# Distinguish LoRA/LyCORIS files based on what version of SD they were
built on top of
- Attempting to run a prompt with a LoRA based on SD v1.X against a
model based on v2.X will now throw an `IncompatibleModelException`. To
import this exception:
`from ldm.modules.lora_manager import IncompatibleModelException` (maybe
this should be defined in ModelManager?)
- Enhance `LoraManager.list_loras()` to accept an optional integer
argument, `token_vector_length`. This will filter the returned LoRA
models to return only those that match the indicated length. Use:
```
768 => for models based on SD v1.X
1024 => for models based on SD v2.X
```
Note that this filtering requires each LoRA file to be opened by
`torch.safetensors`. It will take ~8s to scan a directory of 40 files.
- Added new static methods to `ldm.modules.kohya_lora_manager`:
- check_model_compatibility()
- vector_length_from_checkpoint()
- vector_length_from_checkpoint_file()
- You can now create subdirectories within the `loras` directory and
organize the model files.
- Moved all postinstallation config file and model munging code out of
the CLI and into a separate script named `invokeai-postinstall`
- Fixed two calls to `shutil.copytree()` so that they don't try to
preserve the file mode of the copied files. This is necessary to run
correctly in a Nix environment (see thread at
https://discord.com/channels/1020123559063990373/1091716696965918732/1095662756738371615)
- Update the installer so that an existing virtual environment will be
updated, not overwritten.
- Pin npyscreen version to see if this fixes issues people have had with
installing this module.
Load LoRAs during compel's text embedding encode pass in case there are
requested LoRAs which also want to patch the text encoder.
Also generally cleanup the attention processor patching stuff. It's
still a mess, but at least now it's a *stateless* mess.
Both @mauwii and @keturn have been offline for some time. I am
temporarily removing them from CODEOWNERS so that they will not be
responsible for code reviews until they wish to/are able to re-engage
fully.
Note that I have volunteered @GreggHelt2 to be a codeowner of the
generation backend code, replacing @keturn . Let me know if you're
uncomfortable with this.
- Pin diffusers to 0.14
- Small fix to LoRA loading routine that was preventing placement of
LoRA files in subdirectories.
- Bump version to 2.3.4.post1
- Pin diffusers to 0.14
- Small fix to LoRA loading routine that was preventing placement of
LoRA files in subdirectories.
- Bump version to 2.3.4.post1
- Moved all postinstallation config file and model munging code out
of the CLI and into a separate script named `invokeai-postinstall`
- Fixed two calls to `shutil.copytree()` so that they don't try to preserve
the file mode of the copied files. This is necessary to run correctly
in a Nix environment
(see thread at https://discord.com/channels/1020123559063990373/1091716696965918732/1095662756738371615)
- Update the installer so that an existing virtual environment will be
updated, not overwritten.
- Pin npyscreen version to see if this fixes issues people have had with
installing this module.
- Previous PR to truncate long filenames won't work on windows due to
lack of support for os.pathconf(). This works around the limitation by
hardcoding the value for PC_NAME_MAX when pathconf is unavailable.
- The `multiprocessing` send() and recv() methods weren't working
properly on Windows due to issues involving `utf-8` encoding and
pickling/unpickling. Changed these calls to `send_bytes()` and
`recv_bytes()` , which seems to fix the issue.
Not fully tested on Windows since I lack a GPU machine to test on, but
is working on CPU.
- Attempting to run a prompt with a LoRA based on SD v1.X against a
model based on v2.X will now throw an
`IncompatibleModelException`. To import this exception:
`from ldm.modules.lora_manager import IncompatibleModelException`
(maybe this should be defined in ModelManager?)
- Enhance `LoraManager.list_loras()` to accept an optional integer
argument, `token_vector_length`. This will filter the returned LoRA
models to return only those that match the indicated length. Use:
```
768 => for models based on SD v1.X
1024 => for models based on SD v2.X
```
Note that this filtering requires each LoRA file to be opened
by `torch.safetensors`. It will take ~8s to scan a directory of
40 files.
- Added new static methods to `ldm.modules.kohya_lora_manager`:
- check_model_compatibility()
- vector_length_from_checkpoint()
- vector_length_from_checkpoint_file()
- Previously the user's preferred precision was used to select which
version branch of a diffusers model would be downloaded. Half-precision
would try to download the 'fp16' branch if it existed.
- Turns out that with waifu-diffusion this logic doesn't work, as
'fp16' gets you waifu-diffusion v1.3, while 'main' gets you
waifu-diffusion v1.4. Who knew?
- This PR adds a new optional "revision" field to `models.yaml`. This
can be used to override the diffusers branch version. In the case of
Waifu diffusion, INITIAL_MODELS.yaml now specifies the "main" branch.
- This PR also quenches the NSFW nag that downloading diffusers sometimes
triggers.
- Closes#3160
- Previous PR to truncate long filenames won't work on windows
due to lack of support for os.pathconf(). This works around the
limitation by hardcoding the value for PC_NAME_MAX when pathconf
is unavailable.
Some quick bug fixes related to the UI for the 2.3.4. release.
**Features:**
- Added the ability to now add Textual Inversions to the Negative Prompt
using the UI.
- Added the ability to clear Textual Inversions and Loras from Prompt
and Negative Prompt with a single click.
- Textual Inversions now have status pips - indicating whether they are
used in the Main Prompt, Negative Prompt or both.
**Fixes**
- Fixes#3138
- Fixes#3144
- Fixed `usePrompt` not updating the Lora and TI count in prompt /
negative prompt.
- Fixed the TI regex not respecting names in substrings.
- Fixed trailing spaces when adding and removing loras and TI's.
- Fixed an issue with the TI regex not respecting the `<` and `>` used
by HuggingFace concepts.
- Some other minor bug fixes.
NOTE: This PR works with `diffusers` models **only**. As a result
InvokeAI is now converting all legacy checkpoint/safetensors files into
diffusers models on the fly. This introduces a bit of extra delay when
loading legacy models. You can avoid this by converting the files to
diffusers either at import time, or after the fact.
# Instructions:
1. Download LoRA .safetensors files of your choice and place in
`INVOKEAIROOT/loras`. Unlike the draft version of this PR, the file
names can now contain underscores and hyphens. Names with arbitrary
unicode characters are not supported.
2. Add `withLora(lora-file-basename,weight)` to your prompt. The weight
is optional and will default to 1.0. A few examples, assuming that a
LoRA file named `loras/sushi.safetensors` is present:
```
family sitting at dinner table eating sushi withLora(sushi,0.9)
family sitting at dinner table eating sushi withLora(sushi, 0.75)
family sitting at dinner table eating sushi withLora(sushi)
```
Multiple `withLora()` prompt fragments are allowed. The weight can be
arbitrarily large, but the useful range is roughly 0.5 to 1.0. Higher
weights make the LoRA's influence stronger. The last version of the
syntax, which uses the default weight of 1.0, is waiting on the next
version of the Compel library to be released and may not work at this
time.
In my limited testing, I found it useful to reduce the CFG to avoid
oversharpening. Also I got better results when running the LoRA on top
of the model on which it was based during training.
Don't try to load a SD 1.x-trained LoRA into a SD 2.x model, and vice
versa. You will get a nasty stack trace. This needs to be cleaned up.
3. You can change the location of the `loras` directory by passing the
`--lora_directory` option to `invokeai.
Documentation can be found in docs/features/LORAS.md.
Note that this PR incorporates the unmerged 2.3.3 PR code (#3058) and
bumps the version number up to 2.3.4a0.
A zillion thanks to @felorhik, @neecapp and many others for this
implementation. @blessedcoolant and I just did a little tidying up.
- Remove unused (and probably dangerous) `unload_applied_loras()` method
- Remove unused `LoraManager.loras_to_load` attribute
- Change default LoRA weight to 0.75 when using WebUI to add a LoRA to prompt.
Now, for python 3.9 installer run upgrade pip command like this:
`pip install --upgrade pip`
And because pip binary locked as running process this lead to error(at
least on windows):
```
ERROR: Could not install packages due to an OSError: [WinError 5] Access is denied: 'e:\invokeai\.venv\scripts\pip.exe'
Check the permissions.
```
To prevent this recomended command to upgrade pip is:
`python -m pip install --upgrade pip`
Which not locking pip file.
- removed app directory (a 3.0 feature), so app tests had to go too
- fixed regular expression in the concepts lib which was causing deprecation warnings
(note that this is actually release candidate 7, but I made the mistake
of including an old rc number in the branch and can't easily change it)
## Updating Root directory
- Introduced new mechanism for updating the root directory when
necessary. Currently only used to update the invoke.sh script using new
dialog colors.
- Fixed ROCm torch module version number
## Loading legacy 2.0/2.1 models
- Due to not converting the torch.dtype precision correctly, the
`load_pipeline_from_original_stable_diffusion_ckpt()` was returning
models of dtype float32 regardless of the precision setting. This caused
a precision mismatch crash.
- Problem now fixed (also see #3057 for the same fix to `main`)
## Support for a fourth textual inversion embedding file format
- This variant, exemplified by "easynegative.safetensors" has a single
'embparam' key containing a Tensor.
- Also refactored code to make it easier to read.
- Handle both pickle and safetensor formats.
## Persistent model selection
- To be consistent with WebUI parameter behavior, the currently selected
model is saved on exit and restored on restart for both WebUI and CLI
## Bug fixes
- Name of VAE cache directory was "hug", not "hub". This is fixed.
## VAE fixes
- Allow custom VAEs to be assigned to a legacy model by placing a
like-named vae file adjacent to the checkpoint file.
- The custom VAE will be picked up and incorporated into the diffusers
model if the user chooses to convert/optimize.
## Custom config file loading
- Some of the civitai models instruct users to place a custom .yaml file
adjacent to the checkpoint file. This generally wasn't working because
some of the .yaml files use FrozenCLIPEmbedder rather than
WeightedFrozenCLIPEmbedder, and our FrozenCLIPEmbedder class doesn't
handle the `personalization_config` section used by the the textual
inversion manager. Other .yaml files don't have the
`personalization_config` section at all. Both these issues are
fixed.#1685
## Consistent pytorch version
- There was an inconsistency between the pytorch version requirement in
`pyproject.toml` and the requirement in the installer (which does a
little jiggery-pokery to load torch with the right CUDA/ROCm version
prior to the main pip install. This was causing torch to be installed,
then uninstalled, and reinstalled with a different version number. This
is now fixed.
Instructions:
1. Download LoRA .safetensors files of your choice and place in
`INVOKEAIROOT/loras`. Unlike the draft version of this, the file
names can contain underscores and alphanumerics. Names with
arbitrary unicode characters are not supported.
2. Add `withLora(lora-file-basename,weight)` to your prompt. The
weight is optional and will default to 1.0. A few examples, assuming
that a LoRA file named `loras/sushi.safetensors` is present:
```
family sitting at dinner table eating sushi withLora(sushi,0.9)
family sitting at dinner table eating sushi withLora(sushi, 0.75)
family sitting at dinner table eating sushi withLora(sushi)
```
Multiple `withLora()` prompt fragments are allowed. The weight can be
arbitrarily large, but the useful range is roughly 0.5 to 1.0. Higher
weights make the LoRA's influence stronger.
In my limited testing, I found it useful to reduce the CFG to avoid
oversharpening. Also I got better results when running the LoRA on top
of the model on which it was based during training.
Don't try to load a SD 1.x-trained LoRA into a SD 2.x model, and vice
versa. You will get a nasty stack trace. This needs to be cleaned up.
3. You can change the location of the `loras` directory by passing the
`--lora_directory` option to `invokeai.
Documentation can be found in docs/features/LORAS.md.
- Allow invokeai-update to update using a release, tag or branch.
- Allow CLI's root directory update routine to update directory
contents regardless of whether current version is released.
- In model importation routine, clarify wording of instructions when user is
asked to choose the type of model being imported.
- This variant, exemplified by "easynegative.safetensors" has a single
'embparam' key containing a Tensor.
- Also refactored code to make it easier to read.
- Handle both pickle and safetensor formats.
This commit fixes bugs related to the on-the-fly conversion and loading of
legacy checkpoint models built on SD-2.0 base.
- When legacy checkpoints built on SD-2.0 models were converted
on-the-fly using --ckpt_convert, generation would crash with a
precision incompatibility error.
- In addition, broken logic was causing some 2.0-derived ckpt files to
be converted into diffusers and then processed through the legacy
generation routines - not good.
- installer now installs the pretty dialog-based console launcher
- added dialogrc for custom colors
- add updater to download new launcher when users do an update
- This variant, exemplified by "easynegative.safetensors" has a single
'embparam' key containing a Tensor.
- Also refactored code to make it easier to read.
- Handle both pickle and safetensor formats.
- Imported V2 legacy models will now autoconvert into diffusers at load
time regardless of setting of --ckpt_convert.
- model manager `heuristic_import()` function now looks for side-by-side
yaml and vae files for custom configuration and VAE respectively.
Example of this:
illuminati-v1.1.safetensors illuminati-v1.1.vae.safetensors
illuminati-v1.1.yaml
When the user tries to import `illuminati-v1.1.safetensors`, the yaml
file will be used for its configuration, and the VAE will be used for
its VAE. Conversion to diffusers will happen if needed, and the yaml
file will be used to determine which V2 format (if any) to apply.
NOTE that the changes to `ckpt_to_diffusers.py` were previously reviewed
by @JPPhoto on the `main` branch and approved.
- Imported V2 legacy models will now autoconvert into diffusers
at load time regardless of setting of --ckpt_convert.
- model manager `heuristic_import()` function now looks for
side-by-side yaml and vae files for custom configuration and VAE
respectively.
Example of this:
illuminati-v1.1.safetensors
illuminati-v1.1.vae.safetensors
illuminati-v1.1.yaml
When the user tries to import `illuminati-v1.1.safetensors`, the yaml
file will be used for its configuration, and the VAE will be used for
its VAE. Conversion to diffusers will happen if needed, and the yaml
file will be used to determine which V2 format (if any) to apply.
Several related security fixes:
1. Port #2946 from main to 2.3.2 branch - this closes a hole that allows
a pickle checkpoint file to masquerade as a safetensors file.
2. Add pickle scanning to the checkpoint to diffusers conversion script.
3. Pickle scan VAE non-safetensors files
4. Avoid running scanner twice on same file during the probing and
conversion process.
5. Clean up diagnostic messages.
- The command `invokeai-batch --invoke` was created a time-stamped
logfile with colons in its name, which is a Windows no-no. This corrects
the problem by writing the timestamp out as "13-06-2023_8-35-10"
- Closes#3005
- Since 2.3.2 invokeai stores the next PNG file's numeric prefix in a
file named `.next_prefix` in the outputs directory. This avoids the
overhead of doing a directory listing to find out what file number comes
next.
- The code uses advisory locking to prevent corruption of this file in
the event that multiple invokeai's try to access it simultaneously, but
some users have experienced corruption of the file nevertheless.
- This PR addresses the problem by detecting a potentially corrupted
`.next_prefix` file and falling back to the directory listing method. A
fixed version of the file is then written out.
- Closes#3001
This PR addresses issues raised by #3008.
1. Update documentation to indicate the correct maximum batch size for
TI training when xformers is and isn't used.
2. Update textual inversion code so that the default for batch size is
aware of xformer availability.
3. Add documentation for how to launch TI with distributed learning.
Lots of little bugs have been squashed since 2.3.2 and a new minor point
release is imminent. This PR updates the version number in preparation
for a RC.
- Since 2.3.2 invokeai stores the next PNG file's numeric prefix in a
file named `.next_prefix` in the outputs directory. This avoids the
overhead of doing a directory listing to find out what file number
comes next.
- The code uses advisory locking to prevent corruption of this file in
the event that multiple invokeai's try to access it simultaneously,
but some users have experienced corruption of the file nevertheless.
- This PR addresses the problem by detecting a potentially corrupted
`.next_prefix` file and falling back to the directory listing method.
A fixed version of the file is then written out.
- Closes#3001
Lots of little bugs have been squashed since 2.3.2 and a new minor
point release is imminent. This PR updates the version number in
preparation for a RC.
- `invokeai-batch --invoke` was created a time-stamped logfile with colons in its
name, which is a Windows no-no. This corrects the problem by writing
the timestamp out as "13-06-2023_8-35-10"
- Closes#3005
This PR addresses issues raised by #3008.
1. Update documentation to indicate the correct maximum batch size for
TI training when xformers is and isn't used.
2. Update textual inversion code so that the default for batch size
is aware of xformer availability.
3. Add documentation for how to launch TI with distributed learning.
Two related security fixes:
1. Port #2946 from main to 2.3.2 branch - this closes a hole that
allows a pickle checkpoint file to masquerade as a safetensors
file.
2. Add pickle scanning to the checkpoint to diffusers conversion
script. This will be ported to main in a separate PR.
This commit enhances support for V2 variant (epsilon and v-predict)
import and conversion to diffusers, by prompting the user to select the
proper config file during startup time autoimport as well as in the
invokeai installer script. Previously the user was only prompted when
doing an `!import` from the command line or when using the WebUI Model
Manager.
This commit enhances support for V2 variant (epsilon and v-predict)
import and conversion to diffusers, by prompting the user to select
the proper config file during startup time autoimport as well as
in the invokeai installer script..
At some point `pyproject.toml` was modified to remove the
invokeai-update and invokeai-model-install scripts. This PR fixes the
issue.
If this was an intentional change, let me know and we'll discuss.
# Support SD version 2 "epsilon" and "v-predict" inference
configurations in v2.3
This is a port of the `main` PR #2870 back into V2.3. It allows both
"epsilon" inference V2 models (e.g. "v2-base") and "v-predict" models
(e.g. "V2-768") to be imported and converted into correct diffusers
models. This depends on picking the right configuration file to use, and
since there is no intrinsic difference between the two types of models,
when we detect that a V2 model is being imported, we fall back to asking
the user to select the model type.
This PR ports the `main` PR #2871 to the v2.3 branch. This adjusts the
global diffusers model cache to work with the 0.14 diffusers layout of
placing models in HF_HOME/hub rather than HF_HOME/diffusers. It also
implements the one-time migration action to the new layout.
This PR ports the `main` PR #2871 to the v2.3 branch. This adjusts
the global diffusers model cache to work with the 0.14 diffusers
layout of placing models in HF_HOME/hub rather than HF_HOME/diffusers.
# Programatically generate a large number of images varying by prompt
and other image generation parameters
This is a little standalone script named `dynamic_prompting.py` that
enables the generation of dynamic prompts. Using YAML syntax, you
specify a template of prompt phrases and lists of generation parameters,
and the script will generate a cross product of prompts and generation
settings for you. You can save these prompts to disk for later use, or
pipe them to the invokeai CLI to generate the images on the fly.
Typical uses are testing step and CFG values systematically while
holding the seed and prompt constant, testing out various artist's
styles, and comparing the results of the same prompt across different
models.
A typical template will look like this:
```
model: stable-diffusion-1.5
steps: 30;50;10
seed: 50
dimensions: 512x512
cfg:
- 7
- 12
sampler:
- k_euler_a
- k_lms
prompt:
style:
- greg rutkowski
- gustav klimt
location:
- the mountains
- a desert
object:
- luxurious dwelling
- crude tent
template: a {object} in {location}, in the style of {style}
```
This will generate 96 different images, each of which varies by one of
the dimensions specified in the template. For example, the prompt axis
will generate a cross product list like:
```
a luxurious dwelling in the mountains, in the style of greg rutkowski
a luxurious dwelling in the mountains, in the style of gustav klimt
a luxious dwelling in a desert, in the style of greg rutkowski
... etc
```
A typical usage would be:
```
python scripts/dynamic_prompts.py --invoke --outdir=/tmp/scanning my_template.yaml
```
This will populate `/tmp/scanning` with each of the requested images,
and also generate a `log.md` file which you can open with an e-book
reader to show something like this:

Full instructions can be obtained using the `--instructions` switch, and
an example template can be printed out using `--example`:
```
python scripts/dynamic_prompts.py --instructions
python scripts/dynamic_prompts.py --example > my_first_template.yaml
```
When a legacy ckpt model was converted into diffusers in RAM, the
built-in NSFW checker was not being disabled, in contrast to models
converted and saved to disk. Because InvokeAI does its NSFW checking as
a separate post-processing step (in order to generate blurred images
rather than black ones), this defeated the
--nsfw and --no-nsfw switches.
This closes#2836 and #2580.
Note - this fix will be applied to `main` as a separate PR.
At some point `pyproject.toml` was modified to remove the
invokeai-update script, which in turn breaks the update
function in the launcher scripts. This PR fixes the
issue.
If this was an intentional change, let me know and we'll discuss.
When a legacy ckpt model was converted into diffusers in RAM, the
built-in NSFW checker was not being disabled, in contrast to models
converted and saved to disk. Because InvokeAI does its NSFW checking
as a separate post-processing step (in order to generate blurred
images rather than black ones), this defeated the
--nsfw and --no-nsfw switches.
This closes#2836 and #2580.
This is a different source/base branch from
https://github.com/invoke-ai/InvokeAI/pull/2823 but is otherwise the
same content. `yarn build` was ran on this clean branch.
## What was the problem/requirement? (What/Why)
As part of a [change in
2.3.0](d74c4009cb),
the high resolution fix was no longer being applied when 'Use all' was
selected. This effectively meant that users had to manually analyze
images to ensure that the parameters were set to match.
~~Additionally, and never actually working, Upscaling and Face
Restoration parameters were also not pulling through with the action,
causing a similar usability issue.~~ See:
https://github.com/invoke-ai/InvokeAI/pull/2823#issuecomment-1445530362
## What was the solution? (How)
This change adds a new reducer to the `postprocessingSlice` file,
mimicking the `generationSlice` reducer to assign all parameters
appropriate for the post processing options. This reducer assigns:
* Hi-res's toggle button only if the type is `txt2img`, since `img2img`
hi-res was removed previously
* ~~Upscaling's toggle button, scale, denoising strength, and upscale
strength~~
* ~~Face Restoration's toggle button, type, strength, and fidelity (if
present/applicable)~~
### Minor
* Added `endOfLine: 'crlf'` to prettier's config to prevent all files
from being checked out on Windows due to difference of line endings (and
git not picking up those changes as modifications, causing ghost
modified files from Git)
### Revision 2:
* Removed out upscaling and face restoration pulling of parameters
### Revision 3:
* More defensive coding for the `hires_fix` not present (assume false)
### Out of Scope
* Hi-res strength (applied as img2img strength in the initial image that
is generated) is not in the metadata of the final image and can't be
reconstructed easily
* Upscaling and face restoration have some peculiarities for multi-post
processing outside of the UI, which complicates it enough to scope out
of this PR.
## How were these changes tested?
* `yarn dev` => Server started successfully
* Manual testing on the development server to ensure parameters pulled
correctly
* `yarn build` => Success
## Notes
As with `generationSlice`, this code assumes `action.payload.image` is
valid and doesn't do a formal check on it to ensure it is valid.
- Crash would occur at the end of this sequence:
- launch CLI
- !convert <URL pointing to a legacy ckpt file>
- Answer "Y" when asked to delete original .ckpt file
- This commit modifies model_manager.heuristic_import() to silently
delete the downloaded legacy file after it has been converted into a
diffusers model. The user is no longer asked to approve deletion.
NB: This should be cherry-picked into main once refactor is done.
For your consideration, here is a revised set of codeowners for the v2.3
branch. The previous set had the bad property that both @blessedcoolant
and @lstein were codeowners of everything, meaning that we had the
superpower of being able to put in a PR and get full approval if any
other member of the team (not a codeowner) approved.
The proposed file is a bit more sensible but needs many eyes on it.
Please take a look and make improvements. I wasn't sure where to put
some people, such as @netsvetaev or @GreggHelt2
I don't think it makes sense to tinker with the `main` CODEOWNERS until
the "Big Freeze" code reorganization happens.
I subscribed everyone to this PR. Apologies
- Crash would occur at the end of this sequence:
- launch CLI
- !convert <URL pointing to a legacy ckpt file>
- Answer "Y" when asked to delete original .ckpt file
- This commit modifies model_manager.heuristic_import()
to silently delete the downloaded legacy file after
it has been converted into a diffusers model. The user
is no longer asked to approve deletion.
NB: This should be cherry-picked into main once refactor
is done.
Simple script to generate a file of InvokeAI prompts and settings
that scan across steps and other parameters.
To use, create a file named "template.yaml" (or similar) formatted like this
>>> cut here <<<
steps: "30:50:1"
seed: 50
cfg:
- 7
- 8
- 12
sampler:
- ddim
- k_lms
prompt:
- a sunny meadow in the mountains
- a gathering storm in the mountains
>>> cut here <<<
Create sections named "steps", "seed", "cfg", "sampler" and "prompt".
