## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
fix(nodes): add version to iterate and collect
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
Scale Before Processing Dimensions now respect the Aspect Ratio that is
locked in. This makes it way easier to control the setting when using it
with locked ratios on the canvas.
When a batch creates a session, we need to alert the client of this. Because the sessions are created by the batch manager (not directly in response to a client action), we need to emit an event with the session id.
To accomodate this, a secondary set of sio sub/unsub/event handlers are created. These are specifically for batch events. The room is the `batch_id`.
When creating a batch, the client subscribes to this batch room.
When the batch manager creates a batch session, a `batch_session_created` event is emitted in the appropriate room. It includes the session id. The client then may subscribe to the session room, and all socket stuff proceeds as it did before.
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
Running the config script on Macs triggered an error due to absence of
VRAM on these machines! VRAM setting is now skipped.
## Added/updated tests?
- [ ] Yes
- [X] No : Will add this test in the near future.
@blessedcoolant Per discussion, have updated codeowners so that we're
not force merging things.
This will, however, necessitate a much more disciplined approval.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [X] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
Add textfontimage node to communityNodes.md
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
fix(ui): fix non-nodes validation logic being applied to nodes invoke
button
For example, if you had an invalid controlnet setup, it would prevent
you from invoking on nodes, when node validation was disabled.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes
https://discord.com/channels/1020123559063990373/1028661664519831552/1148431783289966603
## What type of PR is this? (check all applicable)
- [x] Feature
- [x] Optimization
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
# Coherence Mode
A new parameter called Coherence Mode has been added to Coherence Pass
settings. This parameter controls what kind of Coherence Pass is done
after Inpainting and Outpainting.
- Unmasked: This performs a complete unmasked image to image pass on the
entire generation.
- Mask: This performs a masked image to image pass using your input mask
as the coherence mask.
- Mask Edge [DEFAULT] - This performs as masked image to image pass on
the edges of your mask to try and clear out the seams.
# Why The Coherence Masked Modes?
One of the issues with unmasked coherence pass arises when the diffusion
process is trying to align detailed or organic objects. Because Image to
Image tends change the image a little bit even at lower strengths, this
ends up in the paste back process being slightly misaligned. By
providing the mask to the Coherence Pass, we can try to eliminate this
in those cases. While it will be impossible to address this for every
image out there, having these options will allow the user to automate a
lot of this. For everything else there's manual paint over with inpaint.
# Graph Improvements
The graphs have now been refined quite a bit. We no longer do manual
blurring of the masks anymore for outpainting. This is no longer needed
because we now dilate the mask depending on the blur size while pasting
back. As a result we got rid of quite a few nodes that were handling
this in the older graph.
The graphs are also a lot cleaner now because we now tackle Scaled
Dimensions & Coherence Mode completely independently.
Inpainting result seem very promising especially with the Mask Edge
mode.
---
# New Infill Methods [Experimental]
We are currently trying out various new infill methods to see which ones
might perform the best in outpainting. We may keep all of them or keep
none. This will be decided as we test more.
## LaMa Infill
- Renabled LaMA infill in the UI.
- We are trying to get this to work without a memory overhead.
In order to use LaMa, you need to manually download and place the LaMa
JIT model in `models/core/misc/lama/lama.pt`. You can download the JIT
model from Sanster
[here](https://github.com/Sanster/models/releases/download/add_big_lama/big-lama.pt)
and rename it to `lama.pt` or you can use the script in the original
LaMA repo to convert the base model to a JIT model yourself.
## CV2 Infill
- Added a new infilling method using CV2's Inpaint.
## Patchmatch Rescaling
Patchmatch infill input image is now downscaled and infilled. Patchmatch
can be really slow at large resolutions and this is a pretty decent way
to get around that. Additionally, downscaling might also provide a
better patch match by avoiding larger areas to be infilled with
repeating patches. But that's just the theory. Still testing it out.
## [optional] Are there any post deployment tasks we need to perform?
- If we decide to keep LaMA infill, then we will need to host the model
and update the installer to download it as a core model.
Adds my (@dwringer's) released nodes to the community nodes page.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [X] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
Adds my released nodes -
Depth Map from Wavefront OBJ
Enhance Image
Generative Grammar-Based Prompt Nodes
Ideal Size Stepper
Image Compositor
Final Size & Orientation / Random Switch (Integers)
Text Mask (Simple 2D)
* Consolidated saturation/luminosity adjust.
Now allows increasing and inverting.
Accepts any color PIL format and channel designation.
* Updated docs/nodes/defaultNodes.md
* shortened tags list to channel types only
* fix typo in mode list
* split features into offset and multiply nodes
* Updated documentation
* Change invert to discrete boolean.
Previous math was unclear and had issues with 0 values.
* chore: black
* chore(ui): typegen
---------
Co-authored-by: psychedelicious <4822129+psychedelicious@users.noreply.github.com>
Revised links to my node py files, replacing them with links to independent repos. Additionally I consolidated some nodes together (Image and Mask Composition Pack, Size Stepper nodes).
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [x] Yes
- [ ] No
## Description
This PR is based on #4423 and should not be merged until it is merged.
[feat(nodes): add version to node
schemas](c179d4ccb7)
The `@invocation` decorator is extended with an optional `version` arg.
On execution of the decorator, the version string is parsed using the
`semver` package (this was an indirect dependency and has been added to
`pyproject.toml`).
All built-in nodes are set with `version="1.0.0"`.
The version is added to the OpenAPI Schema for consumption by the
client.
[feat(ui): handle node
versions](03de3e4f78)
- Node versions are now added to node templates
- Node data (including in workflows) include the version of the node
- On loading a workflow, we check to see if the node and template
versions match exactly. If not, a warning is logged to console.
- The node info icon (top-right corner of node, which you may click to
open the notes editor) now shows the version and mentions any issues.
- Some workflow validation logic has been shifted around and is now
executed in a redux listener.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes#4393
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
Loading old workflows should prompt a warning, and the node status icon
should indicate some action is needed.
## [optional] Are there any post deployment tasks we need to perform?
I've updated the default workflows:
- Bump workflow versions from 1.0 to 1.0.1
- Add versions for all nodes in the workflows
- Test workflows
[Default
Workflows.zip](https://github.com/invoke-ai/InvokeAI/files/12511911/Default.Workflows.zip)
I'm not sure where these are being stored right now @Millu
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
### Polymorphic Fields
Initial support for polymorphic field types. Polymorphic types are a
single of or list of a specific type. For example, `Union[str,
list[str]]`.
Polymorphics do not yet have support for direct input in the UI (will
come in the future). They will be forcibly set as Connection-only
fields, in which case users will not be able to provide direct input to
the field.
If a polymorphic should present as a singleton type - which would allow
direct input - the node must provide an explicit type hint.
For example, `DenoiseLatents`' `CFG Scale` is polymorphic, but in the
node editor, we want to present this as a number input. In the node
definition, the field is given `ui_type=UIType.Float`, which tells the
UI to treat this as a `float` field.
The connection validation logic will prevent connecting a collection to
`CFG Scale` in this situation, because it is typed as `float`. The
workaround is to disable validation from the settings to make this
specific connection. A future improvement will resolve this.
### Collection Fields
This also introduces better support for collection field types. Like
polymorphics, collection types are parsed automatically by the client
and do not need any specific type hints.
Also like polymorphics, there is no support yet for direct input of
collection types in the UI.
### Other Changes
- Disabling validation in workflow editor now displays the visual hints
for valid connections, but lets you connect to anything.
- Added `ui_order: int` to `InputField` and `OutputField`. The UI will
use this, if present, to order fields in a node UI. See usage in
`DenoiseLatents` for an example.
- Updated the field colors - duplicate colors have just been lightened a
bit. It's not perfect but it was a quick fix.
- Field handles for collections are the same color as their single
counterparts, but have a dark dot in the center of them.
- Field handles for polymorphics are a rounded square with dot in the
middle.
- Removed all fields that just render `null` from `InputFieldRenderer`,
replaced with a single fallback
- Removed logic in `zValidatedWorkflow`, which checked for existence of
node templates for each node in a workflow. This logic introduced a
circular dependency, due to importing the global redux `store` in order
to get the node templates within a zod schema. It's actually fine to
just leave this out entirely; The case of a missing node template is
handled by the UI. Fixing it otherwise would introduce a substantial
headache.
- Fixed the `ControlNetInvocation.control_model` field default, which
was a string when it shouldn't have one.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes#4266
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
Add this polymorphic float node to the end of your
`invokeai/app/invocations/primitives.py`:
```py
@invocation("float_poly", title="Float Poly Test", tags=["primitives", "float"], category="primitives")
class FloatPolyInvocation(BaseInvocation):
"""A float polymorphic primitive value"""
value: Union[float, list[float]] = InputField(default_factory=list, description="The float value")
def invoke(self, context: InvocationContext) -> FloatOutput:
return FloatOutput(value=self.value[0] if isinstance(self.value, list) else self.value)
``
Head over to nodes and try to connecting up some collection and polymorphic inputs.
- Node versions are now added to node templates
- Node data (including in workflows) include the version of the node
- On loading a workflow, we check to see if the node and template versions match exactly. If not, a warning is logged to console.
- The node info icon (top-right corner of node, which you may click to open the notes editor) now shows the version and mentions any issues.
- Some workflow validation logic has been shifted around and is now executed in a redux listener.
The `@invocation` decorator is extended with an optional `version` arg. On execution of the decorator, the version string is parsed using the `semver` package (this was an indirect dependency and has been added to `pyproject.toml`).
All built-in nodes are set with `version="1.0.0"`.
The version is added to the OpenAPI Schema for consumption by the client.
Initial support for polymorphic field types. Polymorphic types are a single of or list of a specific type. For example, `Union[str, list[str]]`.
Polymorphics do not yet have support for direct input in the UI (will come in the future). They will be forcibly set as Connection-only fields, in which case users will not be able to provide direct input to the field.
If a polymorphic should present as a singleton type - which would allow direct input - the node must provide an explicit type hint.
For example, `DenoiseLatents`' `CFG Scale` is polymorphic, but in the node editor, we want to present this as a number input. In the node definition, the field is given `ui_type=UIType.Float`, which tells the UI to treat this as a `float` field.
The connection validation logic will prevent connecting a collection to `CFG Scale` in this situation, because it is typed as `float`. The workaround is to disable validation from the settings to make this specific connection. A future improvement will resolve this.
This also introduces better support for collection field types. Like polymorphics, collection types are parsed automatically by the client and do not need any specific type hints.
Also like polymorphics, there is no support yet for direct input of collection types in the UI.
- Disabling validation in workflow editor now displays the visual hints for valid connections, but lets you connect to anything.
- Added `ui_order: int` to `InputField` and `OutputField`. The UI will use this, if present, to order fields in a node UI. See usage in `DenoiseLatents` for an example.
- Updated the field colors - duplicate colors have just been lightened a bit. It's not perfect but it was a quick fix.
- Field handles for collections are the same color as their single counterparts, but have a dark dot in the center of them.
- Field handles for polymorphics are a rounded square with dot in the middle.
- Removed all fields that just render `null` from `InputFieldRenderer`, replaced with a single fallback
- Removed logic in `zValidatedWorkflow`, which checked for existence of node templates for each node in a workflow. This logic introduced a circular dependency, due to importing the global redux `store` in order to get the node templates within a zod schema. It's actually fine to just leave this out entirely; The case of a missing node template is handled by the UI. Fixing it otherwise would introduce a substantial headache.
- Fixed the `ControlNetInvocation.control_model` field default, which was a string when it shouldn't have one.
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] No
## Description
Automatically infer the name of the model from the path supplied IF the
model name slot is empty. If the model name is not empty, we presume
that the user has entered a model name or made changes to it and we do
not touch it in order to not override user changes.
## Related Tickets & Documents
- Addresses: #4443
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
fix(ui): clicking node collapse button does not bring node to front
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue
https://discord.com/channels/1020123559063990373/1130288930319761428/1147333454632071249
- Closes#4438
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
There is a call in `baseinvocation.invocation_output()` to
`cls.__annotations__`. However, in Python 3.9 not all objects have this
attribute. I have worked around the limitation in the way described in
https://docs.python.org/3/howto/annotations.html , which supposedly will
produce same results in 3.9, 3.10 and 3.11.
## Related Tickets & Documents
See
https://discord.com/channels/1020123559063990373/1146897072394608660/1146939182300799017
for first bug report.
## What type of PR is this? (check all applicable)
- [x] Cleanup
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
Used https://github.com/albertas/deadcode to get rough overview of what
is not used, checked everything manually though. App still runs.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes#4424
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
Ensure it doesn't explode when you run it.
* add StableDiffusionXLInpaintPipeline to probe list
* add StableDiffusionXLInpaintPipeline to probe list
* Blackified (?)
---------
Authored-by: Lincoln Stein <lstein@gmail.com>
Mucked about with to get it merged by: Kent Keirsey <31807370+hipsterusername@users.noreply.github.com>
Add a click handler for node wrapper component that exclusively selects that node, IF no other modifier keys are held.
Technically I believe this means we are doubling up on the selection logic, as reactflow handles this internally also. But this is by far the most reliable way to fix the UX.
## What type of PR is this? (check all applicable)
- [x] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
The logic that introduced a circular import was actually extraneous. I
have entirely removed it.
This fixes the frontend lint test.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
This is the 3.1.0 release candidate. Minor bugfixes will be applied here
during testing and then merged into main upon release.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
- Workflows are saved to image files directly
- Image-outputting nodes have an `Embed Workflow` checkbox which, if
enabled, saves the workflow
- `BaseInvocation` now has an `workflow: Optional[str]` field, so all
nodes automatically have the field (but again only image-outputting
nodes display this in UI)
- If this field is enabled, when the graph is created, the workflow is
stringified and set in this field
- Nodes should add `workflow=self.workflow` when they save their output
image to have the workflow written to the image
- Uploads now have their metadata retained so that you can upload
somebody else's image and have access to that workflow
- Graphs are no longer saved to images, workflows replace them
### TODO
- Images created in the linear UI do not have a workflow saved yet. Need
to write a function to build a workflow around the linear UI graph when
using linear tabs. Unfortunately it will not have the nice positioning
and size data the node editor gives you when you save a workflow...
we'll have to figure out how to handle this.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
All invocation metadata (type, title, tags and category) are now defined in decorators.
The decorators add the `type: Literal["invocation_type"]: "invocation_type"` field to the invocation.
Category is a new invocation metadata, but it is not used by the frontend just yet.
- `@invocation()` decorator for invocations
```py
@invocation(
"sdxl_compel_prompt",
title="SDXL Prompt",
tags=["sdxl", "compel", "prompt"],
category="conditioning",
)
class SDXLCompelPromptInvocation(BaseInvocation, SDXLPromptInvocationBase):
...
```
- `@invocation_output()` decorator for invocation outputs
```py
@invocation_output("clip_skip_output")
class ClipSkipInvocationOutput(BaseInvocationOutput):
...
```
- update invocation docs
- add category to decorator
- regen frontend types
## What type of PR is this? (check all applicable)
- [x] Feature
- [x] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
- Keep Boards Modal open by default.
- Combine Coherence and Mask settings under Compositing
- Auto Change Dimensions based on model type (option)
- Size resets are now model dependent
- Add Set Control Image Height & Width to Width and Height option.
- Fix numerous color & spacing issues (especially those pertaining to
sliders being too close to the bottom)
- Add Lock Ratio Option
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
## QA Instructions, Screenshots, Recordings
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
In current main, long prompts and support for [Compel's `.and()`
syntax](https://github.com/damian0815/compel/blob/main/doc/syntax.md#conjunction)
is missing. This PR adds it back.
### needs Compel>=2.0.2.dev1
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
Send stuff directly from canvas to ControlNet
## Usage
- Two new buttons available on canvas Controlnet to import image and
mask.
- Click them.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
Adds Next and Prev Buttons to the current image node
As usual you don't have to use 😄
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ X ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ X ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ X ] No
## Description
Adds Seamless back into the options for Denoising.
## Related Tickets & Documents
- Related Issue #3975
## QA Instructions, Screenshots, Recordings
- Should test X, Y, and XY seamless tiling for all model architectures.
## Added/updated tests?
- [ ] Yes
- [ X ] No : Will need some guidance on automating this.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
Allow an image and action to be passed into the app for starting state
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
Fix masked generation with inpaint models
## Related Tickets & Documents
- Closes#4295
## Added/updated tests?
- [ ] Yes
- [x] No
Added a node to prompt Oobabooga Text-Generation-Webui
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [x] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [x] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
Adds loading workflows with exhaustive validation via `zod`.
There is a load button but no dedicated save/load UI yet. Also need to add versioning to the workflow format itself.
## What type of PR is this? (check all applicable)
- [X Refactor
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
### Refactoring
This PR refactors `invokeai.app.services.config` to be easier to
maintain by splitting off the argument, environment and init file
parsing code from the InvokeAIAppConfig object. This will hopefully make
it easier for people to find the place where the various settings are
defined.
### New Features
In collaboration with @StAlKeR7779 , I have renamed and reorganized the
settings controlling image generation and model management to be more
intuitive. The relevant portion of the init file now looks like this:
```
Model Cache:
ram: 14.5
vram: 0.5
lazy_offload: true
Device:
precision: auto
device: auto
Generation:
sequential_guidance: false
attention_type: auto
attention_slice_size: auto
force_tiled_decode: false
```
Key differences are:
1. Split `Performance/Memory` into `Device`, `Generation` and `Model
Cache`
2. Added the ability to force the `device`. The value of this option is
one of {`auto`, `cpu`, `cuda`, `cuda:1`, `mps`}
3. Added the ability to force the `attention_type`. Possible values are
{`auto`, `normal`, `xformers`, `sliced`, `torch-sdp`}
4. Added the ability to force the `attention_slice_size` when `sliced`
attention is in use. The value of this option is one of {`auto`, `max`}
or an integer between 1 and 8.
@StAlKeR7779 Please confirm that I wired the `attention_type` and
`attention_slice_size` configuration options to the diffusers backend
correctly.
In addition, I have exposed the generation-related configuration options
to the TUI:

### Backward Compatibility
This refactor should be backward compatible with earlier versions of
`invokeai.yaml`. If the user re-runs the `invokeai-configure` script,
`invokeai.yaml` will be upgraded to the current format. Several
configuration attributes had to be changed in order to preserve backward
compatibility. These attributes been changed in the code where
appropriate. For the record:
| Old Name | Preferred New Name | Comment |
| ------------| ---------------|------------|
| `max_cache_size` | `ram_cache_size` |
| `max_vram_cache` | `vram_cache_size` |
| `always_use_cpu` | `use_cpu` | Better to check conf.device == "cpu" |
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
[fix(stats): fix fail case when previous graph is
invalid](d1d2d5a47d)
When retrieving a graph, it is parsed through pydantic. It is possible
that this graph is invalid, and an error is thrown.
Handle this by deleting the failed graph from the stats if this occurs.
[fix(stats): fix InvocationStatsService
types](1b70bd1380)
- move docstrings to ABC
- `start_time: int` -> `start_time: float`
- remove class attribute assignments in `StatsContext`
- add `update_mem_stats()` to ABC
- add class attributes to ABC, because they are referenced in instances
of the class. if they should not be on the ABC, then maybe there needs
to be some restructuring
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
On `main` (not this PR), create a situation in which an graph is valid
but will be rendered invalid on invoke. Easy way in node editor:
- create an `Integer Primitive` node, set value to 3
- create a `Resize Image` node and add an image to it
- route the output of `Integer Primitive` to the `width` of `Resize
Image`
- Invoke - this will cause first a `Validation Error` (expected), and if
you inspect the error in the JS console, you'll see it is a "session
retrieval error"
- Invoke again - this will also cause a `Validation Error`, but if you
inspect the error you should see it originates in the stats module (this
is the error this PR fixes)
- Fix the graph by setting the `Integer Primitive` to 512
- Invoke again - you get the same `Validation Error` originating from
stats, even tho there are no issues
Switch to this PR, and then you should only ever get the `Validation
Error` that that is classified as a "session retrieval error".
