicates {duplicate_node_ids}")
|
||||
|
||||
# Validate that all node ids match the keys in the nodes dict
|
||||
for k, v in nodes.items():
|
||||
if k != v.id:
|
||||
raise NodeIdMismatchError(f"Node ids must match, got {k} and {v.id}")
|
||||
|
||||
if edges is not None and nodes is not None:
|
||||
# Validate that all edges match nodes in the graph
|
||||
node_ids = set([e.source.node_id for e in edges] + [e.destination.node_id for e in edges])
|
||||
missing_node_ids = [node_id for node_id in node_ids if node_id not in nodes]
|
||||
if missing_node_ids:
|
||||
raise NodeNotFoundError(
|
||||
f"All edges must reference nodes in the graph, missing nodes: {missing_node_ids}"
|
||||
)
|
||||
|
||||
# Validate that all edge fields match node fields in the graph
|
||||
for edge in edges:
|
||||
source_node = nodes.get(edge.source.node_id, None)
|
||||
if source_node is None:
|
||||
raise NodeFieldNotFoundError(f"Edge source node {edge.source.node_id} does not exist in the graph")
|
||||
|
||||
destination_node = nodes.get(edge.destination.node_id, None)
|
||||
if destination_node is None:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination node {edge.destination.node_id} does not exist in the graph"
|
||||
)
|
||||
|
||||
# output fields are not on the node object directly, they are on the output type
|
||||
if edge.source.field not in source_node.get_output_type().__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge source field {edge.source.field} does not exist in node {edge.source.node_id}"
|
||||
)
|
||||
|
||||
# input fields are on the node
|
||||
if edge.destination.field not in destination_node.__fields__:
|
||||
raise NodeFieldNotFoundError(
|
||||
f"Edge destination field {edge.destination.field} does not exist in node {edge.destination.node_id}"
|
||||
)
|
||||
|
||||
return values
|
||||
|
||||
def add_node(self, node: BaseInvocation) -> None:
|
||||
"""Adds a node to a graph
|
||||
|
||||
@ -732,11 +760,10 @@ class Graph(DynamicBaseModel):
|
||||
return g
|
||||
|
||||
|
||||
class GraphExecutionState(DynamicBaseModel):
|
||||
class GraphExecutionState(BaseModel):
|
||||
"""Tracks the state of a graph execution"""
|
||||
|
||||
id: str = Field(description="The id of the execution state", default_factory=lambda: uuid.uuid4().__str__())
|
||||
|
||||
id: str = Field(description="The id of the execution state", default_factory=uuid_string)
|
||||
# TODO: Store a reference to the graph instead of the actual graph?
|
||||
graph: Graph = Field(description="The graph being executed")
|
||||
|
||||
@ -885,7 +912,7 @@ class GraphExecutionState(DynamicBaseModel):
|
||||
new_node = copy.deepcopy(node)
|
||||
|
||||
# Create the node id (use a random uuid)
|
||||
new_node.id = str(uuid.uuid4())
|
||||
new_node.id = uuid_string()
|
||||
|
||||
# Set the iteration index for iteration invocations
|
||||
if isinstance(new_node, IterateInvocation):
|
||||
@ -1120,7 +1147,7 @@ class ExposedNodeOutput(BaseModel):
|
||||
|
||||
|
||||
class LibraryGraph(BaseModel):
|
||||
id: str = Field(description="The unique identifier for this library graph", default_factory=uuid.uuid4)
|
||||
id: str = Field(description="The unique identifier for this library graph", default_factory=uuid_string)
|
||||
graph: Graph = Field(description="The graph")
|
||||
name: str = Field(description="The name of the graph")
|
||||
description: str = Field(description="The description of the graph")
|
||||
@ -1163,24 +1190,3 @@ class LibraryGraph(BaseModel):
|
||||
|
||||
|
||||
GraphInvocation.update_forward_refs()
|
||||
|
||||
|
||||
def update_invocations_union() -> None:
|
||||
global InvocationsUnion
|
||||
global InvocationOutputsUnion
|
||||
InvocationsUnion = Union[BaseInvocation.get_invocations()] # type: ignore
|
||||
InvocationOutputsUnion = Union[BaseInvocationOutput.get_all_subclasses_tuple()] # type: ignore
|
||||
|
||||
Graph.add_fields(
|
||||
nodes=(
|
||||
dict[str, Annotated[InvocationsUnion, Field(discriminator="type")]],
|
||||
Field(description="The nodes in this graph", default_factory=dict),
|
||||
)
|
||||
)
|
||||
|
||||
GraphExecutionState.add_fields(
|
||||
results=(
|
||||
dict[str, Annotated[InvocationOutputsUnion, Field(discriminator="type")]],
|
||||
Field(description="The results of node executions", default_factory=dict),
|
||||
)
|
||||
)
|
||||
|
||||
@ -60,7 +60,7 @@ class ImageFileStorageBase(ABC):
|
||||
image: PILImageType,
|
||||
image_name: str,
|
||||
metadata: Optional[dict] = None,
|
||||
graph: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
thumbnail_size: int = 256,
|
||||
) -> None:
|
||||
"""Saves an image and a 256x256 WEBP thumbnail. Returns a tuple of the image name, thumbnail name, and created timestamp."""