- Each section can have a constant value such as this:
steps: 50
- Or a range of numeric values in the format:
steps: "<start>:<stop>:<step>"
- Or a list of values in the format:
- value1
- value2
- value3
Be careful to: 1) put quotation marks around numeric ranges; 2) put a
space between the "-" and the value in a list of values; and 3) use spaces,
not tabs, at the beginnings of indented lines.
When you run this script, capture the output into a text file like this:
python generate_param_scan.py template.yaml > output_prompts.txt
"output_prompts.txt" will now contain an expansion of all the list
values you provided. You can examine it in a text editor such as
Notepad.
Now start the CLI, and feed the expanded prompt file to it using the
"!replay" command:
!replay output_prompts.txt
Alternatively, you can directly feed the output of this script
by issuing a command like this from the developer's console:
python generate_param_scan.py template.yaml | invokeai
You can use the web interface to view the resulting images and their
metadata.
- stable-diffusion-2.1-base base model from
stabilityai/stable-diffusion-2-1-base
- stable-diffusion-2.1-768 768 pixel model from
stabilityai/stable-diffusion-2-1-768
- sd-inpainting-2.0 512 pixel inpainting model from
runwayml/stable-diffusion-inpainting
This PR also bumps the version number up to v2.3.1.post2
- stable-diffusion-2.1-base
base model from stabilityai/stable-diffusion-2-1-base
- stable-diffusion-2.1-768
768 pixel model from stabilityai/stable-diffusion-2-1-768
- sd-inpainting-2.0
512 pixel inpainting model from runwayml/stable-diffusion-inpainting
author Kyle Schouviller <kyle0654@hotmail.com> 1669872800 -0800
committer Kyle Schouviller <kyle0654@hotmail.com> 1676240900 -0800
Adding base node architecture
Fix type annotation errors
Runs and generates, but breaks in saving session
Fix default model value setting. Fix deprecation warning.
Fixed node api
Adding markdown docs
Simplifying Generate construction in apps
[nodes] A few minor changes (#2510)
* Pin api-related requirements
* Remove confusing extra CORS origins list
* Adds response models for HTTP 200
[nodes] Adding graph_execution_state to soon replace session. Adding tests with pytest.
Minor typing fixes
[nodes] Fix some small output query hookups
[node] Fixing some additional typing issues
[nodes] Move and expand graph code. Add base item storage and sqlite implementation.
Update startup to match new code
[nodes] Add callbacks to item storage
[nodes] Adding an InvocationContext object to use for invocations to provide easier extensibility
[nodes] New execution model that handles iteration
[nodes] Fixing the CLI
[nodes] Adding a note to the CLI
[nodes] Split processing thread into separate service
[node] Add error message on node processing failure
Removing old files and duplicated packages
Adding python-multipart
black:
- extend-exclude legacy scripts
- config for python 3.9 as long as we support it
isort:
- set atomic to true to only apply if no syntax errors are introduced
- config for python 3.9 as long as we support it
- extend_skib_glob legacy scripts
- filter_files
- match line_length with black
- remove_redundant_aliases
- skip_gitignore
- set src paths
- include virtual_env to detect third party modules
- better order of hooks
- add flake8-comprehensions and flake8-simplify
- remove unecesarry hooks which are covered by previous hooks
- add hooks
- check-executables-have-shebangs
- check-shebang-scripts-are-executable
- Updated Spanish translation
- Updated Portuguese (Brazil) translation
- Fix a number of translation issues and add missing strings
- Fix vertical symmetry and symmetry steps issue when generation steps
is adjusted
This PR adds the core of the node-based invocation system first
discussed in https://github.com/invoke-ai/InvokeAI/discussions/597 and
implements it through a basic CLI and API. This supersedes #1047, which
was too far behind to rebase.
## Architecture
### Invocations
The core of the new system is **invocations**, found in
`/ldm/invoke/app/invocations`. These represent individual nodes of
execution, each with inputs and outputs. Core invocations are already
implemented (`txt2img`, `img2img`, `upscale`, `face_restore`) as well as
a debug invocation (`show_image`). To implement a new invocation, all
that is required is to add a new implementation in this folder (there is
a markdown document describing the specifics, though it is slightly
out-of-date).
### Sessions
Invocations and links between them are maintained in a **session**.
These can be queued for invocation (either the next ready node, or all
nodes). Some notes:
* Sessions may be added to at any time (including after invocation), but
may not be modified.
* Links are always added with a node, and are always links from existing
nodes to the new node. These links can be relative "history" links, e.g.
`-1` to link from a previously executed node, and can link either
specific outputs, or can opportunistically link all matching outputs by
name and type by using `*`.
* There are no iteration/looping constructs. Most needs for this could
be solved by either duplicating nodes or cloning sessions. This is open
for discussion, but is a difficult problem to solve in a way that
doesn't make the code even more complex/confusing (especially regarding
node ids and history).
### Services
These make up the core the invocation system, found in
`/ldm/invoke/app/services`. One of the key design philosophies here is
that most components should be replaceable when possible. For example,
if someone wants to use cloud storage for their images, they should be
able to replace the image storage service easily.
The services are broken down as follows (several of these are
intentionally implemented with an initial simple/naïve approach):
* Invoker: Responsible for creating and executing **sessions** and
managing services used to do so.
* Session Manager: Manages session history. An on-disk implementation is
provided, which stores sessions as json files on disk, and caches
recently used sessions for quick access.
* Image Storage: Stores images of multiple types. An on-disk
implementation is provided, which stores images on disk and retains
recently used images in an in-memory cache.
* Invocation Queue: Used to queue invocations for execution. An
in-memory implementation is provided.
* Events: An event system, primarily used with socket.io to support
future web UI integration.
## Apps
Apps are available through the `/scripts/invoke-new.py` script (to-be
integrated/renamed).
### CLI
```
python scripts/invoke-new.py
```
Implements a simple CLI. The CLI creates a single session, and
automatically links all inputs to the previous node's output. Commands
are automatically generated from all invocations, with command options
being automatically generated from invocation inputs. Help is also
available for the cli and for each command, and is very verbose.
Additionally, the CLI supports command piping for single-line entry of
multiple commands. Example:
```
> txt2img --prompt "a cat eating sushi" --steps 20 --seed 1234 | upscale | show_image
```
### API
```
python scripts/invoke-new.py --api --host 0.0.0.0
```
Implements an API using FastAPI with Socket.io support for signaling.
API documentation is available at `http://localhost:9090/docs` or
`http://localhost:9090/redoc`. This includes OpenAPI schema for all
available invocations, session interaction APIs, and image APIs.
Socket.io signals are per-session, and can be subscribed to by session
id. These aren't currently auto-documented, though the code for event
emission is centralized in `/ldm/invoke/app/services/events.py`.
A very simple test html and script are available at
`http://localhost:9090/static/test.html` This demonstrates creating a
session from a graph, invoking it, and receiving signals from Socket.io.
## What's left?
* There are a number of features not currently covered by invocations. I
kept the set of invocations small during core development in order to
simplify refactoring as I went. Now that the invocation code has
stabilized, I'd love some help filling those out!
* There's no image metadata generated. It would be fairly
straightforward (and would make good sense) to serialize either a
session and node reference into an image, or the entire node into the
image. There are a lot of questions to answer around source images,
linked images, etc. though. This history is all stored in the session as
well, and with complex sessions, the metadata in an image may lose its
value. This needs some further discussion.
* We need a list of features (both current and future) that would be
difficult to implement without looping constructs so we can have a good
conversation around it. I'm really hoping we can avoid needing
looping/iteration in the graph execution, since it'll necessitate
separating an execution of a graph into its own concept/system, and will
further complicate the system.
* The API likely needs further filling out to support the UI. I think
using the new API for the current UI is possible, and potentially
interesting, since it could work like the new/demo CLI in a "single
operation at a time" workflow. I don't know how compatible that will be
with our UI goals though. It would be nice to support only a single API
though.
* Deeper separation of systems. I intentionally tried to not touch
Generate or other systems too much, but a lot could be gained by
breaking those apart. Even breaking apart Args into two pieces (command
line arguments and the parser for the current CLI) would make it easier
to maintain. This is probably in the future though.
author Kyle Schouviller <kyle0654@hotmail.com> 1669872800 -0800
committer Kyle Schouviller <kyle0654@hotmail.com> 1676240900 -0800
Adding base node architecture
Fix type annotation errors
Runs and generates, but breaks in saving session
Fix default model value setting. Fix deprecation warning.
Fixed node api
Adding markdown docs
Simplifying Generate construction in apps
[nodes] A few minor changes (#2510)
* Pin api-related requirements
* Remove confusing extra CORS origins list
* Adds response models for HTTP 200
[nodes] Adding graph_execution_state to soon replace session. Adding tests with pytest.
Minor typing fixes
[nodes] Fix some small output query hookups
[node] Fixing some additional typing issues
[nodes] Move and expand graph code. Add base item storage and sqlite implementation.
Update startup to match new code
[nodes] Add callbacks to item storage
[nodes] Adding an InvocationContext object to use for invocations to provide easier extensibility
[nodes] New execution model that handles iteration
[nodes] Fixing the CLI
[nodes] Adding a note to the CLI
[nodes] Split processing thread into separate service
[node] Add error message on node processing failure
Removing old files and duplicated packages
Adding python-multipart
I had inadvertently un-safe-d our translation types when migrating to Weblate.
This PR fixes that, and a number of translation string bugs that went unnoticed due to the lack of type safety,
- Add curated set of starter models based on team discussion. The final
list of starter models can be found in
`invokeai/configs/INITIAL_MODELS.yaml`
- To test model installation, I selected and installed all the models on
the list. This led to my discovering that when there are no more starter
models to display, the console front end crashes. So I made a fix to
this in which the entire starter model selection is no longer shown.
- Update model table in 050_INSTALL_MODELS.md
- Add guide to dealing with low-memory situations
- Version is now `v2.3.1`
- add new script `scripts/make_models_markdown_table.py` that parses
INITIAL_MODELS.yaml and creates markdown table for the model installation
documentation file
- update 050_INSTALLING_MODELS.md with above table, and add a warning
about additional license terms that apply to some of the models.
- Final list can be found in invokeai/configs/INITIAL_MODELS.yaml
- After installing all the models, I discovered a bug in the file
selection form that caused a crash when no remaining uninstalled
models remained. So had to fix this.
The sample_to_image method in `ldm.invoke.generator.base` was still
using ckpt-era code. As a result when the WebUI was set to show
"accurate" intermediate images, there'd be a crash. This PR corrects the
problem.
- Closes#2784
- Closes#2775
- Discord member @marcus.llewellyn reported that some civitai
2.1-derived checkpoints were not converting properly (probably
dreambooth-generated):
https://discord.com/channels/1020123559063990373/1078386197589655582/1078387806122025070
- @blessedcoolant tracked this down to a missing key that was used to
derive vector length of the CLIP model used by fetching the second
dimension of the tensor at "cond_stage_model.model.text_projection".
- On inspection, I found that the same second dimension can be recovered
from key 'cond_stage_model.model.ln_final.bias', and use that instead. I
hope this is correct; tested on multiple v1, v2 and inpainting models
and they converted correctly.
- While debugging this, I found and fixed several other issues:
- model download script was not pre-downloading the OpenCLIP
text_encoder or text_tokenizer. This is fixed.
- got rid of legacy code in `ckpt_to_diffuser.py` and replaced with
calls into `model_manager`
- more consistent status reporting in the CLI.
without this change, the project can be installed on 3.9 but not used
this also fixes the container images
Maybe we should re-enable Python 3.9 checks which would have prevented
this.
- Discord member @marcus.llewellyn reported that some civitai 2.1-derived checkpoints were
not converting properly (probably dreambooth-generated):
https://discord.com/channels/1020123559063990373/1078386197589655582/1078387806122025070
- @blessedcoolant tracked this down to a missing key that was used to
derive vector length of the CLIP model used by fetching the second
dimension of the tensor at "cond_stage_model.model.text_projection".
His proposed solution was to hardcode a value of 1024.
- On inspection, I found that the same second dimension can be
recovered from key 'cond_stage_model.model.ln_final.bias', and use
that instead. I hope this is correct; tested on multiple v1, v2 and
inpainting models and they converted correctly.
- While debugging this, I found and fixed several other issues:
- model download script was not pre-downloading the OpenCLIP
text_encoder or text_tokenizer. This is fixed.
- got rid of legacy code in `ckpt_to_diffuser.py` and replaced
with calls into `model_manager`
- more consistent status reporting in the CLI.
Root directory finding algorithm is:
2) use --root argument
2) use INVOKEAI_ROOT environment variable
3) use VIRTUAL_ENV environment variable
4) use ~/invokeai
Since developers are liable to put virtual environments in their
favorite places, not necessarily in the invokeai root directory, this PR
adds a sanity check that looks for the existence of
`VIRTUAL_ENV/invokeai.init`, and moves on to (4) if not found.
# This will constitute v2.3.1+rc2
## Windows installer enhancements
1. resize installer window to give more room for configure and download
forms
2. replace '\' with '/' in directory names to allow user to
drag-and-drop
folders into the dialogue boxes that accept directories.
3. similar change in CLI for the !import_model and !convert_model
commands
4. better error reporting when a model download fails due to network
errors
5. put the launcher scripts into a loop so that menu reappears after
invokeai, merge script, etc exits. User can quit with "Q".
6. do not try to download fp16 of sd-ft-mse-vae, since it doesn't exist.
7. cleaned up status reporting when installing models
8. Detect when install failed for some reason and print helpful error
message rather than stack trace.
9. Detect window size and resize to minimum acceptable values to provide
better display of configure and install forms.
10. Fix a bug in the CLI which prevented diffusers imported by their
repo_ids
from being correctly registered in the current session (though they
install
correctly)
11. Capitalize the "i" in Imported in the autogenerated descriptions.
Root directory finding algorithm is:
2) use --root argument
2) use INVOKEAI_ROOT environment variable
3) use VIRTUAL_ENV environment variable
4) use ~/invokeai
Since developer's are liable to put virtual environments in their
favorite places, not necessarily in the invokeai root directory, this
PR adds a sanity check that looks for the existence of
VIRTUAL_ENV/invokeai.init, and moves to (4) if not found.
- Fix a bug in the CLI which prevented diffusers imported by their repo_ids
from being correctly registered in the current session (though they install
correctly)
- Capitalize the "i" in Imported in the autogenerated descriptions.
1. resize installer window to give more room for configure and download forms
2. replace '\' with '/' in directory names to allow user to drag-and-drop
folders into the dialogue boxes that accept directories.
3. similar change in CLI for the !import_model and !convert_model commands
4. better error reporting when a model download fails due to network errors
5. put the launcher scripts into a loop so that menu reappears after
invokeai, merge script, etc exits. User can quit with "Q".
6. do not try to download fp16 of sd-ft-mse-vae, since it doesn't exist.
7. cleaned up status reporting when installing models
- Detect when install failed for some reason and print helpful error
message rather than stack trace.
- Detect window size and resize to minimum acceptable values to provide
better display of configure and install forms.
Currently translated at 81.4% (382 of 469 strings)
translationBot(ui): update translation (Russian)
Currently translated at 81.6% (382 of 468 strings)
Co-authored-by: Sergey Krashevich <svk@svk.su>
Translate-URL: https://hosted.weblate.org/projects/invokeai/web-ui/ru/
Translation: InvokeAI/Web UI
## Major Changes
The invokeai-configure script has now been refactored. The work of
selecting and downloading initial models at install time is now done by
a script named `invokeai-model-install` (module name is
`ldm.invoke.config.model_install`)
Screen 1 - adjust startup options:

Screen 2 - select SD models:
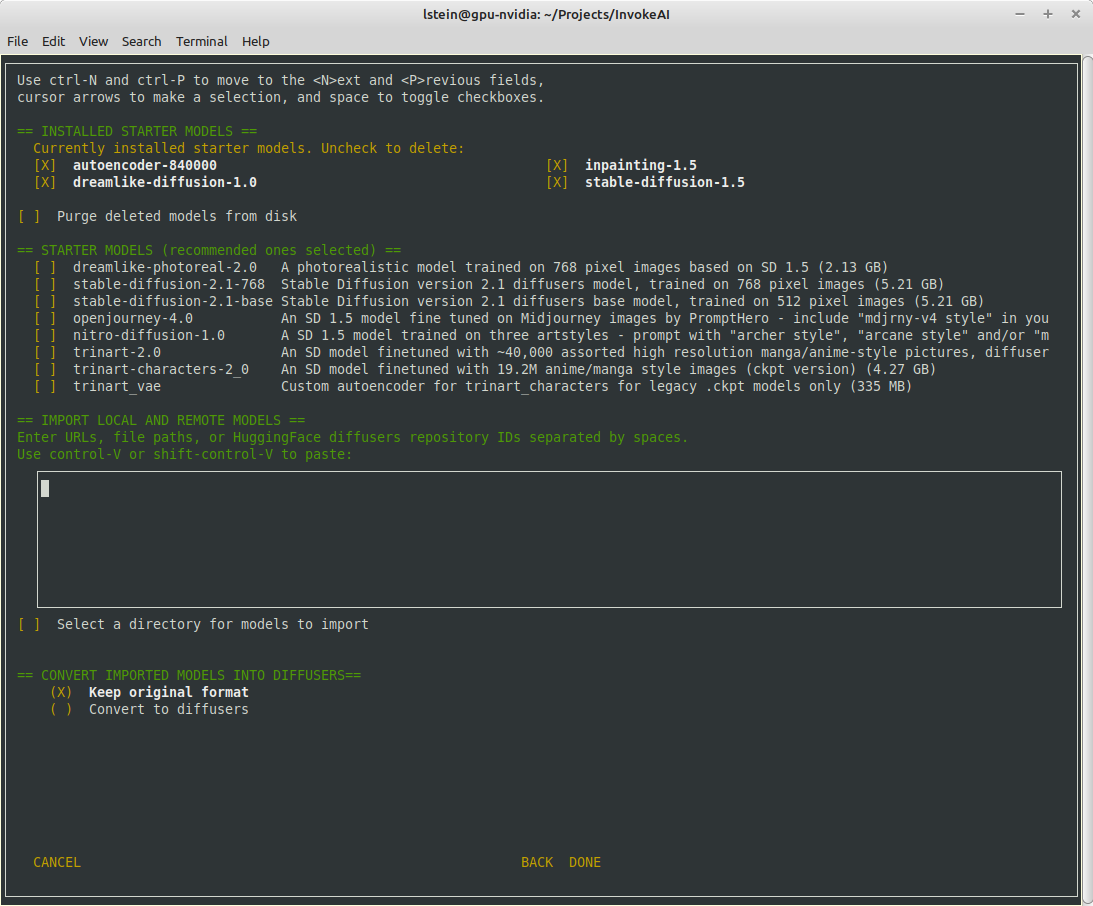
The calling arguments for `invokeai-configure` have not changed, so
nothing should break. After initializing the root directory, the script
calls `invokeai-model-install` to let the user select the starting
models to install.
`invokeai-model-install puts up a console GUI with checkboxes to
indicate which models to install. It respects the `--default_only` and
`--yes` arguments so that CI will continue to work. Here are the various
effects you can achieve:
`invokeai-configure`
This will use console-based UI to initialize invokeai.init,
download support models, and choose and download SD models
`invokeai-configure --yes`
Without activating the GUI, populate invokeai.init with default values,
download support models and download the "recommended" SD models
`invokeai-configure --default_only`
Activate the GUI for changing init options, but don't show the SD
download
form, and automatically download the default SD model (currently SD-1.5)
`invokeai-model-install`
Select and install models. This can be used to download arbitrary
models from the Internet, install HuggingFace models using their
repo_id,
or watch a directory for models to load at startup time
`invokeai-model-install --yes`
Import the recommended SD models without a GUI
`invokeai-model-install --default_only`
As above, but only import the default model
## Flexible Model Imports
The console GUI allows the user to import arbitrary models into InvokeAI
using:
1. A HuggingFace Repo_id
2. A URL (http/https/ftp) that points to a checkpoint or safetensors
file
3. A local path on disk pointing to a checkpoint/safetensors file or
diffusers directory
4. A directory to be scanned for all checkpoint/safetensors files to be
imported
The UI allows the user to specify multiple models to bulk import. The
user can specify whether to import the ckpt/safetensors as-is, or
convert to `diffusers`. The user can also designate a directory to be
scanned at startup time for checkpoint/safetensors files.
## Backend Changes
To support the model selection GUI PR introduces a new method in
`ldm.invoke.model_manager` called `heuristic_import(). This accepts a
string-like object which can be a repo_id, URL, local path or directory.
It will figure out what the object is and import it. It interrogates the
contents of checkpoint and safetensors files to determine what type of
SD model they are -- v1.x, v2.x or v1.x inpainting.
## Installer
I am attaching a zip file of the installer if you would like to try the
process from end to end.
[InvokeAI-installer-v2.3.0.zip](https://github.com/invoke-ai/InvokeAI/files/10785474/InvokeAI-installer-v2.3.0.zip)
motivation: i want to be doing future prompting development work in the
`compel` lib (https://github.com/damian0815/compel) - which is currently
pip installable with `pip install compel`.
-At some point pathlib was added to the list of imported modules and
this broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
-At some point pathlib was added to the list of imported modules and this
broken the os.path code that assembled the sample data set.
-Now fixed by replacing os.path calls with Path methods
- Disable responsive resizing below starting dimensions (you can make
form larger, but not smaller than what it was at startup)
- Fix bug that caused multiple --ckpt_convert entries (and similar) to
be written to init file.
This bug is related to the format in which we stored prompts for some time: an array of weighted subprompts.
This caused some strife when recalling a prompt if the prompt had colons in it, due to our recently introduced handling of negative prompts.
Currently there is no need to store a prompt as anything other than a string, so we revert to doing that.
Compatibility with structured prompts is maintained via helper hook.
Lots of earlier embeds use a common trigger token such as * or the
hebrew letter shan. Previously, the textual inversion manager would
refuse to load the second and subsequent embeddings that used a
previously-claimed trigger. Now, when this case is encountered, the
trigger token is replaced by <filename> and the user is informed of the
fact.
1. Fixed display crash when the number of installed models is less than
the number of desired columns to display them.
2. Added --ckpt_convert option to init file.
Enhancements:
1. Directory-based imports will not attempt to import components of diffusers models.
2. Diffuser directory imports now supported
3. Files that end with .ckpt that are not Stable Diffusion models (such as VAEs) are
skipped during import.
Bugs identified in Psychedelicious's review:
1. The invokeai-configure form now tracks the current contents of `invokeai.init` correctly.
2. The autoencoders are no longer treated like installable models, but instead are
mandatory support models. They will no longer appear in `models.yaml`
Bugs identified in Damian's review:
1. If invokeai-model-install is started before the root directory is initialized, it will
call invokeai-configure to fix the matter.
2. Fix bug that was causing empty `models.yaml` under certain conditions.
3. Made import textbox smaller
4. Hide the "convert to diffusers" options if nothing to import.
In theory, this reduces peak memory consumption by doing the conditioned
and un-conditioned predictions one after the other instead of in a
single mini-batch.
In practice, it doesn't reduce the reported "Max VRAM used for this
generation" for me, even without xformers. (But it does slow things down
by a good 18%.)
That suggests to me that the peak memory usage is during VAE decoding,
not the diffusion unet, but ymmv. It does [improve things for gogurt's
16 GB
M1](https://github.com/invoke-ai/InvokeAI/pull/2732#issuecomment-1436187407),
so it seems worthwhile.
To try it out, use the `--sequential_guidance` option:
2dded68267/ldm/invoke/args.py (L487-L492)
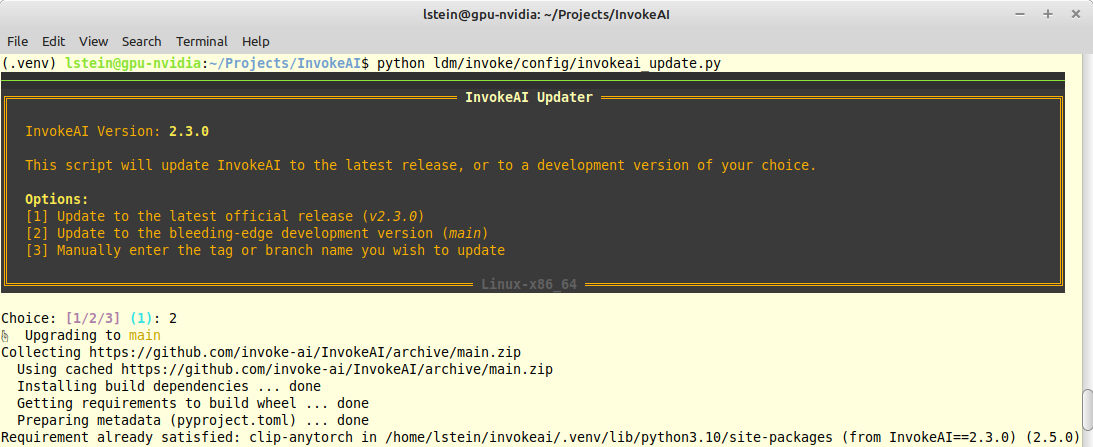
- Adds an update action to launcher script
- This action calls new python script `invokeai-update`, which prompts
user to update to latest release version, main development version, or
an arbitrary git tag or branch name.