This improves the overall responsiveness of the system substantially, but does make each iteration *slightly* slower, distributing the up-front cost across the batch.
Two main changes:
1. Create BatchSessions immediately, but do not create a whole graph execution state until the batch is executed.
BatchSessions are created with a `session_id` that does not exist in sessions database.
The default state is changed to `"uninitialized"` to better represent this.
Results: Time to create 5000 batches reduced from over 30s to 2.5s
2. Use `executemany()` to retrieve lists of created sessions.
Results: time to create 5000 batches reduced from 2.5s to under 0.5s
Other changes:
- set BatchSession state to `"in_progress"` just before `invoke()` is called
- rename a few methods to accomodate the new behaviour
- remove unused `BatchProcessStorage.get_created_sessions()` method
It is `"invocation"` for invocations and `"output"` for outputs. Clients may use this to confidently and positively identify if an OpenAPI schema object is an invocation or output, instead of using a potentially fragile heuristic.
Doing this via `BaseInvocation`'s `Config.schema_extra()` means all clients get an accurate OpenAPI schema.
Shifts the responsibility of correct types to the backend, where previously it was on the client.
Doing this via these classes' `Config.schema_extra()` method makes it unintrusive and clients will get the correct types for these properties.
Shifts the responsibility of correct types to the backend, where previously it was on the client.
The `type` property is required on all of them, but because this is defined in pydantic as a Literal, it is not required in the OpenAPI schema. Easier to fix this by changing the generated types than fiddling around with pydantic.
- move docstrings to ABC
- `start_time: int` -> `start_time: float`
- remove class attribute assignments in `StatsContext`
- add `update_mem_stats()` to ABC
- add class attributes to ABC, because they are referenced in instances of the class. if they should not be on the ABC, then maybe there needs to be some restructuring
When retrieving a graph, it is parsed through pydantic. It is possible that this graph is invalid, and an error is thrown.
Handle this by deleting the failed graph from the stats if this occurs.
Previously if an image was used in nodes and you deleted it, it would reset all of node editor. Same for controlnet.
Now it only resets the specific nodes or controlnets that used that image.
Add "nodrag", "nowheel" and "nopan" class names in interactable elements, as neeeded. This fixes the mouse interactions and also makes the node draggable from anywhere without needing shift.
Also fixes ctrl/cmd multi-select to support deselecting.
- move docstrings to ABC
- `start_time: int` -> `start_time: float`
- remove class attribute assignments in `StatsContext`
- add `update_mem_stats()` to ABC
- add class attributes to ABC, because they are referenced in instances of the class. if they should not be on the ABC, then maybe there needs to be some restructuring
When retrieving a graph, it is parsed through pydantic. It is possible that this graph is invalid, and an error is thrown.
Handle this by deleting the failed graph from the stats if this occurs.
## What type of PR is this? (check all applicable)
- [X] Feature
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
Follow symbolic links when auto importing from a directory. Previously
links to files worked, but links to directories weren’t entered during
the scanning/import process.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
Should be removed when added in diffusers
https://github.com/huggingface/diffusers/pull/4599
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
PR to add Seam Painting back to the Canvas.
## TODO Later
While the graph works as intended, it has become extremely large and
complex. I don't know if there's a simpler way to do this. Maybe there
is but there's soo many connections and visualizing the graph in my head
is extremely difficult. We might need to create some kind of tooling for
this. Coz it's going going to get crazier.
But well works for now.
## What type of PR is this? (check all applicable)
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
This PR enhances the logging of performance statistics to include RAM
and model cache information. After each generation, the following will
be logged. The new information follows TOTAL GRAPH EXECUTION TIME.
```
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> Graph stats: 2408dbec-50d0-44a3-bbc4-427037e3f7d4
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> Node Calls Seconds VRAM Used
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> main_model_loader 1 0.004s 0.000G
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> clip_skip 1 0.002s 0.000G
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> compel 2 2.706s 0.246G
[2023-08-15 21:55:39,010]::[InvokeAI]::INFO --> rand_int 1 0.002s 0.244G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> range_of_size 1 0.002s 0.244G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> iterate 1 0.002s 0.244G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> metadata_accumulator 1 0.002s 0.244G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> noise 1 0.003s 0.244G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> denoise_latents 1 2.429s 2.022G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> l2i 1 1.020s 1.858G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> TOTAL GRAPH EXECUTION TIME: 6.171s
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> RAM used by InvokeAI process: 4.50G (delta=0.10G)
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> RAM used to load models: 1.99G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> VRAM in use: 0.303G
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> RAM cache statistics:
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> Model cache hits: 2
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> Model cache misses: 5
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> Models cached: 5
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> Models cleared from cache: 0
[2023-08-15 21:55:39,011]::[InvokeAI]::INFO --> Cache high water mark: 1.99/7.50G
```
There may be a memory leak in InvokeAI. I'm seeing the process memory
usage increasing by about 100 MB with each generation as shown in the
example above.
The internal `BatchProcessStorage.get_session()` method throws when it finds nothing, but we were not catching any exceptions.
This caused a exception when the batch manager handles a `graph_execution_state_complete` event that did not originate from a batch.
Fixed by handling the exception.
If the values from the `session_dict` are invalid, the model instantiation will fail, or if we end up with an invalid `batch_id`, the app will not run. So I think just parsing the dict directly is equivalent.
Also the LSP analyser is pleased now - no red squigglies.
Providing a `default_factory` is enough for pydantic to know to create the attribute on instantiation if it's not already provided. We can then make make the typing just `str`.
Previously the editor was using prop-drilling node data and templates to get values deep into nodes. This ended up causing very noticeable performance degradation. For example, any text entry fields were super laggy.
Refactor the whole thing to use memoized selectors via hooks. The hooks are mostly very narrow, returning only the data needed.
Data objects are never passed down, only node id and field name - sometimes the field kind ('input' or 'output').
The end result is a *much* smoother node editor with very minimal rerenders.
There is a tricky mouse event interaction between chakra's `useOutsideClick()` hook (used by chakra `<Menu />`) and reactflow. The hook doesn't work when you click the main reactflow area.
To get around this, I've used a dirty hack, copy-pasting the simple context menu component we use, and extending it slightly to respond to a global `contextMenusClosed` redux action.
- also implement pessimistic updates for starring, only changing the images that were successfully updated by backend
- some autoformat changes crept in
If `reactflow` initializes before the node templates are parsed, edges may not be rendered and the viewport may get reset.
- Add `isReady` state to `NodesState`. This is false when we are loading or parsing node templates and true when that is finished.
- Conditionally render `reactflow` based on `isReady`.
- Add `viewport` to `NodesState` & handlers to keep it synced. This allows `reactflow` to mount and unmount freely and not lose viewport.
Refine concept of "parameter" nodes to "primitives":
- integer
- float
- string
- boolean
- image
- latents
- conditioning
- color
Each primitive has:
- A field definition, if it is not already python primitive value. The field is how this primitive value is passed between nodes. Collections are lists of the field in node definitions. ex: `ImageField` & `list[ImageField]`
- A single output class. ex: `ImageOutput`
- A collection output class. ex: `ImageCollectionOutput`
- A node, which functions to load or pass on the primitive value. ex: `ImageInvocation` (in this case, `ImageInvocation` replaces `LoadImage`)
Plus a number of related changes:
- Reorganize these into `primitives.py`
- Update all nodes and logic to use primitives
- Consolidate "prompt" outputs into "string" & "mask" into "image" (there's no reason for these to be different, the function identically)
- Update default graphs & tests
- Regen frontend types & minor frontend tidy related to changes
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
On Windows systems, model merging was crashing at the very last step
with an error related to not being able to serialize a WindowsPath
object. I have converted the path that is passed to `save_pretrained`
into a string, which I believe will solve the problem.
Note that I had to rebuild the web frontend and add it to the PR in
order to test on my Windows VM which does not have the full node stack
installed due to space limitations.
## Related Tickets & Documents
https://discord.com/channels/1020123559063990373/1042475531079262378/1140680788954861698
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: it's smol
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
docker_entrypoint.sh does not quote variable expansion to prevent word
splitting, causing paths with spaces to fail as in #3913
## Related Tickets & Documents
#3913
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #3913
- Closes#3913
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [x] Refactor
- [x] Feature
- [x] Bug Fix
- [x] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
- Remove SDXL raw prompt nodes
- SDXL and SD1/2 generation merged to same nodes - t2l/l2l
- Fixed - if no xformers installed we trying to enable attention
slicing, ignoring torch-sdp availability
- Fixed - In SDXL negative prompt now creating zeroed tensor(according
to official code)
- Added mask field to l2l node
- Removed inpaint node and all legacy code related to this node
- Pass info about seed in latents, so we can use it to initialize
ancestral/sde schedulers
- t2l and l2l nodes moved from strength to denoising_start/end
- Removed code for noise threshold(@hipsterusername said that there no
plans to restore this feature)
- Fixed - first preview image now not gray
- Fixed - report correct total step count in progress, added scheduler
order in progress event
- Added MaskEdge and ColorCorrect nodes (@hipsterusername)
## Added/updated tests?
- [ ] Yes
- [x] No
This is probably better done on the backend or in a different way. This can cause steps to go above 1000 which is more than the set number for the model.
This fixes an import issue introduced in commit 1bfe983. The change made
'invokeai_configure' into a module but this line still tries to call it
as if it's a function. This will result in a `'module' not callable`
error.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
imic from discord ask that I submit a PR to fix this bug.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
This fixes an import issue introduced in commit 1bfe983.
The change made 'invokeai_configure' into a module but this line still tries to call it as if it's a function. This will result in a `'module' not callable` error.
Seam options are now removed. They are replaced by two options --Mask Blur and Mask Blur Method .. which control the softness of the mask that is being painted.
During install testing I discovered two small problems in the
command-line scripts. These are fixed.
## What type of PR is this? (check all applicable)
- [X Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
-
## Have you updated all relevant documentation?
- [X] Yes
## Description
- installer - use correct entry point for invokeai-configure
- model merge script - prevent error when `--root` not provided
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
Add support for LyCORIS IA3 format
## Related Tickets & Documents
- Closes#4229
## Added/updated tests?
- [ ] Yes
- [x] No
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] No - minor fix
## Have you updated all relevant documentation?
- [X] Yes
## Description
It turns out that some LoRAs do not have the text encoder model, and
this was causing the code that distinguishes the model base type during
model import to reject them as having an unknown base model. This PR
enables detection of these cases.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [s] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
was sorting with disabled at top of list instead of bottom
fixes#4217
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes#4217
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->

## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
There was no check at all to see if the canvas had a valid model already
selected. The first model in the list was selected every time.
Now, we check if its valid. If not, we go through the logic to try and
pick the first valid model.
If there are no valid models, or there was a problem listing models, the
model selection is cleared.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes#4125
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
- Go to Canvas tab
- Select a model other than the first one in the list
- Go to a different tab
- Go back to Canvas tab
- The model should be the same as you selected
There was no check at all to see if the canvas had a valid model already selected. The first model in the list was selected every time.
Now, we check if its valid. If not, we go through the logic to try and pick the first valid model.
If there are no valid models, or there was a problem listing models, the model selection is cleared.
## What type of PR is this? (check all applicable)
- [X ] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
## Have you updated all relevant documentation?
- [X] Yes
## Description
This PR adds the `invokeai-import-images` script, which imports a
directory of 2.*.* -generated images into the current InvokeAI root
directory, preserving and converting their metadata. The script also
handles 3.* images.
Many thanks to @techjedi for writing this. This version differs from the
original in two minor respects:
1. It is installed as an `invokeai-import-images` command.
2. The prompts for image and database paths use file completion provided
by the `prompt_toolkit` library.
## To Test
1. Activate the virtual environment for the destination root to import
INTO
2. Run `invokeai-import-images`
3. Follow the prompts
## Related Tickets & Documents
This is a frequently-requested feature on Discord, but I couldn't find
an Issue.
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [X] No : but should in the future
## What type of PR is this? (check all applicable)
- [X ] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [X] No - will be in release notes
## Description
On CUDA systems, this PR adds a new slider to the install-time configure
script for adjusting the VRAM cache and suggests a good starting value
based on the user's max VRAM (this is subject to verification).
On non-CUDA systems this slider is suppressed.
Please test on both CUDA and non-CUDA systems using:
```
invokeai-configure --root ~/invokeai-main/ --skip-sd --skip-support
```
To see and test the default values, move `invokeai.yaml` out of the way
before running.
**Note added 8 August 2023**
This PR also fixes the configure and model install scripts so that if
the window is too small to fit the user interface, the user will be
prompted to interactively resize the window and/or change font size
(with the option to give up). This will prevent `npyscreen` from
generating its horrible tracebacks.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X Yes
- [ ] No
## Description
If `models.yaml` is cleared out for some reason, the model manager will
repopulate it by scanning `models`. However, this would fail with a
pydantic validation error if any SDXL checkpoint models were present
because the lack of logic to pick the correct configuration file. This
has now been added.
## What type of PR is this? (check all applicable)
- [X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X No, because small fix
## Have you updated all relevant documentation?
- [X] Yes
## Description
A logic bug was introduced in PR #4109 that caused Web-based model
updates to fail with a pydantic validation error. This corrects the
problem.
## Related Tickets & Documents
PR #4109
* Fix hue adjustment
Hue adjustment wasn't working correctly because color channels got swapped. This has now been fixed and we're using PIL rather than cv2 to do the RGBA->HSV->RGBA conversion. The range of hue adjustment is also the more typical 0..360 degrees.
orphaned since #3550 removed the LazilyLoadedModelGroup code, probably unused since ModelCache took over responsibility for sequential offload somewhere around #3335.
ApiDependencies.invoker` provides typing for the API's services layer. Marking it `Optional` results in all the routes seeing it as optional, which is not good.
Instead of marking it optional to satisfy the initial assignment to `None`, we can just skip the initial assignment. This preserves the IDE hinting in API layer and is types-legal.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
At install time, when the user's config specified "auto" precision, the
installer was downloading the fp32 models even when an fp16 model would
be appropriate for the OS.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Closes#4127
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No
## Description
Add lora loading for sdxl.
NOT TESTED - I run only 2 loras, please check more(including lycoris if
they already exists).
## QA Instructions, Screenshots, Recordings
https://civitai.com/models/118536/voxel-xl

## Added/updated tests?
- [ ] Yes
- [x] No
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [X] Feature
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
This PR adds execution time and VRAM usage reporting to each graph
invocation. The log output will look like this:
```
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> Graph stats: c7764585-9c68-4d9d-a199-55e8186790f3
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> Node Calls Seconds VRAM Used
[2023-08-02 18:03:04,507]::[InvokeAI]::INFO --> main_model_loader 1 0.005s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> clip_skip 1 0.004s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> compel 2 0.512s 0.26G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> rand_int 1 0.001s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> range_of_size 1 0.001s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> iterate 1 0.001s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> metadata_accumulator 1 0.002s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> noise 1 0.002s 0.01G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> t2l 1 3.541s 1.93G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> l2i 1 0.679s 0.58G
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> TOTAL GRAPH EXECUTION TIME: 4.749s
[2023-08-02 18:03:04,508]::[InvokeAI]::INFO --> Current VRAM utilization 0.01G
```
On systems without CUDA, the VRAM stats are not printed.
The current implementation keeps track of graph ids separately so will
not be confused when several graphs are executing in parallel. It
handles exceptions, and it is integrated into the app framework by
defining an abstract base class and storing an implementation instance
in `InvocationServices`.
multi-select actions include:
- drag to board to move all to that board
- right click to add all to board or delete all
backend changes:
- add routes for changing board for list of image names, deleting list of images
- change image-specific routes to `images/i/{image_name}` to not clobber other routes (like `images/upload`, `images/delete`)
- subclass pydantic `BaseModel` as `BaseModelExcludeNull`, which excludes null values when calling `dict()` on the model. this fixes inconsistent types related to JSON parsing null values into `null` instead of `undefined`
- remove `board_id` from `remove_image_from_board`
frontend changes:
- multi-selection stuff uses `ImageDTO[]` as payloads, for dnd and other mutations. this gives us access to image `board_id`s when hitting routes, and enables efficient cache updates.
- consolidate change board and delete image modals to handle single and multiples
- board totals are now re-fetched on mutation and not kept in sync manually - was way too tedious to do this
- fixed warning about nested `<p>` elements
- closes#4088 , need to handle case when `autoAddBoardId` is `"none"`
- add option to show gallery image delete button on every gallery image
frontend refactors/organisation:
- make typegen script js instead of ts
- enable `noUncheckedIndexedAccess` to help avoid bugs when indexing into arrays, many small changes needed to satisfy TS after this
- move all image-related endpoints into `endpoints/images.ts`, its a big file now, but this fixes a number of circular dependency issues that were otherwise felt impossible to resolve
Currently we use some workflow trigger conditionals to run either a real test workflow (installing the app and running it) or a fake workflow, disguised as the real one, that just auto-passes.
This change refactors the workflow to use a single workflow that can be skipped, using another github action to determine which things to run depending on the paths changed.
## What type of PR is this? (check all applicable)
- [x] Refactor
## Have you discussed this change with the InvokeAI team?
- [x] No, because it's pretty minor
## Have you updated all relevant documentation?
- [x] No
## Description
This PR just moves the PR template to within the `.github/` directory
leading to a overall minimal project structure.
## Added/updated tests?
- [x] No : because this change doesn't affect or need a separate test
- Create abstract base class InvocationStatsServiceBase
- Store InvocationStatsService in the InvocationServices object
- Collect and report stats on simultaneous graph execution
independently for each graph id
- Track VRAM usage for each node
- Handle cancellations and other exceptions gracefully
## What type of PR is this? (check all applicable)
- [ X] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ X] No, because: invisible change
## Have you updated all relevant documentation?
- [ X] Yes
- [ ] No
## Description
There was a problem in 3.0.1 with root resolution. If INVOKEAI_ROOT were
set to "." (or any relative path), then the location of root would
change if the code did an os.chdir() after config initialization. I
fixed this in a quick and dirty way for 3.0.1.post3.
This PR cleans up the code with a little refactoring.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ]X Bug Fix
- [ ] Optimization
- [ X] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ X] No, because: obvious problem
## Have you updated all relevant documentation?
- [ X] Yes
- [ ] No
## Description
The manual installation documentation in both README.md and
020_MANUAL_INSTALL give an incomplete `invokeai-configure` command which
leaves out the path to the root directory to create. As a result, the
invokeai root directory gets created in the user’s home directory, even
if they intended it to be placed somewhere else.
This is a fairly important issue.
## What type of PR is this? (check all applicable)
- [x] Refactor
- [x] Feature
- [x] Bug Fix
- [?] Optimization
## Have you discussed this change with the InvokeAI team?
- [x] No
## Description
- Fixed filter type select using `images` instead of `all` -- Probably
some merge conflict.
- Added loading state for model lists. Handy when the model list takes
longer than a second for any reason to fetch. Better to show this than
an empty screen.
- Refactored the render model list function so we modify the display
component in one area rather than have repeated code.
### Other Issues
- The list can get a bit laggy on initial load when you have a hundreds
of models / loras. This needs to be fixed. Will make another PR for
this.