|
||||
@ -110,7 +110,7 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
image: PILImageType,
|
||||
image_name: str,
|
||||
metadata: Optional[dict] = None,
|
||||
graph: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
thumbnail_size: int = 256,
|
||||
) -> None:
|
||||
try:
|
||||
@ -119,12 +119,23 @@ class DiskImageFileStorage(ImageFileStorageBase):
|
||||
|
||||
pnginfo = PngImagePlugin.PngInfo()
|
||||
|
||||
if metadata is not None:
|
||||
pnginfo.add_text("invokeai_metadata", json.dumps(metadata))
|
||||
if graph is not None:
|
||||
pnginfo.add_text("invokeai_graph", json.dumps(graph))
|
||||
if metadata is not None or workflow is not None:
|
||||
if metadata is not None:
|
||||
pnginfo.add_text("invokeai_metadata", json.dumps(metadata))
|
||||
if workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", workflow)
|
||||
else:
|
||||
# For uploaded images, we want to retain metadata. PIL strips it on save; manually add it back
|
||||
# TODO: retain non-invokeai metadata on save...
|
||||
original_metadata = image.info.get("invokeai_metadata", None)
|
||||
if original_metadata is not None:
|
||||
pnginfo.add_text("invokeai_metadata", original_metadata)
|
||||
original_workflow = image.info.get("invokeai_workflow", None)
|
||||
if original_workflow is not None:
|
||||
pnginfo.add_text("invokeai_workflow", original_workflow)
|
||||
|
||||
image.save(image_path, "PNG", pnginfo=pnginfo)
|
||||
|
||||
thumbnail_name = get_thumbnail_name(image_name)
|
||||
thumbnail_path = self.get_path(thumbnail_name, thumbnail=True)
|
||||
thumbnail_image = make_thumbnail(image, thumbnail_size)
|
||||
|
||||
@ -9,11 +9,7 @@ from pydantic import BaseModel, Field
|
||||
from pydantic.generics import GenericModel
|
||||
|
||||
from invokeai.app.models.image import ImageCategory, ResourceOrigin
|
||||
from invokeai.app.services.models.image_record import (
|
||||
ImageRecord,
|
||||
ImageRecordChanges,
|
||||
deserialize_image_record,
|
||||
)
|
||||
from invokeai.app.services.models.image_record import ImageRecord, ImageRecordChanges, deserialize_image_record
|
||||
|
||||
T = TypeVar("T", bound=BaseModel)
|
||||
|
||||
@ -152,24 +148,20 @@ class ImageRecordStorageBase(ABC):
|
||||
|
||||
|
||||
class SqliteImageRecordStorage(ImageRecordStorageBase):
|
||||
_filename: str
|
||||
_conn: sqlite3.Connection
|
||||
_cursor: sqlite3.Cursor
|
||||
_lock: threading.Lock
|
||||
|
||||
def __init__(self, filename: str) -> None:
|
||||
def __init__(self, conn: sqlite3.Connection, lock: threading.Lock) -> None:
|
||||
super().__init__()
|
||||
self._filename = filename
|
||||
self._conn = sqlite3.connect(filename, check_same_thread=False)