- It then uses `pip` to update to whatever tag was specified.
The user interface (such as it is) looks like this:
- The TI script was looping over all files in the training image
directory, regardless of whether they were image files or not. This PR
adds a check for image file extensions.
-
- Closes#2715
- Fixes longstanding bug in the token vector size code which caused .pt
files to be assigned the wrong token vector length. These were then
tossed out during directory scanning.
- Fixes longstanding bug in the token vector size code which caused
.pt files to be assigned the wrong token vector length. These
were then tossed out during directory scanning.
- Fixed the test for token length; tested on several .pt and .bin files
- Also added a __main__ entrypoint for CLI.py, to make pdb debugging a
bit more convenient.
When selecting the last model of the third model-list in the
model-merging-TUI it crashed because the code forgot about the "None"
element.
Additionally it seems that it accidentally always took the wrong model
as third model if selected?
This simple fix resolves both issues.
Added symmetry to Invoke based on discussions with @damian0815. This can currently only be activated via the CLI with the `--h_symmetry_time_pct` and `--v_symmetry_time_pct` options. Those take values from 0.0-1.0, exclusive, indicating the percentage through generation at which symmetry is applied as a one-time operation. To have symmetry in either axis applied after the first step, use a very low value like 0.001.
- not sure why, but at some pont --ckpt_convert (which converts legacy checkpoints)
into diffusers in memory, stopped working due to float16/float32 issues.
- this commit repairs the problem
- also removed some debugging messages I found in passing
- Fixed the test for token length; tested on several .pt and .bin files
- Also added a __main__ entrypoint for CLI.py, to make pdb debugging a bit
more convenient.
- You can now achieve several effects:
`invokeai-configure`
This will use console-based UI to initialize invokeai.init,
download support models, and choose and download SD models
`invokeai-configure --yes`
Without activating the GUI, populate invokeai.init with default values,
download support models and download the "recommended" SD models
`invokeai-configure --default_only`
As above, but only download the default SD model (currently SD-1.5)
`invokeai-model-install`
Select and install models. This can be used to download arbitrary
models from the Internet, install HuggingFace models using their repo_id,
or watch a directory for models to load at startup time
`invokeai-model-install --yes`
Import the recommended SD models without a GUI
`invokeai-model-install --default_only`
As above, but only import the default model
A few bugs fixed.
- After the recent update to the Cancel Button, it was no longer
respecting sizing in Floating Mode and the Beta Canvas. Fixed that.
- After the recent dependency update, useHotkeys was bugging out for the
fullscreen hotkey `f`. Realized this was happening because the hotkey
was initialized in two places -- in both the gallery and the parameter
floating button. Removed it from both those places and moved it to the
InvokeTabs component. It makes sense to reside it here because it is a
global hotkey.
- Also added index `0` to the default Accordion index in state in order
to ensure that the main accordions stay open. Conveniently this works
great on all tabs. We have all the primary options in accordions so they
stay open. And as for advanced settings, the first one is always Seed
which is an important accordion, so it opens up by default.
Think there may be some more bugs. Looking in to them.
After upgrading the deps, the full screen hotkey started to bug out. I believe this was happening because it was triggered in two different components causing it to run twice. Removed it from both floating buttons and moved it to the Invoke tab. Makes sense to keep it there as it is a global hotkey.
After the recent changes the Cancel button wasn't maintaining min height in floating mode. Also the new button group was not scaling in width correctly on the Canvas Beta UI. Fixed both.
- Adds a translation status badge
- Adds a blurb about contributing a translation (we want Weblate to be
the source of truth for translations, and to avoid updating translations
directly here)
- Upgraded all dependencies
- Removed beta TS 5.0 as it conflicted with some packages
- Added types for `Array.prototype.findLast` and
`Array.prototype.findLastIndex` (these definitions are provided in TS
5.0
- Fixed fixed type import syntax in a few components
- Re-patched `redux-deep-persist` and tested to ensure the patch still
works
The husky pre-commit command was `npx run lint`, but it should run
`lint-staged`. Also, `npx` wasn't working for me. Changed the command to
`npm run lint-staged` and it all works. Extended the `lint-staged`
triggers to hit `json`, `scss` and `html`.
When encountering a bad embedding, InvokeAI was asking about reconfiguring models. This is because the embedding load error was never handled - it now is.
- Upgraded all dependencies
- Removed beta TS 5.0 as it conflicted with some packages
- Added types for `Array.prototype.findLast` and `Array.prototype.findLastIndex` (these definitions are provided in TS 5.0
- Fixed fixed type import syntax in a few components
- Re-patched `redux-deep-persist` and tested to ensure the patch still works
Model Manager lags a bit if you have a lot of models.
Basically added a fake delay to rendering the model list so the modal
has time to load first. Hacky but if it works it works.
## What was the problem/requirement? (What/Why)
Frequently, I wish to cancel the processing of images, but also want the
current image to finalize before I do. To work around this, I need to
wait until the current one finishes before pressing the cancel.
## What was the solution? (How)
* Implemented a button that allows to "Cancel after current iteration,"
which stores a state in the UI that will attempt to cancel the
processing after the current image finishes
* If the button is pressed again, while it is spinning and before the
next iteration happens, this will stop the scheduling of the cancel, and
behave as if the button was never pressed.
### Minor
* Added `.yarn` to `.gitignore` as this was an output folder produced
from following Frontend's README
### Revision 2
#### Major
* Changed from a standalone button to a context menu next to the
original cancel button. Pressing the context menu will give the
drop-down option to select which type of cancel method the user prefers,
and they can press that button for canceling in the specified type
* Moved states to system state for cross-screen and toggled cancel types
management
* Added in distribution for the target yarn version (allowing any
version of yarn to compile successfully), and updated the README to
ensure `--immutable` is passed for onboarding developers
#### Minor
* Updated `.gitignore` to ignore specific yarn folders, as specified by
their team -
https://yarnpkg.com/getting-started/qa#which-files-should-be-gitignored
## How were these changes tested?
* `yarn dev` => Server started successfully
* Manual testing on the development server to ensure the button behaved
as expected
* `yarn run build` => Success
### Artifacts
#### Revision 1
* Video showing the UI changes in action
https://user-images.githubusercontent.com/89283782/218347722-3a15ce61-2d8c-4c38-b681-e7a3e79dd595.mov
* Images showing the basic UI changes


#### Revision 2
* Video showing the UI changes in action
https://user-images.githubusercontent.com/89283782/219901217-048d2912-9b61-4415-85fd-9e8fedb00c79.mov
* Images showing the basic UI changes
(Default state)

(Drop-down context menu active)

(Scheduled cancel selected and running)

(Scheduled cancel started)

## Notes
* Using `SystemState`'s `currentStatus` variable, when the value is
`common:statusIterationComplete` is an alternative to this approach (and
would be more optimal as it should prevent the next iteration from even
starting), but since the names are within the translations, rather than
an enum or other type, this method of tracking the current iteration was
used instead.
* `isLoading` on `IAIIconButton` caused the Icon Button to also be
disabled, so the current solution works around that with conditionally
rendering the icon of the button instead of passing that value.
* I don't have context on the development expectation for `dist` folder
interactions (and couldn't find any documentation outside of the
`.gitignore` mentioning that the folder should remain. Let me know if
they need to be modified a certain way.
- The checkpoint conversion script was generating diffusers models with
the safety checker set to null. This resulted in models that could not
be merged with ones that have the safety checker activated.
- This PR fixes the issue by incorporating the safety checker into all
1.x-derived checkpoints, regardless of user's nsfw_checker setting.
- The checkpoint conversion script was generating diffusers models
with the safety checker set to null. This resulted in models
that could not be merged with ones that have the safety checker
activated.
- This PR fixes the issue by incorporating the safety checker into
all 1.x-derived checkpoints, regardless of user's nsfw_checker setting.
Also tighten up the typing of `device` attributes in general.
Fixes
> ValueError: Expected a torch.device with a specified index or an
integer, but got:cuda
Weblate's first PR was it attempting to fix some translation issues we
had overlooked!
It wanted to remove some keys which it did not see in our translation
source due to typos.
This PR instead corrects the key names to resolve the issues.
# Weblate Translation
After doing a full integration test of 3 translation service providers
on my fork of InvokeAI, we have chosen
[Weblate](https://hosted.weblate.org). The other two viable options were
[Crowdin](https://crowdin.com/) and
[Transifex](https://www.transifex.com/).
Weblate was the choice because its hosted service provides a very solid
UX / DX, can scale as much as we may ever need, is FOSS itself, and
generously offers free hosted service to other libre projects like ours.
## How it works
Weblate hosts its own fork of our repo and establishes a kind of
unidirectional relationship between our repo and its fork.
### InvokeAI --> Weblate
The `invoke-ai/InvokeAI` repo has had the Weblate GitHub app added to
it. This app watches for changes to our translation source
(`invokeai/frontend/public/locales/en.json`) and then updates the
Weblate fork. The Weblate UI then knows there are new strings to be
translated, or changes to be made.
### Translation
Our translators can then update the translations on the Weblate UI. The
plan now is to invite individual community members who have expressed
interest in maintaining a language or two and give them access to the
app. We can also open the doors to the general public if desired.
### Weblate --> InvokeAI
When a translation is ready or changed, the system will make a PR to
`main`. We have a substantial degree of control over this and will
likely manually trigger these PRs instead of letting them fire off
automatically.
Once a PR is merged, we will still need to rebuild the web UI. I think
we can set things up so that we only need the rebuild when a totally new
language is added, but for now, we will stick to this relatively simple
setup.
## This PR
This PR sets up the web UI's translation stuff to work with Weblate:
- merged each locale into a single file
- updated the i18next config and UI to work with this simpler file
structure
- update our eslint and prettier rules to ensure the locale files have
the same format as what Weblate outputs (`tabWidth: 4`)
- added a thank you to Weblate in our README
Once this is merged, I'll link Weblate to `main` and do a couple tests
to ensure it is all working as expected.
This fixes a few cosmetic bugs in the merge models console GUI:
1) Fix the minimum and maximum ranges on alpha. Was 0.05 to 0.95. Now
0.01 to 0.99.
2) Don't show the 'add_difference' interpolation method when 2 models
selected, or the other three methods when three models selected
## Convert v2 models in CLI
- This PR introduces a CLI prompt for the proper configuration file to
use when converting a ckpt file, in order to support both inpainting
and v2 models files.
- When user tries to directly !import a v2 model, it prints out a proper
warning that v2 ckpts are not directly supported and converts it into a
diffusers model automatically.
The user interaction looks like this:
```
(stable-diffusion-1.5) invoke> !import_model /home/lstein/graphic-art.ckpt
Short name for this model [graphic-art]: graphic-art-test
Description for this model [Imported model graphic-art]: Imported model graphic-art
What type of model is this?:
[1] A model based on Stable Diffusion 1.X
[2] A model based on Stable Diffusion 2.X
[3] An inpainting model based on Stable Diffusion 1.X
[4] Something else
Your choice: [1] 2
```
In addition, this PR enhances the bulk checkpoint import function. If a
directory path is passed to `!import_model` then it will be scanned for
`.ckpt` and `.safetensors` files. The user will be prompted to import
all the files found, or select which ones to import.
Addresses
https://discord.com/channels/1020123559063990373/1073730061380894740/1073954728544845855
- fix alpha slider to show values from 0.01 to 0.99
- fix interpolation list to show 'difference' method for 3 models,
- and weighted_sum, sigmoid and inverse_sigmoid methods for 2
Porting over as many usable options to slider as possible.
- Ported Face Restoration settings to Sliders.
- Ported Upscale Settings to Sliders.
- Ported Variation Amount to Sliders.
- Ported Noise Threshold to Sliders <-- Optimized slider so the values
actually make sense.
- Ported Perlin Noise to Sliders.
- Added a suboption hook for the High Res Strength Slider.
- Fixed a couple of small issues with the Slider component.
- Ported Main Options to Sliders.
- Corrected error that caused --full-precision argument to be ignored
when models downloaded using the --yes argument.
- Improved autodetection of v1 inpainting files; no longer relies on the
file having 'inpaint' in the name.
* new OffloadingDevice loads one model at a time, on demand
* fixup! new OffloadingDevice loads one model at a time, on demand
* fix(prompt_to_embeddings): call the text encoder directly instead of its forward method
allowing any associated hooks to run with it.
* more attempts to get things on the right device from the offloader
* more attempts to get things on the right device from the offloader
* make offloading methods an explicit part of the pipeline interface
* inlining some calls where device is only used once
* ensure model group is ready after pipeline.to is called
* fixup! Strategize slicing based on free [V]RAM (#2572)
* doc(offloading): docstrings for offloading.ModelGroup
* doc(offloading): docstrings for offloading-related pipeline methods
* refactor(offloading): s/SimpleModelGroup/FullyLoadedModelGroup
* refactor(offloading): s/HotSeatModelGroup/LazilyLoadedModelGroup
to frame it is the same terms as "FullyLoadedModelGroup"
---------
Co-authored-by: Damian Stewart <null@damianstewart.com>
- filter paths for `build-container.yml` and `test-invoke-pip.yml`
- add workflow to pass required checks on PRs with `paths-ignore`
- this triggers if `test-invoke-pip.yml` does not
- fix "CI checks on main link" in `/README.md`
- filter paths for `build-container.yml` and `test-invoke-pip.yml`
- add workflow to pass required checks on PRs with `paths-ignore`
- this triggers if `test-invoke-pip.yml` does not
- fix "CI checks on main link" in `/README.md`
Assuming that mixing `"literal strings"` and `{'JSX expressions'}`
throughout the code is not for a explicit reason but just a result IDE
autocompletion, I changed all props to be consistent with the
conventional style of using simple string literals where it is
sufficient.
This is a somewhat trivial change, but it makes the code a little more
readable and uniform
- quashed multiple bugs in model conversion and importing
- found old issue in handling of resume of interrupted downloads
- will require extensive testing
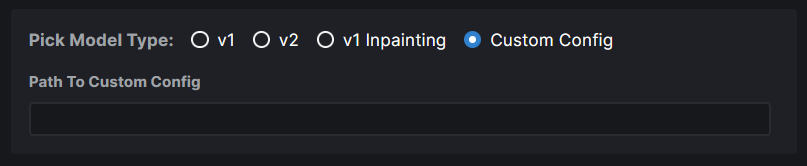
### WebUI Model Conversion
**Model Search Updates**
- Model Search now has a radio group that allows users to pick the type
of model they are importing. If they know their model has a custom
config file, they can assign it right here. Based on their pick, the
model config data is automatically populated. And this same information
is used when converting the model to `diffusers`.
- Files named `model.safetensors` and
`diffusion_pytorch_model.safetensors` are excluded from the search
because these are naming conventions used by diffusers models and they
will end up showing on the list because our conversion saves safetensors
and not bin files.
**Model Conversion UI**
- The **Convert To Diffusers** button can be found on the Edit page of
any **Checkpoint Model**.
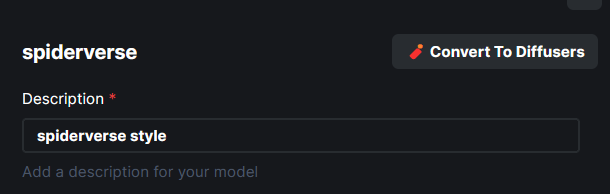
- When converting the model, the entire process is handled
automatically. The corresponding config while at the time of the Ckpt
addition is used in the process.
- Users are presented with the choice on where to save the diffusers
converted model - same location as the ckpt, InvokeAI models root folder
or a completely custom location.
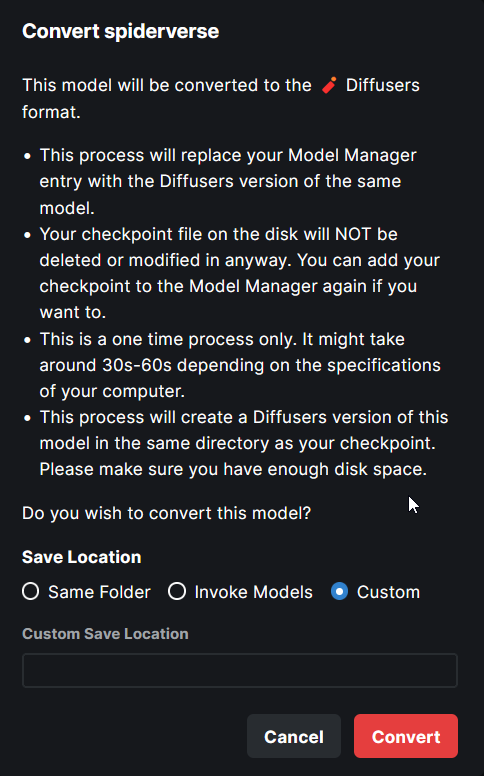
- When the model is converted, the checkpoint entry is replaced with the
diffusers model entry. A user can readd the ckpt if they wish to.
---
More or less done. Might make some minor UX improvements as I refine
things.
Tensors with diffusers no longer have to be multiples of 8. This broke Perlin noise generation. We now generate noise for the next largest multiple of 8 and return a cropped result. Fixes#2674.
`generator` now asks `InvokeAIDiffuserComponent` to do postprocessing work on latents after every step. Thresholding - now implemented as replacing latents outside of the threshold with random noise - is called at this point. This postprocessing step is also where we can hook up symmetry and other image latent manipulations in the future.
Note: code at this layer doesn't need to worry about MPS as relevant torch functions are wrapped and made MPS-safe by `generator.py`.
1. Now works with sites that produce lots of redirects, such as CIVITAI
2. Derive name of destination model file from HTTP Content-Disposition header,
if present.
3. Swap \\ for / in file paths provided by users, to hopefully fix issues with
Windows.
This PR adds a new attributer to ldm.generate, `embedding_trigger_strings`:
```
gen = Generate(...)
strings = gen.embedding_trigger_strings
strings = gen.embedding_trigger_strings()
```
The trigger strings will change when the model is updated to show only
those strings which are compatible with the current
model. Dynamically-downloaded triggers from the HF Concepts Library
will only show up after they are used for the first time. However, the
full list of concepts available for download can be retrieved
programatically like this:
```
from ldm.invoke.concepts_lib import HuggingFAceConceptsLibrary
concepts = HuggingFaceConceptsLibrary()
trigger_strings = concepts.list_concepts()
```
I have added the arabic locale files. There need to be some
modifications to the code in order to detect the language direction and
add it to the current document body properties.
For example we can use this:
import { appWithTranslation, useTranslation } from "next-i18next";
import React, { useEffect } from "react";
const { t, i18n } = useTranslation();
const direction = i18n.dir();
useEffect(() => {
document.body.dir = direction;
}, [direction]);
This should be added to the app file. It uses next-i18next to
automatically get the current language and sets the body text direction
(ltr or rtl) depending on the selected language.
## Provide informative error messages when TI and Merge scripts have
insufficient space for console UI
- The invokeai-ti and invokeai-merge scripts will crash if there is not
enough space in the console to fit the user interface (even after
responsive formatting).
- This PR intercepts the errors and prints a useful error message
advising user to make window larger.
1. The invokeai-configure script has now been refactored. The work of
selecting and downloading initial models at install time is now done
by a script named invokeai-initial-models (module
name is ldm.invoke.config.initial_model_select)
The calling arguments for invokeai-configure have not changed, so
nothing should break. After initializing the root directory, the
script calls invokeai-initial-models to let the user select the
starting models to install.
2. invokeai-initial-models puts up a console GUI with checkboxes to
indicate which models to install. It respects the --default_only
and --yes arguments so that CI will continue to work.
3. User can now edit the VAE assigned to diffusers models in the CLI.
4. Fixed a bug that caused a crash during model loading when the VAE
is set to None, rather than being empty.
- The invokeai-ti and invokeai-merge scripts will crash if there is not enough space
in the console to fit the user interface (even after responsive formatting).
- This PR intercepts the errors and prints a useful error message advising user to
make window larger.
- fix unused variables and f-strings found by pyflakes
- use global_converted_ckpts_dir() to find location of diffusers
- fixed bug in model_manager that was causing the description of converted
models to read "Optimized version of {model_name}'
Strategize slicing based on free [V]RAM when not using xformers. Free [V]RAM is evaluated at every generation. When there's enough memory, the entire generation occurs without slicing. If there is not enough free memory, we use diffusers' sliced attention.
- Adds an update action to launcher script
- This action calls new python script `invokeai-update`, which prompts
user to update to latest release version, main development version,
or an arbitrary git tag or branch name.
- It then uses `pip` to update to whatever tag was specified.
Some of the core features of this PR include:
- optional push image to dockerhub (will be skipped in repos which
didn't set it up)
- stop using the root user at runtime
- trigger builds also for update/docker/* and update/ci/docker/*
- always cache image from current branch and main branch
- separate caches for container flavors
- updated comments with instructions in build.sh and run.sh
This commit cleans up the code that did bulk imports of legacy model
files. The code has been refactored, and the user is now offered the
option of importing all the model files found in the directory, or
selecting which ones to import.
Users can now pick the folder to save their diffusers converted model. It can either be the same folder as the ckpt, or the invoke root models folder or a totally custom location.
Fixed a couple of bugs:
1. The original config file for the ckpt file is derived from the entry in
`models.yaml` rather than relying on the user to select. The implication
of this is that V2 ckpt models need to be assigned `v2-inference-v.yaml`
when they are first imported. Otherwise they won't convert right. Note
that currently V2 ckpts are imported with `v1-inference.yaml`, which
isn't right either.
2. Fixed a backslash in the output diffusers path, which was causing
load failures on Linux.
Remaining issues:
1. The radio buttons for selecting the model type are
nonfunctional. It feels to me like these should be moved into the
dialogue for importing ckpt/safetensors files, because this is
where the algorithm needs help from the user.
2. The output diffusers model is written into the same directory as
the input ckpt file. The CLI does it differently and stores the
diffusers model in `ROOTDIR/models/converted-ckpts`. We should
settle on one way or the other.
Converted the picker options to a Radio Group and also updated the backend to use the appropriate config if it is a v2 model that needs to be converted.
- This PR introduces a CLI prompt for the proper configuration file to
use when converting a ckpt file, in order to support both inpainting
and v2 models files.
- When user tries to directly !import a v2 model, it prints out a proper
warning that v2 ckpts are not directly supported.
## What was the problem/requirement? (What/Why)
* Windows location for the Python environment activate location is
currently incorrect
* Due to this, this command will fail for Windows-based users
* The contributing link within the `Developer Install` sections leads to
a [404](https://invoke-ai.github.io/index.md#Contributing)
* `Developer Install`'s numbered list currently lists 1, 1, 2, . . .
## What was the solution? (How)
* Changed the location of Windows script based on actual location -
[reference](https://docs.python.org/3/library/venv.html)
* Moved the link to point to one directory higher -- the main index.md
* Minor format adjustments to allow for the numbered list to appear as
expected
## How were these changes tested?
* `mkdocs serve` => Verified on local server that the changes reflected
as expected
## Notes
Contributing mentions to set the upstream towards the `development`
branch, but that branch has been untouched for several months, so I've
pointed to the `main` branch. Let me know if we need to switch to a
different one.
…odels
- If CLI asked to convert the currently loaded model, the model would
crash on the first rendering. CLI will now refuse to convert a model
loaded in memory (probably a good idea in any case).
- CLI will offer the `v1-inpainting-inference.yaml` as the configuration
file when importing an inpainting a .ckpt or .safetensors file that has
"inpainting" in the name. Otherwise it offers `v1-inference.yaml` as the
default.
rather than bypassing any path with diffusers in it, im specifically bypassing model.safetensors and diffusion_pytorch_model.safetensors both of which should be diffusers files in most cases.
- If CLI asked to convert the currently loaded model, the model would crash
on the first rendering. CLI will now refuse to convert a model loaded
in memory (probably a good idea in any case).
- CLI will offer the `v1-inpainting-inference.yaml` as the configuration
file when importing an inpainting a .ckpt or .safetensors file that
has "inpainting" in the name. Otherwise it offers `v1-inference.yaml`
as the default.