## What type of PR is this? (check all applicable)
- [x] Refactor
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: trivial
## Description
Adds a few obviously missing `Optional` on fields that default to
`None`.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [X] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because: Just a documentation update
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
Updated documentation with a getting started guide & a glossary of terms
needed to get started
Updated the landing page flow for users
<img width="1430" alt="Screenshot 2023-07-27 at 9 53 25 PM"
src="https://github.com/invoke-ai/InvokeAI/assets/7254508/d0006ba7-2ed4-4044-a1bc-ca9a99df9397">
## Related Tickets & Documents
<!--
For pull requests that relate or
close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [x] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
This is a relatively stable release that corrects the urgent windows
install and model manager problems in 3.0.1. It still has two known
bugs:
1. Many inpainting models are not loading correctly.
2. The merge script is failing to start.
- Remove FaceMask and add link FaceTools repository, which includes FaceMask, FaceOff, and FacePlace
- Move Ideal Size up from under the template entry
## What type of PR is this? (check all applicable)
- [ X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [X] Yes - bug discovered by jpphoto
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ X] Not needed
## Description
The user can customize the location of the models directory by setting
configuration variable `models_dir`. However, the model manager and the
TUI installer were all treating model relative paths as relative to the
invokeai root rather than the designated models directory. This has been
fixed by changing path resolution calls from using `config.root_path` to
`config.models_path`
Unfortunately there were many instances that needed replacement, so this
needs a bit of functional testing - try adding models, removing models,
renaming them, converting checkpoints, etc.
## What type of PR is this? (check all applicable)
- [ X] Optimization
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X ] Yes
- [ ] No
## Description
This PR does two things:
1. if the environment variable INVOKEAI_ROOT is defined at install time,
the zipfile installer will default to its value when asking the user
where to install the software
2. If the user has more than 72 models of any type installed, then the
list will be truncated in the TUI and the user given a warning. Anything
larger than this number of models causes the vertical space to overflow.
The only effect of truncation is that the user will not be able to see
and delete the models that were truncated. The message advises the user
to go to the Web Model Manager interface in this event.
## What type of PR is this? (check all applicable)
- [X ] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ X] No
## Description
This PR fixes several issues with the 3.0.0 conversion script:
- Handles checkpoint variants that don't put dots between fields in the
long state dict key names
- Handles ema, non-ema, pruned and non-pruned ckpts
- Does not add safety checker to converted checkpoints
- Respects precision of original checkpoint file
## What type of PR is this? (check all applicable)
- [ X] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [X] Not needed
## Description
Windows users have been getting a lot of OSErrors while installing 3.0.1
during the pip dependency installation phase. Generally the errors have
involved just two packages, pydantic and numpy. Looking at the install
logs, I see that both of these packages are first installed under one
version number by a dependency, and then uninstalled and replaced by a
slightly different version specified in invoke's `pyproject.toml`. I
think this is the problem - maybe the earlier package is not completely
closed before it is uninstalled and reinstalled.
This PR relaxes pinning of numpy and pydantic in `pyproject.toml`.
Everything seems to install and run properly. Hopefully it will address
the windows install bug as well.
## What type of PR is this? (check all applicable)
- [x] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
- SDXL Metadata was not being retrieved. This PR fixes it.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because:
not yet, making pr to show
## Have you updated relevant documentation?
- [ ] Yes
- [ ] No
## Description
Temp Change Node String input to a textbox, to allow easier input of
prompts and larger strings, it works for me but please tell me if I did
it wrong and if the size is ok
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: minor fix, let me know your thoughts
## Have you updated all relevant documentation?
- [x] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue # https://github.com/invoke-ai/InvokeAI/issues/4017
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : Requires mps device
## [optional] Are there any post deployment tasks we need to perform?
Please test on an MPS (M1/M2) device.
Relevant code causing the error in #401701b6ec21fa/src/diffusers/schedulers/scheduling_euler_discrete.py (L263C3-L268C75)
```
self.sigmas = torch.from_numpy(sigmas).to(device=device)
if str(device).startswith("mps"):
# mps does not support float64
self.timesteps = torch.from_numpy(timesteps).to(device, dtype=torch.float32)
else:
self.timesteps = torch.from_numpy(timesteps).to(device=device)
```
## What type of PR is this? (check all applicable)
- [x] Bug Fix
## Description
- Fix SDXL Concat Link animation not considering the fact that prompt
boxes can be resized.
- Also fixed a minor issue where the overlaying animation box would
block the prompt input resize slightly. Should be good now.
## What type of PR is this? (check all applicable)
- [X ] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
## Have you updated all relevant documentation?
- [X ] Yes
## Description
Added solutions for installation issues related to large SDXL files and
Windows dependency glitches.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
Making the prompt area styling match across all tabs / models and move
all prompt related components into a parent components for quick add.
Cherry picked stuff from the Styles PR coz we ain't gonna merge that.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
- make the `SDXLConcatLink` icon match existing colors in light mode
- make the link toggle button accent color when active (its not super obvious but at least there is *some* visual difference for the button)
## What type of PR is this? (check all applicable)
- [ X] Feature
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
## Have you updated all relevant documentation?
- [ X] Yes - this makes invokeai behave the way it is described in
LOGGING.md
## Description
Prior to this PR, the uvicorn embedded web server did all its logging
independently of the InvokeAI logging infrastructure, and none of the
command-line or `invokeai.yaml` configuration directives, such as
`log_level` had any effect on its output. This PR replaces the uvicorn
logger with InvokeAI's, simultaneously creating a more uniform output
experience, as well as a unified way to control the amount and
destination of the logs.
Here's what we used to see at startup:
```
[2023-07-27 07:29:48,027]::[InvokeAI]::INFO --> InvokeAI version 3.0.1rc2
[2023-07-27 07:29:48,027]::[InvokeAI]::INFO --> Root directory = /home/lstein/invokeai-main
[2023-07-27 07:29:48,028]::[InvokeAI]::INFO --> GPU device = cuda NVIDIA GeForce RTX 4070
[2023-07-27 07:29:48,040]::[InvokeAI]::INFO --> Scanning /home/lstein/invokeai-main/models for new models
[2023-07-27 07:29:49,263]::[InvokeAI]::INFO --> Scanned 22 files and directories, imported 10 models
[2023-07-27 07:29:49,271]::[InvokeAI]::INFO --> Model manager service initialized
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:9090 (Press CTRL+C to quit)
INFO: 127.0.0.1:44404 - "GET /socket.io/?EIO=4&transport=polling&t=OcN7Pvd HTTP/1.1" 200 OK
INFO: 127.0.0.1:44404 - "POST /socket.io/?EIO=4&transport=polling&t=OcN7Pw6&sid=SB-NsBKLSrW7YtM0AAAA HTTP/1.1" 200 OK
INFO: ('127.0.0.1', 44418) - "WebSocket /socket.io/?EIO=4&transport=websocket&sid=SB-NsBKLSrW7YtM0AAAA" [accepted]
INFO: connection open
INFO: 127.0.0.1:44430 - "GET /socket.io/?EIO=4&transport=polling&t=OcN7Pw9&sid=SB-NsBKLSrW7YtM0AAAA HTTP/1.1" 200 OK
INFO: 127.0.0.1:44404 - "GET /socket.io/?EIO=4&transport=polling&t=OcN7PwU&sid=SB-NsBKLSrW7YtM0AAAA HTTP/1.1" 200 OK
INFO: 127.0.0.1:44404 - "GET /api/v1/images/?is_intermediate=true HTTP/1.1" 200 OK
INFO: 127.0.0.1:43448 - "GET / HTTP/1.1" 200 OK
INFO: connection closed
INFO: 127.0.0.1:43448 - "GET /assets/index-5a784cdd.js HTTP/1.1" 200 OK
INFO: 127.0.0.1:43458 - "GET /assets/favicon-0d253ced.ico HTTP/1.1" 304 Not Modified
INFO: 127.0.0.1:43448 - "GET /locales/en.json HTTP/1.1" 200 OK
```
And here's what we see with the new implementation:
```
[2023-07-27 12:05:28,810]::[uvicorn.error]::INFO --> Started server process [875161]
[2023-07-27 12:05:28,810]::[uvicorn.error]::INFO --> Waiting for application startup.
[2023-07-27 12:05:28,810]::[InvokeAI]::INFO --> InvokeAI version 3.0.1rc2
[2023-07-27 12:05:28,810]::[InvokeAI]::INFO --> Root directory = /home/lstein/invokeai-main
[2023-07-27 12:05:28,811]::[InvokeAI]::INFO --> GPU device = cuda NVIDIA GeForce RTX 4070
[2023-07-27 12:05:28,823]::[InvokeAI]::INFO --> Scanning /home/lstein/invokeai-main/models for new models
[2023-07-27 12:05:29,970]::[InvokeAI]::INFO --> Scanned 22 files and directories, imported 10 models
[2023-07-27 12:05:29,977]::[InvokeAI]::INFO --> Model manager service initialized
[2023-07-27 12:05:29,980]::[uvicorn.error]::INFO --> Application startup complete.
[2023-07-27 12:05:29,981]::[uvicorn.error]::INFO --> Uvicorn running on http://127.0.0.1:9090 (Press CTRL+C to quit)
[2023-07-27 12:05:32,140]::[uvicorn.access]::INFO --> 127.0.0.1:45236 - "GET /socket.io/?EIO=4&transport=polling&t=OcO6ILb HTTP/1.1" 200
[2023-07-27 12:05:32,142]::[uvicorn.access]::INFO --> 127.0.0.1:45248 - "GET /socket.io/?EIO=4&transport=polling&t=OcO6ILb HTTP/1.1" 200
[2023-07-27 12:05:32,154]::[uvicorn.access]::INFO --> 127.0.0.1:45236 - "POST /socket.io/?EIO=4&transport=polling&t=OcO6ILr&sid=13O4-5uLx5eP-NuqAAAA HTTP/1.1" 200
[2023-07-27 12:05:32,168]::[uvicorn.access]::INFO --> 127.0.0.1:45252 - "POST /socket.io/?EIO=4&transport=polling&t=OcO6IM0&sid=0KRqxmh7JLc8t7wZAAAB HTTP/1.1" 200
[2023-07-27 12:05:32,171]::[uvicorn.error]::INFO --> ('127.0.0.1', 45264) - "WebSocket /socket.io/?EIO=4&transport=websocket&sid=0KRqxmh7JLc8t7wZAAAB" [accepted]
[2023-07-27 12:05:32,172]::[uvicorn.error]::INFO --> connection open
[2023-07-27 12:05:32,174]::[uvicorn.access]::INFO --> 127.0.0.1:45276 - "GET /socket.io/?EIO=4&transport=polling&t=OcO6IM3&sid=0KRqxmh7JLc8t7wZAAAB HTTP/1.1" 200
```
You can also divert everything to a file with a `invokeai.yaml` entry
like this:
```
Logging:
log_handlers:
- file=/home/lstein/invokeai/logs/access_log
log_format: plain
log_level: info
```
This works with syslog and other log handlers as well.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
https://github.com/huggingface/diffusers/releases/tag/v0.19.0
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X ] Yes
- [ ] No
## Description
This updates InvokeAI's pyproject.toml to the minimum library versions
needed to support Python 3.11. It updates the installer to find and
allow for 3.11, and the documentation.
Between 3.10 and 3.11 there was a change to the handling of `enum`
interpolation into strings that caused the model manager to break. I
think I have fixed the places where this was a problem, but there may be
other instances in which this will cause problems. Please be alert for
errors involving `ModelType` or `BaseModelType`.
I also took the opportunity to add a `SilenceWarnings()` context to the
t2i and i2i invocations. This quenches nags from diffusers about the
HuggingFace NSFW library.
I have tested basic functionality (t2i, i2i, inpaint, lora, controlnet,
nodes) on 3.10 and 3.11 and all seems good. Please test more
extensively!
## Added/updated tests?
- [ X ] Yes - existing tests run to completion
- [ ] No
## [optional] Are there any post deployment tasks we need to perform?
Should be a drop-in replacement.
* add upper bound for minWidth to prevent crash with cypress
* add fallback so UI doesnt crash when backend isnt running
---------
Co-authored-by: Mary Hipp <maryhipp@Marys-MacBook-Air.local>
when multiple python versions are installed with `pyenv`, the executable
(shim) exists, but returns an error when trying to run it
unless activated with `pyenv`. This commit ensures the python
executable is usable.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature (dev feature and reformatting)
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
Introducing black to the code base as a first step towards this:
https://github.com/invoke-ai/InvokeAI/discussions/3721
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : Not applicable
## [optional] Are there any post deployment tasks we need to perform?
All active branches will be affected by this and will need to be
updated.
This PR adds a new github workflow for black as well as config for
pre-commit hooks to those who wish to use it
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [X ] Not needed
## Description
This bugfix enables InvokeAI to convert sd-1, sd-2 and sdxl base model
checkpoints (.safetensors) to diffusers.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ X] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [X ] No
## Description
This PR causes the installer to install, by default, the fine-tuned
SDXL-1.0 VAE located at
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix.
Although this VAE is supposed to run at fp16 resolution, currently it
only works in InvokeAI at fp32. However, because it is a fine tune, it
may have fewer of the watermark-related artifacts that we see with the
SDXL-1.0 VAE.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ X] Not necessary
## Description
When adding new core models to a 3.0.0 root directory needed to support
SDXL, the configure script was (under some conditions) overwriting
models.yaml. This PR corrects the problem.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [X ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X ] Yes
- [ ] No
## Description
I have reworked the console TUIs for the configure and model install
scripts to require much less vertical space. In the event that the
"NEXT" button is still missing and "page 1/2" is displayed, scrolling
beyond the last checkbox will now automatically move to page 2 where the
buttons are displayed. This is not ideal, but will no longer block user
completely.
If users continue to have problems after this, I'll get rid of the TUI
altogether and replace with a web form.
## Added/updated tests?
- [ ] Yes
- [X ] No : not needed
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [X ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X ] No, because they trust me
## Have you updated all relevant documentation?
- [ X] Yes
- [ ] No
## Description
* Added the RAIL++ license for SDXL
* Updated configure script with URLs for both the original RAIL-M and
RAIL++ licenses
* Added invisible watermark documentation and renamed doc file
* Updated documentation for installation
* Updated documentation on settings in invokeai.yaml
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
Metadata was not getting saved coz the accumulator was not plugged in if
watermark or nsfw nodes were turned off.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ x] No, because there was no time!
## Have you updated all relevant documentation?
- [ ] Yes
- [X ] No
## Description
Hotfix for issue of SD1 and SD2 legacy safetensors models not converting
in 3.0.1rc1.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [X ] Yes
- [] No
## Description
This PR adds NSFW checker and invisible watermark fields. The NSFW
checker takes an image input and produces an image output. If NSFW
content is detected, the output image will be blurred and a "caution"
icon pasted into its upper left corner. A boolean `active` field
controls whether the checker is active. If turned off it simply returns
a copy of the image.
The invisible watermark node adds an invisible text to the image,
defaulting to "InvokeAI". To decode the watermark use the
`invisible-watermark` command, which is part of the
`invisible-watermark` library:
```
$ invisible-watermark -v -a decode -t bytes -m dwtDct -l 64 ./bluebird-watermark.png
decode time ms: 14.129877090454102
InvokeAI
```
Note that the `-l` (length) argument is mandatory. It is set to 64 here
because the watermark `InvokeAI` is 8 bytes/64 bits long. The length
must match in order for the watermark to be decoded correctly.
Both nodes are now incorporated into the linear Text2Image and
Image2Image UIs, including the canvas. They are not implemented for
inpaint currently.
The nodes can be disabled with configuration options:
```
invisible_watermark: false
nsfw_checker: false
```
or at launch time with `--no-invisible_watermark` and
`--no-nsfw_checker`.
feat(ui) use `as` for menuitem links
I had requested this be done with the chakra `Link` component, but actually using `as` is correct according to the docs. For other components, you are supposed to use `Link` but looks like `MenuItem` has this built in.
Fixed in all places where we use it.
Also:
- fix github icon
- give menu hamburger button padding
- add menu motion props so it animates the same as other menus
feat(ui): restore ColorModeButton
@maryhipp
chore(ui): lint
feat(ui): remove colormodebutton again
sry
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ X] No - not yet WIP
## Description
This PR adds support for loading and converting checkpoint-format
ControlNet and SDXL models. The SDXL and SDXL-refiner model conversions
are working; however saving the unet in safetensors format leads to
corrupted model files, so currently is saving in .bin format (after
scanning the input model).
ControlNet conversion seems to be working but needs further testing.
To use this PR, you will need to copy the files
`invokeai/configs/stable-diffusion/sd_xl_base.yaml` and
`invokeai/configs/stable-diffusion/sd_xl_refiner.yaml` into
`INVOKEAI/configs/stable-diffusion`. You will also need to run
`invokeai-configure --yes --skip-sd` in order to install additional core
model files needed by the converter.
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
- Update the Aspect Ratio tags to show the aspect ratio values rather
than Wide / Square and etc.
- Updated Lora Input to take values between -50 and 50 coz I found some
LoRA that are actually trained to work until -25 and +15 too. So these
input caps should mostly suffice. If there's ever a LoRA that goes
bonkers on that, we can change it.
- Fixed LoRA's being sorted the wrong way in Lora Select.
- Fixed Embeddings being sorted the wrong way in Embedding Select.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
- add `addNSFWCheckerToGraph` and `addWatermarkerToGraph` functions
- use them in all linear graph creation
- add state & toggles to settings modal to enable these
- trigger queries for app config on socket connect
- disable the nsfw/watermark booleans if we get the app config and they are not available
## What type of PR is this? (check all applicable)
- [x] Feature
## Have you discussed this change with the InvokeAI team?
- [x] Yes
## Description
This PR adds support for SDXL Models in the Linear UI
### DONE
- SDXL Base Text To Image Support
- SDXL Base Image To Image Support
- SDXL Refiner Support
- SDXL Relevant UI
## [optional] Are there any post deployment tasks we need to perform?
Double check to ensure nothing major changed with 1.0 -- In any case
those changes would be backend related mostly. If Refiner is scrapped
for 1.0 models, then we simply disable the Refiner Graph.
Rolled back the earlier split of the refiner model query.
Now, when you use `useGetMainModelsQuery()`, you must provide it an array of base model types.
They are provided as constants for simplicity:
- ALL_BASE_MODELS
- NON_REFINER_BASE_MODELS
- REFINER_BASE_MODELS
Opted to just use args for the hook instead of wrapping the hook in another hook, we can tidy this up later if desired.
We can derive `isRefinerAvailable` from the query result (eg are there any refiner models installed). This is a piece of server state, so by using the list models response directly, we can avoid needing to manually keep the client in sync with the server.
Created a `useIsRefinerAvailable()` hook to return this boolean wherever it is needed.
Also updated the main models & refiner models endpoints to only return the appropriate models. Now we don't need to filter the data on these endpoints.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [X] No
## Description
Updated script to close stale issues with the newest version of the
actions/stale
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [X] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
Not sure how this script gets kicked off
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [x] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: This is a minor fix that I happened upon while
reading
## Have you updated all relevant documentation?
- [x] Yes
- [ ] No
## Description
Within the `mkdocs.yml` file, there's a typo where `Model Merging` is
spelled as `Model Mergeing`. I also found some unnecessary white space
that I removed.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : Not big enough of a change to require tests (unless it is)
## [optional] Are there any post deployment tasks we need to perform?
Might need to re-run the yml file for docs to regenerate, but I'm hardly
familiar with the codebase so 🤷
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: n/a
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No n/a
## Description
Add a generation mode indicator to canvas.
- use the existing logic to determine if generation is txt2img, img2img,
inpaint or outpaint
- technically `outpaint` and `inpaint` are the same, just display
"Inpaint" if its either
- debounce this by 1s to prevent jank
I was going to disable controlnet conditionally when the mode is inpaint
but that involves a lot of fiddly changes to the controlnet UI
components. Instead, I'm hoping we can get inpaint moved over to latents
by next release, at which point controlnet will work.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
https://github.com/invoke-ai/InvokeAI/assets/4822129/87464ae9-4136-4367-b992-e243ff0d05b4
## Added/updated tests?
- [ ] Yes
- [x] No : n/a
## [optional] Are there any post deployment tasks we need to perform?
n/a
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No, n/a
## Description
When a queue item is popped for processing, we need to retrieve its
session from the DB. Pydantic serializes the graph at this stage.