|
||||
self._conn = conn
|
||||
# Enable row factory to get rows as dictionaries (must be done before making the cursor!)
|
||||
self._conn.row_factory = sqlite3.Row
|
||||
self._cursor = self._conn.cursor()
|
||||
self._lock = threading.Lock()
|
||||
self._lock = lock
|
||||
|
||||
try:
|
||||
self._lock.acquire()
|
||||
# Enable foreign keys
|
||||
self._conn.execute("PRAGMA foreign_keys = ON;")
|
||||
self._create_tables()
|
||||
self._conn.commit()
|
||||
finally:
|
||||
|
||||
@ -1,6 +1,6 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from logging import Logger
|
||||
from typing import TYPE_CHECKING, Optional
|
||||
from typing import TYPE_CHECKING, Callable, Optional
|
||||
|
||||
from PIL.Image import Image as PILImageType
|
||||
|
||||
@ -26,12 +26,7 @@ from invokeai.app.services.image_record_storage import (
|
||||
OffsetPaginatedResults,
|
||||
)
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.models.image_record import (
|
||||
ImageDTO,
|
||||
ImageRecord,
|
||||
ImageRecordChanges,
|
||||
image_record_to_dto,
|
||||
)
|
||||
from invokeai.app.services.models.image_record import ImageDTO, ImageRecord, ImageRecordChanges, image_record_to_dto
|
||||
from invokeai.app.services.resource_name import NameServiceBase
|
||||
from invokeai.app.services.urls import UrlServiceBase
|
||||
from invokeai.app.util.metadata import get_metadata_graph_from_raw_session
|
||||
@ -43,6 +38,29 @@ if TYPE_CHECKING:
|
||||
class ImageServiceABC(ABC):
|
||||
"""High-level service for image management."""
|
||||
|
||||
_on_changed_callbacks: list[Callable[[ImageDTO], None]]
|
||||
_on_deleted_callbacks: list[Callable[[str], None]]
|
||||
|
||||
def __init__(self) -> None:
|
||||
self._on_changed_callbacks = list()
|
||||
self._on_deleted_callbacks = list()
|
||||
|
||||
def on_changed(self, on_changed: Callable[[ImageDTO], None]) -> None:
|
||||
"""Register a callback for when an image is changed"""
|
||||
self._on_changed_callbacks.append(on_changed)
|
||||
|
||||
def on_deleted(self, on_deleted: Callable[[str], None]) -> None:
|
||||
"""Register a callback for when an image is deleted"""
|
||||
self._on_deleted_callbacks.append(on_deleted)
|
||||
|
||||
def _on_changed(self, item: ImageDTO) -> None:
|
||||
for callback in self._on_changed_callbacks:
|
||||
callback(item)
|
||||
|
||||
def _on_deleted(self, item_id: str) -> None:
|
||||
for callback in self._on_deleted_callbacks:
|
||||
callback(item_id)
|
||||
|
||||
@abstractmethod
|
||||
def create(
|
||||
self,
|
||||
@ -54,6 +72,7 @@ class ImageServiceABC(ABC):
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
"""Creates an image, storing the file and its metadata."""
|
||||
pass
|
||||
@ -165,6 +184,7 @@ class ImageService(ImageServiceABC):
|
||||
_services: ImageServiceDependencies
|
||||
|
||||
def __init__(self, services: ImageServiceDependencies):
|
||||
super().__init__()
|
||||
self._services = services
|
||||
|
||||
def create(
|
||||
@ -177,6 +197,7 @@ class ImageService(ImageServiceABC):
|
||||
board_id: Optional[str] = None,
|
||||
is_intermediate: bool = False,
|
||||
metadata: Optional[dict] = None,
|
||||
workflow: Optional[str] = None,
|
||||
) -> ImageDTO:
|
||||
if image_origin not in ResourceOrigin:
|
||||
raise InvalidOriginException
|
||||
@ -186,16 +207,16 @@ class ImageService(ImageServiceABC):
|
||||
|
||||
image_name = self._services.names.create_image_name()
|
||||
|
||||
graph = None
|
||||
|
||||
if session_id is not None:
|
||||
session_raw = self._services.graph_execution_manager.get_raw(session_id)
|
||||
if session_raw is not None:
|
||||
try:
|
||||
graph = get_metadata_graph_from_raw_session(session_raw)
|
||||
except Exception as e:
|
||||
self._services.logger.warn(f"Failed to parse session graph: {e}")