Found a couple of places where the formatting was messed up. I also
added a "Quick Start Guide" to the README for people who encounter
InvokeAI through PyPi. It features the PyPi install!
pulling in denoising support from upstream (its already there, invoke
just isn't using it). I've enabled this as a command line argument as
construction of the ESRGAN handler happens once. Ideally this would be a
UI option that could be adjusted for each upscaling task. Unfortunately
that is beyond my current level of InvokeAI-foo.
Upstream reference is here, starting on line 99 "use dni to control the
denoise strength"
https://github.com/xinntao/Real-ESRGAN/blob/master/inference_realesrgan.py
- This makes the launcher options menu on Windows look and act the same
as the Linux/Mac launcher, which previously was lacking the command-line
help option and didn't list item (6) as an option.
Work in progress. I am reviewing and updating the documentation for
2.3.0. The following sections need to be done:
- [x] index.md
- [x] installation/010_INSTALL_AUTOMATED.md
- [x] installation/020_INSTALL_MANUAL.md
- [x] installation/030_INSTALL_CUDA_AND_ROCM.md (needs to be written
from scratch)
- [x] installation/040_INSTALL_DOCKER.md
- [x] installation/050_INSTALLING_MODELS.md
- [x] features/CLI.md
- [x] features/WEB.md
Using Windows 10 I found I needed to use double backslashes to import a
new model, when using single backslash the output would say
"e:_ProjectsCodemodelsldmstable-diffusion-model-to-import.ckpt is
neither the path to a .ckpt file nor a diffusers repository id. Can't
import." This added tip in the documentation will help Windows users
overcome this.
- The following were supposed to be equivalent, but the latter crashes:
```
invoke> banana sushi
invoke> --prompt="banana sushi"
```
This PR fixes the problem.
- Fixes#2548
- This makes the launcher options menu on Windows look and act the same
as the Linux/Mac launcher, which previously was lacking the command-line
help option and didn't list item (6) as an option.
The `useHotkeys` hook for this hotkey didn't have `isConnected` or `isProcessing` in its dependencies array. This prevented `handleDelete()` from dispatching the delete request.
This is an early draft of a codeowners file for InvokeAI. It has plenty
of gaps in it. Please use this PR to add yourself and others where
appropriate.
- The following were supposed to be equivalent, but the latter crashes:
```
invoke> banana sushi
invoke> --prompt="banana sushi"
```
This PR fixes the problem.
- Fixes#2548
This adds some platform-specific help messages to the installer welcome
screen:
- For Windows, the message encourages them to install VC++ core
libraries and the registry long name patch
- For MacOSX, the message warns the user to install the XCode tools.
I found I needed to use double backslashes to import a new model, when using single backslash the output would say "e:_ProjectsCodemodelsldmstable-diffusion-model-to-import.ckpt is neither the path to a .ckpt file nor a diffusers repository id. Can't import." This added tip in the documentation will help Windows users overcome this.
- `eslint` and `prettier` configs
- `husky` to format and lint via pre-commit hook
- `babel-plugin-transform-imports` to treeshake `lodash` and other packages if needed
Lints and formats codebase.
`options` slice was huge and managed a mix of generation parameters and general app settings. It has been split up:
- Generation parameters are now in `generationSlice`.
- Postprocessing parameters are now in `postprocessingSlice`
- UI related things are now in `uiSlice`
There is probably more to be done, like `gallerySlice` perhaps should only manage internal gallery state, and not if the gallery is displayed.
Full-slice selectors have been made for each slice.
Other organisational tweaks.
Previously conversions of .ckpt and .safetensors files to diffusers
models were failing with channel mismatch errors. This is corrected
with this PR.
- The model_manager convert_and_import() method now accepts the path
to the checkpoint file's configuration file, using the parameter
`original_config_file`. For inpainting files this should be set to
the full path to `v1-inpainting-inference.yaml`.
- If no configuration file is provided in the call, then the presence
of an inpainting file will be inferred at the
`ldm.ckpt_to_diffuser.convert_ckpt_to_diffUser()` level by looking
for the string "inpaint" in the path. AUTO1111 does something
similar to this, but it is brittle and not recommended.
- This PR also changes the model manager model_names() method to return
the model names in case folded sort order.
- `eslint` and `prettier` configs
- `husky` to format and lint via pre-commit hook
- `babel-plugin-transform-imports` to treeshake `lodash` and other packages if needed
Lints and formats codebase.
`options` slice was huge and managed a mix of generation parameters and general app settings. It has been split up:
- Generation parameters are now in `generationSlice`.
- Postprocessing parameters are now in `postprocessingSlice`
- UI related things are now in `uiSlice`
There is probably more to be done, like `gallerySlice` perhaps should only manage internal gallery state, and not if the gallery is displayed.
Full-slice selectors have been made for each slice.
Other organisational tweaks.
# enhance model_manager support for converting inpainting ckpt files
Previously conversions of .ckpt and .safetensors files to diffusers
models were failing with channel mismatch errors. This is corrected
with this PR.
- The model_manager convert_and_import() method now accepts the path
to the checkpoint file's configuration file, using the parameter
`original_config_file`. For inpainting files this should be set to
the full path to `v1-inpainting-inference.yaml`.
- If no configuration file is provided in the call, then the presence
of an inpainting file will be inferred at the
`ldm.ckpt_to_diffuser.convert_ckpt_to_diffUser()` level by looking
for the string "inpaint" in the path. AUTO1111 does something
similar to this, but it is brittle and not recommended.
- This PR also changes the model manager model_names() method to return
the model names in case folded sort order.
- Diffusers Sampler list is independent from CKPT Sampler list. And the
app will load the correct list based on what model you have loaded.
- Isolated the activeModelSelector coz this is used in multiple places.
- Possible fix to the white screen bug that some users face. This was
happening because of a possible null in the active model list
description tag. Which should hopefully now be fixed with the new
activeModelSelector.
I'll keep tabs on the last thing. Good to go.
For the torch and torchvision libraries **only**, the installer will now
pass the pip `--force-reinstall` option. This is intended to fix issues
with the user getting a CPU-only version of torch and then not being
able to replace it.
Previously conversions of .ckpt and .safetensors files to diffusers
models were failing with channel mismatch errors. This is corrected
with this PR.
- The model_manager convert_and_import() method now accepts the path
to the checkpoint file's configuration file, using the parameter
`original_config_file`. For inpainting files this should be set to
the full path to `v1-inpainting-inference.yaml`.
- If no configuration file is provided in the call, then the presence
of an inpainting file will be inferred at the
`ldm.ckpt_to_diffuser.convert_ckpt_to_diffUser()` level by looking
for the string "inpaint" in the path. AUTO1111 does something
similar to this, but it is brittle and not recommended.
- This PR also changes the model manager model_names() method to return
the model names in case folded sort order.
test-invoke-pip.yml:
- enable caching of pip dependencies in `actions/setup-python@v4`
- add workflow_dispatch trigger
- fix indentation in concurrency
- set env `PIP_USE_PEP517: '1'`
- cache python dependencies
- remove models cache (since we currently use 190.96 GB of 10 GB while I
am writing this)
- add step to set `INVOKEAI_OUTDIR`
- add outdir arg to invokeai
- fix path in archive results
model_manager.py:
- read files in chunks when calculating sha (windows runner is crashing
otherwise)
- help users to avoid glossing over per-platform prerequisites
- better link colouring
- update link to community instructions to install xcode command line tools
- Issue is that if insufficient diffusers models are defined in
models.yaml the frontend would ungraciously crash.
- Now it emits appropriate error messages telling user what the problem
is.
- Issue is that if insufficient diffusers models are defined in
models.yaml the frontend would ungraciously crash.
- Now it emits appropriate error messages telling user what the problem
is.
- dont build frontend since complications with QEMU
- set pip cache dir
- add pip cache to all pip related build steps
- dont lock pip cache
- update dockerignore to exclude uneeded files
env.sh:
- move check for torch to CONVTAINER_FLAVOR detection
Dockerfile
- only mount `/var/cache/apt` for apt related steps
- remove `docker-clean` from `/etc/apt/apt.conf.d` for BuildKit cache
- remove apt-get clean for BuildKit cache
- only copy frontend to frontend-builder
- mount `/usr/local/share/.cache/yarn` in frountend-builder
- separate steps for yarn install and yarn build
- build pytorch in pyproject-builder
build.sh
- prepare for installation with extras
This change allows passing a directory with multiple models in it to be
imported.
Ensures that diffusers directories will still work.
Fixed up some minor type issues.
This allows the --log_tokenization option to be used as a command line
argument (or from invokeai.init), making it possible to view
tokenization information in the terminal when using the web interface.
- This fixes an edge case crash when the textual inversion frontend
tried to display the list of models and no default model defined
in models.yaml
Co-authored-by: Jonathan <34005131+JPPhoto@users.noreply.github.com>
This allows the --log_tokenization option to be used as a command line argument (or from invokeai.init), making it possible to view tokenization information in the terminal when using the web interface.
- Rename configure_invokeai.py to invokeai_configure.py to be consistent
with installed script name
- Remove warning message about half-precision models not being available
during the model download process.
- adjust estimated file size reported by configure
- guesstimate disk space needed for "all" models
- fix up the "latest" tag to be named 'v2.3-latest'
- To ensure a clean environment, the installer will now detect whether a
previous .venv exists in the install location, and move it to .venv-backup
before creating a fresh .venv.
- Any previous .venv-backup is deleted.
- User is informed of process.
- Rename configure_invokeai.py to invokeai_configure.py to be
consistent with installed script name
- Remove warning message about half-precision models not being
available during the model download process.
- adjust estimated file size reported by configure
- guesstimate disk space needed for "all" models
- fix up the "latest" tag to be named 'v2.3-latest'
`torch` wasn't seeing the environment variable. I suspect this is
because it was imported before the variable was set, so was running with
a different environment.
Many `torch` ops are supported on MPS so this wasn't noticed
immediately, but some samplers like k_dpm_2 still use unsupported
operations and need this fallback.
This PR forces the installer to install the official torch-cu117 wheel
from download.torch.org, rather than relying on PyPi.org to return the
correct version. It ought to correct the problems that some people have
experienced with cuda support not being installed.
1. The convert module was converting ckpt models into
StableDiffusionGeneratorPipeline objects for use in-memory, but then
when saved to disk created files that could not be merged with
StableDiffusionPipeline models. I have added a flag that selects which
pipeline class to return, so that both in-memory and disk conversions
work properly.
2. This PR also fixes an issue with `invoke.sh` not using the correct
path for the textual inversion and merge scripts.
3. Quench nags during the merge process about the safety checker being
turned off.
`torch` wasn't seeing the environment variable. I suspect this is because it was imported before the variable was set, so was running with a different environment.
Many `torch` ops are supported on MPS so this wasn't noticed immediately, but some samplers like k_dpm_2 still use unsupported operations and need this fallback.
* remove non maintained Dockerfile
* adapt Docker related files to latest changes
- also build the frontend when building the image
- skip user response if INVOKE_MODEL_RECONFIGURE is set
- split INVOKE_MODEL_RECONFIGURE to support more than one argument
* rename `docker-build` dir to `docker`
* update build-container.yml
- rename image to invokeai
- add cpu flavor
- add metadata to build summary
- enable caching
- remove build-cloud-img.yml
* fix yarn cache path, link copyjob
Crashes would occur in the invokeai-configure script if no HF token
was found in cache and the user declines to provide one when prompted.
The reason appears to be that on Linux systems getpass_asterisk()
raises an EOFError when no input is provided
On windows10, getpass_asterisk() does not raise the EOFError, but
returns an empty string instead. This patch detects this and raises
the exception so that the control logic is preserved.
if reinstalling over an existing installation where the .venv was
created with symlinks to system python instead of copies of the python
executable, the installer would raise a `SameFileError`, because it
would attempt to copy Python over itself. This fixes the issue.
Copying the executable is still preferred for new environments, because
this guarantees the stable Python version.
- fixes bug in finding the source of the configs dir;
- updates the docs for manual install to clarify the preference to
keeping the `.venv` inside the runtime dir, and the caveat/extra steps
required if done otherwise
if reinstalling over an existing installation where the .venv
was created with symlinks to system python instead of copies
of the python executable, the installer would raise a
SameFileError, because it would attempt to copy Python over
itself. This fixes the issue.
- Added modest adaptive behavior; if the screen is wide enough the three
checklists of models will be arranged in a horizontal row.
- Added color support
## Summary
This PR rewrites the core of the installer in Python for cross-platform
compatibility. Filesystem path manipulation, platform/arch decisions and
various edge cases are handled in a more convenient fashion. The
original `install.bat.in`/`install.sh.in` scripts are kept as
entrypoints for their respective OSs, but only serve as thin wrappers to
the Python module.
In addition, it:
- builds and **packages the .whl with the installer**, so that
downloading a versioned installer will guarantee installation of the
same version of the application.
- updates shell entrypoints:
- new commands are `invokeai`, `invokeai-configure`, `invokeai-ti`,
`invokeai-merge`.
- these commands will be available in the activated `.venv` or via the
launch scripts
- `invoke.py` and `configure_invokeai.py` scripts are deprecated but
kept around for backwards compatibility and keeping users' surprise to a
minimum.
- introduces a new `ldm/invoke/config` package and moves the
`configure_invokeai` script into it. Similarly, movers Textual Inversion
script and TUI to `ldm/invoke/training`.
- moves the `configs` directory into the `ldm/invoke/config` package for
easy distribution.
- updates documentation to reflect all of the above changes
- fixes a failing test
- reduces wheel size to 3MB (from 27MB) by excluding unnecessary image
files under `assets`
⚠️ self-updating functionality and ability to install arbitrary
versions are still WIP. For now we can recommend downloading and running
the installer for a specific version as desired.
## Testing the source install
From the cloned source, check out this branch, and:
`$ python3 installer/main.py --root <path_to_destination>`
Also try:
`$ python3 installer/main.py ` - will prompt for paths
`$ python3 installer/main.py --yes` - will not prompt for any input
- try to combine the `--yes` and `--root` options
- try to install in destinations with "quirky" paths, such as paths
containing spaces in the directory name, etc.
## Testing the packaged install ("Automated Installer"):
Download the
[InvokeAI-installer-v2.3.0+a0.zip](https://github.com/invoke-ai/InvokeAI/files/10533913/InvokeAI-installer-v2.3.0%2Ba0.zip)
file, unzip it, and run the install script for your platform (preferably
in a terminal window)
OR make your own: from the cloned source, check out this branch, and:
```
cd installer
./create_installer.sh
# (do NOT tag/push when prompted! just say "no")
```
This will create the installation media:
`InvokeAI-installer-v2.3.0+a0.zip`. The installer is now
*platform-agnostic* - meaning, both Windows and *nix install resources
are packaged together.
Copy it somewhere as if it had been downloaded from the internet. Unzip
the file, enter the created `InvokeAI-Installer` directory, and run
`install.sh` or `install.bat` as applicable your platform.
⚠️ NOTE!!! `install.sh` accepts the same arguments as are
applicable to the Python script, i.e. you can `install.sh --yes --root
....`. This is NOT yet supported by the Windows `.bat` script. Only
interactive installation is supported on Windows. (this is still a
TODO).
* refactor ckpt_to_diffuser to allow converted pipeline to remain in memory
- This idea was introduced by Damian
- Note that although I attempted to use the updated HuggingFace module
pipelines/stable_diffusion/convert_from_ckpt.py, it was unable to
convert safetensors files for reasons I didn't dig into.
- Default is to extract EMA weights.
* add --ckpt_convert option to load legacy ckpt files as diffusers models
- not quite working - I'm getting artifacts and glitches in the
converted diffuser models
- leave as draft for time being
* do not include safety checker in converted files
* add ability to control which vae is used
API now allows the caller to pass an external VAE model to the
checkpoint conversion process. In this way, if an external VAE is
specified in the checkpoint's config stanza, this VAE will be used
when constructing the diffusers model.
Tested with both regular and inpainting 1.X models.
Not tested with SD 2.X models!
---------
Co-authored-by: Jonathan <34005131+JPPhoto@users.noreply.github.com>
Co-authored-by: Damian Stewart <null@damianstewart.com>
This PR changes the codeowner for the installer directory from
@tildebyte to @ebr due to the former's time commitments.
Further reorganization of the codeowners is pending.
1. only load triton on linux machines
2. require pip >= 23.0 so that editable installs can run without setup.py
3. model files default to SD-1.5, not 2.1
4. use diffusers model of inpainting rather than ckpt
5. selected a new set of initial models based on # of likes at huggingface
- launcher scripts are installed *before* the configure script runs,
so that if something goes wrong in the configure script, the user
can run invoke.{sh,bat} and get the option to re-run configure
- fixed typo in invoke.sh which misspelled name of invokeai-configure
Draft PRs are triggering actions on every commit (except
`test-invoke-pip.yml`).
I've added a conditional to each job to only run when the PR is not a
draft.
(maybe there is a reason we are running all applicable workflows on
draft PRs?)
- also remove conda related things
- rename `invoke` to `invokeai`
- rename `configure_invokeai` to `invokeai-configure`
- rename venv back to common `.venv` but add `--prompt InvokeAI`
- remove outdated information
A new infill method, **solid:** solid color. currently using middle
gray.
Fixes#2417
It seems like the runwayml inpainting model specifically expects those
masked areas to be blanked out like this.
I haven't tried the SD 2.0 inpainting model with it yet.
Otherwise the model seems too reluctant to change these areas, even
though the mask channel should allow it to.
This makes the solid infill method proposed by #2441 less necessary,
though I think there's still a place for an infill method that is faster
than patchmatch and more predictable than tiles.
Even with #2441, this PR is still useful because it influences all areas
to be painted, not just the infill area.
Fixes#2417
- implement the following pattern for finding data files under both
regular and editable install conditions:
import invokeai.foo.bar as bar
path = bar.__path__[0]
- this *seems* to work reliably with Python 3.9. Testing on 3.10 needs
to be performed.
- fixes a spurious "unknown model name" error when trying to edit the
short name of an existing model.
- relaxes naming requirements to include the ':' and '/' characters
in model names
1) Downgrade numpy to avoid dependency conflict with numba
2) Move all non ldm/invoke files into `invokeai`. This includes assets, backend, frontend, and configs.
3) Fix up way that the backend finds the frontend and the generator finds the NSFW caution.png icon.
if running `python3 installer/main.py` from the source distribution,
it would fail because it expected to find a wheel.
this PR tries to perform a source install by going one level up the directory
tree and checking for `pyproject.toml` and `ldm` directory entries to
confirm (to a degree) that this is an InvokeAI distribution
* Update --hires_fix
Change `--hires_fix` to calculate initial width and height based on the model's resolution (if available) and with a minimum size.
- install.sh is now a thin wrapper around the pythonized install script
- install.bat not done yet - to follow
- user messaging is tailored to the current platform (paste shortcuts, file paths, etc)
- emit invoke.sh/invoke.bat scripts to the runtime dir
- improve launch scripts (add help option, etc)
- only emit the platform-specific scripts
if the config directory is missing, initialize it using the standard
process of copying it over, instead of failing to create the config file
this can happen if the user is re-running the config script in a directory which
already has the init file, but no configs dir
the 'setup.py install' method is deprecated in favour of a
build-system independent format: https://peps.python.org/pep-0517/
this is needed to install dependencies that don't have a pyproject.toml
file (only setup.py) in a forward-compatible way
This allows reliable distribution of the initial 'configs' directory
with the Python package, and enables the configuration script to be running
from anywhere, as long as the virtual environment is available on the sys.path
There is a race condition affecting the 'tempfile' module on Windows.
A PermissionsError is raised when cleaning up the temp dir
Python3.10 introduced a flag to suppress this error.
Windows + Python3.9 users will receive an unpleasant stack trace for now
The original textual inversion script in scripts is now superseded. The
replacement can be found in ldm/invoke/textual_inversion.py and is a
merging of the command line and front end scripts. After running `pip
install -e .` there will be a `textual_inversion` command on your path.
You can activate the front end this way:
`textual_inversion -gui`
Adds double-click to reset canvas view to 100%.
- Adds hook to manage single and double clicks
- Single Click `Reset Canvas View` --> scale to fit, no change to
current behaviour
- Double Click `Reset Canvas View` --> set scale to 1
Testing suggests that the diffusers versions of Waifu-1.4 anything-v4.0
require the `sd-vae-ft-mse` to generate decent images, so the
appropriate arguments have been added to the initial model file.
- Model merging and textual inversion scripts have been moved into
`ldm/invoke`, which allows them to be installed properly by
pyproject.toml.
- As part of the pyproject install, the .py suffix is removed from the
command. I.e. use `invoke`, `configure_invokeai`, `merge_models` and
`textual_inversion`.
- GUI versions are activated by adding `--gui` to the command. Without
this, you get a classical argv-based command. Example: `merge_models
--gui`
- Fixed up the launcher scripts to accommodate new naming scheme.
- Keyboard behavior of the GUI front ends has been improved. You can now
use up and down arrow to move from field to field, in addition to <tab>
and ctrl-N/ctrl-P
So far the slider component was unable to take typed input due to a
bunch of issues that were a pain to solve. This PR fixes it.
Things to test:
- Moving the slider also updates the value in the input text box.
- Input text box next to slider can be changed in two ways: If you type
a manual value, the slider will be updated when you lose focus from the
input box. If you use the stepper icons to update the values, the slider
should update immediately.
- Make sure the reset buttons next to the slider are updating correctly
and make sure this updates both the slider and the input box values.
- Brush Size slider -> make sure the hotkeys are updating the input box
too.
- This replaces the original clipseg library with the transformers
version from HuggingFace.
- This should make it possible to register InvokeAI at PyPi and do a
fully automated pip-based install.
- Minor regression: it is no longer possible to specify which device the
clipseg model will be loaded into, and it will reside in CPU. However,
performance is more than acceptable.
- This replaces the original clipseg library with the transformers
version from HuggingFace.
- This should make it possible to register InvokeAI at PyPi and do
a fully automated pip-based install.
- Minor regression: it is no longer possible to specify which device
the clipseg model will be loaded into, and it will reside in CPU.
However, performance is more than acceptable.
Fix two deficiencies in the CLI's support for model management:
1. `!import_model` did not allow user to specify VAE file. This is now
fixed.
2. `!del_model` did not offer the user the opportunity to delete the
underlying
weights file or diffusers directory. This is now fixed.
This PR improves the console reporting of the process of recognizing
trigger tokens and loading their embeds.
1. Do not report "concept is not known to HuggingFace" if the trigger
term is in fact a local embedding trigger.
2. When a trigger term is first recognized during a session, report the
fact.
This should help debug embedding issues in the future.
Note that the local embeddings produced by the new InvokeAI TI training
script default to the format <trigger> with literal angle brackets. This
sets them off from the rest of the text well and will enable
autocomplete at some point in the future. However, this means that they
supersede like-named HuggingFace concepts, and may cause problems for
people uploading them to the HuggingFace repository (although that
problem already exists).
This PR attempts to fix `--free_gpu_mem` option that was not working in
CKPT-based diffuser model after #1583.
I noticed that the memory usage after #1583 did not decrease after
generating an image when `--free_gpu_mem` option was enabled.
It turns out that the option was not propagated into `Generator`
instance, hence the generation will always run without the memory saving
procedure.
This PR also related to #2326. Initially, I was trying to make
`--free_gpu_mem` works on 🤗 diffuser model as well.
In the process, I noticed that InvokeAI will raise an exception when
`--free_gpu_mem` is enabled.
I tried to quickly fix it by simply ignoring the exception and produce a
warning message to user's console.
This PR adds `scripts/merge_fe.py`, which will merge any 2-3 diffusers
models registered in InvokeAI's `models.yaml`, producing a new merged
model that will be registered as well.
Currently this script will only work if all models to be merged are
known by their repo_ids. Local models, including those converted from
ckpt files, will cause a crash due to a bug in the diffusers
`checkpoint_merger.py` code. I have made a PR against
huggingface/diffusers which fixes this:
https://github.com/huggingface/diffusers/pull/2060
I've written up the install procedure for xFormers on Linux systems.
I need help with the Windows install; I don't know what the build
dependencies (compiler, etc) are. This section of the docs is currently
empty.
Please see `docs/installation/070_INSTALL_XFORMERS.md`
other changes which where required:
- move configure_invokeai.py into ldm.invoke
- update files which imported configure_invokeai to use new location:
- ldm/invoke/CLI.py
- scripts/load_models.py
- scripts/preload_models.py
- update test-invoke-pip.yml:
- remove pr type "converted_to_draft"
- remove reference to dev/diffusers
- remove no more needed requirements from matrix
- add pytorch to matrix
- install via `pip3 install --use-pep517 .`
- use the created executables
- this should also fix configure_invoke not executed in windows
To install use `pip install --use-pep517 -e .` where `-e` is optional
- Added new documentation for textual inversion training process
- Move `main.py` into the deprecated scripts folder
- Fix bug in `textual_inversion.py` which was causing it to not load
the globals module correctly.