It's possible for a graph to have been made invalid during the graph
preparation stage (e.g. an ancestor node executes, and its output is not
valid for its successor node's input field).
When this occurs, the session in the DB will fail validation, but we
don't have a chance to find out until it is retrieved and parsed by
pydantic.
This logic was previously not wrapped in any exception handling.
Just after retrieving a session, we retrieve the specific invocation to
execute from the session. It's possible that this could also have some
sort of error, though it should be impossible for it to be a pydantic
validation error (that would have been caught during session
validation). There was also no exception handling here.
When either of these processes fail, the processor gets soft-locked
because the processor's cleanup logic is never run. (I didn't dig deeper
into exactly what cleanup is not happening, because the fix is to just
handle the exceptions.)
This PR adds exception handling to both the session retrieval and node
retrieval and events for each: `session_retrieval_error` and
`invocation_retrieval_error`.
These events are caught and displayed in the UI as toasts, along with
the type of the python exception (e.g. `Validation Error`). The events
are also logged to the browser console.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
Closes#3860 , #3412
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
Create an valid graph that will become invalid during execution. Here's
an example:
This is valid before execution, but the `width` field of the `Noise`
node will end up with an invalid value (`0`). Previously, this would
soft-lock the app and you'd have to restart it.
Now, with this graph, you will get an error toast, and the app will not
get locked up.
## Added/updated tests?
- [x] Yes (ish)
- [ ] No
@Kyle0654 @brandonrising
It seems because the processor runs in its own thread, `pytest` cannot
catch exceptions raised in the processor.
I added a test that does work, insofar as it does recreate the issue.
But, because the exception occurs in a separate thread, the test doesn't
see it. The result is that the test passes even without the fix.
So when running the test, we see the exception:
```py
Exception in thread invoker_processor:
Traceback (most recent call last):
File "/usr/lib/python3.10/threading.py", line 1016, in _bootstrap_inner
self.run()
File "/usr/lib/python3.10/threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "/home/bat/Documents/Code/InvokeAI/invokeai/app/services/processor.py", line 50, in __process
self.__invoker.services.graph_execution_manager.get(
File "/home/bat/Documents/Code/InvokeAI/invokeai/app/services/sqlite.py", line 79, in get
return self._parse_item(result[0])
File "/home/bat/Documents/Code/InvokeAI/invokeai/app/services/sqlite.py", line 52, in _parse_item
return parse_raw_as(item_type, item)
File "pydantic/tools.py", line 82, in pydantic.tools.parse_raw_as
File "pydantic/tools.py", line 38, in pydantic.tools.parse_obj_as
File "pydantic/main.py", line 341, in pydantic.main.BaseModel.__init__
```
But `pytest` doesn't actually see it as an exception. Not sure how to
fix this, it's a bit beyond me.
## [optional] Are there any post deployment tasks we need to perform?
nope don't think so
## What type of PR is this? (check all applicable)
- [x] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
`search_for_models` is explicitly typed as taking a singular `Path` but
was given a list because some later function in the stack expects a
list. Fixed that to be compatible with the paths. This is the only use
of that function.
The `list()` call is unrelated but removes a type warning since it's
supposed to return a list, not a set. I can revert it if requested.
This was found through pylance type errors. Go types!
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
This import is missing and used later in the file.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No: n/a
## Description
At some point I typo'd this and set the max seed to signed int32 max. It
should be *un*signed int32 max.
This restored the seed range to what it was in v2.3.
Also fixed a bug in the Noise node which resulted in the max valid seed
being one less than intended.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issues
#2843 is against v2.3 and increases the range of valid seeds
substantially. Maybe we can explore this in the future but as of v3.0,
we use numpy for a RNG in a few places, and it maxes out at the max
`uint32`. I will close this PR as this supersedes it.
- Closes#3866
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
You should be able to use seeds up to and including `4294967295`.
## Added/updated tests?
- [ ] Yes
- [x] No : don't think we have any relevant tests
## [optional] Are there any post deployment tasks we need to perform?
nope!
At some point I typo'd this and set the max seed to signed int32 max. It should be *un*signed int32 max.
This restored the seed range to what it was in v2.3.
## What type of PR is this? (check all applicable)
- [x] Bug Fix
## Have you discussed this change with the InvokeAI team?
- [x] Yes, we feel very passionate about this.
## Description
Uploading an incorrect JSON file to the Node Editor would crash the app.
While this is a much larger problem that we will tackle while refining
the Node Editor, this is a fix that should address 99% of the cases out
there.
When saving an InvokeAI node graph, there are three primary keys.
1. `nodes` - which has all the node related data.
2. `edges` - which has all the edges related data
3. `viewport` - which has all the viewport related data.
So when we load back the JSON, we now check if all three of these keys
exist in the retrieved JSON object. While the `viewport` itself is not a
mandatory key to repopulate the graph, checking for it will allow us to
treat it as an additional check to ensure that the graph was saved from
InvokeAI.
As a result ...
- If you upload an invalid JSON file, the app now warns you that the
JSON is invalid.
- If you upload a JSON of a graph editor that is not InvokeAI, it simply
warns you that you are uploading a non InvokeAI graph.
So effectively, you should not be able to load any graph that is not
generated by ReactFlow.
Here are the edge cases:
- What happens if a user maintains the above key structure but tampers
with the data inside them? Well tested it. Turns out because we validate
and build the graph based on the JSON data, if you tamper with any data
that is needed to rebuild that node, it simply will skip that and load
the rest of the graph with valid data.
- What happens if a user uploads a graph that was made by some other
random ReactFlow app? Well, same as above. Because we do not have to
parse that in our setup, it simply will skip it and only display what
are setup to do.
I think that just about covers 99% of the cases where this could go
wrong. If there's any other edges cases, can add checks if need be. But
can't think of any at the moment.
## Related Tickets & Documents
### Closes
- #3893
- #3881
## [optional] Are there any post deployment tasks we need to perform?
Yes. Making @psychedelicious a little bit happier. :P
- use the existing logic to determine if generation is txt2img, img2img, inpaint or outpaint
- technically `outpaint` and `inpaint` are the same, just display
"Inpaint" if its either
- debounce this by 1s to prevent jank
When a queue item is popped for processing, we need to retrieve its session from the DB. Pydantic serializes the graph at this stage.
It's possible for a graph to have been made invalid during the graph preparation stage (e.g. an ancestor node executes, and its output is not valid for its successor node's input field).
When this occurs, the session in the DB will fail validation, but we don't have a chance to find out until it is retrieved and parsed by pydantic.
This logic was previously not wrapped in any exception handling.
Just after retrieving a session, we retrieve the specific invocation to execute from the session. It's possible that this could also have some sort of error, though it should be impossible for it to be a pydantic validation error (that would have been caught during session validation). There was also no exception handling here.
When either of these processes fail, the processor gets soft-locked because the processor's cleanup logic is never run. (I didn't dig deeper into exactly what cleanup is not happening, because the fix is to just handle the exceptions.)
This PR adds exception handling to both the session retrieval and node retrieval and events for each: `session_retrieval_error` and `invocation_retrieval_error`.
These events are caught and displayed in the UI as toasts, along with the type of the python exception (e.g. `Validation Error`). The events are also logged to the browser console.
## What type of PR is this? (check all applicable)
- [x] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: n/a
## Have you updated all relevant documentation?
- [ ] Yes
- [x] No n/a
## Description
Big cleanup:
- improve & simplify the app logging
- resolve all TS issues
- resolve all circular dependencies
- fix all lint/format issues
## QA Instructions, Screenshots, Recordings
`yarn lint` passes:

<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : n/a
## [optional] Are there any post deployment tasks we need to perform?
bask in the glory of what *should* be a fully-passing frontend lint on
this PR
Added the Ideal Size node
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because: It's a community node addition
## Have you updated all relevant documentation?
- [X] Yes
- [ ] No
## Description
Added a reference to my community node that calculates the ideal size
for initial latent generation that avoids duplication. This is the logic
that was present in 2.3.5's first pass of high-res optimization.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [X] No : This is a documentation change that references my community
node.
## [optional] Are there any post deployment tasks we need to perform?
Add Face Mask to communityNodes.md
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [x] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Have you updated all relevant documentation?
- [x] Yes
- [ ] No
## Description
Add Face Mask to communituNodes.md list.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [x] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: just updated docs to try to help lead new users to
installs a little easier
## Have you updated relevant documentation?
- [x] Yes
- [ ] No
## Description
Some minor docs tweaks
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [x] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
Revised boards logic and UI
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue # discord convos
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : n/a
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Description
On mps generating images with resolution above ~1536x1536 results in
"fried" output. Main problem that such resolution results in tensors in
size more then 4gb. Looks like that some of mps internals can't handle
properly this, so to mitigate it I break attention calculation in
chunks.
## QA Instructions, Screenshots, Recordings
Example of bad output:

## What type of PR is this? (check all applicable)
- [ X] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Description
This is a WIP to collect documentation enhancements and other polish
prior to final 3.0.0 release. Minor bug fixes may go in here if
non-controversial. It should be merged into main prior to the final
release.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [ ] No, because:
## Have you updated relevant documentation?
- [ ] Yes
- [ ] No
## Description
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [x] Bug Fix
## Desc
Fixes a bug where the board name is not displayed in the header if there
are no images in it.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [x] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [x] Yes
- [ ] No, because:
## Description
Add progress preview for sdxl generation nodes
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X ] Yes
- [ ] No, because:
## Have you updated relevant documentation?
- [ X] Yes (swagger)
- [ ] No
## Description
This add new routes for getting and setting the command line console
logging level.
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [X] Feature
- [ ] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
- [ ] Community Node Submission
## Have you discussed this change with the InvokeAI team?
- [X] Yes Discussed with @hipsterusername yesterday
- [ ] No, because:
## Have you updated relevant documentation?
- [ ] Yes
- [X] No Not yet (but change to default ControlNet resizing doesn't
require any user documentation)
## Description
This PR adds resize modes (just_resize, crop_resize, fill_resize) to
InvokeAI's ControlNet node. The implementation is largely based on
lllyasviel's, which includes a high quality resizer specifically
intended to handle common ControlNet preprocessor outputs, such as
binary (black/white) images, grayscale images, and binary or grayscale
thin lines. Previously the InvokeAI ControlNet implementation only did a
simple resize with independent x/y scaling to match noise latent.
### "just_resize" mode (the default setting)
With the new implementation, using the default "just_resize" mode,
ControlNet images are still resized with independent x/y scaling to
match the noise latent resolution, but with the high quality resizer. As
a result, images generated in InvokeAI now look much closer to
counterparts generated via sd-webui-controlnet. See example below. All
inference runs are using prompt="old man", same ControlNet canny edge
detection preprocessor and model and control image, identical other
parameters except for control_mode. The top row is previous simple
resize implementation, the bottom row is with new high quality resizer
and "just_resize" mode. Control_mode is: left="balanced", middle="more
prompt", right="more control". The high quality resize images are
identical (at least by eye) to output from sd-webui-controlnet with same
settings.

## "crop_resize" and "fill_resize" modes
The other two resize modes are "crop_resize" and "fill_resize". Whereas
"just_resize" ignores any aspect ratio mismatch between the ControlNet
image and the noise latent, these other modes preserve the aspect ratio
of the ControlNet image. The "crop_resize" mode does this by cropping
the image, and the "fill_resize" option does this by expanding the image
(adding fill pixels). See example below. In this case all inference runs
are using prompt="old man", the ControlNet Midas depth detection
preprocessor and depth model, same control image of size 512x512,
control_mode="balanced", and identical other parameters except for
resize_mode and noise latent dimensions. For top row noise latent size
is 768x512, and for bottom row noise latent size is 512x768. Resize_mode
is: left="just_resize", middle="crop_resize", right="fill_resize"

## Are there any post deployment tasks we need to perform?
To use "just_resize" mode in linear UI, no post deployment work is
needed. The default is switched from old resizer to new high quality
resizer.
To use "just_resize", "crop_resize", and "fill_resize" modes in node UI,
no post deployment work is needed. There is also an additional option
"just_resize_simple" that uses old resizer, mainly left in for testing
and for anyone curious to see the difference.
To use "crop_resize" and "fill_resize" in linear UI, there will need to
be some work to incorporate choice of three modes in ControlNet UI
(probably best to not expose "just_resize_simple" in linear UI, it just
confuses things).
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [ X] Yes
- [ ] No, because:
## Description
This changes the "sync" route from a GET to POST method, in keeping with
the Representational Existential(?) State Transfer (REST) protocol.
* feat(ui): enhance clear intermediates feature
- retrieve the # of intermediates using a new query (just uses list images endpoint w/ limit of 0)
- display the count in the UI
- add types for clearIntermediates mutation
- minor styling and verbiage changes
* feat(ui): remove unused settings option for guides
* feat(ui): use solid badge variant
consistent with the rest of the usage of badges
* feat(ui): update board ctx menu, add board auto-add
- add context menu to system boards - only open is select board. did this so that you dont think its broken when you click it
- add auto-add board. you can right click a user board to enable it for auto-add, or use the gallery settings popover to select it. the invoke button has a tooltip on a short delay to remind you that you have auto-add enabled
- made useBoardName hook, provide it a board id and it gets your the board name
- removed `boardIdToAdTo` state & logic, updated workflows to auto-switch and auto-add on image generation
* fix(ui): clear controlnet when clearing intermediates
* feat: Make Add Board icon a button
* feat(db, api): clear intermediates now clears all of them
* feat(ui): make reset webui text subtext style
* feat(ui): board name change submits on blur
---------
Co-authored-by: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [ ] Bug Fix
- [ ] Optimization
- [x] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [x] No, because: documentation update that needs review from the team
before going live
## Description
I updated the contribution guidelines, adding more structure and a
getting started guide. Also re-organized the tabs to be in the order of
most commonly used.
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
run `mkdocs serve` to check it out
## Added/updated tests?
- [ ] Yes
- [X ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [X] Yes
- [ ] No, because:
## Description
ImageToLatentsInvocation defaulted to float16 rather than detect the
requested precision from configs.
This caused an exception to be raised on systems that don't support
float16 (e.g. CPU).
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current
pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [x] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
* feat(ui): migrate listImages to RTK query using createEntityAdapter
- see comments in `endpoints/images.ts` for explanation of the caching
- so far, only manually updating `all` images when new image is generated. no other manual cache updates are implemented, but will be needed.
- fixed some weirdness with loading state components (like the spinners in gallery)
- added `useThumbnailFallback` for `IAIDndImage`, this displays the tiny webp thumbnail while the full-size images load
- comment out some old thunk related stuff in gallerySlice, which is no longer needed
* feat(ui): add manual cache updates for board changes (wip)
- update RTK Query caches when adding/removing single image to/from board
- work more on migrating all image-related operations to RTK Query
* update AddImagesToBoardContext so that it works when user uses context menu + modal
* handle case where no image is selected
* get assets working for main list and boards - dnd only
* feat(ui): migrate image uploads to RTK Query
- minor refactor of `ImageUploader` and `useImageUploadButton` hooks, simplify some logic
- style filesystem upload overlay to match existing UI
- replace all old `imageUploaded` thunks with `uploadImage` RTK Query calls, update associated logic including canvas related uploads
- simplify `PostUploadAction`s that only need to display user input
* feat(ui): remove `receivedPageOfImages` thunks
* feat(ui): remove `receivedImageUrls` thunk
* feat(ui): finish removing all images thunks
stuff now broken:
- image usage
- delete board images
- on first load, no image selected
* feat(ui): simplify `updateImage` cache manipulation
- we don't actually ever change categories, so we can remove a lot of logic
* feat(ui): simplify canvas autosave
- instead of using a network request to set the canvas generation as not intermediate, we can just do that in the graph
* feat(ui): simplify & handle edge cases in cache updates
* feat(db, api): support `board_id='none'` for `get_many` images queries
This allows us to get all images that are not on a board.
* chore(ui): regen types
* feat(ui): add `All Assets`, `No Board` boards
Restructure boards:
- `all images` is all images
- `all assets` is all assets
- `no board` is all images/assets without a board set
- user boards may have images and assets
Update caching logic
- much simpler without every board having sub-views of images and assets
- update drag and drop operations for all possible interactions
* chore(ui): regen types
* feat(ui): move download to top of context menu
* feat(ui): improve drop overlay styles
* fix(ui): fix image not selected on first load
- listen for first load of all images board, then select the first image
* feat(ui): refactor board deletion
api changes:
- add route to list all image names for a board. this is required to handle board + image deletion. we need to know every image in the board to determine the image usage across the app. this is fetched only when the delete board and images modal is opened so it's as efficient as it can be.
- update the delete board route to respond with a list of deleted `board_images` and `images`, as image names. this is needed to perform accurate clientside state & cache updates after deleting.
db changes:
- remove unused `board_images` service method to get paginated images dtos for a board. this is now done thru the list images endpoint & images service. needs a small logic change on `images.delete_images_on_board`
ui changes:
- simplify the delete board modal - no context, just minor prop drilling. this is feasible for boards only because the components that need to trigger and manipulate the modal are very close together in the tree
- add cache updates for `deleteBoard` & `deleteBoardAndImages` mutations
- the only thing we cannot do directly is on `deleteBoardAndImages`, update the `No Board` board. we'd need to insert image dtos that we may not have loaded. instead, i am just invalidating the tags for that `listImages` cache. so when you `deleteBoardAndImages`, the `No Board` will re-fetch the initial image limit. i think this is more efficient than e.g. fetching all image dtos to insert then inserting them.
- handle image usage for `deleteBoardAndImages`
- update all (i think/hope) the little bits and pieces in the UI to accomodate these changes
* fix(ui): fix board selection logic
* feat(ui): add delete board modal loading state
* fix(ui): use thumbnails for board cover images
* fix(ui): fix race condition with board selection
when selecting a board that doesn't have any images loaded, we need to wait until the images haveloaded before selecting the first image.
this logic is debounced to ~1000ms.
* feat(ui): name 'No Board' correctly, change icon
* fix(ui): do not cache listAllImageNames query
if we cache it, we can end up with stale image usage during deletion.
we could of course manually update the cache as we are doing elsewhere. but because this is a relatively infrequent network request, i'd like to trade increased cache mgmt complexity here for increased resource usage.
* feat(ui): reduce drag preview opacity, remove border
* fix(ui): fix incorrect queryArg used in `deleteImage` and `updateImage` cache updates
* fix(ui): fix doubled open in new tab
* fix(ui): fix new generations not getting added to 'No Board'
* fix(ui): fix board id not changing on new image when autosave enabled
* fix(ui): context menu when selection is 0
need to revise how context menu is triggered later, when we approach multi select
* fix(ui): fix deleting does not update counts for all images and all assets
* fix(ui): fix all assets board name in boards list collapse button
* fix(ui): ensure we never go under 0 for total board count
* fix(ui): fix text overflow on board names
---------
Co-authored-by: Mary Hipp <maryhipp@Marys-MacBook-Air.local>
* new route to clear intermediates
* UI to clear intermediates from settings modal
* cleanup
* PR feedback
---------
Co-authored-by: Mary Hipp <maryhipp@Marys-MacBook-Air.local>
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [x] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
## Description
In transformers 4.31.0 `text_model.embeddings.position_ids` no longer
part of state_dict.
Fix untested as can't run right now but should be correct. Also need to
check how transformers 4.30.2 works with this fix.