|
||||
graph = None
|
||||
# TODO: Do we want to store the graph in the image at all? I don't think so...
|
||||
# graph = None
|
||||
# if session_id is not None:
|
||||
# session_raw = self._services.graph_execution_manager.get_raw(session_id)
|
||||
# if session_raw is not None:
|
||||
# try:
|
||||
# graph = get_metadata_graph_from_raw_session(session_raw)
|
||||
# except Exception as e:
|
||||
# self._services.logger.warn(f"Failed to parse session graph: {e}")
|
||||
# graph = None
|
||||
|
||||
(width, height) = image.size
|
||||
|
||||
@ -217,9 +238,10 @@ class ImageService(ImageServiceABC):
|
||||
)
|
||||
if board_id is not None:
|
||||
self._services.board_image_records.add_image_to_board(board_id=board_id, image_name=image_name)
|
||||
self._services.image_files.save(image_name=image_name, image=image, metadata=metadata, graph=graph)
|
||||
self._services.image_files.save(image_name=image_name, image=image, metadata=metadata, workflow=workflow)
|
||||
image_dto = self.get_dto(image_name)
|
||||
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self._services.logger.error("Failed to save image record")
|
||||
@ -238,7 +260,9 @@ class ImageService(ImageServiceABC):
|
||||
) -> ImageDTO:
|
||||
try:
|
||||
self._services.image_records.update(image_name, changes)
|
||||
return self.get_dto(image_name)
|
||||
image_dto = self.get_dto(image_name)
|
||||
self._on_changed(image_dto)
|
||||
return image_dto
|
||||
except ImageRecordSaveException:
|
||||
self._services.logger.error("Failed to update image record")
|
||||
raise
|
||||
@ -377,6 +401,7 @@ class ImageService(ImageServiceABC):
|
||||
try:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._services.image_records.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image record")
|
||||
raise
|
||||
@ -393,6 +418,8 @@ class ImageService(ImageServiceABC):
|
||||
for image_name in image_names:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._services.image_records.delete_many(image_names)
|
||||
for image_name in image_names:
|
||||
self._on_deleted(image_name)
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image records")
|
||||
raise
|
||||
@ -409,6 +436,7 @@ class ImageService(ImageServiceABC):
|
||||
count = len(image_names)
|
||||
for image_name in image_names:
|
||||
self._services.image_files.delete(image_name)
|
||||
self._on_deleted(image_name)
|
||||
return count
|
||||
except ImageRecordDeleteException:
|
||||
self._services.logger.error("Failed to delete image records")
|
||||
|
||||
0
invokeai/app/services/invocation_cache/__init__.py
Normal file
@ -0,0 +1,62 @@
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
|
||||
|
||||
class InvocationCacheBase(ABC):
|
||||
"""
|
||||
Base class for invocation caches.
|
||||
When an invocation is executed, it is hashed and its output stored in the cache.
|
||||
When new invocations are executed, if they are flagged with `use_cache`, they
|
||||
will attempt to pull their value from the cache before executing.
|
||||
|
||||
Implementations should register for the `on_deleted` event of the `images` and `latents`
|
||||
services, and delete any cached outputs that reference the deleted image or latent.
|
||||
|
||||
See the memory implementation for an example.
|
||||
|
||||
Implementations should respect the `node_cache_size` configuration value, and skip all
|
||||
cache logic if the value is set to 0.