- Sort models alphabetically in console front end
- Only show diffusers models in console front end
Starting `invoke.py` with --no-xformers will disable
memory-efficient-attention support if xformers is installed.
For symmetry, `--xformers` will enable support, but this is already the
default if xformers is available.
This commit suppresses a few irrelevant warning messages that the
diffusers module produces:
1. The warning that turning off the NSFW detector makes you an
irresponsible person.
2. Warnings about running fp16 models stored in CPU (we are not running
them in CPU, just caching them in CPU RAM)
This commit suppresses a few irrelevant warning messages that the
diffusers module produces:
1. The warning that turning off the NSFW detector makes you an
irresponsible person.
2. Warnings about running fp16 models stored in CPU (we are not running
them in CPU, just caching them in CPU RAM)
Starting `invoke.py` with --no-xformers will disable
memory-efficient-attention support if xformers is installed.
--xformers will enable support, but this is already the
default.
- During trigger token processing, emit better status messages indicating
which triggers were found.
- Suppress message "<token> is not known to HuggingFace library, when
token is in fact a local embed.
- When a ckpt or safetensors file uses an external autoencoder and we
don't know which diffusers model corresponds to this (if any!), then
we fallback to using stabilityai/sd-vae-ft-mse
- This commit improves error reporting so that user knows what is happening.
- After successfully converting a ckt file to diffusers, model_manager
will attempt to create an equivalent 'vae' entry to the resulting
diffusers stanza.
- This is a bit of a hack, as it relies on a hard-coded dictionary
to map ckpt VAEs to diffusers VAEs. The correct way to do this
would be to convert the VAE to a diffusers model and then point
to that. But since (almost) all models are using vae-ft-mse-840000-ema-pruned,
I did it the easy way first and will work on the better solution later.
1. !import_model did not allow user to specify VAE file. This is now fixed.
2. !del_model did not offer the user the opportunity to delete the underlying
weights file or diffusers directory. This is now fixed.
This commit allows InvokeAI to store & load 🤗 models at a location set
by `XDG_CACHE_HOME` environment variable if `HF_HOME` is not set.
By integrating this commit, a user who either use `HF_HOME` or
`XDG_CACHE_HOME` environment variables in their environment can let
InvokeAI to reuse the existing cache directory used by 🤗 library by
default. I happened to benefit from this commit because I have a Jupyter
Notebook that uses 🤗 diffusers model stored at `XDG_CACHE_HOME`
directory.
Reference:
https://huggingface.co/docs/huggingface_hub/main/en/package_reference/environment_variables#xdgcachehome
Updated the link for the MS Visual C libraries - I'm not sure if MS
changed the location of the files but this new one leads right to the
file downloads.
- Migration process will not crash if duplicate model files are found,
one in legacy location and the other in new location. The model in the
legacy location will be deleted in this case.
- Added a hint to stable-diffusion-2.1 telling people it will work best
with 768 pixel images.
- Added the anything-4.0 model.
Added a --default_only argument that limits model downloads to the
single default model, for use in continuous integration.
New behavior
- switch -
--yes --default_only Behavior
----- -------------- --------
<not set> <not set> interactive download
--yes <not set> non-interactively download all
recommended models
--yes --default_only non-interactively download the
default model
Added a --default_only argument that limits model downloads to the single
default model, for use in continuous integration.
New behavior
- switch -
--yes --default_only Behavior
----- -------------- --------
<not set> <not set> interactive download
--yes <not set> non-interactively download all
recommended models
--yes --default_only non-interactively download the
default model
- All tensors in diffusers code path are now set explicitly to
float32 or float16, depending on the --precision flag.
- autocast is still used in the ckpt path, since it is being
deprecated.
- Work around problem with OmegaConf.update() that prevented model names
from containing periods.
- Fix logic bug in !delete_model that didn't check for existence of model
in config file.
* docs: Fix links to pip and Conda installation methods
* docs: Improve installation script readability
This commit adds a space between `-m` option and the module name.
* docs: Fix alignments of step 4 & 9 in `pip` installation method
* docs: Rewrite step 10 of the ` pip` installation method
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
- Migration process will not crash if duplicate model files are found,
one in legacy location and the other in new location.
The model in the legacy location will be deleted in this case.
- Added a hint to stable-diffusion-2.1 telling people it will work best
with 768 pixel images.
- Added the anything-4.0 model.
* initial commit of DiffusionPipeline class
* spike: proof of concept using diffusers for txt2img
* doc: type hints for Generator
* refactor(model_cache): factor out load_ckpt
* model_cache: add ability to load a diffusers model pipeline
and update associated things in Generate & Generator to not instantly fail when that happens
* model_cache: fix model default image dimensions
* txt2img: support switching diffusers schedulers
* diffusers: let the scheduler do its scaling of the initial latents
Remove IPNDM scheduler; it is not behaving.
* web server: update image_progress callback for diffusers data
* diffusers: restore prompt weighting feature
* diffusers: fix set-sampler error following model switch
* diffusers: use InvokeAIDiffuserComponent for conditioning
* cross_attention_control: stub (no-op) implementations for diffusers
* model_cache: let offload_model work with DiffusionPipeline, sorta.
* models.yaml.example: add diffusers-format model, set as default
* test-invoke-conda: use diffusers-format model
test-invoke-conda: put huggingface-token where the library can use it
* environment-mac: upgrade to diffusers 0.7 (from 0.6)
this was already done for linux; mac must have been lost in the merge.
* preload_models: explicitly load diffusers models
In non-interactive mode too, as long as you're logged in.
* fix(model_cache): don't check `model.config` in diffusers format
clean-up from recent merge.
* diffusers integration: support img2img
* dev: upgrade to diffusers 0.8 (from 0.7.1)
We get to remove some code by using methods that were factored out in the base class.
* refactor: remove backported img2img.get_timesteps
now that we can use it directly from diffusers 0.8.1
* ci: use diffusers model
* dev: upgrade to diffusers 0.9 (from 0.8.1)
* lint: correct annotations for Python 3.9.
* lint: correct AttributeError.name reference for Python 3.9.
* CI: prefer diffusers-1.4 because it no longer requires a token
The RunwayML models still do.
* build: there's yet another place to update requirements?
* configure: try to download models even without token
Models in the CompVis and stabilityai repos no longer require them. (But runwayml still does.)
* configure: add troubleshooting info for config-not-found
* fix(configure): prepend root to config path
* fix(configure): remove second `default: true` from models example
* CI: simplify test-on-push logic now that we don't need secrets
The "test on push but only in forks" logic was only necessary when tests didn't work for PRs-from-forks.
* create an embedding_manager for diffusers
* internal: avoid importing diffusers DummyObject
see https://github.com/huggingface/diffusers/issues/1479
* fix "config attributes…not expected" diffusers warnings.
* fix deprecated scheduler construction
* work around an apparent MPS torch bug that causes conditioning to have no effect
* 🚧 post-rebase repair
* preliminary support for outpainting (no masking yet)
* monkey-patch diffusers.attention and use Invoke lowvram code
* add always_use_cpu arg to bypass MPS
* add cross-attention control support to diffusers (fails on MPS)
For unknown reasons MPS produces garbage output with .swap(). Use
--always_use_cpu arg to invoke.py for now to test this code on MPS.
* diffusers support for the inpainting model
* fix debug_image to not crash with non-RGB images.
* inpainting for the normal model [WIP]
This seems to be performing well until the LAST STEP, at which point it dissolves to confetti.
* fix off-by-one bug in cross-attention-control (#1774)
prompt token sequences begin with a "beginning-of-sequence" marker <bos> and end with a repeated "end-of-sequence" marker <eos> - to make a default prompt length of <bos> + 75 prompt tokens + <eos>. the .swap() code was failing to take the column for <bos> at index 0 into account. the changes here do that, and also add extra handling for a single <eos> (which may be redundant but which is included for completeness).
based on my understanding and some assumptions about how this all works, the reason .swap() nevertheless seemed to do the right thing, to some extent, is because over multiple steps the conditioning process in Stable Diffusion operates as a feedback loop. a change to token n-1 has flow-on effects to how the [1x4x64x64] latent tensor is modified by all the tokens after it, - and as the next step is processed, all the tokens before it as well. intuitively, a token's conditioning effects "echo" throughout the whole length of the prompt. so even though the token at n-1 was being edited when what the user actually wanted was to edit the token at n, it nevertheless still had some non-negligible effect, in roughly the right direction, often enough that it seemed like it was working properly.
* refactor common CrossAttention stuff into a mixin so that the old ldm code can still work if necessary
* inpainting for the normal model. I think it works this time.
* diffusers: reset num_vectors_per_token
sync with 44a0055571
* diffusers: txt2img2img (hires_fix)
with so much slicing and dicing of pipeline methods to stitch them together
* refactor(diffusers): reduce some code duplication amongst the different tasks
* fixup! refactor(diffusers): reduce some code duplication amongst the different tasks
* diffusers: enable DPMSolver++ scheduler
* diffusers: upgrade to diffusers 0.10, add Heun scheduler
* diffusers(ModelCache): stopgap to make from_cpu compatible with diffusers
* CI: default to diffusers-1.5 now that runwayml token requirement is gone
* diffusers: update to 0.10 (and transformers to 4.25)
* diffusers: use xformers when available
diffusers no longer auto-enables this as of 0.10.2.
* diffusers: make masked img2img behave better with multi-step schedulers
re-randomizing the noise each step was confusing them.
* diffusers: work more better with more models.
fixed relative path problem with local models.
fixed models on hub not always having a `fp16` branch.
* diffusers: stopgap fix for attention_maps_callback crash after recent merge
* fixup import merge conflicts
correction for 061c5369a2
* test: add tests/inpainting inputs for masked img2img
* diffusers(AddsMaskedGuidance): partial fix for k-schedulers
Prevents them from crashing, but results are still hot garbage.
* fix --safety_checker arg parsing
and add note to diffusers loader about where safety checker gets called
* generate: fix import error
* CI: don't try to read the old init location
* diffusers: support loading an alternate VAE
* CI: remove sh-syntax if-statement so it doesn't crash powershell
* CI: fold strings in yaml because backslash is not line-continuation in powershell
* attention maps callback stuff for diffusers
* build: fix syntax error in environment-mac
* diffusers: add INITIAL_MODELS with diffusers-compatible repos
* re-enable the embedding manager; closes#1778
* Squashed commit of the following:
commit e4a956abc37fcb5cf188388b76b617bc5c8fda7d
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 15:43:07 2022 +0100
import new load handling from EmbeddingManager and cleanup
commit c4abe91a5ba0d415b45bf734068385668b7a66e6
Merge: 032e856e 1efc6397
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 15:09:53 2022 +0100
Merge branch 'feature_textual_inversion_mgr' into dev/diffusers_with_textual_inversion_manager
commit 032e856eefb3bbc39534f5daafd25764bcfcef8b
Merge: 8b4f0fe9 bc515e24
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 15:08:01 2022 +0100
Merge remote-tracking branch 'upstream/dev/diffusers' into dev/diffusers_with_textual_inversion_manager
commit 1efc6397fc6e61c1aff4b0258b93089d61de5955
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 15:04:28 2022 +0100
cleanup and add performance notes
commit e400f804ac471a0ca2ba432fd658778b20c7bdab
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 14:45:07 2022 +0100
fix bug and update unit tests
commit deb9ae0ae1016750e93ce8275734061f7285a231
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 14:28:29 2022 +0100
textual inversion manager seems to work
commit 162e02505dec777e91a983c4d0fb52e950d25ff0
Merge: cbad4583 12769b3d
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 11:58:03 2022 +0100
Merge branch 'main' into feature_textual_inversion_mgr
commit cbad45836c6aace6871a90f2621a953f49433131
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 11:54:10 2022 +0100
use position embeddings
commit 070344c69b0e0db340a183857d0a787b348681d3
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 11:53:47 2022 +0100
Don't crash CLI on exceptions
commit b035ac8c6772dfd9ba41b8eeb9103181cda028f8
Author: Damian Stewart <d@damianstewart.com>
Date: Sun Dec 18 11:11:55 2022 +0100
add missing position_embeddings
commit 12769b3d3562ef71e0f54946b532ad077e10043c
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 13:33:25 2022 +0100
debugging why it don't work
commit bafb7215eabe1515ca5e8388fd3bb2f3ac5362cf
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 13:21:33 2022 +0100
debugging why it don't work
commit 664a6e9e14
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 12:48:38 2022 +0100
use TextualInversionManager in place of embeddings (wip, doesn't work)
commit 8b4f0fe9d6e4e2643b36dfa27864294785d7ba4e
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 12:48:38 2022 +0100
use TextualInversionManager in place of embeddings (wip, doesn't work)
commit ffbe1ab11163ba712e353d89404e301d0e0c6cdf
Merge: 6e4dad60023df37e
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 02:37:31 2022 +0100
Merge branch 'feature_textual_inversion_mgr' into dev/diffusers
commit 023df37eff
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 02:36:54 2022 +0100
cleanup
commit 05fac594ea
Author: Damian Stewart <d@damianstewart.com>
Date: Fri Dec 16 02:07:49 2022 +0100
tweak error checking
commit 009f32ed39
Author: damian <null@damianstewart.com>
Date: Thu Dec 15 21:29:47 2022 +0100
unit tests passing for embeddings with vector length >1
commit beb1b08d9a
Author: Damian Stewart <d@damianstewart.com>
Date: Thu Dec 15 13:39:09 2022 +0100
more explicit equality tests when overwriting
commit 44d8a5a7c8
Author: Damian Stewart <d@damianstewart.com>
Date: Thu Dec 15 13:30:13 2022 +0100
wip textual inversion manager (unit tests passing for 1v embedding overwriting)
commit 417c2b57d9
Author: Damian Stewart <d@damianstewart.com>
Date: Thu Dec 15 12:30:55 2022 +0100
wip textual inversion manager (unit tests passing for base stuff + padding)
commit 2e80872e3b
Author: Damian Stewart <d@damianstewart.com>
Date: Thu Dec 15 10:57:57 2022 +0100
wip new TextualInversionManager
* stop using WeightedFrozenCLIPEmbedder
* store diffusion models locally
- configure_invokeai.py reconfigured to store diffusion models rather than
CompVis models
- hugging face caching model is used, but cache is set to ~/invokeai/models/repo_id
- models.yaml does **NOT** use path, just repo_id
- "repo_name" changed to "repo_id" to following hugging face conventions
- Models are loaded with full precision pending further work.
* allow non-local files during development
* path takes priority over repo_id
* MVP for model_cache and configure_invokeai
- Feature complete (almost)
- configure_invokeai.py downloads both .ckpt and diffuser models,
along with their VAEs. Both types of download are controlled by
a unified INITIAL_MODELS.yaml file.
- model_cache can load both type of model and switches back and forth
in CPU. No memory leaks detected
TO DO:
1. I have not yet turned on the LocalOnly flag for diffuser models, so
the code will check the Hugging Face repo for updates before using the
locally cached models. This will break firewalled systems. I am thinking
of putting in a global check for internet connectivity at startup time
and setting the LocalOnly flag based on this. It would be good to check
updates if there is connectivity.
2. I have not gone completely through INITIAL_MODELS.yaml to check which
models are available as diffusers and which are not. So models like
PaperCut and VoxelArt may not load properly. The runway and stability
models are checked, as well as the Trinart models.
3. Add stanzas for SD 2.0 and 2.1 in INITIAL_MODELS.yaml
REMAINING PROBLEMS NOT DIRECTLY RELATED TO MODEL_CACHE:
1. When loading a .ckpt file there are lots of messages like this:
Warning! ldm.modules.attention.CrossAttention is no longer being
maintained. Please use InvokeAICrossAttention instead.
I'm not sure how to address this.
2. The ckpt models ***don't actually run*** due to the lack of special-case
support for them in the generator objects. For example, here's the hard
crash you get when you run txt2img against the legacy waifu-diffusion-1.3
model:
```
>> An error occurred:
Traceback (most recent call last):
File "/data/lstein/InvokeAI/ldm/invoke/CLI.py", line 140, in main
main_loop(gen, opt)
File "/data/lstein/InvokeAI/ldm/invoke/CLI.py", line 371, in main_loop
gen.prompt2image(
File "/data/lstein/InvokeAI/ldm/generate.py", line 496, in prompt2image
results = generator.generate(
File "/data/lstein/InvokeAI/ldm/invoke/generator/base.py", line 108, in generate
image = make_image(x_T)
File "/data/lstein/InvokeAI/ldm/invoke/generator/txt2img.py", line 33, in make_image
pipeline_output = pipeline.image_from_embeddings(
File "/home/lstein/invokeai/.venv/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1265, in __getattr__
raise AttributeError("'{}' object has no attribute '{}'".format(
AttributeError: 'LatentDiffusion' object has no attribute 'image_from_embeddings'
```
3. The inpainting diffusion model isn't working. Here's the output of "banana
sushi" when inpainting-1.5 is loaded:
```
Traceback (most recent call last):
File "/data/lstein/InvokeAI/ldm/generate.py", line 496, in prompt2image
results = generator.generate(
File "/data/lstein/InvokeAI/ldm/invoke/generator/base.py", line 108, in generate
image = make_image(x_T)
File "/data/lstein/InvokeAI/ldm/invoke/generator/txt2img.py", line 33, in make_image
pipeline_output = pipeline.image_from_embeddings(
File "/data/lstein/InvokeAI/ldm/invoke/generator/diffusers_pipeline.py", line 301, in image_from_embeddings
result_latents, result_attention_map_saver = self.latents_from_embeddings(
File "/data/lstein/InvokeAI/ldm/invoke/generator/diffusers_pipeline.py", line 330, in latents_from_embeddings
result: PipelineIntermediateState = infer_latents_from_embeddings(
File "/data/lstein/InvokeAI/ldm/invoke/generator/diffusers_pipeline.py", line 185, in __call__
for result in self.generator_method(*args, **kwargs):
File "/data/lstein/InvokeAI/ldm/invoke/generator/diffusers_pipeline.py", line 367, in generate_latents_from_embeddings
step_output = self.step(batched_t, latents, guidance_scale,
File "/home/lstein/invokeai/.venv/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/data/lstein/InvokeAI/ldm/invoke/generator/diffusers_pipeline.py", line 409, in step
step_output = self.scheduler.step(noise_pred, timestep, latents, **extra_step_kwargs)
File "/home/lstein/invokeai/.venv/lib/python3.9/site-packages/diffusers/schedulers/scheduling_lms_discrete.py", line 223, in step
pred_original_sample = sample - sigma * model_output
RuntimeError: The size of tensor a (9) must match the size of tensor b (4) at non-singleton dimension 1
```
* proper support for float32/float16
- configure script now correctly detects user's preference for
fp16/32 and downloads the correct diffuser version. If fp16
version not available, falls back to fp32 version.
- misc code cleanup and simplification in model_cache
* add on-the-fly conversion of .ckpt to diffusers models
1. On-the-fly conversion code can be found in the file ldm/invoke/ckpt_to_diffusers.py.
2. A new !optimize command has been added to the CLI. Should be ported to Web GUI.
User experience on the CLI is this:
```
invoke> !optimize /home/lstein/invokeai/models/ldm/stable-diffusion-v1/sd-v1-4.ckpt
INFO: Converting legacy weights file /home/lstein/invokeai/models/ldm/stable-diffusion-v1/sd-v1-4.ckpt to optimized diffuser model.
This operation will take 30-60s to complete.
Success. Optimized model is now located at /home/lstein/tmp/invokeai/models/optimized-ckpts/sd-v1-4
Writing new config file entry for sd-v1-4...
>> New configuration:
sd-v1-4:
description: Optimized version of sd-v1-4
format: diffusers
path: /home/lstein/tmp/invokeai/models/optimized-ckpts/sd-v1-4
OK to import [n]? y
>> Verifying that new model loads...
>> Current VRAM usage: 2.60G
>> Offloading stable-diffusion-2.1 to CPU
>> Loading diffusers model from /home/lstein/tmp/invokeai/models/optimized-ckpts/sd-v1-4
| Using faster float16 precision
You have disabled the safety checker for <class 'ldm.invoke.generator.diffusers_pipeline.StableDiffusionGeneratorPipeline'> by passing `safety_checker=None`. Ensure that you abide to the conditions of the Stable Diffusion \
license and do not expose unfiltered results in services or applications open to the public. Both the diffusers team and Hugging Face strongly recommend to keep the safety filter enabled in all public facing circumstances,\
disabling it only for use-cases that involve analyzing network behavior or auditing its results. For more information, please have a look at https://github.com/huggingface/diffusers/pull/254 .
| training width x height = (512 x 512)
>> Model loaded in 3.48s
>> Max VRAM used to load the model: 2.17G
>> Current VRAM usage:2.17G
>> Textual inversions available:
>> Setting Sampler to k_lms (LMSDiscreteScheduler)
Keep model loaded? [y]
```
* add parallel set of generator files for ckpt legacy generation
* generation using legacy ckpt models now working
* diffusers: fix missing attention_maps_callback
fix for 23eb80b404
* associate legacy CrossAttention with .ckpt models
* enable autoconvert
New --autoconvert CLI option will scan a designated directory for
new .ckpt files, convert them into diffuser models, and import
them into models.yaml.
Works like this:
invoke.py --autoconvert /path/to/weights/directory
In ModelCache added two new methods:
autoconvert_weights(config_path, weights_directory_path, models_directory_path)
convert_and_import(ckpt_path, diffuser_path)
* diffusers: update to diffusers 0.11 (from 0.10.2)
* fix vae loading & width/height calculation
* refactor: encapsulate these conditioning data into one container
* diffusers: fix some noise-scaling issues by pushing the noise-mixing down to the common function
* add support for safetensors and accelerate
* set local_files_only when internet unreachable
* diffusers: fix error-handling path when model repo has no fp16 branch
* fix generatorinpaint error
Fixes :
"ModuleNotFoundError: No module named 'ldm.invoke.generatorinpaint'
https://github.com/invoke-ai/InvokeAI/pull/1583#issuecomment-1363634318
* quench diffuser safety-checker warning
* diffusers: support stochastic DDIM eta parameter
* fix conda env creation on macos
* fix cross-attention with diffusers 0.11
* diffusers: the VAE needs to be tiling as well as the U-Net
* diffusers: comment on subfolders
* diffusers: embiggen!
* diffusers: make model_cache.list_models serializable
* diffusers(inpaint): restore scaling functionality
* fix requirements clash between numba and numpy 1.24
* diffusers: allow inpainting model to do non-inpainting tasks
* start expanding model_cache functionality
* add import_ckpt_model() and import_diffuser_model() methods to model_manager
- in addition, model_cache.py is now renamed to model_manager.py
* allow "recommended" flag to be optional in INITIAL_MODELS.yaml
* configure_invokeai now downloads VAE diffusers in advance
* rename ModelCache to ModelManager
* remove support for `repo_name` in models.yaml
* check for and refuse to load embeddings trained on incompatible models
* models.yaml.example: s/repo_name/repo_id
and remove extra INITIAL_MODELS now that the main one has diffusers models in it.
* add MVP textual inversion script
* refactor(InvokeAIDiffuserComponent): factor out _combine()
* InvokeAIDiffuserComponent: implement threshold
* InvokeAIDiffuserComponent: diagnostic logs for threshold
...this does not look right
* add a curses-based frontend to textual inversion
- not quite working yet
- requires npyscreen installed
- on windows will also have the windows-curses requirement, but not added
to requirements yet
* add curses-based interface for textual inversion
* fix crash in convert_and_import()
- This corrects a "local variable referenced before assignment" error
in model_manager.convert_and_import()
* potential workaround for no 'state_dict' key error
- As reported in https://github.com/huggingface/diffusers/issues/1876
* create TI output dir if needed
* Update environment-lin-cuda.yml (#2159)
Fixing line 42 to be the proper order to define the transformers requirement: ~= instead of =~
* diffusers: update sampler-to-scheduler mapping
based on https://github.com/huggingface/diffusers/issues/277#issuecomment-1371428672
* improve user exp for ckt to diffusers conversion
- !optimize_models command now operates on an existing ckpt file entry in models.yaml
- replaces existing entry, rather than adding a new one
- offers to delete the ckpt file after conversion
* web: adapt progress callback to deal with old generator or new diffusers pipeline
* clean-up model_manager code
- add_model() verified to work for .ckpt local paths,
.ckpt remote URLs, diffusers local paths, and
diffusers repo_ids
- convert_and_import() verified to work for local and
remove .ckpt files
* handle edge cases for import_model() and convert_model()
* add support for safetensor .ckpt files
* fix name error
* code cleanup with pyflake
* improve model setting behavior
- If the user enters an invalid model name at startup time, will not
try to load it, warn, and use default model
- CLI UI enhancement: include currently active model in the command
line prompt.