## Related Tickets & Documents
8e5d1619b3 (diff-7f53db5caa73a4cbeb0dca3b396e3d52f30f025b8c48d4daf51eb7abb6e2b949R191)https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module.register_buffer
## QA Instructions, Screenshots, Recordings
```
File "C:\Users\artis\Documents\invokeai\.venv\lib\site-packages\invokeai\backend\model_management\convert_ckpt_to_diffusers.py", line 844, in convert_ldm_clip_checkpoint
text_model.load_state_dict(text_model_dict)
File "C:\Users\artis\Documents\invokeai\.venv\lib\site-packages\torch\nn\modules\module.py", line 2041, in load_state_dict
raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
RuntimeError: Error(s) in loading state_dict for CLIPTextModel:
Unexpected key(s) in state_dict: "text_model.embeddings.position_ids".
```
## What type of PR is this? (check all applicable)
- [ ] Refactor
- [ ] Feature
- [X] Bug Fix
- [ ] Optimization
- [ ] Documentation Update
## Have you discussed this change with the InvokeAI team?
- [ ] Yes
- [X] No, because:
## Description
Fix for
```
File "/home/invokeuser/InvokeAI/invokeai/app/services/processor.py",
line 70, in __process
outputs = invocation.invoke(
File "/home/invokeuser/InvokeAI/invokeai/app/invocations/latent.py",
line 660, in invoke
device=choose_torch_device()
NameError: name 'choose_torch_device' is not defined
```
when using scale latents node
## Related Tickets & Documents
<!--
For pull requests that relate or close an issue, please include them
below.
For example having the text: "closes #1234" would connect the current pull
request to issue 1234. And when we merge the pull request, Github will
automatically close the issue.
-->
- Related Issue #
- Closes #
## QA Instructions, Screenshots, Recordings
<!--
Please provide steps on how to test changes, any hardware or
software specifications as well as any other pertinent information.
-->
## Added/updated tests?
- [ ] Yes
- [ ] No : _please replace this line with details on why tests
have not been included_
## [optional] Are there any post deployment tasks we need to perform?
We're thrilled to have you here and we're excited for you to contribute.
Invoke AI originated as a project built by the community, and that vision carries forward today as we aim to build the best pro-grade tools available. We work together to incorporate the latest in AI/ML research, making these tools available in over 20 languages to artists and creatives around the world as part of our fully permissive OSS project designed for individual users to self-host and use.
Here are some guidelines to help you get started:
### Technical Prerequisites
## Contributing to Invoke AI
Anyone who wishes to contribute to InvokeAI, whether features, bug fixes, code cleanup, testing, code reviews, documentation or translation is very much encouraged to do so.
Front-end: You'll need a working knowledge of React and TypeScript.
To join, just raise your hand on the InvokeAI Discord server (#dev-chat) or the GitHub discussion board.
Back-end: Depending on the scope of your contribution, you may need to know SQLite, FastAPI, Python, and Socketio. Also, a good majority of the backend logic involved in processing images is built in a modular way using a concept called "Nodes", which are isolated functions that carry out individual, discrete operations. This design allows for easy contributions of novel pipelines and capabilities.
### Areas of contribution:
### How to Submit Contributions
#### Development
If you’d like to help with development, please see our [development guide](contribution_guides/development.md). If you’re unfamiliar with contributing to open source projects, there is a tutorial contained within the development guide.
To start contributing, please follow these steps:
#### Nodes
If you’d like to help with development, please see our [nodes contribution guide](/nodes/contributingNodes). If you’re unfamiliar with contributing to open source projects, there is a tutorial contained within the development guide.
1. Familiarize yourself with our roadmap and open projects to see where your skills and interests align. These documents can serve as a source of inspiration.
2. Open a Pull Request (PR) with a clear description of the feature you're adding or the problem you're solving. Make sure your contribution aligns with the project's vision.
3. Adhere to general best practices. This includes assuming interoperability with other nodes, keeping the scope of your functions as small as possible, and organizing your code according to our architecture documents.
#### Documentation
If you’d like to help with documentation, please see our [documentation guide](contribution_guides/documentation.md).
### Types of Contributions We're Looking For
#### Translation
If you'd like to help with translation, please see our[translation guide](contribution_guides/translation.md).
We welcome all contributions that improve the project. Right now, we're especially looking for:
#### Tutorials
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
1. Quality of life (QOL) enhancements on the front-end.
2. New backend capabilities added through nodes.
3. Incorporating additional optimizations from the broader open-source software community.
We hope you enjoy using our software as much as we enjoy creating it, and we hope that some of those of you who are reading this will elect to become part of our contributor community.
### Communication and Decision-making Process
Project maintainers and code owners review PRs to ensure they align with the project's goals. They may provide design or architectural guidance, suggestions on user experience, or provide more significant feedback on the contribution itself. Expect to receive feedback on your submissions, and don't hesitate to ask questions or propose changes.
### Contributors
For more robust discussions, or if you're planning to add capabilities not currently listed on our roadmap, please reach out to us on our Discord server. That way, we can ensure your proposed contribution aligns with the project's direction before you start writing code.
This project is a combined effort of dedicated people from across the world.[Check out the list of all these amazing people](https://invoke-ai.github.io/InvokeAI/other/CONTRIBUTORS/). We thank them for their time, hard work and effort.
### Code of Conduct and Contribution Expectations
### Code of Conduct
We want everyone in our community to have a positive experience. To facilitate this, we've established a code of conduct and a statement of values that we expect all contributors to adhere to. Please take a moment to review these documents—they're essential to maintaining a respectful and inclusive environment.
The InvokeAI community is a welcoming place, and we want your help in maintaining that. Please review our [Code of Conduct](https://github.com/invoke-ai/InvokeAI/blob/main/CODE_OF_CONDUCT.md) to learn more - it's essential to maintaining a respectful and inclusive environment.
By making a contribution to this project, you certify that:
@ -49,6 +48,12 @@ This disclaimer is not a license and does not grant any rights or permissions. Y
This disclaimer is provided "as is" without warranty of any kind, whether expressed or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose, or non-infringement. In no event shall the authors or copyright holders be liable for any claim, damages, or other liability, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the contribution or the use or other dealings in the contribution.
### Support
For support, please use this repository's [GitHub Issues](https://github.com/invoke-ai/InvokeAI/issues), or join the [Discord](https://discord.gg/ZmtBAhwWhy).
Original portions of the software are Copyright (c) 2023 by respective contributors.
---
Remember, your contributions help make this project great. We're excited to see what you'll bring to our community!
| Name | `image`| The variable that will hold our image |
| Type Hint | `Union[ImageField, None]` | The types for our field. Indicates that the image can either be an `ImageField` type or `None` |
| Field | `Field(description="The input image", default=None)` | The image variable is a field which needs a description and a default value that we set to `None`. |
| type_hints | `Dict[str, Literal["integer", "float", "boolean", "string", "enum", "image", "latents", "model", "control"]]` | `type_hint: "model"` provides type hints related to the model like displaying a list of available models |
| tags | `List[str]` | `tags: ['resize', 'image']` will classify your invocation under the tags of resize and image. |
| title | `str` | `title: 'Resize Image` will rename your to this custom title rather than infer from the name of the Invocation class. |
So let us update your `ResizeInvocation` with some extra configuration and see
| Name | `strength` | This field is referred to as `strength` |
| Type Hint | `float` | This field must be of type `float` |
| Field | `Field(default=0.75, gt=0, le=1, description="The strength")` | The default value is `0.75`, the value must be in the range (0,1], and help text will show "The strength" for this field. |
Notice that `image` has type `Union[ImageField,None]`. The `Union` allows this
field to be parsed with `None` as a value, which enables linking to previous
invocations. All fields should either provide a default value or allow `None` as
a value, so that they can be overwritten with a linked output from another
invocation.
The special type `ImageField` is also used here. All images are passed as
`ImageField`, which protects them from pydantic validation errors (since images
only ever come from links).
Finally, note that for all linking, the `type` of the linked fields must match.
If the `name` also matches, then the field can be **automatically linked** to a
previous invocation by name and matching.
### Config
```py
# Schema customisation
classConfig(InvocationConfig):
schema_extra={
"ui":{
"tags":["upscaling","image"],
},
}
```
This is an optional configuration for the invocation. It inherits from
pydantic's model `Config` class, and it used primarily to customize the
autogenerated OpenAPI schema.
The UI relies on the OpenAPI schema in two ways:
- An API client & Typescript types are generated from it. This happens at build
time.
- The node editor parses the schema into a template used by the UI to create the
node editor UI. This parsing happens at runtime.
In this example, a `ui` key has been added to the `schema_extra` dict to provide
some tags for the UI, to facilitate filtering nodes.
See the Schema Generation section below for more information.
If you are looking to help to with a code contribution, InvokeAI uses several different technologies under the hood: Python (Pydantic, FastAPI, diffusers) and Typescript (React, Redux Toolkit, ChakraUI, Mantine, Konva). Familiarity with StableDiffusion and image generation concepts is helpful, but not essential.
For more information, please review our area specific documentation:
If you don't feel ready to make a code contribution yet, no problem! You can also help out in other ways, such as [documentation](documentation.md) or [translation](translation.md).
There are two paths to making a development contribution:
1. Choosing an open issue to address. Open issues can be found in the [Issues](https://github.com/invoke-ai/InvokeAI/issues?q=is%3Aissue+is%3Aopen) section of the InvokeAI repository. These are tagged by the issue type (bug, enhancement, etc.) along with the “good first issues” tag denoting if they are suitable for first time contributors.
1. Additional items can be found on our [roadmap](https://github.com/orgs/invoke-ai/projects/7). The roadmap is organized in terms of priority, and contains features of varying size and complexity. If there is an inflight item you’d like to help with, reach out to the contributor assigned to the item to see how you can help.
2. Opening a new issue or feature to add. **Please make sure you have searched through existing issues before creating new ones.**
*Regardless of what you choose, please post in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord before you start development in order to confirm that the issue or feature is aligned with the current direction of the project. We value our contributors time and effort and want to ensure that no one’s time is being misspent.*
## Best Practices:
* Keep your pull requests small. Smaller pull requests are more likely to be accepted and merged
* Comments! Commenting your code helps reviwers easily understand your contribution
* Use Python and Typescript’s typing systems, and consider using an editor with [LSP](https://microsoft.github.io/language-server-protocol/) support to streamline development
* Make all communications public. This ensure knowledge is shared with the whole community
## **How do I make a contribution?**
Never made an open source contribution before? Wondering how contributions work in our project? Here's a quick rundown!
Before starting these steps, ensure you have your local environment [configured for development](../LOCAL_DEVELOPMENT.md).
1. Find a [good first issue](https://github.com/invoke-ai/InvokeAI/contribute) that you are interested in addressing or a feature that you would like to add. Then, reach out to our team in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord to ensure you are setup for success.
2. Fork the [InvokeAI](https://github.com/invoke-ai/InvokeAI) repository to your GitHub profile. This means that you will have a copy of the repository under**your-GitHub-username/InvokeAI**.
3. Clone the repository to your local machine using:
If you're unfamiliar with using Git through the commandline, [GitHub Desktop](https://desktop.github.com) is a easy-to-use alternative with a UI. You can do all the same steps listed here, but through the interface.
4. Create a new branch for your fix using:
```bash
git checkout -b branch-name-here
```
5. Make the appropriate changes for the issue you are trying to address or the feature that you want to add.
6. Add the file contents of the changed files to the "snapshot" git uses to manage the state of the project, also known as the index:
```bash
git add insert-paths-of-changed-files-here
```
7. Store the contents of the index with a descriptive message.
```bash
git commit -m "Insert a short message of the changes made here"
```
8. Push the changes to the remote repository using
```markdown
git push origin branch-name-here
```
9. Submit a pull request to the **main** branch of the InvokeAI repository.
10. Title the pull request with a short description of the changes made and the issue or bug number associated with your change. For example, you can title an issue like so "Added more log outputting to resolve #1234".
11. In the description of the pull request, explain the changes that you made, any issues you think exist with the pull request you made, and any questions you have for the maintainer. It's OK if your pull request is not perfect (no pull request is), the reviewer will be able to help you fix any problems and improve it!
12. Wait for the pull request to be reviewed by other collaborators.
13. Make changes to the pull request if the reviewer(s) recommend them.
14. Celebrate your success after your pull request is merged!
If you’d like to learn more about contributing to Open Source projects, here is a[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github).
## **Where can I go for help?**
If you need help, you can ask questions in the [#dev-chat](https://discord.com/channels/1020123559063990373/1049495067846524939) channel of the Discord.
For frontend related work, **@pyschedelicious** is the best person to reach out to.
For backend related work, please reach out to **@blessedcoolant**, **@lstein**, **@StAlKeR7779** or **@pyschedelicious**.
## **What does the Code of Conduct mean for me?**
Our [Code of Conduct](CODE_OF_CONDUCT.md) means that you are responsible for treating everyone on the project with respect and courtesy regardless of their identity. If you are the victim of any inappropriate behavior or comments as described in our Code of Conduct, we are here for you and will do the best to ensure that the abuser is reprimanded appropriately, per our code.
The UI is a fairly straightforward Typescript React app, with the Unified Canvas being more complex.
Code is located in`invokeai/frontend/web/`for review.
## Stack
State management is Redux via[Redux Toolkit](https://github.com/reduxjs/redux-toolkit). We lean heavily on RTK:
-`createAsyncThunk`for HTTP requests
-`createEntityAdapter`for fetching images and models
-`createListenerMiddleware`for workflows
The API client and associated types are generated from the OpenAPI schema. See API_CLIENT.md.
Communication with server is a mix of HTTP and[socket.io](https://github.com/socketio/socket.io-client)(with a simple socket.io redux middleware to help).
[Chakra-UI](https://github.com/chakra-ui/chakra-ui)& [Mantine](https://github.com/mantinedev/mantine) for components and styling.
[Konva](https://github.com/konvajs/react-konva)for the canvas, but we are pushing the limits of what is feasible with it (and HTML canvas in general). We plan to rebuild it with[PixiJS](https://github.com/pixijs/pixijs)to take advantage of WebGL's improved raster handling.
[Vite](https://vitejs.dev/)for bundling.
Localisation is via[i18next](https://github.com/i18next/react-i18next), but translation happens on our[Weblate](https://hosted.weblate.org/engage/invokeai/)project. Only the English source strings should be changed on this repo.
## Contributing
Thanks for your interest in contributing to the InvokeAI Web UI!
We encourage you to ping @psychedelicious and @blessedcoolant on[Discord](https://discord.gg/ZmtBAhwWhy)if you want to contribute, just to touch base and ensure your work doesn't conflict with anything else going on. The project is very active.
### Dev Environment
**Setup**
1. Install[node](https://nodejs.org/en/download/). You can confirm node is installed with:
```bash
node --version
```
2. Install [yarn classic](https://classic.yarnpkg.com/lang/en/) and confirm it is installed by running this:
```bash
npm install --global yarn
yarn --version
```
From`invokeai/frontend/web/`run`yarn install`to get everything set up.
Start everything in dev mode:
1. Ensure your virtual environment is running
2. Start the dev server:`yarn dev`
3. Start the InvokeAI Nodes backend:`python scripts/invokeai-web.py # run from the repo root`
4. Point your browser to the dev server address e.g.[http://localhost:5173/](http://localhost:5173/)
### VSCode Remote Dev
We've noticed an intermittent issue with the VSCode Remote Dev port forwarding. If you use this feature of VSCode, you may intermittently click the Invoke button and then get nothing until the request times out. Suggest disabling the IDE's port forwarding feature and doing it manually via SSH:
Documentation is an important part of any open source project. It provides a clear and concise way to communicate how the software works, how to use it, and how to troubleshoot issues. Without proper documentation, it can be difficult for users to understand the purpose and functionality of the project.
## Contributing
All documentation is maintained in the InvokeAI GitHub repository. If you come across documentation that is out of date or incorrect, please submit a pull request with the necessary changes.
When updating or creating documentation, please keep in mind InvokeAI is a tool for everyone, not just those who have familiarity with generative art.
## Help & Questions
Please ping @imic1 or @hipsterusername in the [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
InvokeAI uses[Weblate](https://weblate.org/)for translation. Weblate is a FOSS project providing a scalable translation service. Weblate automates the tedious parts of managing translation of a growing project, and the service is generously provided at no cost to FOSS projects like InvokeAI.
## Contributing
If you'd like to contribute by adding or updating a translation, please visit our[Weblate project](https://hosted.weblate.org/engage/invokeai/). You'll need to sign in with your GitHub account (a number of other accounts are supported, including Google).
Once signed in, select a language and then the Web UI component. From here you can Browse and Translate strings from English to your chosen language. Zen mode offers a simpler translation experience.
Your changes will be attributed to you in the automated PR process; you don't need to do anything else.
## Help & Questions
Please check Weblate's[documentation](https://docs.weblate.org/en/latest/index.html)or ping @Harvestor on [Discord](https://discord.com/channels/1020123559063990373/1049495067846524939) if you have any questions.
## Thanks
Thanks to the InvokeAI community for their efforts to translate the project!
Tutorials help new & existing users expand their abilty to use InvokeAI to the full extent of our features and services.
Currently, we have a set of tutorials available on our [YouTube channel](https://www.youtube.com/@invokeai), but as InvokeAI continues to evolve with new updates, we want to ensure that we are giving our users the resources they need to succeed.
Tutorials can be in the form of videos or article walkthroughs on a subject of your choice. We recommend focusing tutorials on the key image generation methods, or on a specific component within one of the image generation methods.
## Contributing
Please reach out to @imic or @hipsterusername on [Discord](https://discord.gg/ZmtBAhwWhy) to help create tutorials for InvokeAI.
# :material-library-shelves: The Hugging Face Concepts Library and Importing Textual Inversion files
# :material-library-shelves: Textual Inversions and LoRAs
With the advances in research, many new capabilities are available to customize the knowledge and understanding of novel concepts not originally contained in the base model.
@ -64,21 +64,25 @@ select the embedding you'd like to use. This UI has type-ahead support, so you c
## Using LoRAs
LoRA files are models that customize the output of Stable Diffusion image generation.
Larger than embeddings, but much smaller than full models, they augment SD with improved
understanding of subjects and artistic styles.
LoRA files are models that customize the output of Stable Diffusion
image generation. Larger than embeddings, but much smaller than full
models, they augment SD with improved understanding of subjects and
artistic styles.
Unlike TI files, LoRAs do not introduce novel vocabulary into the model's known tokens. Instead,
LoRAs augment the model's weights that are applied to generate imagery. LoRAs may be supplied
with a "trigger" word that they have been explicitly trained on, or may simply apply their
effect without being triggered.
Unlike TI files, LoRAs do not introduce novel vocabulary into the
model's known tokens. Instead, LoRAs augment the model's weights that
are applied to generate imagery. LoRAs may be supplied with a
"trigger" word that they have been explicitly trained on, or may
simply apply their effect without being triggered.
LoRAs are typically stored in .safetensors files, which are the most secure way to store and transmit
these types of weights. You may install any number of `.safetensors` LoRA files simply by copying them into
the `lora` directory of the corresponding InvokeAI models directory (usually `invokeai`
in your home directory). For example, you can simply move a Stable Diffusion 1.5 LoRA file to
the `sd-1/lora` folder.
LoRAs are typically stored in .safetensors files, which are the most
secure way to store and transmit these types of weights. You may
install any number of `.safetensors` LoRA files simply by copying them
into the `autoimport/lora` directory of the corresponding InvokeAI models
directory (usually `invokeai` in your home directory).
To use these when generating, open the LoRA menu item in the options panel, select the LoRAs you want to apply
and ensure that they have the appropriate weight recommended by the model provider. Typically, most LoRAs perform best at a weight of .75-1.