|
||||
"""
|
||||
|
||||
@abstractmethod
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
"""Retrieves an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
"""Stores an invocation output in the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
"""Deletes an invocation output from the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def clear(self) -> None:
|
||||
"""Clears the cache"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
"""Gets the key for the invocation's cache item"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def disable(self) -> None:
|
||||
"""Disables the cache, overriding the max cache size"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def enable(self) -> None:
|
||||
"""Enables the cache, letting the the max cache size take effect"""
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
"""Returns the status of the cache"""
|
||||
pass
|
||||
@ -0,0 +1,9 @@
|
||||
from pydantic import BaseModel, Field
|
||||
|
||||
|
||||
class InvocationCacheStatus(BaseModel):
|
||||
size: int = Field(description="The current size of the invocation cache")
|
||||
hits: int = Field(description="The number of cache hits")
|
||||
misses: int = Field(description="The number of cache misses")
|
||||
enabled: bool = Field(description="Whether the invocation cache is enabled")
|
||||
max_size: int = Field(description="The maximum size of the invocation cache")
|
||||
@ -0,0 +1,111 @@
|
||||
from queue import Queue
|
||||
from typing import Optional, Union
|
||||
|
||||
from invokeai.app.invocations.baseinvocation import BaseInvocation, BaseInvocationOutput
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_common import InvocationCacheStatus
|
||||
from invokeai.app.services.invoker import Invoker
|
||||
|
||||
|
||||
class MemoryInvocationCache(InvocationCacheBase):
|
||||
__cache: dict[Union[int, str], tuple[BaseInvocationOutput, str]]
|
||||
__max_cache_size: int
|
||||
__disabled: bool
|
||||
__hits: int
|
||||
__misses: int
|
||||
__cache_ids: Queue
|
||||
__invoker: Invoker
|
||||
|
||||
def __init__(self, max_cache_size: int = 0) -> None:
|
||||
self.__cache = dict()
|
||||
self.__max_cache_size = max_cache_size
|
||||
self.__disabled = False
|
||||
self.__hits = 0
|
||||
self.__misses = 0
|
||||
self.__cache_ids = Queue()
|
||||
|
||||
def start(self, invoker: Invoker) -> None:
|
||||
self.__invoker = invoker
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
self.__invoker.services.images.on_deleted(self._delete_by_match)
|
||||
self.__invoker.services.latents.on_deleted(self._delete_by_match)
|
||||
|
||||
def get(self, key: Union[int, str]) -> Optional[BaseInvocationOutput]:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
item = self.__cache.get(key, None)
|
||||
if item is not None:
|
||||
self.__hits += 1
|
||||
return item[0]
|
||||
self.__misses += 1
|
||||
|
||||
def save(self, key: Union[int, str], invocation_output: BaseInvocationOutput) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
if key not in self.__cache:
|
||||
self.__cache[key] = (invocation_output, invocation_output.json())
|
||||
self.__cache_ids.put(key)
|
||||
if self.__cache_ids.qsize() > self.__max_cache_size:
|
||||
try:
|
||||
self.__cache.pop(self.__cache_ids.get())
|
||||
except KeyError:
|
||||
# this means the cache_ids are somehow out of sync w/ the cache
|
||||
pass
|
||||
|
||||
def delete(self, key: Union[int, str]) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
if key in self.__cache:
|
||||
del self.__cache[key]
|
||||
|
||||
def clear(self, *args, **kwargs) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
self.__cache.clear()
|
||||
self.__cache_ids = Queue()
|
||||
self.__misses = 0
|
||||
self.__hits = 0
|
||||
|
||||
def create_key(self, invocation: BaseInvocation) -> int:
|
||||
return hash(invocation.json(exclude={"id"}))
|
||||
|
||||
def disable(self) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
self.__disabled = True
|
||||
|
||||
def enable(self) -> None:
|
||||
if self.__max_cache_size == 0:
|
||||
return
|
||||