* update test-invoke-pip.yml
- fix model cache path to point to runwayml/stable-diffusion-v1-5
- remove `skip-sd-weights` from configure_invokeai.py args
* exclude dev/diffusers from "fail for draft PRs"
* disable "fail on PR jobs"
* re-add `--skip-sd-weights` since no space
* update workflow environments
- include `INVOKE_MODEL_RECONFIGURE: '--yes'`
* clean up model load failure handling
- Allow CLI to run even when no model is defined or loadable.
- Inhibit stack trace when model load fails - only show last error
- Give user *option* to run configure_invokeai.py when no models
successfully load.
- Restart invokeai after reconfiguration.
* further edge-case handling
1) only one model in models.yaml file, and that model is broken
2) no models in models.yaml
3) models.yaml doesn't exist at all
* fix incorrect model status listing
- "cached" was not being returned from list_models()
- normalize handling of exceptions during model loading:
- Passing an invalid model name to generate.set_model() will return
a KeyError
- All other exceptions are returned as the appropriate Exception
* CI: do download weights (if not already cached)
* diffusers: fix scheduler loading in offline mode
* CI: fix model name (no longer has `diffusers-` prefix)
* Update txt2img2img.py (#2256)
* fixes to share models with HuggingFace cache system
- If HF_HOME environment variable is defined, then all huggingface models
are stored in that directory following the standard conventions.
- For seamless interoperability, set HF_HOME to ~/.cache/huggingface
- If HF_HOME not defined, then models are stored in ~/invokeai/models.
This is equivalent to setting HF_HOME to ~/invokeai/models
A future commit will add a migration mechanism so that this change doesn't
break previous installs.
* feat - make model storage compatible with hugging face caching system
This commit alters the InvokeAI model directory to be compatible with
hugging face, making it easier to share diffusers (and other models)
across different programs.
- If the HF_HOME environment variable is not set, then models are
cached in ~/invokeai/models in a format that is identical to the
HuggingFace cache.
- If HF_HOME is set, then models are cached wherever HF_HOME points.
- To enable sharing with other HuggingFace library clients, set
HF_HOME to ~/.cache/huggingface to set the default cache location
or to ~/invokeai/models to have huggingface cache inside InvokeAI.
* fixes to share models with HuggingFace cache system
- If HF_HOME environment variable is defined, then all huggingface models
are stored in that directory following the standard conventions.
- For seamless interoperability, set HF_HOME to ~/.cache/huggingface
- If HF_HOME not defined, then models are stored in ~/invokeai/models.
This is equivalent to setting HF_HOME to ~/invokeai/models
A future commit will add a migration mechanism so that this change doesn't
break previous installs.
* fix error "no attribute CkptInpaint"
* model_manager.list_models() returns entire model config stanza+status
* Initial Draft - Model Manager Diffusers
* added hash function to diffusers
* implement sha256 hashes on diffusers models
* Add Model Manager Support for Diffusers
* fix various problems with model manager
- in cli import functions, fix not enough values to unpack from
_get_name_and_desc()
- fix crash when using old-style vae: value with new-style diffuser
* rebuild frontend
* fix dictconfig-not-serializable issue
* fix NoneType' object is not subscriptable crash in model_manager
* fix "str has no attribute get" error in model_manager list_models()
* Add path and repo_id support for Diffusers Model Manager
Also fixes bugs
* Fix tooltip IT localization not working
* Add Version Number To WebUI
* Optimize Model Search
* Fix incorrect font on the Model Manager UI
* Fix image degradation on merge fixes - [Experimental]
This change should effectively fix a couple of things.
- Fix image degradation on subsequent merges of the canvas layers.
- Fix the slight transparent border that is left behind when filling the bounding box with a color.
- Fix the left over line of color when filling a bounding box with color.
So far there are no side effects for this. If any, please report.
* Add local model filtering for Diffusers / Checkpoints
* Go to home on modal close for the Add Modal UI
* Styling Fixes
* Model Manager Diffusers Localization Update
* Add Safe Tensor scanning to Model Manager
* Fix model edit form dispatching string values instead of numbers.
* Resolve VAE handling / edge cases for supplied repos
* defer injecting tokens for textual inversions until they're used for the first time
* squash a console warning
* implement model migration check
* add_model() overwrites previous config rather than merges
* fix model config file attribute merging
* fix precision handling in textual inversion script
* allow ckpt conversion script to work with safetensors .ckpts
Applied patch here:
beb932c5d1
* fix name "args" is not defined crash in textual_inversion_training
* fix a second NameError: name 'args' is not defined crash
* fix loading of the safety checker from the global cache dir
* add installation step to textual inversion frontend
- After a successful training run, the script will copy learned_embeds.bin
to a subfolder of the embeddings directory.
- User given the option to delete the logs and intermediate checkpoints
(which together use 7-8G of space)
- If textual inversion training fails, reports the error gracefully.
* don't crash out on incompatible embeddings
- put try: blocks around places where the system tries to load an embedding
which is incompatible with the currently loaded model
* add support for checkpoint resuming
* textual inversion preferences are saved and restored between sessions
- Preferences are stored in a file named text-inversion-training/preferences.conf
- Currently the resume-from-checkpoint option is not working correctly. Possible
bug in textual_inversion_training.py?
* copy learned_embeddings.bin into right location
* add front end for diffusers model merging
- Front end doesn't do anything yet!!!!
- Made change to model name parsing in CLI to support ability to have merged models
with the "+" character in their names.
* improve inpainting experience
- recommend ckpt version of inpainting-1.5 to user
- fix get_noise() bug in ckpt version of omnibus.py
* update environment*yml
* tweak instructions to install HuggingFace token
* bump version number
* enhance update scripts
- update scripts will now fetch new INITIAL_MODELS.yaml so that
configure_invokeai.py will know about the diffusers versions.
* enhance invoke.sh/invoke.bat launchers
- added configure_invokeai.py to menu
- menu defaults to browser-based invoke
* remove conda workflow (#2321)
* fix `token_ids has shape torch.Size([79]) - expected [77]`
* update CHANGELOG.md with 2.3.* info
- Add information on how formats have changed and the upgrade process.
- Add short bug list.
Co-authored-by: Damian Stewart <d@damianstewart.com>
Co-authored-by: Damian Stewart <null@damianstewart.com>
Co-authored-by: Lincoln Stein <lincoln.stein@gmail.com>
Co-authored-by: Wybartel-luxmc <37852506+Wybartel-luxmc@users.noreply.github.com>
Co-authored-by: mauwii <Mauwii@outlook.de>
Co-authored-by: mickr777 <115216705+mickr777@users.noreply.github.com>
Co-authored-by: blessedcoolant <54517381+blessedcoolant@users.noreply.github.com>
Co-authored-by: Eugene Brodsky <ebr@users.noreply.github.com>
Co-authored-by: Matthias Wild <40327258+mauwii@users.noreply.github.com>
* update version number
* print version number at startup
* move version number into ldm/invoke/_version.py
* bump version to 2.2.6+a0
* handle whitespace better
* resolve issues raised by mauwii during PR review
1. create_installers.sh now asks before tagging and committing the
current repo
2. trailing whitespace removed from user-provided location of invokeai
directory in install.bat
Updated the link for the MS Visual C libraries - I'm not sure if MS changed the location of the files but this new one leads right to the file downloads.
- Removed links from the install instructions to the installer zip files.
- Replaced "2.2.4" with "2.X.X" globally, to avoid the docs going out of
date.
* Permit cmd override for CORS modification
* Enable multiple origins for CORS
* Remove CMD_OVERRIDE
* Revert executable bit change
* Defensively convert list into string
* Bad if statement
* Retry rebase
* Retry rebase
Co-authored-by: Chris Dawson <chris@vivoh.com>
- fix problem of facexlib weights being downloaded into the .venv
package directory when codeformer restoration requested.
- now users pre-downloaded weights in ~/invokeai/models/gfpgan/weights
(which is shared with gfpgan)
Co-authored-by: Matthias Wild <40327258+mauwii@users.noreply.github.com>
- Fixed codeformer module so that the facexlib files are downloaded
into their pre-stored location in models/gfpgan/weights (shared
with the GFPGAN module)
* installer tweaks in preparation for v2.2.5
- pin numpy to 1.23.* to avoid requirements conflict with numba
- update.sh and update.bat now accept a tag or branch string, not a URL
- update scripts download latest requirements-base before updating.
* update.bat.in debugged and working
* update pulls from "latest" now
* bump version number
* fix permissions on create_installer.sh
* give Linux user option of installing ROCm or CUDA
* rc2.2.5 (install.sh) relative path fixes (#2155)
* (installer) fix bug in resolution of relative paths in linux install script
point installer at 2.2.5-rc1
selecting ~/Data/myapps/ as location would create a ./~/Data/myapps
instead of expanding the ~/ to the value of ${HOME}
also, squash the trailing slash in path, if it was entered by the user
* (installer) add option to automatically start the app after install
also: when exiting, print the command to get back into the app
* remove extraneous whitespace
* model_cache applies rootdir to config path
* bring installers up to date with 2.2.5-rc2
* bump rc version
* create_installer now adds version number
* rebuild frontend
* bump rc#
* add locales to frontend dist package
- bump to patchlevel 6
* bump patchlevel
* use invoke-ai version of GFPGAN
- This version is very slightly modified to allow weights files
to be pre-downloaded by the configure script.
* fix formatting error during startup
* bump patch level
* workaround #2 for GFPGAN facexlib() weights downloading
* bump patch
* ready for merge and release
* remove extraneous comment
* set PYTORCH_ENABLE_MPS_FALLBACK directly in invoke.py
Co-authored-by: Eugene Brodsky <ebr@users.noreply.github.com>
* Update WEBUIHOTKEYS.md
Fixed display errors so it no longer show extra plus signs on the site
* Update WEBUIHOTKEYS.md
Correction to keycap look to have symbols on special keys like enter, shift, and ctrl.
- A couple of users have reported that switching back and forth
between ckpt models is causing a "GPU out of memory" crash.
Traceback suggests there is actually a CPU RAM issue.
- This speculative test simply performs a round of garbage collection
before the point where the crash occurs.
[![CI checks on main badge]][CI checks on main link] [![CI checks on dev badge]][CI checks on dev link] [![latest commit to dev badge]][latest commit to dev link]
[![CI checks on main badge]][CI checks on main link] [![latest commit to main badge]][latest commit to main link]
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link]
[![github open issues badge]][github open issues link] [![github open prs badge]][github open prs link] [![translation status badge]][translation status link]
[CI checks on dev badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/development?label=CI%20status%20on%20dev&cache=900&icon=github
[CI checks on dev link]: https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Adevelopment
[CI checks on main badge]: https://flat.badgen.net/github/checks/invoke-ai/InvokeAI/main?label=CI%20status%20on%20main&cache=900&icon=github
[CI checks on main link]:https://github.com/invoke-ai/InvokeAI/actions/workflows/test-invoke-conda.yml
[CI checks on main link]:https://github.com/invoke-ai/InvokeAI/actions?query=branch%3Amain
[latest commit to dev badge]: https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/development?icon=github&color=yellow&label=last%20dev%20commit&cache=900
[latest commit to dev link]: https://github.com/invoke-ai/InvokeAI/commits/development
[latest commit to main badge]: https://flat.badgen.net/github/last-commit/invoke-ai/InvokeAI/main?icon=github&color=yellow&label=last%20dev%20commit&cache=900
[latest commit to main link]: https://github.com/invoke-ai/InvokeAI/commits/main
the open source text-to-image generator. It provides a streamlined
process with various new features and options to aid the image
generation process. It runs on Windows, macOS and Linux machines, with
GPU cards with as little as 4 GB of RAM. It provides both a polished
Web interface (see below), and an easy-to-use command-line interface.
InvokeAI is a leading creative engine built to empower professionals and enthusiasts alike. Generate and create stunning visual media using the latest AI-driven technologies. InvokeAI offers an industry leading Web Interface, interactive Command Line Interface, and also serves as the foundation for multiple commercial products.
**Quick links**: [[How to Install](#installation)] [<ahref="https://discord.gg/ZmtBAhwWhy">Discord Server</a>] [<ahref="https://invoke-ai.github.io/InvokeAI/">Documentation and Tutorials</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/">Code and Downloads</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/discussions">Discussion, Ideas & Q&A</a>]
**Quick links**: [[How to Install](https://invoke-ai.github.io/InvokeAI/#installation)] [<ahref="https://discord.gg/ZmtBAhwWhy">Discord Server</a>] [<ahref="https://invoke-ai.github.io/InvokeAI/">Documentation and Tutorials</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/">Code and Downloads</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/issues">Bug Reports</a>] [<ahref="https://github.com/invoke-ai/InvokeAI/discussions">Discussion, Ideas & Q&A</a>]
_Note: InvokeAI is rapidly evolving. Please use the
[Issues](https://github.com/invoke-ai/InvokeAI/issues) tab to report bugs and make feature
requests. Be sure to use the provided templates. They will help us diagnose issues faster._
### Automatic Installer (suggested for 1st time users)
1. Go to the bottom of the [Latest Release Page](https://github.com/invoke-ai/InvokeAI/releases/latest)
2. Download the .zip file for your OS (Windows/macOS/Linux).
3. Unzip the file.
4. If you are on Windows, double-click on the `install.bat` script. On macOS, open a Terminal window, drag the file `install.sh` from Finder into the Terminal, and press return. On Linux, run `install.sh`.
5. Wait a while, until it is done.
6. The folder where you ran the installer from will now be filled with lots of files. If you are on Windows, double-click on the `invoke.bat` file. On macOS, open a Terminal window, drag `invoke.sh` from the folder into the Terminal, and press return. On Linux, run `invoke.sh`
7. Press 2 to open the "browser-based UI", press enter/return, wait a minute or two for Stable Diffusion to start up, then open your browser and go to http://localhost:9090.
8. Type `banana sushi` in the box on the top left and click `Invoke`:
InvokeAI is supported across Linux, Windows and macOS. Linux
users can use either an Nvidia-based card (with CUDA support) or an
AMD card (using the ROCm driver).
#### System
You wil need one of the following:
### System
You will need one of the following:
- An NVIDIA-based graphics card with 4 GB or more VRAM memory.
- An Apple computer with an M1 chip.
- An AMD-based graphics card with 4GB or more VRAM memory. (Linux only)
We do not recommend the GTX 1650 or 1660 series video cards. They are
unable to run in half-precision mode and do not have sufficient VRAM
to render 512x512 images.
#### Memory
### Memory
- At least 12 GB Main Memory RAM.
#### Disk
### Disk
- At least 12 GB of free disk space for the machine learning model, Python, and all its dependencies.
**Note**
## Features
If you have a Nvidia 10xx series card (e.g. the 1080ti), please
run the dream script in full-precision mode as shown below.
Feature documentation can be reviewed by navigating to [the InvokeAI Documentation page](https://invoke-ai.github.io/InvokeAI/features/)
Similarly, specify full-precision mode on Apple M1 hardware.
### *Web Server & UI*
Precision is auto configured based on the device. If however you encounter
errors like 'expected type Float but found Half' or 'not implemented for Half'
you can try starting `invoke.py` with the `--precision=float32` flag to your initialization command
InvokeAI offers a locally hosted Web Server & React Frontend, with an industry leading user experience. The Web-based UI allows for simple and intuitive workflows, and is responsive for use on mobile devices and tablets accessing the web server.
Or by updating your InvokeAI configuration file with this argument.
### *Unified Canvas*
### Features
The Unified Canvas is a fully integrated canvas implementation with support for all core generation capabilities, in/outpainting, brush tools, and more. This creative tool unlocks the capability for artists to create with AI as a creative collaborator, and can be used to augment AI-generated imagery, sketches, photography, renders, and more.
- [Simplified API for text to image generation](https://invoke-ai.github.io/InvokeAI/features/OTHER/#simplified-api)
InvokeAI's advanced prompt syntax allows for token weighting, cross-attention control, and prompt blending, allowing for fine-tuned tweaking of your invocations and exploration of the latent space.
For users utilizing a terminal-based environment, or who want to take advantage of CLI features, InvokeAI offers an extensive and actively supported command-line interface that provides the full suite of generation functionality available in the tool.
### Other features
- *Support for both ckpt and diffusers models*
- *SD 2.0, 2.1 support*
- *Noise Control & Tresholding*
- *Popular Sampler Support*
- *Upscaling & Face Restoration Tools*
- *Embedding Manager & Support*
- *Model Manager & Support*
### Coming Soon
- *Node-Based Architecture & UI*
- And more...
### Latest Changes
For our latest changes, view our [Release Notes](https://github.com/invoke-ai/InvokeAI/releases)
For our latest changes, view our [Release
Notes](https://github.com/invoke-ai/InvokeAI/releases) and the
[CHANGELOG](docs/CHANGELOG.md).
### Troubleshooting
## Troubleshooting
Please check out our **[Q&A](https://invoke-ai.github.io/InvokeAI/help/TROUBLESHOOT/#faq)** to get solutions for common installation
problems and other issues.
# Contributing
## Contributing
Anyone who wishes to contribute to this project, whether documentation, features, bug fixes, code
cleanup, testing, or code reviews, is very much encouraged to do so.
To join, just raise your hand on the InvokeAI Discord server (#dev-chat) or the GitHub discussion board.
If you'd like to help with translation, please see our [translation guide](docs/other/TRANSLATION.md).
If you are unfamiliar with how
to contribute to GitHub projects, here is a
[Getting Started Guide](https://opensource.com/article/19/7/create-pull-request-github). A full set of contribution guidelines, along with templates, are in progress. You can **make your pull request against the "main" branch**.
@ -181,15 +277,11 @@ This fork is a combined effort of various people from across the world.
[Check out the list of all these amazing people](https://invoke-ai.github.io/InvokeAI/other/CONTRIBUTORS/). We thank them for
their time, hard work and effort.
Thanks to [Weblate](https://weblate.org/) for generously providing translation services to this project.
### Support
For support, please use this repository's GitHub Issues tracking service. Feel free to send me an
email if you use and like the script.
For support, please use this repository's GitHub Issues tracking service, or join the Discord.
Original portions of the software are Copyright (c) 2022
[Lincoln D. Stein](https://github.com/lstein)
Original portions of the software are Copyright (c) 2023 by respective contributors.
### Further Reading
Please see the original README for more information on this software and underlying algorithm,
located in the file [README-CompViz.md](https://invoke-ai.github.io/InvokeAI/other/README-CompViz/).
Applications are built on top of the invoke framework. They should construct `invoker` and then interact through it. They should avoid interacting directly with core code in order to support a variety of configurations.
### Web UI
The Web UI is built on top of an HTTP API built with [FastAPI](https://fastapi.tiangolo.com/) and [Socket.IO](https://socket.io/). The frontend code is found in `/frontend` and the backend code is found in `/ldm/invoke/app/api_app.py` and `/ldm/invoke/app/api/`. The code is further organized as such:
| Component | Description |
| --- | --- |
| api_app.py | Sets up the API app, annotates the OpenAPI spec with additional data, and runs the API |
| dependencies | Creates all invoker services and the invoker, and provides them to the API |
| events | An eventing system that could in the future be adapted to support horizontal scale-out |
| sockets | The Socket.IO interface - handles listening to and emitting session events (events are defined in the events service module) |
| routers | API definitions for different areas of API functionality |
### CLI
The CLI is built automatically from invocation metadata, and also supports invocation piping and auto-linking. Code is available in `/ldm/invoke/app/cli_app.py`.
## Invoke
The Invoke framework provides the interface to the underlying AI systems and is built with flexibility and extensibility in mind. There are four major concepts: invoker, sessions, invocations, and services.
### Invoker
The invoker (`/ldm/invoke/app/services/invoker.py`) is the primary interface through which applications interact with the framework. Its primary purpose is to create, manage, and invoke sessions. It also maintains two sets of services:
- **invocation services**, which are used by invocations to interact with core functionality.
- **invoker services**, which are used by the invoker to manage sessions and manage the invocation queue.
### Sessions
Invocations and links between them form a graph, which is maintained in a session. Sessions can be queued for invocation, which will execute their graph (either the next ready invocation, or all invocations). Sessions also maintain execution history for the graph (including storage of any outputs). An invocation may be added to a session at any time, and there is capability to add and entire graph at once, as well as to automatically link new invocations to previous invocations. Invocations can not be deleted or modified once added.
The session graph does not support looping. This is left as an application problem to prevent additional complexity in the graph.
### Invocations
Invocations represent individual units of execution, with inputs and outputs. All invocations are located in `/ldm/invoke/app/invocations`, and are all automatically discovered and made available in the applications. These are the primary way to expose new functionality in Invoke.AI, and the [implementation guide](INVOCATIONS.md) explains how to add new invocations.
### Services
Services provide invocations access AI Core functionality and other necessary functionality (e.g. image storage). These are available in `/ldm/invoke/app/services`. As a general rule, new services should provide an interface as an abstract base class, and may provide a lightweight local implementation by default in their module. The goal for all services should be to enable the usage of different implementations (e.g. using cloud storage for image storage), but should not load any module dependencies unless that implementation has been used (i.e. don't import anything that won't be used, especially if it's expensive to import).
## AI Core
The AI Core is represented by the rest of the code base (i.e. the code outside of `/ldm/invoke/app/`).
Invocations represent a single operation, its inputs, and its outputs. These operations and their outputs can be chained together to generate and modify images.
## Creating a new invocation
To create a new invocation, either find the appropriate module file in `/ldm/invoke/app/invocations` to add your invocation to, or create a new one in that folder. All invocations in that folder will be discovered and made available to the CLI and API automatically. Invocations make use of [typing](https://docs.python.org/3/library/typing.html) and [pydantic](https://pydantic-docs.helpmanual.io/) for validation and integration into the CLI and API.
All invocations must derive from `BaseInvocation`. They should have a docstring that declares what they do in a single, short line. They should also have a `type` with a type hint that's `Literal["command_name"]`, where `command_name` is what the user will type on the CLI or use in the API to create this invocation. The `command_name` must be unique. The `type` must be assigned to the value of the literal in the type hint.
Inputs consist of three parts: a name, a type hint, and a `Field` with default, description, and validation information. For example:
| Part | Value | Description |
| ---- | ----- | ----------- |
| Name | `strength` | This field is referred to as `strength` |
| Type Hint | `float` | This field must be of type `float` |
| Field | `Field(default=0.75, gt=0, le=1, description="The strength")` | The default value is `0.75`, the value must be in the range (0,1], and help text will show "The strength" for this field. |
Notice that `image` has type `Union[ImageField,None]`. The `Union` allows this field to be parsed with `None` as a value, which enables linking to previous invocations. All fields should either provide a default value or allow `None` as a value, so that they can be overwritten with a linked output from another invocation.
The special type `ImageField` is also used here. All images are passed as `ImageField`, which protects them from pydantic validation errors (since images only ever come from links).
Finally, note that for all linking, the `type` of the linked fields must match. If the `name` also matches, then the field can be **automatically linked** to a previous invocation by name and matching.
The `invoke` function is the last portion of an invocation. It is provided an `InvocationContext` which contains services to perform work as well as a `session_id` for use as needed. It should return a class with output values that derives from `BaseInvocationOutput`.
Before being called, the invocation will have all of its fields set from defaults, inputs, and finally links (overriding in that order).
Assume that this invocation may be running simultaneously with other invocations, may be running on another machine, or in other interesting scenarios. If you need functionality, please provide it as a service in the `InvocationServices` class, and make sure it can be overridden.