To use these when generating, open the LoRA menu item in the options
panel, select the LoRAs you want to apply and ensure that they have
the appropriate weight recommended by the model provider. Typically,
@ -178,24 +174,28 @@ These configuration settings allow you to enable and disable various InvokeAI fe
| `esrgan` | `true` | Activate the ESRGAN upscaling options|
| `internet_available` | `true` | When a resource is not available locally, try to fetch it via the internet |
| `log_tokenization` | `false` | Before each text2image generation, print a color-coded representation of the prompt to the console; this can help understand why a prompt is not working as expected |
| `nsfw_checker` | `true` | Activate the NSFW checker to blur out risque images |
| `patchmatch` | `true` | Activate the "patchmatch" algorithm for improved inpainting |
| `restore` | `true` | Activate the facial restoration features (DEPRECATED; restoration features will be removed in 3.0.0) |
### Memory/Performance
### Generation
These options tune InvokeAI's memory and performance characteristics.
| Setting | Default Value | Description |
|----------|----------------|--------------|
| `always_use_cpu` | `false` | Use the CPU to generate images, even if a GPU is available |
| `free_gpu_mem` | `false` | Aggressively free up GPU memory after each operation; this will allow you to run in low-VRAM environments with some performance penalties |
| `max_cache_size` | `6` | Amount of CPU RAM (in GB) to reserve for caching models in memory; more cache allows you to keep models in memory and switch among them quickly |
| `max_vram_cache_size` | `2.75` | Amount of GPU VRAM (in GB) to reserve for caching models in VRAM; more cache speeds up generation but reduces the size of the images that can be generated. This can be set to zero to maximize the amount of memory available for generation. |
| `precision` | `auto` | Floating point precision. One of `auto`, `float16` or `float32`. `float16` will consume half the memory of `float32` but produce slightly lower-quality images. The `auto` setting will guess the proper precision based on your video card and operating system |
| `sequential_guidance` | `false` | Calculate guidance in serial rather than in parallel, lowering memory requirements at the cost of some performance loss |
| `xformers_enabled` | `true` | If the x-formers memory-efficient attention module is installed, activate it for better memory usage and generation speed|
| `tiled_decode` | `false` | If true, then during the VAE decoding phase the image will be decoded a section at a time, reducing memory consumption at the cost of a performance hit |
| `sequential_guidance` | `false` | Calculate guidance in serial rather than in parallel, lowering memory requirements at the cost of some performance loss |
| `attention_type` | `auto` | Select the type of attention to use. One of `auto`,`normal`,`xformers`,`sliced`, or `torch-sdp` |
| `attention_slice_size` | `auto` | When "sliced" attention is selected, set the slice size. One of `auto`, `balanced`, `max` or the integers 1-8|
| `force_tiled_decode` | `false` | Force the VAE step to decode in tiles, reducing memory consumption at the cost of performance |
### Device
These options configure the generation execution device.
| `device` | `auto` | Preferred execution device. One of `auto`, `cpu`, `cuda`, `cuda:1`, `mps`. `auto` will choose the device depending on the hardware platform and the installed torch capabilities. |
| `precision` | `auto` | Floating point precision. One of `auto`, `float16` or `float32`. `float16` will consume half the memory of `float32` but produce slightly lower-quality images. The `auto` setting will guess the proper precision based on your video card and operating system |
ControlNet is a powerful set of features developed by the open-source community (notably, Stanford researcher [**@ilyasviel**](https://github.com/lllyasviel)) that allows you to apply a secondary neural network model to your image generation process in Invoke.
ControlNet is a powerful set of features developed by the open-source
community (notably, Stanford researcher
[**@ilyasviel**](https://github.com/lllyasviel)) that allows you to
apply a secondary neural network model to your image generation
process in Invoke.
With ControlNet, you can get more control over the output of your image generation, providing you with a way to direct the network towards generating images that better fit your desired style or outcome.
With ControlNet, you can get more control over the output of your
image generation, providing you with a way to direct the network
towards generating images that better fit your desired style or
outcome.
### How it works
ControlNet works by analyzing an input image, pre-processing that image to identify relevant information that can be interpreted by each specific ControlNet model, and then inserting that control information into the generation process. This can be used to adjust the style, composition, or other aspects of the image to better achieve a specific result.
ControlNet works by analyzing an input image, pre-processing that
image to identify relevant information that can be interpreted by each
specific ControlNet model, and then inserting that control information
into the generation process. This can be used to adjust the style,
composition, or other aspects of the image to better achieve a
specific result.
### Models
As part of the model installation, ControlNet models can be selected including a variety of pre-trained models that have been added to achieve different effects or styles in your generated images. Further ControlNet models may require additional code functionality to also be incorporated into Invoke's Invocations folder. You should expect to follow any installation instructions for ControlNet models loaded outside the default models provided by Invoke. The default models include:
InvokeAI provides access to a series of ControlNet models that provide
different effects or styles in your generated images. Currently
InvokeAI only supports "diffuser" style ControlNet models. These are
folders that contain the files `config.json` and/or
`diffusion_pytorch_model.safetensors` and
`diffusion_pytorch_model.fp16.safetensors`. The name of the folder is
the name of the model.
***InvokeAI does not currently support checkpoint-format
ControlNets. These come in the form of a single file with the
extension `.safetensors`.***
Diffuser-style ControlNet models are available at HuggingFace
(http://huggingface.co) and accessed via their repo IDs (identifiers
in the format "author/modelname"). The easiest way to install them is
to use the InvokeAI model installer application. Use the
`invoke.sh`/`invoke.bat` launcher to select item [5] and then navigate
to the CONTROLNETS section. Select the models you wish to install and
press "APPLY CHANGES". You may also enter additional HuggingFace
*The node editor is experimental. We've made it accessible because we use it to develop the application, but we have not addressed the many known rough edges. It's very easy to shoot yourself in the foot, and we cannot offer support for it until it sees full release (ETA v3.1). Everything is subject to change without warning.*
🚨
The nodes editor is a blank canvas allowing for the use of individual functions and image transformations to control the image generation workflow. The node processing flow is usually done from left (inputs) to right (outputs), though linearity can become abstracted the more complex the node graph becomes. Nodes inputs and outputs are connected by dragging connectors from node to node.
To better understand how nodes are used, think of how an electric power bar works. It takes in one input (electricity from a wall outlet) and passes it to multiple devices through multiple outputs. Similarly, a node could have multiple inputs and outputs functioning at the same (or different) time, but all node outputs pass information onward like a power bar passes electricity. Not all outputs are compatible with all inputs, however - Each node has different constraints on how it is expecting to input/output information. In general, node outputs are colour-coded to match compatible inputs of other nodes.
## Anatomy of a Node
Individual nodes are made up of the following:
- Inputs: Edge points on the left side of the node window where you connect outputs from other nodes.
- Outputs: Edge points on the right side of the node window where you connect to inputs on other nodes.
- Options: Various options which are either manually configured, or overridden by connecting an output from another node to the input.
## Diffusion Overview
Taking the time to understand the diffusion process will help you to understand how to set up your nodes in the nodes editor.
There are two main spaces Stable Diffusion works in: image space and latent space.
Image space represents images in pixel form that you look at. Latent space represents compressed inputs. It’s in latent space that Stable Diffusion processes images. A VAE (Variational Auto Encoder) is responsible for compressing and encoding inputs into latent space, as well as decoding outputs back into image space.
When you generate an image using text-to-image, multiple steps occur in latent space:
1. Random noise is generated at the chosen height and width. The noise’s characteristics are dictated by the chosen (or not chosen) seed. This noise tensor is passed into latent space. We’ll call this noise A.
1. Using a model’s U-Net, a noise predictor examines noise A, and the words tokenized by CLIP from your prompt (conditioning). It generates its own noise tensor to predict what the final image might look like in latent space. We’ll call this noise B.
1. Noise B is subtracted from noise A in an attempt to create a final latent image indicative of the inputs. This step is repeated for the number of sampler steps chosen.
1. The VAE decodes the final latent image from latent space into image space.
image-to-image is a similar process, with only step 1 being different:
1. The input image is decoded from image space into latent space by the VAE. Noise is then added to the input latent image. Denoising Strength dictates how much noise is added, 0 being none, and 1 being all-encompassing. We’ll call this noise A. The process is then the same as steps 2-4 in the text-to-image explanation above.
Furthermore, a model provides the CLIP prompt tokenizer, the VAE, and a U-Net (where noise prediction occurs given a prompt and initial noise tensor).
A noise scheduler (eg. DPM++ 2M Karras) schedules the subtraction of noise from the latent image across the sampler steps chosen (step 3 above). Less noise is usually subtracted at higher sampler steps.
| CannyImageProcessor | Canny edge detection for ControlNet |
| ClipSkip | Skip layers in clip text_encoder model |
| Collect | Collects values into a collection |
| Prompt (Compel) | Parse prompt using compel package to conditioning |
| ContentShuffleImageProcessor | Applies content shuffle processing to image |
| ControlNet | Collects ControlNet info to pass to other nodes |
| CvInpaint | Simple inpaint using opencv |
| Divide | Divides two numbers |
| DynamicPrompt | Parses a prompt using adieyal/dynamic prompt's random or combinatorial generator |
| FloatLinearRange | Creates a range |
| HedImageProcessor | Applies HED edge detection to image |
| ImageBlur | Blurs an image |
| ImageChannel | Gets a channel from an image |
| ImageCollection | Load a collection of images and provide it as output |
| ImageConvert | Converts an image to a different mode |
| ImageCrop | Crops an image to a specified box. The box can be outside of the image. |
| ImageInverseLerp | Inverse linear interpolation of all pixels of an image |
| ImageLerp | Linear interpolation of all pixels of an image |
| ImageMultiply | Multiplies two images together using `PIL.ImageChops.Multiply()` |
| ImagePaste | Pastes an image into another image |
| ImageProcessor | Base class for invocations that reprocess images for ControlNet |
| ImageResize | Resizes an image to specific dimensions |
| ImageScale | Scales an image by a factor |
| ImageToLatents | Scales latents by a given factor |
| InfillColor | Infills transparent areas of an image with a solid color |
| InfillPatchMatch | Infills transparent areas of an image using the PatchMatch algorithm |
| InfillTile | Infills transparent areas of an image with tiles of the image |
| Inpaint | Generates an image using inpaint |
| Iterate | Iterates over a list of items |
| LatentsToImage | Generates an image from latents |
| LatentsToLatents | Generates latents using latents as base image |
| LeresImageProcessor | Applies leres processing to image |
| LineartAnimeImageProcessor | Applies line art anime processing to image |
| LineartImageProcessor | Applies line art processing to image |
| LoadImage | Load an image and provide it as output |
| Lora Loader | Apply selected lora to unet and text_encoder |
| Model Loader | Loads a main model, outputting its submodels |
| MaskFromAlpha | Extracts the alpha channel of an image as a mask |
| MediapipeFaceProcessor | Applies mediapipe face processing to image |
| MidasDepthImageProcessor | Applies Midas depth processing to image |
| MlsdImageProcessor | Applied MLSD processing to image |
| Multiply | Multiplies two numbers |
| Noise | Generates latent noise |
| NormalbaeImageProcessor | Applies NormalBAE processing to image |
| OpenposeImageProcessor | Applies Openpose processing to image |
| ParamFloat | A float parameter |
| ParamInt | An integer parameter |
| PidiImageProcessor | Applies PIDI processing to an image |
| Progress Image | Displays the progress image in the Node Editor |
| RandomInit | Outputs a single random integer |
| RandomRange | Creates a collection of random numbers |
| Range | Creates a range of numbers from start to stop with step |
| RangeOfSize | Creates a range from start to start + size with step |
| ResizeLatents | Resizes latents to explicit width/height (in pixels). Provided dimensions are floor-divided by 8. |
| RestoreFace | Restores faces in the image |
| ScaleLatents | Scales latents by a given factor |
| SegmentAnythingProcessor | Applies segment anything processing to image |
| ShowImage | Displays a provided image, and passes it forward in the pipeline |
| StepParamEasing | Experimental per-step parameter for easing for denoising steps |
| Subtract | Subtracts two numbers |
| TextToLatents | Generates latents from conditionings |
| TileResampleProcessor | Bass class for invocations that preprocess images for ControlNet |
| Upscale | Upscales an image |
| VAE Loader | Loads a VAE model, outputting a VaeLoaderOutput |
| ZoeDepthImageProcessor | Applies Zoe depth processing to image |
## Node Grouping Concepts
There are several node grouping concepts that can be examined with a narrow focus. These (and other) groupings can be pieced together to make up functional graph setups, and are important to understanding how groups of nodes work together as part of a whole. Note that the screenshots below aren't examples of complete functioning node graphs (see Examples).
### Noise
As described, an initial noise tensor is necessary for the latent diffusion process. As a result, all non-image *ToLatents nodes require a noise node input.
As described, conditioning is necessary for the latent diffusion process, whether empty or not. As a result, all non-image *ToLatents nodes require positive and negative conditioning inputs. Conditioning is reliant on a CLIP tokenizer provided by the Model Loader node.
The ImageToLatents node doesn't require a noise node input, but requires a VAE input to convert the image from image space into latent space. In reverse, the LatentsToImage node requires a VAE input to convert from latent space back into image space.
It is common to want to use both the same seed (for continuity) and random seeds (for variance). To define a seed, simply enter it into the 'Seed' field on a noise node. Conversely, the RandomInt node generates a random integer between 'Low' and 'High', and can be used as input to the 'Seed' edge point on a noise node to randomize your seed.
Control means to guide the diffusion process to adhere to a defined input or structure. Control can be provided as input to non-image *ToLatents nodes from ControlNet nodes. ControlNet nodes usually require an image processor which converts an input image for use with ControlNet.
The Lora Loader node lets you load a LoRA (say that ten times fast) and pass it as output to both the Prompt (Compel) and non-image *ToLatents nodes. A model's CLIP tokenizer is passed through the LoRA into Prompt (Compel), where it affects conditioning. A model's U-Net is also passed through the LoRA into a non-image *ToLatents node, where it affects noise prediction.
Use the ImageScale, ScaleLatents, and Upscale nodes to upscale images and/or latent images. The chosen method differs across contexts. However, be aware that latents are already noisy and compressed at their original resolution; scaling an image could produce more detailed results.
Iteration is a common concept in any processing, and means to repeat a process with given input. In nodes, you're able to use the Iterate node to iterate through collections usually gathered by the Collect node. The Iterate node has many potential uses, from processing a collection of images one after another, to varying seeds across multiple image generations and more. This screenshot demonstrates how to collect several images and pass them out one at a time.
Multiple image generation in the node editor is done using the RandomRange node. In this case, the 'Size' field represents the number of images to generate. As RandomRange produces a collection of integers, we need to add the Iterate node to iterate through the collection.
To control seeds across generations takes some care. The first row in the screenshot will generate multiple images with different seeds, but using the same RandomRange parameters across invocations will result in the same group of random seeds being used across the images, producing repeatable results. In the second row, adding the RandomInt node as input to RandomRange's 'Seed' edge point will ensure that seeds are varied across all images across invocations, producing varied results.
With our knowledge of node grouping and the diffusion process, let’s break down some basic graphs in the nodes editor. Note that a node's options can be overridden by inputs from other nodes. These examples aren't strict rules to follow and only demonstrate some basic configurations.
- Model Loader: A necessity to generating images (as we’ve read above). We choose our model from the dropdown. It outputs a U-Net, CLIP tokenizer, and VAE.
- Prompt (Compel): Another necessity. Two prompt nodes are created. One will output positive conditioning (what you want, ‘dog’), one will output negative (what you don’t want, ‘cat’). They both input the CLIP tokenizer that the Model Loader node outputs.
- Noise: Consider this noise A from step one of the text-to-image explanation above. Choose a seed number, width, and height.
- TextToLatents: This node takes many inputs for converting and processing text & noise from image space into latent space, hence the name TextTo**Latents**. In this setup, it inputs positive and negative conditioning from the prompt nodes for processing (step 2 above). It inputs noise from the noise node for processing (steps 2 & 3 above). Lastly, it inputs a U-Net from the Model Loader node for processing (step 2 above). It outputs latents for use in the next LatentsToImage node. Choose number of sampler steps, CFG scale, and scheduler.
- LatentsToImage: This node takes in processed latents from the TextToLatents node, and the model’s VAE from the Model Loader node which is responsible for decoding latents back into the image space, hence the name LatentsTo**Image**. This node is the last stop, and once the image is decoded, it is saved to the gallery.
- Prompt (Compel): Two prompt nodes. One positive (dog), one negative (dog). Same CLIP inputs from the Model Loader node as before.
- ImageToLatents: Upload a source image directly in the node window, via drag'n'drop from the gallery, or passed in as input. The ImageToLatents node inputs the VAE from the Model Loader node to decode the chosen image from image space into latent space, hence the name ImageTo**Latents**. It outputs latents for use in the next LatentsToLatents node. It also outputs the source image's width and height for use in the next Noise node if the final image is to be the same dimensions as the source image.
- Noise: A noise tensor is created with the width and height of the source image, and connected to the next LatentsToLatents node. Notice the width and height fields are overridden by the input from the ImageToLatents width and height outputs.
- LatentsToLatents: The inputs and options are nearly identical to TextToLatents, except that LatentsToLatents also takes latents as an input. Considering our source image is already converted to latents in the last ImageToLatents node, and text + noise are no longer the only inputs to process, we use the LatentsToLatents node.
- LatentsToImage: Like previously, the LatentsToImage node will use the VAE from the Model Loader as input to decode the latents from LatentsToLatents into image space, and save it to the gallery.
- Noise: Width and height of the CannyImageProcessor ControlNet image is passed in to set the dimensions of the noise passed to TextToLatents.
- CannyImageProcessor: The CannyImageProcessor node is used to process the source image being used as a ControlNet. Each ControlNet processor node applies control in different ways, and has some different options to configure. Width and height are passed to noise, as mentioned. The processed ControlNet image is output to the ControlNet node.
- ControlNet: Select the type of control model. In this case, canny is chosen as the CannyImageProcessor was used to generate the ControlNet image. Configure the control node options, and pass the control output to TextToLatents.
- TextToLatents: Similar to the basic text-to-image example, except ControlNet is passed to the control input edge point.
This extension provides the ability to restore faces and upscale images.
This sections details the ability to improve faces and upscale images.
## Face Fixing
The default face restoration module is GFPGAN. The default upscale is
Real-ESRGAN. For an alternative face restoration module, see
[CodeFormer Support](#codeformer-support) below.
As of InvokeAI 3.0, the easiest way to improve faces created during image generation is through the Inpainting functionality of the Unified Canvas. Simply add the image containing the faces that you would like to improve to the canvas, mask the face to be improved and run the invocation. For best results, make sure to use an inpainting specific model; these are usually identified by the "-inpainting" term in the model name.
As of version 1.14, environment.yaml will install the Real-ESRGAN package into
the standard install location for python packages, and will put GFPGAN into a
subdirectory of "src" in the InvokeAI directory. Upscaling with Real-ESRGAN
should "just work" without further intervention. Simply indicate the desired scale on
the popup in the Web GUI.
**GFPGAN** requires a series of downloadable model files to work. These are
loaded when you run `invokeai-configure`. If GFPAN is failing with an
error, please run the following from the InvokeAI directory:
```bash
invokeai-configure
```
If you do not run this script in advance, the GFPGAN module will attempt to
download the models files the first time you try to perform facial
reconstruction.
### Upscaling
## Upscaling
Open the upscaling dialog by clicking on the "expand" icon located
above the image display area in the Web UI:
@ -41,82 +19,23 @@ above the image display area in the Web UI:
There are three different upscaling parameters that you can
adjust. The first is the scale itself, either 2x or 4x.
The default upscaling option is Real-ESRGAN x2 Plus, which will scale your image by a factor of two. This means upscaling a 512x512 image will result in a new 1024x1024 image.