self.__disabled = False
|
||||
|
||||
def get_status(self) -> InvocationCacheStatus:
|
||||
return InvocationCacheStatus(
|
||||
hits=self.__hits,
|
||||
misses=self.__misses,
|
||||
enabled=not self.__disabled and self.__max_cache_size > 0,
|
||||
size=len(self.__cache),
|
||||
max_size=self.__max_cache_size,
|
||||
)
|
||||
|
||||
def _delete_by_match(self, to_match: str) -> None:
|
||||
if self.__max_cache_size == 0 or self.__disabled:
|
||||
return
|
||||
|
||||
keys_to_delete = set()
|
||||
for key, value_tuple in self.__cache.items():
|
||||
if to_match in value_tuple[1]:
|
||||
keys_to_delete.add(key)
|
||||
|
||||
if not keys_to_delete:
|
||||
return
|
||||
|
||||
for key in keys_to_delete:
|
||||
self.delete(key)
|
||||
|
||||
self.__invoker.services.logger.debug(f"Deleted {len(keys_to_delete)} cached invocation outputs for {to_match}")
|
||||
@ -3,14 +3,21 @@
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
from queue import Queue
|
||||
from typing import Optional
|
||||
|
||||
from pydantic import BaseModel, Field
|
||||
from typing import Optional
|
||||
|
||||
|
||||
class InvocationQueueItem(BaseModel):
|
||||
graph_execution_state_id: str = Field(description="The ID of the graph execution state")
|
||||
invocation_id: str = Field(description="The ID of the node being invoked")
|
||||
session_queue_id: str = Field(description="The ID of the session queue from which this invocation queue item came")
|
||||
session_queue_item_id: int = Field(
|
||||
description="The ID of session queue item from which this invocation queue item came"
|
||||
)
|
||||
session_queue_batch_id: str = Field(
|
||||
description="The ID of the session batch from which this invocation queue item came"
|
||||
)
|
||||
invoke_all: bool = Field(default=False)
|
||||
timestamp: float = Field(default_factory=time.time)
|
||||
|
||||
|
||||
@ -1,21 +1,26 @@
|
||||
# Copyright (c) 2022 Kyle Schouviller (https://github.com/kyle0654) and the InvokeAI Team
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import TYPE_CHECKING
|
||||
|
||||
if TYPE_CHECKING:
|
||||
from logging import Logger
|
||||
|
||||
from invokeai.app.services.board_images import BoardImagesServiceABC
|
||||
from invokeai.app.services.boards import BoardServiceABC
|
||||
from invokeai.app.services.images import ImageServiceABC
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsServiceBase
|
||||
from invokeai.app.services.model_manager_service import ModelManagerServiceBase
|
||||
from invokeai.app.services.events import EventServiceBase
|
||||
from invokeai.app.services.latent_storage import LatentsStorageBase
|
||||
from invokeai.app.services.invocation_queue import InvocationQueueABC
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.config import InvokeAIAppConfig
|
||||
from invokeai.app.services.events import EventServiceBase
|
||||
from invokeai.app.services.graph import GraphExecutionState, LibraryGraph
|
||||
from invokeai.app.services.images import ImageServiceABC
|
||||
from invokeai.app.services.invocation_cache.invocation_cache_base import InvocationCacheBase
|
||||
from invokeai.app.services.invocation_queue import InvocationQueueABC
|
||||
from invokeai.app.services.invocation_stats import InvocationStatsServiceBase
|
||||
from invokeai.app.services.invoker import InvocationProcessorABC
|
||||
from invokeai.app.services.item_storage import ItemStorageABC
|
||||
from invokeai.app.services.latent_storage import LatentsStorageBase
|
||||
from invokeai.app.services.model_manager_service import ModelManagerServiceBase
|
||||
from invokeai.app.services.session_processor.session_processor_base import SessionProcessorBase
|
||||
from invokeai.app.services.session_queue.session_queue_base import SessionQueueBase
|
||||
|
||||
|
||||
class InvocationServices:
|
||||
@ -26,8 +31,8 @@ class InvocationServices:
|
||||
boards: "BoardServiceABC"
|
||||
configuration: "InvokeAIAppConfig"
|
||||
events: "EventServiceBase"
|
||||
graph_execution_manager: "ItemStorageABC"["GraphExecutionState"]
|
||||
graph_library: "ItemStorageABC"["LibraryGraph"]