### Outputs
```py
classImageOutput(BaseInvocationOutput):
"""Base class for invocations that output an image"""
Output classes look like an invocation class without the invoke method. Prefer to use an existing output class if available, and prefer to name inputs the same as outputs when possible, to promote automatic invocation linking.
| `--prompt_as_dir` | `-p` | `False` | Name output directories using the prompt text. |
| `--from_file <path>` | | `None` | Read list of prompts from a file. Use `-` to read from standard input |
| `--model <modelname>` | | `stable-diffusion-1.4` | Loads model specified in configs/models.yaml. Currently one of "stable-diffusion-1.4" or "laion400m" |
| `--full_precision` | `-F` | `False` | Run in slower full-precision mode. Needed for Macintosh M1/M2 hardware and some older video cards. |
| `--model <modelname>` | | `stable-diffusion-1.5` | Loads the initial model specified in configs/models.yaml. |
| `--ckpt_convert ` | | `False` | If provided both .ckpt and .safetensors files will be auto-converted into diffusers format in memory |
| `--autoconvert <path>` | | `None` | On startup, scan the indicated directory for new .ckpt/.safetensor files and automatically convert and import them |
| `--precision` | | `fp16` | Provide `fp32` for full precision mode, `fp16` for half-precision. `fp32` needed for Macintoshes and some NVidia cards. |
| `--png_compression <0-9>` | `-z<0-9>` | `6` | Select level of compression for output files, from 0 (no compression) to 9 (max compression) |
| `--safety-checker` | | `False` | Activate safety checker for NSFW and other potentially disturbing imagery |
| `--full_precision` | | `False` | Same as `--precision=fp32`|
| `--weights <path>` | | `None` | Path to weights file; use `--model stable-diffusion-1.4` instead |
| `--laion400m` | `-l` | `False` | Use older LAION400m weights; use `--model=laion400m` instead |
@ -136,7 +142,7 @@ mixture of both using any of the accepted command switch formats:
# InvokeAI initialization file
# This is the InvokeAI initialization file, which contains command-line default values.
# Feel free to edit. If anything goes wrong, you can re-initialize this file by deleting
# or renaming it and then running configure_invokeai.py again.
# or renaming it and then running invokeai-configure again.
# The --root option below points to the folder in which InvokeAI stores its models, configs and outputs.
--root="/Users/mauwii/invokeai"
@ -208,6 +214,8 @@ Here are the invoke> command that apply to txt2img:
| `--variation <float>` | `-v<float>` | `0.0` | Add a bit of noise (0.0=none, 1.0=high) to the image in order to generate a series of variations. Usually used in combination with `-S<seed>` and `-n<int>` to generate a series a riffs on a starting image. See [Variations](./VARIATIONS.md). |
| `--with_variations <pattern>` | | `None` | Combine two or more variations. See [Variations](./VARIATIONS.md) for now to use this. |
| `--save_intermediates <n>` | | `None` | Save the image from every nth step into an "intermediates" folder inside the output directory |
| `--h_symmetry_time_pct <float>` | | `None` | Create symmetry along the X axis at the desired percent complete of the generation process. (Must be between 0.0 and 1.0; set to a very small number like 0.0001 for just after the first step of generation.) |
| `--v_symmetry_time_pct <float>` | | `None` | Create symmetry along the Y axis at the desired percent complete of the generation process. (Must be between 0.0 and 1.0; set to a very small number like 0.0001 for just after the first step of generation.) |
!!! note
@ -336,8 +344,10 @@ useful for debugging the text masking process prior to inpainting with the
### Model selection and importation
The CLI allows you to add new models on the fly, as well as to switch among them
rapidly without leaving the script.
The CLI allows you to add new models on the fly, as well as to switch
among them rapidly without leaving the script. There are several
different model formats, each described in the [Model Installation
Guide](../installation/050_INSTALLING_MODELS.md).
#### `!models`
@ -347,9 +357,9 @@ model is bold-faced
Example:
<pre>
laion400mnot loaded <nodescription>
<b>stable-diffusion-1.4 active Stable Diffusion v1.4</b>
waifu-diffusion not loaded Waifu Diffusion v1.3
inpainting-1.5 not loaded Stable Diffusion inpainting model
<b>stable-diffusion-1.5 active Stable Diffusion v1.5</b>
waifu-diffusion not loaded Waifu Diffusion v1.4
</pre>
#### `!switch <model>`
@ -361,43 +371,30 @@ Note how the second column of the `!models` table changes to `cached` after a
model is first loaded, and that the long initialization step is not needed when
corresponding to bloc97's `prompt_edit_spatial_start/_end` and
`prompt_edit_tokens_start/_end` but with the math swapped to make it easier to
intuitively understand.
- Example usage:`a (cat).swap(dog, s_end=0.3) eating a hotdog` - the `s_end`
argument means that the "spatial" (self-attention) edit will stop having any
effect after 30% (=0.3) of the steps have been done, leaving Stable
Diffusion with 70% of the steps where it is free to decide for itself how to
reshape the cat-form into a dog form.
- The numbers represent a percentage through the step sequence where the edits
should happen. 0 means the start (noisy starting image), 1 is the end (final
image).
- For img2img, the step sequence does not start at 0 but instead at
(1-strength) - so if strength is 0.7, s_start and s_end must both be
greater than 0.3 (1-0.7) to have any effect.
- Convenience option `shape_freedom` (0-1) to specify how much "freedom" Stable
Diffusion should have to change the shape of the subject being swapped.
- `a (cat).swap(dog, shape_freedom=0.5) eating a hotdog`.
For example, consider the prompt `a cat.swap(dog) playing with a ball in the forest`. Normally, because of the word words interact with each other when doing a stable diffusion image generation, these two prompts would generate different compositions:
- `a cat playing with a ball in the forest`
- `a dog playing with a ball in the forest`
| `a cat playing with a ball in the forest` | `a dog playing with a ball in the forest` |
| --- | --- |
| img | img |
- For multiple word swaps, use parentheses: `a (fluffy cat).swap(barking dog) playing with a ball in the forest`.
- To swap a comma, use quotes: `a ("fluffy, grey cat").swap("big, barking dog") playing with a ball in the forest`.
- Supports options `t_start` and `t_end` (each 0-1) loosely corresponding to bloc97's `prompt_edit_tokens_start/_end` but with the math swapped to make it easier to
intuitively understand. `t_start` and `t_end` are used to control on which steps cross-attention control should run. With the default values `t_start=0` and `t_end=1`, cross-attention control is active on every step of image generation. Other values can be used to turn cross-attention control off for part of the image generation process.
- For example, if doing a diffusion with 10 steps for the prompt is `a cat.swap(dog, t_start=0.3, t_end=1.0) playing with a ball in the forest`, the first 3 steps will be run as `a cat playing with a ball in the forest`, while the last 7 steps will run as `a dog playing with a ball in the forest`, but the pixels that represent `dog` will be locked to the pixels that would have represented `cat` if the `cat` prompt had been used instead.
- Conversely, for `a cat.swap(dog, t_start=0, t_end=0.7) playing with a ball in the forest`, the first 7 steps will run as `a dog playing with a ball in the forest` with the pixels that represent `dog` locked to the same pixels that would have represented `cat` if the `cat` prompt was being used instead. The final 3 steps will just run `a cat playing with a ball in the forest`.
> For img2img, the step sequence does not start at 0 but instead at `(1.0-strength)` - so if the img2img `strength` is `0.7`, `t_start` and `t_end` must both be greater than `0.3` (`1.0-0.7`) to have any effect.
Prompt2prompt `.swap()` is not compatible with xformers, which will be temporarily disabled when doing a `.swap()` - so you should expect to use more VRAM and run slower that with xformers enabled.
For .pt files it's also possible to train multiple tokens (modify the
placeholder string in `configs/stable-diffusion/v1-finetune.yaml`) and combine
LDM checkpoints using:
## Using Embeddings
```bash
python3 ./scripts/merge_embeddings.py \
--manager_ckpts /path/to/first/embedding.pt \
[</path/to/second/embedding.pt>,[...]]\
--output_path /path/to/output/embedding.pt
```
After training completes, the resultant embeddings will be saved into your `$INVOKEAI_ROOT/embeddings/<trigger word>/learned_embeds.bin`.
Credit goes to rinongal and the repository
These will be automatically loaded when you start InvokeAI.
Please see [the repository](https://github.com/rinongal/textual_inversion) and
Add the trigger word, surrounded by angle brackets, to use that embedding. For example, if your trigger word was `terence`, use `<terence>` in prompts. This is the same syntax used by the HuggingFace concepts library.
**Note:**`.pt` embeddings do not require the angle brackets.
## Troubleshooting
### `Cannot load embedding for <trigger>. It was trained on a model with token dimension 1024, but the current model has token dimension 768`
Messages like this indicate you trained the embedding on a different base model than the currently selected one.
For example, in the error above, the training was done on SD2.1 (768x768) but it was used on SD1.5 (512x512).
## Reading
For more information on textual inversion, please see the following
resources:
* The [textual inversion repository](https://github.com/rinongal/textual_inversion) and
Here you can find the documentation for different features.
- The Basics
- The [Web User Interface](WEB.md)
Guide to the Web interface. Also see the
[WebUI Hotkeys Reference Guide](WEBUIHOTKEYS.md)
- The [Unified Canvas](UNIFIED_CANVAS.md)
Build complex scenes by combine and modifying multiple images in a
stepwise fashion. This feature combines img2img, inpainting and
outpainting in a single convenient digital artist-optimized user
interface.
- The [Command Line Interface (CLI)](CLI.md)
Scriptable access to InvokeAI's features.
- [Visual Manual for InvokeAI](https://docs.google.com/presentation/d/e/2PACX-1vSE90aC7bVVg0d9KXVMhy-Wve-wModgPFp7AGVTOCgf4xE03SnV24mjdwldolfCr59D_35oheHe4Cow/pub?start=false&loop=true&delayms=60000) (contributed by Statcomm)
- Image Generation
- [Prompt Engineering](PROMPTS.md)
Get the images you want with the InvokeAI prompt engineering language.
- [Post-Processing](POSTPROCESS.md)
Restore mangled faces and make images larger with upscaling. Also see
the [Embiggen Upscaling Guide](EMBIGGEN.md).
- The [Concepts Library](CONCEPTS.md)
Add custom subjects and styles using HuggingFace's repository of
embeddings.
- [Image-to-Image Guide for the CLI](IMG2IMG.md)
Use a seed image to build new creations in the CLI.
- [Inpainting Guide for the CLI](INPAINTING.md)
Selectively erase and replace portions of an existing image in the CLI.
- [Outpainting Guide for the CLI](OUTPAINTING.md)
Extend the borders of the image with an "outcrop" function within the
CLI.
- [Generating Variations](VARIATIONS.md)
Have an image you like and want to generate many more like it?
The Docs you find here (/docs/*) are built and deployed via mkdocs. If you want to run a local version to verify your changes, it's as simple as::
@ -81,22 +83,6 @@ Q&A</a>]
This fork is rapidly evolving. Please use the [Issues tab](https://github.com/invoke-ai/InvokeAI/issues) to report bugs and make feature requests. Be sure to use the provided templates. They will help aid diagnose issues faster.
- [WebUI Unified Canvas for Img2Img, inpainting and outpainting](features/UNIFIED_CANVAS.md)
- [Visual Manual for InvokeAI v2.3.1](https://docs.google.com/presentation/d/e/2PACX-1vSE90aC7bVVg0d9KXVMhy-Wve-wModgPFp7AGVTOCgf4xE03SnV24mjdwldolfCr59D_35oheHe4Cow/pub?start=false&loop=true&delayms=60000) (contributed by Statcomm)
<!-- separator -->
<!-- separator -->
### The InvokeAI Command Line Interface
- [Command Line Interace Reference Guide](features/CLI.md)
<!-- separator -->
### Image Management
- [Image2Image](features/IMG2IMG.md)
- [Inpainting](features/INPAINTING.md)
- [Outpainting](features/OUTPAINTING.md)
- [Adding custom styles and subjects](features/CONCEPTS.md)
- [Using LoRA models](features/LORAS.md)
- [Upscaling and Face Reconstruction](features/POSTPROCESS.md)
- [Not Safe for Work (NSFW) Checker](features/NSFW.md)
<!-- seperator -->
### Prompt Engineering
- [Prompt Syntax](features/PROMPTS.md)
- [Generating Variations](features/VARIATIONS.md)
## :octicons-log-16: Latest Changes
### v2.2.4 <small>(11 December 2022)</small>
### v2.3.3 <small>(29 March 2023)</small>
#### the `invokeai` directory
#### Bug Fixes
1. When using legacy checkpoints with an external VAE, the VAE file is now scanned for malware prior to loading. Previously only the main model weights file was scanned.
2. Textual inversion will select an appropriate batchsize based on whether `xformers` is active, and will default to `xformers` enabled if the library is detected.
3. The batch script log file names have been fixed to be compatible with Windows.
4. Occasional corruption of the `.next_prefix` file (which stores the next output file name in sequence) on Windows systems is now detected and corrected.
5. An infinite loop when opening the developer's console from within the `invoke.sh` script has been corrected.
Previously there were two directories to worry about, the directory that
contained the InvokeAI source code and the launcher scripts, and the `invokeai`
directory that contained the models files, embeddings, configuration and
outputs. With the 2.2.4 release, this dual system is done away with, and
everything, including the `invoke.bat` and `invoke.sh` launcher scripts, now
live in a directory named `invokeai`. By default this directory is located in
your home directory (e.g. `\Users\yourname` on Windows), but you can select
where it goes at install time.
#### Enhancements
1. It is now possible to load and run several community-contributed SD-2.0 based models, including the infamous "Illuminati" model.
2. The "NegativePrompts" embedding file, and others like it, can now be loaded by placing it in the InvokeAI `embeddings` directory.
3. If no `--model` is specified at launch time, InvokeAI will remember the last model used and restore it the next time it is launched.
4. On Linux systems, the `invoke.sh` launcher now uses a prettier console-based interface. To take advantage of it, install the `dialog` package using your package manager (e.g. `sudo apt install dialog`).
5. When loading legacy models (safetensors/ckpt) you can specify a custom config file and/or a VAE by placing like-named files in the same directory as the model following this example:
```
my-favorite-model.ckpt
my-favorite-model.yaml
my-favorite-model.vae.pt # or my-favorite-model.vae.safetensors
```
After installation, you can delete the install directory (the one that the zip
file creates when it unpacks). Do **not** delete or move the `invokeai`
You can place frequently-used startup options in this file, such as the default
number of steps or your preferred sampler. To keep everything in one place, this
file has now been moved into the `invokeai` directory and is named
`invokeai.init`.
Since version 2.3.1 the following bugs have been fixed:
#### To update from Version 2.2.3
1. Black images appearing for potential NSFW images when generating with legacy checkpoint models and both `--no-nsfw_checker` and `--ckpt_convert` turned on.
2. Black images appearing when generating from models fine-tuned on Stable-Diffusion-2-1-base. When importing V2-derived models, you may be asked to select whether the model was derived from a "base" model (512 pixels) or the 768-pixel SD-2.1 model.
3. The "Use All" button was not restoring the Hi-Res Fix setting on the WebUI
4. When using the model installer console app, models failed to import correctly when importing from directories with spaces in their names. A similar issue with the output directory was also fixed.
5. Crashes that occurred during model merging.
6. Restore previous naming of Stable Diffusion base and 768 models.
7. Upgraded to latest versions of `diffusers`, `transformers`, `safetensors` and `accelerate` libraries upstream. We hope that this will fix the `assertion NDArray > 2**32` issue that MacOS users have had when generating images larger than 768x768 pixels. Please report back.
The easiest route is to download and unpack one of the 2.2.4 installer files.
When it asks you for the location of the `invokeai` runtime directory, respond
with the path to the directory that contains your 2.2.3 `invokeai`. That is, if
`invokeai` lives at `C:\Users\fred\invokeai`, then answer with `C:\Users\fred`
and answer "Y" when asked if you want to reuse the directory.
As part of the upgrade to `diffusers`, the location of the diffusers-based models has changed from `models/diffusers` to `models/hub`. When you launch InvokeAI for the first time, it will prompt you to OK a one-time move. This should be quick and harmless, but if you have modified your `models/diffusers` directory in some way, for example using symlinks, you may wish to cancel the migration and make appropriate adjustments.
The `update.sh` (`update.bat`) script that came with the 2.2.3 source installer
does not know about the new directory layout and won't be fully functional.
#### New "Invokeai-batch" script
#### To update to 2.2.5 (and beyond) there's now an update path.
2.3.2 introduces a new command-line only script called
`invokeai-batch` that can be used to generate hundreds of images from
prompts and settings that vary systematically. This can be used to try
the same prompt across multiple combinations of models, steps, CFG
settings and so forth. It also allows you to template prompts and
generate a combinatorial list like: ``` a shack in the mountains,
photograph a shack in the mountains, watercolor a shack in the
mountains, oil painting a chalet in the mountains, photograph a chalet
in the mountains, watercolor a chalet in the mountains, oil painting a
shack in the desert, photograph ... ```
As they become available, you can update to more recent versions of InvokeAI
using an `update.sh` (`update.bat`) script located in the `invokeai` directory.
Running it without any arguments will install the most recent version of
InvokeAI. Alternatively, you can get set releases by running the `update.sh`
script with an argument in the command shell. This syntax accepts the path to
the desired release's zip file, which you can find by clicking on the green
"Code" button on this repository's home page.
If you have a system with multiple GPUs, or a single GPU with lots of
VRAM, you can parallelize generation across the combinatorial set,
reducing wait times and using your system's resources efficiently
(make sure you have good GPU cooling).
#### Other 2.2.4 Improvements
To try `invokeai-batch` out. Launch the "developer's console" using
the `invoke` launcher script, or activate the invokeai virtual
environment manually. From the console, give the command
`invokeai-batch --help` in order to learn how the script works and
create your first template file for dynamic prompt generation.
-Fix InvokeAI GUI initialization by @addianto in #1687
-fix link in documentation by @lstein in #1728
-Fix broken link by @ShawnZhong in #1736
-Remove reference to binary installer by @lstein in #1731
-documentation fixes for 2.2.3 by @lstein in #1740
-Modify installer links to point closer to the source installer by @ebr in
#1745
-add documentation warning about 1650/60 cards by @lstein in #1753
-Fix Linux source URL in installation docs by @andybearman in #1756
-Make install instructions discoverable in readme by @damian0815 in #1752
-typo fix by @ofirkris in #1755
-Non-interactive model download (support HUGGINGFACE_TOKEN) by @ebr in #1578
-fix(srcinstall): shell installer - cp scripts instead of linking by @tildebyte
in #1765
-stability and usage improvements to binary & source installers by @lstein in
#1760
-fix off-by-one bug in cross-attention-control by @damian0815 in #1774
-Eventually update APP_VERSION to 2.2.3 by @spezialspezial in #1768
-invoke script cds to its location before running by @lstein in #1805
-Make PaperCut and VoxelArt models load again by @lstein in #1730
-Fix --embedding_directory / --embedding_path not working by @blessedcoolant in
#1817
-Clean up readme by @hipsterusername in #1820
-Optimized Docker build with support for external working directory by @ebr in
#1544
-disable pushing the cloud container by @mauwii in #1831
-Fix docker push github action and expand with additional metadata by @ebr in
#1837
-Fix Broken Link To Notebook by @VedantMadane in #1821
-Account for flat models by @spezialspezial in #1766
-Update invoke.bat.in isolate environment variables by @lynnewu in #1833
-Arch Linux Specific PatchMatch Instructions & fixing conda install on linux by
@SammCheese in #1848
-Make force free GPU memory work in img2img by @addianto in #1844
-New installer by @lstein
### v2.3.1 <small>(26 February 2023)</small>
For older changelogs, please visit the
This is primarily a bugfix release, but it does provide several new features that will improve the user experience.
#### Enhanced support for model management
InvokeAI now makes it convenient to add, remove and modify models. You can individually import models that are stored on your local system, scan an entire folder and its subfolders for models and import them automatically, and even directly import models from the internet by providing their download URLs. You also have the option of designating a local folder to scan for new models each time InvokeAI is restarted.
There are three ways of accessing the model management features:
1. ***From the WebUI***, click on the cube to the right of the model selection menu. This will bring up a form that allows you to import models individually from your local disk or scan a directory for models to import.
Choose option (5) _download and install models_ from the `invoke` launcher script to start a new console-based application for model management. You can use this to select from a curated set of starter models, or import checkpoint, safetensors, and diffusers models from a local disk or the internet. The example below shows importing two checkpoint URLs from popular SD sites and a HuggingFace diffusers model using its Repository ID. It also shows how to designate a folder to be scanned at startup time for new models to import.
Command-line users can start this app using the command `invokeai-model-install`.
The `!install_model` and `!convert_model` commands have been enhanced to allow entering of URLs and local directories to scan and import. The first command installs .ckpt and .safetensors files as-is. The second one converts them into the faster diffusers format before installation.
Internally InvokeAI is able to probe the contents of a .ckpt or .safetensors file to distinguish among v1.x, v2.x and inpainting models. This means that you do **not** need to include "inpaint" in your model names to use an inpainting model. Note that Stable Diffusion v2.x models will be autoconverted into a diffusers model the first time you use it.
Please see [INSTALLING MODELS](https://invoke-ai.github.io/InvokeAI/installation/050_INSTALLING_MODELS/) for more information on model management.
#### An Improved Installer Experience
The installer now launches a console-based UI for setting and changing commonly-used startup options:
After selecting the desired options, the installer installs several support models needed by InvokeAI's face reconstruction and upscaling features and then launches the interface for selecting and installing models shown earlier. At any time, you can edit the startup options by launching `invoke.sh`/`invoke.bat` and entering option (6) _change InvokeAI startup options_
Command-line users can launch the new configure app using `invokeai-configure`.
This release also comes with a renewed updater. To do an update without going through a whole reinstallation, launch `invoke.sh` or `invoke.bat` and choose option (9) _update InvokeAI_ . This will bring you to a screen that prompts you to update to the latest released version, to the most current development version, or any released or unreleased version you choose by selecting the tag or branch of the desired version.
Command-line users can run this interface by typing `invokeai-configure`
#### Image Symmetry Options
There are now features to generate horizontal and vertical symmetry during generation. The way these work is to wait until a selected step in the generation process and then to turn on a mirror image effect. In addition to generating some cool images, you can also use this to make side-by-side comparisons of how an image will look with more or fewer steps. Access this option from the WebUI by selecting _Symmetry_ from the image generation settings, or within the CLI by using the options `--h_symmetry_time_pct` and `--v_symmetry_time_pct` (these can be abbreviated to `--h_sym` and `--v_sym` like all other options).
This release introduces a beta version of the WebUI Unified Canvas. To try it out, open up the settings dialogue in the WebUI (gear icon) and select _Use Canvas Beta Layout_:
Refresh the screen and go to to Unified Canvas (left side of screen, third icon from the top). The new layout is designed to provide more space to work in and to keep the image controls close to the image itself:
#### Model conversion and merging within the WebUI
The WebUI now has an intuitive interface for model merging, as well as for permanent conversion of models from legacy .ckpt/.safetensors formats into diffusers format. These options are also available directly from the `invoke.sh`/`invoke.bat` scripts.
#### An easier way to contribute translations to the WebUI
We have migrated our translation efforts to [Weblate](https://hosted.weblate.org/engage/invokeai/), a FOSS translation product. Maintaining the growing project's translations is now far simpler for the maintainers and community. Please review our brief [translation guide](https://github.com/invoke-ai/InvokeAI/blob/v2.3.1/docs/other/TRANSLATION.md) for more information on how to contribute.
#### Numerous internal bugfixes and performance issues
This releases quashes multiple bugs that were reported in 2.3.0. Major internal changes include upgrading to `diffusers 0.13.0`, and using the `compel` library for prompt parsing. See [Detailed Change Log](#full-change-log) for a detailed list of bugs caught and squished.
#### Summary of InvokeAI command line scripts (all accessible via the launcher menu)
1.<aname="hardware_requirements">**Hardware Requirements**: </a>Make sure that your system meets the [hardware
requirements](../index.md#hardware-requirements) and has the
appropriate GPU drivers installed. For a system with an NVIDIA
card installed, you will need to install the CUDA driver, while
AMD-based cards require the ROCm driver. In most cases, if you've
already used the system for gaming or other graphics-intensive
tasks, the appropriate drivers will already be installed. If
unsure, check the [GPU Driver Guide](030_INSTALL_CUDA_AND_ROCM.md)
!!! info "Required Space"
Installation requires roughly 18G of free disk space to load the libraries and
recommended model weights files.
Installation requires roughly 18G of free disk space to load
the libraries and recommended model weights files.
Regardless of your destination disk, your *system drive* (`C:\` on Windows, `/` on macOS/Linux) requires at least 6GB of free disk space to download and cache python dependencies. NOTE for Linux users: if your temporary directory is mounted as a `tmpfs`, ensure it has sufficient space.
Regardless of your destination disk, your *system drive*
(`C:\` on Windows, `/` on macOS/Linux) requires at least 6GB
of free disk space to download and cache python
dependencies.
2. Check that your system has an up-to-date Python installed. To do this, open
up a command-line window ("Terminal" on Linux and Macintosh, "Command" or
"Powershell" on Windows) and type `python --version`. If Python is
installed, it will print out the version number. If it is version `3.9.1` or
higher, you meet requirements.
NOTE for Linux users: if your temporary directory is mounted
as a `tmpfs`, ensure it has sufficient space.