The second is the "Denoising Strength." Higher values will smooth out
the image and remove digital chatter, but may lose fine detail at
higher values.
Other options are the x4 upscalers, which will scale your image by a factor of 4.
Third, "Upscale Strength" allows you to adjust how the You can set the
scaling stength between `0` and `1.0` to control the intensity of the
scaling. AI upscalers generally tend to smooth out texture details. If
you wish to retain some of those for natural looking results, we
Any words between a pair of square brackets will instruct Stable
Diffusion to attempt to ban the concept from the generated image. The
same effect is achieved by placing words in the "Negative Prompts"
textbox in the Web UI.
```text
this is a test prompt [not really] to make you understand [cool] how this works.
```
In the above statement, the words 'not really cool` will be ignored by Stable
Diffusion.
Here's a prompt that depicts what it does.
original prompt:
`#!bash "A fantastical translucent pony made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve"`
That image has a woman, so if we want the horse without a rider, we can
influence the image not to have a woman by putting [woman] in the prompt, like
this:
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman]"`
That's nice - but say we also don't want the image to be quite so blue. We can
add "blue" to the list of negative prompts, so it's now [woman blue]:
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman blue]"`
Getting close - but there's no sense in having a saddle when our horse doesn't
have a rider, so we'll add one more negative prompt: [woman blue saddle].
`#!bash "A fantastical translucent poney made of water and foam, ethereal, radiant, hyperalism, scottish folklore, digital painting, artstation, concept art, smooth, 8 k frostbite 3 engine, ultra detailed, art by artgerm and greg rutkowski and magali villeneuve [woman blue saddle]"`
* The only requirement for words to be ignored is that they are in between a pair of square brackets.
* You can provide multiple words within the same bracket.
* You can provide multiple brackets with multiple words in different places of your prompt. That works just fine.
* To improve typical anatomy problems, you can add negative prompts like `[bad anatomy, extra legs, extra arms, extra fingers, poorly drawn hands, poorly drawn feet, disfigured, out of frame, tiling, bad art, deformed, mutated]`.
---
## **Prompt Syntax Features**
The InvokeAI prompting language has the following features:
@ -102,9 +28,6 @@ The following syntax is recognised:
`a tall thin man (picking (apricots)1.3)1.1`. (`+` is equivalent to 1.1, `++`
is pow(1.1,2), `+++` is pow(1.1,3), etc; `-` means 0.9, `--` means pow(0.9,2),
etc.)
- attention also applies to `[unconditioning]` so
`a tall thin man picking apricots [(ladder)0.01]` will _very gently_ nudge SD
away from trying to draw the man on a ladder
You can use this to increase or decrease the amount of something. Starting from
this prompt of `a man picking apricots from a tree`, let's see what happens if
@ -150,7 +73,7 @@ Or, alternatively, with more man:
-`("a tall thin man picking apricots", "a tall thin man picking pears").blend(1,1)`
- The existing prompt blending using `:<weight>` will continue to be supported -
@ -168,6 +91,24 @@ Or, alternatively, with more man:
See the section below on "Prompt Blending" for more information about how this
works.
### Prompt Conjunction
Join multiple clauses together to create a conjoined prompt. Each clause will be passed to CLIP separately.
For example, the prompt:
```bash
"A mystical valley surround by towering granite cliffs, watercolor, warm"
```
Can be used with .and():
```bash
("A mystical valley", "surround by towering granite cliffs", "watercolor", "warm").and()
```
Each will give you different results - try them out and see what you prefer!
### Cross-Attention Control ('prompt2prompt')
Sometimes an image you generate is almost right, and you just want to change one
@ -190,7 +131,7 @@ For example, consider the prompt `a cat.swap(dog) playing with a ball in the for
- For multiple word swaps, use parentheses: `a (fluffy cat).swap(barking dog) playing with a ball in the forest`.
- To swap a comma, use quotes: `a ("fluffy, grey cat").swap("big, barking dog") playing with a ball in the forest`.
- Supports options `t_start` and `t_end` (each 0-1) loosely corresponding to bloc97's `prompt_edit_tokens_start/_end` but with the math swapped to make it easier to
- Supports options `t_start` and `t_end` (each 0-1) loosely corresponding to (bloc97's)[(https://github.com/bloc97/CrossAttentionControl)] `prompt_edit_tokens_start/_end` but with the math swapped to make it easier to
intuitively understand. `t_start` and `t_end` are used to control on which steps cross-attention control should run. With the default values `t_start=0` and `t_end=1`, cross-attention control is active on every step of image generation. Other values can be used to turn cross-attention control off for part of the image generation process.
- For example, if doing a diffusion with 10 steps for the prompt is `a cat.swap(dog, t_start=0.3, t_end=1.0) playing with a ball in the forest`, the first 3 steps will be run as `a cat playing with a ball in the forest`, while the last 7 steps will run as `a dog playing with a ball in the forest`, but the pixels that represent `dog` will be locked to the pixels that would have represented `cat` if the `cat` prompt had been used instead.
- Conversely, for `a cat.swap(dog, t_start=0, t_end=0.7) playing with a ball in the forest`, the first 7 steps will run as `a dog playing with a ball in the forest` with the pixels that represent `dog` locked to the same pixels that would have represented `cat` if the `cat` prompt was being used instead. The final 3 steps will just run `a cat playing with a ball in the forest`.
@ -201,7 +142,7 @@ Prompt2prompt `.swap()` is not compatible with xformers, which will be temporari
This will tell the sampler to blend 25% of the concept of prompt #1 with 75%
of the concept of prompt #2. It is recommended to keep the sum of the weights to around 1.0, but interesting things might happen if you go outside of this range.
Because you are exploring the "mind" of the AI, the AI's way of mixing two
concepts may not match yours, leading to surprising effects. To illustrate, here
@ -236,13 +170,14 @@ are three images generated using various combinations of blend weights. As
usual, unless you fix the seed, the prompts will give you different results each
time you run them.
<figure markdown>
Let's examine how this affects image generation results:
### "blue sphere, red cube, hybrid"
</figure>
```bash
"blue sphere, red cube, hybrid"
```
This example doesn't use melding at all and represents the default way of mixing
This example doesn't use blending at all and represents the default way of mixing
concepts.
<figuremarkdown>
@ -251,55 +186,47 @@ concepts.
</figure>
It's interesting to see how the AI expressed the concept of "cube" as the four
quadrants of the enclosing frame. If you look closely, there is depth there, so
the enclosing frame is actually a cube.
It's interesting to see how the AI expressed the concept of "cube" within the sphere. If you look closely, there is depth there, so the enclosing frame is actually a cube.
Now that's interesting. We get neither a blue sphere nor a red cube, but a red
sphere embedded in a brick wall, which represents a melding of concepts within
the AI's "latent space" of semantic representations. Where is Ludwig
Wittgenstein when you need him?
Now that's interesting. We get an image with a resemblance of a red cube, with a hint of blue shadows which represents a melding of concepts within the AI's "latent space" of semantic representations.
| `--host HOST` | Web server: Host or IP to listen on. Set to 0.0.0.0 to accept traffic from other devices on your network. |
| `--port PORT` | Web server: Port to listen on |
| `--certfile CERTFILE` | Web server: Path to certificate file to use for SSL. Use together with --keyfile |
| `--keyfile KEYFILE` | Web server: Path to private key file to use for SSL. Use together with --certfile' |
| `--gui` | Start InvokeAI GUI - This is the "desktop mode" version of the web app. It uses Flask to create a desktop app experience of the webserver. |
Scroll down the control panel until you get to the LoRA accordion
Taking the time to understand the diffusion process will help you to understand how to more effectively use InvokeAI.
There are two main ways Stable Diffusion works - with images, and latents.
Image space represents images in pixel form that you look at. Latent space represents compressed inputs. It’s in latent space that Stable Diffusion processes images. A VAE (Variational Auto Encoder) is responsible for compressing and encoding inputs into latent space, as well as decoding outputs back into image space.
To fully understand the diffusion process, we need to understand a few more terms: UNet, CLIP, and conditioning.
A U-Net is a model trained on a large number of latent images with with known amounts of random noise added. This means that the U-Net can be given a slightly noisy image and it will predict the pattern of noise needed to subtract from the image in order to recover the original.
CLIP is a model that tokenizes and encodes text into conditioning. This conditioning guides the model during the denoising steps to produce a new image.
The U-Net and CLIP work together during the image generation process at each denoising step, with the U-Net removing noise in such a way that the result is similar to images in the U-Net’s training set, while CLIP guides the U-Net towards creating images that are most similar to the prompt.
When you generate an image using text-to-image, multiple steps occur in latent space:
1. Random noise is generated at the chosen height and width. The noise’s characteristics are dictated by seed. This noise tensor is passed into latent space. We’ll call this noise A.
2. Using a model’s U-Net, a noise predictor examines noise A, and the words tokenized by CLIP from your prompt (conditioning). It generates its own noise tensor to predict what the final image might look like in latent space. We’ll call this noise B.
3. Noise B is subtracted from noise A in an attempt to create a latent image consistent with the prompt. This step is repeated for the number of sampler steps chosen.
4. The VAE decodes the final latent image from latent space into image space.
Image-to-image is a similar process, with only step 1 being different:
1. The input image is encoded from image space into latent space by the VAE. Noise is then added to the input latent image. Denoising Strength dictates how may noise steps are added, and the amount of noise added at each step. A Denoising Strength of 0 means there are 0 steps and no noise added, resulting in an unchanged image, while a Denoising Strength of 1 results in the image being completely replaced with noise and a full set of denoising steps are performance. The process is then the same as steps 2-4 in the text-to-image process.
Furthermore, a model provides the CLIP prompt tokenizer, the VAE, and a U-Net (where noise prediction occurs given a prompt and initial noise tensor).
A noise scheduler (eg. DPM++ 2M Karras) schedules the subtraction of noise from the latent image across the sampler steps chosen (step 3 above). Less noise is usually subtracted at higher sampler steps.
New to image generation with AI? You’re in the right place!
This is a high level walkthrough of some of the concepts and terms you’ll see as you start using InvokeAI. Please note, this is not an exhaustive guide and may be out of date due to the rapidly changing nature of the space.
## Using InvokeAI
### **Prompt Crafting**
- Prompts are the basis of using InvokeAI, providing the models directions on what to generate. As a general rule of thumb, the more detailed your prompt is, the better your result will be.
*To get started, here’s an easy template to use for structuring your prompts:*
- Subject, Style, Quality, Aesthetic
- **Subject:** What your image will be about. E.g. “a futuristic city with trains”, “penguins floating on icebergs”, “friends sharing beers”
- **Style:** The style or medium in which your image will be in. E.g. “photograph”, “pencil sketch”, “oil paints”, or “pop art”, “cubism”, “abstract”
- **Quality:** A particular aspect or trait that you would like to see emphasized in your image. E.g. "award-winning", "featured in {relevant set of high quality works}", "professionally acclaimed". Many people often use "masterpiece".
- **Aesthetics:** The visual impact and design of the artwork. This can be colors, mood, lighting, setting, etc.
- There are two prompt boxes: *Positive Prompt*&*Negative Prompt*.
- A **Positive** Prompt includes words you want the model to reference when creating an image.
- Negative Prompt is for anything you want the model to eliminate when creating an image. It doesn’t always interpret things exactly the way you would, but helps control the generation process. Always try to include a few terms - you can typically use lower quality image terms like “blurry” or “distorted” with good success.
- Some examples prompts you can try on your own:
- A detailed oil painting of a tranquil forest at sunset with vibrant+ colors and soft, golden light filtering through the trees
- friends sharing beers in a busy city, realistic colored pencil sketch, twilight, masterpiece, bright, lively
### Generation Workflows
- Invoke offers a number of different workflows for interacting with models to produce images. Each is extremely powerful on its own, but together provide you an unparalleled way of producing high quality creative outputs that align with your vision.
- **Text to Image:** The text to image tab focuses on the key workflow of using a prompt to generate a new image. It includes other features that help control the generation process as well.
- **Image to Image:** With image to image, you provide an image as a reference (called the “initial image”), which provides more guidance around color and structure to the AI as it generates a new image. This is provided alongside the same features as Text to Image.
- **Unified Canvas:** The Unified Canvas is an advanced AI-first image editing tool that is easy to use, but hard to master. Drag an image onto the canvas from your gallery in order to regenerate certain elements, edit content or colors (known as inpainting), or extend the image with an exceptional degree of consistency and clarity (called outpainting).
### Improving Image Quality
- Fine tuning your prompt - the more specific you are, the closer the image will turn out to what is in your head! Adding more details in the Positive Prompt or Negative Prompt can help add / remove pieces of your image to improve it - You can also use advanced techniques like upweighting and downweighting to control the influence of certain words. [Learn more here](https://invoke-ai.github.io/InvokeAI/features/PROMPTS/#prompt-syntax-features).
- **Tip: If you’re seeing poor results, try adding the things you don’t like about the image to your negative prompt may help. E.g. distorted, low quality, unrealistic, etc.**
- Explore different models - Other models can produce different results due to the data they’ve been trained on. Each model has specific language and settings it works best with; a model’s documentation is your friend here. Play around with some and see what works best for you!
- Increasing Steps - The number of steps used controls how much time the model is given to produce an image, and depends on the “Scheduler” used. The schedule controls how each step is processed by the model. More steps tends to mean better results, but will take longer - We recommend at least 30 steps for most
- Tweak and Iterate - Remember, it’s best to change one thing at a time so you know what is working and what isn't. Sometimes you just need to try a new image, and other times using a new prompt might be the ticket. For testing, consider turning off the “random” Seed - Using the same seed with the same settings will produce the same image, which makes it the perfect way to learn exactly what your changes are doing.
- Explore Advanced Settings - InvokeAI has a full suite of tools available to allow you complete control over your image creation process - Check out our [docs if you want to learn more](https://invoke-ai.github.io/InvokeAI/features/).
## Terms & Concepts
If you're interested in learning more, check out [this presentation](https://docs.google.com/presentation/d/1IO78i8oEXFTZ5peuHHYkVF-Y3e2M6iM5tCnc-YBfcCM/edit?usp=sharing) from one of our maintainers (@lstein).
### Stable Diffusion
Stable Diffusion is deep learning, text-to-image model that is the foundation of the capabilities found in InvokeAI. Since the release of Stable Diffusion, there have been many subsequent models created based on Stable Diffusion that are designed to generate specific types of images.
### Prompts
Prompts provide the models directions on what to generate. As a general rule of thumb, the more detailed your prompt is, the better your result will be.
### Models
Models are the magic that power InvokeAI. These files represent the output of training a machine on understanding massive amounts of images - providing them with the capability to generate new images using just a text description of what you’d like to see. (Like Stable Diffusion!)
Invoke offers a simple way to download several different models upon installation, but many more can be discovered online, including at ****. Each model can produce a unique style of output, based on the images it was trained on - Try out different models to see which best fits your creative vision!
- *Models that contain “inpainting” in the name are designed for use with the inpainting feature of the Unified Canvas*
### Scheduler
Schedulers guide the process of removing noise (de-noising) from data. They determine:
1. The number of steps to take to remove the noise.
2. Whether the steps are random (stochastic) or predictable (deterministic).
3. The specific method (algorithm) used for de-noising.
Experimenting with different schedulers is recommended as each will produce different outputs!
### Steps
The number of de-noising steps each generation through.
Schedulers can be intricate and there's often a balance to strike between how quickly they can de-noise data and how well they can do it. It's typically advised to experiment with different schedulers to see which one gives the best results. There has been a lot written on the internet about different schedulers, as well as exploring what the right level of "steps" are for each. You can save generation time by reducing the number of steps used, but you'll want to make sure that you are satisfied with the quality of images produced!
### Low-Rank Adaptations / LoRAs
Low-Rank Adaptations (LoRAs) are like a smaller, more focused version of models, intended to focus on training a better understanding of how a specific character, style, or concept looks.
### Textual Inversion Embeddings
Textual Inversion Embeddings, like LoRAs, assist with more easily prompting for certain characters, styles, or concepts. However, embeddings are trained to update the relationship between a specific word (known as the “trigger”) and the intended output.
### ControlNet
ControlNets are neural network models that are able to extract key features from an existing image and use these features to guide the output of the image generation model.
### VAE
Variational auto-encoder (VAE) is a encode/decode model that translates the "latents" image produced during the image generation procees to the large pixel images that we see.
This fork is rapidly evolving. Please use the [Issues tab](https://github.com/invoke-ai/InvokeAI/issues) to report bugs and make feature requests. Be sure to use the provided templates. They will help aid diagnose issues faster.
This project is rapidly evolving. Please use the [Issues tab](https://github.com/invoke-ai/InvokeAI/issues) to report bugs and make feature requests. Be sure to use the provided templates as it will help aid response time.
The nodes editor is a blank canvas allowing for the use of individual functions and image transformations to control the image generation workflow. Nodes take in inputs on the left side of the node, and return an output on the right side of the node. A node graph is composed of multiple nodes that are connected together to create a workflow. Nodes' inputs and outputs are connected by dragging connectors from node to node. Inputs and outputs are color coded for ease of use.
To better understand how nodes are used, think of how an electric power bar works. It takes in one input (electricity from a wall outlet) and passes it to multiple devices through multiple outputs. Similarly, a node could have multiple inputs and outputs functioning at the same (or different) time, but all node outputs pass information onward like a power bar passes electricity. Not all outputs are compatible with all inputs, however - Each node has different constraints on how it is expecting to input/output information. In general, node outputs are colour-coded to match compatible inputs of other nodes.
If you're not familiar with Diffusion, take a look at our [Diffusion Overview.](../help/diffusion.md) Understanding how diffusion works will enable you to more easily use the Nodes Editor and build workflows to suit your needs.
## Important Concepts
There are several node grouping concepts that can be examined with a narrow focus. These (and other) groupings can be pieced together to make up functional graph setups, and are important to understanding how groups of nodes work together as part of a whole. Note that the screenshots below aren't examples of complete functioning node graphs (see Examples).
### Noise
An initial noise tensor is necessary for the latent diffusion process. As a result, the Denoising node requires a noise node input.

### Text Prompt Conditioning
Conditioning is necessary for the latent diffusion process, whether empty or not. As a result, the Denoising node requires positive and negative conditioning inputs. Conditioning is reliant on a CLIP text encoder provided by the Model Loader node.
The ImageToLatents node takes in a pixel image and a VAE and outputs a latents. The LatentsToImage node does the opposite, taking in a latents and a VAE and outpus a pixel image.

### Defined & Random Seeds
It is common to want to use both the same seed (for continuity) and random seeds (for variety). To define a seed, simply enter it into the 'Seed' field on a noise node. Conversely, the RandomInt node generates a random integer between 'Low' and 'High', and can be used as input to the 'Seed' edge point on a noise node to randomize your seed.
The ControlNet node outputs a Control, which can be provided as input to non-image *ToLatents nodes. Depending on the type of ControlNet desired, ControlNet nodes usually require an image processor node, such as a Canny Processor or Depth Processor, which prepares an input image for use with ControlNet.
The Lora Loader node lets you load a LoRA and pass it as output.A LoRA provides fine-tunes to the UNet and text encoder weights that augment the base model’s image and text vocabularies.

### Scaling
Use the ImageScale, ScaleLatents, and Upscale nodes to upscale images and/or latent images. Upscaling is the process of enlarging an image and adding more detail. The chosen method differs across contexts. However, be aware that latents are already noisy and compressed at their original resolution; scaling an image could produce more detailed results.
Iteration is a common concept in any processing, and means to repeat a process with given input. In nodes, you're able to use the Iterate node to iterate through collections usually gathered by the Collect node. The Iterate node has many potential uses, from processing a collection of images one after another, to varying seeds across multiple image generations and more. This screenshot demonstrates how to collect several images and use them in an image generation workflow.