|
||||
graph_execution_manager: "ItemStorageABC[GraphExecutionState]"
|
||||
graph_library: "ItemStorageABC[LibraryGraph]"
|
||||
images: "ImageServiceABC"
|
||||
latents: "LatentsStorageBase"
|
||||
logger: "Logger"
|
||||
@ -35,6 +40,9 @@ class InvocationServices:
|
||||
processor: "InvocationProcessorABC"
|
||||
performance_statistics: "InvocationStatsServiceBase"
|
||||
queue: "InvocationQueueABC"
|
||||
session_queue: "SessionQueueBase"
|
||||
session_processor: "SessionProcessorBase"
|
||||
invocation_cache: "InvocationCacheBase"
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
@ -42,8 +50,8 @@ class InvocationServices:
|
||||
boards: "BoardServiceABC",
|
||||
configuration: "InvokeAIAppConfig",
|
||||
events: "EventServiceBase",
|
||||
graph_execution_manager: "ItemStorageABC"["GraphExecutionState"],
|
||||
graph_library: "ItemStorageABC"["LibraryGraph"],
|
||||
graph_execution_manager: "ItemStorageABC[GraphExecutionState]",
|
||||
graph_library: "ItemStorageABC[LibraryGraph]",
|
||||
images: "ImageServiceABC",
|
||||
latents: "LatentsStorageBase",
|
||||
logger: "Logger",
|
||||
@ -51,10 +59,12 @@ class InvocationServices:
|
||||
processor: "InvocationProcessorABC",
|
||||
performance_statistics: "InvocationStatsServiceBase",
|
||||
queue: "InvocationQueueABC",
|
||||
session_queue: "SessionQueueBase",
|
||||
session_processor: "SessionProcessorBase",
|
||||
invocation_cache: "InvocationCacheBase",
|
||||
):
|
||||
self.board_images = board_images
|
||||
self.boards = boards
|
||||
self.boards = boards
|
||||
self.configuration = configuration
|
||||
self.events = events
|
||||
self.graph_execution_manager = graph_execution_manager
|
||||
@ -66,3 +76,6 @@ class InvocationServices:
|
||||
self.processor = processor
|
||||
self.performance_statistics = performance_statistics
|
||||
self.queue = queue
|
||||
self.session_queue = session_queue
|
||||
self.session_processor = session_processor
|
||||
self.invocation_cache = invocation_cache
|
||||
|
||||
@ -28,22 +28,22 @@ The abstract base class for this class is InvocationStatsServiceBase. An impleme
|
||||
writes to the system log is stored in InvocationServices.performance_statistics.
|
||||
"""
|
||||
|
||||
import psutil
|
||||
import time
|
||||
from abc import ABC, abstractmethod
|
||||
from contextlib import AbstractContextManager
|
||||
from dataclasses import dataclass, field
|
||||
from typing import Dict
|
||||
|
||||
import psutil
|
||||
import torch
|
||||
|
||||
import invokeai.backend.util.logging as logger
|
||||
from invokeai.backend.model_management.model_cache import CacheStats
|
||||
|
||||
from ..invocations.baseinvocation import BaseInvocation
|
||||
from .graph import GraphExecutionState
|
||||
from .item_storage import ItemStorageABC
|
||||
from .model_manager_service import ModelManagerService
|
||||
from invokeai.backend.model_management.model_cache import CacheStats
|
||||
|
||||
# size of GIG in bytes
|
||||
GIG = 1073741824
|
||||
|
||||
@ -17,7 +17,14 @@ class Invoker:
|
||||
self.services = services
|
||||
self._start()
|
||||
|
||||
def invoke(self, graph_execution_state: GraphExecutionState, invoke_all: bool = False) -> Optional[str]:
|
||||
def invoke(
|
||||
self,
|
||||
session_queue_id: str,
|
||||
session_queue_item_id: int,
|
||||
session_queue_batch_id: str,
|
||||
graph_execution_state: GraphExecutionState,
|
||||
invoke_all: bool = False,
|
||||
) -> Optional[str]:
|
||||
"""Determines the next node to invoke and enqueues it, preparing if needed.
|
||||
Returns the id of the queued node, or `None` if there are no nodes left to enqueue."""
|
||||
|
||||
@ -32,7 +39,9 @@ class Invoker:
|
||||
# Queue the invocation
|
||||
self.services.queue.put(
|
||||
InvocationQueueItem(
|
||||
# session_id = session.id,
|
||||
session_queue_id=session_queue_id,
|
||||
session_queue_item_id=session_queue_item_id,
|
||||
session_queue_batch_id=session_queue_batch_id,
|
||||
graph_execution_state_id=graph_execution_state.id,
|
||||
invocation_id=invocation.id,
|
||||
invoke_all=invoke_all,
|
||||
|
||||