!!! warning "If you see an older version, or get a command not found error"
2.<aname="software_requirements">**Software Requirements**: </a>Check that your system has an up-to-date Python installed. To do
this, open up a command-line window ("Terminal" on Linux and
Macintosh, "Command" or "Powershell" on Windows) and type `python
--version`. If Python is installed, it will print out the version
number. If it is version `3.9.*` or `3.10.*`, you meet
requirements. We do not recommend using Python 3.11 or higher,
as not all the libraries that InvokeAI depends on work properly
with this version.
Go to [Python Downloads](https://www.python.org/downloads/) and
download the appropriate installer package for your platform. We recommend
- Installation requires an up to date version of the Microsoft Visual C libraries. Please install the 2015-2022 libraries available here: https://learn.microsoft.com/en-us/cpp/windows/deploying-native-desktop-applications-visual-cpp?view=msvc-170
Please double-click on the file `WinLongPathsEnabled.reg` and
accept the dialog box that asks you if you wish to modify your registry.
This activates long filename support on your system and will prevent
mysterious errors during installation.
=== "Mac users"
- After installing Python, you may need to run the
following command from the Terminal in order to install the Web
certificates needed to download model data from https sites. If
you see lots of CERTIFICATE ERRORS during the last part of the
install, this is the problem, and you can fix it with this command:
For reasons that are not entirely clear, installing the correct version of Python can be a bit of a challenge on Ubuntu, Linux Mint, Pop!_OS, and other Debian-derived distributions.
On Ubuntu 22.04 and higher, run the following:
=== "Linux"
To install an appropriate version of Python on Ubuntu 22.04
and higher, run the following:
```
sudo apt update
@ -98,75 +93,101 @@ version of InvokeAI with the option to upgrade to experimental versions later.
Both `python` and `python3` commands are now pointing at Python3.10. You can still access older versions of Python by calling `python2`, `python3.8`, etc.
Both `python` and `python3` commands are now pointing at
Python3.10. You can still access older versions of Python by
calling `python2`, `python3.8`, etc.
Linux systems require a couple of additional graphics libraries to be installed for proper functioning of `python3-opencv`. Please run the following:
Linux systems require a couple of additional graphics
libraries to be installed for proper functioning of
4. Unpack the zip file into a convenient directory. This will create a new
directory named "InvokeAI-Installer". This example shows how this would look
using the `unzip` command-line tool, but you may use any graphical or
command-line Zip extractor:
You may need to install the Xcode command line tools. These
are a set of tools that are needed to run certain applications in a
Terminal, including InvokeAI. This package is provided
directly by Apple. To install, open a terminal window and run `xcode-select --install`. You will get a macOS system popup guiding you through the
install. If you already have them installed, you will instead see some
output in the Terminal advising you that the tools are already installed. More information can be found at [FreeCode Camp](https://www.freecodecamp.org/news/install-xcode-command-line-tools/)
commands and the PIP package manager. The [second one](#Conda_method)
based on the Anaconda3 package manager (`conda`). Both methods require
you to enter commands on the terminal, also known as the "console".
!!! tip "Conda"
As of InvokeAI v2.3.0 installation using the `conda` package manager is no longer being supported. It will likely still work, but we are not testing this installationmethod.
Note that the conda install method is currently deprecated and will not
be supported at some point in the future.
On Windows systems you are encouraged to install and use the
If you choose the run the web interface, point your browser at
@ -197,393 +248,122 @@ manager, please follow these steps:
!!! tip
You can permanently set the location of the runtime directory by setting the environment variable INVOKEAI_ROOT to the path of the directory.
You can permanently set the location of the runtime directory
by setting the environment variable `INVOKEAI_ROOT` to the
path of the directory. As mentioned previously, this is
*highly recommended** if your virtual environment is located outside of
your runtime directory.
9. Render away!
10. Render away!
Browse the [features](../features/CLI.md) section to learn about all the things you
can do with InvokeAI.
Browse the [features](../features/CLI.md) section to learn about all the
things you can do with InvokeAI.
Note that some GPUs are slow to warm up. In particular, when using an AMD
card with the ROCm driver, you may have to wait for over a minute the first
time you try to generate an image. Fortunately, after the warm up period
rendering will be fast.
10. Subsequently, to relaunch the script, be sure to run "conda activate
invokeai", enter the `InvokeAI` directory, and then launch the invoke
script. If you forget to activate the 'invokeai' environment, the script
will fail with multiple `ModuleNotFound` errors.
11. Subsequently, to relaunch the script, activate the virtual environment, and
then launch `invokeai` command. If you forget to activate the virtual
environment you will most likeley receive a `command not found` error.
!!! tip
!!! warning
Do not move the source code repository after installation. The virtual environment directory has absolute paths in it that get confused if the directory is moved.
Do not move the runtime directory after installation. The virtual environment will get confused if the directory is moved.
---
12. Other scripts
### Conda method
The [Textual Inversion](../features/TEXTUAL_INVERSION.md) script can be launched with the command:
1. Check that your system meets the
[hardware requirements](index.md#Hardware_Requirements) and has the
appropriate GPU drivers installed. In particular, if you are a Linux user
with an AMD GPU installed, you may need to install the
Afterwards verify that the file `environment.yml` has been created, either via the
explorer or by using the command `dir` from the terminal
```cmd
dir
```
!!! warning "Do not try to run conda on directly on the subdirectory environments file. This won't work. Instead, copy or link it to the top-level directory as shown."
6. Create the conda environment:
=== "MPS (M1 and M2 Macs)"
```bash
conda env update
pip install -e . --use-pep517
```
This will create a new environment named `invokeai` and install all InvokeAI
dependencies into it. If something goes wrong you should take a look at
[troubleshooting](#troubleshooting).
Be sure to pass `-e` (for an editable install) and don't forget the
dot ("."). It is part of the command.
7. Activate the `invokeai` environment:
You can now run `invokeai` and its related commands. The code will be
read from the repository, so that you can edit the .py source files
and watch the code's behavior change.
In order to use the newly created environment you will first need to
activate it
4. If you wish to contribute to the InvokeAI project, you are
encouraged to establish a GitHub account and "fork"
https://github.com/invoke-ai/InvokeAI into your own copy of the
repository. You can then use GitHub functions to create and submit
pull requests to contribute improvements to the project.
```bash
Please see [Contributing](../index.md#contributing) for hints
on getting started.
### Unsupported Conda Install
Congratulations, you found the "secret" Conda installation
instructions. If you really **really** want to use Conda with InvokeAI
| `HUGGING_FACE_HUB_TOKEN` | No default, but **required**! | This is the only **required** variable, without it you can't download the huggingface models |
| `REPOSITORY_NAME` | The Basename of the Repo folder | This name will used as the container repository/image name |
| `VOLUMENAME` | `${REPOSITORY_NAME,,}_data` | Name of the Docker Volume where model files will be stored |
| `ARCH` | arch of the build machine | can be changed if you want to build the image for another arch |
| `INVOKEAI_TAG` | latest | the Container Repository / Tag which will be used |
| `PIP_REQUIREMENTS` | `requirements-lin-cuda.txt` | the requirements file to use (from `environments-and-requirements`) |
| `CONTAINER_FLAVOR`| cuda | the flavor of the image, which can be changed if you build f.e. with amd requirements file. |
| `INVOKE_DOCKERFILE` | `docker-build/Dockerfile` | the Dockerfile which should be built, handy for development |
| `ARCH` | arch of the build machine | Can be changed if you want to build the image for another arch |
| `CONTAINER_REGISTRY` | ghcr.io | Name of the Container Registry to use for the full tag |
| `CONTAINER_REPOSITORY` | `$(whoami)/${REPOSITORY_NAME}` | Name of the Container Repository |
| `CONTAINER_FLAVOR` | `cuda`| The flavor of the image to built, available options are `cuda`, `rocm` and `cpu`. If you choose `rocm` or `cpu`, the extra-index-url will be selected automatically, unless you set one yourself. |
| `CONTAINER_TAG` | `${INVOKEAI_BRANCH##*/}-${CONTAINER_FLAVOR}` | The Container Repository / Tag which will be used |
| `INVOKE_DOCKERFILE` | `Dockerfile` | The Dockerfile which should be built, handy for development |
| `PIP_EXTRA_INDEX_URL` | | If you want to use a custom pip-extra-index-url |
</figure>
#### Build the Image
I provided a build script, which is located in `docker-build/build.sh` but still
needs to be executed from the Repository root.
I provided a build script, which is located next to the Dockerfile in
`docker/build.sh`. It can be executed from repository root like this:
```bash
./docker-build/build.sh
./docker/build.sh
```
The build Script not only builds the container, but also creates the docker
volume if not existing yet, or if empty it will just download the models.
volume if not existing yet.
#### Run the Container
After the build process is done, you can run the container via the provided
`docker-build/run.sh` script
`docker/run.sh` script
```bash
./docker-build/run.sh
./docker/run.sh
```
When used without arguments, the container will start the webserver and provide
For example, use `GPU_FLAGS=device=GPU-3a23c669-1f69-c64e-cf85-44e9b07e7a2a` to choose a specific device identified by a UUID.
## Running InvokeAI in the cloud with Docker
We offer an optimized Ubuntu-based image that has been well-tested in cloud deployments. Note: it also works well locally on Linux x86_64 systems with an Nvidia GPU. It *may* also work on Windows under WSL2 and on Intel Mac (not tested).
An advantage of this method is that it does not need any local setup or additional dependencies.
See the `docker-build/Dockerfile.cloud` file to familizarize yourself with the image's content.
### Prerequisites
- a `docker` runtime
- `make` (optional but helps for convenience)
- Huggingface token to download models, or an existing InvokeAI runtime directory from a previous installation
Neither local Python nor any dependencies are required. If you don't have `make` (part of `build-essentials` on Ubuntu), or do not wish to install it, the commands from the `docker-build/Makefile` are readily adaptable to be executed directly.
### Building and running the image locally
1. Clone this repo and `cd docker-build`
1. `make build` - this will build the image. (This does *not* require a GPU-capable system).
1. _(skip this step if you already have a complete InvokeAI runtime directory)_
- `make configure` (This does *not* require a GPU-capable system)
- this will create a local cache of models and configs (a.k.a the _runtime dir_)
- enter your Huggingface token when prompted
1. `make web`
1. Open the `http://localhost:9090` URL in your browser, and enjoy the banana sushi!
To use InvokeAI on the cli, run `make cli`. To open a Bash shell in the container for arbitraty advanced use, `make shell`.
#### Building and running without `make`
(Feel free to adapt paths such as `${HOME}/invokeai` to your liking, and modify the CLI arguments as necessary).
!!! example "Build the image and configure the runtime directory"
This image works anywhere you can run a container with a mounted Docker volume. You may either build this image on a cloud instance, or build and push it to your Docker registry. To manually run this on a cloud instance (such as AWS EC2, GCP or Azure VM):
1. build this image either in the cloud (you'll need to pull the repo), or locally
1. `docker tag` it as `your-registry/invokeai` and push to your registry (i.e. Dockerhub)
1. `docker pull` it on your cloud instance
1. configure the runtime directory as per above example, using `docker run ... configure_invokeai.py` script
1. use either one of the `docker run` commands above, substituting the image name for your own image.
To run this on Runpod, please refer to the following Runpod template: https://www.runpod.io/console/gpu-secure-cloud?template=vm19ukkycf (you need a Runpod subscription). When launching the template, feel free to set the image to pull your own build.
The template's `README` provides ample detail, but at a high level, the process is as follows:
1. create a pod using this Docker image
1. ensure the pod has an `INVOKEAI_ROOT=<path_to_your_persistent_volume>` environment variable, and that it corresponds to the path to your pod's persistent volume mount
1. Run the pod with `sleep infinity` as the Docker command
1. Use Runpod basic SSH to connect to the pod, and run `python scripts/configure_invokeai.py` script
1. Stop the pod, and change the Docker command to `python scripts/invoke.py --web --host 0.0.0.0`
1. Run the pod again, connect to your pod on HTTP port 9090, and enjoy the banana sushi!
Running on other cloud providers such as Vast.ai will likely work in a similar fashion.
For example, use `GPU_FLAGS=device=GPU-3a23c669-1f69-c64e-cf85-44e9b07e7a2a` to
choose a specific device identified by a UUID.
---
@ -240,13 +164,12 @@ Running on other cloud providers such as Vast.ai will likely work in a similar f
If you're on a **Linux container** the `invoke` script is **automatically
started** and the output dir set to the Docker volume you created earlier.
If you're **directly on macOS follow these startup instructions**.
With the Conda environment activated (`conda activate ldm`), run the interactive
If you're **directly on macOS follow these startup instructions**. With the
Conda environment activated (`conda activate ldm`), run the interactive
interface that combines the functionality of the original scripts `txt2img` and
`img2img`:
Use the more accurate but VRAM-intensive full precision math because
half-precision requires autocast and won't work.
By default the images are saved in `outputs/img-samples/`.
`img2img`: Use the more accurate but VRAM-intensive full precision math because
half-precision requires autocast and won't work. By default the images are saved
in `outputs/img-samples/`.
```Shell
python3 scripts/invoke.py --full_precision
@ -262,9 +185,9 @@ invoke> q
### Text to Image
For quick (but bad) image results test with 5 steps (default 50) and 1 sample
image. This will let you know that everything is set up correctly.
Then increase steps to 100 or more for good (but slower) results.
The prompt can be in quotes or not.
image. This will let you know that everything is set up correctly. Then increase
steps to 100 or more for good (but slower) results. The prompt can be in quotes
or not.
```Shell
invoke> The hulk fighting with sheldon cooper -s5 -n1
@ -277,10 +200,9 @@ You'll need to experiment to see if face restoration is making it better or
worse for your specific prompt.
If you're on a container the output is set to the Docker volume. You can copy it
wherever you want.
You can download it from the Docker Desktop app, Volumes, my-vol, data.
Or you can copy it from your Mac terminal. Keep in mind `docker cp` can't expand
`*.png` so you'll need to specify the image file name.
wherever you want. You can download it from the Docker Desktop app, Volumes,
my-vol, data. Or you can copy it from your Mac terminal. Keep in mind
`docker cp` can't expand `*.png` so you'll need to specify the image file name.
On your host Mac (you can use the name of any container that mounted the
|stable-diffusion-1.5 | v1-5-pruned-emaonly.ckpt | Most recent version of base Stable Diffusion model | https://huggingface.co/runwayml/stable-diffusion-v1-5 |
| stable-diffusion-1.4 | sd-v1-4.ckpt | Previous version of base Stable Diffusion model | https://huggingface.co/CompVis/stable-diffusion-v-1-4-original |
| inpainting-1.5 | sd-v1-5-inpainting.ckpt | Stable Diffusion 1.5 model specialized for inpainting | https://huggingface.co/runwayml/stable-diffusion-inpainting |
| waifu-diffusion-1.3 | model-epoch09-float32.ckpt | Stable Diffusion 1.4 trained to produce anime images | https://huggingface.co/hakurei/waifu-diffusion-v1-3 |
|`<all models>` | vae-ft-mse-840000-ema-pruned.ckpt | A fine-tune file add-on file that improves face generation | https://huggingface.co/stabilityai/sd-vae-ft-mse-original/ |
|Model Name | HuggingFace Repo ID | Description | URL |
|---------- | ---------- | ----------- | --- |
|stable-diffusion-1.5|runwayml/stable-diffusion-v1-5|Stable Diffusion version 1.5 diffusers model (4.27 GB)|https://huggingface.co/runwayml/stable-diffusion-v1-5 |
|sd-inpainting-1.5|runwayml/stable-diffusion-inpainting|RunwayML SD 1.5 model optimized for inpainting, diffusers version (4.27 GB)|https://huggingface.co/runwayml/stable-diffusion-inpainting |
|stable-diffusion-2.1|stabilityai/stable-diffusion-2-1|Stable Diffusion version 2.1 diffusers model, trained on 768 pixel images (5.21 GB)|https://huggingface.co/stabilityai/stable-diffusion-2-1 |
|sd-inpainting-2.0|stabilityai/stable-diffusion-2-1|Stable Diffusion version 2.0 inpainting model (5.21 GB)|https://huggingface.co/stabilityai/stable-diffusion-2-1 |
|analog-diffusion-1.0|wavymulder/Analog-Diffusion|An SD-1.5 model trained on diverse analog photographs (2.13 GB)|https://huggingface.co/wavymulder/Analog-Diffusion |
|deliberate-1.0|XpucT/Deliberate|Versatile model that produces detailed images up to 768px (4.27 GB)|https://huggingface.co/XpucT/Deliberate |
|dreamlike-photoreal-2.0|dreamlike-art/dreamlike-photoreal-2.0|A photorealistic model trained on 768 pixel images based on SD 1.5 (2.13 GB)|https://huggingface.co/dreamlike-art/dreamlike-photoreal-2.0 |
|inkpunk-1.0|Envvi/Inkpunk-Diffusion|Stylized illustrations inspired by Gorillaz, FLCL and Shinkawa; prompt with "nvinkpunk" (4.27 GB)|https://huggingface.co/Envvi/Inkpunk-Diffusion |
|openjourney-4.0|prompthero/openjourney|An SD 1.5 model fine tuned on Midjourney; prompt with "mdjrny-v4 style" (2.13 GB)|https://huggingface.co/prompthero/openjourney |
|portrait-plus-1.0|wavymulder/portraitplus|An SD-1.5 model trained on close range portraits of people; prompt with "portrait+" (2.13 GB)|https://huggingface.co/wavymulder/portraitplus |
|seek-art-mega-1.0|coreco/seek.art_MEGA|A general use SD-1.5 "anything" model that supports multiple styles (2.1 GB)|https://huggingface.co/coreco/seek.art_MEGA |
|trinart-2.0|naclbit/trinart_stable_diffusion_v2|An SD-1.5 model finetuned with ~40K assorted high resolution manga/anime-style images (2.13 GB)|https://huggingface.co/naclbit/trinart_stable_diffusion_v2 |
|waifu-diffusion-1.4|hakurei/waifu-diffusion|An SD-1.5 model trained on 680k anime/manga-style images (2.13 GB)|https://huggingface.co/hakurei/waifu-diffusion |
Note that these files are covered by an "Ethical AI" license which forbids
certain uses. You will need to create an account on the Hugging Face website and
accept the license terms before you can access the files.
The predefined configuration file for InvokeAI (located at
`configs/models.yaml`) provides entries for each of these weights files.
`stable-diffusion-1.5` is the default model used, and we strongly recommend that
you install this weights file if nothing else.
Note that these files are covered by an "Ethical AI" license which
forbids certain uses. When you initially download them, you are asked
to accept the license terms. In addition, some of these models carry
additional license terms that limit their use in commercial
applications or on public servers. Be sure to familiarize yourself
with the model terms by visiting the URLs in the table above.
## Community-Contributed Models
There are too many to list here and more are being contributed every day.
HuggingFace maintains a
[fast-growing repository](https://huggingface.co/sd-concepts-library) of
fine-tune (".bin") models that can be imported into InvokeAI by passing the
`--embedding_path` option to the `invoke.py` command.
There are too many to list here and more are being contributed every
* `--model <modelname>` -- Start up with the indicated model loaded
* `--ckpt_convert` -- When a checkpoint/safetensors model is loaded, convert it into a `diffusers` model in memory. This does not permanently save the converted model to disk.
* `--autoconvert <path/to/directory>` -- Scan the indicated directory path for new checkpoint/safetensors files, convert them into `diffusers` models, and import them into InvokeAI.
Here is an example of providing an argument on the command line using
| arabian-nights-1.0 | This is the name of the model that you will refer to from within the CLI and the WebGUI when you need to load and use the model. |
| description | Any description that you want to add to the model to remind you what it is. |
| weights | Relative path to the .ckpt weights file for this model. |
| config | This is the confusingly-named configuration file for the model itself. Use `./configs/stable-diffusion/v1-inference.yaml` unless the model happens to need a custom configuration, in which case the place you downloaded it from will tell you what to use instead. For example, the runwayML custom inpainting model requires the file `configs/stable-diffusion/v1-inpainting-inference.yaml`. This is already inclued in the InvokeAI distribution and is configured automatically for you by the `configure_invokeai.py` script. |
| vae | If you want to add a VAE file to the model, then enter its path here. |
| width, height | This is the width and height of the images used to train the model. Currently they are always 512 and 512. |
Note that `format` is `ckpt` for both `.ckpt` and `.safetensors` files.
#### A diffusers model
A stanza for a `diffusers` model will look like this for a HuggingFace
model with a repository ID:
```yaml
arabian-nights-1.1:
description: An even better fine-tune of the Arabian Nights
repo_id: captahab/arabian-nights-1.1
format: diffusers
default: true
```
And for a downloaded directory:
```yaml
arabian-nights-1.1:
description: An even better fine-tune of the Arabian Nights
path: /path/to/captahab-arabian-nights-1.1
format: diffusers
default: true
```
There is additional syntax for indicating an external VAE to use with
this model. See `INITIAL_MODELS.yaml` and `models.yaml` for examples.
After you save the modified `models.yaml` file relaunch
`invokeai`. The new model will now be available for your use.
Save the `models.yaml` and relaunch InvokeAI. The new model should now be
Afterwards verify that the file `environment.yml` has been created, either via the
explorer or by using the command `dir` from the terminal
```cmd
dir
```
!!! warning "Do not try to run conda on directly on the subdirectory environments file. This won't work. Instead, copy or link it to the top-level directory as shown."
6. Create the conda environment:
```bash
conda env update
```
This will create a new environment named `invokeai` and install all InvokeAI
dependencies into it. If something goes wrong you should take a look at
[troubleshooting](#troubleshooting).
7. Activate the `invokeai` environment:
In order to use the newly created environment you will first need to
activate it
```bash
conda activate invokeai
```
Your command-line prompt should change to indicate that `invokeai` is active
by prepending `(invokeai)`.
8. Pre-Load the model weights files:
!!! tip
If you have already downloaded the weights file(s) for another Stable
Diffusion distribution, you may skip this step (by selecting "skip" when
prompted) and configure InvokeAI to use the previously-downloaded files. The
process for this is described in [here](INSTALLING_MODELS.md).
```bash
python scripts/configure_invokeai.py
```
The script `configure_invokeai.py` will interactively guide you through the
process of downloading and installing the weights files needed for InvokeAI.
Note that the main Stable Diffusion weights file is protected by a license
agreement that you have to agree to. The script will list the steps you need
to take to create an account on the site that hosts the weights files,
accept the agreement, and provide an access token that allows InvokeAI to
legally download and install the weights files.
If you get an error message about a module not being installed, check that
the `invokeai` environment is active and if not, repeat step 5.
9. Run the command-line- or the web- interface:
!!! example ""
!!! warning "Make sure that the conda environment is activated, which should create `(invokeai)` in front of your prompt!"
=== "CLI"
```bash
python scripts/invoke.py
```
=== "local Webserver"
```bash
python scripts/invoke.py --web
```
=== "Public Webserver"
```bash
python scripts/invoke.py --web --host 0.0.0.0
```
If you choose the run the web interface, point your browser at
http://localhost:9090 in order to load the GUI.
10. Render away!
Browse the [features](../features/CLI.md) section to learn about all the things you
can do with InvokeAI.
Note that some GPUs are slow to warm up. In particular, when using an AMD
card with the ROCm driver, you may have to wait for over a minute the first
time you try to generate an image. Fortunately, after the warm up period
rendering will be fast.
11. Subsequently, to relaunch the script, be sure to run "conda activate
invokeai", enter the `InvokeAI` directory, and then launch the invoke
script. If you forget to activate the 'invokeai' environment, the script
will fail with multiple `ModuleNotFound` errors.
## Updating to newer versions of the script
This distribution is changing rapidly. If you used the `git clone` method
(step 5) to download the InvokeAI directory, then to update to the latest and
greatest version, launch the Anaconda window, enter `InvokeAI` and type:
InvokeAI uses [Weblate](https://weblate.org) for translation. Weblate is a FOSS project providing a scalable translation service. Weblate automates the tedious parts of managing translation of a growing project, and the service is generously provided at no cost to FOSS projects like InvokeAI.
## Contributing
If you'd like to contribute by adding or updating a translation, please visit our [Weblate project](https://hosted.weblate.org/engage/invokeai/). You'll need to sign in with your GitHub account (a number of other accounts are supported, including Google).
Once signed in, select a language and then the Web UI component. From here you can Browse and Translate strings from English to your chosen language. Zen mode offers a simpler translation experience.
Your changes will be attributed to you in the automated PR process; you don't need to do anything else.
## Help & Questions
Please check Weblate's [documentation](https://docs.weblate.org/en/latest/index.html) or ping @psychedelicious or @blessedcoolant on Discord if you have any questions.
## Thanks
Thanks to the InvokeAI community for their efforts to translate the project!
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}