Multiple image generation in the node editor is done using the RandomRange node. In this case, the 'Size' field represents the number of images to generate. As RandomRange produces a collection of integers, we need to add the Iterate node to iterate through the collection.
To control seeds across generations takes some care. The first row in the screenshot will generate multiple images with different seeds, but using the same RandomRange parameters across invocations will result in the same group of random seeds being used across the images, producing repeatable results. In the second row, adding the RandomInt node as input to RandomRange's 'Seed' edge point will ensure that seeds are varied across all images across invocations, producing varied results.
If you're coming to InvokeAI from ComfyUI, welcome! You'll find things are similar but different - the good news is that you already know how things should work, and it's just a matter of wiring them up!
Some things to note:
- InvokeAI's nodes tend to be more granular than default nodes in Comfy. This means each node in Invoke will do a specific task and you might need to use multiple nodes to achieve the same result. The added granularity improves the control you have have over your workflows.
- InvokeAI's backend and ComfyUI's backend are very different which means Comfy workflows are not able to be imported into InvokeAI. However, we have created a [list of popular workflows](exampleWorkflows.md) for you to get started with Nodes in InvokeAI!
These are nodes that have been developed by the community, for the community. If you're not sure what a node is, you can learn more about nodes [here](overview.md).
If you'd like to submit a node for the community, please refer to the [node creation overview](contributingNodes.md).
To download a node, simply download the `.py` node file from the link and add it to the `invokeai/app/invocations` folder in your Invoke AI install location. Along with the node, an example node graph should be provided to help you get started with the node.
To use a community node graph, download the the `.json` node graph file and load it into Invoke AI via the **Load Nodes** button on the Node Editor.
## Community Nodes
### FaceTools
**Description:** FaceTools is a collection of nodes created to manipulate faces as you would in Unified Canvas. It includes FaceMask, FaceOff, and FacePlace. FaceMask autodetects a face in the image using MediaPipe and creates a mask from it. FaceOff similarly detects a face, then takes the face off of the image by adding a square bounding box around it and cropping/scaling it. FacePlace puts the bounded face image from FaceOff back onto the original image. Using these nodes with other inpainting node(s), you can put new faces on existing things, put new things around existing faces, and work closer with a face as a bounded image. Additionally, you can supply X and Y offset values to scale/change the shape of the mask for finer control on FaceMask and FaceOff. See GitHub repository below for usage examples.
**Description:** This node calculates an ideal image size for a first pass of a multi-pass upscaling. The aim is to avoid duplication that results from choosing a size larger than the model is capable of.
**Description:** This node adds a film grain effect to the input image based on the weights, seeds, and blur radii parameters. It works with RGB input images only.
**Description:** This InvokeAI node takes in a collection of images and randomly chooses one. This can be useful when you have a number of poses to choose from for a ControlNet node, or a number of input images for another purpose.
**Description:** Retroize is a collection of nodes for InvokeAI to "Retroize" images. Any image can be given a fresh coat of retro paint with these nodes, either from your gallery or from within the graph itself. It includes nodes to pixelize, quantize, palettize, and ditherize images; as well as to retrieve palettes from existing images.
**Description:** This is a video frame image provider + indexer/video creation nodes for hooking up to iterators and ranges and ControlNets and such forinvokeAInode experimentation. Think animation + ControlNet outputs.
"describe a new mystical creature in its natural environment"
*can return*
"The mystical creature I am describing to you is called the "Glimmerwing". It is a majestic, iridescent being that inhabits the depths of the most enchanted forests and glimmering lakes. Its body is covered in shimmering scales that reflect every color of the rainbow, and it has delicate, translucent wings that sparkle like diamonds in the sunlight. The Glimmerwing's home is a crystal-clear lake, surrounded by towering trees with leaves that shimmer like jewels. In this serene environment, the Glimmerwing spends its days swimming gracefully through the water, chasing schools of glittering fish and playing with the gentle ripples of the lake's surface.
As the sun sets, the Glimmerwing perches on a branch of one of the trees, spreading its wings to catch the last rays of light. The creature's scales glow softly, casting a rainbow of colors across the forest floor. The Glimmerwing sings a haunting melody, its voice echoing through the stillness of the night air. Its song is said to have the power to heal the sick and bring peace to troubled souls. Those who are lucky enough to hear the Glimmerwing's song are forever changed by its beauty and grace."
a Text-Generation-Webui instance (might work remotely too, but I never tried it) and obviously InvokeAI 3.x
**Note**
This node works best with SDXL models, especially as the style can be described independantly of the LLM's output.
--------------------------------
### Depth Map from Wavefront OBJ
**Description:** Render depth maps from Wavefront .obj files (triangulated) using this simple 3D renderer utilizing numpy and matplotlib to compute and color the scene. There are simple parameters to change the FOV, camera position, and model orientation.
To be imported, an .obj must use triangulated meshes, so make sure to enable that option if exporting from a 3D modeling program. This renderer makes each triangle a solid color based on its average depth, so it will cause anomalies if your .obj has large triangles. In Blender, the Remesh modifier can be helpful to subdivide a mesh into small pieces that work well given these limitations.
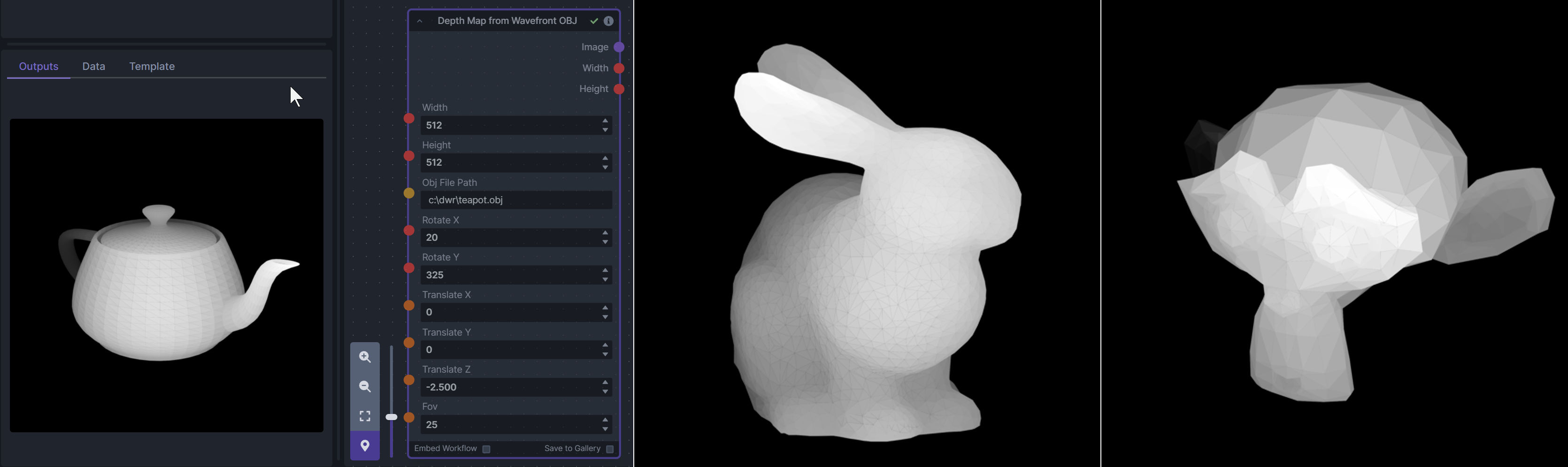
--------------------------------
### Enhance Image (simple adjustments)
**Description:** Boost or reduce color saturation, contrast, brightness, sharpness, or invert colors of any image at any stage with this simple wrapper for pillow [PIL]'s ImageEnhance module.
Color inversion is toggled with a simple switch, while each of the four enhancer modes are activated by entering a value other than 1 in each corresponding input field. Values less than 1 will reduce the corresponding property, while values greater than 1 will enhance it.
**Description:** This set of 3 nodes generates prompts from simple user-defined grammar rules (loaded from custom files - examples provided below). The prompts are made by recursively expanding a special template string, replacing nonterminal "parts-of-speech" until no more nonterminal terms remain in the string.
This includes 3 Nodes:
- *Lookup Table from File* - loads a YAML file "prompt" section (or of a whole folder of YAML's) into a JSON-ified dictionary (Lookups output)
- *Lookups Entry from Prompt* - places a single entry in a new Lookups output under the specified heading
- *Prompt from Lookup Table* - uses a Collection of Lookups as grammar rules from which to randomly generate prompts.
--------------------------------
### Image and Mask Composition Pack
**Description:** This is a pack of nodes for composing masks and images, including a simple text mask creator and both image and latent offset nodes. The offsets wrap around, so these can be used in conjunction with the Seamless node to progressively generate centered on different parts of the seamless tiling.
This includes 4 Nodes:
- *Text Mask (simple 2D)* - create and position a white on black (or black on white) line of text using any font locally available to Invoke.
- *Image Compositor* - Take a subject from an image with a flat backdrop and layer it on another image using a chroma key or flood select background removal.
- *Offset Latents* - Offset a latents tensor in the vertical and/or horizontal dimensions, wrapping it around.
- *Offset Image* - Offset an image in the vertical and/or horizontal dimensions, wrapping it around.
**Description:** This is a set of nodes for calculating the necessary size increments for doing upscaling workflows. Use the *Final Size & Orientation* node to enter your full size dimensions and orientation (portrait/landscape/random), then plug that and your initial generation dimensions into the *Ideal Size Stepper* and get 1, 2, or 3 intermediate pairs of dimensions for upscaling. Note this does not output the initial size or full size dimensions: the 1, 2, or 3 outputs of this node are only the intermediate sizes.
A third node is included, *Random Switch (Integers)*, which is just a generic version of Final Size with no orientation selection.
**Description:** text font to text image node for InvokeAI, download a font to use (or if in font cache uses it from there), the text is always resized to the image size, but can control that with padding, optional 2nd line
The nodes linked have been developed and contributed by members of the Invoke AI community. While we strive to ensure the quality and safety of these contributions, we do not guarantee the reliability or security of the nodes. If you have issues or concerns with any of the nodes below, please raise it on GitHub or in the Discord.
## Help
If you run into any issues with a node, please post in the [InvokeAI Discord](https://discord.gg/ZmtBAhwWhy).
To learn about the specifics of creating a new node, please visit our [Node creation documentation](../contributing/INVOCATIONS.md).
Once you’ve created a node and confirmed that it behaves as expected locally, follow these steps:
- Make sure the node is contained in a new Python (.py) file
- Submit a pull request with a link to your node in GitHub against the `nodes` branch to add the node to the [Community Nodes](Community Nodes) list
- Make sure you are following the template below and have provided all relevant details about the node and what it does.
- A maintainer will review the pull request and node. If the node is aligned with the direction of the project, you might be asked for permission to include it in the core project.
### Community Node Template
```markdown
--------------------------------
### Super Cool Node Template
**Description:** This node allows you to do super cool things with InvokeAI.
|Boolean Primitive Collection | A collection of boolean primitive values|
|Boolean Primitive | A boolean primitive value|
|Canny Processor | Canny edge detection for ControlNet|
|CLIP Skip | Skip layers in clip text_encoder model.|
|Collect | Collects values into a collection|
|Color Correct | Shifts the colors of a target image to match the reference image, optionally using a mask to only color-correct certain regions of the target image.|
|Color Primitive | A color primitive value|
|Compel Prompt | Parse prompt using compel package to conditioning.|
|Conditioning Primitive Collection | A collection of conditioning tensor primitive values|
|Conditioning Primitive | A conditioning tensor primitive value|
|Content Shuffle Processor | Applies content shuffle processing to image|
|ControlNet | Collects ControlNet info to pass to other nodes|
|OpenCV Inpaint | Simple inpaint using opencv.|
|Denoise Latents | Denoises noisy latents to decodable images|
|Divide Integers | Divides two numbers|
|Dynamic Prompt | Parses a prompt using adieyal/dynamicprompts' random or combinatorial generator|
|Upscale (RealESRGAN) | Upscales an image using RealESRGAN.|
|Float Primitive Collection | A collection of float primitive values|
|Float Primitive | A float primitive value|
|Float Range | Creates a range|
|HED (softedge) Processor | Applies HED edge detection to image|
|Blur Image | Blurs an image|
|Extract Image Channel | Gets a channel from an image.|
|Image Primitive Collection | A collection of image primitive values|
|Convert Image Mode | Converts an image to a different mode.|
|Crop Image | Crops an image to a specified box. The box can be outside of the image.|
|Image Hue Adjustment | Adjusts the Hue of an image.|
|Inverse Lerp Image | Inverse linear interpolation of all pixels of an image|
|Image Primitive | An image primitive value|
|Lerp Image | Linear interpolation of all pixels of an image|
|Offset Image Channel | Add to or subtract from an image color channel by a uniform value.|
|Multiply Image Channel | Multiply or Invert an image color channel by a scalar value.|
|Multiply Images | Multiplies two images together using `PIL.ImageChops.multiply()`.|
|Blur NSFW Image | Add blur to NSFW-flagged images|
|Paste Image | Pastes an image into another image.|
|ImageProcessor | Base class for invocations that preprocess images for ControlNet|
|Resize Image | Resizes an image to specific dimensions|
|Scale Image | Scales an image by a factor|
|Image to Latents | Encodes an image into latents.|
|Add Invisible Watermark | Add an invisible watermark to an image|
|Solid Color Infill | Infills transparent areas of an image with a solid color|
|PatchMatch Infill | Infills transparent areas of an image using the PatchMatch algorithm|
|Tile Infill | Infills transparent areas of an image with tiles of the image|
|Integer Primitive Collection | A collection of integer primitive values|
|Integer Primitive | An integer primitive value|
|Iterate | Iterates over a list of items|
|Latents Primitive Collection | A collection of latents tensor primitive values|
|Latents Primitive | A latents tensor primitive value|
|Latents to Image | Generates an image from latents.|
|Leres (Depth) Processor | Applies leres processing to image|
|Lineart Anime Processor | Applies line art anime processing to image|
|Lineart Processor | Applies line art processing to image|
|LoRA Loader | Apply selected lora to unet and text_encoder.|
|Main Model Loader | Loads a main model, outputting its submodels.|
|Combine Mask | Combine two masks together by multiplying them using `PIL.ImageChops.multiply()`.|
|Mask Edge | Applies an edge mask to an image|
|Mask from Alpha | Extracts the alpha channel of an image as a mask.|
|Mediapipe Face Processor | Applies mediapipe face processing to image|
|Midas (Depth) Processor | Applies Midas depth processing to image|
|MLSD Processor | Applies MLSD processing to image|
|Multiply Integers | Multiplies two numbers|
|Noise | Generates latent noise.|
|Normal BAE Processor | Applies NormalBae processing to image|
|ONNX Latents to Image | Generates an image from latents.|
|ONNX Prompt (Raw) | A node to process inputs and produce outputs. May use dependency injection in __init__ to receive providers.|
|ONNX Text to Latents | Generates latents from conditionings.|
|ONNX Model Loader | Loads a main model, outputting its submodels.|
|Openpose Processor | Applies Openpose processing to image|
|PIDI Processor | Applies PIDI processing to image|
|Prompts from File | Loads prompts from a text file|
|Random Integer | Outputs a single random integer.|
|Random Range | Creates a collection of random numbers|
|Integer Range | Creates a range of numbers from start to stop with step|
|Integer Range of Size | Creates a range from start to start + size with step|
|Resize Latents | Resizes latents to explicit width/height (in pixels). Provided dimensions are floor-divided by 8.|
|SDXL Compel Prompt | Parse prompt using compel package to conditioning.|
|SDXL LoRA Loader | Apply selected lora to unet and text_encoder.|
|SDXL Main Model Loader | Loads an sdxl base model, outputting its submodels.|
|SDXL Refiner Compel Prompt | Parse prompt using compel package to conditioning.|
|SDXL Refiner Model Loader | Loads an sdxl refiner model, outputting its submodels.|
|Scale Latents | Scales latents by a given factor.|
|Segment Anything Processor | Applies segment anything processing to image|
|Show Image | Displays a provided image, and passes it forward in the pipeline.|
An Node is simply a single operation that takes in inputs and returns
out outputs. Multiple nodes can be linked together to create more
complex functionality. All InvokeAI features are added through nodes.
### Anatomy of a Node
Individual nodes are made up of the following:
- Inputs: Edge points on the left side of the node window where you connect outputs from other nodes.
- Outputs: Edge points on the right side of the node window where you connect to inputs on other nodes.
- Options: Various options which are either manually configured, or overridden by connecting an output from another node to the input.
With nodes, you can can easily extend the image generation capabilities of InvokeAI, and allow you build workflows that suit your needs.
You can read more about nodes and the node editor [here](../nodes/NODES.md).
To get started with nodes, take a look at some of our examples for [common workflows](../nodes/exampleWorkflows.md)
## Downloading New Nodes
To download a new node, visit our list of [Community Nodes](../nodes/communityNodes.md). These are nodes that have been created by the community, for the community.
yieldText.from_markup("Some of the installation steps take a long time to run. Please be patient. If the script appears to hang for more than 10 minutes, please interrupt with [i]Control-C[/] and retry.",justify="center")
yieldText.from_markup(
"Some of the installation steps take a long time to run. Please be patient. If the script appears to hang for more than 10 minutes, please interrupt with [i]Control-C[/] and retry.",
f"Failed to create directory {dest} due to insufficient permissions",
style=Style(color="red"),
highlight=True,
)
exceptOSErrorasexc:
console.print_exception(exc)
exceptOSError:
console.print_exception()
ifConfirm.ask("Would you like to try again?"):
dest_path(init_path)
@ -165,6 +167,10 @@ def graphical_accelerator():
"an [gold1 b]NVIDIA[/] GPU (using CUDA™)",
"cuda",
)
nvidia_with_dml=(
"an [gold1 b]NVIDIA[/] GPU (using CUDA™, and DirectML™ for ONNX) -- ALPHA",
"cuda_and_dml",
)
amd=(
"an [gold1 b]AMD[/] GPU (using ROCm™)",
"rocm",
@ -179,7 +185,7 @@ def graphical_accelerator():
)
ifOS=="Windows":
options=[nvidia,cpu]
options=[nvidia,nvidia_with_dml,cpu]
ifOS=="Linux":
options=[nvidia,amd,cpu]
elifOS=="Darwin":
@ -300,15 +306,20 @@ def introduction() -> None:
)
console.line(2)
def_platform_specific_help()->str:
def_platform_specific_help()->str:
ifOS=="Darwin":
text=Text.from_markup("""[b wheat1]macOS Users![/]\n\nPlease be sure you have the [b wheat1]Xcode command-line tools[/] installed before continuing.\nIf not, cancel with [i]Control-C[/] and follow the Xcode install instructions at [deep_sky_blue1]https://www.freecodecamp.org/news/install-xcode-command-line-tools/[/].""")
text=Text.from_markup(
"""[b wheat1]macOS Users![/]\n\nPlease be sure you have the [b wheat1]Xcode command-line tools[/] installed before continuing.\nIf not, cancel with [i]Control-C[/] and follow the Xcode install instructions at [deep_sky_blue1]https://www.freecodecamp.org/news/install-xcode-command-line-tools/[/]."""
)
elifOS=="Windows":
text=Text.from_markup("""[b wheat1]Windows Users![/]\n\nBefore you start, please do the following:
text=Text.from_markup(
"""[b wheat1]Windows Users![/]\n\nBefore you start, please do the following:
1. Double-click on the file [b wheat1]WinLongPathsEnabled.reg[/] in order to
enable long path support on your system.
2. Make sure you have the [b wheat1]Visual C++ core libraries[/] installed. If not, install from
raiseHTTPException(status_code=500,detail="Failed to remove images from board")
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}